
【论文导读】2024年论文导读第十三期
【论文导读】2024年论文导读第十三期
CCF多媒体专委会 2024年07月02日 15:18 北京


论文导读
2024年论文导读第十三期(总第一百零四期)
目 录
|
1 |
Rate-Adaptive Neural Network for Image Compressive Sensing |
|
2 |
Print-Camera Resistant Image Watermarking with Deep Noise Simulation and Constrained Learning |
|
3 |
Towards Continual Egocentric Activity Recognition: A Multi-Modal Egocentric Activity Dataset for Continual Learning |
|
4 |
Deep Neighborhood Structure-Preserving Hashing for Large-Scale Image Retrieval |
|
5 |
Coarse-to-Fine Depth Super-Resolution with Adaptive RGB-D Feature Attention |
01
Rate-Adaptive Neural Network for Image Compressive Sensing
作者:
惠晨1,张盛平1,崔文学1,刘绍辉1,姜峰1*,赵德斌1
单位:
1哈尔滨工业大学
邮箱:
chenhui@stu.hit.edu.cn;
s.zhang@hit.edu.cn;
wxcui@hit.edu.cn;
shliu@hit.edu.cn;
fjiang@hit.edu.cn;
dbzhao@hit.edu.cn
论文:
https://ieeexplore.ieee.org/abstract/document/10202562
*通讯作者
1.引言
近年来,基于深度学习的图像压缩感知(CS)方法取得了显著的进展,并被应用在多个领域,如单像素成像、磁共振成像(MRI)和图像传输。然而,大多数CS方法的采样矩阵是固定的,只能处理一种采样率(如图1所示),且他们对图像不同区域采用相同的采样率,导致图像CS重建性能的降低(如图2所示)。针对这个问题,本文提出了一种率自适应的图像压缩感知网络(RACSNet),它能够根据图像内容特征实现自适应的采样率分配,从而提升图像重建的质量。

2.方法介绍
