
【论文导读】2024年论文导读第十五期
【论文导读】2024年论文导读第十五期
CCF多媒体专委会 2024年07月30日 19:20 北京


论文导读
2024年论文导读第十五期(总第一百零六期)
目 录
|
1 |
Hierarchical Forgery Classifier on Multi-Modality Face Forgery Clues |
|
2 |
Disjoint Masking With Joint Distillation for Efficient Masked Image Modeling |
|
3 |
Learning Mutually Exclusive Part Representations for Fine-Grained Image Classification |
|
4 |
MMI-Det: Exploring Multi-Modal Integration for Visible and Infrared Object Detection |
|
5 |
When Channel Correlation Meets Sparse Prior: Keeping Interpretability in Image Compressive Sensing |
01
Hierarchical Forgery Classifier on Multi-Modality Face Forgery Clues
作者:
Decheng Liu, Zeyang Zheng, Chunlei Peng, Yukai Wang, Nannan Wang, Xinbo Gao
单位:
西安电子科技大学
邮箱:
clpeng@xidian.edu.cn
论文:
https://ieeexplore.ieee.org/document/10216334
1.研究动机
人脸伪造检测在保护个人隐私和保障社会安全方面发挥着重要作用。然而如图1所示,现有的方法总是将伪造检测视为简单的二元分类任务,忽略了对多种模态伪造图像类型的探索。在本文中,我们提出了一种新颖的用于多模态人脸伪造检测的伪造分类器。该伪造分类器的核心是利用内部注意力机制在图像域和频域探索强鉴别伪造线索,同时通过真实性反馈策略设计了具体的分层人脸伪造分类器以整合多种判别线索。大量实验表明,我们的方法在多模态伪造检测任务中有良好的表现。
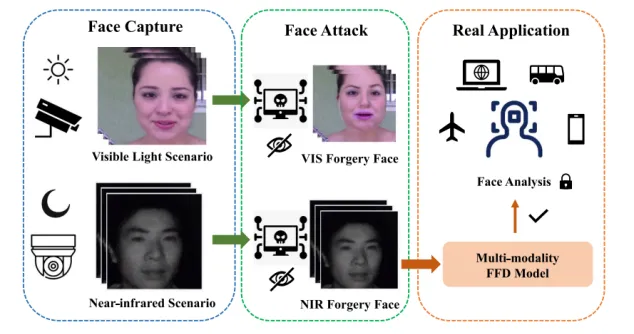
图1 多模态人脸伪造检测任务在现实世界中的应用示意图。
2.所提方法
本文所提框架如图2所示,该方法主要由两个部分组成:局部混合域伪造表示和分层人脸伪造分类。在空间域中,我们首先应用SIFT算法来提取鲁棒性的纹理判别信息,同时提取深度网络特征以获取高级语义判别信息,手工特征与深度学习特征共同构成了互补的判别信息;而在频率域中,我们使用DCT变换获取每个patch的深度网络特征。为了进一步有效地挖掘不同图像patch之间的依赖关系,我们设计了AttenFusion Block来处理上述提取的特征。为了进一步融合图像域和频域的不同互补判别信息,我们利用自适应的精细加权来安排可学习的权重来获得分数,以替代的方式确定输入人脸的真实性。最后为了识别伪造类型,我们仅使用图像域的判别信息进行分类。
