
【论文导读】2024年论文导读第十二期
【论文导读】2024年论文导读第十二期
CCF多媒体专委会 2024年06月18日 19:30 北京


论文导读
2024年论文导读第十二期(总第一百零三期)
目 录
|
1 |
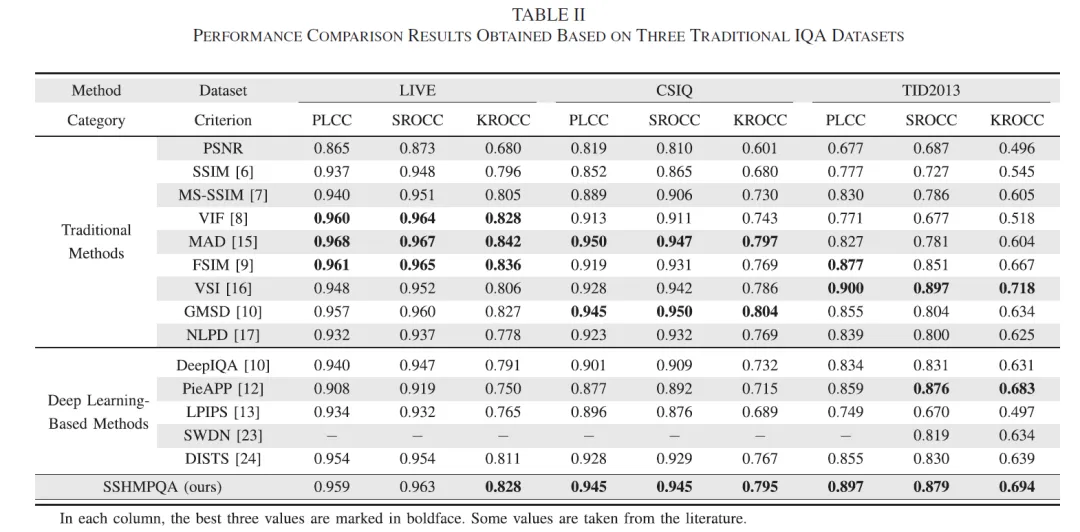
Perceptual Quality Analysis in Deep Domains Using Structure Separation and High-Order Moments |
|
2 |
Dual Modality Prompt Tunning for Vision-Language Pre-Trained Model |
|
3 |
Cooperative Bargaining Game Based Adaptive Video Multicast Over Mobile Edge Networks |
|
4 |
CATNet: A Cascaded and Aggregated Transformer Network for RGB-D Salient Object Detection |
|
5 |
Completed Part Transformer for Person Re-Identification |
01
Perceptual Quality Analysis in Deep Domains Using Structure Separation and High-Order Moments
作者:
咸伟志1 2, 周明亮* 1, 房斌*1, 向涛1, 贾维嘉3, 陈斌2 4
单位:
1重庆大学,2哈尔滨工业大学重庆研究院,3北京师范大学-香港浸会大学联合国际学院, 4哈尔滨工业大学(深圳)
邮箱:
wasxxwz@163.com;
zml0913yy@163.com;
fb@cqu.edu.cn;
txiang@cqu.edu.cn;
jiawj@uic.edu.cn;
chenbin2020@hit.edu.cn
论文:
https://ieeexplore.ieee.org/document/10180056
代码:
https://github.com/WeizhiXian/SSHMPQA
*通讯作者
1.研究背景和动机
图像是由结构化的对象和覆盖物体表面的纹理所组成的,它们对HVS来说具有完全不同的视觉效果,一个性能优异的IQA方法应该充分考虑图像结构的视觉显著性效应和图像纹理的遮蔽效应。结构是描述图像内容的关键基础,因为结构传达了图像中呈现的基本信息,使人们能够理解图像的语义。人们在观看一幅图像时,首先会自然而然地感知到它的结构,并理解这个结构中的物体,而不是检查详细的局部纹理。因此,HVS对图像中的结构失真极为敏感。纹理是一种反映了图像中的同质现象的视觉特征,它包括了物体表面有规律和周期性变化的像素排列。由于视觉遮蔽效应,HVS对一些纹理失真并不敏感,这意味着失真图像中的纹理区域不一定要与参考图像在每个对应像素上完全相同。


