
【论文导读】2024年论文导读第十四期
【论文导读】2024年论文导读第十四期
CCF多媒体专委会 2024年07月16日 17:32 北京


论文导读
2024年论文导读第十四期(总第一百零五期)
目 录
|
1 |
Balanced Classification: A Unified Framework for Long-Tailed Object Detection |
|
2 |
Show Me a Video: A Large-Scale Narrated Video Dataset for Coherent Story Illustration |
|
3 |
Exploiting Multi-Scale Parallel Self-Attention and Local Variation via Dual-Branch Transformer-CNN Structure for Face Super-Resolution |
|
4 |
An Adaptive Sample Assignment Network for Tiny Object Detection |
|
5 |
Dynamic Confidence Sampling and Label Semantic Guidance Learning for Domain Adaptive Retrieval |
01
Balanced Classification: A Unified Framework for Long-Tailed Object Detection
作者:
齐天浩,谢洪涛*,李攀登,葛健男,张勇东
单位:
中国科学技术大学
邮箱:
qth@mail.ustc.edu.cn;
htxie@ustc.edu.cn;
lpd@mail.ustc.edu.cn;
gejn@mail.ustc.edu.cn;
zhyd73@ustc.edu.cn
论文:
https://ieeexplore.ieee.org/abstract/document/10225715
代码:
https://github.com/Tianhao-Qi/BACL
*通讯作者
1.论文简介
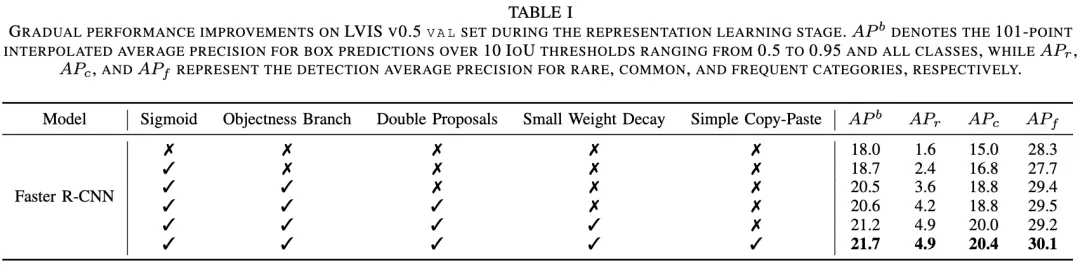
传统的检测器在处理长尾分布的数据时,由于分类偏向于有多数样本的头部类别,检测性能会急剧下降。本文认为这种分类偏差源于两个因素:1)前景类别分布不平衡导致的不平等竞争,2)尾部类别样本多样性不足。为解决这些问题,我们引入了一个名为BACL(平衡分类)的统一框架,该框架能够自适应地纠正类别分布差异引起的不平等竞争,同时能增强样本多样性。具体来说,我们提出了一种新的前景分类平衡损失(FCBL),通过引入成对的类别感知边距和自动调整的权重项来缓解头部类别的主导地位,并将注意力转移到难以区分的类别上,防止尾部类别在不平等竞争中被过度抑制。此外,我们还提出了一个动态特征幻觉模块(FHM),通过在特征空间中合成幻觉样本来增强尾部类别的表示,引入额外的数据多样性。在这种分而治之的方法中,BACL在具有挑战性的LVIS基准上取得了新的最先进水平,相比于使用ResNet-50-FPN的原始Faster R-CNN,我们的方法在总体和尾部类别上的AP分别提高了5.8%和16.1%。大量实验证明,BACL在各种数据集和不同的骨干网络和架构上均能实现性能提升。
2.论文方法
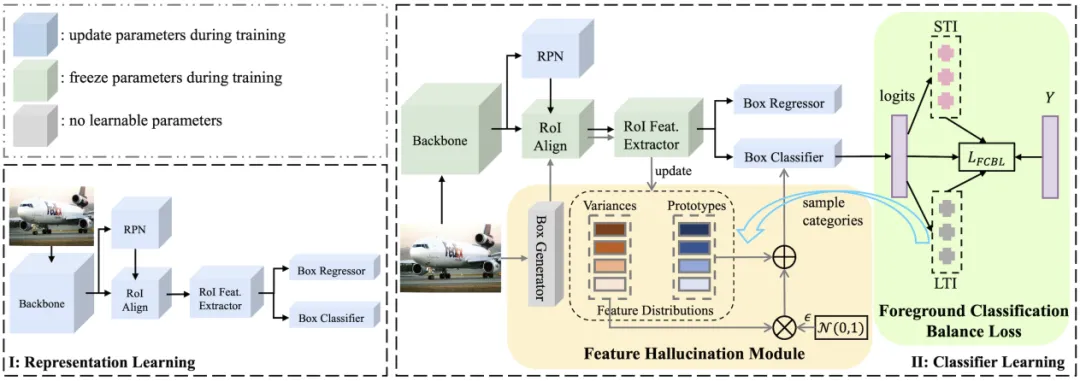
本文针对长尾目标检测提出了一个全新的框架。首先,在表示学习阶段,通过一系列创新的技术,如Sigmoid分类器、Copy-Paste增强等,获取了更鲁棒的特征表示。然后,在分类器学习阶段,通过引入长短时指标对作为前景分类平衡损失FCBL和特征幻觉模块FHM的构建基础,来校准分类偏差,从而使模型更加关注尾部类别的检测。
表示学习阶段
分类器学习阶段
1)长-短时指标对

