
2023年论文导读第二十四期
【论文导读】2023年论文导读第二十五期
CCF多媒体专委会 2023-12-19 08:00 发表于山东


论文导读
2023年论文导读第二十五期(总第九十一期)
目 录
|
1 |
MM-PCQA: Multi-Modal Learning for No-reference Point Cloud Quality Assessment |
|
2 |
FGNet: Towards Filling the Intra-class and Inter-class Gaps for Few-shot Segmentation |
|
3 |
Image Composition with Depth Registration |
|
4 |
Accurate MRI Reconstruction via Multi-Domain Recurrent Networks |
|
5 |
Manifold-Aware Self-Training for Unsupervised Domain Adaptation on Regressing 6D Object Pose |
|
6 |
3D Surface Super-resolution from Enhanced 2D Normal Images: A Multimodal-driven Variational AutoEncoder Approach |
01
MM-PCQA: Multi-Modal Learning for No-reference Point Cloud Quality Assessment
基于多模态学习的无参考点云质量评价
作者:张子澄、孙伟、闵雄阔、王启源、何俊、周泉、翟广涛
单位:上海交通大学
邮箱:
zzc1998@sjtu.edu.cn
论文:
https://arxiv.org/abs/2209.00244
代码:
https://github.com/zzc-1998/MM-PCQA
点云质量评价旨在量化点云的视觉质量分数。纯几何的点云模态可以明确地揭示几何下采样的失真,但在不涉及投影的情况下,它们无法识别纹理噪声,这提出了对多模态感知的需求。因此,为了提升点云质量评价(Point Cloud Quality Assessment, PCQA)的性能,我们提出了一种用于无参考点云质量评价(No-reference Point Cloud Quality Assessment , NR-PCQA)的多模态学习策略,该策略不仅从3D点云模态中提取质量感知特征,还可以从2D投影模态中提取。