2. 方法概述
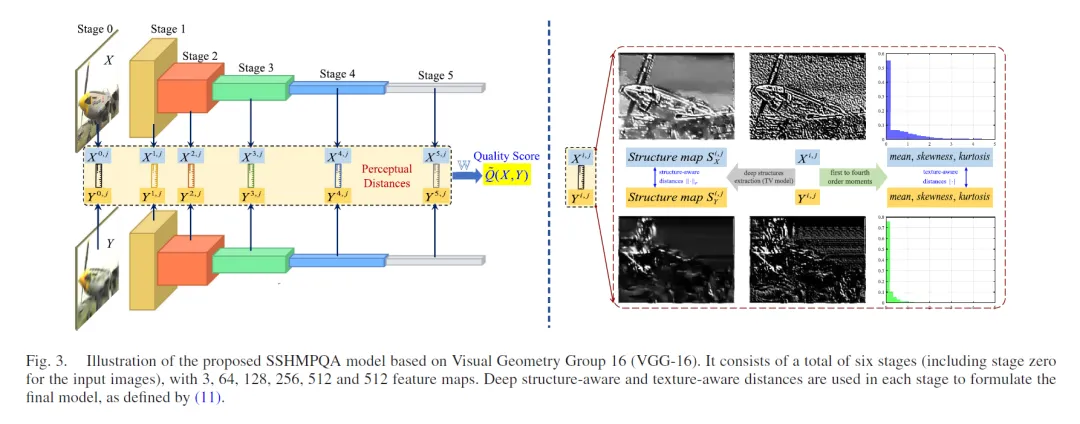
提出了一个基于深度结构和纹理特征的FR-IQA模型(perceptual quality analysis model using structure separation and high-order moments, SSHMPQA),该模型同时是知识驱动和数据驱动的,能感知结构和纹理信息,并且具有良好的可解释性、较强的泛化能力和对空间扰动的高鲁棒性。SSHMPQA的基本框架如下:
① 首先,使用TV模型将图像的深度感知结构从预训练的VGG-16网络的特征图中分离出来,从而在纹理抑制的情况下使得深度纹理图保持有意义的物体形状。在此基础上,本章在深度域中定义了结构感知距离。
② 其次,使用一阶到四阶矩来计算特征图概率分布的平均值、偏度和峰度。在此基础上,本章在深度域中定义了一个纹理感知距离。
③ 最后,设计了一个感知凸优化问题,并通过解决这个优化问题来建立最终的SSHMPQA模型。因此,所提出的模型是数据驱动的,但不需要复杂而漫长的训练过程,因为该优化问题有一个精确的数学解析解。
3. 实验分析
考虑到KADID-10k数据集具有10100个训练样本,为了验证SSHMPQA模型的泛化性,SSHMPQA模型将在KADID-10k上训练,并在其他数据集上进行跨数据集对比试验。为了验证所提出的SSHMPQA模型的结构和纹理感知能力,本节还在Amsterdam纹理库(Amsterdam Library of Textures, ALOT)上进行了的实验,该数据集包含250种彩色纹理图案。综合实验结果表明,SSHMPQA模型具备较强的泛化能力,可以感知图像的结构和纹理,并且对空间扰动具有鲁棒性。此外,我们还做了抗空间扰动的实验。


02
Dual Modality Prompt Tunning for Vision-Language Pre-Trained Model
作者:
邢颖慧1,武启睿1,程德2*,张世周1,梁国强1,王鹏1,张艳宁1
单位:
1西北工业大学计算机学院 空天地海一体化大数据应用技术国家工程实验室,2西安电子科技大学通信工程学院
邮箱:
xyh_7491@nwpu.edu.cn;
wuqirui@mail.nwpu.edu.cn;
dcheng@xidian.edu.cn;
szzhang@nwpu.edu.cn;
gqliang@nwpu.edu.cn;
