
2024年论文导读第二期
【论文导读】2024年论文导读第二期
CCF多媒体专委会 2024-01-16 09:00 发表于山东


论文导读
2024年论文导读第二期(总第九十三期)
目 录
|
1 |
Learning 3D Photography Videos via Self-supervised Diffusion on Single Images |
|
2 |
Adaptive Path-Memory Network for Temporal Knowledge Graph Reasoning |
|
3 |
CSGCL: Community-Strength-Enhanced Graph Contrastive Learning |
|
4 |
Discrepancy-Guided Reconstruction Learning for Image Forgery Detection |
|
5 |
Divide Rows and Conquer Cells: Towards Structure Recognition for Large Tables |
|
6 |
Appearance Prompt Vision Transformer for Connectome Reconstruction |
01
Learning 3D Photography Videos via Self-supervised Diffusion on Single Images
作者:王晓东1,吴晨飞2,殷晟明2,倪旻恒2,Jianfeng Wang3,Linjie Li3,Zhengyuan Yang3,杨凡2,Lijuan Wang3,Zicheng Liu3,方跃坚1,段楠2
单位:1北京大学,2微软亚洲研究院,3微软(美国)
邮箱:
wangxiaodong21s@stu.pku.edu.cn
论文:
https://www.ijcai.org/proceedings/2023/167
论文讲解视频:
https://www.bilibili.com/video/BV19P411b7MN/?spm_id_from=333.999.0.0,第2章节
1.研究背景和动机
扩散模型在文本生成图像任务上展现了惊艳的能力,例如以Stable-diffusion为代表的系列工作。这类模型可以直接适配到图像拓展(如给定人物前景,生成图像背景),但是这些方法依赖于给定的图像信息和文本,对于多样的前景信息过少的情况,很难生视觉效果一致的图像。同时,我们关注到3D摄影生成这项任务,同样是基于图像的已有内容,去填补由于图像转动而产生的缺失区域。所以这项工作旨在将扩散模型从二维图新拓展任务推广到3D摄影任务上。对于3D摄影生成任务,主要的挑战在于:1)3D摄影视频数据较少,很难基于多视图的方法训练一个开放域的模型。2)基于单视图的方法是直接通过先验知识随机掩码一些区域,这与实际推理的缺失区域有较大的差距,导致生成效果不佳。这项工作借助预训练的文本生成图像模型的先验知识,设计自监督的训练,保证了在图像拓展和3D摄影生成任务上的一致性和多样性。
