
【论文导读】2024论文导读第十期
【论文导读】2024年论文导读第十期
CCF多媒体专委会 2024年05月21日 09:30 北京


论文导读
2024年论文导读第十期(总第一百零一期)
目 录
|
1 |
GCVC: Graph Convolution Vector Distribution Calibration for Fish Group Activity Recognition |
|
2 |
Limb-Aware Virtual Try-On Network With Progressive Clothing Warping |
|
3 |
Self-Supervised Intra-Modal and Cross-Modal Contrastive Learning for Point Cloud Understanding |
|
4 |
SGSR-Net: Structure Semantics Guided LiDAR Super-Resolution Network for Indoor LiDAR SLAM |
|
5 |
Privileged Modality Learning via Multimodal Hallucination |
01
GCVC: Graph Convolution Vector Distribution Calibration for Fish Group Activity Recognition
作者:
赵振锡1 2 3 4, 杨信廷 2 3 4, 刘锦涛2 3 4 5, 周超* 2 3 4 , 赵春江* 2 3 4
单位:
1西北农林科技大学信息工程学院,2北京市农林科学院信息技术研究中心,3国家农业信息化工程技术研究中心,4农产品质量安全追溯技术及应用国家工程研究中心,5 University of Almería
邮箱:
zzx0525_2018@nwafu.edu.cn;
nercitaznxt@163.com;
jintaol@163.com;
supperchao@hotmail.com;
zzx0525_2018@163.com
论文:
https://ieeexplore.ieee.org/document/10155192
数据集:
https://github.com/ crazysboy/GCVC/tree/master
*通讯作者
1.研究背景
现有的鱼类动作识别算法仅使用表面动作特征和其他辅助信息来直接推理鱼群活动,忽略了个体鱼类动作与群体活动之间的关键关系,例如对象检测或目标跟踪算法。另一方面,基于深度学习的人类群体活动识别网络无法有效解决鱼类遮挡严重、姿态多样、个体鱼类运动不明显、鱼类自发且不规则运动等问题。上述挑战使得所使用的主干网络难以提取鱼类行为特征,导致特征向量数据分布的粘连。这是因为存在相似的鱼类个体动作和群体活动、鱼类群体阻碍、食物干扰等各种动作特征和干扰信息混杂在高频特征信息中。特征向量数据分布的粘附是指提取的活动特征向量类在特征空间分布中混合在一起而没有明显分离的情况。传统的骨干网络和GCN难以从混淆数据分布中提取重要特征。如图1(a)所示,活动特征向量类别的分布呈现混合性和粘附性。相对于图1(b),四种活动特征向量没有明确的边界。
