
2024年论文导读第一期
【论文导读】2024年论文导读第一期
CCF多媒体专委会 2024-01-02 08:00 发表于山东


论文导读
2024年论文导读第一期(总第九十二期)
目 录
|
1 |
RuleMatch: Matching Abstract Rules for Semi-supervised Learning of Human Standard Intelligence Tests |
|
2 |
Dual-view Correlation Hybrid Attention Network for Robust Holistic Mammogram Classification |
|
3 |
Few-shot Classifcation via Ensemble Learning with Multi-Order Statistics |
|
4 |
Temporal Constrained Feasible Subspace Learning for Human Pose Forecasting |
|
5 |
Accurate MRI Reconstruction via Multi-Domain Recurrent Networks |
|
6 |
Video Diffusion Models with Local-Global Context Guidance |
01
RuleMatch: Matching Abstract Rules for Semi-supervised Learning of Human Standard Intelligence Tests
RuleMatch:半监督学习中的抽象规则匹配及其在人类标准智力测试中的应用
作者:徐云龙1,杨凌霄2,游宏志3,甄宗雷4,王大辉4,万小红4,谢晓华2,张洳源1
单位:1上海交通大学,2中山大学,3电子科技大学,4北京师范大学
邮箱:
yxu103@u.rochester.edu,
yanglx9@mail.sysu.edu.cn,
hongzhi-you@uestc.edu.cn,
zhenzonglei@bnu.edu.cn,
wangdh@bnu.edu.cn,
xhwan@bnu.edu.cn,
xiexiaoh6@mail.sysu.edu.cn,
ruyuanzhang@sjtu.edu.cn
论文:
https://www.ijcai.org/proceedings/2023/0179.pdf
人工智能领域一直面临的挑战之一是模拟人类的抽象视觉推理能力。本研究介绍的“RuleMatch”方法,正是针对这一领域的一项新尝试。该方法特别适用于解决Raven’s Progressive Matrices (RPM)问题,这是评估人类抽象视觉推理能力的标准测试。