peng.wang@nwpu.edu.cn;
ynzhang@nwpu.edu.cn
论文:
https://ieeexplore.ieee.org/document/10171397
代码:
https://github.com/fanrena/DPT
*通讯作者
1. 研究动机
CLIP将图文两种模态的数据⽤两个编码器映射到⼀个特征空间中,通过对两个模态特征进⾏对比学习,建立了⼀个对齐的图文多模态特征空间。为了高效利用CLIP泛化性极强的可迁移表征,提示学习通过改造输入为模型提供任务相关的上下文,探索了预训练模型中储存的通用知识对下游任务的有益信息,但手工设计提示需要专家知识辅助且很难获得最优提示,费时费力。一种名为上下文优化(CoOp)的方法引入了一组作为来自语言侧的文本提示的可学习向量解决了这一问题。然而,单独调整文本提示仅能调节合成的“分类器”,而无法影响由图像编码器计算的视觉特征。如图1(b)中所示,对文本编码器的调整无法使视觉编码器关注于下游任务相关的区域,因此导致次优解。在本文中,我们提出了一种通过同时学习文本和视觉提示的双模态提示调优(DPT)范式。为了让最终图像特征更多关注目标视觉概念,我们的DPT中进一步提出了一个类感知视觉提示调优(CAVPT)模块。在CAVPT生成模块中,CAVPT通过执行文本提示特征和图像特征之间的交叉注意力来动态生成,以编码下游任务相关信息和视觉实例信息。如图1(c)所示,我们的方法有效的改善了CLIP模型无法关注于下游任务相关区域的问题。
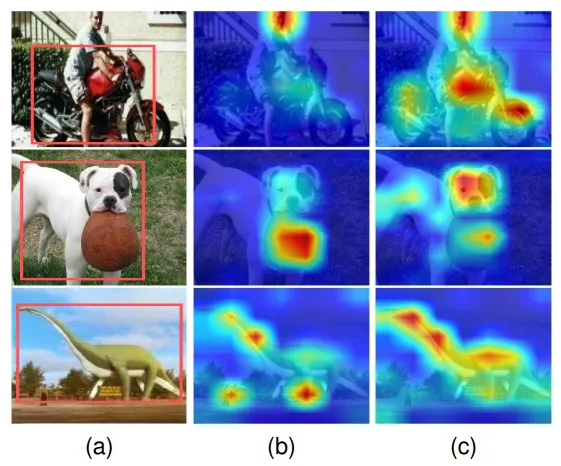
图1 不同方法的视觉编码器注意力图可视化 。(a) 为原始图像,红色框标记了本图的GT目标。(b) Zero-shot CLIP/CLIP的可视化。(c) 本文所提方法的可视化。
2. 方法概述
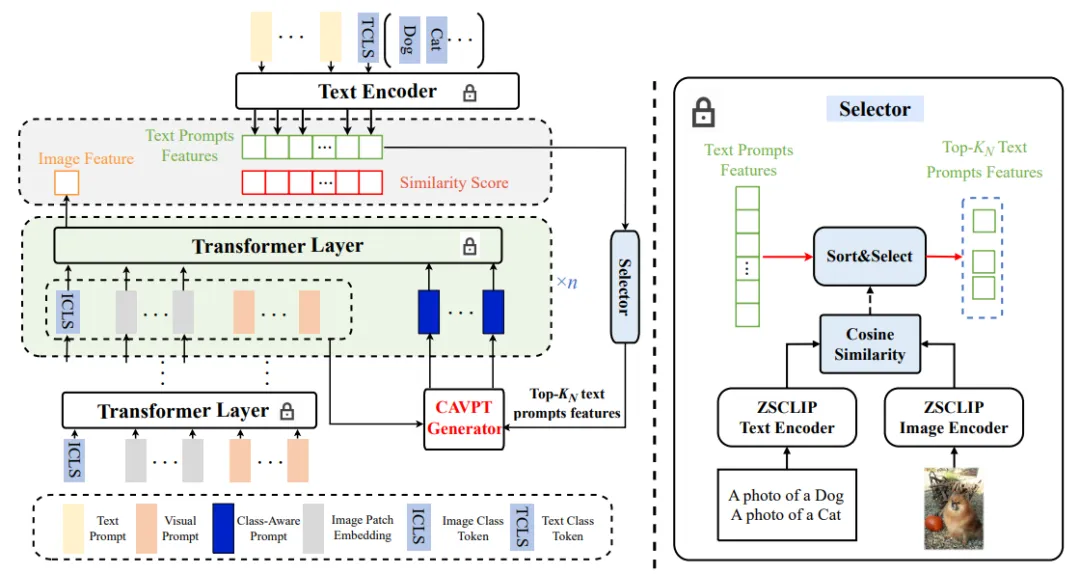
图2 DPT的总体框架,由冻结的CLIP以及文本提示,视觉提示,以及类感知视觉提示生成器三个可学习模块组成。
本文提出的框架如图2所示,由冻结的CLIP视觉编码器,文本编码器两部分,以及视觉提示、文本提示、类感知视觉提示生成器三个可学习模块组成。为了使模型能够对视觉特征进行调优,我们同时引入文本与视觉双模态提示,同时对视觉特征与文本特征进行调优,有效的改善了Zero-shot CLIP只关注于显著区域而非任务相关区域的问题。
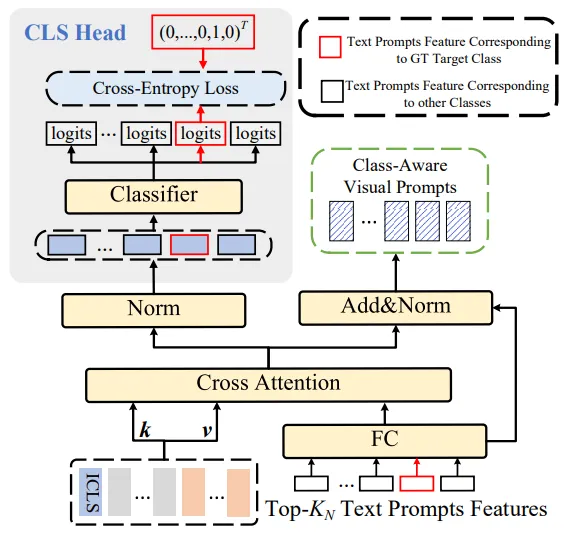
图3 类感知视觉提示生成器框架