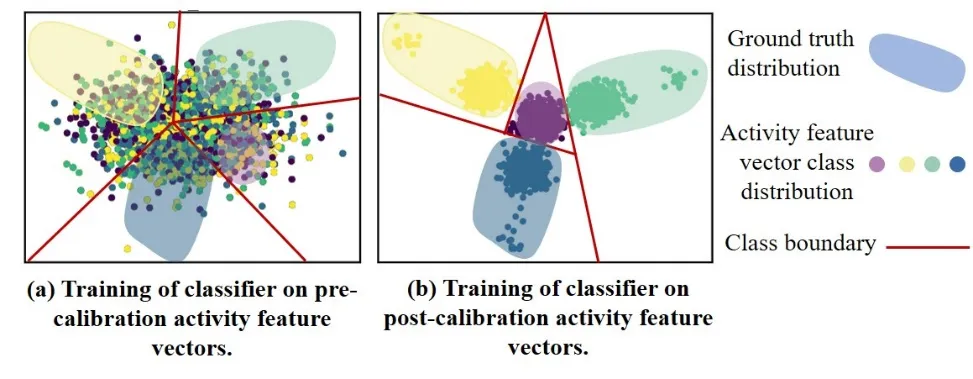
图1分类器在活动特征向量校准前后的比较。(a)表明活动特征向量类的分布是混乱且粘连在一起的(本文中称为“基础数据”)。分类器很难从基础数据中得出准确的边界。此外,类边界内的活动特征向量数据的分布与真实分布不匹配。(b)显示了分类器在校准后活动特征向量上的训练。与(a)相比,分类器可以准确地划分不同活动特征向量类之间的边界。在类边界区域内,没有其他类别标签点,符合真实的分布范围。
因此,结合鱼类动作行为的特点,本文提出了一种新的图卷积向量校准(GCVC)方法用于鱼群活动识别。活动特征向量校准模块旨在解决数据粘连以及特征信息估计分布与真实分布之间的不匹配问题。其思路是首先统计原始数据的分布,使其活动特征向量各维服从高斯分布。然后从校准后的分布中采样少量学习样本以扩充分类器的输入。此外,本文还改进了残差分割注意力网络主干网络(ResNeSt50-tiny),加强了提取鱼类动作特征的能力。主要的改进是砍掉了负责小目标检测的特征输出层,ResNeSt-tiny还增加了动作特征融合模块。
2. 方法概述
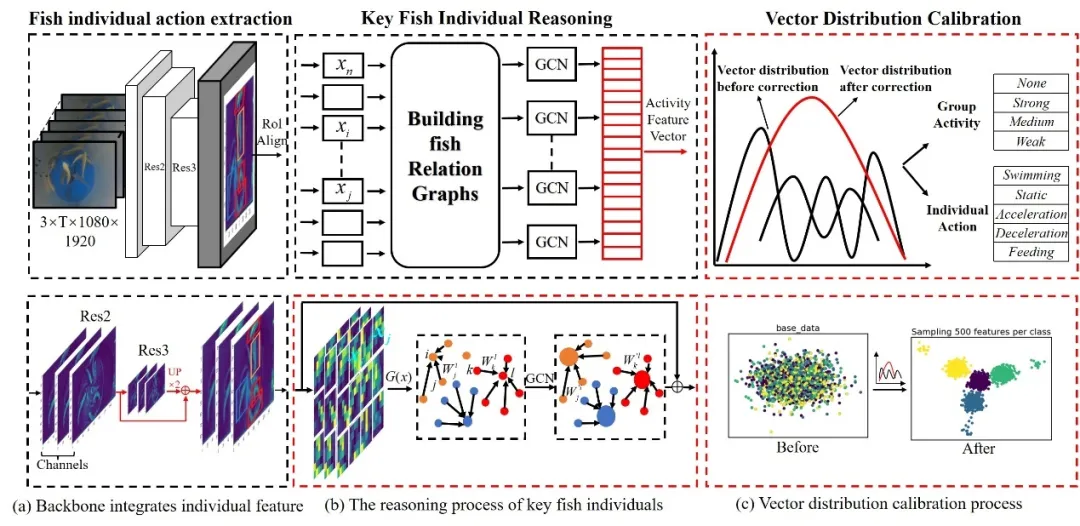
图2 GCVC网络结构
整体群体活动识别网络如图2所示,主要分为3部分:鱼类个体动作提取、关键鱼类个体动作推理和活动特征向量校准模块。首先,将视频序列中t-1、t、t+1处的3张相邻鱼类活动图片输入到backbone(ResNeSt-tiny)中提取目标特征并输出两种尺度,并用作为动作特征提取网络的输入,以获得个体鱼的动作特征(图2(a))。其次,将提取的包含个体动作特征(xi)的信息输入到GCN中进行动作关系推理,并生成动作特征向量(图2(b))。最后,将生成的活动特征向量输入到活动特征向量标定模块中,修正数据分布,使特征向量的维数接近高斯分布,对活动行为和个体动作标签进行分类(图2(c))))。对包含活动特征向量的数据样本进行强化和校正,降低了原始数据分布的粘附性。同时降低了分类难度,从而提高了识别准确率。图2中的活动特征向量校准模块中的黑色曲线代表校正前存在的几种可能数据的估计分布,可能与真实的估计分布不匹配。红色曲线表示校正数据的估计分布。
3.实验分析