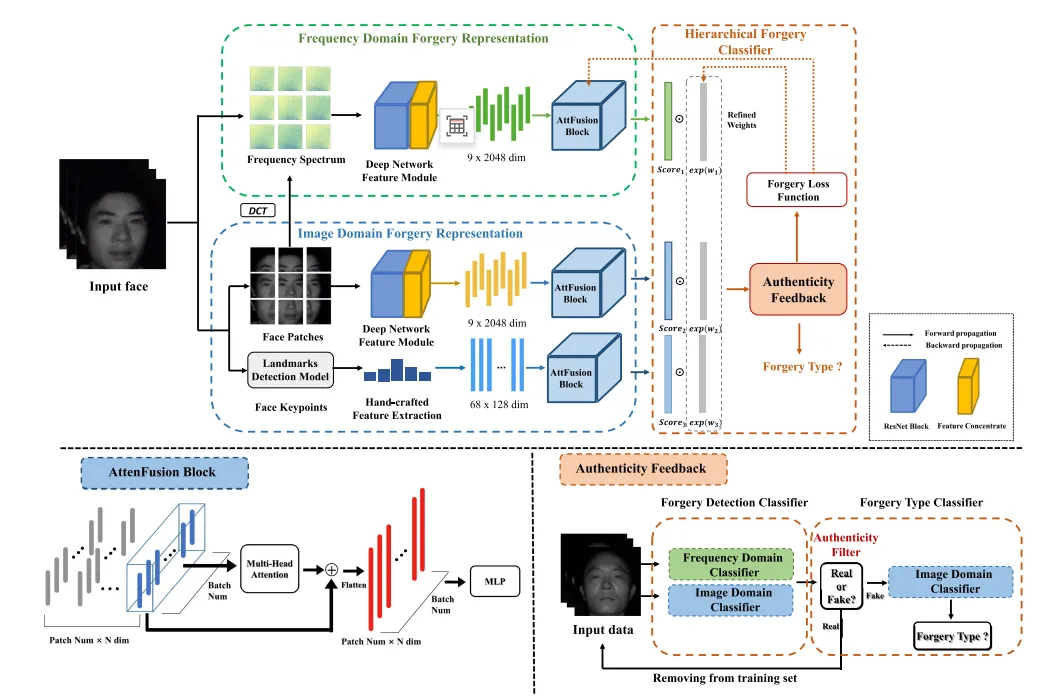
图2 基于多模态人脸伪造线索的分层伪造分类器框架。
3.实验结果
我们在CASIA NIR-VIS 2.0数据集,ForgeryNIR数据集和WildDeepfake数据集三个数据集中测试了所提方法的性能。图3展示了上述多模态人脸伪造检测的样本。

图 3 数据集示例。
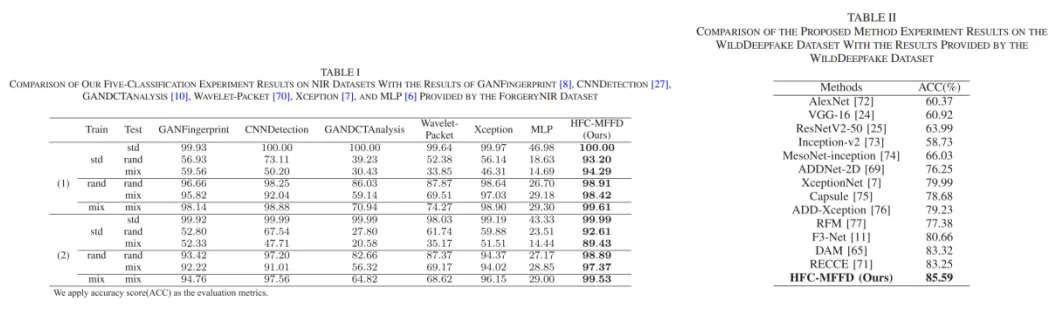
为了验证所提出算法在近红外人脸数据集上的有效性和鲁棒性,我们在ForgerNIR数据集和NIR-real数据集上进行了一系列实验。如表1所示我们的方法具有良好的检测性能。同时在表2中,我们的方法在可见光伪造数据集中也能达到最佳性能。
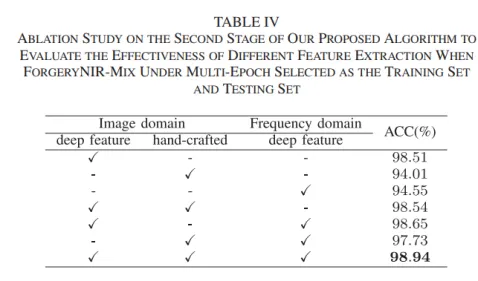
此外,我们进一步分析我们提出的算法。我们对提出的算法进行了一系列的消融研究评价其有效性和鲁棒性。如表4所示,在图像域和频域融合深度特征和手工特征可以获得较好的伪造跟踪性能(98.54%),比单独使用深度特征和手工特征分别提高0.03%和4.53%。这是因为所提出的局部混合域伪造表示可以有效地探索鲁棒性鉴别伪造线索,从而提高检测性能。
02
Disjoint Masking With Joint Distillation for Efficient Masked Image Modeling
作者:
马鑫1,刘畅2,谢春宇3,叶龙1,邓亚峰3,季向阳2
单位:
1中国传媒大学,2清华大学,3360人工智能研究院
邮箱:
mx_mark@cuc.edu.cn;
yelong@cuc.edu.cn;
liuchang2022@tsinghua.edu.cn;
xyji@tsinghua.edu.cn;
yuxie@buaa.edu.cn;
dengyafeng@gmail.com
论文:
https://ieeexplore.ieee.org/document/10225408
代码:
https://github.com/mx-mark/DMJD
1. 简介
随着视觉转换器(Vision Transformer,ViT)的出现,视觉自监督学习领域克服了模型结构的障碍,成功引入了掩码建模代理任务(Masked Image Modeling,MIM),成为当前视觉自监督表征学习中最有潜力的代理任务之一。然而MIM方法通常需要较高的训练开销,限制了MIM广泛的应用和研究。本文认为导致MIM训练效率较低的原因在于,现有方法仅使用掩码部分的图像信号作为监督信息,在每轮的梯度估计中只利用了图像监督信号的部分子集。由于监督信号的不充分使用,最终降低了模型的训练效率。通过绘制模型收敛曲线和不同掩码设定的关系可知(图1),简单地改变MIM的掩码比例和预测比例会降低模型收敛速度。
