
2024年论文导读第三期
【论文导读】2024年论文导读第三期
CCF多媒体专委会 2024-01-30 09:00 发表于山东


论文导读
2024年论文导读第三期(总第九十四期)
目 录
|
1 |
Learned Image Compression Using Cross-Component Attention Mechanism |
|
2 |
Enhancing Network by Reinforcement Learning and Neural Confined Local Search |
|
3 |
Model Conversion via Differentially Private Data-Free Distillation |
|
4 |
Semi-supervised Domain Adaptation in Graph Transfer Learning |
|
5 |
KMF: Knowledge-Aware Multi-Faceted Representation Learning for Zero-Shot Node Classification |
01
Learned Image Compression Using Cross-Component Attention Mechanism
基于跨分量注意力机制的端到端图像压缩
作者:段文鸿1,常峥2,贾川民3,*,王苫社3,马思伟3,*,宋利1,高文3
单位:1上海交通大学,2中国科学院大学,3北京大学
邮箱:
whduan@sjtu.edu.cn
changzheng18@mails.ucas.ac.cn
cmjia@pku.edu.cn
sswang@pku.edu.cn
swma@pku.edu.cn
song_li@sjtu.edu.cn
wgao@pku.edu.com
论文:
https://ieeexplore.ieee.org/abstract/document/10268865
代码:
https://github.com/duanwenhong/LIC_AIPM/tree/main
对图像进行压缩编码是多媒体领域的热点研究问题,主要目标就是最小化图像的率失真损失,即保证质量的同时尽可能降低码率。近年来,端到端图像压缩算法取得了很好的表现。然而,当前主流的端到端图像压缩算法都是针对于RGB格式的图片,因为RGB和YUV420颜色空间特性差异,这些算法对于广泛应用在视频编码的YUV420格式的图像压缩并不适用。为解决此问题,本文提出一种基于信息指导机制的图像压缩方法,通过跨分量注意力机制对于YUV420格式图像实现高效的图像压缩,结构如图1所示。设计提出了基于信息指导单元(IGU)和注意力机制的双分支信息保护模块 (AIPM),双分支结构一方面可以保护跨分量信息分布,避免不同分量信息的相互干扰,特征注意力模块(FAB)可以保护分量的重要信息。另一方面,可以充分利用亮-色度分量间的相关性,通过亮度信息的指导更好地保护色度信息。进一步提出自适应跨分量增强模块(ACEM),利用不同分量的相关性重建图像细节。实验表明所提出的图像压缩框架相比于当前主流图像压缩算法可以实现更好的性能,相比于编码标准VVC,在统测序列上平均可以取得8.37%码率节省。此外还提出了一种面向上下文模块的量化方案,可以客服由于上下文模型浮点操作的误差累积引起的解码错误问题,为未来端到端编码器实际应用提供了一种普适的解决方案。

图1文章提出的端到端图像压缩框架
方法简介:
(a)提出了一种跨分量双分支信息保护模块
为了在编码提取亮度和色度特征过程中更好地保护信息,文章创新性地提出了跨分量双分支信息保护模块 (AIPM),结构如图1 (a)所示。在AIPM中,为了实现对于在编码过程中不同分量重要特征的信息保护,本文利用注意力机制分配更多的码率给复杂的区域。设计并提出了特征注意力模块 (FAB)来进行重要信息的保护,结构如图2所示。在FAB中,通过残差通道注意力模块 (RCA)来实现码率分配,通过细粒度注意力模块 (FA)来增加模型的感受野,从而通过残差学习更好地保护重要信息。

图2 Feature attention Block (FAB)模块
在编码过程中,为了更好地保护色度信息,文章提出了信息指导单元 (IGU),结构如图1 (b)所示。亮度分量相比于色度分量有更多的纹理和结构信息,故通过自注意力机制进行亮色度相关性的建模,在编码过程中利用亮度指导色度的信息提取过程。在所提出IGU单向指导模块的基础上,进一步设计了双向指导模块 (BGU),在编码过程中亮色度信息相互指导,结构如图3所示,算法如图4所示。

图3 bidirectional-guided unit (BGU)模块
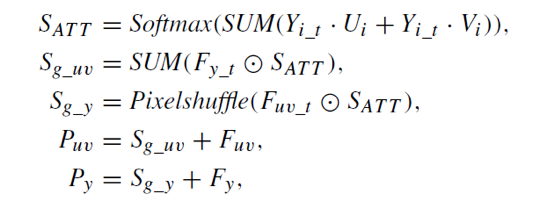
图4 BGU算法流程
(b)自适应跨分量增强模块
在解码端,利用编码端生成的亮色度注意力建模信息传输到解码端,通过亮度对色度的信息引导实现进一步质量增强。具体来说,利用亮度和注意力信息生成亮度对色度的指导图,与解码生成的色度信息一同进行色度的质量增强,结构如图5所示。