2)前景分类平衡损失FCBL
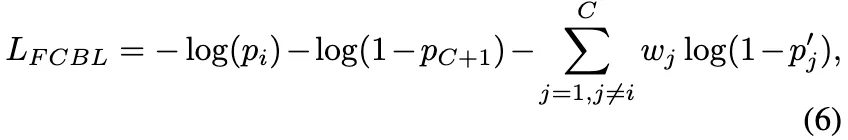
FCBL主要在任何一对前景类别之间引入了一个适应性类别感知边缘(adaptive class-aware margin),以改善一个类别对另一个类别的支配作用。该边缘与相应长期指标的比率成对数比例。其次,自然数据和长尾数据集通常具有大的词汇集,这增加了训练分类器的难度。因此,FCBL 集成了一个自动调整的权重项。这个自动调整的权重项的引入旨在优先考虑混淆类别,同时忽略良好分类的类别。简单来说,FCBL 通过引入适应性类别感知边缘和自动调整的权重项,有效地解决了不同前景类别之间不平等的竞争问题。适应性边缘帮助分类器感知类别差异并动态调整抑制梯度的幅度。自动调整的权重项有助于区分易混淆类别和分类良好的类别。这两个组件共同使 FCBL 能够在长尾分布场景中改善前景类别之间的不平等竞争,从而提高了分类器的泛化能力。
3)特征幻觉模块FHM
虽然 FCBL 可以解决前景类别之间的不平等竞争问题,但它无法解决尾部类别的样本稀缺问题。FHM 旨在解决尾部类别的代表性不足问题,它首先实时捕捉每个类别的特征分布,然后根据长期指标的指导为选定的类别生成训练特征。接下来它为出现在batch中的每个类别计算特征的均值和方差,然后使用指数移动平均函数更改相应的原型和方差。最后,FHM 通过为每个类别分配一个与长期指标成反比的采样概率来更加关注尾部类别,并随机选择数个类别后通过重参数化技巧为每个类别生成若干幻觉特征作为补充样本。
3.实验
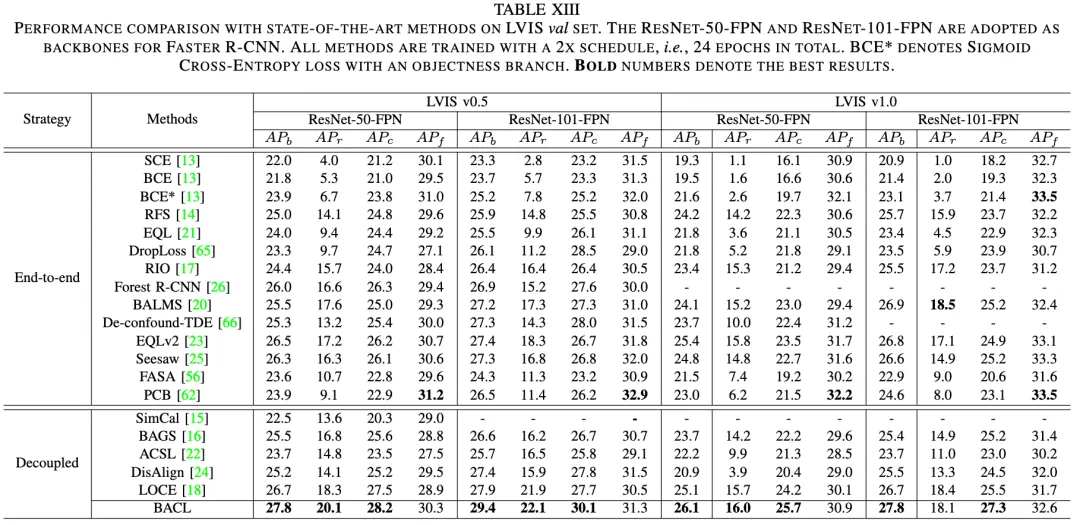
BACL框架在LVIS数据集的两个版本(LVIS v0.5 & LVIS v1.0)上表现出色,与当前最先进的方法相比取得了显著的优势。特别是在使用ResNet-50-FPN和ResNet-101-FPN骨干时,BACL在总体AP方面均取得了优异成绩。
1)稀有类别检测:BACL在稀有类别的检测上特别出色,不仅超过了端到端训练方法,还在解耦训练方法中实现了20%以上的AP。
2)常见类别检测:BACL不仅在稀有类别上表现优异,还在常见类别上实现了明显的提升。
3)不同骨干结构的适应性:无论是较小的ResNet-50-FPN,还是较大的ResNet-101-FPN骨干,BACL都展示了卓越的性能,证明了其广泛的适用性和灵活性。