为此,本文设计了基于位置互补多视图的掩码建模视觉表征学习算法。该算法为输入图像采样多个不同掩码位置的数据视图,使得模型能够更充分地利用每幅图像进行训练,如图2所示。具体来说,在每轮数据视图的掩码位置采样过程中,算法优先考虑没有被其他数据视图采样的图像区域作为掩码对象。通过这种方式,单个输入图像中更多的图像信号能够被用于监督掩码重建任务的学习。由于整体图像监督信号使用率的提升是通过多视图的方式实现,单个掩码视图中仍保持了最优的掩码比例和预测比例设置,在保证适当掩码重建任务难度的同时,加速了模型收敛。
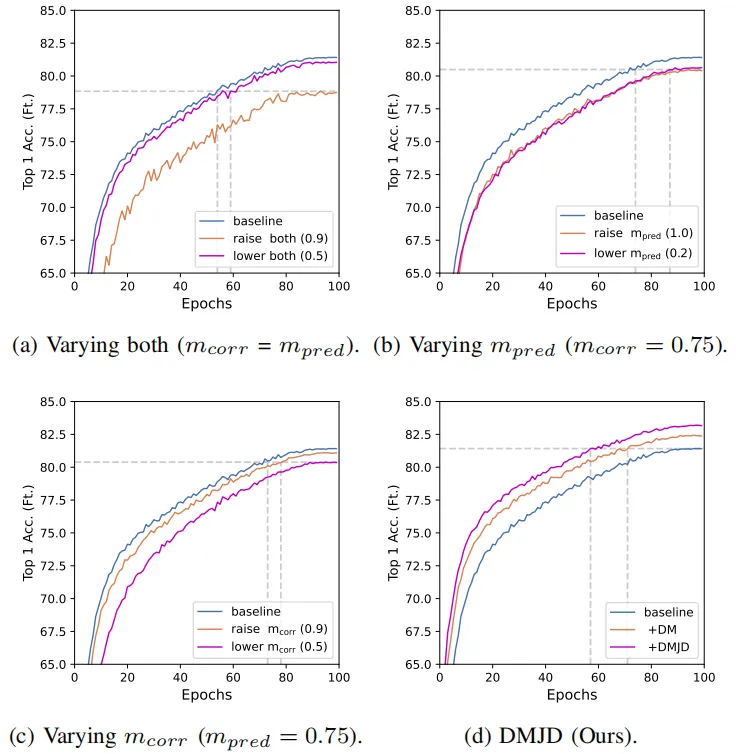
图1 不同掩码和预测比例设置对模型训练效率的影响
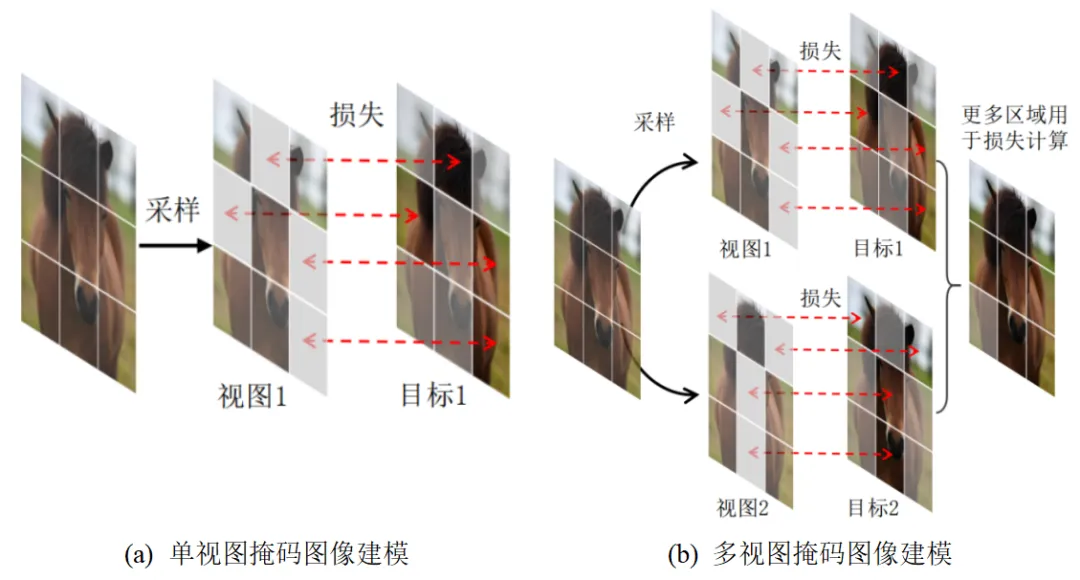
图2 掩码图像建模中的多视图
2.方法
针对上述问题,本文提出了基于位置互补多视图的掩码建模视觉表征学习算法,该算法由不相交掩码多视图采样策略、学习率自适应放缩规则和联合解码器三部分构成(如图3所示)。其中不相交掩码采样策略是对输入图像在掩码视图采样的过程中添加掩码位置的约束,该约束使得采样的多个掩码视图间掩码区域交集最小,尽可能充分利用全部的图像区域参与到单轮掩码重建的梯度估计中,降低梯度估计的方差,从而提升视觉模型的训练效率(如图4所示)。随着图像监督信号使用的增多,意味着梯度估计更加准确,这会减少优化过程中的梯度扰动,尽管可以提升模型收敛速度,但也减弱了模型跳出局部最优解的能力,最终可能导致模型泛化性变差。学习率自适应放缩规则是针对增大图像信号使用所带来的模型泛化问题提出的,通过使用数据监督信号使用率的相对增幅来放缩学习率,在提升模型收敛速度的同时保证了泛化性。尽管所提算法通过使用多视图的方式,规避了在单个掩码视图中提升预测比例所造成的表征退化问题,但实际上,单个掩码视图中可见区域的图像监督信号仍然有进一步利用的空间。为了进一步提升单掩码视图中监督信号的利用率,从改进掩码重建结构的角度出发,设计了一个双分支的联合解码器结构。该结构通过设立一个额外的网络结构分支来重建单掩码视图中的可见图像区域,进一步提升了单个掩码视图中可见区域图像监督信号的利用效率。
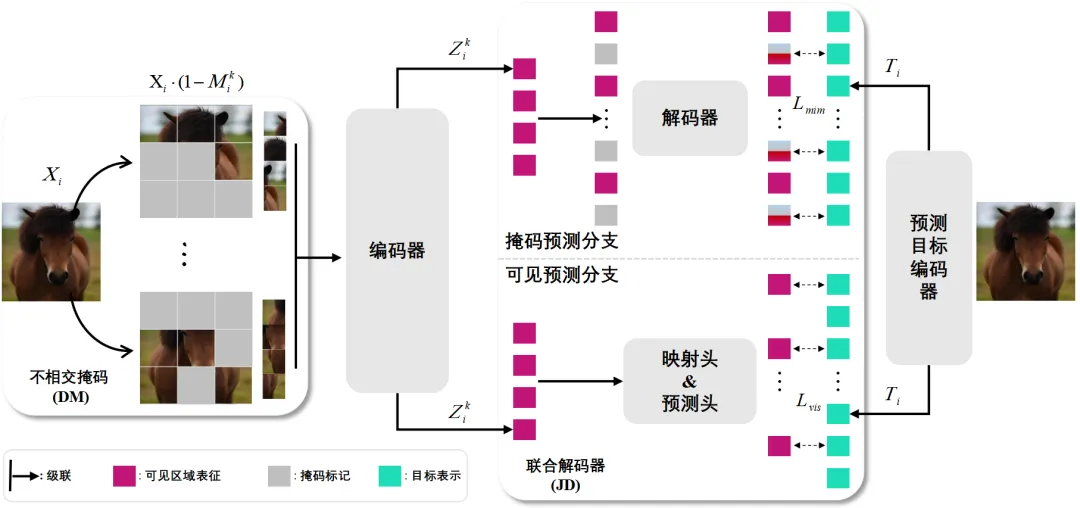
图3 基于位置互补多视图的掩码建模视觉表征学习方法框架示意图
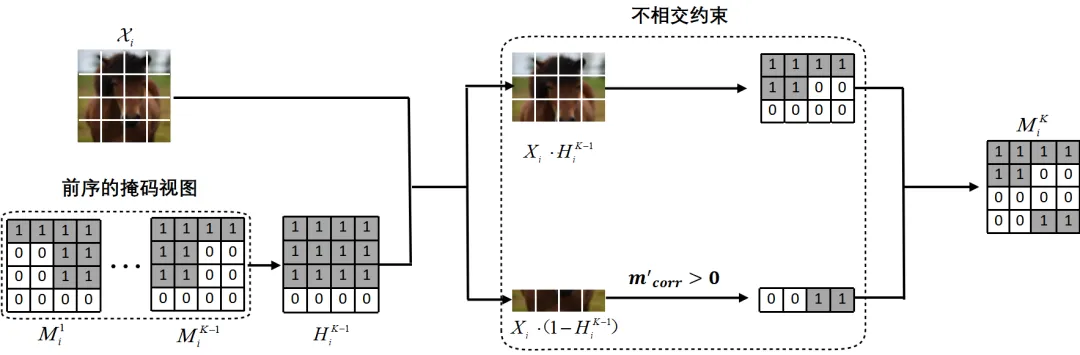
图4 不相交掩码采样策略示意图
3.实验结果
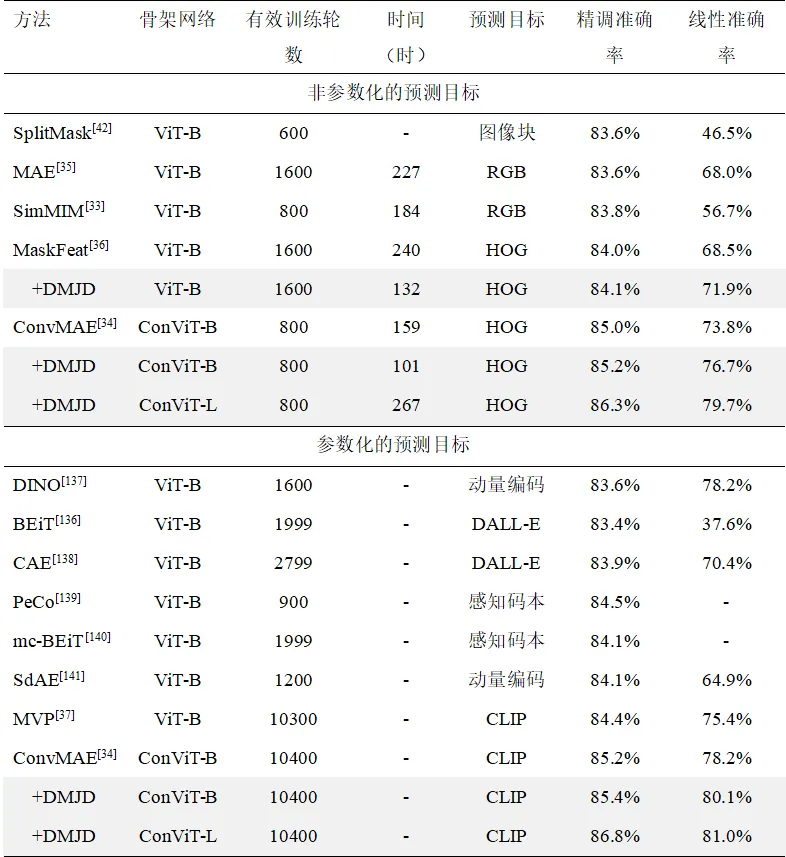
本方法在常见的Benchmark数据集上进行了充分的实验验证,表1展示了不相交掩码(DM)在四种经典掩码图像建模的方法上的收敛速度提升结果,图5展示了可见预测分支相较于传统模型,可以帮助模型在图像块级别聚合更丰富上下文信息,表2在使用不同视觉编码器的条件下与其他先进方法的结果对比,证明了本章方法在显著改善模型的识别效果的同时大幅提升了模型的训练效率。
