
【论文导读】2024年论文导读第十一期
【论文导读】2024年论文导读第十一期
CCF多媒体专委会 2024年06月04日 09:30 北京


论文导读
2024年论文导读第十一期(总第一百零二期)
目 录
|
1 |
Modeling Multiple Aesthetic Views for Series Photo Selection |
|
2 |
DiscrimLoss: A Universal Loss for Hard Samples and Incorrect Samples Discrimination |
|
3 |
Flow Guidance Deformable Compensation Network for Video Frame Interpolation |
|
4 |
Resolving Zero-Shot and Fact-Based Visual Question Answering via Enhanced Fact Retrieval |
|
5 |
CGLF-Net: Image Emotion Recognition Network by Combining Global Self-Attention Features and Local Multiscale Features |
01
Modeling Multiple Aesthetic Views for Series Photo Selection
为系列照片选择建模多种美学视图
作者:
黄瑾1,宫永顺1*,张璐2,张健3,聂礼强4,尹义龙1*
单位:
1山东大学、2昆士兰大学、3悉尼科技大学、4哈尔滨工业大学(深圳)
邮箱:
jinhuang.mla@gmail.com
ysgong@sdu.edu.cn
ylyin@sdu.edu.cn
论文:
https://ieeexplore.ieee.org/document/10168263
*通讯作者
1.研究背景和动机
图像美学质量评价(Image Aesthetic Quality Assessment, IAQA)的目标是自动评估图像在视觉上的美感。而系列照片选择(serial photo selection, SPS)是图像美学质量评价的一个重要分支,它侧重于在一系列几乎相同的照片中识别最佳图像。然而,现有方法通常只关注从原始图像中提取特征,忽略了图像的多视图可能蕴含的更为丰富的美学信息(如图1所示,传统的图像美学评价方法若仅依赖深度卷积网络提取特征,则对于相似的图像通常给出相近的评分,从而导致结果缺乏实际参考价值。)。