02
Show Me a Video: A Large-Scale Narrated Video Dataset for Coherent Story Illustration
一个用于连贯长故事展示的大规模叙述视频数据集
作者:
路雨1,倪飞跃2,王浩帆3,郭晓锋3,朱霖潮1*,杨宗鑫1,宋睿华2,程乐乐3,杨易1
单位:
1浙江大学,2中国人民大学,3快手
邮箱:
aniki.yulu@gmail.com
论文:
https://ieeexplore.ieee.org/abstract/document/10195243
代码:
https://nfy-dot.github.io/CVSV-dataset/
*通讯作者
1. 引言
在多媒体研究中,用视觉内容阐释多句长故事是一个重大挑战。尽管以前的工作集中在图像层面上的故事到视觉的顺序展示,或用视频片段表示单个句子,但用连贯的视频展示长篇多句故事仍然是一个未被充分探索的领域。在本文中,我们提出了基于视频的故事展示任务,该任务专注于用检索到的视频片段来视觉上阐释多个句子的长故事。为了支持这项任务,我们首先创建了一个大规模的数据集,其中包含8,5000个叙述性故事和长视频对,每个故事有60对视频片段和文本句子,一共有472万视频-文本对。然后,我们提出了故事上下文增强模型,受到语言理解中序列建模的启发,该模型利用故事中的局部和全局上下文信息。通过全面的定量实验,我们展示了我们基线模型的有效性。此外,定性结果和详细的用户研究揭示了我们的方法可以从故事中检索出连贯的视频序列。
2. 数据集
我们收集了Coherent Video Story Visualization (CVSV) 数据集,该数据集包含来自在线视频平台的各种电影解说视频,用于顺序故事建模,并确保故事段落能够连贯地描述视频内容。其中包含85000个故事-视频对,每个故事-视频对由60对一致的句子和连贯的片段组成,其中句子来自叙述性故事,而不是独立的描述。我们选择电影解说视频作为我们的数据源,以构建高质量视频和故事的数据集,因为它们固有的讲故事和全局视觉连贯性。
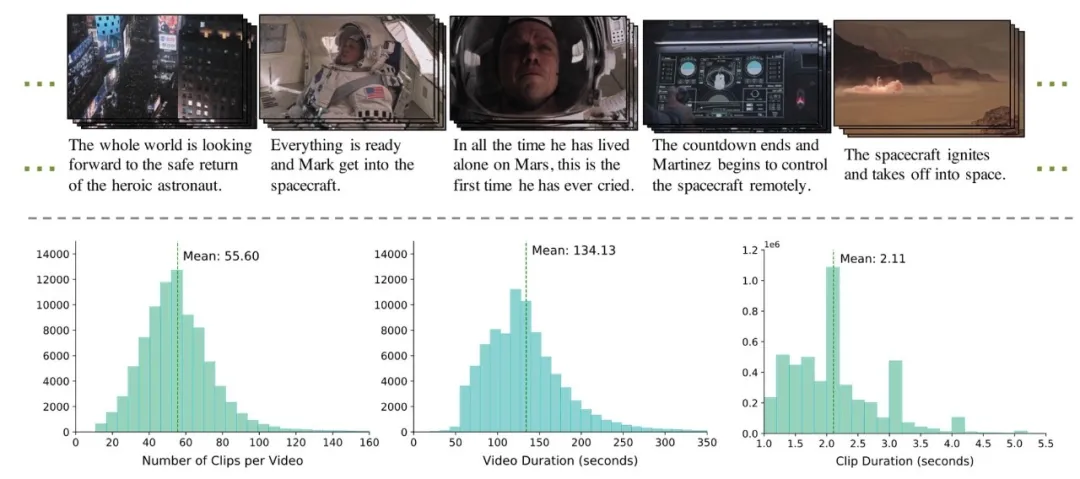
图1 典型的Coherent Video Story Visualization (CVSV) 数据集示例(上图),以及数据统计分布信息(下图)
3.方法
故事上下文增强模型(Story Context-Enhanced Model, SCEM)的概览如图2:
1)预训练编码器提取特征:模型首先使用预训练的视频编码器和文本编码器从原始片段和句子中提取特征。
2)上下文增强单元融合特征:接着,应用故事上下文增强单元,将句子表示与整个故事的上下文信息融合。
3)故事-视频对比训练:最后,模型通过故事-视频对比(Story-Video Contrast)进行训练,该训练方法在局部和全局层面对齐故事和视频。
这种模型设计使得SCEM能够捕捉故事中的句子之间以及与视频片段之间的语义关联,进而提高视频检索和故事展示任务的性能。
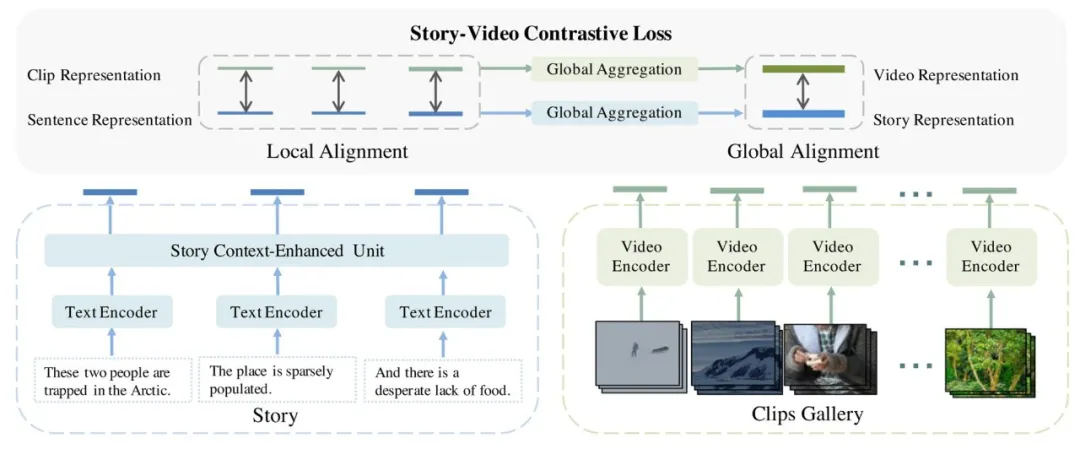
图2 模型框架
4. 实验
表1 和其他方法在CVSV数据集上的比较
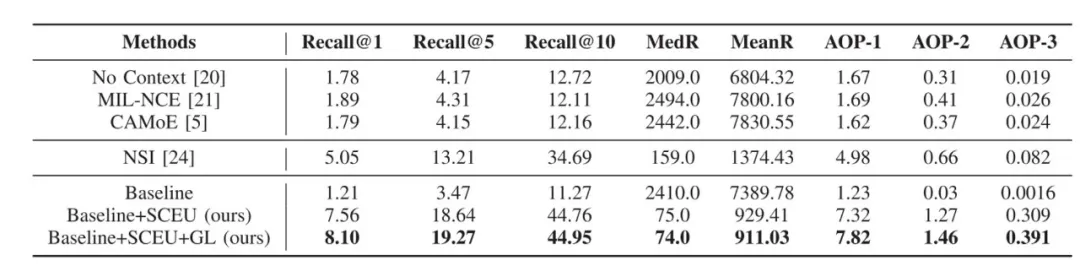
如表一所示,我们的方法相比于其他的方法在召回率上取得了显著的提升,其中SCEU模块剧烈的将Recall@1从1.21提升到了7.56,这证明了在这种多文本视频检索问题上,建模故事全局相关性的重要性。