图3展示了RACSNet的框架,其由三个模块组成:自适应采样模块(图4)、重建网络模块(图6)和图像优化模块。自适应采样模块对不同图像块自适应的分配采样率;重建网络模块对采样后的测量值进行初始重建和深度重建;图像优化模块则用于消除块效应并提升图像质量。具体而言,首先使用基于测量域的重建失真来指导不同图像块的采样率分配,该方法只利用测量值而不需要获取原始图像。然后,设计了一种逐步训练策略来训练可重复使用的采样矩阵(图5),使其能够在任意采样率下对图像块进行采样生成压缩的测量值。随后,提出了一种金字塔形的初始重建子网络和分层深度重建子网络,用于从压缩测量值中重建图像块。最后,利用重建失真图和改进的损失函数来消除块效应并进一步增强重建质量。

图3 所提出的RACSNet的框架图
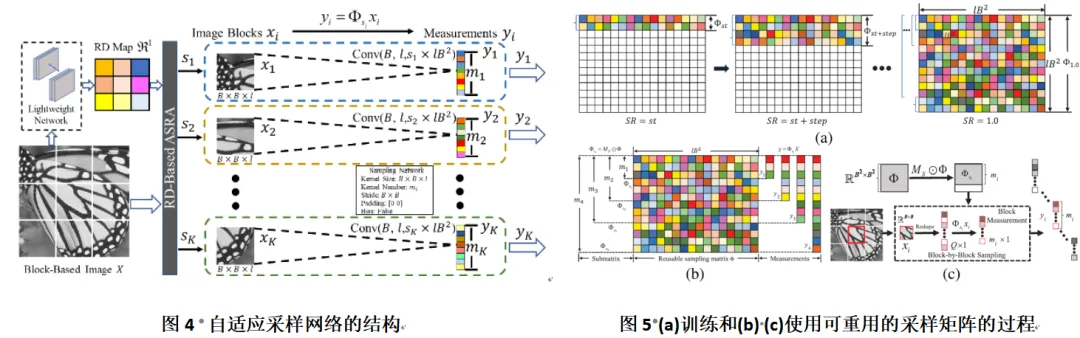
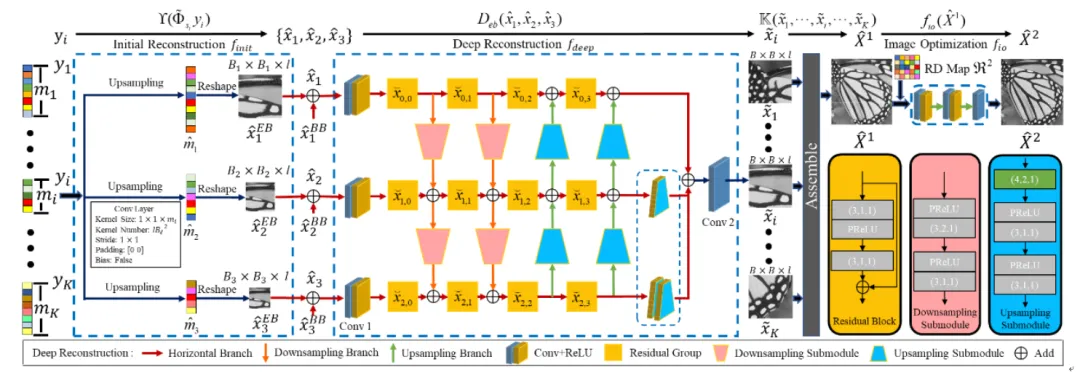
图6 重建网络的结构图,以三个尺度的深度重建网络为例
3.实验结果
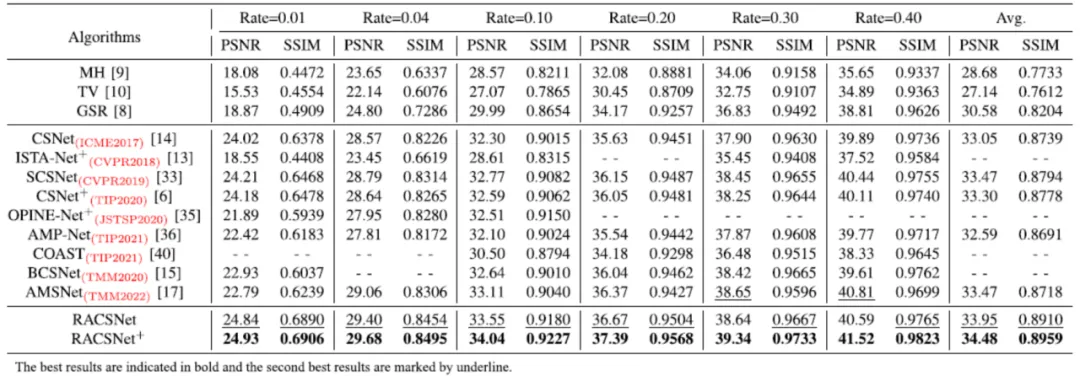
为了验证RACSNet的性能,本文与12个CS算法进行了对比,包括基于优化的算法、基于深度网络的非自适应CS算法和自适应CS算法。实验结果表明,RACSNet在客观指标(表1)和主观视觉质量(图8)方面都显著优于现有的自适应和非自适应CS方法,并为自适应采样率分配提供了一种新的解决方案。此外,我们也对自适应采样进行了消融实验(图7),可以看出自适应采样策略将更加关注图像的细节,从而在视觉效果方面实现更精细的重建。
表1 在set5数据集上不同图像cs方法的平均PSNR和SSIM比较

02
Print-Camera Resistant Image Watermarking with Deep Noise Simulation and Constrained Learning
基于深度噪声模拟和约束学习的抗打印拍照图像水印
作者:
秦川1,李晓萌1,张振毅1,栗风永2,张新鹏3,冯国瑞3
单位:
1上海理工大学,2上海电力大学,3上海大学
邮箱:
qin@usst.edu.cn;
202330353@st.usst.edu.cn;
justicefy@163.com;
fyli@shiep.edu.cn;
xzhang@shu.edu.cn;
grfeng@shu.edu.cn
论文:
https://ieeexplore.ieee.org/document/10175655
代码:
https://github.com/davidgdd1/Print-Camera-resilient-watermarking.git