表1 不相交掩码采样策略对MIM训练效率的提升效果
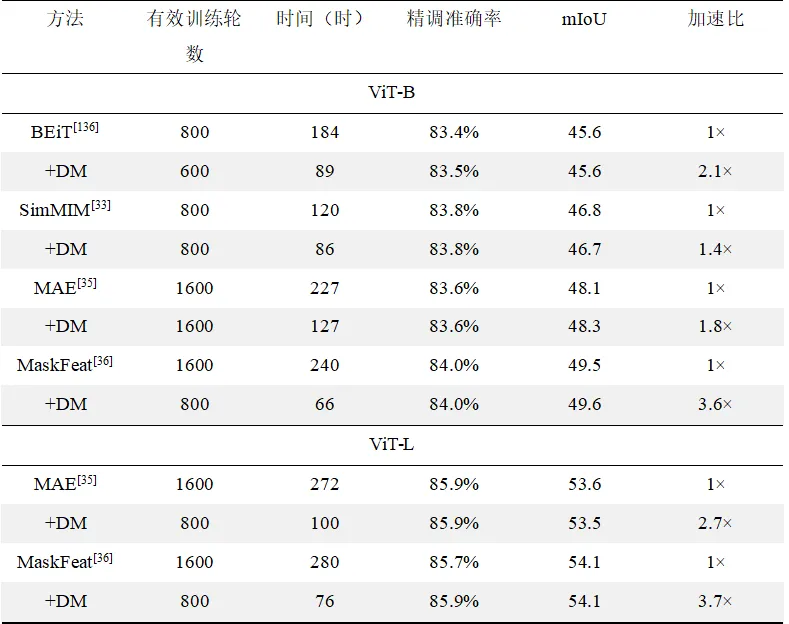

图5 有无可见预测分支的注意力视图可视化
表2 ImageNet-1k图像分类性能对比
03
Learning Mutually Exclusive Part Representations for Fine-Grained Image Classification
作者:
王川铭1,傅慧源1,马华东1*
单位:
1北京邮电大学
邮箱:
wcm@bupt.edu.cn
fhy@bupt.edu.cn
mhd@bupt.edu.cn
论文:
https://ieeexplore.ieee.org/abstract/document/10229186
*通讯作者
1.研究动机
细粒度图像分类 (Fine-grained image classification,FGIC) 旨在区分同一大类下不同的子类别,例如识别出车辆的型号、鸟的种类等。与粗粒度分类任务相比,细粒度图像分类中的目标外观十分相似,彼此之间的差异细微,同时类别数量众多,非相关领域人士难以进行准确的区分。现有方法主要通过设计额外的监督策略来定位目标的多个判别性部件,并从中提取判别性表征来提升分类精度。然而,如图 1 所示,在缺乏明确监督信息的情况下,现有方法会存在注意力区域不集中,关注背景区域或者相似的区域的现象,造成提取到的部件表征多样性减弱以及判别性下降。此外,我们发现细粒度分类的图像中存在目标分辨率过低的问题,这缩小了注意力产生的空间,从而降低了分类的准确性。为此,本文提出了一种无需额外监督来一组多样化、判别性部件表征的方法,从而实现精确的细粒度图像分类。
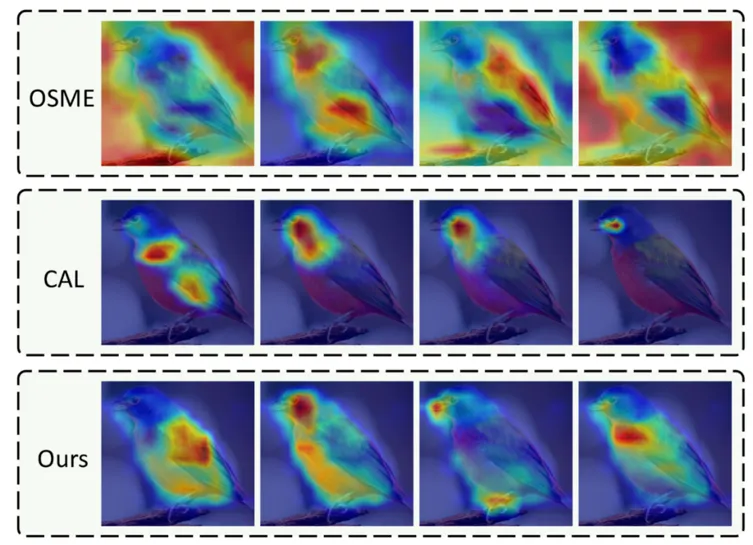
图1 不同多部件表征学习方法中的注意力可视化(每种方法生成四个注意力图)。前两行来自对比方法OSME和CAL,第三行来自我们所提方法。图像来自CUB-200-2011数据集,行色表示高响应区域,蓝色表示低响应区域。
2.方法概述
如图2所示,所提出的方法仅依赖最终的分类损失来学习一组多样化且有判别性的部件表征来实现准确的细粒度图像分类。首先,输入图像被送入骨干网络进行多尺度特征的提取,对于其中一个特征,利用一个互斥注意力学习模块(MEA)来生成能够关注目标不同关键区域的空间注意力,从而产生互斥的部件表征。然后,为了减少部件表征之间通道耦合性,设计了一个部件通道加权模块(PCW)从全局通道注意力中进行加权采样来调整每个部件表征的通道幅值,从而增强了来自相同特征图的部件表征的多样性。此外,为了确保全面且充分的部件表征提取,方法还引入了多粒度特征学习,从不同语义和内容级别的图征图中提取部件表征,从而有效地捕获目标细节信息。最后,这些表征被发送到对应的分类器进行预测。
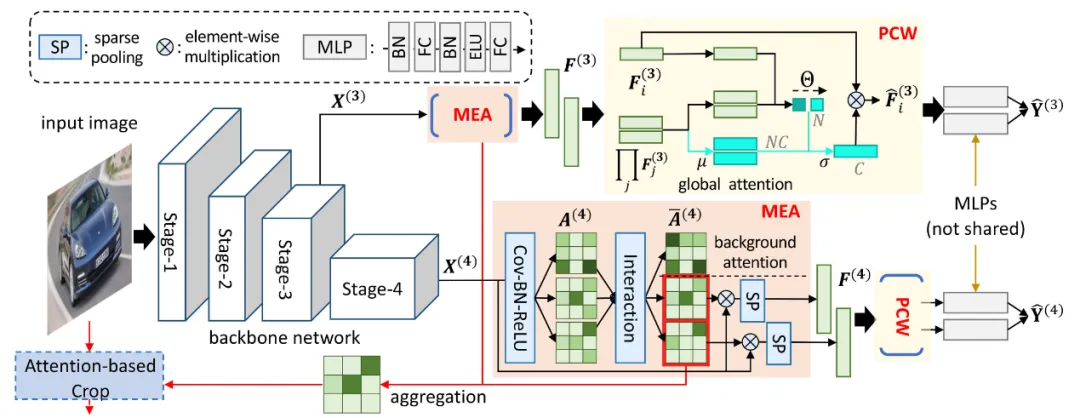
图2 基于互斥多部件表征学习的细粒度图像分类框架
3.实验分析
