
2023年论文导读第二十三期
【论文导读】2023年论文导读第二十三期
CCF多媒体专委会 2023-11-21 19:13 发表于山东


论文导读
2023年论文导读第二十三期(总第八十九期)
目 录
|
1 |
Image Defogging Based on Regional Gradient Constrained Prior |
|
2 |
Robust Image Ordinal Regression with Controllable Image Generation |
|
3 |
Robust Reinforcement Learning via Progressive Task Sequence |
|
4 |
MMPN: Multi-supervised Mask Protection Network for Pansharpening |
|
5 |
RaSa: Relation and Sensitivity Aware Representation Learning for Text-based Person Search |
|
5 |
CostFormer: Cost Transformer for Cost Aggregation in Multi-view Stereo |
01
Image Defogging Based on Regional Gradient Constrained Prior
基于区域梯度约束的图像去雾
作者:郭强1,张志2,周明亮3,岳宏4,浦华燕3,罗均3
单位:1北京航空航天大学,2中国民航大学,3重庆大学,4中信科公司
邮箱:
gq2016@buaa.edu.cn,
zhangz@cauc.edu.cn,
mingliangzhou@cqu.edu.cn,
yuehong3@126.com,
phygood_2001@shu.edu.cn,
luojun@cqu.edu.cn
论文:
https://dl.acm.org/doi/abs/10.1145/3617834
雾天对室外监控系统的功能产生了重大影响。雾霾天气下,由于空气中存在大量漂浮着的粒子,光线传播过程中与这些悬浮粒子相互作用,使得光线发生散射,最终到达成像设备的场景光信息受损。所以拍摄得到的图像存在对比度较低、清晰度低、细节丢失等问题,影响后续对图像的进一步处理应用。如何在雾天中保持景深相似、外观差异较大的图像区域之间的去雾均匀性仍然是一个挑战。传统的去雾方法往往忽视了景深信息和区域外观的差异,这会导致去雾效果不均匀,有些区域过度去雾,有些区域去雾不足。因此,设计出一种能够考虑景深和区域外观差异的去雾方法,以保持图像区域间的去雾均匀性,是当前研究的重要方向之一。
针对上述问题,如图1所示,本文提出了一种基于区域梯度约束先验去雾(regional gradient constrained prior,RGCP)方法以实现更准确、更自然的去雾效果,从而提高监控系统中雾天图像的去雾性能,该方法利用场景结构的分段平滑特性来实现准确估计和可靠约束。 RGCP首先推导得出,雾霾图像中相似像素聚集并在空间上容易形成区域,RGB空间中的区域像素簇符从卡方分布, 簇的置信边界的偏移量可以被视为每个区域的初始约束。 RGCP进一步利用梯度分布来区分不同的区域,并利用区域间约束函数来约束平坦区域中的估计,从而保持估计图和深度图之间的一致性。
本研究的主要贡献总结如下:(1)所提出的方法解决了雾图像去雾不准确和不均匀的问题, 基于梯度信息的区域像素边界的推导,有利于消除复杂环境的雾天图像的推理,提高先验的准确性。(2)所提出的基于RGCP的去雾方法与现有方法相比具有较高的效率。
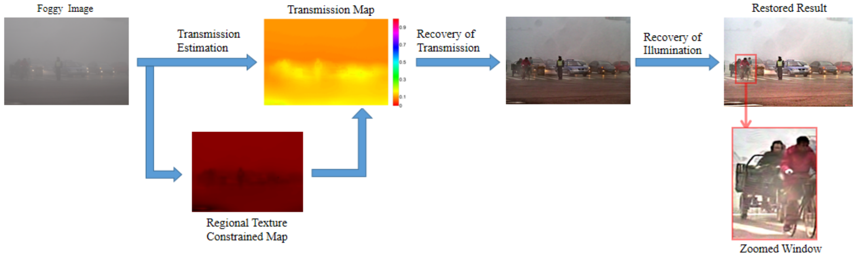
图1 提出的算法整体框架