2.方法
我们的训练和推理流程如图1所示。我们方法设计的核心是减小训练和推理之间产生的差距,不同于之前的基于图像的方法直接随机掩码一些区域,我们使用相机变换的方式实时的做图像的前向变换和后向变换。如图1左侧所示,对于给定图像,先使用一个预训练的单目深度估计模型估计它的深度图,再假定一个相机位置S,通过对这个相机位置随机施加扰动的方式进行前向渲染。因为我们需要保证渲染后的图像和原始图像是相同的位置,所以我们再次去除这个扰动,得到后向渲染的图像。由于渲染过程会产生一些缺失区域,最终蓝色的区域就是我们需要通过训练模型去补全的区域。这个图像对在训练中被随机构造,用于训练给定图像的条件生成扩散模型。在推理时,相机变换产生的未知区域,直接使用训练好的模型进行预测即可。
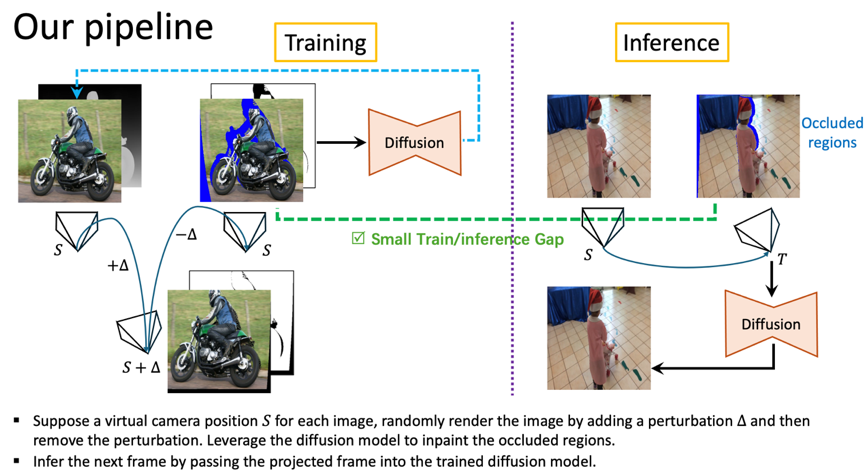
图1模型的训练和推理过程
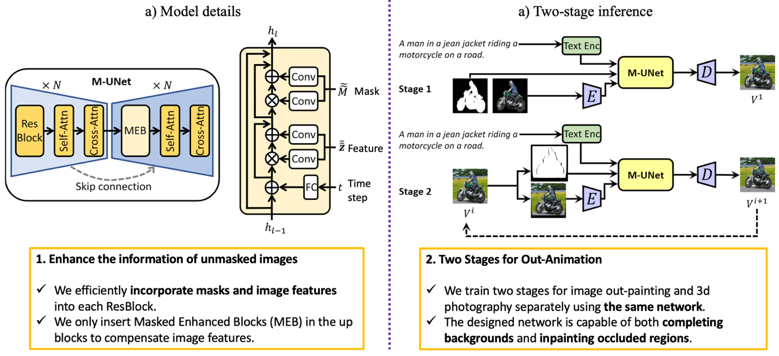
图2模型细节和两阶段推理
原始的扩散模型的网络结构只支持文本作为条件输入,为了支持更多的条件输入,我们设计了高效的MEB(Masked Enhanced Block)去执行特征注入的功能。我们将变换产生的掩码和已知区域的隐变量特征也随着时间步的特征注入到U-Net网络的残差模块中,作为特征补偿。对于两阶段的推理,第一阶段对给定图像进行拓展,第二阶段去逐帧地推理得到3D摄影视频,两阶段训练所使用的网络结构是完全一样的。
3.实验
我们在RE10K、MC数据集上进行新视角预测任务的评估,我们的方法作为只使用图片数据的方法,在多个指标上取得了和现有方法相当的效果。

我们在MSCOCO数据集上比较了图像拓展的效果,取得了最优的表现。我们也和现有的方法进行了定性比较,如图3和图4所示。

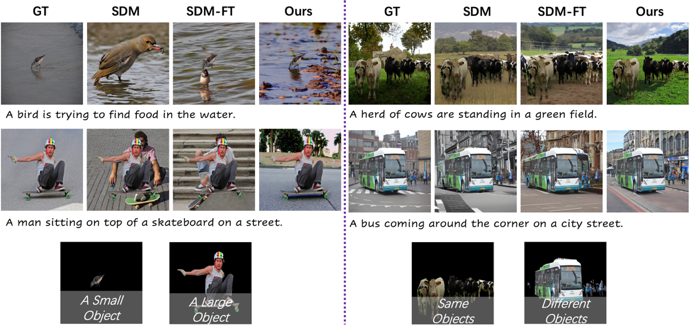
图3多样的图像拓展的效果比较,提出的模型生成的多样性和一致性都优于其他方法。

图4新视角预测的效果比较,提出的模型生成的一致性和清晰度都优于其他方法。
02
Adaptive Path-Memory Network for Temporal Knowledge Graph Reasoning
作者:董昊,宁致远,汪澎洋,乔子越,王鹏飞,周园春,傅衍杰
单位:中国科学院计算机网络信息中心,中国科学院大学,澳门大学,香港科技大学(广州),中佛罗里达大学
邮箱:
donghcn@gmail.com
论文:
https://www.ijcai.org/proceedings/2023/0232.pdf
代码:
https://github.com/hhdo/DaeMon
研究背景