本文在包含CUB-200-2011(Bird)、Stanford-Cars(Car)、FGVC-Aircraft(Air)在内的多个细粒度图像分类基准数据集上进行验证实验,评估了所提方法的有效性。与当前先进方法的比较结果如表1所示,试验结果表明了所提出的方法可以胜过各种最先进的方法 (SoTA),而无需额外的损失设计或复杂的训练过程。图3展示了所提方法生成的注意力,其中每个子图的第一列是背景注意力,后四列是前景注意力。表明所提MEA模块能够有效区分图像的背景和前景区域以及定位目标不同的关键区域。
表1 不同方法在多个细粒度图像分类数据集上的性能比较
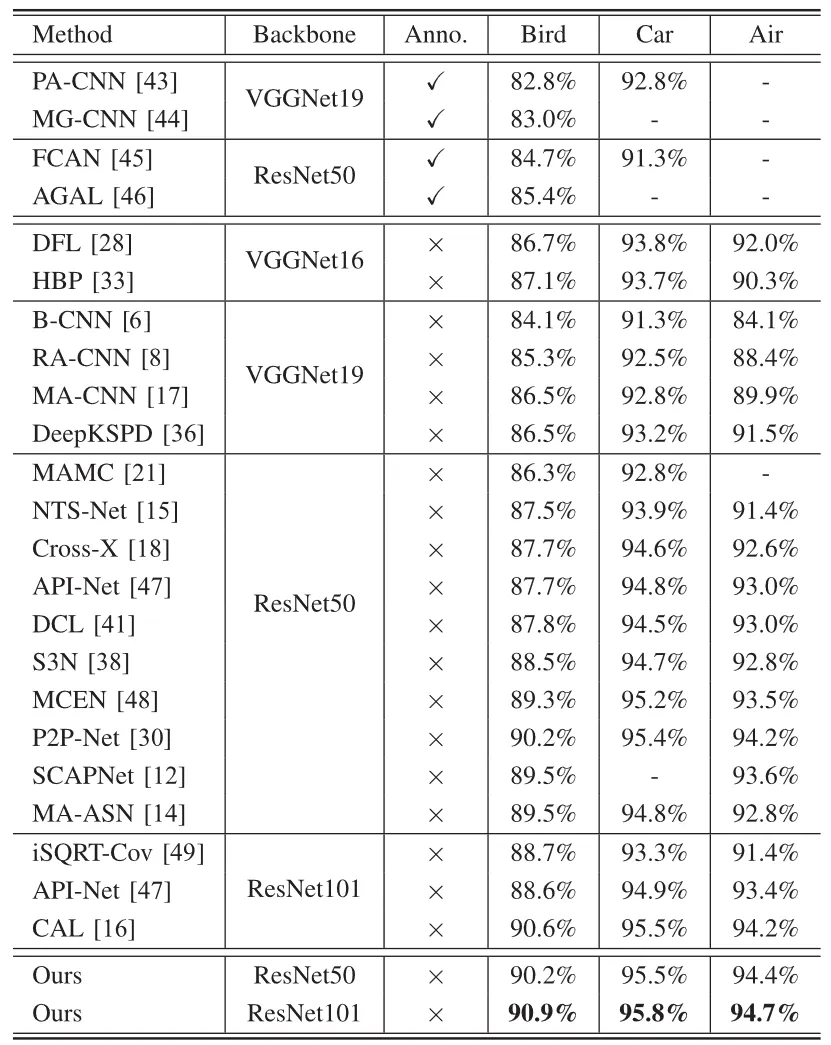
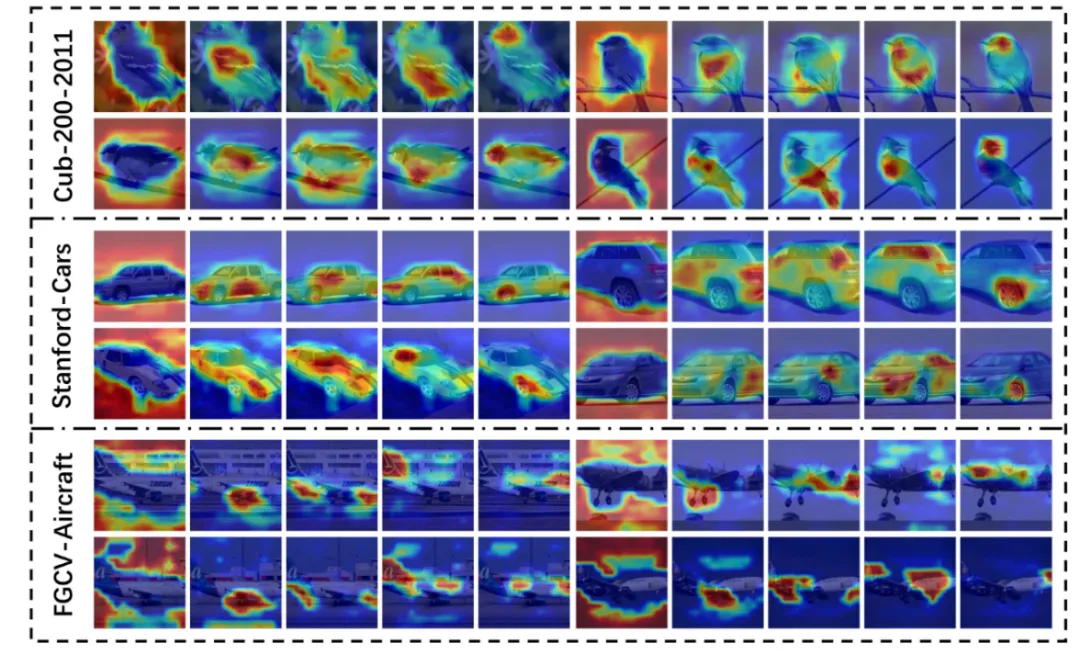
图3 部件注意力可视化
04
MMI-Det: Exploring Multi-Modal Integration for Visible and Infrared Object Detection
作者:
曾宇乔,梁腾飞,金一*,李浥东
单位:
北京交通大学交通大数据与人工智能教育部重点实验室
邮箱:
yuqiaozeng@bjtu.edu.cn;
tengfei.liang@bjtu.edu.cn;
yjin@bjtu.edu.cn;
ydli@bjtu.edu.cn
论文:
https://ieeexplore.ieee.org/abstract/document/10570450
代码:
https://github.com/joewybean/MMI-Det
*通讯作者
1.论文简介
随着计算机视觉和自动驾驶技术的发展,准确的目标检测对智慧安防和智能驾驶至关重要。然而基于单一模态图像的目标检测方法的性能容易受到低光照或动态变化环境的影响,难以准确检测出复杂场景中的关键目标。作为计算机视觉领域中的一项关键任务,可见光-红外(VIS-IR)目标检测旨在结合可见光和红外数据,提供场景中目标的类别和位置信息。真实场景下可见光与近红外图像在成像质地的表观差异巨大,然而现有检测方法在多模态检测任务上的性能不佳,且难以平衡融合和检测任务的优化方向,无法实现端到端的模态融合与检测。
为应对上述问题,我们提出基于轮廓增强与频域变换的RGB-IR多模态目标检测方法MMI-Det。该方法能够深度结合可见光-红外模态的互补信息,并在图像融合和目标检测任务的优化方向之间取得平衡,输出更加准确鲁棒的检测结果。方法首先在模型的浅层设计幅值自适应的轮廓增强模块,增强网络对不同模态下目标轮廓信息的感知能力。其次,由于频谱特征受图像成像质地影响较小,可有效表达目标的不变性特征,方法在模型的深层基于频域变换的模态融合策略进行跨模态语义对齐。通过傅里叶变换提取可见光和红外模态的高频信息,结合模式分离和自注意力机制,增强模型对不同空间位置下目标的感知能力。此外,方法利用对比学习策略构建正负样本对,引导模型学习模态不变特征,增强在复杂场景下的检测鲁棒性。最后,本文设计了一个基于结构相似性和信息熵的复合损失函数,引导模型在融合任务和检测任务之间取得优化平衡,进一步提升检测性能。我们在公开的FLIR、M3FD、LLVIP、TNO和MSRS数据集上进行了大量实验。实验结果表明,与现有方法相比,我们的方法在多模态信息感知与融合能力上具有明显优势,并在多光谱检测任务中取得了更加鲁棒准确的实验结果。