图2 不同方法的数据集去雾效果对比
本工作将所设计的算法与其他先进算法进行了对比实验,如图2所示。结果显示,与先进方法相比,论文所提出的方法在透射率和照明度的恢复方面取得了更好的平衡。结果表明,该方法可以增强边缘的梯度并改善感知细节,从而无需大量训练图像和繁琐的计算即可实现各种气候条件下雾霾的祛除,进而获得令人满意的去雾性能。
02
Robust Image Ordinal Regression with Controllable Image Generation
基于可控图像生成的鲁棒叙述回归
作者:程奕1,应豪超1,胡仁君2,王锦鸿1,郑文浩1,张啸3,陈子仪4,吴健1
单位:1浙江大学,2阿里巴巴,3山东大学,4圣母大学 美国
邮箱:
chengy1@zju.edu.cn
论文:
https://arxiv.org/abs/2305.04213
我们要解决的问题是叙述回归任务,叙述回归任务是一种特殊的多分类任务,但是类别之间存在递进关系,比如年轻到老年的人脸图像,无症状到重症状的医学图像等。由于交叉熵损失函数无法优化正确标签以外的概率(假如标签是1,那么在叙述回归中判别为2和判别为3应该是不同的损失),之前的方法主要聚焦于构造模型和损失函数,用于增加类别之间的联系。
但是我们发现在叙述回归的数据集中,存在另一个非常普遍的现象:类别不平衡。在我们的论文中统计了使用的三个常见的公开数据集,发现他们某些类的占比相比于其他类别非常大。因此如何保证在这种情况下提升小类别的准确率就成了一个需要关心的问题。

同时,在这种情况下,我们还发现一个问题,那就是类别的交叠,正常而言特征的分类边界应该是下图的背景色,但是由于类别1和类别3的数据包含了类别2的特征(该现象在叙述回归中特别严重,比如无皱纹的老年人就是一种老年类别对中年类别的交叠),由数据得到的决策边界就会被挤压导致整体准确率下降。
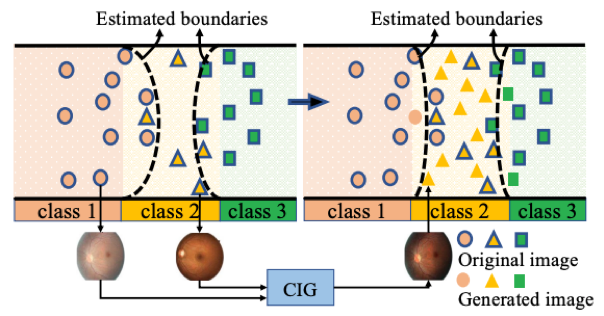
为了解决以上两个问题,我们提出了一个可控图像生成的训练框架(CIG)。这个框架主要包含三个部分,Encoder(E),特征分离重组(S-F)和生成器(Generator)。其中Encoder可以为任意特征提取网络,我们采用了Vgg16个PVT这两个有代表性的CNN和Vision Transformer模型,同时对应的Generator就是UNet和Transformer Encoder。首先我们通过dataloader得到一个主图像(main),然后在其周边类别中采样一张参考图像(Reference),对这两张图像进行特征提取得到Fm和Fr这两个特征。然后对主图像提取其结构特征(比如脸型,眼球结构等),对参考图像提取类别特征(比如皱纹,血管损伤等),并进行混合,最后将混合的图像通过Generator进行生成。
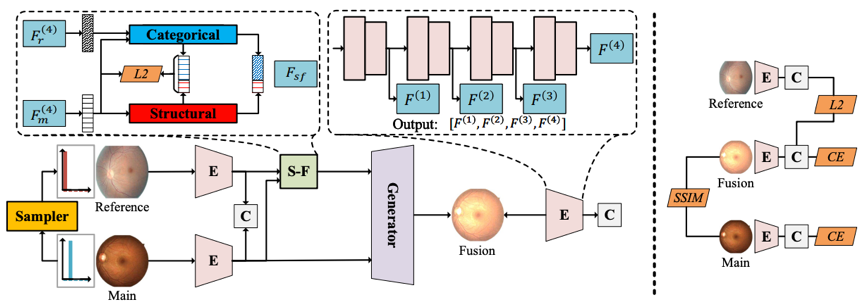
在这个过程中,我们通过对生成图像和主图像计算SSIM来保证结构相似,通过计算参考图和生成图的logit来保证类别相似。同时类别-结构分离我们仅使用了简单的网络层,这就需要Encoder能提供较好的类别-特征分离能力。
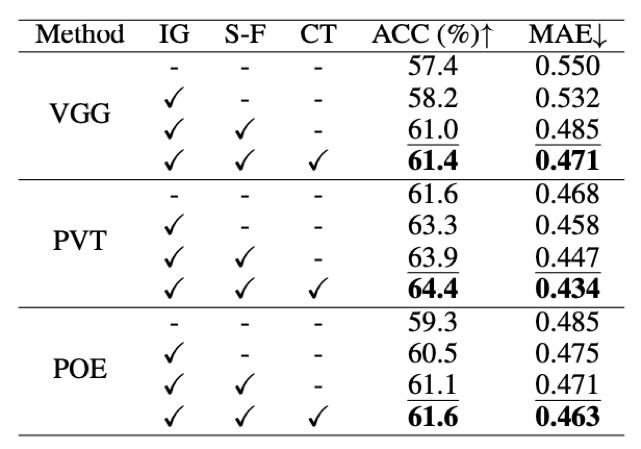
我们的实验结果表明,在不改变Encoder的情况下,我们的模型相比于baseline有非常大的提升,同时在小类别的提升上更加显著。消融实验表明,在整体框架训练完成后,单独对Encoder额外训练一段时间效果还能提升,这是因为之前encoder需要提取结构相关特征,在额外训练时就可以将这部分冗余特征剔除仅保留类别特征。