图1 RPM问题的挑战
图1展示了两个RPM问题的例子。每个问题包含八个上下文图像,目标是从八个答案图像中选出正确的一个,填补问题矩阵中的空缺部分,使得三行或三列形成相似的抽象规则。这类问题的复杂性在于其需要理解和应用不同的抽象规则。

图2 RuleMatch方法
RuleMatch方法通过对未标注数据应用基于规则的增强,提高模型的训练效果。如图2所示,该方法使用三种不同视角的规则增强,并利用网络从其中两个视角估计伪标签。我们对规则进行增强的方式是文章的核心创新点,我们的三种增强方法为:MaskObj:从8个图片中任选一张,遮挡住其大小为4分之1的方块;MaskPanel,从8个图片中任选一张,对其完全遮挡;MaskRow, 任选一行,完全遮挡。这里,对于规则的扰动程度是依次变强的,也就从各种角度上去迫使神经网络学习规则。我们对于未标注样本的样本随机用两种增强方法进行两次视角强化,如果这两个视角的估计标签一致,这个未标注样本及其伪标签就会被用于网络训练。
实验结果的重要性
在RAVEN数据集上的实验结果显示,RuleMatch在两个主要的RPM数据集上均达到了最佳性能。这不仅显示了RuleMatch在抽象视觉推理任务上的有效性,也表明了它在理解和处理复杂视觉信息方面的重要进步。
结论
RuleMatch方法的成功表明,通过在更高层次上的创新,我们可以有效地提升机器学习领域中的数据效率和规则泛化能力。这项工作不仅为机器学习提供了新的视角,也为未来人工智能的发展开辟了新的道路。
02
Dual-view Correlation Hybrid Attention Network for Robust Holistic Mammogram Classification
作者:王植炜1,冼俊林2,刘康义2,李欣1,李强1,杨欣2
单位:
1华中科技大学-武汉光电国家研究中心,
2华中科技大学-电子信息与通信学院
邮箱:
zwwang@hust.edu.cn,
xianjunlin@hust.edu.cn,
m20202099@hust.edu.cn,
m202372818@hust.edu.cn,
liqiang8@hust.edu.cn,
xinyang2014@hust.edu.cn
论文:
https://arxiv.org/abs/2306.10676
1.背景
乳腺钼靶图像对乳腺癌筛查至关重要,临床中通常依赖颅尾位(CC)和内侧斜位(MLO)两个视角的图像信息进行诊断。然而,现有的乳腺钼靶影像分析方法大多是独立地学习两种视角的特征,或者局限于独立地提取不同视角图像的特征,再进行简单的空间聚合,这种方式往往难以充分利用到双视角信息,最终无法取得最优的诊断性能。因此,我们提出了基于双视角特征关联最大化与混合注意力机制的乳腺癌分类网络(DCHA-Net),在不利用病灶掩膜标注信息的情况下,去显式地挖掘并最大化双视角图像的特征相关性,从而获得鲁棒的整体乳腺诊断性能。