其次,传统的卷积神经网络(CNN)由于感受野的限制,难以捕获图像的全局信息(如图2所示)。综上,图像的美学评价是一个主观且多维度的过程,它涉及到图像的多个方面,如构图、色彩、光影、纹理等,仅基于单一特征的评估方法往往难以全面反映图像的美学特性。此外,不同的观察者可能会从不同的角度和视角来评价图像的美学质量,这些不同的视图之间既存在一致性也存在互补性。因此,如何有效地融合不同视图的特征,并考虑它们之间的空间相关性,是提高图像美学评估准确性的关键。

图1 系列照片选择任务
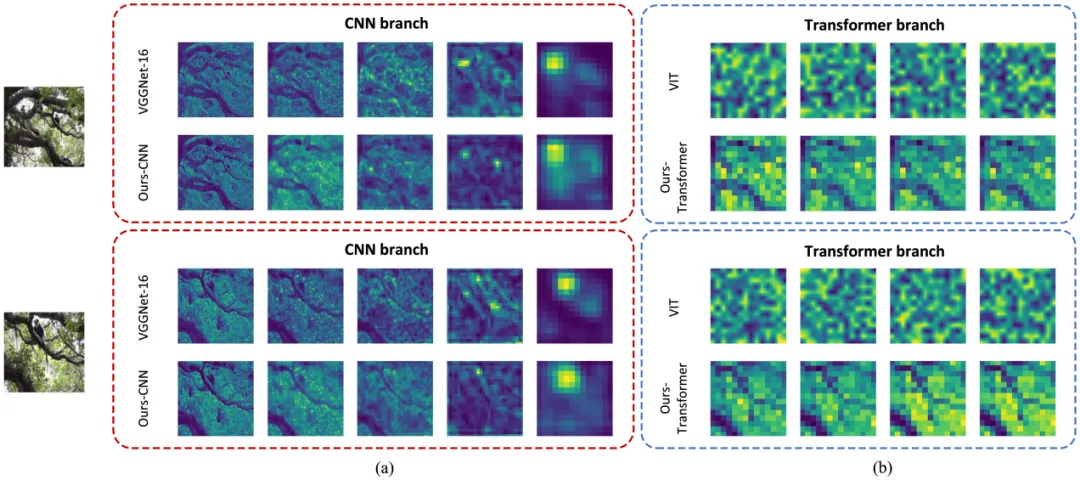
图2 卷积特征与transformer特征的可视化对比
2. 研究方法
本研究提出了基于多视图图学习的系列照片选择方法(SPSNet),如图3所示。该方法的核心思想是利用图结构来表示不同特征视图间的关系,并通过图学习方法挖掘这些视图之间的内在关联和互补性。首先,使用特征提取器将同一图像的不同特征视图(包括传统、通用和深度特征)统一处理为多视图特征。然后,为了进一步加强不同视图之间信息的一致性,提出了一个基于自适应加权自注意力模块的多视图协同融合策略。该策略能够自适应地调整不同视图的权重,使得在融合过程中能够充分考虑各个视图的重要性。最后,设计了一个图结构,其中节点代表不同的特征视图,边则通过计算视图之间的相似性来构建。通过这种方式能够有效地表达不同视图之间的关系,从而更好地理解图像的整体美学特性。
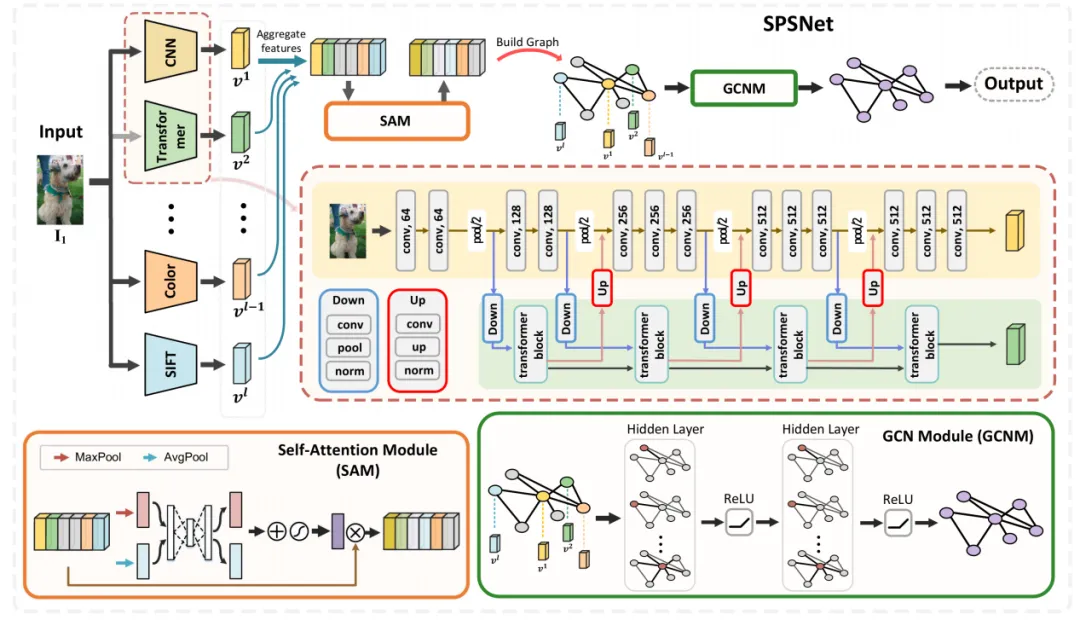
图3 研究方法总体框架图
3. 实验分析
为验证SPSNet的性能,本文与基线方法进行了对比,通过图像对分类准确率评估其表现,如表1所示。图4展示了卷积与Transformer特征的可视化结果,经特征耦合学习后,所得表征对细微差异的分辨能力有所提升。此外,本方法在图像美学质量评价研究中也展现出卓越性能,如表2所示。实验结果充分表明,该方法能有效区分细微审美差异,并精准提取图像中的关键审美特征。
表1 不同系列照片选择方法在Phototriage数据集上的比较结果
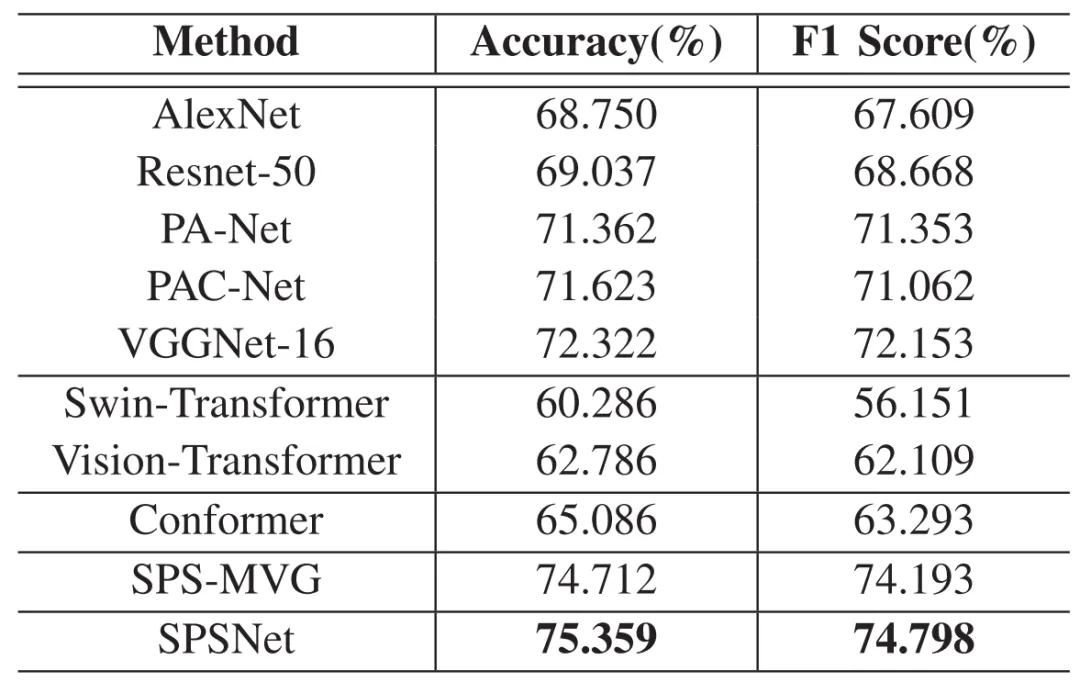
表2 本方法与现有图像美学质量评价方法在AVA数据集上的比较结果
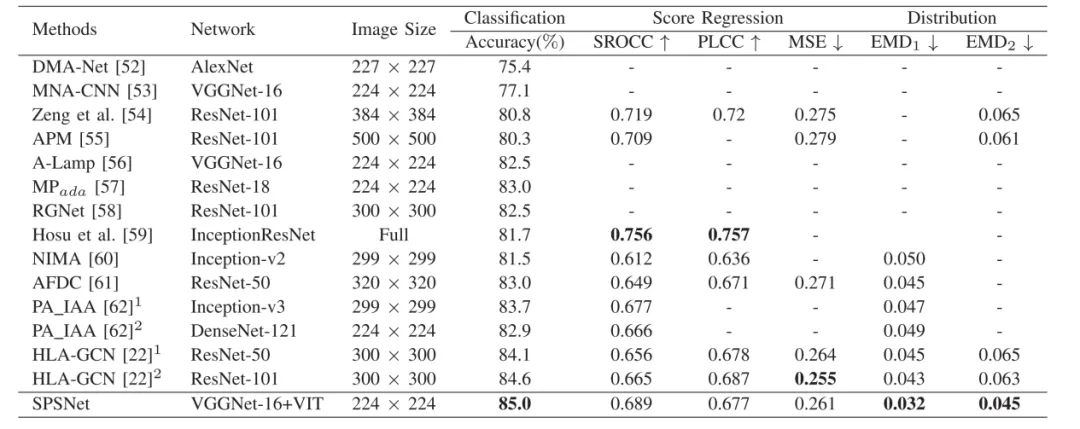
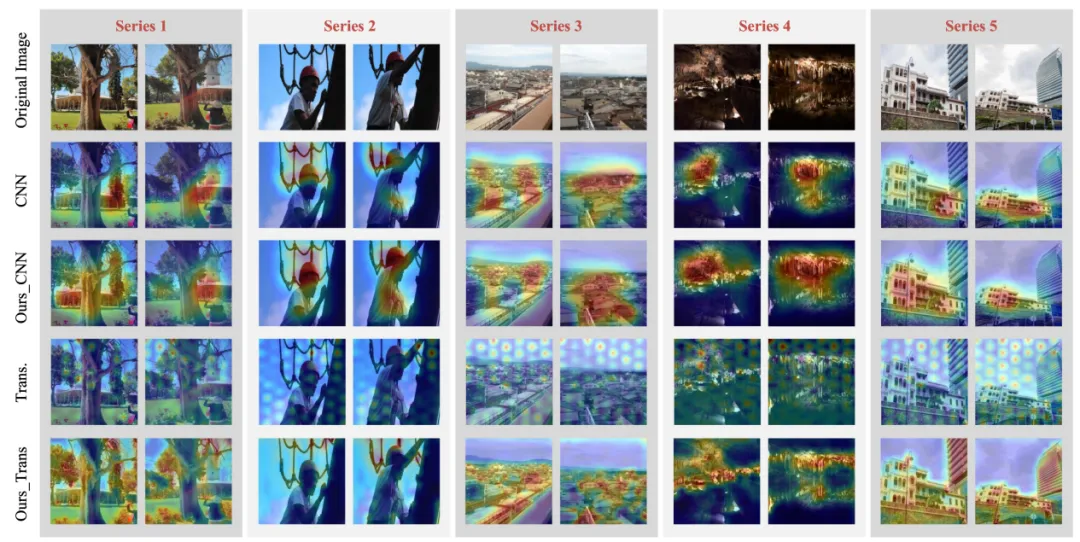
图4 特征可视化示例
02
DiscrimLoss: A Universal Loss for Hard Samples and Incorrect Samples Discrimination