采用这种策略有两个主要原因。首先,点云可以在2D/3D场景中被感知。我们可以通过将点云投影到屏幕上从2D角度查看点云,或者使用VR设备直接以3D格式观看点云。因此,多模态学习能够涵盖更多实际情况的范围。其次,不同类型的失真对不同模态的视觉影响有所不同。如下图所示,结构损伤和几何下采样在点云模态中更为明显,而图像模态对由颜色量化和颜色噪声引起的纹理失真更敏感。

动机展示
我们提出的多模态框架如下图所示。考虑到局部模式(如光滑和粗糙)对质量评价非常重要,我们首先提出将点云分割成子模型进行分析,而不是直接进行下采样。接着我们从几个固定视点渲染点云,并保持固定的观看距离来维持纹理尺度的一致性,从而获得图像投影。然后使用点云编码器和图像编码器分别对点云和投影图像进行编码,生成质量感知的特征编码,随后通过对称的跨模态注意力进行加强。最后,将这些质量感知的特征编码通过全连接层解码成质量值。

方法框架
最终,我们提出的多模态方法在多个点云质量评价数据集上取得了优异的性能表现,相对于传统的单模态质量评价算法有着显著的性能提升。这充分证明了我们设计思路的有效性,并且证实了多模态学习能够有效帮助模型提升对点云视觉质量的感知能力。
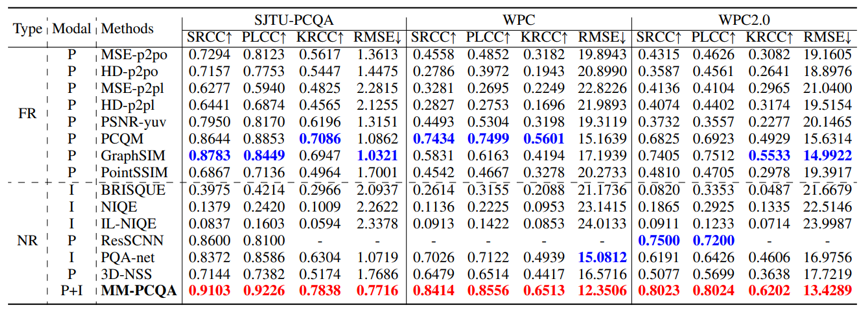
实验性能
02
FGNet: Towards Filling the Intra-class and Inter-class Gaps for Few-shot Segmentation
作者:张雨轩,杨威,王绍蔚
单位:中国科学技术大学
邮箱:
yxzhang123@mail.ustc.edu.cn;
qubit@ustc.edu.cn;
wangsw@gzhu.edu.cn
论文:
https://www.ijcai.org/proceedings/2023/0194.pdf
研究背景
小样本语义分割近几年取得了非常大的进展,但现阶段的方法主要面临两个问题:1)类内方差过大:当前方法往往采用原型的方式学习到某个特定类别的平均特征,而当新类别的样本标注数量过少时,就会导致此类别的模式覆盖不完备。换言之,支撑集的特征与查询集相差过大,就会导致建立的原型无法与查询集进行匹配。2)类间方差过小:新类别样本的稀缺致使其特征空间变得稀疏,并进一步导致类间分类混淆。具体来说,对于具有相似特征的两个类别,当前方法难以鉴定其决策边界。
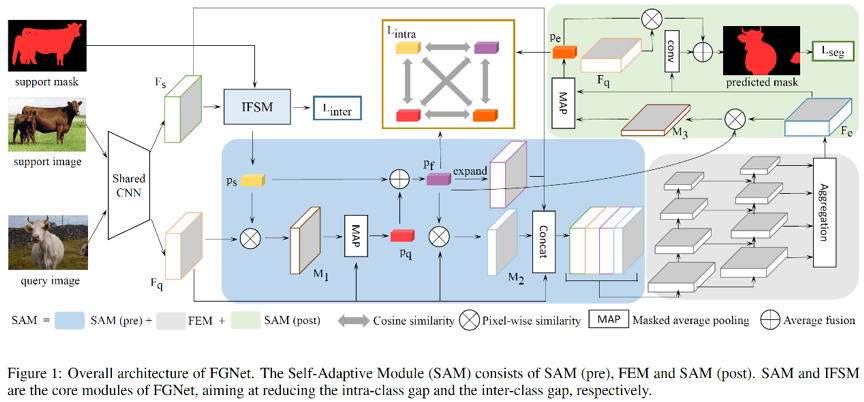