2.论文方法
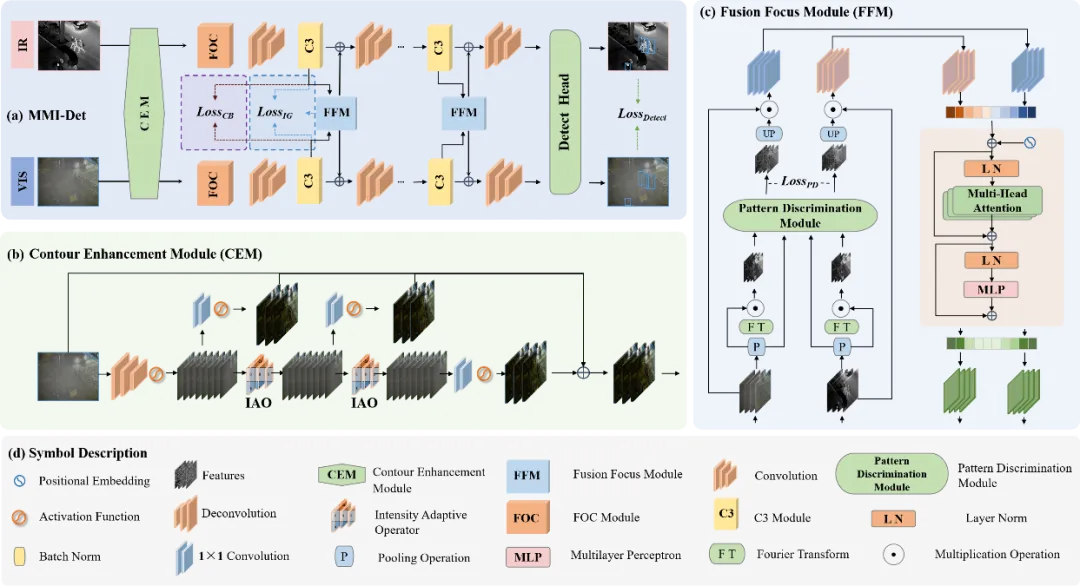
图1 MMI-Det方法框图. (a) 整体结构. (b) 轮廓增强模块. (c) 融合聚焦模块.
针对当前可见光-红外目标检测任务中存在的模态难融合与融合-检测任务优化方向不一致等问题,本文设计一种基于多层次模态融合的多光谱目标检测方法MMI-Det,其整体结构如图1所示。首先,对于输入的可见光图像与红外图像,方法在模型的浅层设计幅值自适应的轮廓增强模块(CEM),能够让模型动态地调整对场景中目标轮廓的增强程度,进而适应动态变化的真实道路场景。此外,为克服可见光和红外模态的特征分布差异,增强两模态中关键信息的融合,本文在模型的深层设计融合聚焦模块(FFM)。
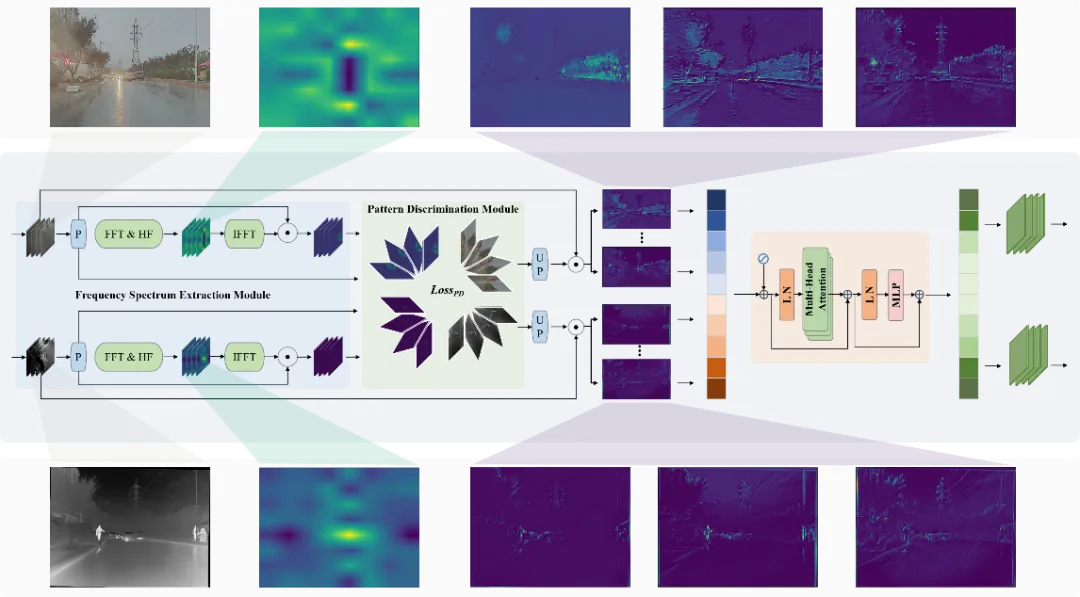
图2 融合聚焦模块
如图2所示,同一场景下的不同模态图像在特征分布上呈现较大的表观差异,由于频谱特征受图像成像质地影响较小,可有效表达目标的不变性特征,FFM首先设计基于傅里叶变换的高频特征提取分支,将不同模态特征由空域转化成频域,提取出其中的高频分量再还原为空域特征。经过高频提取后的特征包含更加显著的目标轮廓及纹理信息,便于模型进行跨模态语义对齐,对目标进行更加准确的检测定位。为进一步增强模型对不同模态与不同空间位置下目标的感知能力,我们设计多模态模式分离损失。此损失函数通过拉远不同模态下的多通道高频特征,让模型能够增强对不同模态及不同空间位置下目标特征分布的感知。如图2所示,经过模式分离学习后模型输出的特征不仅可以分辨出不同模态下的目标轮廓,对于同一模态的不同空间位置目标也具备更加强大的感知能力。
此外,为提高模型的多模态感知训练效率,本文设计了对比桥接模块(CBM),利用对比学习策略将成对的可见光-红外图像设为正样本,将未成对的可见光-红外图像设为负样本,以引导模型提高对可见光-红外场景中模态不变特征的感知能力。最后,为平衡VIS-IR目标检测模型对于图像融合任务和目标检测任务的优化方向,我们设计了信息引导模块(IGM)。受图像融合任务的启发,我们使基于该任务的评估指标设计信息引导损失,可以在训练过程中指导模型更有效地融合两种模态的特征信息。总之,通过在模型的不同层次针对性地设计上述模块,MMI-Det 可以实现端到端的联合优化,并给出准确、稳健的检测结果。
3.实验分析
为综合评估我们方法的检测性能,论文在多个数据集下进行了定性可视化及定量分析实验。首先,方法在多个数据集上进行了定性的目标检测可视化实验。

图3 各类方法在M3FD数据集上的目标检测结果可视化情况