2.方法
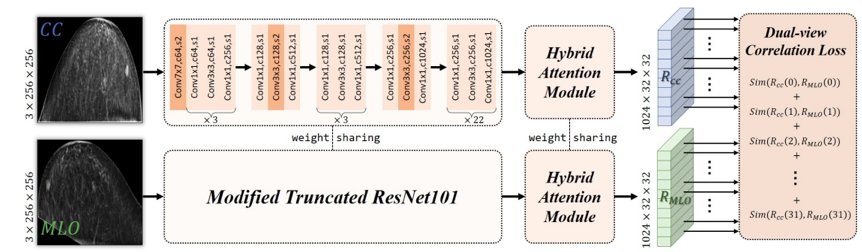
图1 提出的DCHA-Net整体网络框图
如图1所示,DCHA-Net使用两个共享权重的ResNet-101分支,分别提取CC和MLO视角图像的特征,再输入到混合注意力机制模块,并被重塑为新的特征图R,最后进行双视角特征关联最大化约束,即计算每一组相互匹配的行向量特征之间的相关性系数的平均值。

图2 理想情况下3D乳腺与2D双视角图像之间的转换关系示意图
如图2所示,来自不同视角的两段条状区域,如果它们与乳腺胸壁的距离相同,它们往往对应同一乳腺组织区域,两部分特征是相互匹配、高度相关的。如图3所示,混合注意力机制模块由一个局部注意力机制模块(Local Attention Block)和一个全局注意力机制模块(Non-local Attention Block)组成。两个分支的特征图在被该混合注意力机制模块重塑后,新的特征图R中的各个像素位置都会包含来自其周围像素的信息(局部相关性),以及其所属平行于胸壁的条状区域内其他像素的信息(全局相关性)。通过该方式,DCHA-Net中的特征得以不断优化,两个分支能相互辅助,从而提高网络最终的整体乳腺诊断精确度。
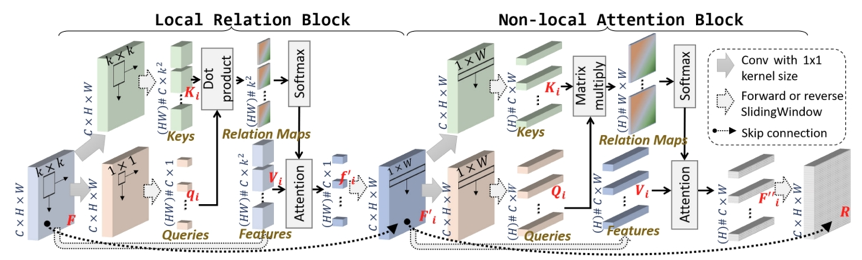
图3 局部注意力机制模块和全局注意力机制模块的详细架构
3.实验
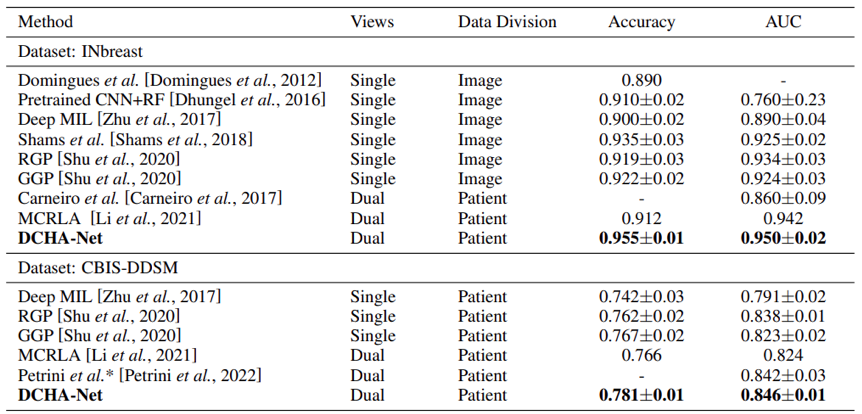
本文在INbreast和CBIS-DDSM两个乳腺公开数据集上进行了实验验证,通过Accuracy和AUC两个定量指标来评估所提出的DCHA-Net的有效性,并与目前先进方法的结果进行比较,具体结果如表1所示。本文提出的DCHA-Net在真正挖掘并利用了乳腺双视角信息后,可以显著提高整体乳腺诊断性能,达到了现有方法的最优精度。
表1 与目前先进方法的定量对比结果(平均值±标准差)
03
Few-shot Classifcation via Ensemble Learning with Multi-Order Statistics
基于多阶统计量集成的小样本图像分类算法
作者:杨赛1,刘凡2,*,陈德龙2,周峻3
单位:
1南通大学电气工程学院,
2河海大学计算机与信息学院,
3格里菲斯大学信息与通信技术学院
邮箱:
fanliu@hhu.edu.cn
论文:
https://www.ijcai.org/proceedings/2023/0181.pdf
*通讯作者