图1 FGNet算法整体框架
研究方法
本文提出了一个统一的网络FGNet,用于解决上述类内和类间的方差问题。FGNet的模型结构如图1所示。在FGNet中,我们设计了一个自对齐模块SAM来解决类内方差问题,并构造了一个类间特征分离模块IFSM来解决类间方差问题。对于前者,考虑到小样本任务中难免存在支撑集样本不充分的问题,因此SAM通过建立高置信度查询集原型的方式,用于对查询集的图像特征进行自适应匹配,使得该方法适用于任意图像以避免支撑集原型不全面的问题。对于后者,为解决类间相似度高的问题,IFSM模块从以下两个方面入手:1)通过一个类交叉损失来降低不同类别特征原型之间的相似度,从而拉大对应特征空间的距离,使得决策边界更加清晰。2)背景区域往往是容易忽视的部分,在小样本分割任务的设定中,背景区域往往包含较多的非目标类别实例。因此IFSM采用超像素SLIC的方法,对背景区域进行划分,然后对每一个超像素提取特征原型,并降低其与前景特征原型之间的相似度。通过上述两个优化目标,IFSM拉大了不同类别特征之间的距离。
实验结果
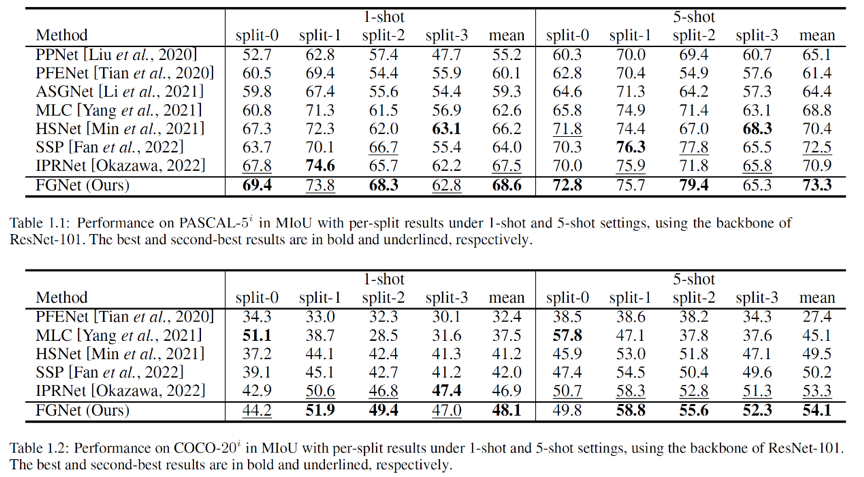
FGNet在两个最常用的公开数据集(Pascal-5i和COCO-20i)上,在1-shot和5-shot两种场景下均达到了当前最佳的性能表现,主要的实验结果如表1所示。
表1 主要实验结果
03
Image Composition with Depth Registration
基于深度注册的图像合成
作者:李赞1,2,王文成1,2,侯飞1,2
单位:1中国科学院软件研究所计算机科学国家重点实验室,2中国科学院大学
邮箱:
lizhan@ios.ac.cn
whn@ios.ac.cn
houfei@ios.ac.cn
论文:
https://www.ijcai.org/proceedings/2023/0126.pdf
1.引言
图像合成是指将来自不同图像中的内容融合成一张看似真实的图像,是一种应用广泛的图像内容生成方法。已有的图像合成方法在色彩的无缝拼接方面取得了很大的进步,但对于图像内容之间的遮挡关系研究不多。为此,已有方法往往需要用户交互地进行遮挡关系的调整或删去被遮挡的部分,以生成遮挡关系合适的合成图像。但这需要大量的交互操作,工作效率不高。本文提出一种深度注册的方法,只需简单的交互处理,即可便捷地处理不同图像内容之间的遮挡关系,很好地提高工作效率。
2.方法
我们的方法主要分为以下三步:
1) 利用图像内容分割和深度估计的深度学习方法,获得源图像和目标图像中的各种图像内容及其在各自图像中的深度信息。然后,对于将融入目标图像的源图像中的被拾取图像内容,任意选定其中一个像素为锚点,并计算该图像内容中其它像素到锚点像素的深度差,由此得到该图像内容与视点无关的一种与视点无关的“差值”三维表达。
2) 将来自源图像中的拾取图像内容放到目标图像中,并调整其图像呈现的大小,使其看上去与目标图像中的一个比对图像内容具有相似的深度,由此,可将该比对图像内容中的一个合适像素的深度信息赋值给拾取图像内容中的锚点像素,并基于拾取图像内容的“差值”三维表达,即可得到该拾取图像内容在目标图像所在三维空间中的深度信息,完成其深度注册。
3) 对于完成了深度注册的拾取图像内容,用户根据合成图像的需求将其进行不同位置的摆放,然后可依据目标图像中各内容与拾取图像内容的深度信息进行比对,即可处理它们之间的遮挡关系。
由于深度学习方法对于图像分割和深度估计存在一定的误差,会影响图像合成中的遮挡关系的处理。对此,我们方法提出进行交互的遮挡关系的纠正,并在纠正过程中进行图像内容分割和深度估计的优化改进,由此在后续的不同摆放方式的图像合成中能更有效地处理遮挡关系,以减少交互操作。
3.实验
我们与多个关注遮挡关系处理的图像合成方法进行了对比,包括:1)基于一定先验处理遮挡关系的Tan方法,2)基于深度学习处理遮挡关系的CompGAN方法,3)基于手动调整的Photoshop (PS)方法。如图1中的实验结果所示,Tan和CompGAN会生成遮挡关系错误的合成图像。虽然PS方法能生成遮挡关系合适的合成图像,但其交互次数和时间开销比我们方法要多许多倍(见表1)。

图1 对比方法的合成图像比较
表1 与Photoshop的效率对比(基于图1中的图像生成)

04
Accurate MRI Reconstruction via Multi-Domain Recurrent Networks
作者:魏金宝,王志杰,汪孔桥,郭立,傅雪阳,刘际,陈勋
单位:中国科学技术大学,华米科技
邮箱:
wei1998@mail.ustc.edu.cn
论文:
https://www.ijcai.org/proceedings/2023/0169.pdf
1. 介绍
目前多数快速磁共振重建算法方法专注于在空间域或是在频率域上重建欠采样磁共振图像,却忽略了这两个域之间的相关性,阻碍了重建算法性能的进一步提高。为了解决这个问题,我们在这项工作中提出了一种以多域学习(MDL)块为基本单元的新型多域循环网络(MDR-Net),以逐步重建欠采样磁共振图像。