图3 定性结果比较
如图三所示,相比较“无上下文”方法,我们的方法检索到的视频具有视觉和语义上更一致性的结果。而“无上下文”模型的结果则包含有截然不同风格的视频片段。
03
Exploiting Multi-Scale Parallel Self-Attention and Local Variation via Dual-Branch Transformer-CNN Structure for Face Super-Resolution
作者:
史金钢,王雨思,余梓彤,黎冠新,洪晓鹏,王飞,龚怡宏
单位:
西安交通大学软件学院
邮箱:
jingang.shi@hotmail.com
论文:
https://ieeexplore.ieee.org/document/10207832
代码:
https://github.com/jingang-cv/DBTC
1.研究背景
本文提出了一种基于Transformer-CNN双分支的人脸图像超分辨率重建算法。本文重新审视CNN和Transformer模型各自的优缺点,并对各个模型的缺点进行改进,并结合两种模型的优势。该算法采用了Transformer-CNN双分支的设计思想,其中Transformer分支改进自注意力机制,使用平行自注意力模块来同时捕捉人脸图像的局部和非局部依赖,充分利用人脸图像的对称特性。CNN分支则使用基于局部固定卷积的注意力模块,通过捕捉相邻像素间的梯度变化来消除伪影,产生更清晰的细节。最后,提出双分支调制模块结合两种模型的优势,提高网络的重建能力。本文在公开的人脸数据集上进行实验,实验结果表明所提出的算法可以显著增强人脸图像的重建效果,证明了所提出算法的优越性。
2.方法概述
本文所提出的人脸图像超分辨率重建模型是由多个Transformer-CNN双分支模块构成的层级结构。所提出的Transformer-CNN双分支模块主要包含了三个部分:Transformer分支,CNN分支和双分支调制模块。
Transformer分支:在人脸面部图像中普遍存在对称区域,例如两只眼睛,鼻子和嘴。卷积操作的局部性特点无法充分利用这些特性,在探索非局部区域相互关系上有局限性。为了更好地利用人脸图像的对称特性,Transformer分支中改进自注意力机制,将其设计为可以同时探索局部和非局部的依赖关系的并行自注意力机制,用于提取面部图像上不同尺度纹理的分层特征嵌入。
CNN分支:在人脸图像超分辨率重建任务中,输入图片的分辨率往往很低,这造成了传统的卷积操作在重建中难以有效恢复详细的纹理特征。但是人脸有丰富的结构细节,如面部轮廓、面部关键部位等。为了更好地描述人脸图像纹理的局部结构,捕捉相邻像素的变化,本章提出了一种全新的局部固定卷积,其可以探索相邻像素之间的梯度特征,缓解重建过程中的模糊效应,增强模型重建图像边缘的能力。它的核心是利用相邻像素间的梯度特性,以加强对边缘和纹理的重建。
双分支调制模块:Transformer分支用于提取图像块级别的特征,CNN分支用于提取像素级别的特征,在构建Transformer分支和CNN分支后,提出了一个双分支调制块,使两个分支提取的特征能够相互补充,调制融合了这两个分支的优势,从而进一步提高了模型的性能。
3.实验分析
本文在CelebA, CelebAMask-HQ,Helen, FFHQ四个代表性数据集上进行实验和评测,在由16*16到128*128的8倍放大测试条件下,所得到的可视化重建人脸图像结果如图1所示:

图1 (a) Bicubic; (b) SRResNet; (c) RCA; (d) SPARNet; (e) SISN; (f) IGAN; (g) SwinIR; (h) Uformer; (i) 本文算法; (j) HR image
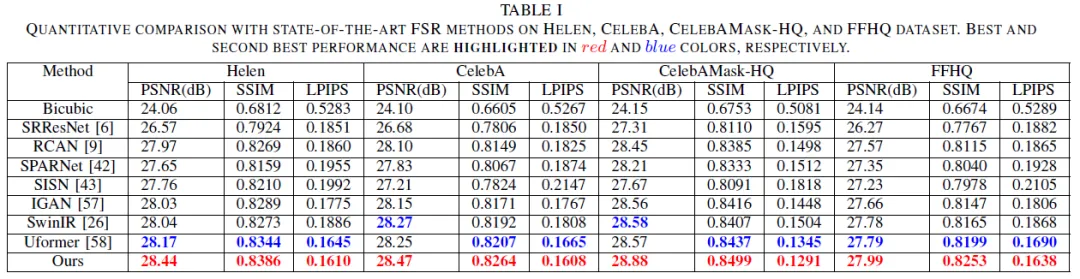
本文针对不同对比算法在各数据集上的数值化评测结果(PSNR,SSIM,LPIPS)如表1所示,本文算法在各数据集上均取得了较优的结果。
针对实际场景所拍摄的照片(如图2),本文算法的超分辨率结果在图3中展示,所生成的重建照片具有更清晰的细节和更为逼真的纹理。

图2 1927年拍摄于索尔维会议的照片

图3(a) Bicubic; (b) SRResNet; (c) RCA; (d) SPARNet; (e) SISN; (f) IGAN; (g) SwinIR; (h) Uformer; (i) 本文算法
04
An Adaptive Sample Assignment Network for Tiny Object Detection
作者:
戴洪浩1,高珊珊1*,黄红1,毛德乾1,张晨昊2,周元峰3
单位:
1山东财经大学,2北京理工大学,3山东大学
邮箱:
dhhtang@163.com;
gsszxy@aliyun.com;
Hh981222@163.com;
Mamba_mdq@163.com;
zachzhang07@163.com;
yfzhou@sdu.edu.cn
论文:
https://ieeexplore.ieee.org/abstract/document/10219068
代码:
https://github.com/DaiHonghao/retinanet_OEPD.git
*通讯作者
1.研究背景和动机
微小目标(一般是指尺度小于32像素的目标)因为存在尺度小、特征信息少和易受环境干扰等问题,准确地判断小目标的位置和类别仍然是目标检测研究面临着的巨大挑战。过小的图像占比,使得小目标检测(Tiny Object Detection,TOD)算法往往需要计算过多的背景区域,如图1.1(a),存在大量计算冗余,并产生了严重的正负样本不平衡问题。另一方面,过小的尺度导致正样本之间具有显著差异,但目前的样本分配方法往往不具备更加细致的划分,使得模型学习过程中无法区分简单标签和困难标签。我们希望设计一种只关注小目标存在区域(图1.1(b))的自适应样本分配策略和使网络聚焦于小目标的语义信息传播方法。因此,创新性地提出一种基于像素级目标存在概率热力图的分配样本策略,结合了anchor-free方法中像素级预测的优势和anchor-base方法中便于样本分配的优势,基于目标存在概率值引导划分正样本、难样本、复杂样本和简单负样本,过滤大多数简单负样本,在一定程度上实现正负样本的平衡。设计了一种自顶向下、逐层聚焦的特征强化方案,有效增强小目标的高级语义信息的传播能力。上述两个解决方案具有很好的泛化和迁移能力,可以应用在任意一阶段和两阶段目标检测网络上,有效增强TOD性能。