图5自适应跨分量增强模块
(c)上下文模型量化方案
为了克服跨平台解码中由于上下文浮点操作产生的误差累积问题,文章提出了上下文模型量化方案。首先使用一个卷积层替代原有的掩码卷积层,使用掩码卷积层的权重替代卷积层的权重。然后,在上下文模型的每个模块插入观测器来计算数据的范围以及量化参数,使用数据集的子集进行校准以及模型的量化转换。
实验部分:
在Vimeo90k数据集进行训练,在VVC统测序列,Kodak,CLIC,以及IEEE 1857.11统测数据集ClassC上进行测试。全面对比了所提出框架和当前主流的图像压缩方法和HEVC/VVC传统编码标准在其他数据集的率失真性能,曲线如图6所示,(a)/(b)/(c)分别是Kodak,CLIC,以及IEEE 1857.11统测数据集ClassC数据集的结果。所提出方法在VVC数据集和VTM-11.0对比结果如图7所示。

图6 Kodak,CLIC,以及IEEE 1857.11统测数据集ClassC数据集RD曲线

图7 VVC统测序列数据集性能对比
从图7中可以看出,所提出算法相比于传统编码标准以及主流算法可以取得明显的码率节省,其中相比于最新编码标准VVC,在PSNR指标平均可以节省10%的码率。
图8展示了和端到端的主流图像压缩算法和编码标准的主观效果,所提出算法在更低的码率下可以取得更好的主观效果。

图8主观效果对比
为了验证量化算法的有效性,进一步对比了模型量化前后的性能,如图9所示。量化后模型码率损失小于1%,同时在低码率情况下基本不存在性能损失,这充分显示了所提出量化算法的有效性。在未来工作中,还将考虑差分等量化算法的方式进一步减少模型的量化损失,进一步地降低模型的存储和计算复杂度。
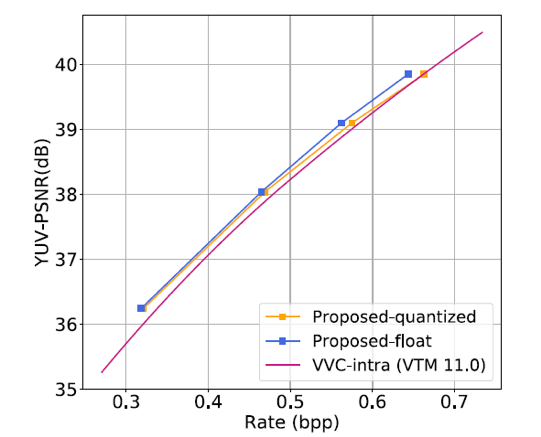
图9量化前后效果对比
总结:
文章首次利用在编码端亮色度的相关性建模,从而在编码过程中更好地保护色度的重要特征,对于解码端利用相关性实现质量增强,在编解码端通过跨分量注意力实现亮度对色度的指导。该方案通过展示利用不同分量信息的相关性提升端到端图像压缩方案的率失真性能,从而推进了图像编码研究领域的进一步发展。
02
Enhancing Network by Reinforcement Learning and Neural Confined Local Search
基于强化学习和神经局部搜索的网络系统增强
作者:胡奇夫,李茹杨*,邓琪,赵雅倩,李仁刚
单位:浪潮电子信息产业股份有限公司
邮箱:
huqifu90@gmail.com
liruyang@ieisystem.com
论文:
https://www.ijcai.org/proceedings/2023/236
*通讯作者
1.引言
社会经济秩序的正常运转依赖于网络化系统的可靠运行,例如电网、通信网络、交通网络等。网络鲁棒性是衡量网络在遭受攻击时保持可靠运行的能力,然而现实中大量的网络在设计时未充分考虑鲁棒性,需要事后增强。因此,网络增强问题主要考虑,能否通过少量修改网络结构以尽可能提高其鲁棒性?
2.方法
我们将网络增强问题建模为一个序列决策问题,提出了知识增强的环境状态表示、基于层次化注意力机制的决策网络,并进一步提出神经局部搜索来提升初始解。
(1)知识增强的环境状态表示(NEP-AM)。为对环境进行充分表征,我们引入了两类知识,第一类常用于刻画拓扑结构,第二类是求解网络增强问题中常见启发式算法的决策指标。利用上述两类知识,智能体能更好地感知环境。
(2)基于层次化注意力机制的决策网络(NEP-HAM)。我们在底层注意力机制中屏蔽非邻居节点,在上层中注意力机制中不屏蔽任何节点,因此节点聚合信息的范围从小到大构成了层次化的注意力机制。实验结果表明,层次化注意力机制相比非层次化注意力机制有更好(差)的分布内(外)泛化能力,这是因为前者对网络结构的变化更为敏感。
(3)神经局部搜索(NCLS)。智能体完成求解后,可通过局部搜索进一步提升求解质量。为实现大邻域上的局部搜索,我们提出神经局部搜索,其关键点在于利用预训练的模型对大邻域进行采样,进而将搜索空间限制在采样所得的样本上。实验结果表明,和 1-opt 局部搜索相比,神经局部搜索能找到更好的解。
3.实验
针对预训练、主动搜索任务,我们将提出的方法与启发式算法、已有强化学习算法进行了对比,结果如表 1-2 所示。为验证神经局部搜索的有效性,我们和 1-opt Local Search 进行了对比,结果如图 3 所示。以上结果均说明了我们方法的有效性。
表1预训练任务上的评估结果。我们在20个节点的网络上进行预训练,评估了预训练模型在分布内的泛化能力和分布外的泛化能力。括号外(中)的结果对应目标攻击(随机故障)