作者:
吴婷婷1, 丁效1*, 张浩1, 高靖龙1, 唐旻骥1,杜理1,秦兵1,刘挺1
单位:
1哈尔滨工业大学
邮箱:
ttwu@ir.hit.edu.cn;xding@ir.hit.edu.cn;
zhh1000@hit.edu.cn;jlgao@ir.hit.edu.cn;
mjtang@ir.hit.edu.cn;ldu@ir.hit. edu.cn;
bqin@ir.hit.edu.cn;tliu@ir.hit.edu.cn
论文:
https://ieeexplore.ieee.org/abstract/document/10167857
代码:
https://github.com/tangminji/DiscrimLoss
*通讯作者
1.简介
给定带噪声标签的数据,深度神经网络会逐渐记住噪声标签并损害模型性能。为了缓解这一问题,课程学习按照样本从易到难等有意义的顺序对训练样本排序,提高模型性能与泛化性。经典的课程学习没有区分非简单样例(Difficult sample)中类别正确的困难样例(Hard sample)和错误样例(Incorrect sample),如图1所示。实际上,模型应该学习困难样例以促进泛化,而不应该过度拟合错误样例。

图1 简单、困难、错误样例。每个例子下方给定了参考标签,可能是带噪标签
为此,我们提出了一种名为DiscrimLoss的损失函数,旨在区分困难样例和错误样例,以提升模型在噪声数据上的泛化能力。如图2所示, DiscrimLoss 是一种阶段式的学习策略。在早期的训练阶段,我们通过区分简单样例和非简单样例(Difficult,它包括困难样例和错误样例)来提高模型的性能。当进入后面的训练阶段时,我们的目标是分离困难样例和错误样例,增强模型的泛化。这样,模型可以更充分地从正确样例(Clean,它包括简单样例和困难样例)中学习,避免记忆噪声标签。我们在图像分类、图像回归、文本序列回归和事件关系推理方面的多种噪声程度的实验上证明了该方法的通用性和有效性。
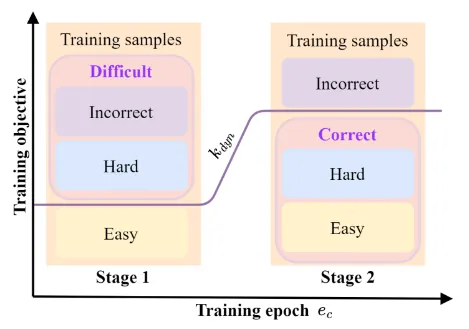
图2 DiscrimLoss两阶段学习策略
2.方法
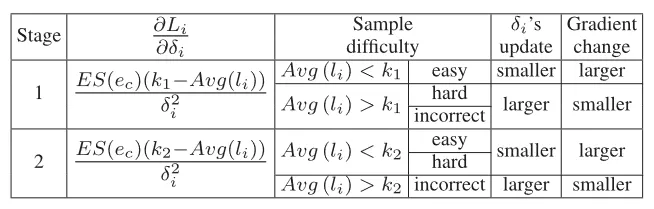