实验数据集:
https://drive.google.com/drive/folders/1asrLEHupz25W5jB_69hmZe3mbWKdrknf?usp=sharing
1. 引言
通过相机对打印后的数字图像进行拍摄,可能会带来图像非法获取和分发的问题。为此可事先在待保护的数字图像中嵌入水印,即使打印的含水印图像被相机捕获,也能保证照片中水印的完整性,从而达到版权保护和溯源的目的。相较于数字环境,打印-拍照(Print-Camera, P-C)过程引入的噪声更为复杂,如打印机的类型、相机的分辨率和拍摄环境等都会直接影响水印提取的精度,传统的鲁棒水印方法很难适用于抗P-C的场景。为此,本文提出了一种基于端到端框架的抗P-C图像水印方案。
2. 方法概述
本文提出的端到端框架主要包括四个模块:编码器、鉴别器、失真网络和解码器,见图1。基于U-Net结构的编码器用于将原始图像和水印串联起来生成含水印图像。通过加入对原始图像的下采样反馈,使得编码器对每一层的下采样特征信息学习更加充分并增强原始图像和含水印图像之间的相似度;为了提高含水印图像的生成质量,鉴别器被用来监督编码器的训练并判断其输入的结果是否含有水印;失真网络用于攻击含水印图像,它由数学模型和P-C噪声模拟网络(Noise Simulation Network, NSN)组成。由于数学模型难以完全模拟出真实P-C过程中存在的噪声,因此NSN用于补充被忽略的噪声并减少数学模型带来的过拟合噪声,如图2所示;含有空间变换网络(Spatial Transformer Network, STN)的解码器可在提高对输入图像的几何不变性的同时提取出嵌入的水印。通过使用STN,水印提取层对P-C过程产生的畸变具有更强的鲁棒性。本文提出的基于JND的多任务损失函数可用于降低含水印图像的失真度。具体方法细节可参见论文。
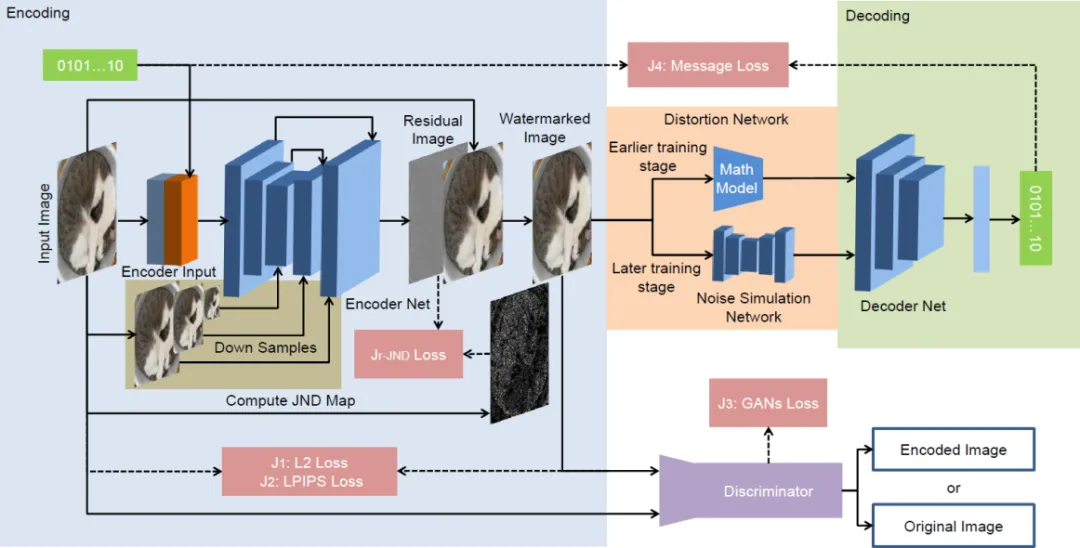
图1 本文提出的抗打印-拍照的图像水印方法流程图
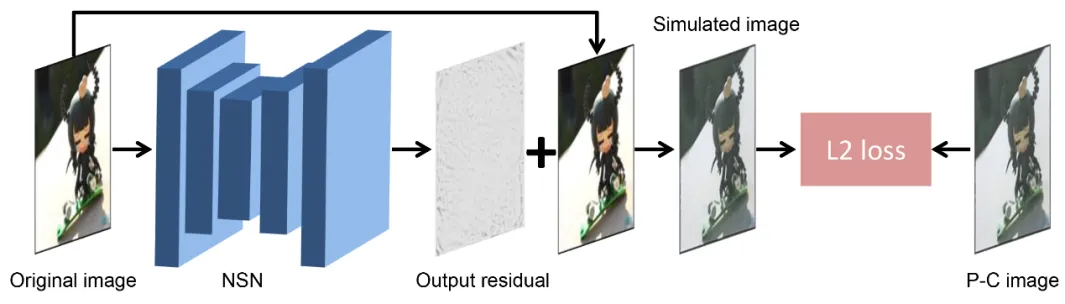
图2 噪声模拟网络NSN示意图
3.实验结果
实验通过NSN的噪声模拟效果、含水印图像视觉质量、鲁棒性以及水印嵌入容量几个方面来评估本文方法的性能,图3为一组经由NSN模拟的噪声图像示例图。表1为含水印图像视觉质量(PSNR和SSIM)的比较结果。对于鲁棒性,本文分别在数字环境下和真实环境下进行了比较。图4为一组在数字环境下针对图像缩放和运动模糊的鲁棒性实验结果。表2和表3为真实P-C环境下对于不同拍摄角度和距离的鲁棒性实验结果。表4则分析了不同嵌入容量对模型性能的影响。其中,ε用于评估解码信息的平均准确率,即鲁棒性。