表2主动搜索任务上的评估结果。括号外(中)的结果对应目标攻击(随机故障)

表3神经局部搜索的评估结果。括号外(中)的结果对应目标攻击(随机故障)

03
Model Conversion via Differentially Private Data-Free Distillation
作者:刘博超1,王鹏举1,李世鲲1,曾丹2,葛仕明1
单位:1中国科学院信息工程研究所, 2 上海大学
邮箱:
geshiming.iie.ac.cn
论文:
https://www.ijcai.org/proceedings/2023/0243.pdf
深度神经网络在各个领域取得的巨大成功与大量数据和模型的开源息息相关。在不同的人工智能社区中有着各式各样的开源模型,但是这些模型的开源由于其训练数据中的隐私信息也许会导致隐私泄露问题。如何将这些有价值的模型进行安全的发布成为了一个亟待解决的问题。因此,我们考虑一种基于差分隐私无数据蒸馏的模型转换方法来将这些模型转换为隐私保护的模型进行发布。如图1所示,以无数据知识蒸馏为主体框架,在反向传播过程中的梯度中加入噪声实现差分隐私,从而训练得到隐私保护的学生模型用于发布。

图1差分隐私无数据蒸馏
在这个工作中,我们以将敏感的教师模型转换为可发布的学生模型为目标,平衡模型性能与隐私保护能力。我们从两个方面实现隐私保护:1)我们以无数据知识蒸馏为主题框架,避免了学生模型直接接触教师的训练数据;2)在学生训练时的反向传播过程中,加入了高斯噪声实现了差分隐私保护。同时为了提高学生模型性能,我们采用归一化来代替传统差分隐私训练方法中的梯度裁剪操作。通过这种差分隐私的无数据蒸馏方法将教师模型转换为隐私保护的学生模型用于发布。我们在多个数据集上的实验证明了方法的有效性。

04
Semi-supervised Domain Adaptation in Graph Transfer Learning
作者:乔子越,罗霄,肖濛,董昊,周园春,熊辉*
单位:
香港科技大学(广州)江门双碳实验室,
广州市香港科大霍英东研究院,
中国科学院计算机网络信息中心,
中国科学院大学
邮箱:
zyqiao@ust.hk
论文:
https://www.ijcai.org/proceedings/2023/0253.pdf
*通讯作者
1. 概述
这篇论文的动机源于图迁移学习中的一个关键挑战:如何在源图(有大量标签数据)和目标图(标签数据稀缺或完全没有)之间有效地转移知识。现实中,如社交网络等领域的数据常呈现为图形结构,但标签的获取往往代价高昂或不可行。这导致了一个问题:如何在源图的丰富标签信息和目标图的标签缺乏之间建立有效的知识迁移机制。然而,这仍然是一项不容易的任务,因为它必须解决两个基本挑战:
挑战1:如何克服跨图之间的显著领域转移,以实现领域不变的预测?源图和目标图之间的领域转移大致包括以下两个方面:图拓扑和节点属性。例如,不同的图可能具有不同的链接密度和子结构模式,而来自不同来源的手工制作的节点属性可能分别具有显著的偏差。这带来的领域转移比传统数据更为显著。
挑战2:如何缓解分类器对于准确和标签区分性预测的标签稀缺性问题?由于目标图完全没有标签,现有的工作只进行领域对齐,而没有考虑整体分布可能很好地对齐,但类别级别的分布可能不适合分类器的情况。更糟糕的是,源图上只有一部分节点标签可用,阻碍了有效的分类器学习。因此,利用图拓扑来提高分类器对未标记节点的区分能力至关重要。
因此,论文提出了一种新型的半监督域适应方法,旨在解决这一挑战,特别是在存在显著域差异和标签稀缺的情况下,提高目标图的分类准确性。