图1 MDR-Net 总体结构框图
2. 方法
为解决上述问题,本文基于编码器-译码器结构设计了一个新型多域循环网络(如图1所示),其中引入了手工设计的MDL模块(如图2所示)用于提取空-频域细化特征。具体地说,MDL 模块包含的频率分支利用傅里叶变换(FFT)来学习频域的全局信息,同时空域分支使用残差卷积模块提取局部特征,期间对各个分支学习到的特征信息进行互补学习,最后采用多头部转置注意力(MDTA)对学习到的空-频域特征进行跨信道特征交互。

图2 MDLB 多域学习模块
另外,实验发现基于空域的损失函数往往会导致网络难以恢复图像的高频信息,导致重建图像的病理细节丢失。基于此,本文引入了一种基于频域的损失函数,以缩小频谱差距,实验发现,该损失函数能够有效地重建图像的频域信息,准确地恢复了图像的精细特征。
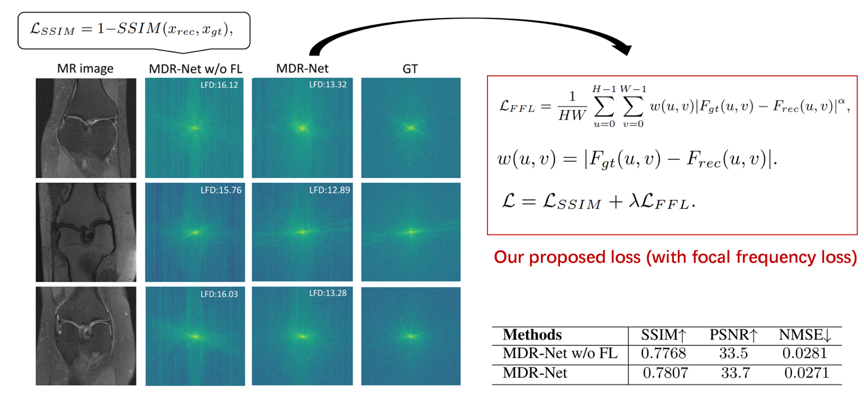
图3 损失函数设计及实验结果对比
3. 实验
我们在两个公开的MRI数据集上进行了实验,结果表明所提出的MDR-Net 始终优于其他竞争方法,并能够提供更多图像的细节信息。
表1 定量结果对比
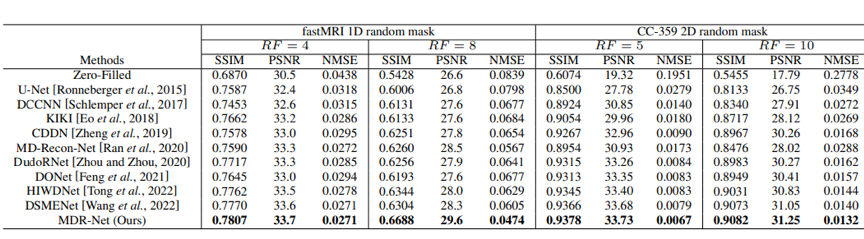
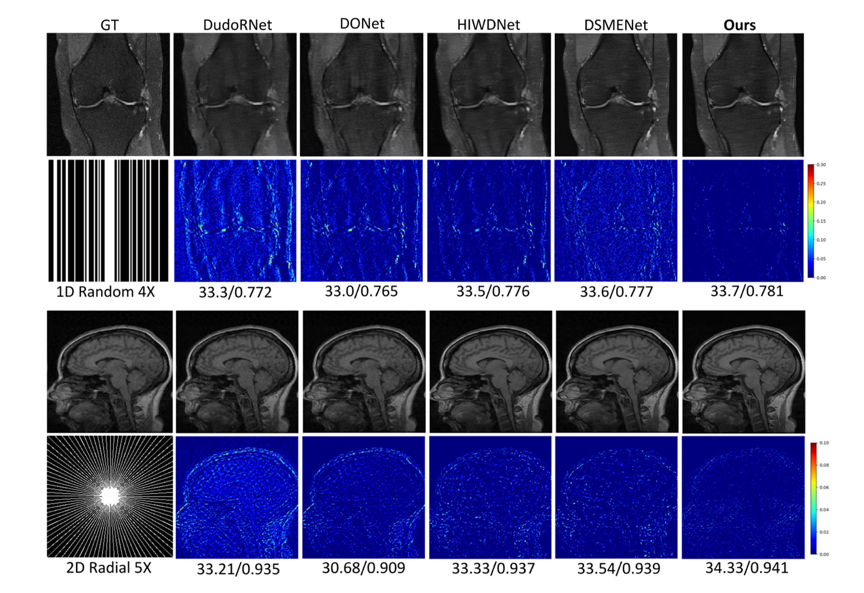
图4 定性结果对比
05
Manifold-Aware Self-Training for Unsupervised Domain Adaptation on Regressing 6D Object Pose
作者:张懿辰1, 林杰鸿1, 陈轲1,2, 许泽林1, 王耀威2, 贾奎1,2
单位:1华南理工大学,2鹏城实验室
邮箱:
eezyc@mail.scut.edu.cn,
lin.jiehong@mail.scut.edu.cn,
eexuzelin@mail.scut.edu.cn,
chenk@scut.edu.cn,
kuijia@scut.edu.cn,
wangyw@pcl.ac.cn
论文:
https://doi.org/10.24963/ijcai.2023/193
一、背景:
在实际生产中,标注用于训练6D姿态回归任务所需的数据十分繁琐,通过PBR渲染合成数据可以极大简化数据标注流程,但是在合成数据上训练的模型与真实数据之间存在domain gap,需要找到缩减差距的方法。针对分类任务的无监督域适应(UDA)方法已有不少研究,但是对于姿态估计或回归任务的UDA方法很少而且效果不佳,本文提出了一种SOTA的仅需要RGB图像的针对姿态回归的UDA方法。