图3 NSN网络模拟效果示例图。(a1)-(e1)为原始图像,(a2)-(e2)真实的P-C图像,(a3)-(e3)为模拟图像。
表1 含水印图像生成质量的比较结果
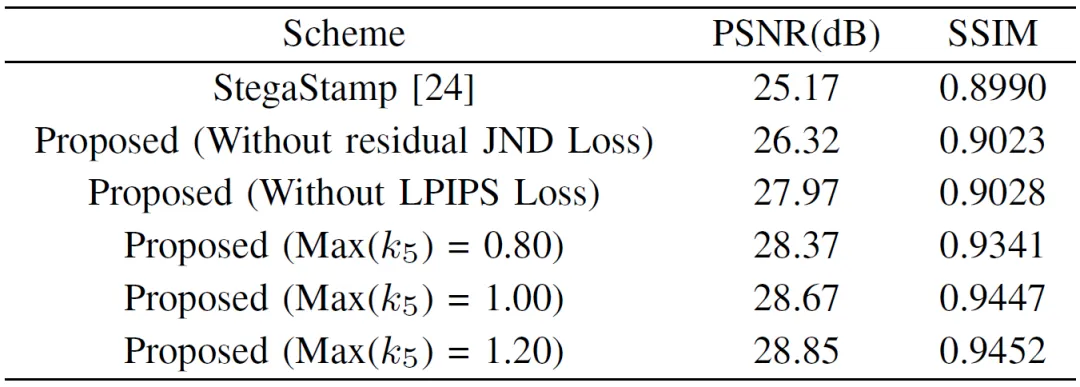
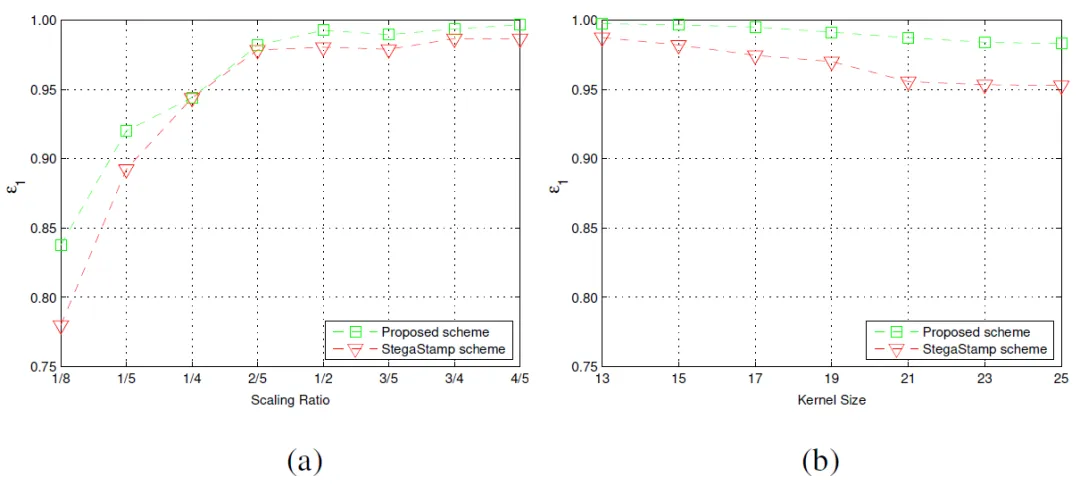
图4 针对图像缩放和运动模糊的鲁棒性比较。(a)图像缩放,(b)运动模糊。
表2 不同拍摄角度下的鲁棒性比较
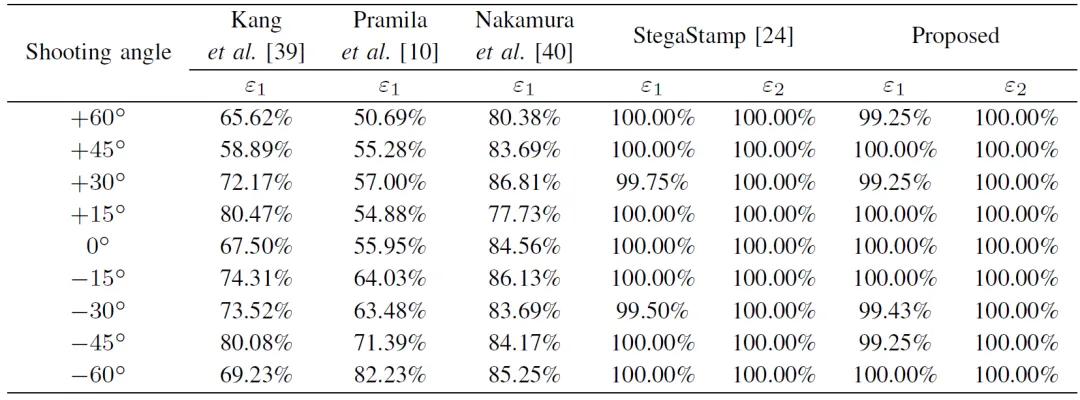
表3 不同拍摄距离下的鲁棒性比较
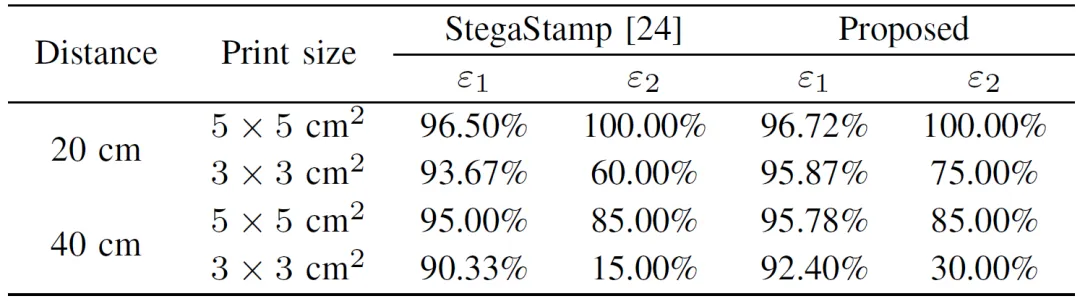
表4 不同嵌入容量下模型的性能比较
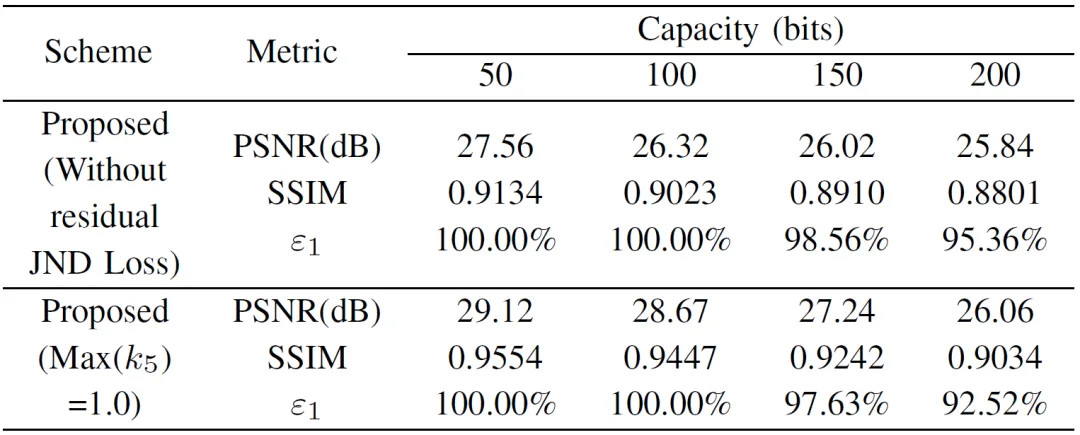
实验结果表明,本文方法在保证嵌入容量和含水印图像质量的同时,能够实现对P-C过程的强鲁棒性,在图像版权保护和溯源追踪等方面具有重要的应用价值。
03
Towards Continual Egocentric Activity Recognition: A Multi-Modal Egocentric Activity Dataset for Continual Learning
作者:
许林峰*,吴庆波*,潘力立*,孟凡满*,李宏亮,贺驰原,王涵昕,程少旭,戴禹
单位:
电子科技大学
邮箱:
lfxu@uestc.edu.cn;
qbwu@uestc.edu.cn;
lilipan@uestc.edu.cn;
fmmeng@uestc.edu.cn;
hlli@uestc.edu.cn;
202121011634@std.uestc.edu.cn;
hxwang09@std.uestc.edu.cn;
202222011833@std.uestc.edu.cn;
ydai@std.uestc.edu.cn
论文:
https://ieeexplore.ieee.org/abstract/document/10184468
代码:
https://ivipclab.github.io/publication_uestc-mmea-cl/mmea-cl
*通讯作者
1.引言