03
Robust Reinforcement Learning via Progressive Task Sequence
作者:李轶珂*、田蕴哲*、童恩栋#、牛温佳#、刘吉强
单位:北京交通大学
邮箱:
yikeli@bjtu.edu.cn
论文:
https://doi.org/10.24963/ijcai.2023/51
*共同一作,#共同通讯
1. 研究背景和动机
由于仿真与现实之间的差距,鲁棒强化学习(RL)一直是一个具有挑战性的问题。现有的研究通常通过求解“最大-最小”问题(max-min problem)来解决鲁棒强化学习问题,其主要思想是在最坏的扰动条件下最大化累积奖励(worst-case optimization)。然而,这种最坏情况下的优化往往导致保守的最终策略或是破坏训练过程的稳定性,影响策略的鲁棒性和泛化性能。
2. 方法概述
为了解决上述问题,本文从问题建模和算法定义两方面解决鲁棒强化学习问题。一方面,本文将鲁棒强化学习建模为一个“最大-期望”问题(max-expectation problem),其目标是同时在最坏扰动(worst cases)和非最坏扰动(non-worst cases)下优化当前策略。另一方面,本文提出一个名为动态鲁棒强化学习(Dynamic Robust RL, DRRL)的算法框架来解决上述提出的“最大-期望”优化问题,通过构建一个渐进式任务序列实现动态的多任务学习,从而提高了策略的鲁棒性和训练的稳定性。
1) 问题建模

图1 (a)传统“最大-最小”鲁棒强化学习范式, (b)“最大-期望”鲁棒强化学习范式
在“最大-最小”鲁棒强化学习范式下,策略优化的目标表示为:

在“最大-期望”鲁棒强化学习范式下,策略优化的目标表示为:
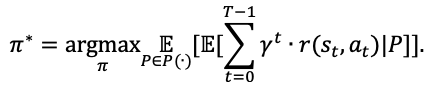
其中,P(·)表示一组可能的状态转移分布,∀P∊P(·)表示某个扰动下的状态转移分布。
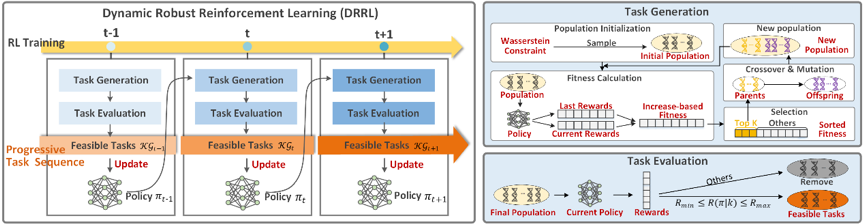
图2 算法框架流程图
DRRL框架的核心是一个任务生成和排序机制,其目标是动态输出对当前策略难度适中的任务集合,称为可行任务(feasible tasks)。纵观整个训练过程,各阶段生成的可行任务集合组成了一个难度递增的渐进式任务序列,实际用于策略优化。包含几个主要步骤:
步骤1. 任务生成:使用基于算法来生成任务,种群中每个个体代表一个任务。采用基于奖励增速的适应度函数,选出“最有继续训练潜力”的任务。计算公式为:

步骤2. 任务评估:对步骤1生成的任务进行二次筛选,同时具有交大奖励增速和适中奖励值( Rmin≤R(��|k)≤Rmax)的任务将被筛选出,称为可行任务,实际用于策略优化。
步骤3. 任务排序:随训练过程进行,期望奖励的上下限Rmin和Rmax是根据当前平均奖励R(��m)来动态更新的。
3. 实验分析
本文分别在无扰动力、对手智能体扰动力、人工设定扰动参数下验证了所得策略的鲁棒性,如表1所示。图3可视化了在测试环境(人工设定扰动参数)下的策略鲁棒性效果。结果显示,DRRL(1)不损失策略在正常无干扰下的性能,(2)提升了在扰动环境中的鲁棒性。
表1 策略在无扰动、对手扰动、测试扰动下的性能对比


图3 在不同扰动参数组合下的策略平均奖励值热力图。横轴为"mass”,纵轴为"friction”
04
MMPN: Multi-supervised Mask Protection Network for Pansharpening
作者:陈常杰1,杨勇2*,黄淑英2,涂伟3,万伟国2,魏盛娜2
单位:1江西财经大学,2天津工业大学,3江西科技师范大学
邮箱:
chencjpro@163.com
greatyangy@126.com
shuyinghuang2010@126.com
ncsytuwei@163.com
wanwgplus@163.com
shengnaw@163.com
论文:
https://www.ijcai.org/proceedings/2023/
代码:
https://github.com/ sharpeningNN/MMPN
*通讯作者
1. 引言:
全色锐化(Pansharpening)是将全色(PAN)图像与多光谱(MS)图像融合创建出高空间分辨率的多光谱(HRMS)图像的过程。目前,基于深度学习的Pansharpening方法常常导致融合结果中存在边缘模糊和光谱失真等问题。为了解决这些问题,本文提出了一种基于多监督掩码保护网络(MMPN)的Pansharpening方法。
2. 方法:
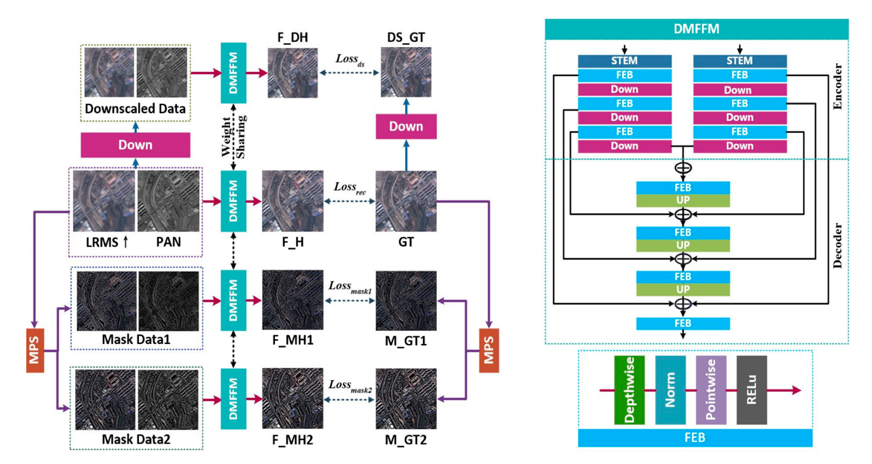
图1 提出的MMPN框架示意图.
本文从保留空间信息并降低光谱失真的思想出发,提出MMPN并设计了一种掩模保护策略(MPS),如图1所示。基于MPS,MMPN包含四个分支,每个分支都配备了一个双流多尺度特征融合模块(DMFFM)。DMFFM从PAN和MS图像中分别提取和融合特征。首先,通过提出的MPS对输入源图像和参考图像(GT)进行分解,分别获得掩模数据和监督图像(M_GT1和M_GT2);然后,构建了四个共享权重的DMFFM(深度多通道特征融合模块)网络分支,分别对源图像、两个掩模数据及源图像的低分辨率版本进行融合;最后,定义了包含四个损失项的联合损失函数来训练网络。
3.实验:
本文在模拟和真实的卫星数据集上进行了主观和客观实验,包括IKONOS(4波段)、Pléiades(4波段)和WorldView-3(8波段),并与一些最先进的Pansharpening方法进行对比。IKONOS模拟数据集的实验结果如图2所示,三个卫星数据集的平均定量评估结果如表1所示。从图2和表1可知,本文提出的方法在主观与客观指标上都达到了最优。
此外,在真实数据集Pléiades进行了融合实验,为了更清晰地观察不同融合结果之间的光谱和细节信息的差异,选择了两个小区域进行放大,结果如图3所示。实验结果可以看出,我们的结果比其他比较方法的结果具有更丰富的光谱信息和空间细节。真实数据集Pléiades和WorldView-3的平均定量评估结果如表2所示。综合图3和表2,所提出的MMPN在真实数据集上都取得了很好的效果。