1. 研究背景和动机
小样本图像分类旨在仅使用少量已标记的训练样本对新类别进行分类,在减少标记成本、缩小人类智能与机器模型之间性能差距方面具有重要研究价值。由于该任务所使用的监督信息有限,通常需要借助于基类样本作为额外的辅助数据集学习得到先验知识。不同于元学习,迁移学习弃用复杂的片段式训练方式逐渐成为该任务中流行的学习范式。在迁移学习框架下,如何获取优良的泛化特征表示是提高小样本图像分类性能的关键因素。最近的工作表明集成学习在小样本图像分类任务中表现优异。然而,这些工作都处于初步研究阶段,仍然缺乏理论分析来解释取得良好性能的根本原因。并且这些工作中所设计的模型具有较大的参数容量和时间开销。为了解决上述问题,本文在迁移学习框架下提出小样本集成学习定理,其核心内容是关于新类错误率的紧致泛化误差边界,即在给定基类与新类域差的情况下,通过在基类上进行集成学习,新类的泛化误差将会相应地被降低。同时,本文理论上证明卷积张量特征的不同阶的统计量之间是互补的,将它们融合才能完整地描述张量特征所服从的概率密度分布。在上述理论的指导下,本文提出基于多阶统计量集成的小样本图像分类算法。
2. 方法概述
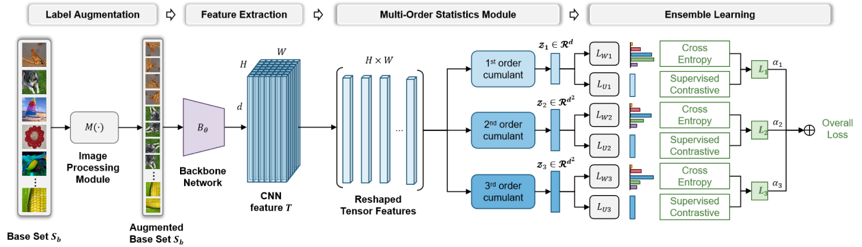
图1 本文方法框架图
定理1(小样本集成学习)假设H为学习空间,对于任何基于基类数据Sb所优化的学习器h∊{ho}Ho=1∊H以及$\overline{h}=\sum_{o=1}^{O} ho∊H$,学习器h和\overline{h}在新类数据Sn上的泛化误差满足以下关系:
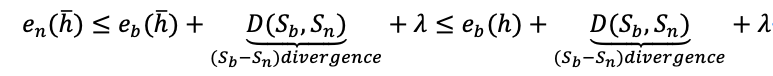
其中, ��=Ex∊Sb|fn(x)-fb(x)|为一常量,en(\overline{h})为学习器\overline{h}在Sn上的期望误差,eb(h)为学习器 h在Sn上的期望误差。
命题1 假定卷积张量特征的随机变量被表示为t,其服从均值��为和方差为��的高斯分布f(t),该变量的第二特征函数为:
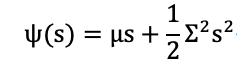
根据第二特征函数的定义可知,随机变量t 的各阶矩表示为:
![]()
Remark:由定理1可知,在给定基类与新类域差的情况下,通过在基类上进行集成学习,新类的泛化误差将会相应地被降低。该定理可以有效地解释集成学习在小样本图像分类任务中发挥作用的原因,即多个学习器被组合在一起,以增强基类上的泛化性能,从而在新类中获得更好的泛化性能。 由命题1 可知,当卷积张量特征服从高斯分布时,二阶以上的矩统计量为0。然而,卷积张量特征服从高斯分布的假设太强,现实情况中通常不满足该条件。在这种情况下,高阶统计量同样包含很多有用的信息。