DiscrimLoss的核心思想是采用两阶段训练目标,通过自适应阈值实现不同训练阶段的切换。DiscrimLoss为每个样本分别维护权重,以实现对样本学习的侧重和抑制。为实现稳定样本权重估计,DiscrimLoss设计了早期线性抑制项Early Suppression和历史损失Historical Loss两个组件,分别抑制初始阶段的梯度更新和考虑样本损失的历史值。同时,我们根据小损失准则,用动态变化的阈值和历史损失的相对大小,区分当前阶段侧重学习的样本和抑制学习的错误样本,为他们的样本权重进行不同方向的更新。DiscrimLoss的数学公式如公式(1)所示,不同阶段样本权重和梯度变化更新的趋势如表1所示。我们用动态变化的阈值实现两阶段的过渡,如公式(2)所示,初始阈值, 为类别数,对应模型早期随机预测的期望损失。随着训练步数的增加,噪声样本的学习始终被抑制,困难样本由于和简单样本包含通用模式损失能和噪声样本产生一定差距,同时最终会增长到, 可以在最终阶段区分困难样本和噪声样本,以提升模型的泛化性并保持对噪声样本学习的抑制。
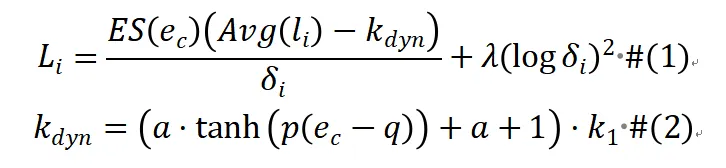
表1 不同阶段不同难度样本的权重因子和梯度变化的更新趋势
3.实验
我们在MNIST, CIFAR-10, CIFAR-100, Clothing1m的图像分类、UTKFace的图像回归、Digit SUM的文本序列回归和WIKIHOW的事件类型推理任务上开展了实验,表2和表3分别展示了在数据带噪的图像分类任务和事件类型推测任务上我们方法与现有基线性能的定量比较。实验结果显示,DiscrimLoss不仅提升了模型在干净测试集上的泛化性能,而且相较多个基准方法具有一致的增益。同时,相比传统的交叉熵损失,DiscrimLoss可以在训练后期显著区分困难样本和噪声样本,使得噪声样本在训练末期仍保持高损失的状态,如图3所示。这一成果验证了DiscrimLoss对硬样本和错误样本的有效区分,以及其在提升模型泛化能力方面的有效性和普适性。
表2 CIFAR-10,CIFAR-100不同标签噪声比率下测试集准确率
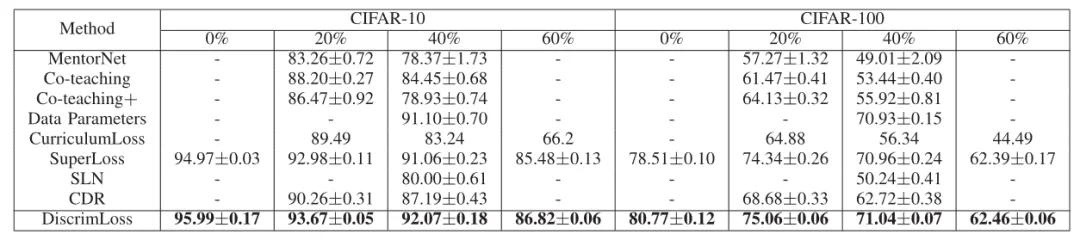
表3 WIKIHOW不同子任务下测试集准确率
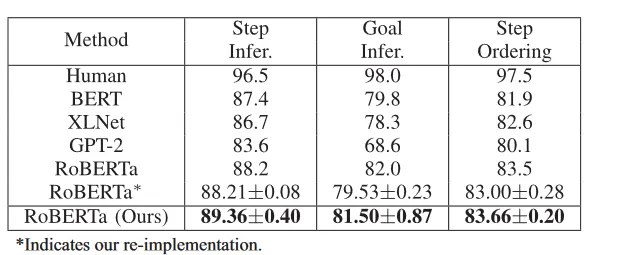
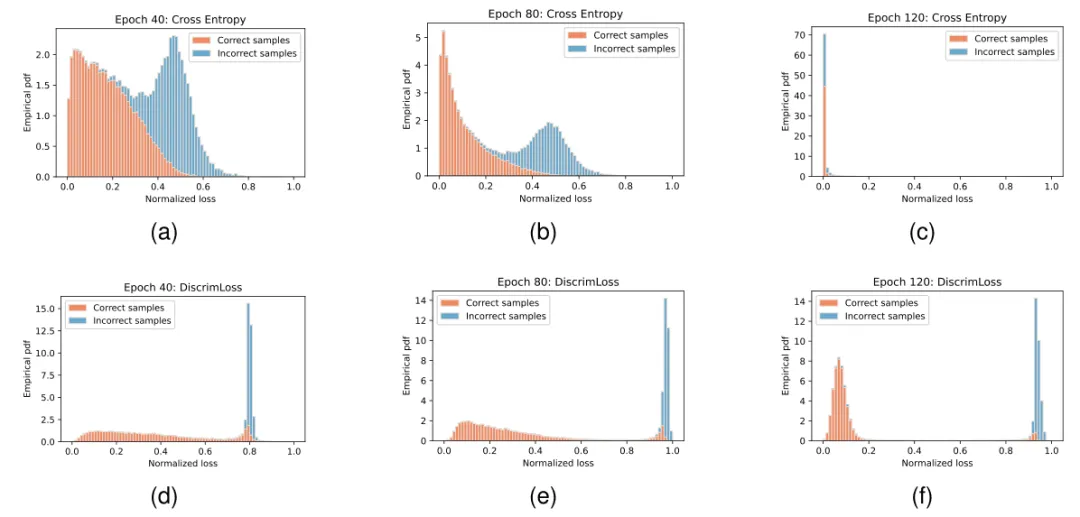
图3 CIFAR-100 40%噪声训练样本归一化损失分布。(a)(b)(c)为采用交叉熵训练第40、80、120epoch的损失分布,(d)(e)(f) 为采用DiscrimLoss训练第40、80、120epoch的损失分布
03
Flow Guidance Deformable Compensation Network for Video Frame Interpolation
作者:
雷鹏程1,方发明1,曾铁勇2,张桂戌1