为了评估本文所提出模型的性能,本文提出了鱼类活动数据集。该文章是第一个提出了水下鱼类活动数据集。与现有的人类群体活动数据集相比,鱼类活动数据集面临更多挑战。 CAD和排球数据集中具有明确的动作意图和人体运动特征。然而,在水下环境中,鱼群可能会相互干扰和未吃完的饲料颗粒也对识别产生干扰。鱼的个体动作和群体活动相似且变化不大。例如,在鱼类加速和减速动作时,它们只需要轻微移动鱼鳍,这种变化是细微的。与人类的动作不同,人有明显的肢体运动变化。鱼类活动数据集可以准确反映鱼类在喂食前后的行为变化,有助于了解鱼类习性、生长状况、制定有效的管理策略提供技术支持。
表1和表2实验结果表明,GCVC的群体活动识别准确率为93.33%,Macro-F1为93.25%,分别比之前提高了19.21%和24.2%。通过使用GCVC,校正后的活动特征向量分布更加一致,并且数据粘连减少,模型可以实现更充分的监督学习。另外,本文探究每个鱼类个体行为与群体活动行为之间的关系,如图3所示。图3表明,本文所提算法能够准确反映个体鱼动作与群体活动之间的关系。
表1 6种不同算法间的Action_acc和Goup Activity acc比较结果
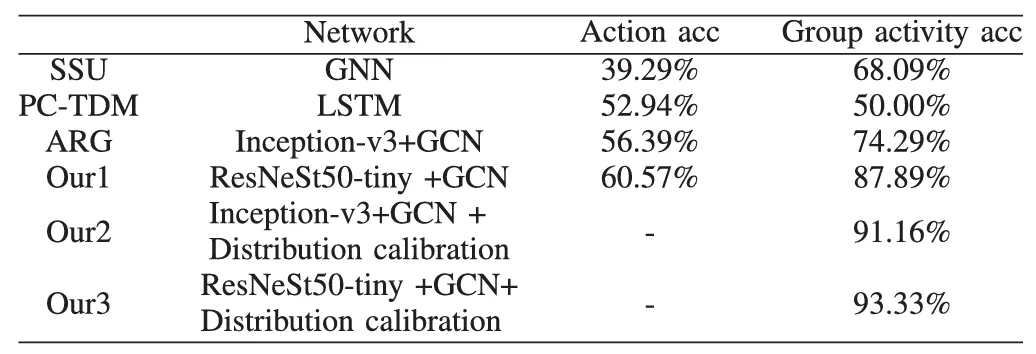
表2不同网络结构在鱼类活动测试集上的对比结果
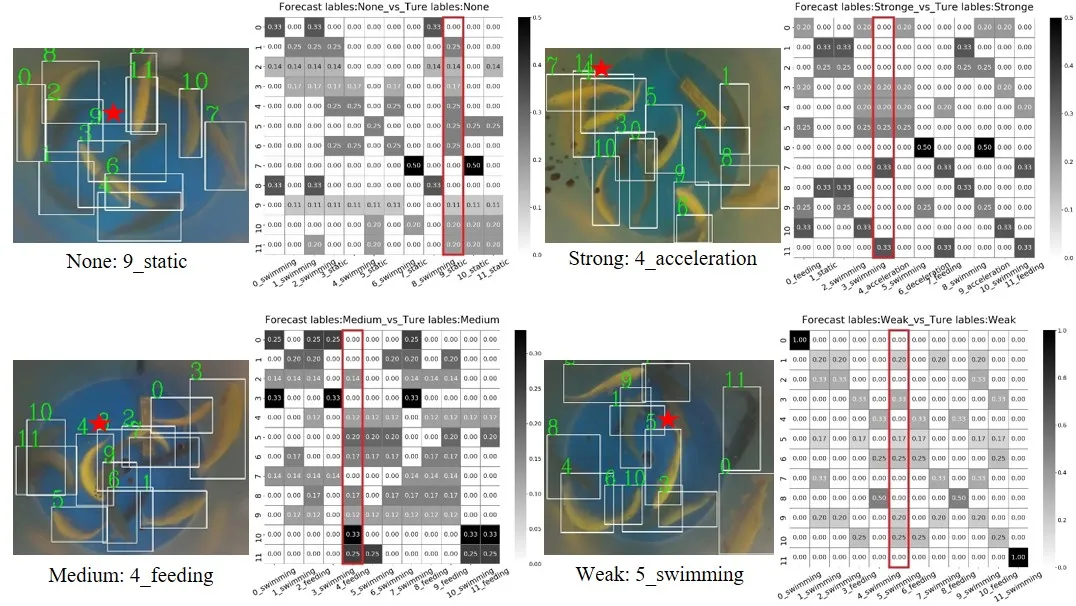
图3个体动作与群体活动关系可视化。每个例子左边的鱼类图片为输入帧,具有鱼类个体真实标记框和鱼类群组活动标签;右边为12个鱼类个体动作之间的关系图。横坐标为对应编号和真实动作标签,纵坐标为输入帧的鱼类个体编号;红色矩形框为该输入帧某个动作的行之和最大值,代表着关键的动作行为
02
Limb-Aware Virtual Try-On Network With Progressive Clothing Warping
作者:
张盛平1,韩潇宇1,张维刚1,蓝湘源2,姚鸿勋1,黄庆明3
单位:
1哈尔滨工业大学,2鹏城实验室,3中国科学院大学
邮箱:
s.zhang@hit.edu.cn;xyhan@stu.hit.edu.cn; wgzhang@hit.edu.cn;lanxy@pcl.ac.cn; h.yao@hit.edu.cn; qmhuang@ucas.ac.cn
论文:
https://ieeexplore.ieee.org/abstract/document/10152500
代码:
https://github.com/xyhanHIT/PL-VTONv2
1. 简介
虚拟试穿技术的目标是将一张服装图像迁移至一张人物图像上,在实现服装替换的同时,尽可能地保留其他区域的内容一致性。本文提出一个名为PL-VTON(Limb-Aware Virtual Try-On Network With Progressive Clothing Warping)的肢体感知虚拟试穿网络。如图1所示,该网络通过逐步执行可控的、细粒度的服装形变,以确保目标服装与人体姿态的对齐,随后服装形变结果在肢体感知切片的引导下与人物图像融合,在达到换装效果的同时保证了人物肢体等细节区域的真实性。