图1 小目标存在区域占比示意图
2.方法论述
首先,提出了一个基于目标存在概率判定网络(Object Existence Probability Determination Network,OEPD-Net),该模型为我们提供了每个区域存在微小目标的概率值,为自适应样本分配和自适应裁剪方法提供先验知识。
其次,基于OEPD-Net提出了自适应样本分配方法,依据目标存在概率值和真值,对样本细致划分,为其赋予相应的权重,以提升网络的学习能力。
再次,基于OEPD-Net提出了自适应裁剪算法,依据目标存在概率值,对图像进行自适应裁剪,提升微小目标的相对尺度,同时减少了大量的背景信息,降低计算冗余。
最后,设计了一个聚焦强化模块,依据目标存在概率值,聚焦强化微小目标存在的区域,在强化微小目标特征的同时减少背景噪声的干扰。
依托于OEPD-Net的迁移泛化能力,以经典的RetinaNet为例,依靠OEPD-Net提供的高质量样本和聚焦模块增强微小物体深层语义信息传播的能力,构建了一个高性能的TOD网络。图2展示了该网络的总体结构图。
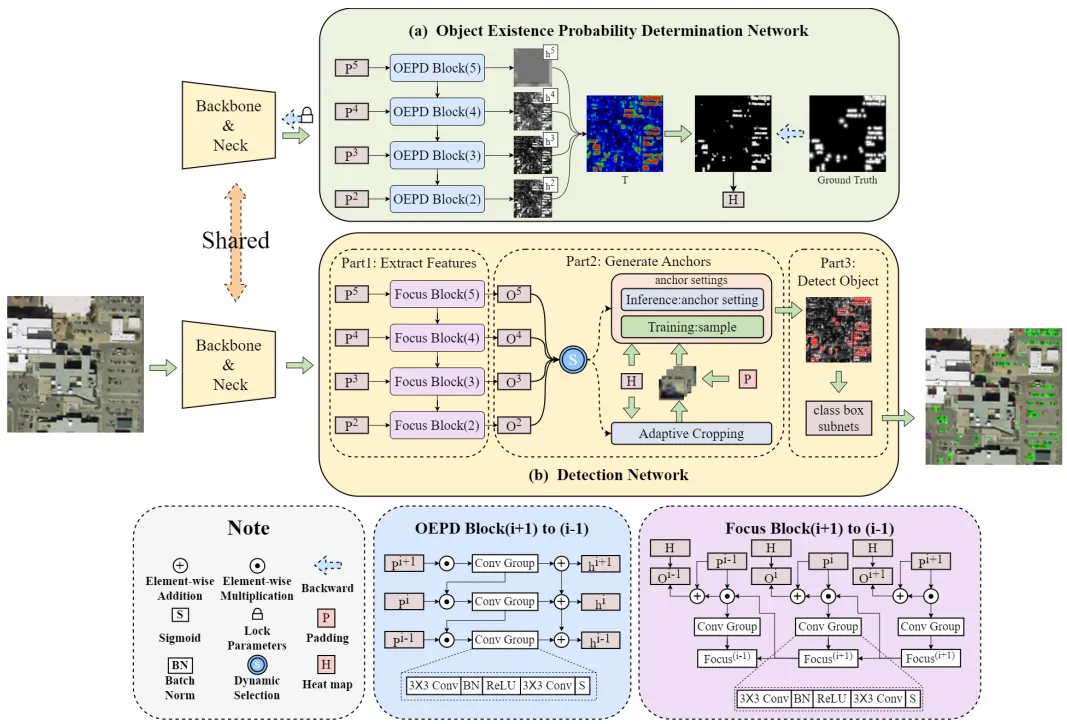
图2 网络架构
3.实验分析
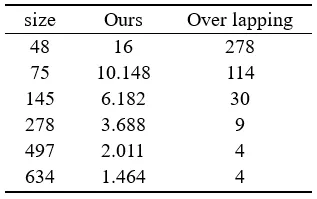
本方法在2个主流微小目标检测数据集上进行了实验,并在AI-TOD数据集上做了消融实验。图3展示了目标真值与所提出的聚焦强化模块的聚焦情况。可见我们的聚焦模块能够适应多种条件,并且可以有效聚焦小目标的位置,忽略绝大多数背景区域。图4和表1分别展示了目标存在概率值的情况,和与其他方法的结果可视化和指标对比。可见本文所提出的方法有效提升了准确率和召回率。图5和表2展示了自适应裁剪的情况和与其他方法的对比可视化和指标对比,可以看到裁剪方法囊括了大部分小目标,同时准确率和召回率有所提升。图6展示了自适应裁剪算法与传统的随机裁剪算法相比情况,可以看到本文所提出的方法中,子图存在目标的占比(裁剪可能出现子图中不存在目标的情况)远远高于随机裁剪。表3展示了自适应裁剪算法与传统的重叠裁剪方法相比,可以看到本文所提出的方法,在子图的数量上远远少于传统方法。