单位:
1华东师范大学计算机科学与技术学院
2香港中文大学数学系
邮箱:
pengchenglei1995@163.com
fmfang@cs.ecnu.edu.cn
gxzhang@cs.ecnu.edu.cn
zeng@math.cuhk.edu.hk
论文:
https://ieeexplore.ieee.org/abstract/document/10164197
代码:
https://github.com/lpcccc-cv/FGDCN
1.引言
基于光流和基于变形卷积(DConv)的方法是解决视频帧插值(VFI)问题的两种主流方法。然而,基于光流的VFI方法往往存在光流图估计不准确的问题,特别是在处理复杂和不规则的真实运动时;基于DConv的VFI方法在处理复杂运动方面具有优势,但其自由度的增加使得DConv模型的训练变得困难。为了解决这些问题,本文提出了一种用于VFI任务的光流引导可变形补偿网络(FGDCN)。FGDCN将中间帧采样过程拆解为两步:光流估计和可变形补偿。具体来讲,光流估计阶段利用粗到细的光流估计网络直接估计中间流动,同时合成粗的中间帧。在第一步学习到的光流先验的指导下,我们在可变形补偿阶段设计了一个金字塔形可变形补偿网络来补偿光流步骤中缺失的细节。
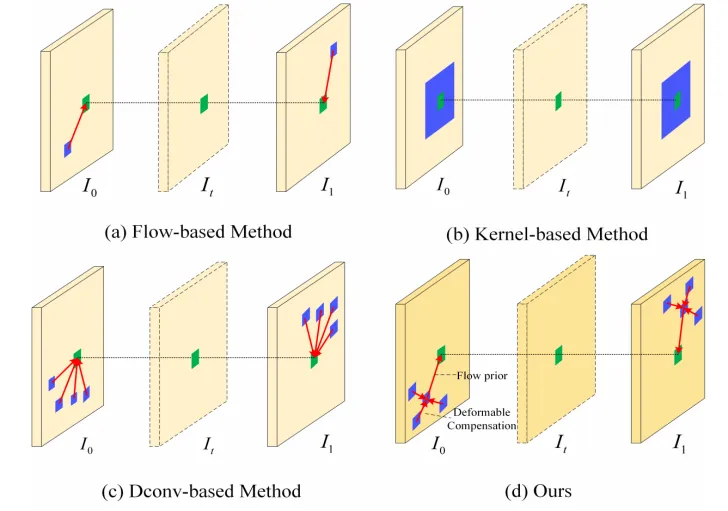
图 1 不同VFI方法采样模式对比。(a)基于光流估计的方法;(b)基于内核估计的方法;(c)基于可变形卷积的方法;(d)本文提出的光流引导可变形补偿的方法
2.方法介绍
我们所提出的模型总体流程图如图2所示。它包含一个光流估计步骤和一个可变形补偿步骤。
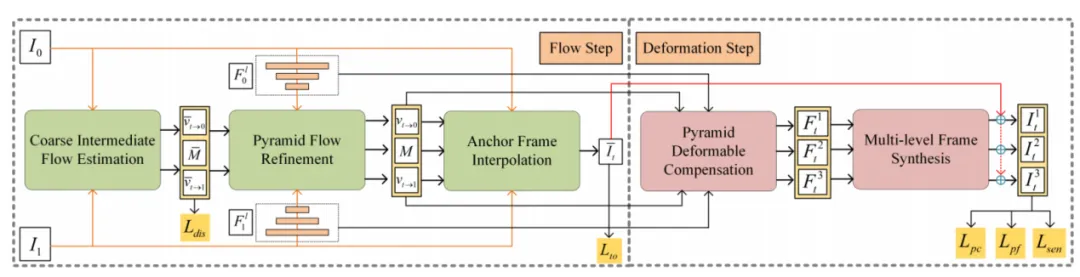
图2 FGDCN总体流程图
1、Flow step
光流估计步骤旨在估计准确的流程图并同时估计出临时的中间帧。光流步由粗中间流估计模块、金字塔流细化模块和中间帧插值模块组成。该阶段我们利用两个损失函数,弱监督流量估计损失和面向任务的光流估计损失来估计由粗到细中间帧光流。
2、Deformation step
基于光流估计的方法经常受到光流估计不准确的问题,仅对图像或特征进行流变形无法处理大的运动和复杂的场景。为了解决这个问题,我们设计了一个变形步骤来补偿流步骤中缺失的细节。如图3所示,该步骤包含一个金字塔变形补偿网络(PDCN)和一个多级框架合成网络(MFSN)。与以往基于DCN的直接检测完整运动的VFI方法不同,我们的PDCN通过在流步中使用学习到的流先验作为指导,减少了偏移学习的负担。这种策略不仅使DConv层更具可训练性,而且有助于挖掘更详细的信息。该部分由金字塔内容损失、频率损失和census loss进行联合监督训练。