近年来,基于深度学习的行为识别技术得到了飞速发展,然而,大多数现有数据集采用第三人称视角,限制了模型的视觉感知能力。相比之下,第一人称视频捕捉个体执行动作时的视角,能够提供更为沉浸的体验。可穿戴设备的发展使得大规模第一人称视频的收集更加便捷,这推动了计算机视觉研究从“旁观者”向“参与者”转变。现如今,第一人称行为识别已广泛应用于人机交互、医疗监控、自动驾驶、具身智能等领域。第一人称视频中的人类行为识别面临着诸多挑战,包括快速变化的视角、动态背景的缺失以及关注点的不同。惯性传感器数据(如陀螺仪和加速度计)提供的位置和方向信息可以弥补视觉数据的不足。尽管结合视觉和传感器数据的多模态学习研究颇具价值,但由于缺乏相关数据集,其发展较缓慢。此外,随着通用人工智能技术的发展,探索深度神经网络(DNN)在开放世界中的连续学习能力成为一大研究热点,但针对多模态第一人称连续行为识别的研究仍然不足。
2.数据集
本文构建了面向第一人称视角的持续行为识别数据集UESTC-MMEA-CL。其包含了32个开放环境下的日常行为类别,共计超过30小时的行为实例片段,是当前面向开放场景规模最大的第一人称行为识别数据集。如图1所示,其中每一个行为实例片段包括时间上同步的第一视角视频、加速度计和陀螺仪时序传感序列。与其它面向第一人称视角的行为识别数据集不同,UESTC-MMEA-CL专为研究面向第一人称行为识别的连续学习任务而建立,包含充足的日常行为类别与类平衡的可训练行为数据,支持多种增量任务的划分。
3.基线模型与方法
多模态行为识别模型:图2是面向视频图像、加速度计序列、陀螺仪序列的多模态行为识别模型。来自多个时间采样片段的多模态信息使用时间滑动窗(Temporal Binding Network,TBN)进行随机组合得到一个窗口的输入数据。其中视频帧提取器使用BN-Inception进行视觉特征提取,预处理后的加速度计和陀螺仪传感序列使用DeepConvLSTM进行运动信息特征提取。模型先将每一个窗口得到的多模态特征进行融合得到每一个窗口的预测结果,随后将各个时间窗口的预测结果取平均进行综合。
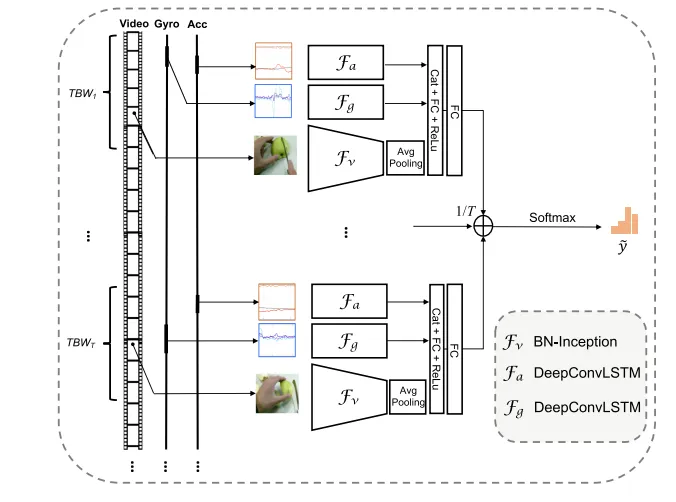
图2 多模态行为识别模型
连续学习基线:本文评估的代表性连续学习基线方法包括了:Finetune(微调)、LwF(知识蒸馏)、EWC(参数保护)、iCaRL(基于回放数据)。
4.实验结果
一般行为识别:本文使用了三种多模态融合架构(TBN、MAFnet、MM-GCN)进行了一般行为识别任务的相关评估实验,表1是评估结果的展示。
表1 多模态行为识别评估结果