时间知识图(TKG)推理旨在基于历史信息预测未来缺失的事实,近年来得到了越来越多的研究兴趣,为推理任务建立了大量的历史结构和时间特征模型。现有的大多数工作主要依靠实体表示来对图结构进行建模。然而,TKG实体在现实世界场景中的规模是相当大的,随着时间的推移,新实体的数量将不断增加。因此,我们提出了一种利用关系特征建模的新架构。它能够自适应地对历史时间上查询头实体和每个候选尾实体之间的时间路径信息进行建模,从而实现对未来确实事实的推理。
研究方法
这项工作提出了DaeMon。如图所示,它的主要思想是在考虑查询关系r的情况下,用序列子图自适应地对历史时间上查询头实体s和每个尾实体候选之间的可查询路径信息进行建模。由于每个时间戳的子图是独立的且不连接的,我们希望通过不断更新收集到的路径信息来捕捉跨时间的连接信息。
为了记录跨时间戳的路径信息,我们构建了路径存储器(path memory)来临时保存当前收集信息的状态。然后,我们使用路径聚合单元(path aggregation unit, PAU)来建模基于存储器中s与o之间的综合路径信息。此外,我们提出了记忆传递策略(memory passing strategy)来引导相邻时间之间的记忆状态传递。基于存储在存储器中的最终学习的查询感知路径信息,可以使用匹配函数在未来的时间戳进行推理。路径信息建模的一个高级思想是捕获子图序列之间的关系链模式。
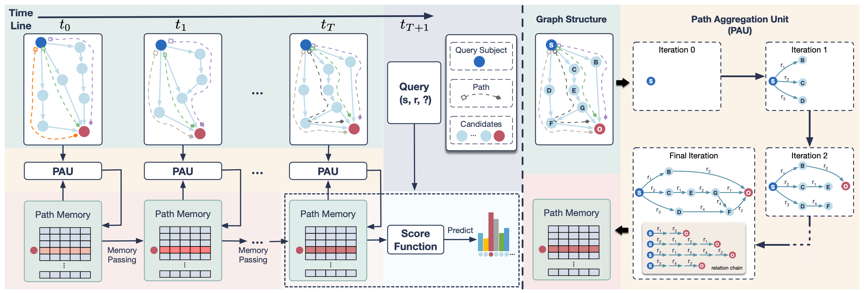
实验结果
我们在四个公开的TKG数据集上进行了实验,结果表明所提出的DaeMon优于其他基线方法,并原生支持模型的迁移。

03
CSGCL: Community-Strength-Enhanced Graph Contrastive Learning
作者:陈汉1,2,*,赵子文1,*,李玉华1,†,邹逸雄1,李瑞轩1,张瑞1,3,†
单位:
1华中科技大学计算机学院,2华中科技大学人工智能研究院,3清华大学
邮箱:
HanChenHUST@hust.edu.cn,
zwzhao@hust.edu.cn,
idcliyuhua@hust.edu.cn,
yixiongz@hust.edu.cn,
rxli@hust.edu.cn,
rayteam@yeah.net
论文:
https://arxiv.org/abs/2305.04658
代码:
https://github.com/HanChen-HUST/CSGCL
论文介绍博客:
https://zhuanlan.zhihu.com/p/628116694
*共同第一作者 †通讯作者
一.简介
社区(或群组,community)是图数据一种十分重要的拓扑结构。它由一批密集连接的节点组成,社区内的边密度比社区外的边密度一般要大得多。但是,在现有的图自监督学习范式中,很少有人深入考虑社区带来的语义影响。不同的社区存在一种对全局语义影响力的差异,本文将这种差异称为“社区强度”(community strength),由社区内边的占比和社区间边密度两项联合定义。忽略社区强度的差异可能造成潜在的表示偏差,因为社区强度本身是大型网络中存在的一种特性。如果影响力更大的社区遭到严重破坏,会导致图的全局语义发生偏移。