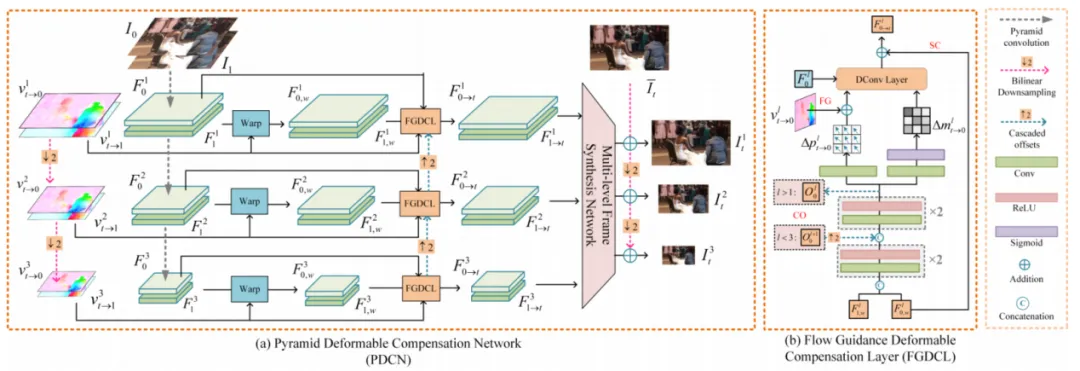
图3 我们提出的金字塔可变形补偿网络
3.实验结果
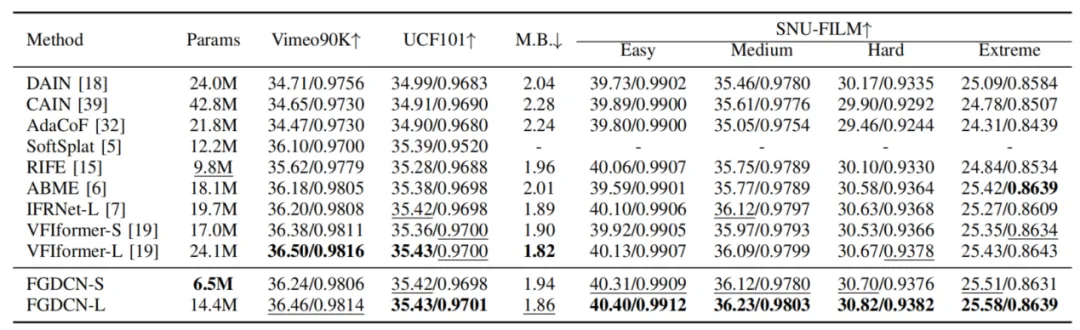
我们在Vimeo90K、UCF101、Middlebury和SNU-FILM四个公开数据集上测试我们模型的性能。图4所示的消融实验结果表明,所提出的光流引导可变形补偿策略可以有效有提升模型对复杂运动估计的准确性。表1的定量结果比较表明我们的方法能以更少的参数量,获得比现有最先进方法更优的视频插帧结果。

图4 我们提出的光流引导可变形补偿策略对运动估计及视频插帧结果的影响
表1 不同VFI重建方法参数量及性能(PSNR/SSIM)对比
04
Resolving Zero-Shot and Fact-Based Visual Question Answering via Enhanced Fact Retrieval
作者:
吴森、赵国帅、钱学明
单位:
西安交通大学
邮箱:
guoshuai.zhao@xjtu.edu.cn
论文:
https://ieeexplore.ieee.org/document/10163831
代码:
https://github.com/onexphe/RZF-VQA
数据集:
FVQA: https://github.com/wangpengnorman/FVQA
ZS-F-VQA:https://github.com/China-UK-ZSL/ZS-F-VQA
1.引言
视觉问答(Visual Question Answering,VQA)是一种结合自然语言处理与计算机视觉领域的先进技术于一体的智能系统,它能够依据给定图像及其相关问题中的视觉特征和文本描述,精准地推断出与图像内容紧密契合的答案。 然而,视觉问答系统尚存几大待攻克难题:首要问题是如何在零样本条件下针对数据集中未出现过的答案进行合理推理。其次,在利用外部知识辅助推理的过程中,由于外部知识库中实体和关系的规模庞大,准确检索关系和实体成为一个性能瓶颈,对下游任务效果产生显著消极影响。为此,本研究提出一种新型的基于外部知识的零样本 VQA 模型,其主体思路如图1所示,该方法旨在通过高效检索知识库中的元素,优化并提升模型在无先验实例学习下的泛化能力。
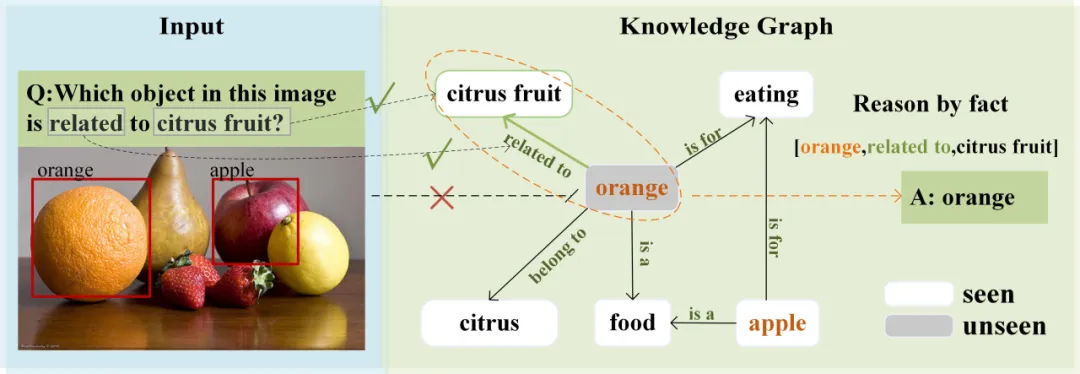
图1 研究思路示意图
2.方法