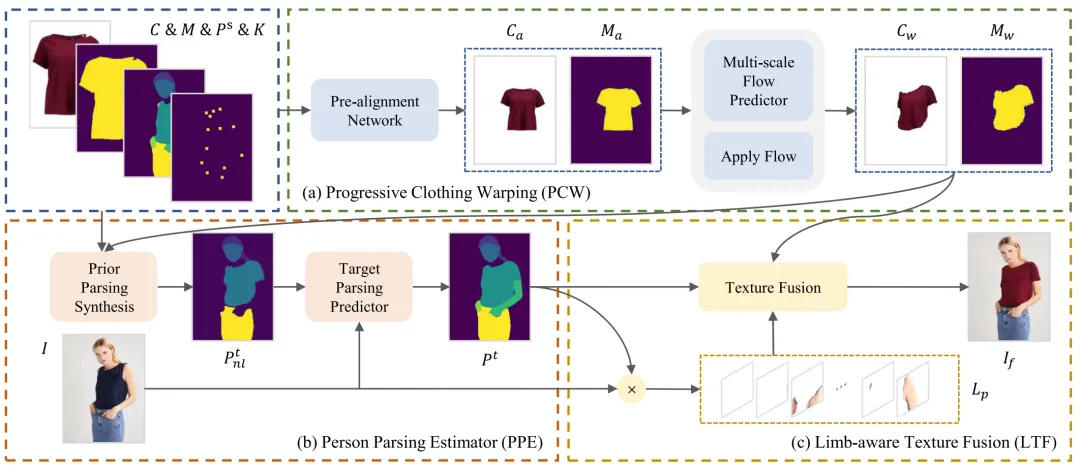
图1基于渐进式服装形变的肢体感知虚拟试穿网络PL-VTON
2. 方法
本文提出的方法共由三个子模块组成:渐进式服装形变(PCW)、人体解析估计(PPE)以及肢体感知纹理融合(LTF)。
渐进式服装形变(PCW):PCW模块采用两阶段对齐策略,首先通过预对齐网络对目标服装的位置和尺寸进行显式建模,然后使用多尺度流估计器来预测目标服装的像素级几何形变。在此过程中,为了更贴近人体穿衣的真实情况,我们还引入了一种重力感知损失,通过构建一个基于位置的渐变掩膜,调整形变网络对服装不同区域的监督权重,从而更好地处理衣服边缘并使形变结果更加真实。
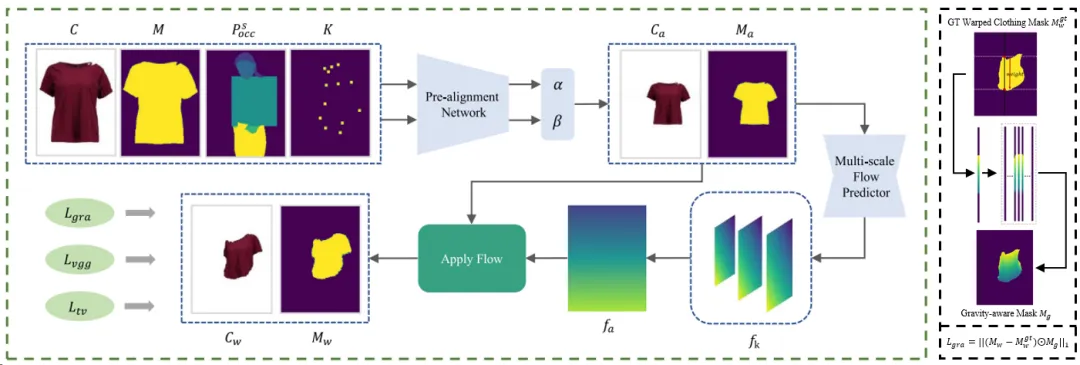
图2渐进式服装形变模块
人体解析估计(PPE):如图3(左)所示,PPE模块的主要作用是预测人穿着目标服装时的解析图,为后续的肢体纹理提取和试穿结果的生成提供位置信息,在该过程中我们引入了含有形变服装信息的非肢体目标解析图来保证预测过程的平滑过渡。
肢体感知纹理融合(LTF):在得到形变服装和目标人体解析结果后,LTF模块在肢体感知切片的引导下执行由粗到细的纹理融合过程。如图3(右)所示,首先根据形变服装、原人物图像以及目标人体解析图得到一个预试穿结果。随后,提取人物图像中的肢体部分,将其切分并在通道维度重新连接,形成一组肢体感知切片。然后,我们将预试穿结果进一步编码,并将肢体感知切片作为额外一路,在去除低维空间特征的情况下通过一个特征关联模块将两路的编码结果在高阶位置融合,最后对融合结果上采样,得到最终的试穿结果。
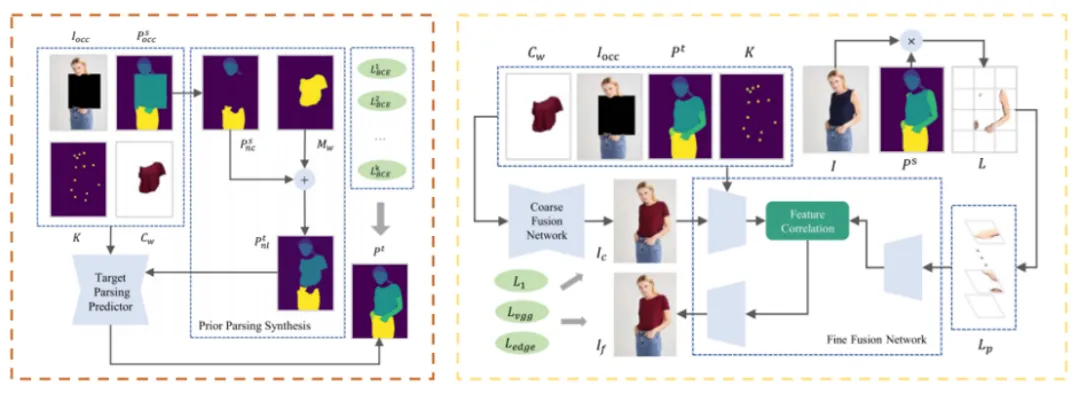
图3人体解析估计模块(左)与肢体感知纹理融合模块(右)
3. 实验
本文主要在VITON、MPV、VITON-HD以及Dress Code四个数据集上进行了实验。首先,图4展示了不同方法在VITON数据集上的定性结果对比。我们选取了长袖换短袖、短袖换长袖、复杂纹理换装、复杂人体姿势换装等多种不同的样例进行测试。通过对比可以发现,PL-VTON可以产生更加准确的服装形变结果以及真实的肢体纹理细节,从而更好地应对大多数情况下的虚拟试穿任务。

图4 在VITON数据集上的定性结果对比
图5展示了PL-VTON在VITON-HD和Dress Code数据集上的定性结果,这些结果表明了我们的方法在面对各种风格的服装和不同的人物图像时具有出色的鲁棒性和泛化能力。

图5在VITON-HD数据集(左)和Dress Code数据集(右)上的定性结果展示
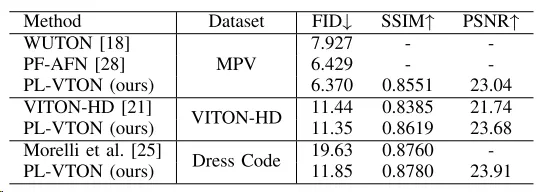
最后,表1、表2分别展示了各方法在不同数据集上的定量结果对比,可以看出,相比于现有方法,PL-VTON 在各个数据集上均取得了更好的指标。