基于定理1和命题1,本文提出基于多阶统计量集成的小样本图像分类算法,该方法的总体框图如图1所示。该方法首先将基类的图像进行图像增强,然后输入到主干网络中进行特征提取,输出的卷积特征被转换为矩阵,用于不同分支中不同阶统计量的计算。当使用三个分支时, 1st-order, 2nd-order 和 3rd-order统计量的具体公式如下:
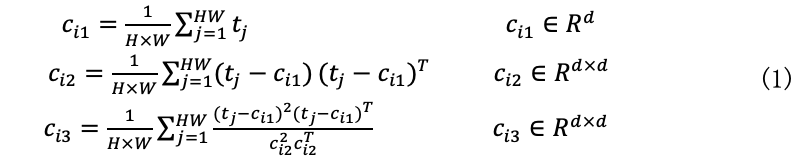
式(1)中,t表示卷积张量特征。对于每个学习个体同时建立分类损失和相似性损失,具体表达如下:
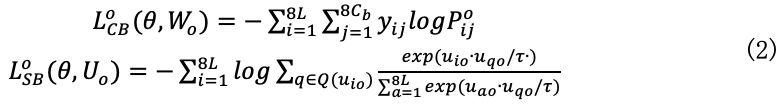
式(2)中, yij表示标签值,Poij表示第o个体的概率输出值,Q(��io)表示正例样本集合,是由与��io具有相同标签值的样本组成,��qo表示Q(��io)中的第q个样本。则第o个学习个体的目标函数为:

则集成学习的总体损失函数为:
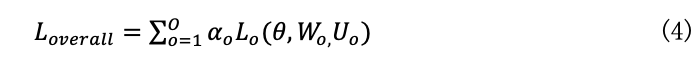
式(4)中��o为权重系数。预训练阶段采用梯度下降法对(4)中的损失函数进行优化。预训练完成后,使用主干网络以及各个分支对新类数据集中的支持样本与查询样本提取特征,并使用逻辑回归分类器完成对新类样本的分类决策。
3.实验分析
表1 在miniImageNet, tieredImageNe,CIFAR-FS数据集上与state-of-the-art 方法的正确率比较结果(%)
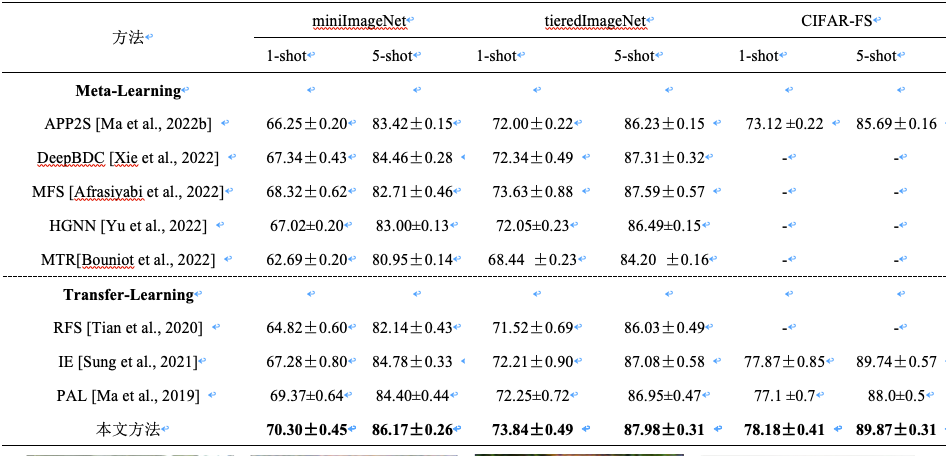

图2 基于1st-order, 2nd-order 和 3rd-order统计特征的重构图像
本文在多个小样本图像分类数据集上对算法的性能进行了详尽的实验。表1为在miniImageNet, tieredImageNe,CIFAR-FS数据集上与state-of-the-art 方法的比较结果。由表1中的结果可知,与小样本图像分类领域内的若干个state-of-the-art 方法相比较,本文方法能够取得更优良的分类性能。为了分析本文方法的优异性能,使用 Deep Image Prior 方法分别对卷积特征的1st-order, 2nd-order 和 3rd-order统计特征进行图像重构,重构后的图像如图2所示。由图2中的结果可知,随着统计特征的阶数变高,重建的图像变得更加平滑。上述现象表明,2nd-order和3rd-order统计特征比1st-order统计特征对噪声点等奇异性变化更具鲁棒性, 而1st-order特征比2nd-order和3rd-order统计特征具有更强的捕捉图像细节的能力。上述分析表明,1st-order、2nd-order 和3rd-order统计特征具有互补性,本文方法能够将多阶统计特征集成,从而取得更优良的性能。