本文提出的方法结合预训练模型与知识图谱技术,旨在提升输入信息的表达能力和信息聚合能力,以减轻错误级联效应,并利用零样本学习策略应对未见问题。本文所提出方法框架如图2所示,该方法主要包含三个模块:第一个模块为输入表示(Input Representation)模块,负责将文本信息与图像信息分别投射到三个特征空间内,形成输入信息在特征空间内的表示形式。第二个模块为事实提取(Fact Extraction)模块,通过在三个特征空间中比较输入信息与知识图谱中各集合元素的相似度,获取集合元素与输入间的相似度分数分布。第三个模块为推理(Reasoning)模块,负责将来自关系域与实体域的信息聚合至答案推理流程。
该算法利用特化的预训练模型以生成输入信息的高质量表示,并在对比学习框架下构造统一特征空间以实现外部事实的高效检索。通过这种方式,算法成功加强了从知识库中精准抽取实体和关系的能力,并有效降低了级联错误给下游任务带来的负面影响。同时进一步引入了一种基于知识图谱的加权分数策略,用以有效聚合来自实体与关系集合内的信息。
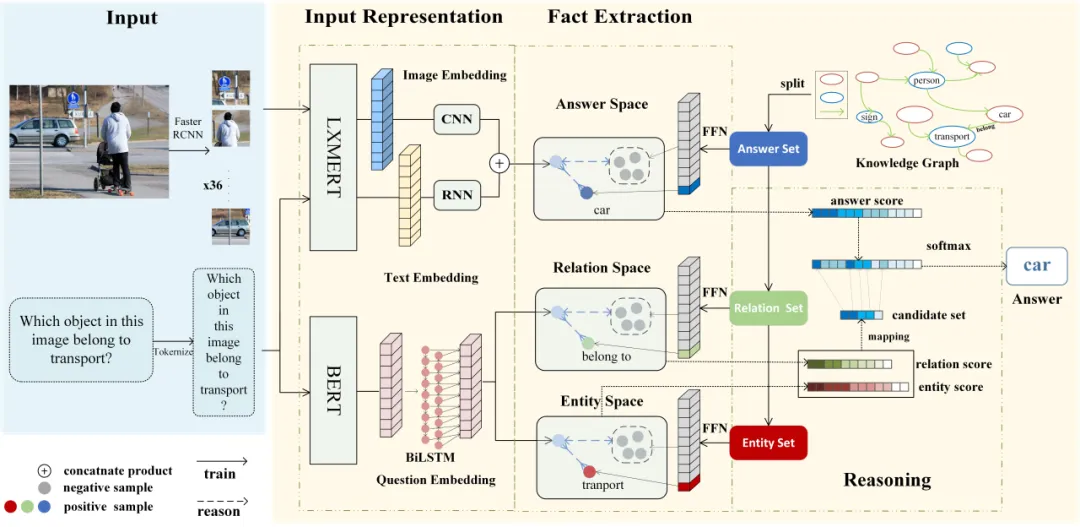
图2 方法整体架构图
3.实验
本文采用两个基于外部事实的视觉问答数据集来评估和对比不同方法的性能表现 ,总体实验结果如表1、2所示,证明了本文提出方法在实体提取和关系提取方面的显著优势,以及良好的适应性和性能表现。
表1 本文方法与对比方法在视觉问答数据集ZS-F-VQA上的对比实验结果
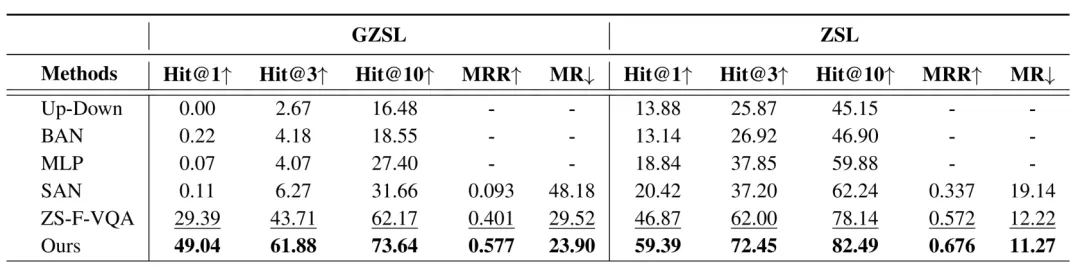
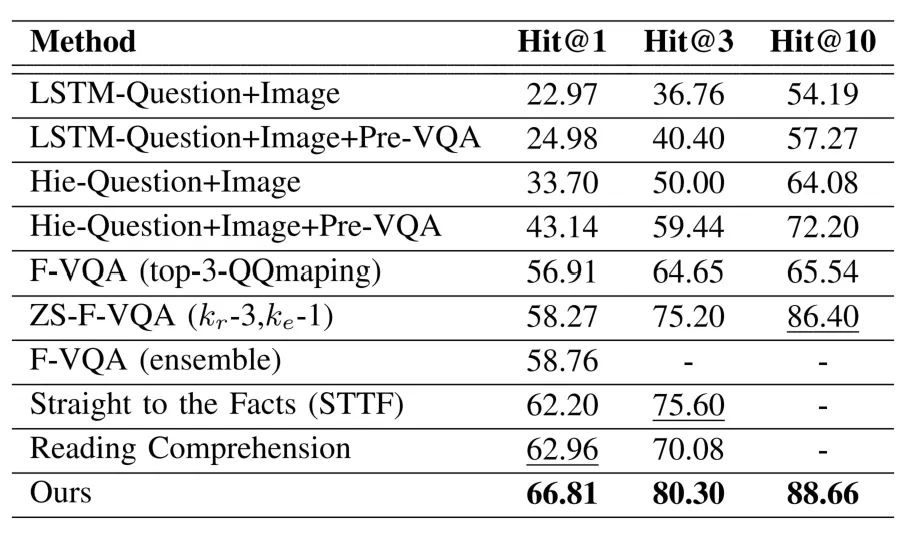
表2 本文方法与对比方法在视觉问答数据集F-VQA上的对比实验结果
05
CGLF-Net: Image Emotion Recognition Network by Combining Global Self-Attention Features and Local Multiscale Features
作者:
罗俣桐1,仲心月2,曾敏晨1,谢家兰1,王诗园1,刘光远*1
单位:
1西南大学,2奥克兰大学
邮箱:
lyt252012778@email.swu.edu.cn;
xzhong3@utas.edu.au;
zmczmc@email.swu.edu.cn;
jialanxie@email.swu.edu.cn;
wangshiyuan@e-mail.swu.edu.cn;
liugy@swu.edu.cn
论文:
https://ieeexplore.ieee.org/document/10163850
* 通讯作者
1.研究背景