二、方法创新:
1) 将6D姿态直接回归任务拆分为对特征缩放鲁棒的全局粗分类和局部微调回归,使姿态回归器获得跨域特征缩放鲁棒性,同时能够利用分类器上的置信度τ筛选高置信度伪标签(图1红色部分),然后利用self-training进行全局特征对齐,缩小domain gap。

图1
2) 引入累积目标相关度正则化(图1、2中cumulative target correlation regularization),利用回归目标的分段流形相关性在不同域上一致的特性,获得跨域鲁棒性,同时减轻粗分类分支对姿态回归模型流形分布的影响。图2左下角图像特征的t-SNE图展示了该正则化的效果。
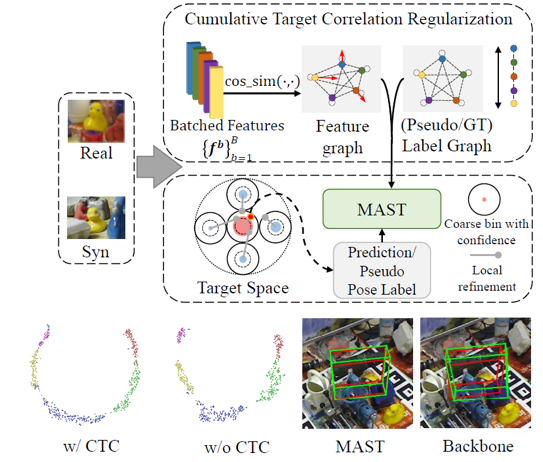
图2
三、实验:
表1、表2中,我们的方法在LineMOD(LM)、Occluded LineMOD(LMO)、HomebrewedDB数据集上超过其他现有方法。
表1 在LineMOD数据集上的对比,以ADD(-S)的平均召回率作为指标
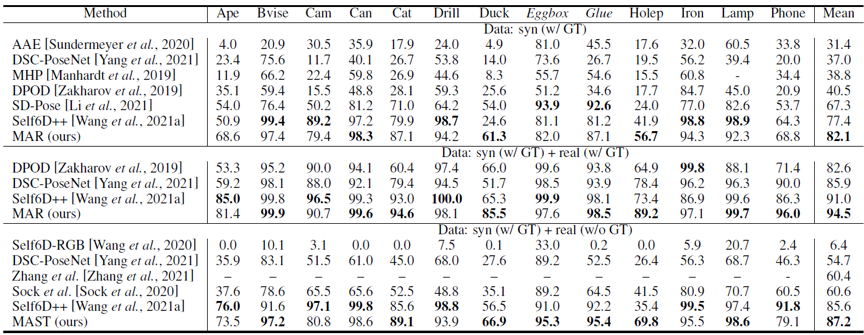
表2 在Occluded LineMOD和HomebrewedDB数据集上的对比,以ADD(-S)的平均召回率作为指标
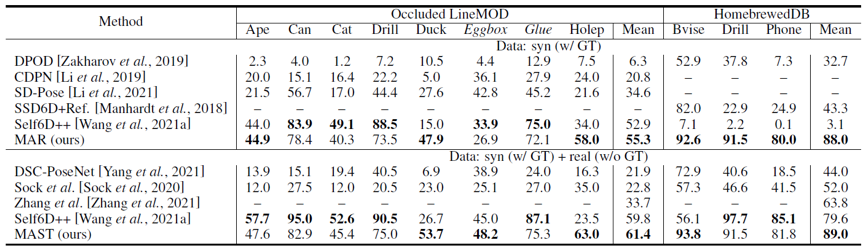
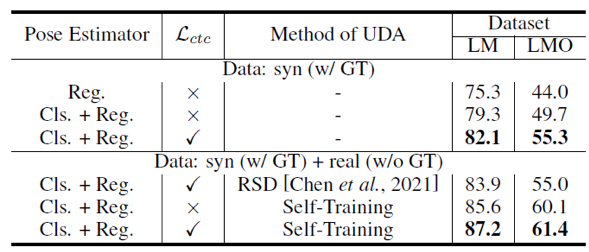
表3的消融实验证明了将回归任务拆分成分类任务和回归任务、累积目标相关度正则化对模型在跨域数据上性能的积极作用。
表3 消融实验对比,以ADD(-S)的平均召回率作为指标
06
3D Surface Super-resolution from Enhanced 2D Normal Images: A Multimodal-driven Variational AutoEncoder Approach
基于二维法线图增强的三维表面超分辩率:一种多模态驱动的变分自编码器方法
作者:谢伍媛1,黄腾聪1,王妙辉1,2,3,*
单位:
1 深圳大学,
2 射频异质异构集成全国重点实验室(深圳大学),
3 深圳市人工智能与机器人研究院
邮箱:
wuyuan.xie@gmail.com
tengconghuangcs@gmail.com
wang.miaohui@gmail.com
论文:
https://www.ijcai.org/proceedings/2023/175