为了促进模型进一步关注到任务特定的信息,我们引入了CAVPT,如图3所示,CAVPT生成器以不同类别文本特征为query,通过与视觉特征图进行交叉注意力计算,编码类别感知的特定区域视觉信息并注入视觉提示,为了获得更具区分度的类别特定的视觉表征,我们对交叉注意力获得的视觉信息进行了分类。CAVPT进一步提高了模型对任务相关的视觉信息的感知。此外,我们对作为query的文本特征进行了Top-K筛选,有效的减少了计算开销。
3.实验分析
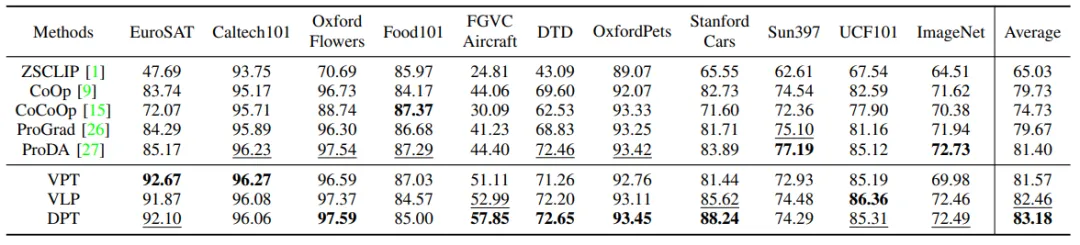
本方法在11个下游数据集上进行了实验,图4展示了本方法在ViT-B/32与ViT-B/16两种视觉编码器上不同shot数下的平均精度,表1与表2分别展示了本方法在ViT-B/32与ViT-B/16两种视觉编码器上16shot情况下与其他先进方法的结果对比。可⻅我们的双模态提⽰策略相较于单模态提⽰有了提升。⽽在CAVPT的辅助下,DPT相较于VLP取得了进一步提升。
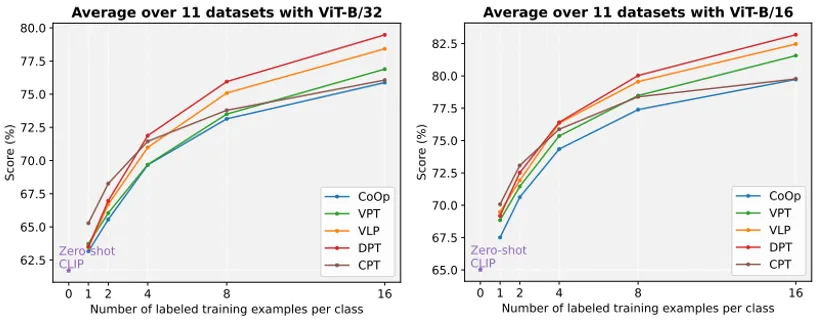
图4 在1、2、4、8、16 shot下,我们的方法与其他方法在不同视觉编码器下的平均精度对比
表1 在16-shot、以ViT-B/32为视觉编码器情况下,我们的方法与先进方法的结果对比
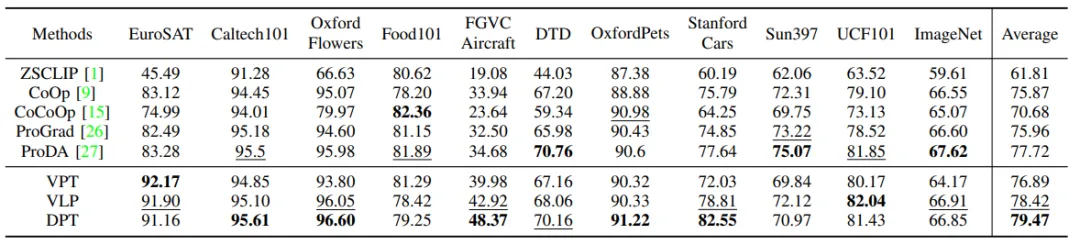
表2 在16-shot、以ViT-B/16为视觉编码器情况下,我们的方法与先进方法的结果对比
03
Cooperative Bargaining Game Based Adaptive Video Multicast Over Mobile Edge Networks
作者:
谭小彬1,2,李思敏1,王顺义1,刘杨阳1,郑烇1,2,*,杨坚1,2
单位:
1中国科学技术大学,2合肥综合性国家科学中心人工智能研究院
邮箱:
xbtan@ustc.edu.cn;
lisimin@mail.ustc.edu.cn;
wsy12@mail.ustc.edu.cn;
lyy2017@mail.ustc.edu.cn;
qzheng@ustc.edu.cn;
jianyang@ustc.edu.cn
论文:
https://ieeexplore.ieee.org/document/10184187
*通讯作者
1.引言
在网络资源有限、信道质量动态变化的无线网络上提供高质量的视频服务是一个具有挑战性的问题,采用组播技术传输视频可以提高视频服务质量和网络资源利用效率,是解决无线网络上视频传输问题的有效手段。本文研究在应用了多播广播多媒体服务(MBMS)和移动边缘计算(MEC)技术的移动通信网络上的视频组播问题,提出了一种基于k-means聚类和合作讨价还价博弈的自适应视频组播解决方案(KGS)。针对视频组播中用户分组、资源分配、码率决策三个步骤,我们为网络中的多个多播广播同步频率网络(MBSFN)中的用户建立了基于合作讨价还价博弈(CBG)的视频组播联合优化模型。然后将该模型转化为两阶段凸优化问题和非线性整数规划问题,并提出了一种基于启发式方法的视频组播方案,实现了帕累托最优的视频组播。最后,我们通过大量的仿真实验验证了所提方案的有效性。