表1 在VITON数据集上的定量结果对比
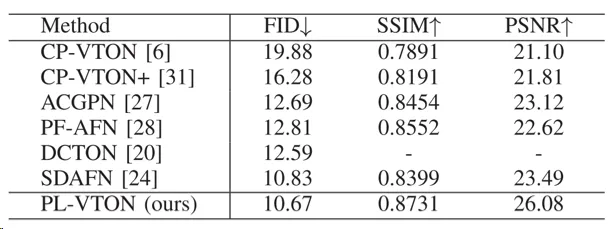
表2 在MPV、VITON-HD以及Dress Code数据集上的定量结果对比
03
Self-Supervised Intra-Modal and Cross-Modal Contrastive Learning for Point Cloud Understanding
用于点云理解的自监督模态内和跨模态的对比学习
作者:
武越1,刘家铭1,公茂果2,公沛然1,范晓龙2,秦凯3,苗启广1,马文萍4
单位:
1西安电子科技大学计算机科学与技术学院,2西安电子科技大学电子工程学院,3斯威本科技大学计算机科学和软件工程系,4西安电子科技大学人工智能学院
邮箱:
ywu@xidian.edu.cn;
ljm@stu.xidian.edu.cn;
gpr@stu.xidian.edu.cn;
fanxiaolong@outlook.com;
kqin@swin.edu.au;
qgmiao@xidian.edu.cn;
wpma@mail.xidian.edu.cn;
gong@ieee.org
论文:
https://ieeexplore.ieee.org/document/10147273
代码:
https://github.com/liujia99/CrossNet
1.研究背景
深度学习研究的主要驱动力是表征学习。回顾之前使用大量数据和覆盖注释来训练网络的基本思想,我们发现即使只有少量数据甚至没有注释,也可以训练网络。这种现象的一个重要设置是预训练阶段是自我监督的,这实际上打开了具有无限训练集大小并实现令人满意的结果的可能性。同时,自监督预训练在自然语言处理和二维视觉中的成功也推动了其在三维视觉中的应用。
然而,类似于投影然后重建的自动编码器方法大多使用变换后的点云之间的对比学习来进行自我监督,由于缺乏注释和其他有效的支持信息,导致性能有限。因此,我们希望基于未标记的数据找到其他支持信息,不同数据模式的存在引起了我们的注意。
受融合多模式自监督学习的启发,我们提出了CrossNet,旨在通过研究深度学习中的自监督预训练和监督微调来推进点云理解,如图1所示。我们的基本思想是捕捉3D点云和2D图像之间的对应关系,在满足点云自对比学习的条件下,可以进一步学习亚稳态点云表示。
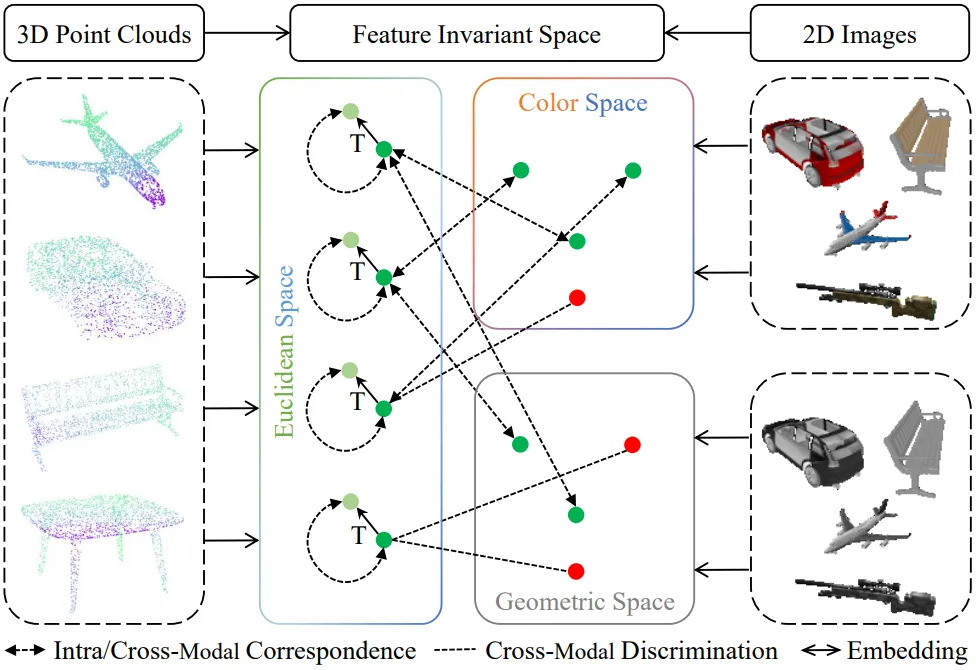
图1 CrossNet示例。给定呈现的3D点云及其2D图像,在特征空间中实现3D到2D的对应。注意,2D图像是从3D点云直接渲染的。
2.方法概述
本文所提方法简单且高效:我们分别向点云和图像分支添加特征提取模块和投影头模块,以自监督的方式训练主干网络。网络预训练后,只保留点云特征提取模块即可对下游任务进行微调并直接预测结果。