图3为在各方法在M3FD数据集上的检测可视化结果。该数据集包含几类复杂天气场景,能够在一定程度上反映真实天气条件下各类方法的检测能力。例如,在雾天(第一行、第三行)和浓烟(第四行)的场景中,可见光模态图像往往难以提供清晰的图像,而红外图像则能提供更加清晰的场景信息。虽然现有方法可以利用可见光图像和红外图像的互补优势来探测烟雾中的人类。然而在烟雾分布不均匀的复杂场景中,一些方法则不能准确检测出其中的关键目标。例如,在第一个场景中,ICAFusion 错误地为烟雾中的行人输出了多个检测框;而在第三个场景中,InFusion-Net 错误地将远处山丘的轮廓检测为行人。相比之下,我们的 MMI-Det 采用了轮廓增强模块,可以有效捕捉目标的边缘和轮廓特征,而这些边缘及轮廓特征在光线不足、大雾等恶劣天气场景中往往非常重要。上述实验结果反映MMI-Det能够在多种场景中准确地感知并融合VIS与IR模态下的目标细节与轮廓特征,并保持准确而鲁棒的检测能力。

图4 各类方法在LLVIP数据集上的目标检测结果可视化情况

图5 各类方法在MSRS数据集上的目标检测结果可视化情况
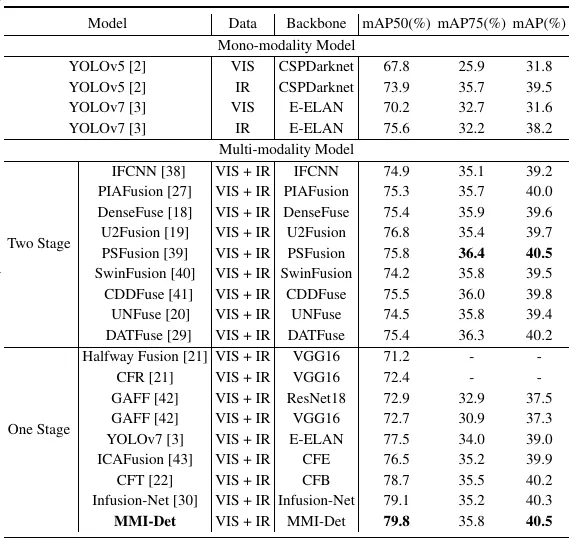
此外,在表1中我们使用不同的评估指标对 FLIR 数据集上的各种模型进行了全面的定量比较。该表分为两个不同的部分:“单模态模型”和 “多模态模型”。在单模态模型部分,我们研究了单模态方法在 VIS 或 IR 模态下的性能。例如,将YOLOv5与CSPDarknet结合后,VIS模态下的mAP50为67.8%,IR模态下的mAP50为73.9%,反映了这些方法在不同模态下的检测能力。此外,我们研究了多模态检测方法的性能,分为“两阶段”和“一阶段”策略。对于两阶段模型,如 IFCNN、U2Fusion、PSFusion、SwinFusion、CDDFuse、UNFuse和DATFuse,在融合VIS和 IR信息后的mAP值相比单模态目标检测方法都取得了一定的提高。而我们的MMI-Det 的检测指标mAP50 为 79.8%,证明了其在 FLIR 数据集中可以利用设计的多层次融合策略,实现更加准确的目标检测结果。总体而言,多模态方法优于单模态方法,而 MMI-Det 获得了相对更高的检测结果,这也反映出本文的MMI-Det在 FLIR 数据集上可以拥有较好的VIS-IR目标检测能力。
表1 不同检测方法在FLIR数据集上的mAP检测指标情况
05
When Channel Correlation Meets Sparse Prior: Keeping Interpretability in Image Compressive Sensing
作者:
孔笑宇,陈勇勇,何震宇
单位:
哈尔滨工业大学(深圳)
邮箱:
xiaoykong15@gmail.com;
YongyongChen.cn@gmail.com;
zhenyuhe@hit.edu.cn
论文:
https://ieeexplore.ieee.org/document/10231373
1.引言