2.方法概述
论文提出了一种基于k-means聚类和合作讨价还价博弈的自适应视频组播解决方案(KGS)。如图1所示,我们提出的视频组播由用户分组、资源分配与码率决策三个相互影响的部分组成,我们将视频传输问题描述为一个联合优化问题,然后对该问题进行解耦,设计了一种基于启发式方法的解决方法。
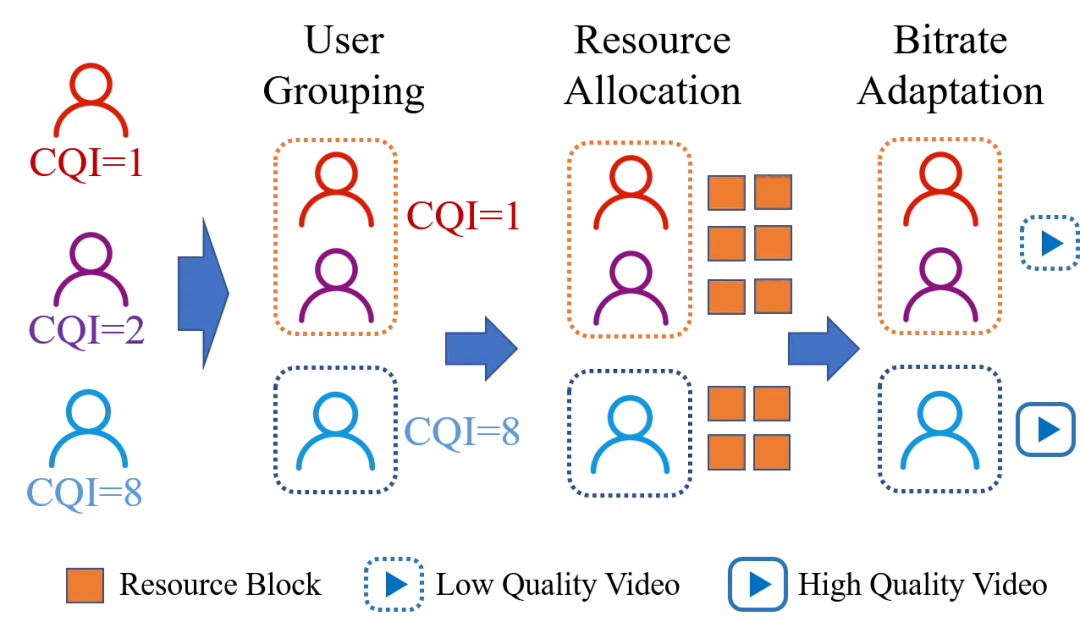
图1 视频组播流程图
首先,我们提出了一种基于k-means聚类的用户分组方法,以CQI为特征生成合适的组播组。在该分组方案下,同一组播组中的用户具有近似的CQI。因此,在这种组播分组方案中,不会出现频谱效率相对较低的用户降低组内其他用户的视频码率的状况。
其次,我们把资源分配问题建模为一个合作讨价还价博弈模型,其中每个组播组都是一个以系统效用最大化为目标的玩家。资源分配的结果将受到用户数量、有效 CQI 等因素的影响,并最终获得纳什均衡解(NBS)。该博弈模型的NBS是最优资源配置结果,但是并不是资源分配结果的显示表达。因此我们采用KKT条件对NBS问题进行求解,获得每个组播组所分配的资源块数量。此外,考虑到物理资源块不可进一步分割,我们将由KKT求解得到的结果向下取整作为初始状态,之后采用贪婪策略将剩下资源块分配给组播组。
最后,基于分配给每个组播组的物理频谱资源,综合考虑影响用户QoE的因素(包括视频质量、停顿时长和视频质量振荡等),我们提出了一种最优化组播组QoE 的自适应码率策略,在满足避免中断和码率切换的约束条件下选择最高码率级别,实现最优化组播用户整体QoE的目标。
3.实验分析
我们在不同的代表性场景中使用了多个评价指标对论文所提出的KGS方案进行了评估。通过用户平均QoE、公平性、资源利用率、时间复杂度等指标验证了KGS方案的有效性。
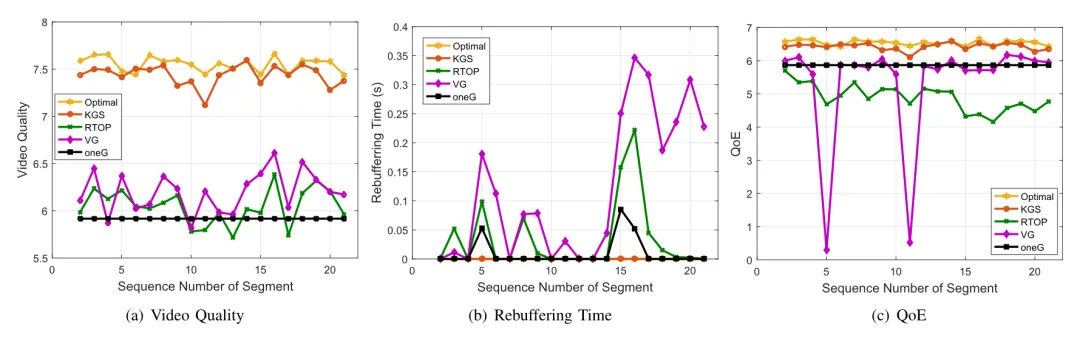
图2 通用场景中不同算法的QoE
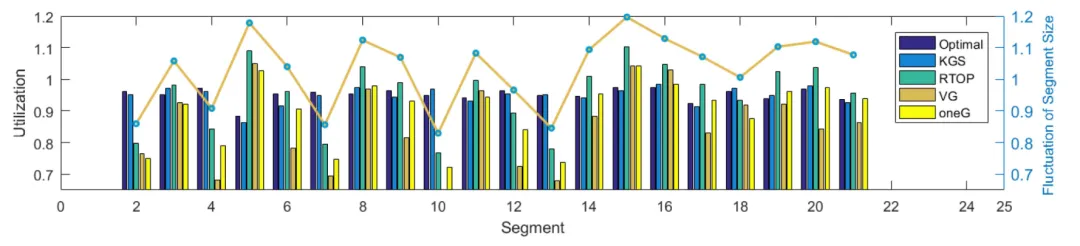
图3 通用场景下不同算法的资源利用率
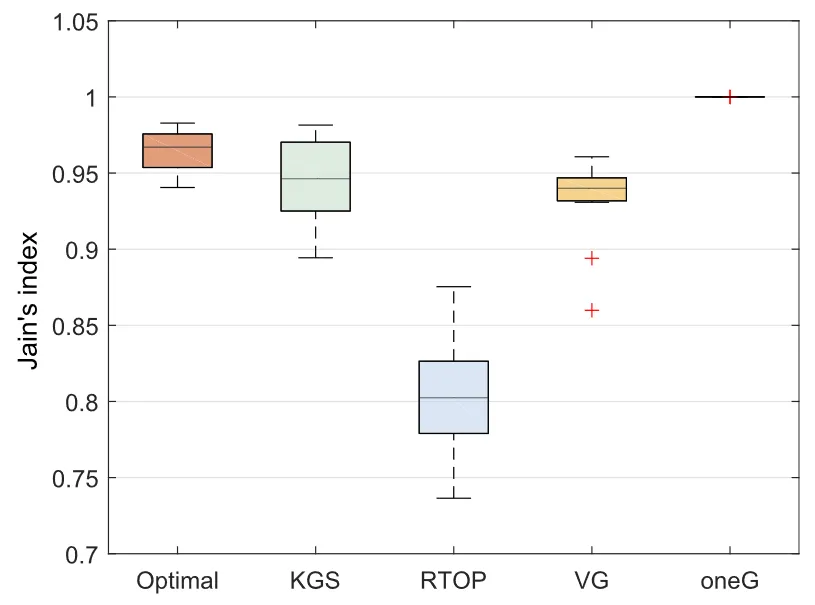
图4 不同算法的公平性
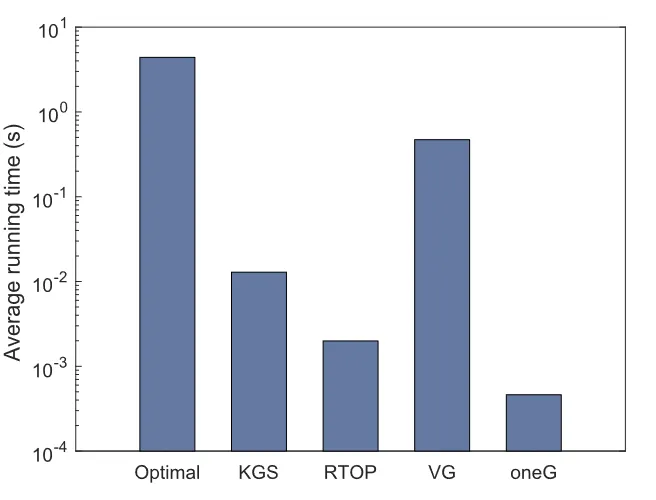
图5 通用场景下不同算法的平均运行时间
04