模态内对应学习。如图2(上)的点云分支所示,给定一个输入的3D点云,我们构建其增强版本和。这里和是使用点旋转、缩放和平移的变换的随机组合,以及包括抖动、归一化和弹性失真的空间变换。理论上,在同一个世界坐标中有两个视图和对齐,我们需要计算这两个视图之间的对应映射。如果存在,则点和点是跨越两个视图的一对匹配点。
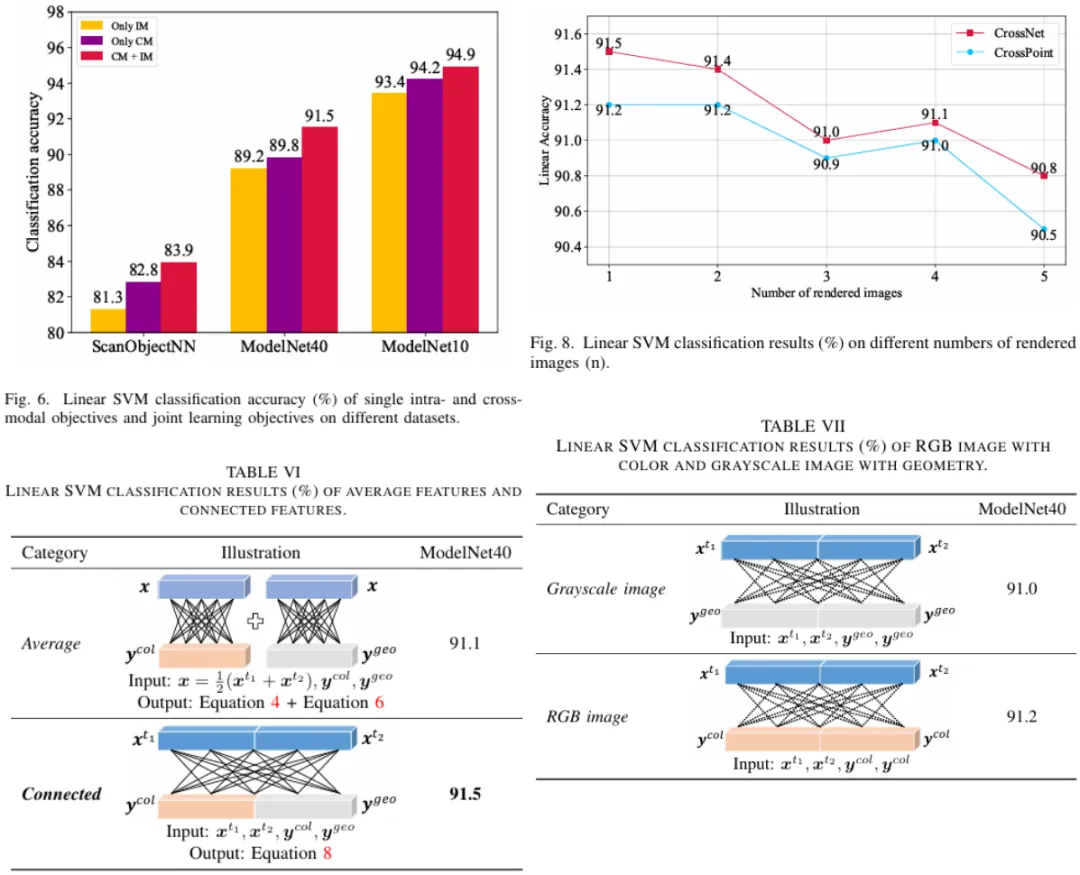
跨模态对应学习。除了点云的模态内对应关系,我们还旨在引入点云和图像之间的跨模态对应关系来学习判别特征,从而使不具有颜色和几何特征的点云能够表现出更好的学习能力。我们试图通过连接特征而不是平均特征的方式来研究跨模态对应关系,选择这样做的原因如下:1)在没有任何先验知识处理的情况下直接平均特征可能会削弱其在高维特征空间中的泛化能力,并且容易出现冗余;2)由于颜色和几何图像特征不共享权重,因此在将连接输入损失学习网络后,更容易捕获点云和图像之间的更多潜在联系。
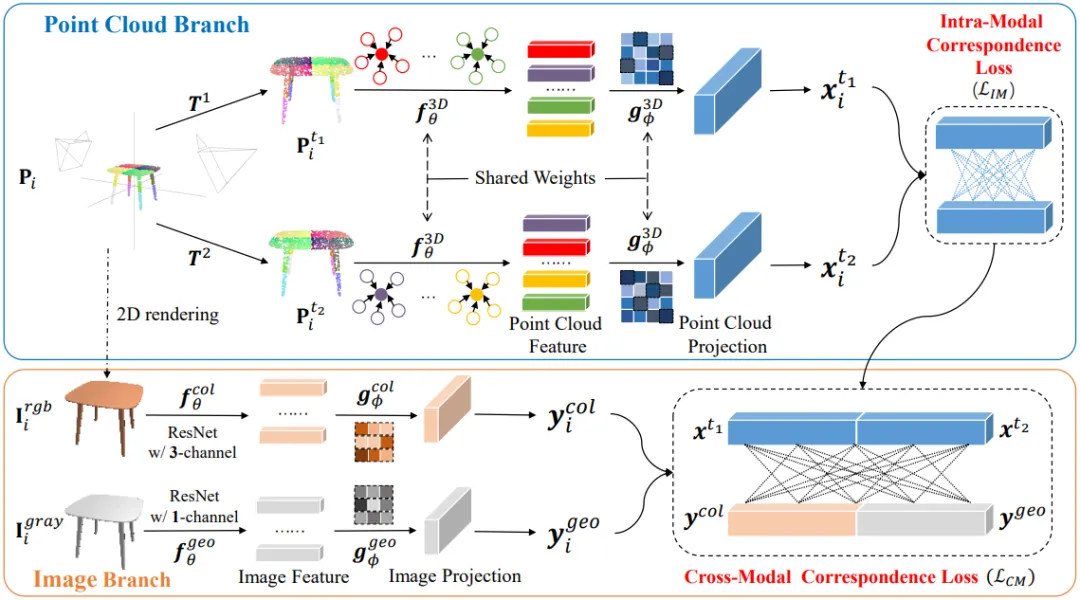
图2 CrossNet框架。它由两个分支组成,即:点云分支,通过选择给定点云的两个随机角度,然后增强所施加的不变性,来评估点云模态内的对应性;图像分支,通过在连接的点云原型特征和渲染的图像原型特征之间引入对比损失来形成跨模态对应。
3.实验分析
我们在多个基准上的实验证明了对点云分类和分割结果的改进,并且学习到的表征可以跨领域推广,包括(1)三维对象形状分类,(2)三维对象部分分割和(3)三维场景语义分割。
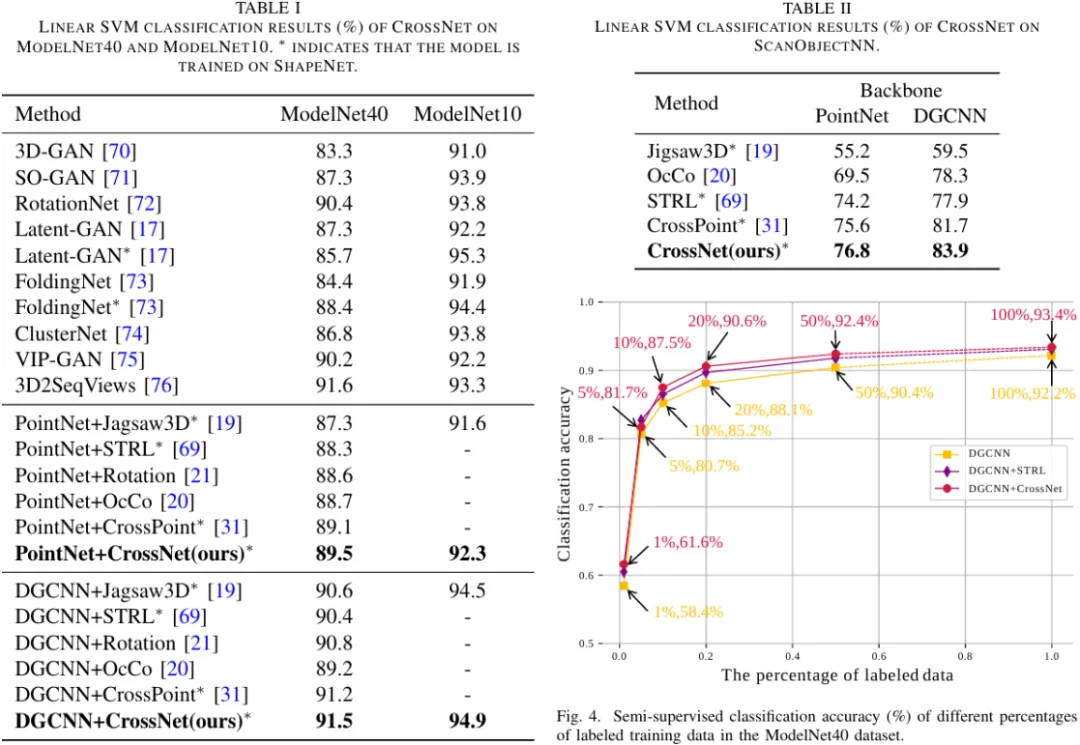
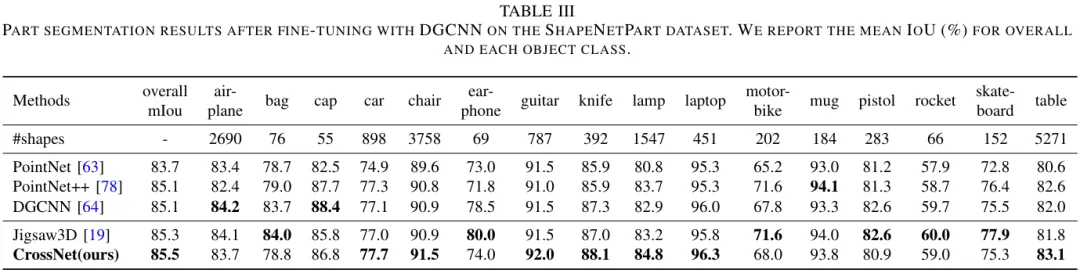

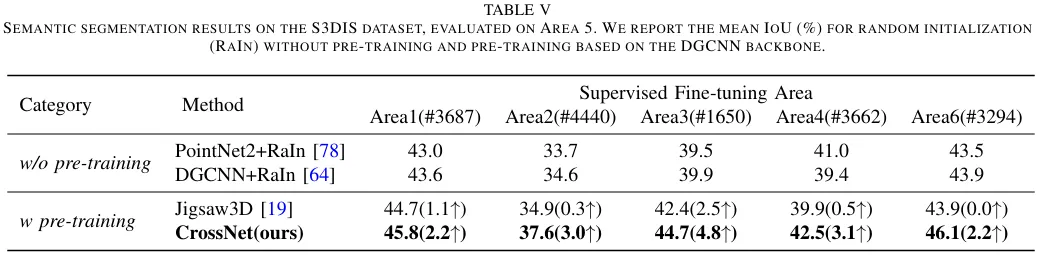
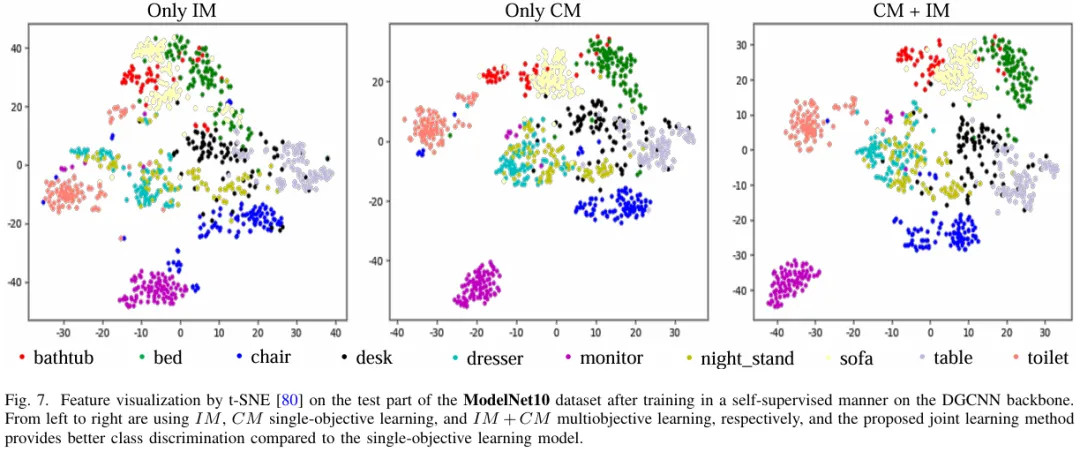
04
SGSR-Net: Structure Semantics Guided LiDAR Super-Resolution Network for Indoor LiDAR SLAM
作者:
陈驰*,金昂,王治邺,郑永伟,杨必胜,周剑,徐宇航,涂志刚
单位:
武汉大学测绘遥感信息工程国家重点实验室
邮箱:
chichen@whu.edu.cn;angjin@whu.edu.cn;zhiye.wang@whu.edu.cn;2016301610307@whu.edu.cn; bshyang@whu.edu.cn;jianzhou@whu.edu.cn;
yuhangxu@whu.edu.cn; tuzhigang@whu.edu.cn
论文:
https://ieeexplore.ieee.org/abstract/document/10164213
*通讯作者
1.简介