04
Temporal Constrained Feasible Subspace Learning for Human Pose Forecasting
作者:王高昂1,宋明黎1
单位:1浙江大学
邮箱:
gaoangwang@intl.zju.edu.cn
论文:
https://doi.org/10.24963/ijcai.2023/161
人体姿态预测是一项序列建模任务,旨在从历史运动中预测未来的人体姿态。这项任务在许多应用中引起了越来越多的关注,例如自动驾驶、医疗保健、远程操作和协作机器人等。大多数现有方法专注于时空神经网络模型设计,以学习运动模式以减小预测误差。尽管这些数据驱动的深度学习模型可以逼近非常复杂的函数,并在大规模数据集上取得出色的性能,但它们较传统简单的机器学习模型缺乏可解释性。当测试数据偏离训练数据分布时,可能会出现意外输出。即使达到了较小的平均关节位置误差(MPJPE),其中一些预测的姿态也不是时序上可行的解决方案。常用方法的缺点如图1所示。尽管常用方法在训练阶段中使用了时间约束,但由于在推断阶段没有使用这些约束,预测模型仍可能生成不可行的姿态。例如,由于人类无法做出突然的动作,因此人体关节速度变化的上限应受到约束。这样的约束不仅应在训练阶段满足,而且在推断阶段对于未见过的测试数据也应该满足。然而,关于确保姿态预测任务的时序约束可行解的方案在文献中很少被讨论。
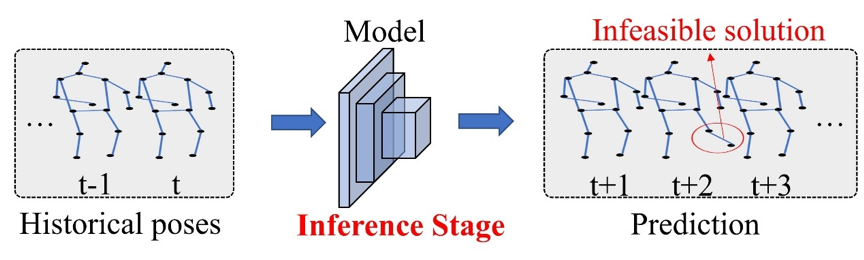
图1 常见方法往往在推理阶段会得到物理不可行的姿态
物理约束可以缓解数据驱动深度学习模型的这些问题。通过将来自物理世界的法则和人类的一般知识引入,带有物理约束的预测和决策比纯粹基于数据的模型更可靠。一些现有方法考虑在深度学习模型中引入物理约束,通常通过采用来自受限优化的思想,使用正则化的训练算法和损失函数,或者通过迭代投影校正模型输出。然而,大多数现有方法使用的是近似而不是寻找严格遵守约束的可行解决方案。此外,在推断阶段可能需要迭代适应,这会带来额外的计算成本。此外,与无约束模型相比,受约束的模型通常会找到次优解,导致性能下降。
在本文中,我们处理考虑了满足时序约束可行解的人体姿态预测问题,其中人体关节速度的变化应遵循物理运动的连续性属性。为了解决这个问题,我们提出了一个用于人体姿态预测的时态约束可行子空间学习框架。具体而言,我们不是直接监督原始姿态空间中的预测,而是通过利用简单的投影函数(如ReLU和ELU)显式地学习时序约束子空间。然后可以应用反向变换来获得最终的人体姿态预测。由于在训练和推断阶段都保证了约束条件,因此在推断中不需要额外的迭代投影或优化步骤。此外,与大多数现有方法通常为了满足物理约束而牺牲准确性不同,我们提出的方法可以通过约束的可行解进一步减小预测误差。我们的算法流程如图2所示。