CATNet: A Cascaded and Aggregated Transformer Network for RGB-D Salient Object Detection
作者:
孙福明1,任鹏1,尹博文1,王法胜1,李豪杰2
单位:
1大连民族大学,2大连理工大学
邮箱:
sunfuming@dlnu.edu.cn;
renpeng9707@outlook.com;
997450910@qq.com;
wangfasheng@dlnu.edu.cn;
hjli@dlut.edu.cn
论文:
https://ieeexplore.ieee.org/document/10179145
1.引言
显著性目标检测旨在定位场景中最显眼的物体,是许多计算机视觉任务的预处理步骤。随着深度学习的发展,大量基于卷积神经网络的显著性目标检测方法被开发。然而,这些方法存在三个局限:1)卷积神经网络无法有效全局建模。由于卷积神经网络固有的滑动窗口特征提取方法,基于卷积神经网络的方法无法很好地提取全局特征,限制了模型的性能。2)跨模态融合的挑战。RGB图像和深度图像各自具有独特特点,但直接融合策略会降低模型性能。一些融合策略忽略了输入图像的质量,导致融合特征的辨识度下降。3)多尺度特征聚合的难题。不同尺度的特征各自具有独特性,高层特征包含丰富语义信息,而低层特征包含详细边缘信息。直接聚合多尺度特征会引入低层特征带来的干扰信息,导致模型性能下降。为了应对上述局限,本文提出一种级联聚合Transformer网络(CATNet)。具体地说,该网络利用Swin Transformer来建模全局特征。本文设计跨模态融合模块来解决深度图质量差和显著目标易受背景干扰的问题。此外,本文还设计级联校正解码器,它通过级联方式进行多尺度特征聚合,选择性地聚合、细化和修正多尺度特征,解决信息损失和边界模糊的问题。
2.方法
本文提出了一种级联聚合Transformer网络(CATNet),该网络主要包括五个部分:Swin Transformer编码器、跨模态融合模块、注意力特征增强模块、边缘生成器和级联校正解码器。具体来说,使用Swin Transformer编码器分别从RGB图像和深度图像中提取多层特征。为了获得高级特征的多尺度信息,我们在Swin Transformer编码器的末端添加了注意力特征增强模块。然后,为了有效地融合RGB和深度模态的特征,将来自Swin Transformer编码器的多级特征输入跨模态特征融合模块进行跨模态特征融合。最后,利用级联校正解码器整合跨模态特征融合模块中的多尺度融合特征,推断出最终的显著性图。此外,为了生成具有清晰边界的显著性映射,本文引入了边缘生成器来生成显著对象的边缘轮廓。图1展示了该网络的总体结构图。
3.实验