激光雷达通过离散的3D点云对现实世界进行采样,已成为自主机器人的主要且必不可少的3D传感器。为了确保表面点的精确采样,高线数激光雷达(例如Ouster OS0-128)通常用于收集机器人任务的密集点云,包括对象检测和跟踪、同时定位与制图(SLAM)。然而,此类传感器的高成本和大体积/重量/能耗限制了它们在更广泛的场景中的使用,例如有效载荷有限的小型无人机/UGV。现有的点云超分辨率研究没有考虑场景的几何语义,导致下游子任务(例如SLAM)的超分辨率点效果不够理想。因此,本文提出了SGSR-Net,一种结构语义引导的多线束激光雷达点云超分辨率网络。
2.方法
SGSR-Net通过垂直空间注意力和通道注意力增强CNN模型,并与蒙特卡罗滤波相结合,从稀疏范围图像输入中生成密集且具有结构感知的点云。首先,提出一种注意力机制引导的编码器-解码器深度神经网络来生成超分辨率粗点云;其次,通过快速结构分割检索室内场景布局。粗点云通过蒙特卡罗Dropout进行细化,并通过具有结构语义的逻辑池进行自适应阈值选择,生成针对室内LiDAR-SLAM优化的超分辨率点。
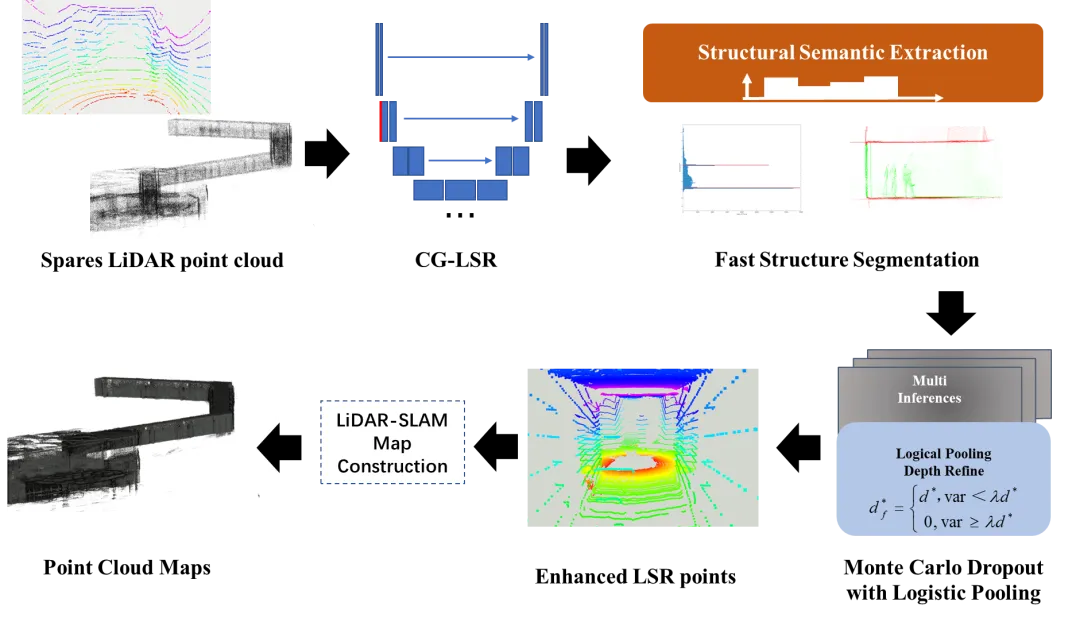
图1 SGSR-Net方法流程图
3.实验
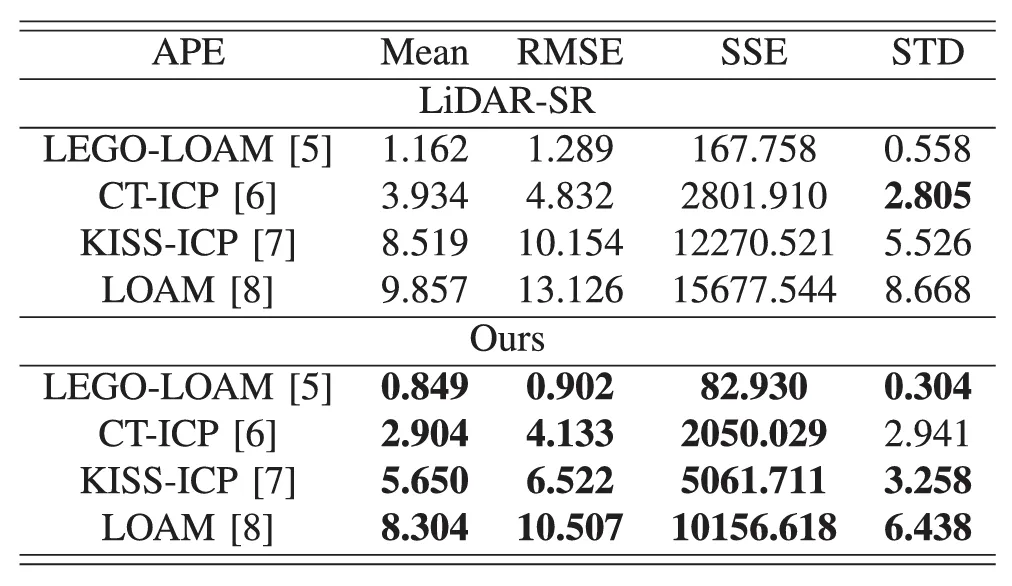
SGSR-Net使用配备多个多线束激光雷达的UGV收集的数据集进行验证。结果表明,与SOTA方法相比,所提出的CGLSR(CASE Attention Guided Encoder-Decoder LiDAR Super-Resolution Network)点云超分辨率网络,将超分辨率点的MAE降低了12.4%,降至0.177m。SGSR-Net生成的超分辨率点的室内SLAM结果表明,绝对位姿误差(APE)的均值和RMSE分别下降了27%和30%,分别降至0.849m和0.902m,这显着改善了LiDAR-SLAM系统的室内SLAM性能和稳定性(即LeGO-LOAM)。SGSR-Net按照雷达扫描线排列生成超分辨率点,并保留由传感器生成的原始深度图像定义的空间分区。SGSR-Net与SLAM算法无关,可以作为激光雷达点输入插入任何LiDAR里程计/SLAM系统(例如LOAM、LeGO-LOAM、CT-ICP)。


图2超分辨率结果与真值比较
表1最大漂移和相对误差性能
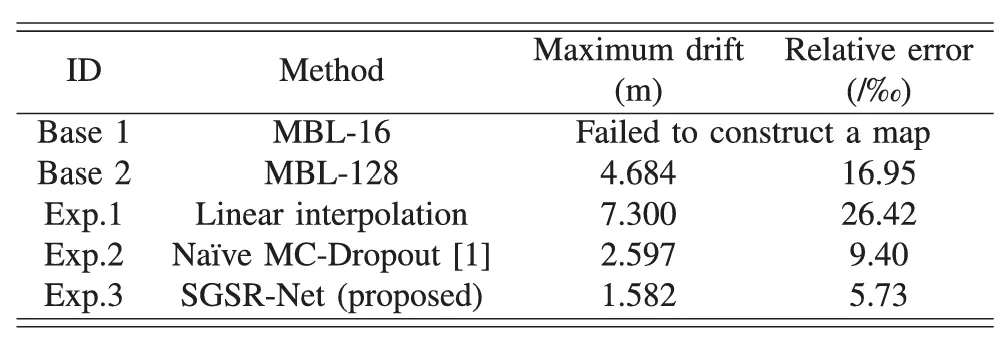
表2不同激光雷达SLAM方法的APE定量评价
05
Privileged Modality Learning via Multimodal Hallucination
作者:
韦仕才,骆春波*,罗杨,徐加朗
单位:
电子科技大学
邮箱:
shiciawei@uestc.edu.cn;c.luo@ieee.org
论文:
https://ieeexplore.ieee.org/abstract/document/10146467
代码:
https://github.com/shicaiwei123/TMM-MMH
* 通讯作者
1.研究背景和动机
近些年,多模态学习技术因其卓越的性能和鲁棒性受到了越来越多的关注,并在多个领域取得了显著成果,如医疗图像分析、动作识别和面部反欺诈。已有的多模态方法大都假设所有的训练数据在训练和测试阶段是可获取。然而,实际应用场景中,由于设备限制或用户隐私等因素,在模型推理阶段可能很难获取完整的多模态信息。因此,如何利用仅在训练阶段获取的特权模态(privileged modality)信息来辅助多模态模型的优化成了多模态学习领域的重要挑战。当前的方法主要关注训练一个幻觉网络(Hallucination network)从可用模态中恢复特权模态信息,然后进行信息的后融合 (图1 上)。这类方法简单有效,但是忽略了模态间丰富的跨模态交互信息,同时,这些方法也并没有利用好已有的基于完整数据训练的多模态模型,带来了算力资源的浪费。
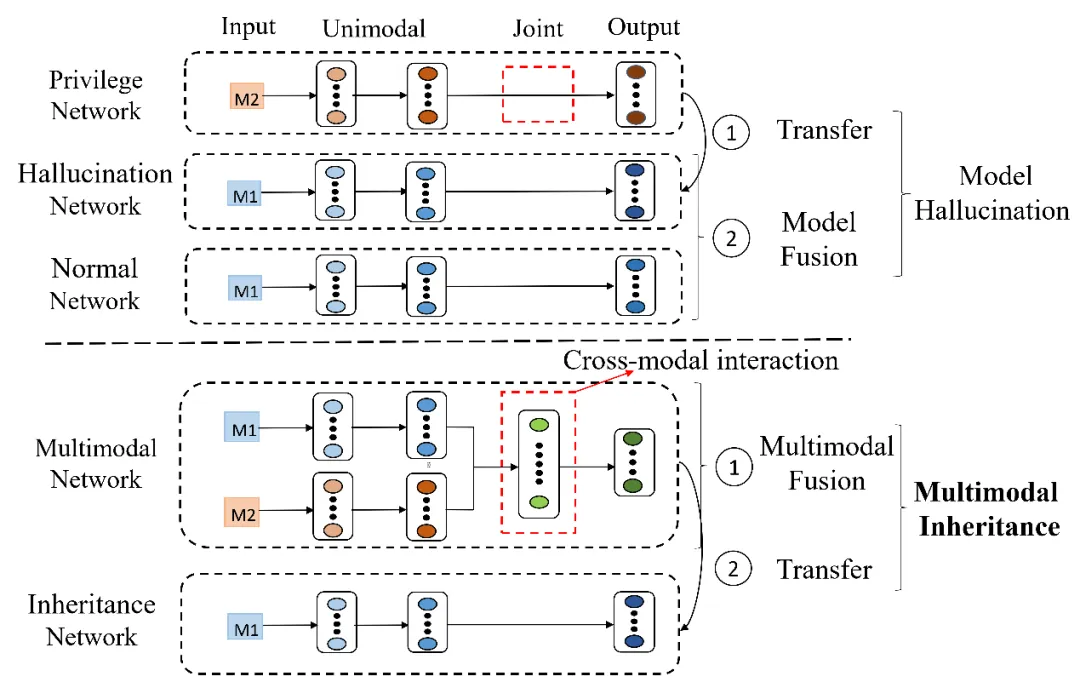
图1传统模态幻觉框架(上)和提出的多模态幻觉框架(下)
2.方法细节
为此,本文提出了一种名为多模态幻觉(MMH)的新框架,通过将完整多模态信息传递给仅具有不完全模态输入的幻觉网络,从而实现完整模态和缺失模态的关联,同时保留关键的多模态交互信息(图1下)。此外,还提出了两种策略来应对输入和网络结构差异所带来的优化挑战。具体流程如下所示:
(1)预训练完整多模态模型:使用完整的多模态数据集训练一个多模态模型,以提取完整的跨模态信息。
(2) 训练幻觉网络:针对只能获取部分模态数据的场景下,训练一个幻觉网络。这个网络以可获取模态为输入,利用提出的区域感知蒸馏(RAD)和差异感知蒸馏(DAD)从预训练的多模态模型中学习获取跨模态交互信息的信息。 区域感知蒸馏策略:将多模态网络在多个区域上的响应知识传递给幻觉网络,以指导幻觉网络关注对分类任务有意义的区域。差异感知蒸馏策略:使幻觉网络学习多模态网络中样本表示之间的局部差异,从而获得由多模态线索精炼的类间判别信息。
(3)在目标场景下推理:使用训练好的幻觉网络在只有部分模态数据的实际场景下进行推理。
3.试验结果与分析
表1与当前最优方法在CASIA-SURF和CEFA-SURF数据集上的活体检测任务对比结果
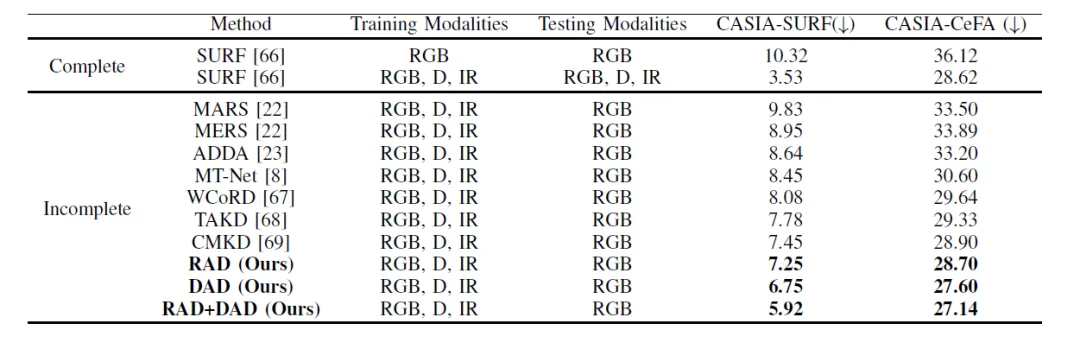
表2与当前最优方法在HMDB51和UCF101数据集上的动作识别任务对比试验

表1和2展示了所提出的方法在不同任务,不同数据集和模态组合上,都能取得SOTA的效果。

编辑人:吴建龙、任文琦
专委会责任副主任:张勇东

微信扫一扫
关注该公众号
 京公网安备11010802017125号
京公网安备11010802017125号