2.方法
这篇论文提出了一种半监督图域适应(SGDA)方法,旨在解决图传递学习中的域适应问题。其方法分为三个主要部分:
1)节点嵌入泛化:使用图卷积网络,计算节点间的正成对互信息,从而探索高阶的拓扑信息,以学习泛化的节点表示。
2)对抗性转换:引入可训练的偏移参数到源图中,通过对抗性学习训练图编码器和偏移参数,以实现源图和目标图间的域分布对齐。
3)伪标签与后验分数:针对无标签节点引入伪标签和后验分数,通过计算节点与类中心的相对位置,改善模型在目标图上的分类性能。
这种方法通过上述三个部分的结合,有效地解决了图传递学习中的域适应问题,特别是在标签稀缺的情况下。

3.实验
实验使用了三个真实世界的图数据集:ACMv9、Citationv1和DBLPv7。每个类别代表不同的研究领域,节点表示论文,边代表引用关系。为了验证SGDA的有效性,论文选用了多种图神经网络和领域适应方法作为基准进行比较。使用两层图卷积网络作为SGDA的基础,调整不同的实验参数进行测试。通过在多个公开数据集上的实验,论文验证了其方法在不同实验设置下的有效性。


05
KMF: Knowledge-Aware Multi-Faceted Representation Learning for Zero-Shot Node Classification
KMF:用于零样本节点分类的知识感知多方面表示学习
作者:吴李康、蒋俊极、赵洪科、王皓、连德富、张梦迪、陈恩红
单位:中国科学技术大学
邮箱:
wulk@mail.ustc.edu.cn
论文:
https://www.ijcai.org/proceedings/2023/0262.pdf
代码:
https://github.com/guaiqihen/MVE
研究动机
在图数据分析中,零样本节点分类(Zero-Shot Node Classification,ZNC)已成为一个新兴且关键的任务。该任务旨在预测模型在训练过程中未观察到的未知类别的节点。现有的研究主要利用图神经网络(Graph Neural Networks,GNNs)将特征原型与标签语义关联起来,从而实现从已知类别到未知类别的知识转移。然而,先前的工作忽略了特征-语义对齐中多方面的语义定向,即节点的内容通常涵盖与多个标签的语义相关的各种主题。因此,有必要分离和判断不同影响认知能力的语义因素,以提高模型的普适性。为此,我们提出了一种基于知识图谱(Knowledge Graph,KG)的多方面感知(Knowledge-Aware Multi-Faceted,KMF)框架,通过提取KG中的话题来增强标签语义的丰富性。然后,将每个节点的内容重构为知识Topic级别的表示,为不同标签提供多方面和细粒度的语义关联。由于图实例(即节点)表示的特殊性,我们开发了一种新的几何约束来减轻由节点信息聚合引起的原型漂移问题。最后,我们在几个公共图数据集上进行了大量实验,并设计了一个零样本跨领域推荐的应用。定量结果通过与现有最先进的基线方法进行比较,证明了KMF的有效性和泛化能力。

挑战与策略
为了实现在图数据上细粒度的知识转移的高质量零样本学习,必须克服一些挑战。首先,很难从节点的原始内容中生成与标签的多语义对齐的表征向量。为了解决这个问题,我们引入了一种知识感知的主题挖掘算法。具体而言,标签(例如,“机器学习”,“数据库”)被视为给定知识图谱上的锚点(我们在工作中使用ConceptNet)。由于语义以结构化和空间形式分布在知识图谱上,我们基于锚点的位置获得了对应的主题邻域集合。通过将节点内容的单词与主题匹配,原始节点的文本可以分离成与标签相关的多个语义集合。然后,我们使用预训练的语言模型(例如BERT或者Llama)和GNN来嵌入基于主题的节点表示,并进行拓扑特征挖掘。此外,我们面临第二个挑战,即节点的基于图的聚合操作通常会导致节点过度平滑的问题。对于多方面框架,我们还需要设计一种特殊的差异增强机制。我们将基于主题的子表示向量视为可删除的属性,并提出了一种主题视图的图对比学习策略来增强节点的区分性。同时,我们发现节点的聚合会吸收与其自身类别不同的邻居的信息。这种扩散导致特征子空间中每个类别的原型漂移,进一步影响了零样本学习中语义子空间和特征子空间的对齐。为了解决这个最后的挑战,我们提出了一种几何约束损失,从两个方向和距离共同约束特征和语义的分布,其可以很容易地集成到我们的框架中。
实验结果
我们在多个真实世界的图数据集上进行了充分的实验。零样本节点分类的定量结果表明,与一些强大的对比方法相比,我们提出的知识感知多方面框架(KMF)取得了更优的表现。


编辑人:桑基韬、聂礼强
专委会责任副主任:徐常胜
 京公网安备11010802017125号
京公网安备11010802017125号