压缩感知理论将采样和压缩两个过程合而为一,通过使用线性采样矩阵对数据进行采样压缩,从而使测量值远远小于传统采样方法下的数据量。受限于采样值规模,图像压缩感知重建是一个不适定问题。为了获得可靠的重构质量,许多方法引入了额外的先验知识来限制解决空间,同时借助深度网络提升算法性能。但是,现有算法没有充分利用CNN生成的多通道特征,仅将它们视为类似向量的数据,并对它们进行单一静态阈值学习。这种处理方式不仅使二维图像退化为了一维向量,丢弃了图像的空间信息,忽略了卷积多层特征图带来的丰富表达能力,导致了较差的重构质量。同时,使用训练后固定的静态阈值也难以应对真实世界复杂多变的图像分布。为了解决上述通道信息缺失的问题,本章文提出针对通道信息关联的深度展开式网络,通道自适应阈值网络(CAT-Net),利用卷积特征图通道之间的相关性动态计算每个通道各自的阈值。CAT-Net在保持稀疏先验物理可解释性的同时,提升了重建质量。
2.方法介绍
CAT-Net 网络使用深度展开式网络结构,由三个部分组成:采样和初始化网络、通道自适应重构网络和全局信息网络。
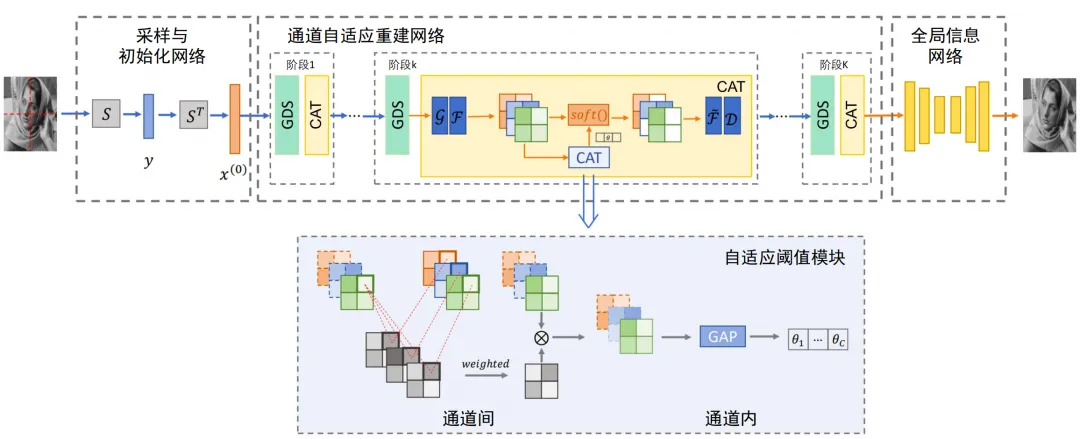
图1 CAT-Net结构图
在通道自适应重构网络,本文使用结合深度学习与优化算法的深度展开式网络结构。通过对初始重建进行K次迭代优化后获得重建输出x(K)。相较于传统单个静态阈值,基于通道关联计算的多通道动态阈值不仅保留了图像的空间信息,同时引入了高阶的通道交互信息。通过自适应地调整阈值,CAT-Net可以更加仔细和精确地进行重建,对于细节的重建也更加细致。
3.实验结果
表1展示了三个灰色数据集 Set5、Set11 和 Set14 上的比较结果。可以看出,CAT-Net 在所有采样比率下,每个数据集上的 PSNR得分最高。并且,本文的模型在较低的采样比率(0.01、0.04 或 0.1)下仍表现更好,这符合实际需求,即较少的采样条目和更好的重建结果。
表1 灰度数据集 Set11、Set5 和 Set14 进行平均 PSNR/SSIM 结果比较。最佳结用粗体标出,次佳结果用下划线标出。
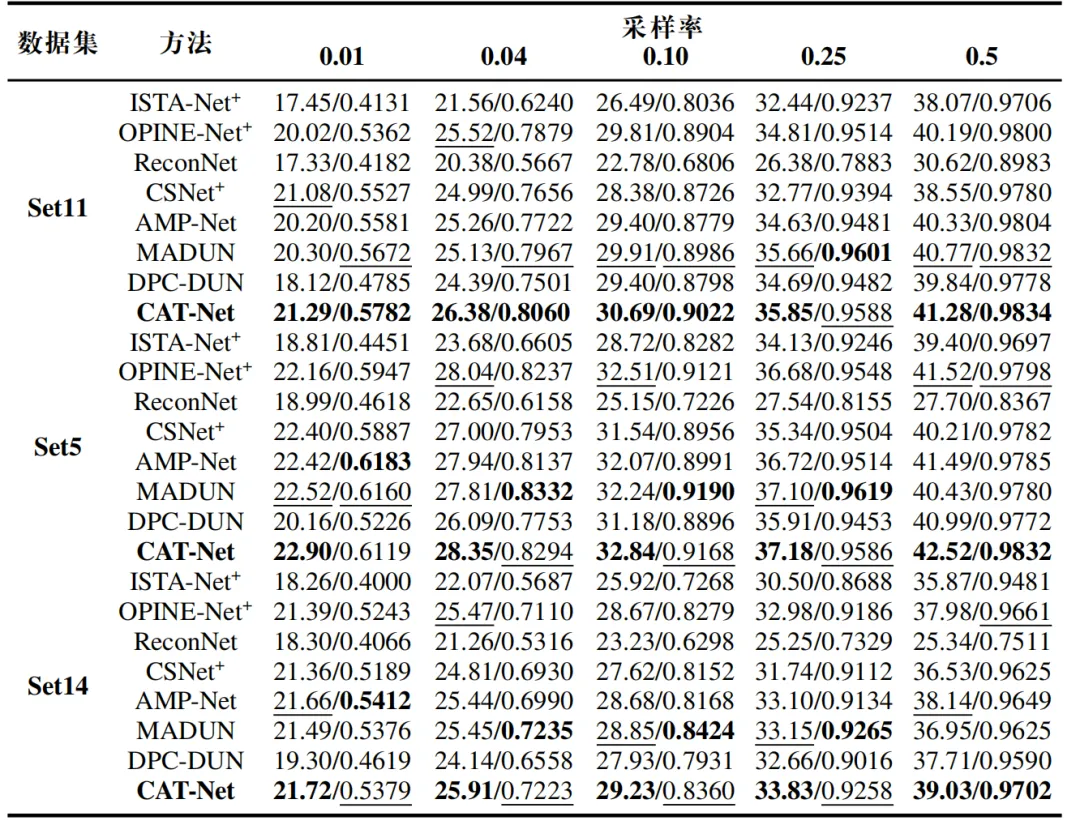
表2展示了在两个大型彩色图像数据集 CBSD68 和 Waterloo 上的性能比较。尽管CAT-Net 是在灰度数据集上训练的,但所提出的通道自适应阈值可以很好地适应不同的颜色通道,并成功重建彩色图像。
表2 对彩色数据集 CBSD68 和 Waterloo 进行平均 PSNR/SSIM 结果比较。最佳结果用粗体标出,次佳结果用下划线标出。
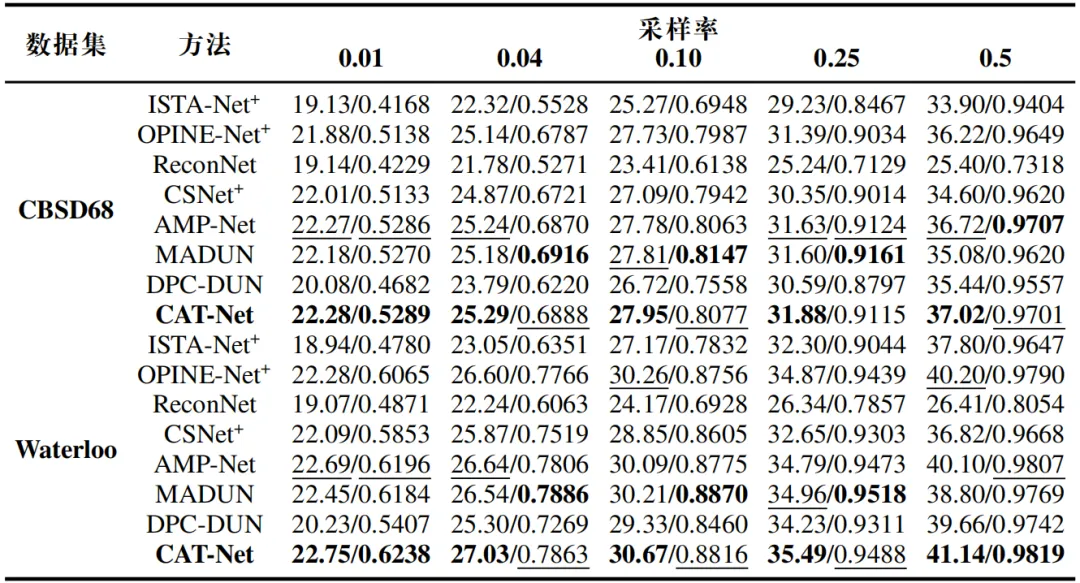
图2可视化结果展示了CAT-Net通过使用通道相关性操作重建出生动的纹理样式,同时自适应通道相关阈值可以对不常见输入分布进行重建,如单词。

图2 在采样比例为 0.1 时,Set11 数据集中的“Barbara”的图像(上)和 Set14 数据集中的“PPT”(下)进行了重建比较。

编辑人:吴建龙、任文琦
专委会责任副主任:张勇东

微信扫一扫
关注该公众号
 京公网安备11010802017125号
京公网安备11010802017125号