图像情感识别不仅需要解析图像本身的视觉内容,更要考量观看者对这些内容的情感反馈,加之图像内在的复杂性和多样性,使得情感识别面临巨大的挑战。心理学研究揭示了图像内部不同区域对于引发特定情感反应具有差异性的重要性,局部特征可能隐藏着丰富的情感线索。因此,有效融合局部特征与全局特征成为了提升图像情感识别性能的关键环节。
然而,以往研究中倾向于将视觉特征视为全局表征,从而忽视了图像局部区域所蕴含的情感信息。一些研究直接尝试利用CNN来提取图像特征,但卷积操作难以完全捕获全局上下文信息。近年来,Transformer结构在图像分类任务中崭露头角,凭借其独特的自注意力机制高效地获取图像的全局表示。在实际应用中,CNN着重于逐区域地细化特征提取,而Transformer则能灵活地关注并权衡各个区域。现有的图像情感识别研究中,并未充分探索结合卷积特征与自注意力特征以同步抽取局部与全局特征的方案。
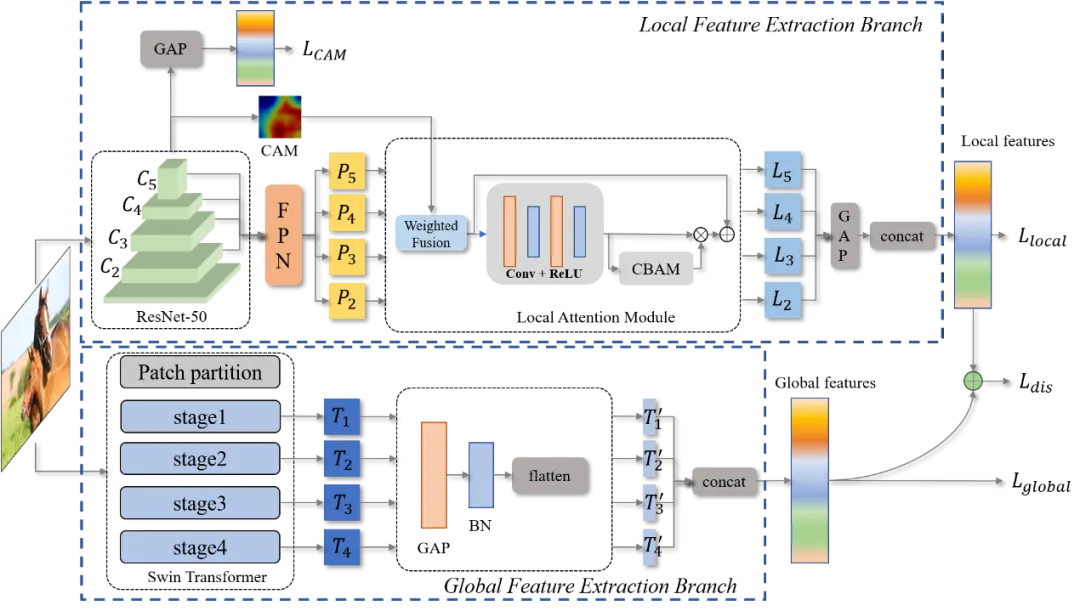
图1 整体网络结构图
2. 方法概述
因此,我们提出了结合图像自注意力特征和局部多尺度特征的图像情感识别网络CGLF-Net,整体结构如图1所示。我们的模型分为局部多尺度特征提取分支和全局自注意力提取分支。在局部多尺度特征提取分支中,我们通过改进的特征金字塔网络和 CAM 加权局部注意力模块(CW-LAM)提取图像的局部多尺度特征。在全局特征提取分支中,我们通过跨尺度Transformer网络获得全局自注意力特征。为保持两个网络分支输出分布的一致性,在损失函数中引入了KL散度。此外,还在损失函数中加入了 CAM 损失项,以进一步提高性能。
3.实验分析
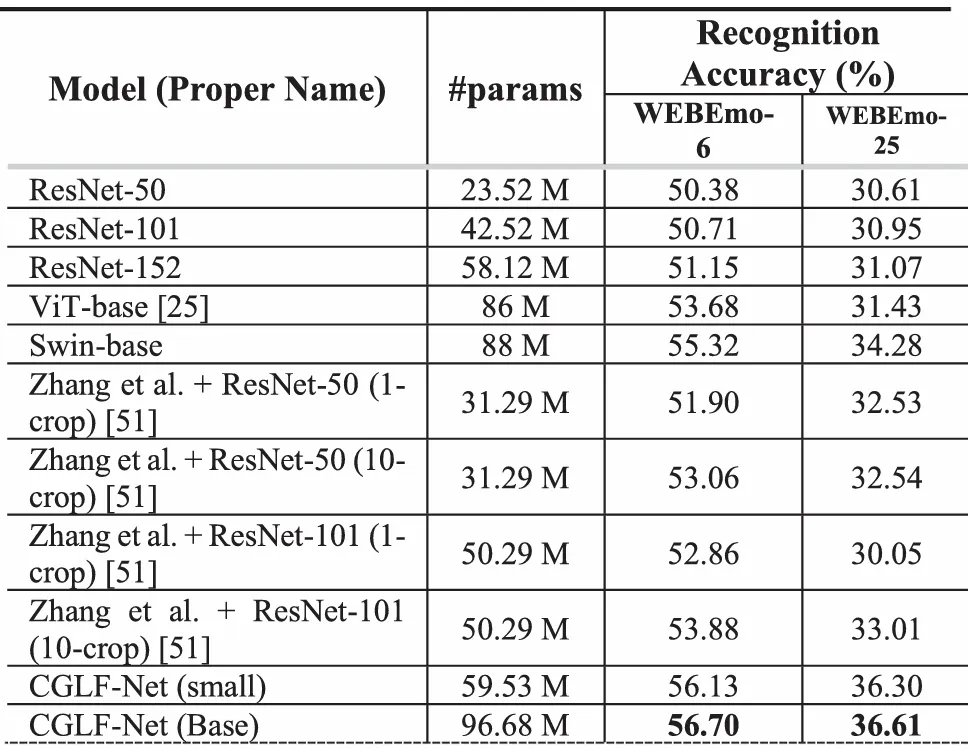
我们在常用的Emotion-6、FI-8和WEBEmo图像情感数据集上,与现有的先进算法进行了对比实验,结果如表1、表2和表3所示。由实验结果可知,我们的方法相比于现有的方法均能取得可对比的结果,特别是在小规模的Emotion-6数据集上,我们的方法取得了最先进的结果。
表1 Emotion-6数据集上与现有先进算法比较结果
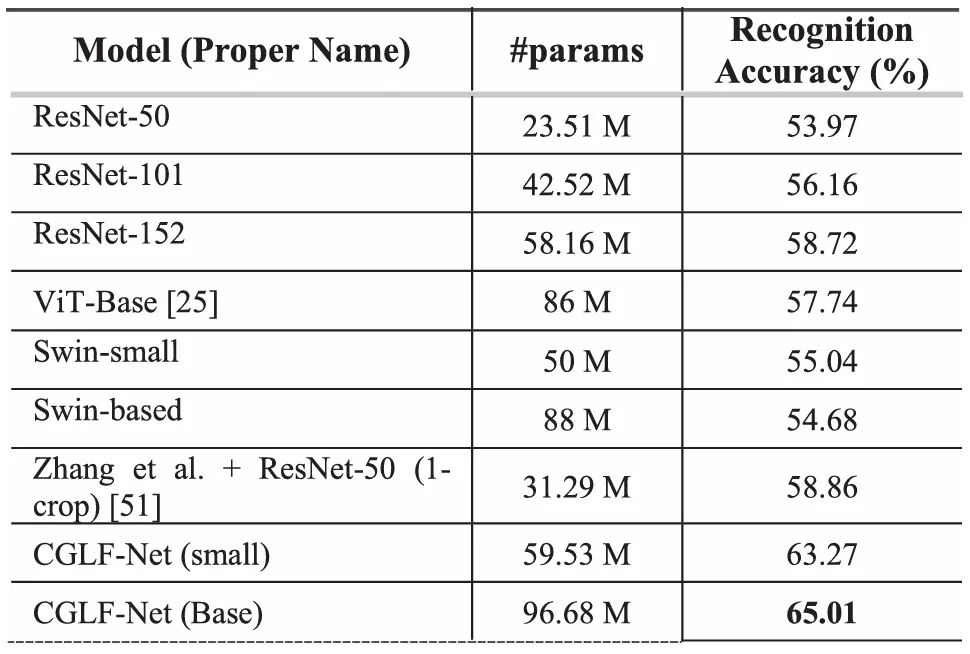
表2 FI-8数据集上与其他先进算法比较结果
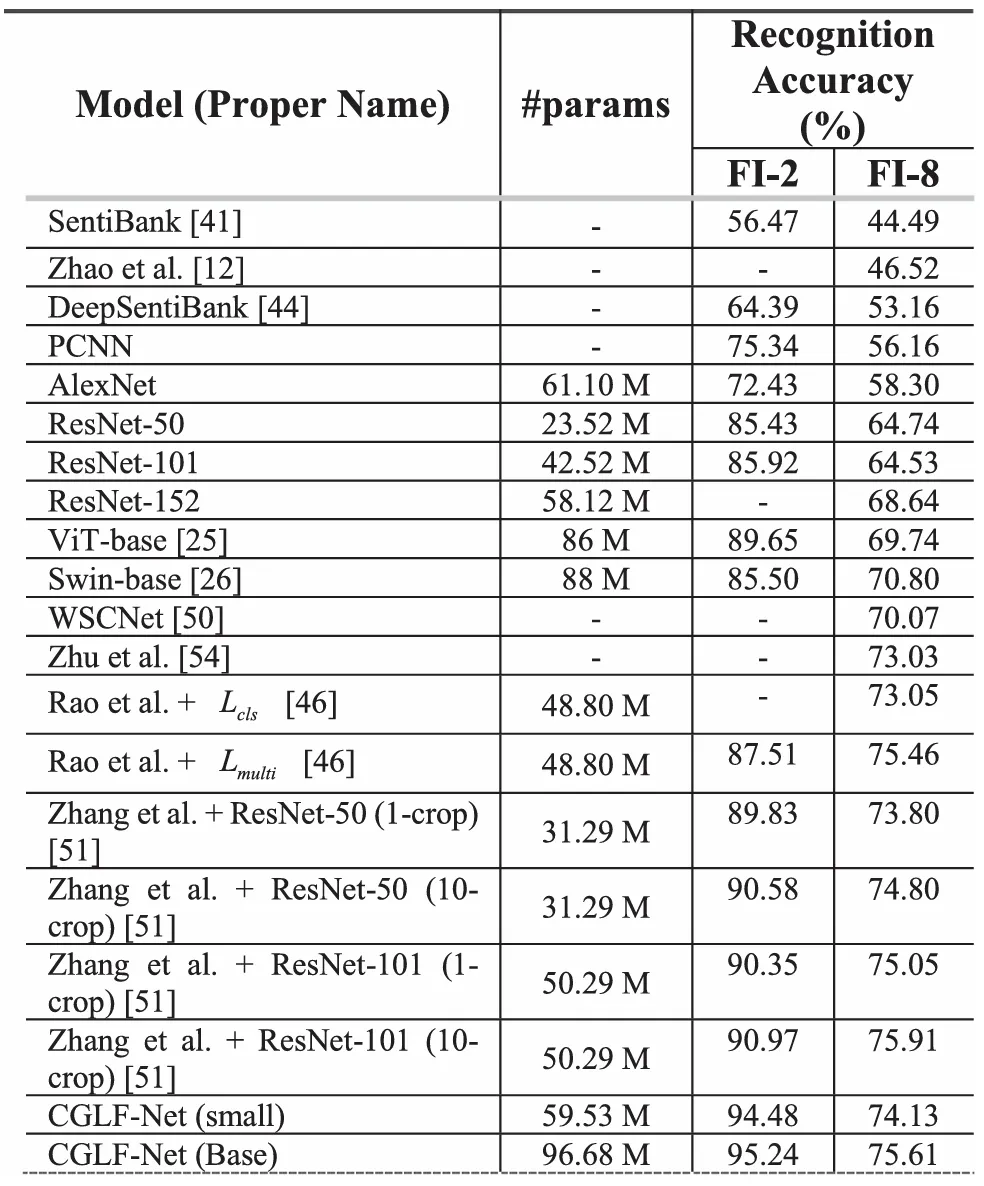
表3 WEBEmo数据集上与现有先进算法比较结果

编辑人:吴建龙、任文琦
专委会责任副主任:张勇东

微信扫一扫
关注该公众号
 京公网安备11010802017125号
京公网安备11010802017125号