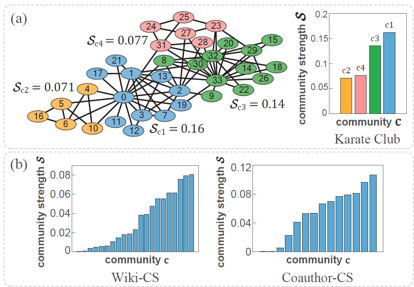
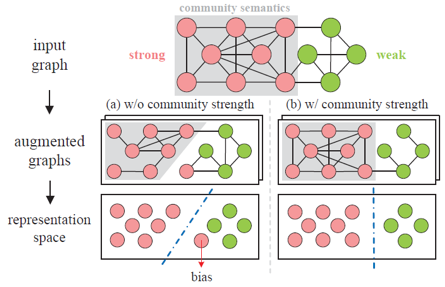
图1社区强度及其在真实社交网络数据集中的分布,以及不区分强度的社区学习导致的表示误差
二.方法
基于社区强度的图对比学习模型(Community-Strength-enhanced Graph Contrastive Learning, CSGCL)为了从图数据中尽可能地挖掘出有效的社区信息,设计了一套能够区分不同强度的社区的图对比学习框架,如下图所示。
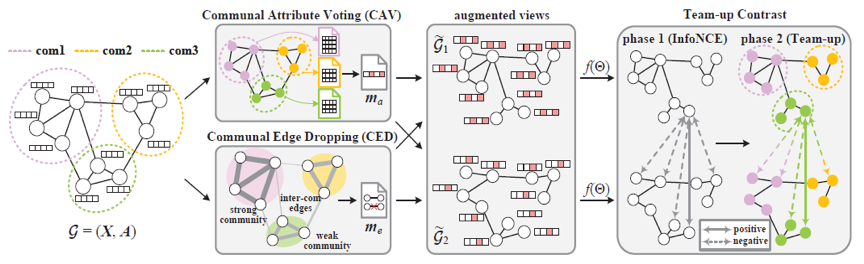
图2 CSGCL框架示意图
CSGCL首先提出了社区属性投票(Communal Attribute Voting, CAV)和社区链接移除(Communal Edge Dropping, CED)两种新的图增强方法。其中,CAV是一种基于特征掩码的、通过社区打分的形式去除冗余特征维度的增强方法。并且,在一个强社区的多数节点中影响力更大的维度更应该被对比学习保留。CED是一种基于边掩码的、保护全局社区语义的增强方法,其设计思路可以概括为(1)社区内的边比社区间的边更重要,因为保护社区内的边可以突出各社区本身的结构,督促模型学习它们;(2)强社区内的边比弱社区内的边更重要,因为图的全局语义主要受强社区内的链接影响。除此以外,为了保证能够学到社区的差异,CSGCL设计了渐进式的对比学习方案,称为“组队”(Team-up)。它将训练过程分为两个阶段,第一阶段仍旧使用传统的InfoNCE作为损失,而在经过一段训练时间之后,进入Team-up阶段,社区强度一项在相似度函数中的比重逐渐上升,开始缓慢地引导模型关注社区强度。
三.实验结果
CSGCL在几个常见的社交网络基准数据集上和多种下游任务上都达到了最先进的性能。这些数据集包括网页链接数据集Wiki-CS,共同作者数据集Coauthor-CS,以及共同购买数据集Amazon-Photo和Amazon-Computers。下游任务包括三个:节点分类、节点聚类和链接预测。另外,嵌入向量空间结果也由t-SNE可视化给出。
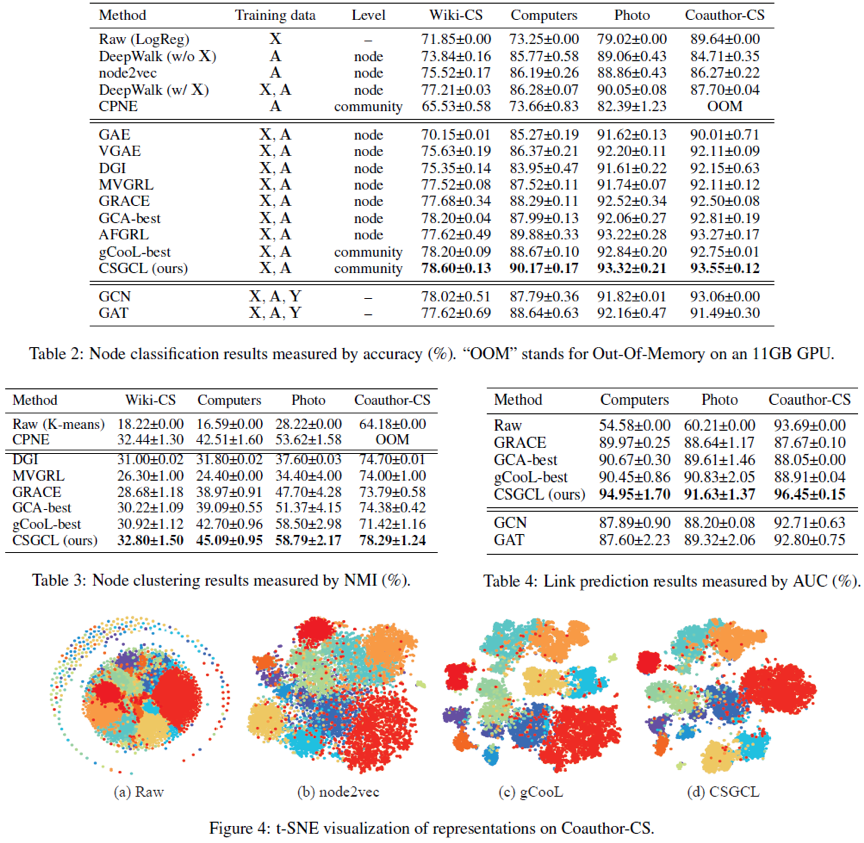
图3实验结果
04
Discrepancy-Guided Reconstruction Learning for Image Forgery Detection
基于差异性引导重构学习的图像伪造检测
作者:石泽男1,2, 陈海鹏1,2 , 陈隆3, 张冬3,∗
单位:
1吉林大学,
2 符号计算与知识工程教育部重点实验室,吉林大学