持续行为识别:图3展示了在Finetune条件下进行持续行为识别任务的实验结果。本文发现,在持续行为识别任务上,模型的灾难性遗忘是严重的:其中传感器模态的遗忘情况相比一般视觉模态更加严重,且使用多模态信息进行持续行为识别任务会比仅使用视觉单模态更困难。
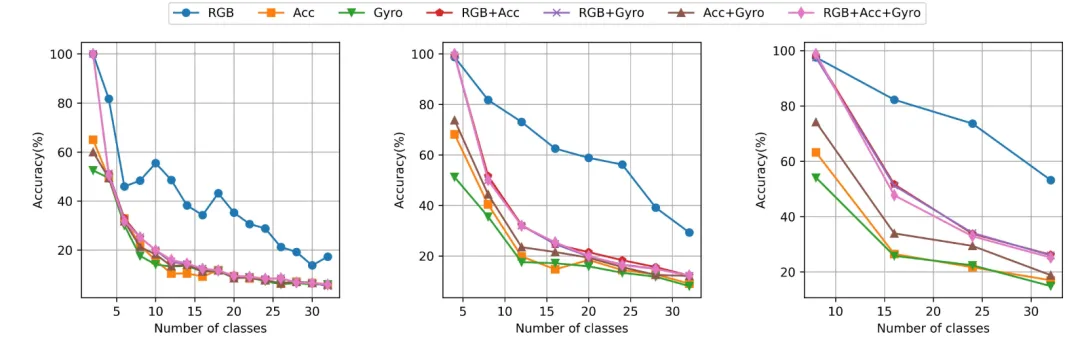
图3 多模态持续行为识别评估结果(Finetune)
图4展示了使用具有代表性的连续学习方法优化持续行为识别任务的实验结果,与单一视觉模态不同,使用LwF、EWC这些正则化方法对于传感模态和多模态模型的性能改善并不显著,且视觉-传感多模态模型的表现均不如单一视觉模态。
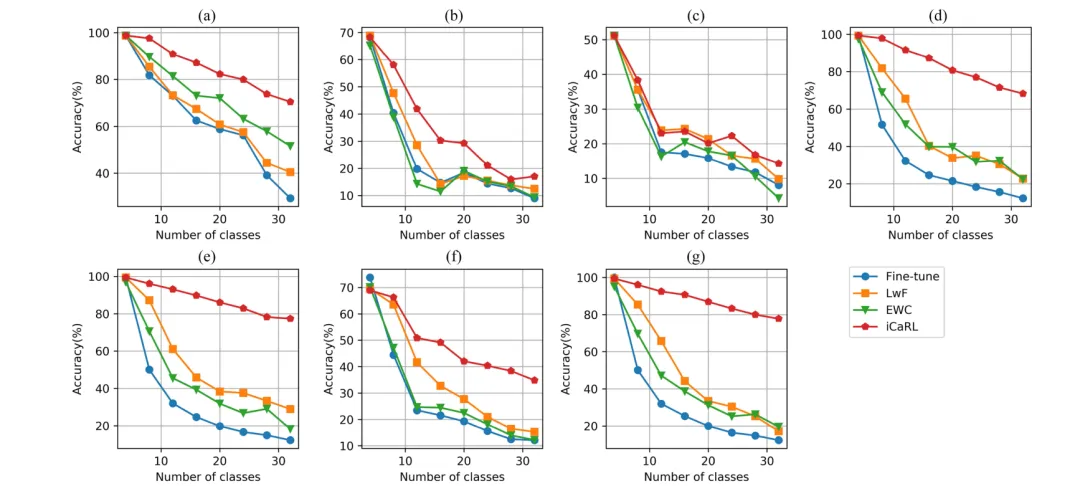
图4 使用连续学习方法优化后的多模态持续行为识别评估结果
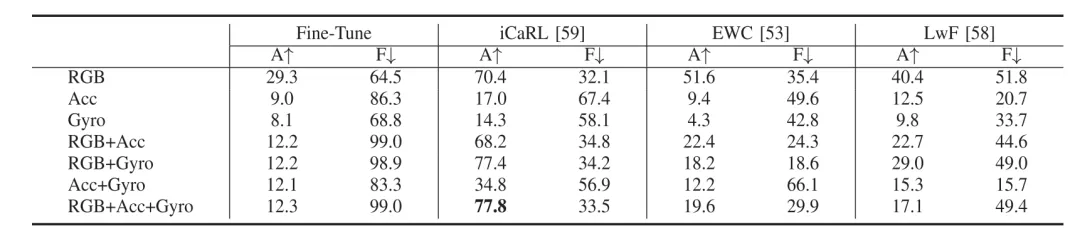
除此之外,如表2所示,通过数据回放(iCaRL)可以有效改善传感器模态的持续行为识别性能,并且在视觉-传感多模态模型下的持续行为识别性能优于单一视觉模态。
表2 多模态持续行为识别的平均准确率A(%)与平均遗忘率F(%)
04
Deep Neighborhood Structure-Preserving Hashing for Large-Scale Image Retrieval
作者:
秦琦冰1,2,谢坷珍2,张文锋3,王成端1,*,黄磊2,*
单位:
1潍坊学院,2中国海洋大学,3重庆师范大学
邮箱:
qinbing@wfu.edu.cn;
huangl@ouc.edu.cn
论文:
https://ieeexplore.ieee.org/document/10177242
*通讯作者
1.研究背景和动机
凭借低存储代价和高查询效率的优势,深度哈希学习已经成为了当前大规模图像检索领域的研究热点之一。现有的深度哈希框架通常采用基于pair-wise或者triplet-wise目标函数进行模型优化,并将样本对之间的相似度阈值设置为常量参数。以triplet-wise目标函数为例,所有的三元组样本之间的相似度阈值为固定的。在训练过程中,如果样本对之间的相似性超过了给定的阈值,深度哈希模型将学习不到任何有价值的信息,产生的哈希编码难以保持原始空间的邻居关系。以图1为例,由于Dogs 和 Wolves属于同一物种,图1-(a)中负样本对(Dogs,Wolves)之间相似性阈值应该小于图1-(b)中负样本对(Dogs,Airplanes)之间相似性阈值。然而现有的深度哈希学习策略通常将所有训练样本之间的相似性阈值设置为统一的常量参数,会导致训练过程中的模型崩塌。