图2 方法流程图
本文主要贡献总结如下:(1)我们在人体姿态预测任务中引入了时序约束,并为训练和推断阶段提供了可行解。与大多数现有工作不同,我们提出的方法的时序可行解在推断中无需通过任何迭代、适应、优化或近似的情况获得。(2)我们提出了一种新颖的时序约束子空间学习框架。与在原始姿态空间中直接监督预测不同,我们显式学习了一个时序约束的子空间,然后进行逆变换以获得最终的预测。(3)基于STS-GCN作为编码器骨干网络,我们在人体姿态预测任务Human3.6M、AMASS等数据集上取得了的领先性能,同时满足了时序的可行约束。
05
Accurate MRI Reconstruction via Multi-Domain Recurrent Networks
作者:魏金宝,王志杰,汪孔桥,郭立,傅雪阳,刘际,陈勋
单位:中国科学技术大学,华米科技
邮箱:
wei1998@mail.ustc.edu.cn
论文:
https://www.ijcai.org/proceedings/2023/0169.pdf
1. 介绍
目前多数快速磁共振重建算法方法专注于在空间域或是在频率域上重建欠采样磁共振图像,却忽略了这两个域之间的相关性,阻碍了重建算法性能的进一步提高。为了解决这个问题,我们在这项工作中提出了一种以多域学习(MDL)块为基本单元的新型多域循环网络(MDR-Net),以逐步重建欠采样磁共振图像。
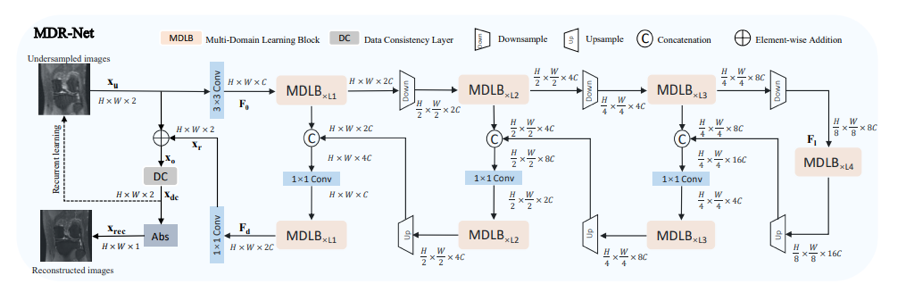
图1 MDR-Net 总体结构框图
2. 方法
为解决上述问题,本文基于编码器-译码器结构设计了一个新型多域循环网络(如图1所示),其中引入了手工设计的MDL模块(如图2所示)用于提取空-频域细化特征。具体地说,MDL 模块包含的频率分支利用傅里叶变换(FFT)来学习频域的全局信息,同时空域分支使用残差卷积模块提取局部特征,期间对各个分支学习到的特征信息进行互补学习,最后采用多头部转置注意力(MDTA)对学习到的空-频域特征进行跨信道特征交互。
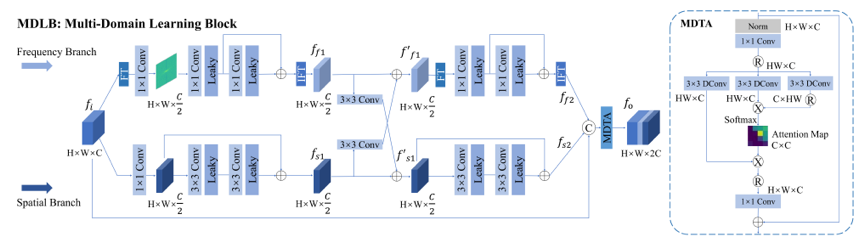
图2 MDLB 多域学习模块
另外,实验发现基于空域的损失函数往往会导致网络难以恢复图像的高频信息,导致重建图像的病理细节丢失。基于此,本文引入了一种基于频域的损失函数,以缩小频谱差距,实验发现,该损失函数能够有效地重建图像的频域信息,准确地恢复了图像的精细特征。
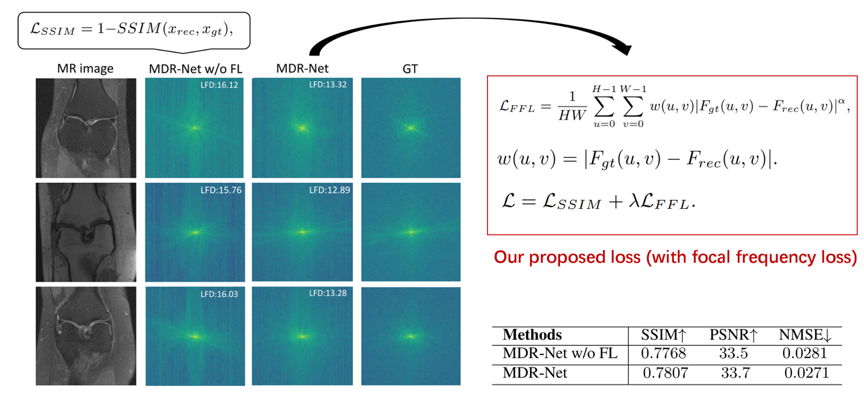
图3 损失函数设计及实验结果对比
3. 实验