图2 IKONOS模拟数据集上的融合结果。
表1 Pléiades、IKONOS和WorldView-3模拟数据集的平均定量结果。
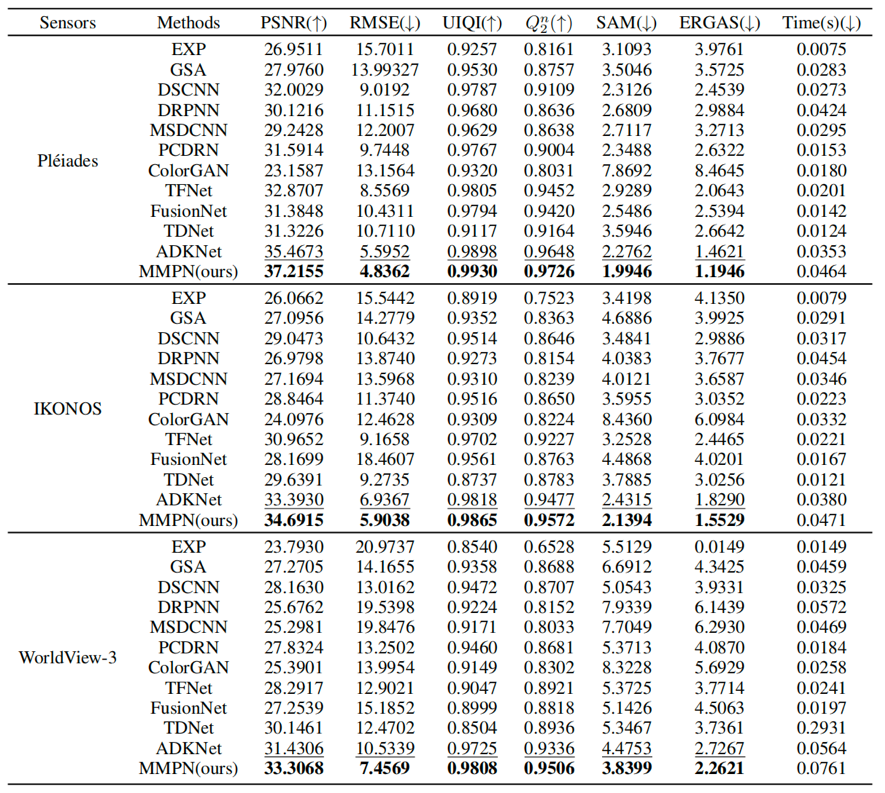