*通讯作者
简介
随着计算机软硬件技术的飞速发展,对三维表面重建、感知和分析的需求在各种计算机应用中越来越大,而高质量的三维数据是满足这些应用的基本载体之一。然而,一方面,采集高分辨率(HR)三维内容的成本较高且效率较低;另一方面,现有的低分辨率(LR)三维物体还有很大的利用价值。考虑到这些因素,开发一种低成本的三维表面增强方法来补充对高质量三维数据的需求是有较大意义的。
然而直接对三维表面在点云域或网格域进行增强处理容易产生难以忽视的走样,相比之下基于二维法线图增强的三维表面超分辩率方法经研究可以得到更好的重建结果。但目前此类方法的研究还有限,且大多数方法没有充分考虑到三维表面自带的多模态信息,本文提出的方法就基于二维法线域提出了一个新的网络框架,并结合多模态信息提高了三维表面超分辩率的效果。
主要方法与贡献
如下图所示,本文设计了一个基于二维法线域的 VAE 神经网络框架。本文方法首先从三维表面法线信息中提取出角度信息,并从多角度光照图像中提取高频细节信息,结合原始的法线信息作为网络的多模态输入。然后设计了一个跨尺度多模态编解码结构作为网络主干进行三维表面超分辩率。在网络的中间部分,本文设计了一个用于融合不同模态表面信息的高斯混合模型mmGMM结构,这个结构通过将编码到隐空间的多模态的信息进行处理,使用高斯混合模型对其中的相关多模态信息进行模态对齐和融合操作,提高了算法的性能。从实验结果上看本文提出的方法能够在维持三维表面超分辩率中大尺度结构一致性,避免整体走样的同时,结合多模态辅助信息提高对表面细节的恢复效果。
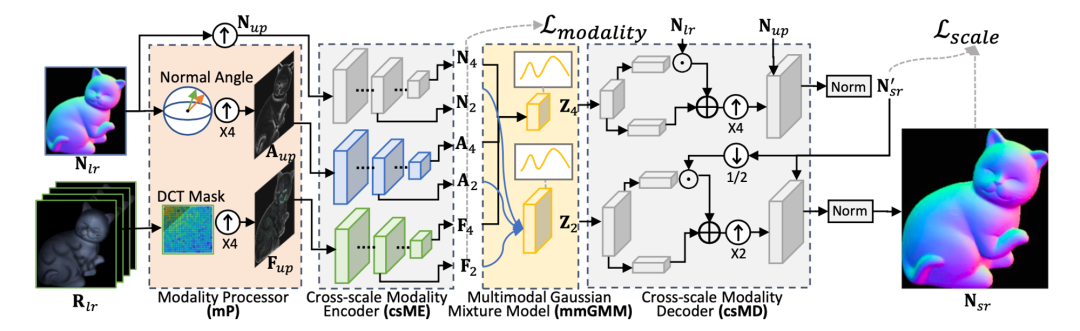
本文的主要贡献总结如下:(1)基于二维法线域的 VAE 框架,建立了一种新的多模态三维表面超分辨率框架;(2)研究了一种融合三维物体法线和纹理模态的高斯混合模型,这是一种利用辅助模态信息的更全面的多模态融合方法;(3)开发了一种新的跨尺度模态 VAE 网络结构,能够同时保留大表面结构和细粒度表面几何形状。
实验结果
本文将所设计的算法与其他先进算法进行了对比实验,其中视觉对比结果如下图所示。结果显示,本文使用的基于二维法线图的方法避免了基于点云的方法或基于网格的方法存在的严重走样,且将此方法应用在其他超分辩率领域的先进结构上对网络设计进行对比,可以看到本文提出的方法恢复了三维表面更多的细节,得到了更清晰锐利的微小结构,获得令人满意的三维表面超分辩率性能。


 京公网安备11010802017125号
京公网安备11010802017125号