我们在两个公开的MRI数据集上进行了实验,结果表明所提出的MDR-Net 始终优于其他竞争方法,并能够提供更多图像的细节信息。
表1 定量结果对比
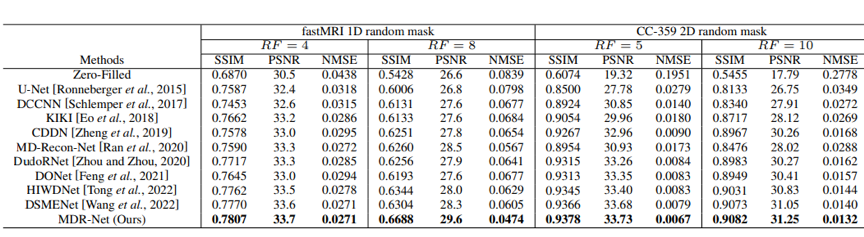

图4 定性结果对比
06
Video Diffusion Models with Local-Global Context Guidance
作者:杨思远1,张璐2,刘瑜1,*,姜智卓1,何友1
单位: 1清华大学,2大连理工大学
邮箱:
yang-sy21@mails.tsinghua.edu.cn,
zhangluu@dlut.edu.cn,
liuyu77360132@126.com,
heyou_f@126.com,
jiangzhizhuo@sz.tsinghua.edu.cn
论文:
https://arxiv.org/abs/2306.02562
代码:
https://github.com/exisas/LGC-VD
*通讯作者
视频序列预测旨在根据给定的单张图像生成内容合理、时序连续的视频序列。最近,扩散模型在图像生成领域取得了突破性进展,其已经取代对抗生成模型成为内容生成领域的基准方法。然而,将扩散模型迁移至视频预测任务仍存在诸多挑战。为了提升预测视频序列的时序连续性,现有方法通常在扩散模型的UNet中引入时间维度的操作(如3D卷积、时序注意力等)。然而,这种操作势必会引入巨大的计算量,为模型的训练和预测增加负担。如何在减少视频扩散模型的计算量的同时,提升预测序列的质量已经成为该领域的首要研究问题。为此,本文提出一种基于局部-全局上下文引导的视频扩散模型(LGC-VD)。该算法通过利用自回归框架从而实现针对视频预测、无条件预测和视频插帧的统一架构。首先,提出局部-全局上下文引导机制,通过将前序预测结果作为引导信息以提升后续视频的连续性。具体地,将前序视频片段的局部帧引入UNet与当前序列充分耦合。同时,利用序列编码器来获取前序视频片段的全局信息,并利用互注意力计算实现交互。此外,提出一种双阶段的训练策略,以提升扩散模型对预测误差的鲁棒性。
本文的主要贡献总结如下:
1. 提出局部-全局上下文引导机制以获取多层级引导信息,进而提升视频预测连续性;
2. 提出两阶段训练机制,通过将预测误差作为数据增广格式来提升模型对预测误差的鲁棒性;
3. 在两个公开数据集的结果证明本算法在视频预测、无条件生成和视频插帧任务的优越性。
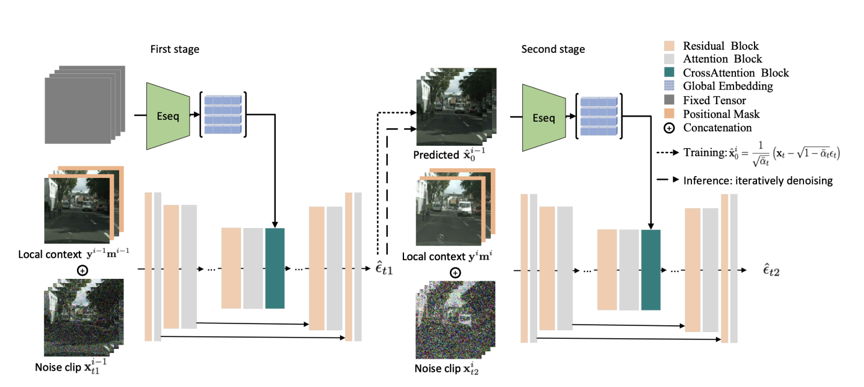
图1 算法网络结构图

图2 与SOTA算法的视觉对比结果

编辑人:桑基韬、聂礼强
专委会责任副主任:徐常胜
 京公网安备11010802017125号
京公网安备11010802017125号