图3 Pléiades真实数据集的融合结果。
表2 Pléiades和WorldView-3真实数据集的平均定量结果。

05
RaSa: Relation and Sensitivity Aware Representation Learning for Text-based Person Search
作者:白杨1,曹敏1*,高大明1,曹自强1,陈晨2,范振峰3,聂礼强4,张民1,4
单位:
1苏州大学
2中国科学院自动化研究所
3中国科学院计算技术研究所
4哈尔滨工业大学(深圳)
邮箱:
ybaibyougert@stu.suda.edu.cn,
mcao@suda.edu.cn
论文:
https://www.ijcai.org/proceedings/2023/0062.pdf
代码:
https://github.com/Flame-Chasers/RaSa
1. 简介
基于文本的行人搜索旨在通过给定的文本描述来检索出符合该描述的行人图像,解决这一任务的关键在于学习强大的多模态特征表示。为此,我们提出了一种关系感知和敏感性感知的表示学习方法(RaSa),其中包括两个学习任务:关系感知学习和敏感性感知学习。
(1) 关系感知学习:现有的方法往往对正关系不加区分,无差别地拉近具有正关系的图像和文本特征,然而它们忽视了图像和标注文本之间可能存在的噪声对应(如图1(a)中红色标记部分),从而导致过拟合学习。关系感知学习引入了一项正关系判别任务,通过学习判别强正关系和弱正关系的方式额外引入正则项,从而降低过拟合风险。
(2) 敏感性感知学习:学习对数据增强不变的特征表示是现有方法中提高特征鲁棒性的一种常见做法。在此之上,我们提出了敏感性感知学习,鼓励模型主动检测被替换的词(如图1(b)所示),也即对词替换这种数据增强具有敏感性,从而加强学习到的特征表示。

图1 (a) 强正关系与弱正关系图示;(b) 基于词替换的敏感性感知学习
2. 方法
我们提出的关系感知学习和敏感性感知学习可以适配到多个现有的网络架构中。本文默认采用视觉-语言预训练模型ALBEF为主干网络。

图2 RaSa网络架构图
图2展示了本文方法的网络架构图。给定一对图像和文本,它们分别由视觉编码器和文本编码器独立编码得到视觉特征和文本特征,之后二者送入到跨模态编码器进行交互融合,并最终生成多模态特征。
(1)为使得特征融合更顺利,在进行融合之前,首先使用对比学习约束单模态特征并得到对比损失Lcl。
(2)关系感知学习:对于多模态特征,我们使用一个二分类器判定图像与文本关系,其中需要判定的关系包括:
正关系与负关系判定:Lp-itm=Ep(I,T)H(yitm,��itm(I,T)),其中H表示交叉熵函数
强正关系与弱正关系判定:Lprd=Ep(I,Tp)H(yprd,��prd(I,Tp))
关系感知损失函数:Lra=Lp-itm+��1Lprd
(3)敏感性感知学习:为了增大替换词检测的任务难度,我们使用掩码语言建模(MLM)生成更加迷惑的词进行替换,然后再让模型进行词替换检测。这个过程可以抽象为:
替换词生成:Lmlm=Ep(I,Tmsk)H(ymlm,��mlm(I,Tmsk))
替换词检测:Lm-rtd = Ep(I,Trep)H(ym-rtd,��m-rtd(I,Trep))
敏感性感知损失函数:Lsa=Lmlm+��2Lm-rtd
(4)综上所述,训练时的总体优化目标:L=Lra+Lsa+��3Lct
3. 实验
我们在基于文本的行人搜索的3个公开数据集上进行了测试,并在2个图像-文本检索和2个细粒度检索数据集上进行了泛化实验,最终实验结果表明我们的方法具有明显的优势。更详细的实验内容请参见论文。
表1 在CUHK-PEDES数据集上与当前先进方法的结果对比