图3 聚焦强化模块的聚焦情况

图4 目标存在概率和与基础方法的对比情况

图5 自适应裁剪结果和其他裁剪方法的检测对比
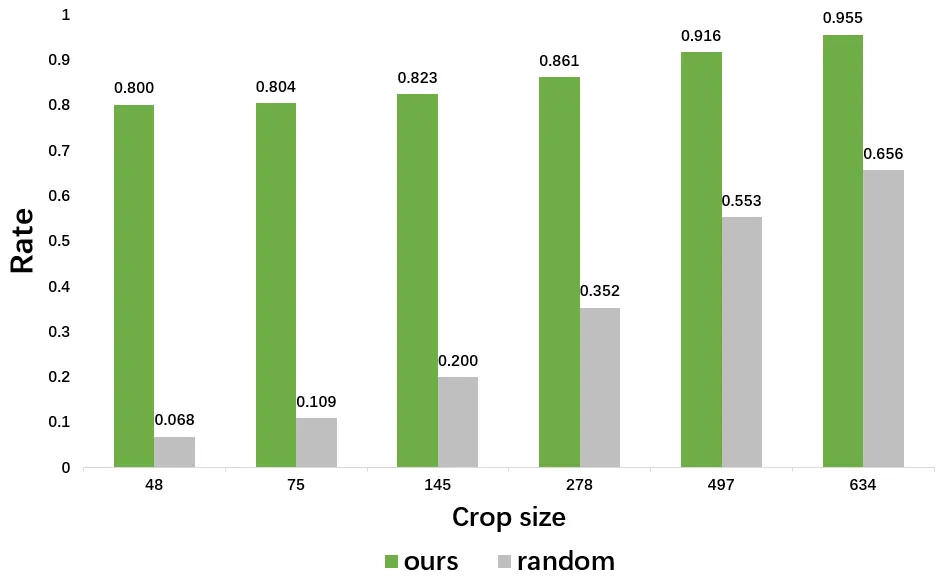
图6 自适应裁剪方法与随机裁剪算法在相同裁剪尺寸下存在目标的子图数量占比
表1 在AI-TOD数据集上与其他方法的对比结果
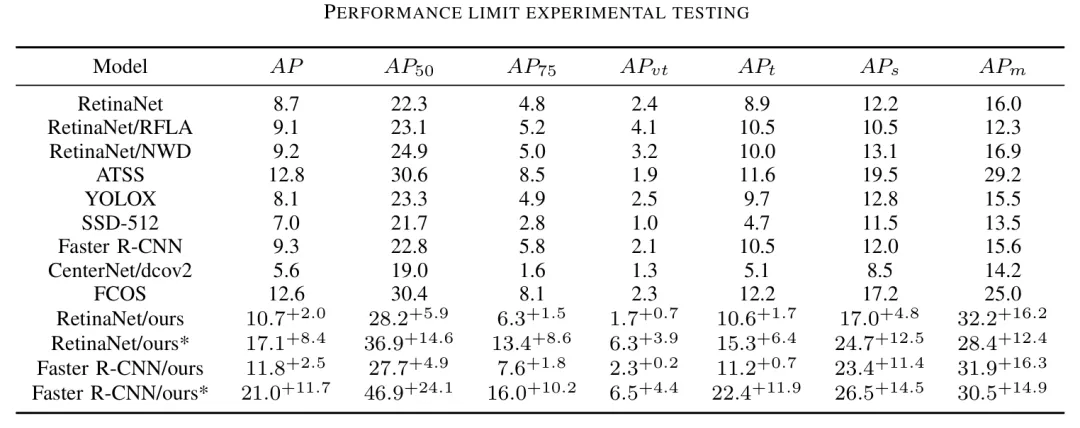
表2在Tiny-Person数据集上与基础方法的对比结果

表3 自适应裁剪算法与重叠裁剪算法的子图数量对比结果
05
Dynamic Confidence Sampling and Label Semantic Guidance Learning for Domain Adaptive Retrieval
动态置信采样和标签语义指导学习的域适应检索
作者:
张巍、周康宾、滕璐瑶*、汤非易、伍乃骐、滕少华、黎坚
单位:
广东工业大学、广州番禺职业技术学院、澳门科技大学
邮箱:
weizhang@gdut.edu.cn;
kb1838388004@163.com;
luna.teng@qq.com
论文:
https://ieeexplore.ieee.org/document/10190169
*通讯作者
1.引言
域自适应检索目的是减少检索过程中源域和目标域之间的域偏移。查询数据集(源域)和检索到的数据集(目标域)分别属于两个不同的域,意味着这两个域之间存在很大的域差异。先前的域适应检索方法忽略了由不正确的伪标签所导致的错误积累和域特定信息导致的域偏移(如图)。我们提出了动态置信采样和标签语义指导学习(DCS-LSG)的域适应检索方法。DCS-LSG的三个贡献如下: (a)动态置信采样(DCS)只选择高置信的目标样本进行训练,减少错误伪标签造成的误差积累;(b)标签语义指导(LSG)学习嵌入标签语义以减少特征与标签之间的语义差异;(c)双投影松弛(DPR)策略分别学习源域和目标域的两个耦合投影矩阵,在两个特定的子空间上学习特定域的信息。因此,在汉明空间中从两个标签语义空间产生有判别性的哈希码。