3香港科技大学
邮箱:
shizn@jlu.edu.cn,
chenhp@jlu.edu.cn,
longchen@ust.hk,
dongz@ust.hk
论文:
https://www.ijcai.org/proceedings/2023/0154.pdf
代码:
https://github.com/znshi/DisGRL
先进的图像协同编辑和合成方法(如ChatGPT、扩散模型等)使人们可以轻而易举地篡改图像。例如,特定图像中的物体和这些物体的外部属性完全可以通过一些文本进行插值。虽然这些方法可以增加图像的多样性和趣味性,但另一方面也带来了新的问题,即人们对图像所表达信息的信任度降低。此外,被篡改的图像还可能被用于一些恶意场合(如假新闻和蓄意诽谤),从而带来潜在的社会危害。因此,探索有效的图像伪造检测方法迫在眉睫。
为此,本文利用重构思想提出了一种新的图像伪造检测范式DisGRL,以提高对伪造敏感和真实紧凑视觉模式的模型学习能力。与现有的只关注特定差异模式(如噪音、纹理和频率)的方法相比,具有更强的通用性。如图1所示,本文首先提出了一个差异性引导的编码器(DisGE)来提取对伪造敏感的视觉模式。此外,本文构建了一个双头重构(DouHR)模块,以增强不同颗粒空间中真正紧凑的视觉模式。在双头重构模块的引导下,本文进一步引入了差异聚合检测器(DisAD)来聚合这些真正的紧凑视觉模式,以提高对未知模式的造假检测能力。论文在四个具有挑战性的数据集上进行了验证,实验结果表明,DisGRL与现有图像伪造检测方法相比具有显著的性能提升,并具有较好的泛化能力。

图1 DisGRL算法整体框架
我们提出的重构学习旨在通过建立双头重构方案来保留更多的真伪差异性变化。为了验证其有效性,如图 5 所示,我们可视化两个重构的输出以及原始输入和重构图之间相应的差异。我们可以观察到真实的人脸可以被很好地重建而几乎没有模糊,而伪造部分的虚假人脸则无法被恢复。差异图显示可能是伪造区域的痕迹,进一步突显了真实和伪造人脸之间的差异。与Diff-1相比,Diff-2能够额外增强和补充人脸中的伪造区域。例如,针对NT伪造样本,Diff-1响应在嘴部区域较弱,而在Diff-2中数值较大,说明在图像伪造检测中使用额外头进行重建的重要性和有用性。

图2模型在FF++数据集上的重构和差异可视化结果图。“rec1”和“rec2”是双头重构结果。“Diff-1”和“Diff-2”分别表示对应的像素级差异。
05
Divide Rows and Conquer Cells: Towards Structure Recognition for Large Tables
作者:申化文1,2,高翔1,魏谨4,1,乔梁3,周宇1,2*,李强1,2,程战战3
单位:1中国科学院信息工程研究所,2中国科学院大学,3海康威视研究院
邮箱:
shenhuawen@iie.ac.cn
zhouyu@iie.ac.cn
论文:
https://www.ijcai.org/proceedings/2023/0152.pdf
*通讯作者
动机
现实生活中,许多表格不是电子化的方式保存的,而是以非结构化的图像格式存储,例如照片、扫描文档等。这些非结构化的表格图像很难被计算机直接分析和处理,给归档和检索等自动化过程带来了困难。随着深度学习的发展,许多基于图像描述的表格结构识别方法被提出。这些方法旨在端对端地将表格图像转换为结构化的表格,但也存在两个问题:(1)生成的表格序列是一维的,而表格是以二维的形式组织的,两种形式在内在逻辑上存在一定的不一致性;(2)生成的表格序列非常长,而现有的方法都是使用自回归形式生成表格结构序列,这会带来严重的误差累计问题。
方法
本文提出了一个半自回归的端对端表格结构识别方法DRCC。DRCC由三部分组成:(1)用于提取图像特征的编码器模块;(2)用于预测表格行的行解码器模块;(3)用于预测表格单元格的单元格解码器模块。
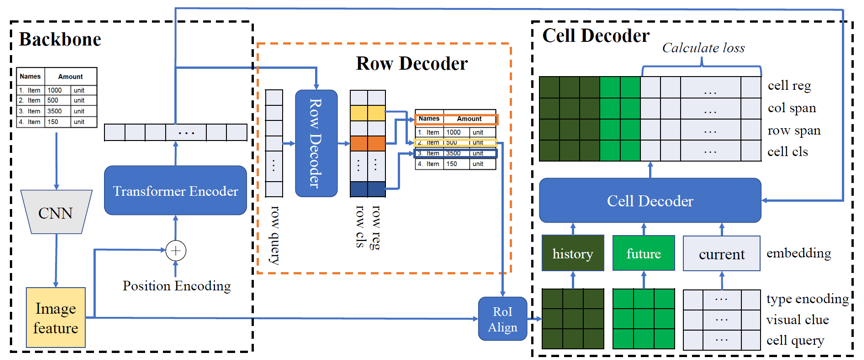
编码器模块由残差卷积网络与Transformer模型组成,得到的视觉语义特征将会用于接下来的解码过程。
本文的主要贡献是级联的两步解码器。模型两个解码器都使用Transformer解码器作为主体结构。其中,行解码器使用可学习的嵌入向量作为输入,然后使用交叉注意力机制与Transformer编码器得到的语义特征进行交互,预测得到每一行的位置与类别信息。
模型的第二个解码模块是单元格解码器,单元格解码器与行解码器仅在分类头部不同,其余模型结构完全一致,仅对输入输出形式做了修改。单元格解码器采用半自回归的形式进行解码,通过结合行解码器预测得到的行的信息、以往迭代过程中单元格解码器预测得到的单元格信息与残差卷积网络提取得到的视觉特征融合作为输入,并与编码器提取得到的语义信息进行交互,按照单元格从上到下的顺序,逐行预测每一行中的单元格信息。在每一步迭代中,单元格解码器将会预测得到当前行的所有单元格。
结果
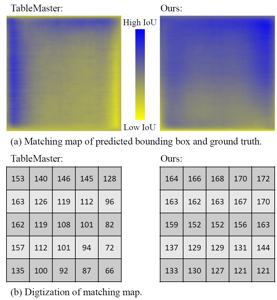
本文在多个公开数据集上进行了实验,实验结果证明了方法的有效性。

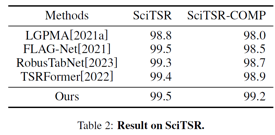
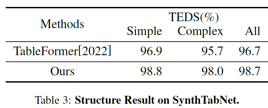
同时本文分析了半自回归的DRCC与自回归的TableMaster在表格图像不同位置的正确率,进一步验证了此方法能够在一定程度上缓解以往方法的误差累计。
06
Appearance Prompt Vision Transformer for Connectome Reconstruction
基于表观提示视觉transformer的连接组重建方法
作者:孙锐,罗乃淞,潘裕文,麦华煜,张天柱,熊志伟,吴枫
单位: 中国科学技术大学,合肥综合性国家科学中心人工智能研究院,深空探测实验室
邮箱:
issunrui@mail.ustc.edu.cn,
lns6@mail.ustc.edu.cn,
panyw@mail.ustc.edu.cn,
mai556@mail.ustc.edu.cn,
tzzhang@ustc.edu.cn,
zwxiong@ustc.edu.cn,
fengwu@ustc.edu.cn
论文:
https://www.ijcai.org/proceedings/2023/0158.pdf
研究背景
神经连通性重建是了解生物重建功能的基础任务,对于电生理学、细胞生理学、遗传学等基础科学研究有着广泛的推动作用。三维电子显微镜是唯一可用的成像仪器,具有足够的分辨率来没有歧义地可视化和重建密集的神经形态。然而,在这个分辨率下,即使是中等大小的神经回路也会产生大量的神经元数量(例如,在单个百万像素图像中通常有数百个神经元实例),这对于人工注释来说是非常费力的(例如,通常重建 体积所需的人工劳动需要超过100,000小时。最近,大量研究已经将注意力转向深度神经网络,以追求自动神经连接重建。由于所有神经元实例都是同一类型(即生物细胞),具有复杂的形态和密集交织的分支,因此如何充分探索具有判别力的信息以进行准确的神经元重建是极具挑战性的。
方法概述
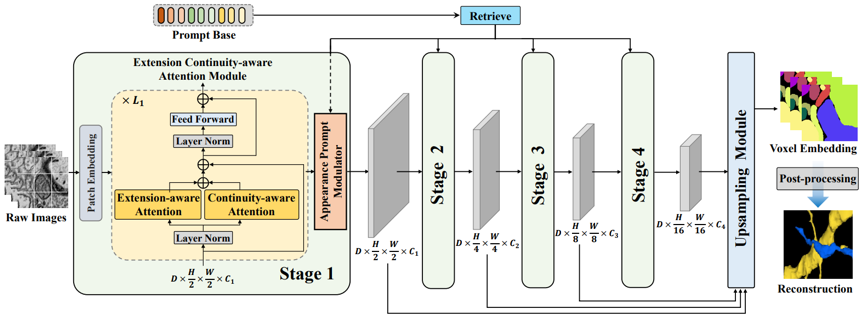
图1表观提示视觉transformer (APViT)示意图
如图1所示,我们提出统一的表观提示视觉transformer (APViT) 用于连接组重建,具体而言,针对神经元的延续性以及切片间的连续性,我们提出延伸-连续感知模块用于构建层级化注意力机制以学习实例体素语义上下文信息从全局层面,并利用连续性先验来增强体素空间感知性。进一步,我们提出表观提示调制器来利用有着丰富空间信息的体素自适应表观知识来指导实例体素语义的学习,探索了亲和度学习与度量学习互补的巨大潜力。值得注意的是,我们的方法有着很大的灵活性,可以适应各种后处理 (Waterz, LMC, MWS)等而只需要训练一次。
实验结果
如表1,表2和图2所示,APViT在AC3/AC4 以及 CREMI 数据集上的表现远远优于现有的方法。除此之外,我们将之前的方法在AC3/AC4测试集上的重建结果可视化。可以看出,之前方法在重建相对简单清晰的神经元时都表现良好,但在面对相互纠缠的神经元个体时表现往往不尽人意,而APViT往往可以区分这些神经元归功于特定的设计。
表1在AC3/AC4数据集上的性能比较
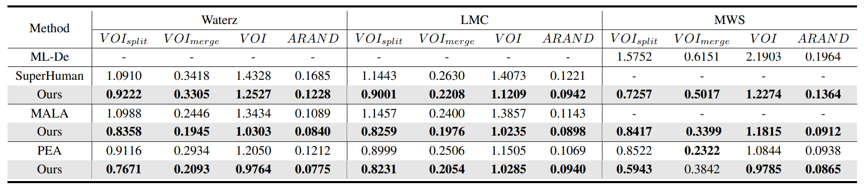
表2在CREMI数据集上的性能比较

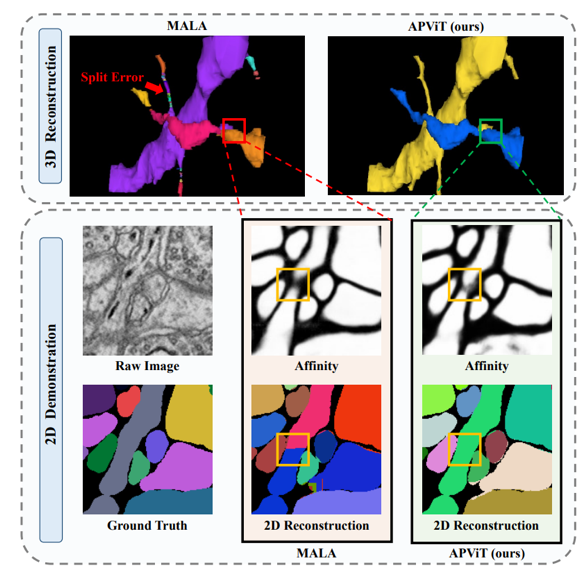
图2在AC3/AC4数据集上的可视化

编辑人:桑基韬、聂礼强
专委会责任副主任:徐常胜
 京公网安备11010802017125号
京公网安备11010802017125号