在七个广泛使用的基准数据集上的实验结果证明了所提出CATNet的有效性和优越性,与一些先进方法的性能对比如表1和表2所示。
为了进一步验证CATNet的有效性,图2展示了一些定性可视化结果。可以观察到,在许多具有挑战性的场景下,CATNet比其他模型生成了更精确的显著性图,这表明CATNet更具竞争力。例如:边缘和细节(第1−第2行)、小的对象(第3−第4行)、低质量的深度图(第5−第6行)、复杂的背景(第7−第8行)和大的对象(第9−第10行)。
表1 与基于Transformer的方法性能对比结果,红色的代表最优结果,绿色的代表次优结果,蓝色的代表第三优结果。
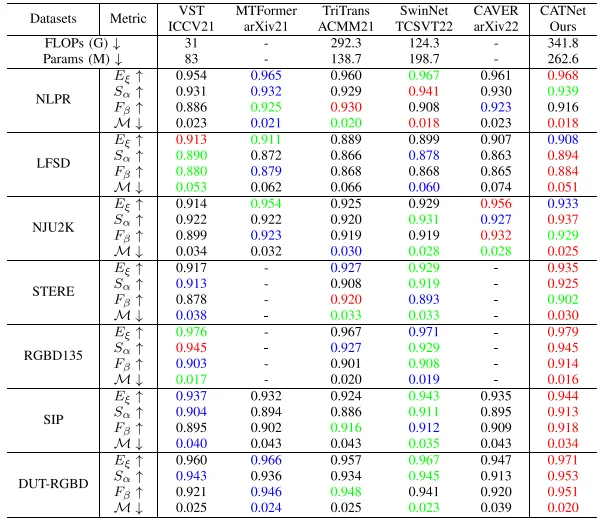
表2 与基于CNN的方法性能对比结果,红色的代表最优结果,绿色的代表次优结果,蓝色的代表第三优结果。
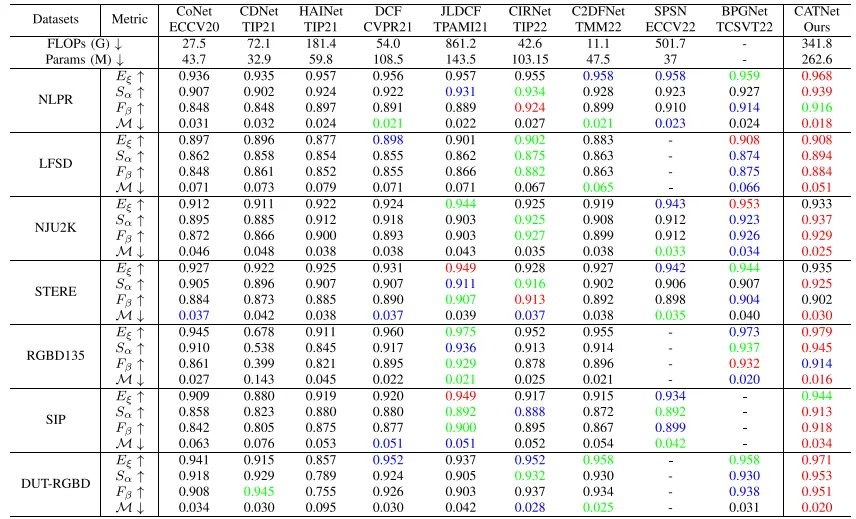

图2 与其它先进方法的定性可视化结果对比
05
Completed Part Transformer for Person Re-Identification
基于完备部件Transformer的行人再识别
作者:
张重,贺迪,刘爽,肖柏华,Tariq S. Durrani
单位:
天津师范大学电子与通信工程学院/人工智能学院,中国科学院自动化研究所,英国斯特拉斯克莱德大学电子与电气工程系
邮箱:
zhong.zhang8848@gmail.com;
clarkhedi@gmail.com;
shuangliu.tjnu@gmail.com;
baihua.xiao@ia.ac.cn;
t.durrani@strath.ac.uk
论文:
https://ieeexplore.ieee.org/document/10180050
1.简介
因为行人图像的部件特征可以提供人体的结构信息,所以行人图像中的部件特征对于行人再识别的性能至关重要的。然而,大多数方法使用Transformer学习长距离依赖时,如图1(a),将行人图像划分为一系列非重叠的令牌去学习全局交互,其中,每个令牌对应为一个特征向量,令牌之间的交互表示特征向量之间的交互,并利用自注意力机制学习不同位置令牌之间的关系。在学习令牌之间的交互时,忽视了部件之间的交互,从而导致部件依赖信息的缺失。
为此,本文提出了一种新颖的Transformer网络,命名为CPT用于行人再识别。其核心模块是Part Transformer Layer,它包括Intra-part Layer和Part-global Layer,它们分别从部件内交互和部件-全局交互两个方面学习长距离依赖信息,如图1(b)。除此之外,为了克服Part Transformer Layer在学习过程中令牌数量固定,导致引入不相关信息的问题,本文提出自适应精细令牌(ART)模块专注于学习行人图像中信息量丰富令牌之间的交互,从而提高行人特征的判别性。