2.方法介绍
框架图
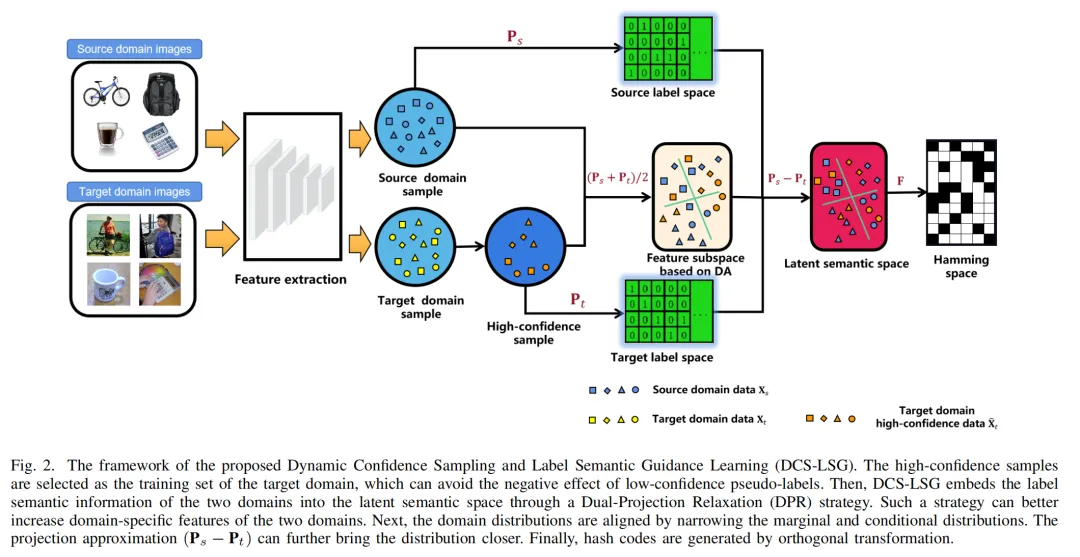
2.1 动态置信采样(DCS)
首先,DCS通过判定两个分类器PTXS和PTXt的预测值是否一致来进行初步筛选。其次,在迭代过程中动态调整两个域分类器的权重,以更好地预测伪标签。最后,通过考虑类选择以避免类的不平衡问题。因此,通过减少低置信度伪标签导致的错误积累,提高了检索性能。
2.2 标签语义指导(LSG)学习
为了充分保留源域的特征信息和标签语义信息,LSG将源域标签和目标域高置信度伪标签嵌入到投影矩阵P中,进行线性回归,以建立两个域中特征和标签语义之间的关系。
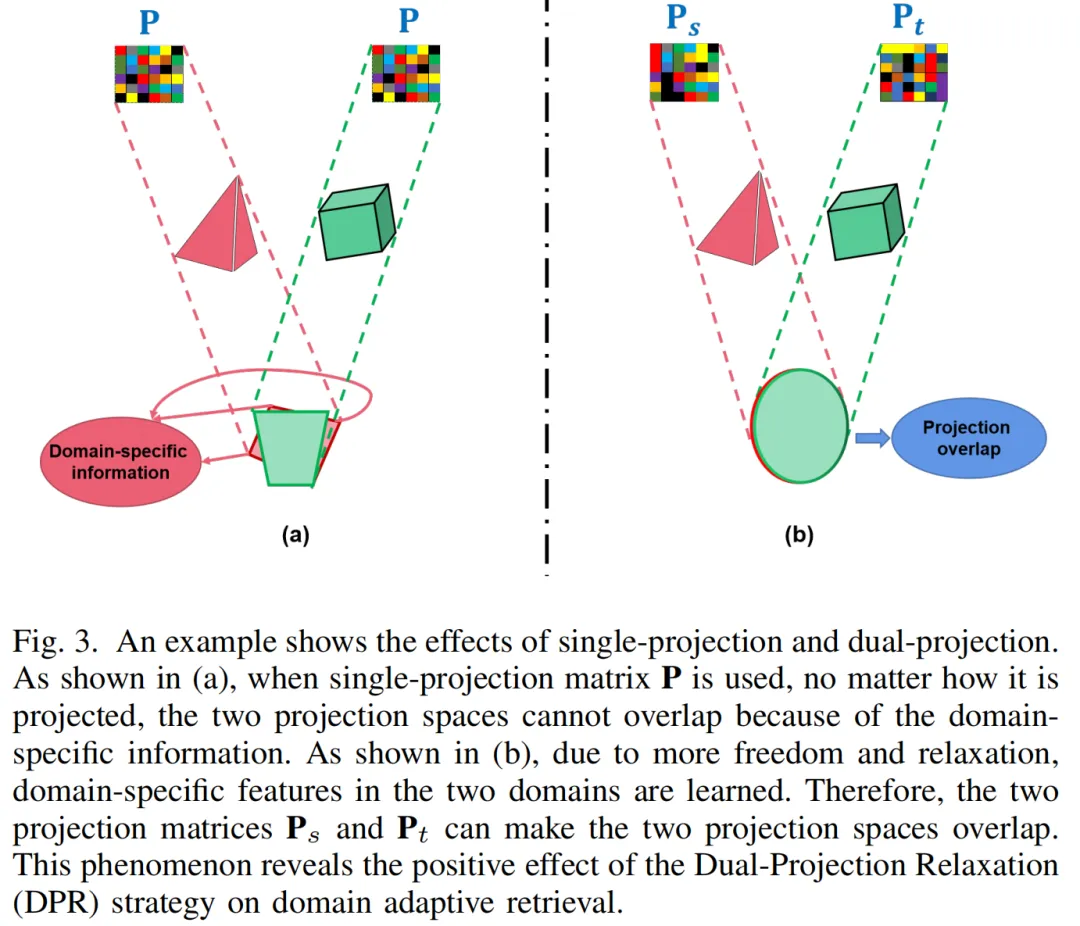
2.3 双投影松弛(DPR)策略
先前的域自适应检索方法通过将源域和目标域投影到一个共同的低维子空间中来保持域的一致性。然而,如图所示,由于存在特定域信息,单投影很难将两个域投影到同一子空间中。双投影松弛(DPR)策略将两个域分别投射到两个不同的子空间中。具体地说,DPR策略分别引入PTXS和PTXt'来学习源域和目标域的知识。如图3 (b)所示,DPR策略具有更多的自由度。在此过程中,LSG和DCS会被相应地修改,都是用双投影策略学习域特定信息。最后,为了保持结构域的一致性,我们最小化了两个投影矩阵Ps和Pt之间的距离。投影近似不仅可以减少分布差异,还可以缩小两个域之间的汉明距离。