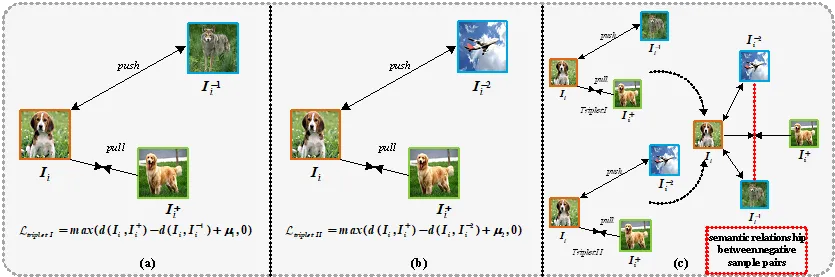
图1 基于近邻结构保持的深度哈希框架研究动机
2.研究方法
通过引入区分性原始特征计算样本对之间的相似性阈值,本文提出了一种基于近邻结构保持的深度哈希学习框架来产生具有区分性的哈希编码。具体的深度哈希学习框架如图2所示,总体包括三个部分:(1)通过提取区分性的目标特征来计算样本对之间的相似性阈值,本文设计了一种基于自适应阈值的四元组排序损失来保持原始空间的潜在近邻结构,保证学习到的哈希编码具有良好的类内聚敛性和类间分离性。(2)基于四元组损失优化,本文采用了一种四元组正则化约束来减少哈希学习中的量化误差。(3)通过联合学习哈希位的平衡性和独立性,本文设计了一种离散化约束损失来减少不同哈希位之间的信息 冗余,提升所学习到的哈希编码的区分性。
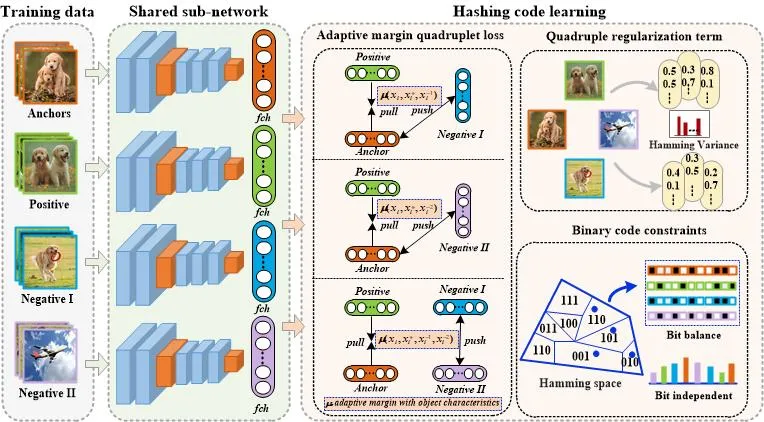
图2 本文所提方法的总体框架图
3.实验结果与分析
为了验证本文所提方法的有效性,分别在CIFAR-10、NUS-WIDE、MIRFLICKR-25K以及 MS COCO四个公开数据集上与多个主流的传统哈希/深度哈希进行了对比实验,具体实验结果如下所示。表1中展现了四个公开数据集上基于16-bits、32bits和64bits的mAP结果。此外,在CIFAR-10上,我们还绘制了128位哈希编码的t-SNE结果图,具体结果如图3所示。
表1 CIFAR-10、NUS-WIDE、MIRFLICKR-25K以及 MS COCO数据集上基于16-bits、32bits和64bits的mAP结果
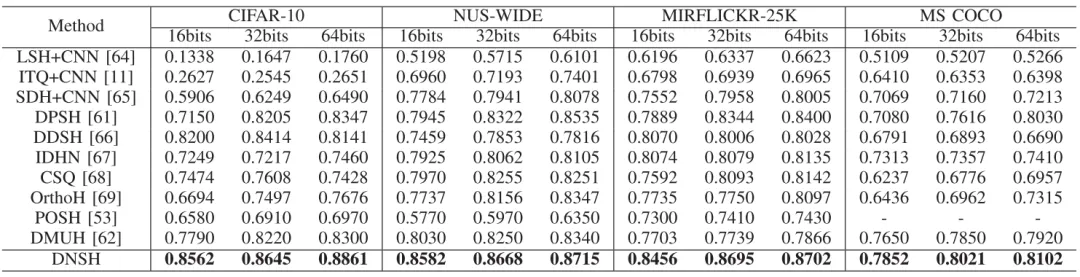
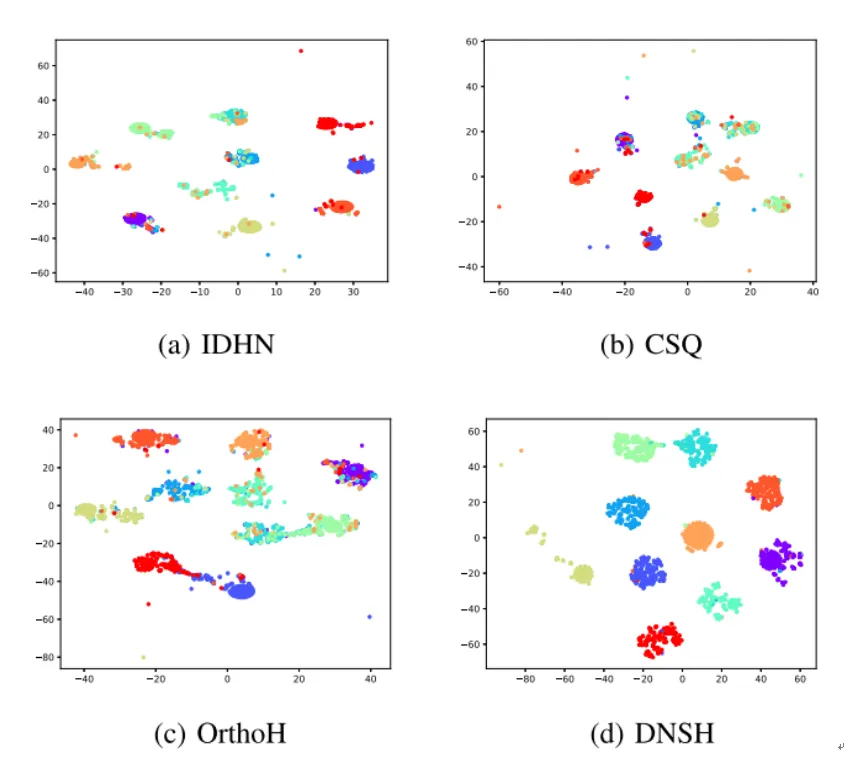
图3 CIFAR-10数据集上基于128位哈希编码的t-SNE可视化结果
05
Coarse-to-Fine Depth Super-Resolution with Adaptive RGB-D Feature Attention
作者:
张帆1,柳娜1,段福庆1*
单位:
1北京师范大学人工智能学院
邮箱:
fqduan@bnu.edu.cn
论文:
https://ieeexplore.ieee.org/document/10209231
*通讯作者
1.研究背景