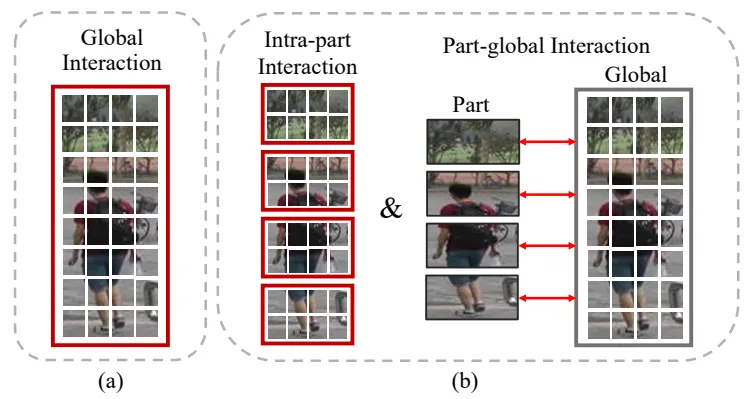
图1 (a) 从整个行人图像中获得令牌,并构建全局交互;(b) 从行人图像的条纹部件生成令牌,并构建部件内交互和部件-全局交互,以学习完备的部件交互。红色方框和红色双向箭头分别表示使用自注意力和交叉注意力学习交互。
2. 方法
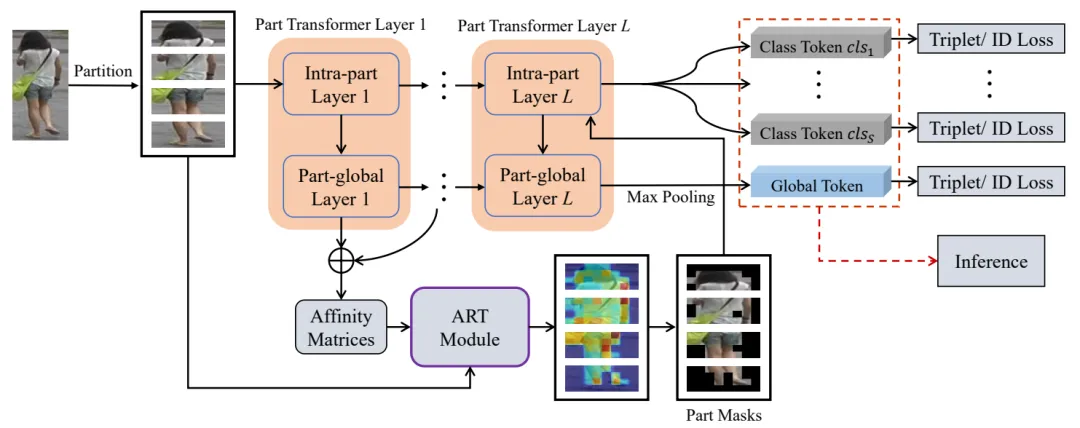
图2 CPT的整体框架图
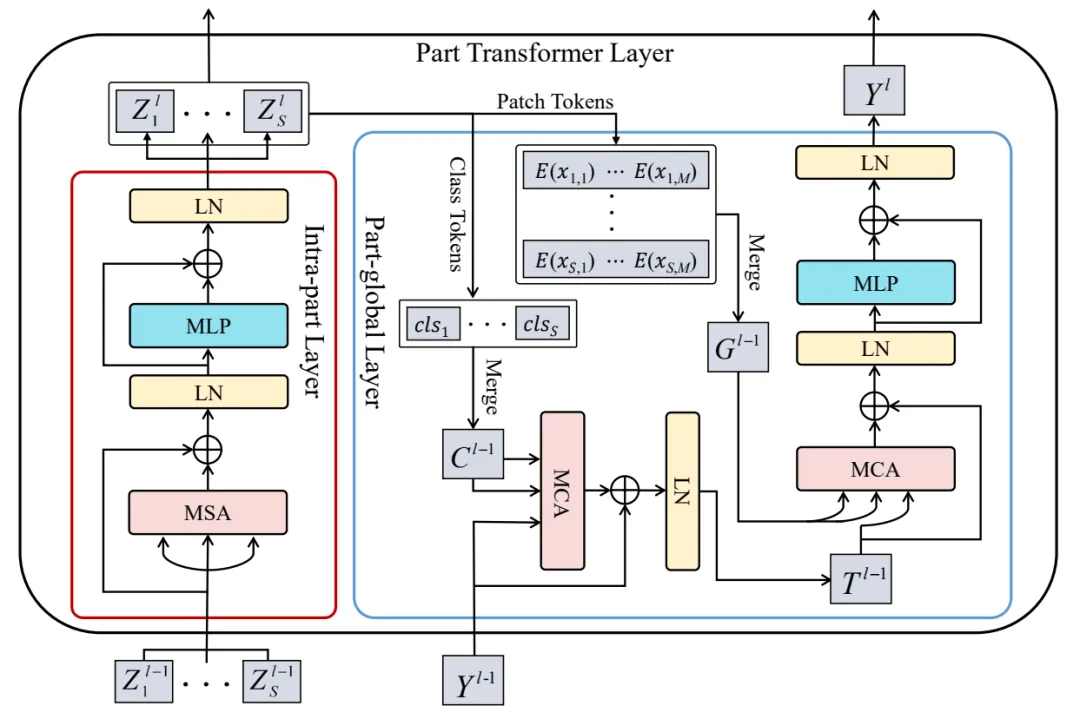
图3 Part Transformer Layer的结构图
本文提出方法的整体框架如图2所示。首先,将每个行人图像分割成几个条纹,然后将它们输入到L个Part Transformer Layer中,Part Transformer Layer的结构如图3所示。其中,每个Part Transformer Layer由一个Intra-part Layer和一个Part-global Layer组成。Intra-part Layer学习部件内交互,它表示每个条纹部件内令牌之间的交互,即挖掘行人图像条纹部件内部的长距离依赖关系。Part-global Layer学习部件-全局交互,它有助于学习完备的部件交互,表示每个条纹部件与整个行人图像中所有令牌之间的交互。其中,每个条纹用一个特征向量表示,条纹部件与整个行人图像中所有令牌的交互通过交叉注意机制实现,从而能够聚合每个条纹部件的全局信息。
除此之外,为了捕获有效的显著性区域信息,本文提出ART模块,基于Part-global Layer中的亲和力矩阵扩大部件感知区域,生成部件掩码进而有助于在部件交互学习过程中保留每个条纹中包含较多信息的令牌,从而有利于准确学习人体部件的细粒度信息。
3. 实验
本文将所提出的方法在MSMT17,Market1501,DukeMTMC-reID和CUHK03四个行人再识别数据集进行了实验,验证了提出方法的有效性。表1是消融实验,表2是与SOTA方法的对比实验。图4表示ART模块生成的部件掩码的可视化结果。
表1 本方法的消融实验
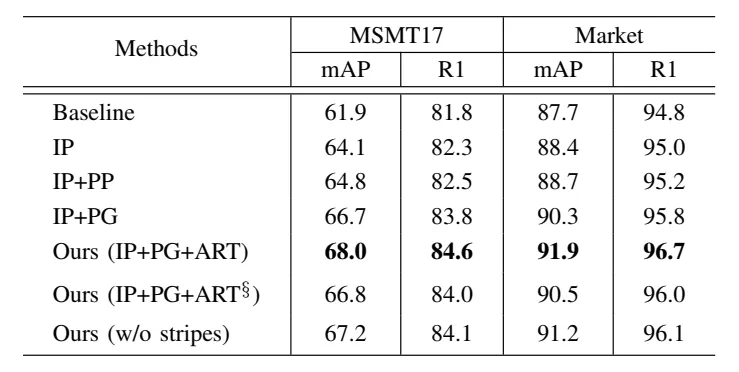
表2 本方法的对比实验
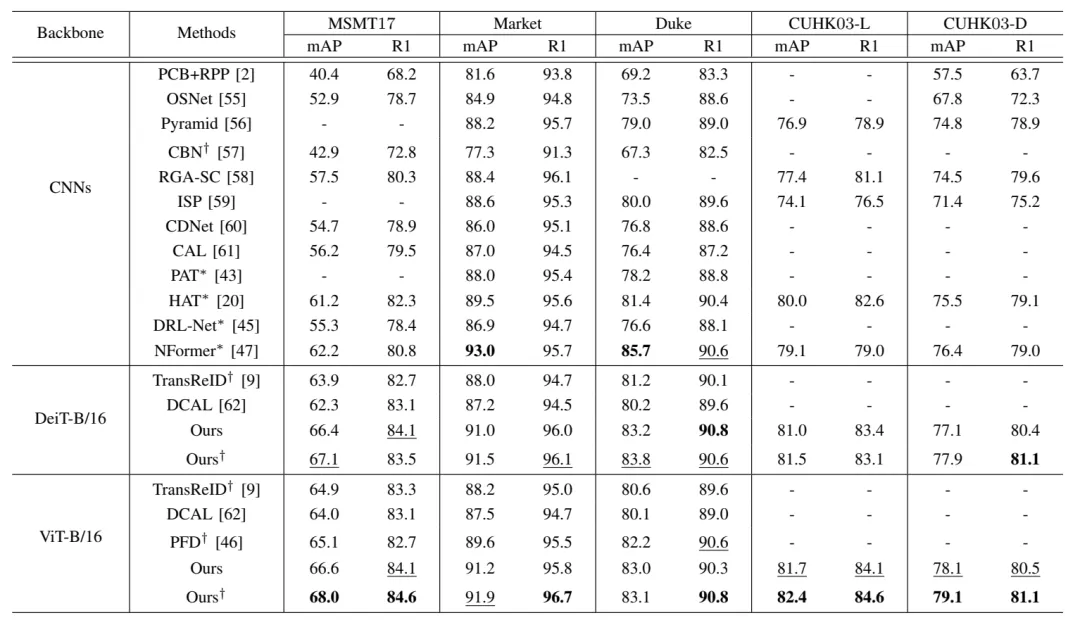

图4 ART模块生成的部件掩码的可视化结果,红色块表示丢弃的令牌

编辑人:吴建龙、任文琦
专委会责任副主任:张勇东

微信扫一扫
关注该公众号
 京公网安备11010802017125号
京公网安备11010802017125号