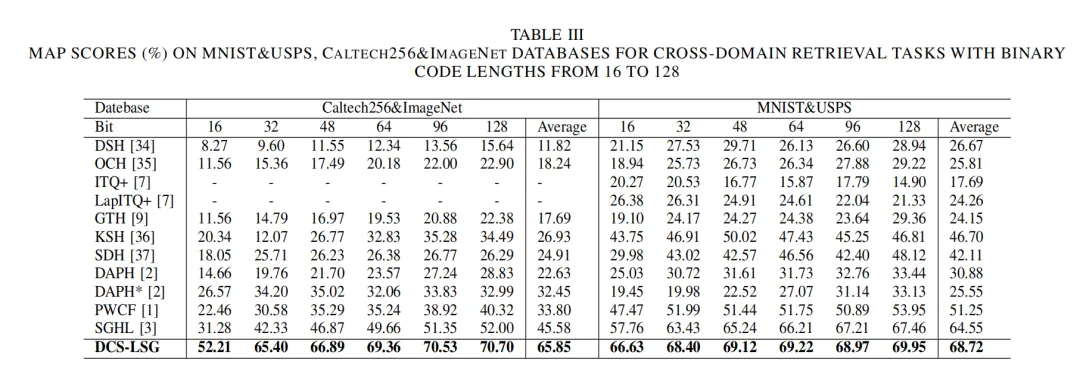
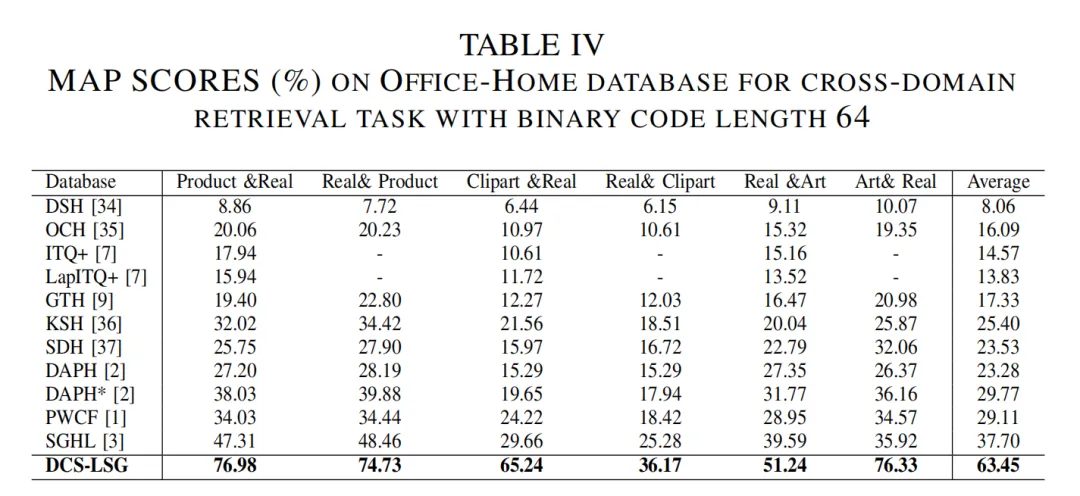
3.实验结果
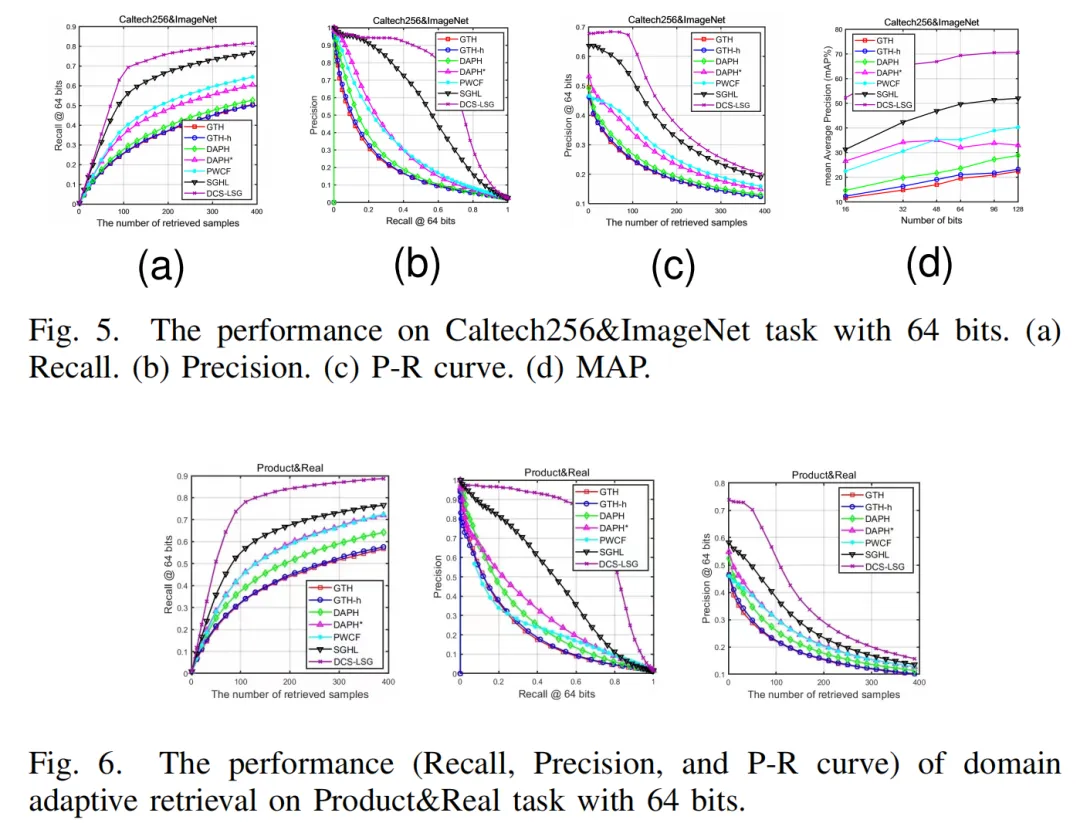
在实验中,我们使用三个数据集(MNIST+USPS, Cross-dataset Testbed, 和 Office-Home)来验证所提出的方法。DCS-LSG在所有数据集上的性能都优于所有的迁移哈希方法。与域自适应检索方法(ITQ+,LapITQ+,KSH,SDH,GTH,DAPH,DAPH*,PWCF和SGHL)相比,DCS-LSG在 Cross-dataset Testbed、MNIST+USPS和Office-Home上分别提高了20.27%、4.17%和25.75%。特别在和深度学习方法对比中,DCS-LSG比DHLing具有更好的检索性能,在Office-Home数据集中的Clipart&Real 和 Real&Product任务上,性能分别提高了34.43%和29.49%。

编辑人:吴建龙、任文琦
专委会责任副主任:张勇东

微信扫一扫
关注该公众号
 京公网安备11010802017125号
京公网安备11010802017125号