深度图可以为环境感知和理解提供有效的三维信息约束,在三维重建、自动驾驶等领域有着广泛的应用。然而,受到硬件条件和成像过程的限制,深度图会受到传感器噪声、边缘受损和分辨率低等多种退化的影响。为了提高深度图的空间分辨率和图像质量,基于RGB-D数据的深度图超分辨率方法利用同一场景的彩色图像来提供额外的结构信息。然而,彩色纹理和深度结构之间存在不一致性,已有的方法直接融合这两种特征或是采用手工算子对彩色图像的特征进行筛选,可能会导致纹理复制等伪影。
2.方法概述
针对上述问题,本文提出了一种基于RGB-D特征自适应注意的由粗到精深度图超分辨率方法,包含CONet和RFNet两个子网络。总体网络结构如图1所示。
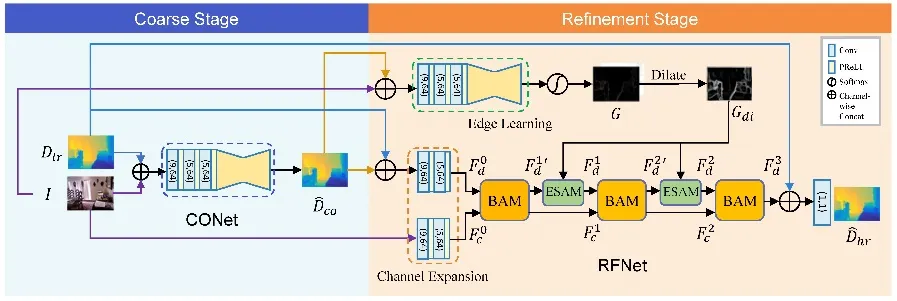
图1 网络总体结构示意图
(1)粗糙阶段
该阶段中的CONet负责进行低分辨率深度图的预处理,通过所提出的粗糙监督策略(Coarse Supervision Strategy),使CONet对输入的低分辨率深度图进行初步的去噪和超分辨率处理,减轻深度图中的噪声和模糊等退化,并输出粗糙的超分辨率深度图,提高网络应对大倍率超分辨率的能力。
(2)精细化阶段
精细化阶段的RFNet采用3个分支注意力模块(BAM)和2个边缘感知的空间注意力模块(ESAM)来学习互补的RGB-D特征,
BAM的结构如图2左侧所示,该模块利用双分支结构的通道自注意力机制,结合残差学习,对输入的深度图像特征和彩色图像特征自适应地分配权重,抑制纹理复制伪影,输出融合后的RGB-D特征。ESAM的结构如图2右侧所示,对输入的中间级特征计算空间注意力图,并结合边缘学习网络提取的边缘引导信息,得到边缘感知的空间注意力图,可以提高网络对长距离依赖关系的捕捉能力,提升深度图重要区域的细节恢复效果。
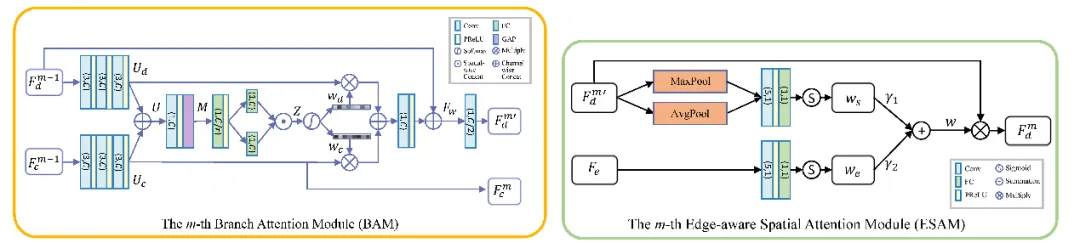
图2 BAM模块(左)和ESAM模块(右)的详细结构
3.实验结果
本文在RGB-D-D、NYU Depth v2和Middlebury Stereo数据集上与目前的先进方法进行了对比实验(2×、4×、8×、16×)。实验结果表明,所提方法可以抑制纹理复制现象并恢复准确的边缘结构,在定量和定性评估中均取得了优秀的效果。本文在有噪声Middlebury数据集上实验结果如表1和图3所示。
表1有噪声Middlebury数据集上的定量实验结果(MAD)
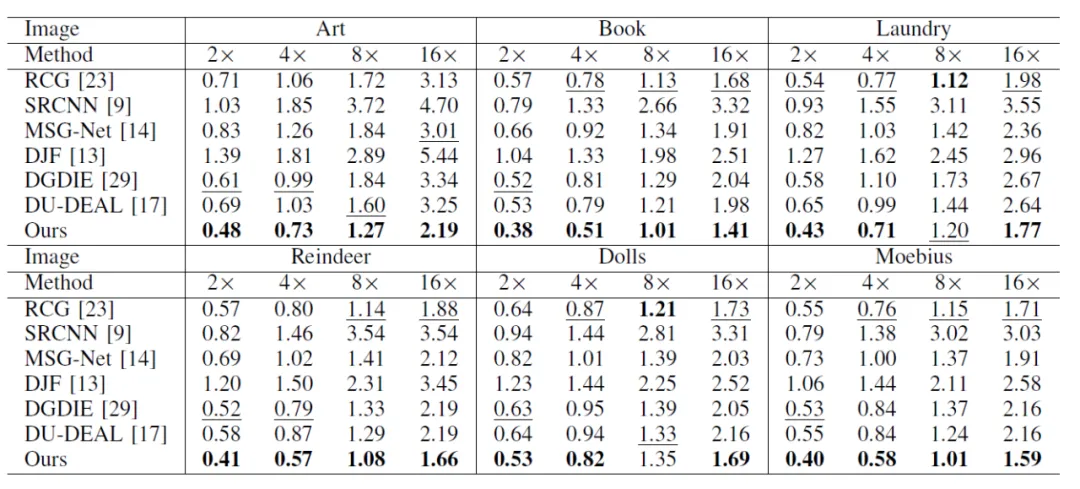

图3有噪声Middlebury数据集中Laundry 的16× 超分辨率实验结果对比

编辑人:吴建龙、任文琦
专委会责任副主任:张勇东

微信扫一扫
关注该公众号
 京公网安备11010802017125号
京公网安备11010802017125号