06
CostFormer: Cost Transformer for Cost Aggregation in Multi-view Stereo
作者:陈伟涛, 许鸿斌, 周志鹏, 刘洋, 孙佰贵, 康文雄, 谢宣松
单位:
阿里巴巴达摩院 , 华南理工大学
邮箱:
hillskyxm@gmail.com,
hongbinxu1013@gmail.com
论文:
https://arxiv.org/abs/2305.10320
三维重建是计算机视觉的基础课题,多视角立体是其中的一种重要实现方式,该方式会从一系列同一场景但不同视角的二维影像中重建该场景的三维信息,目前已广泛应用于自动导航,自动驾驶,增强现实等领域;近几年,深度学习已经广泛应用于基于学习的多视角立体,比如开山之作MVSNET及其后续的改进CasMVSNet; 其核心是源像素和参考像素的匹配,而代价体聚合又是其中的关键步骤;相比于卷积神经网络,Transformer是一种基于自注意力机制的深度结构,其全局的注意力机制可以克服卷积神经网络有限的局部感受野问题,因此近两年已有方法把Transformer应用到多视角立体上,比如TransMVS把Transformer用于提取图像特征的特征金字塔网络,但在只采用卷积的代价体聚合上,仍然会由于卷积的缺陷而产生错误的匹配,因此如何把Transformer用于代价体聚合成为一个新的改进方向,相比于图像特征,代价体多了一个深度的维度,在设计自注意力机制的时候不仅需要像图像特征那样考虑空间维度,同时也要做到深度感知,但同时由于自注意力机制指数级别增长的复杂度,且代价体各个维度的值都比较高,直接把全局自注意力机制应用于高维度的代价体,很容易引起显存的耗尽以及推理时间的大幅增长。
在此背景下,我们提出一种基于代价体Transformer的多视角立体三维重建方法,该方法设计了一种高效的Transformer,即CostFormer,改善了卷积神经网络代价体聚合的缺陷,从而进一步改善整体重建的效果;CostFormer做到深度感知的同时也克服了全局自注意力机制指数级别增长复杂度带来的显存的耗尽以及推理时间的大幅增长。CostFormer是一种可即插即用于当前基于卷积神经网络的多视角立体方法。
方法:
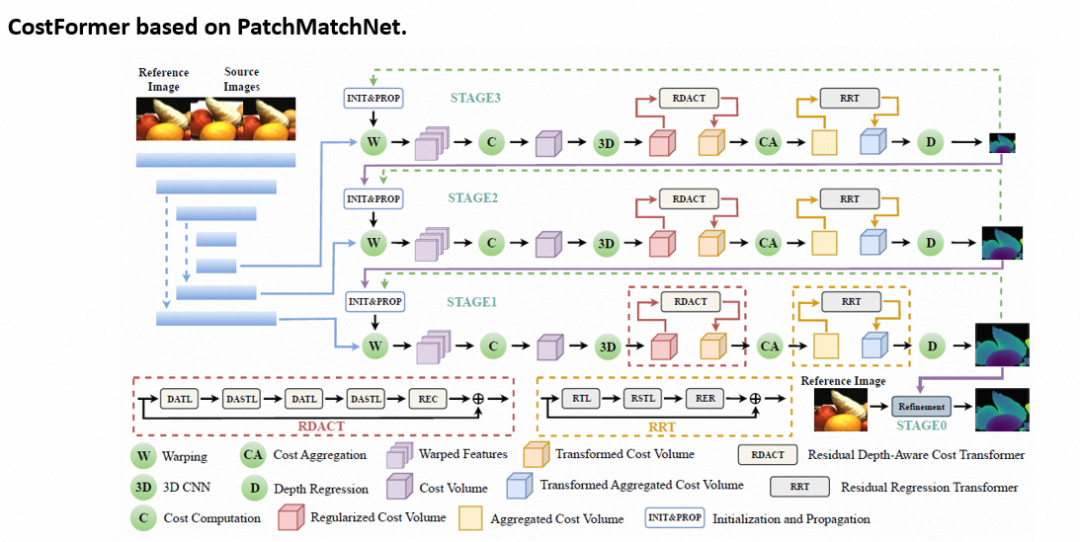
其中RDACT整体结构图如下图,由基于窗口的深度感知Transformer层和深度感知的移位Transformer层以及重嵌入代价层堆叠而成。





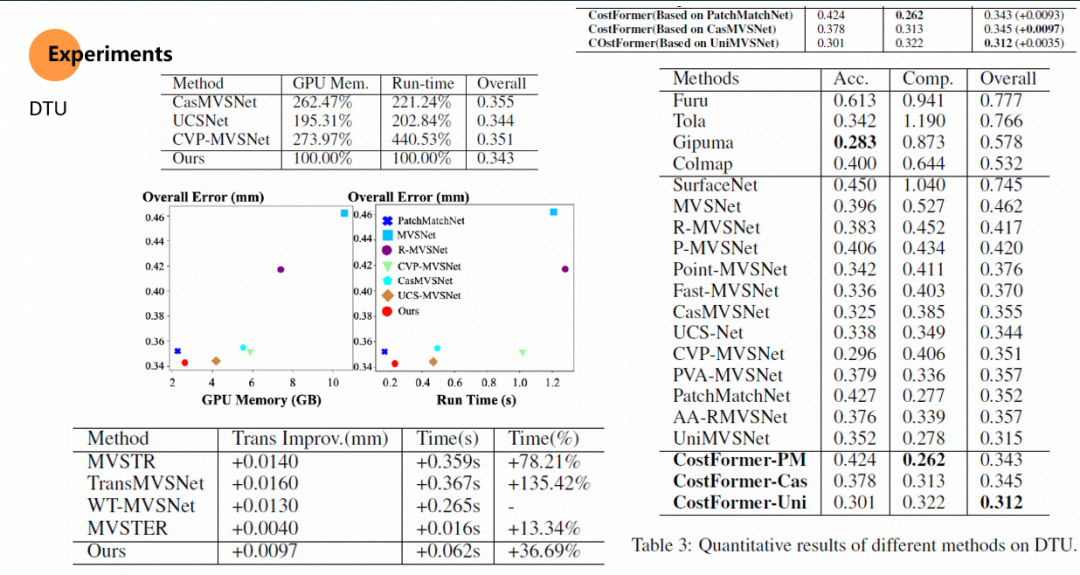
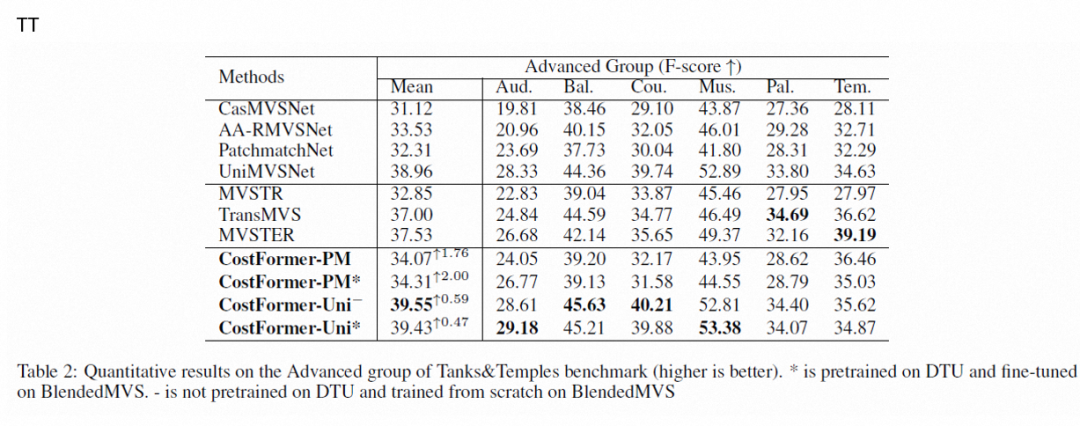
实验结果:





 京公网安备11010802017125号
京公网安备11010802017125号