
【论文导读】2024年论文导读第十六期
【论文导读】2024年论文导读第十六期
CCF多媒体专委会 2024年08月13日 16:34 北京


论文导读
2024年论文导读第十六期(总第一百零七期)
目 录
|
1 |
Cross Modal Compression With Variable Rate Prompt |
|
2 |
RFFNet: Towards Robust and Flexible Fusion for Low-Light Image Denoising |
|
3 |
Fast Fourier Inception Networks for Occluded Video Prediction |
|
4 |
Unsupervised Monocular Estimation of Depth and Visual Odometry Using Attention and Depth-Pose Consistency Loss |
|
5 |
MFNet:Real-time motion focus network for video frame interpolation |
01
Cross Modal Compression With Variable Rate Prompt
作者:
高俊龙1、黎吉国2、贾川民3*、王苫社1、马思伟1、高文1
单位:
1北京大学计算机学院视频与视觉技术国家工程研究中心
2中国科学院计算技术研究所
3北京大学王选计算机研究所
邮箱:
jlgao@pku.edu.cn;
jiguo.li@vipl.ict.ac.cns;
cmjia@pku.edu.cn;
swang@pku.edu.cn;
swma@pku.edu.cn;
wgao@pku.edu.cn
论文:
https://ieeexplore.ieee.org/document/10236483
*通讯作者
1.研究背景
跨模态压缩框架(Cross modal compression,CMC)的目标是将图像编码为一种或多种模态的紧凑表示,并由这些表示重建出与原始图像相似的图像。使用文本作为基础压缩域表示的跨模态压缩具有超高压缩比,利用了人类知识对图像内容进行高度抽象概括,探索了基于知识和多模态大模型的智能编码的潜能,突破了传统编码方法以信号统计特性为基础的限制,拓展了当前图像压缩框架。当前方法难以控制码率,难以满足不同的传输条件、存储介质、应用需求。码率的控制可以通过控制文本长度来获得。实现不同长度文本生成的直接方法是,给定文本长度,模型生成不同长度的文本。近年来,多模态大模型在海量数据训练下学习大量的知识。多模态大模型是一个知识库,是否可以减少微调模型来调用知识库完成任务?因此,专家学者们提出提示学习来实现这个需求。受提示学习启发,本文将生成目标文本长度的文本当成是一种任务,使得多模态大模型生成符合目标长度的文本,从而实现可变码率。本文首先提出基于提示学习的可变码率跨模态图像压缩(VR-CMC)框架,引入可变码率提示方法,并在数据预处理、训练和推理阶段提出相应策略。 如图1所示,根据不同目标长度,压缩模型编码得到不同长度的文本,并用于重构出相应的图像。
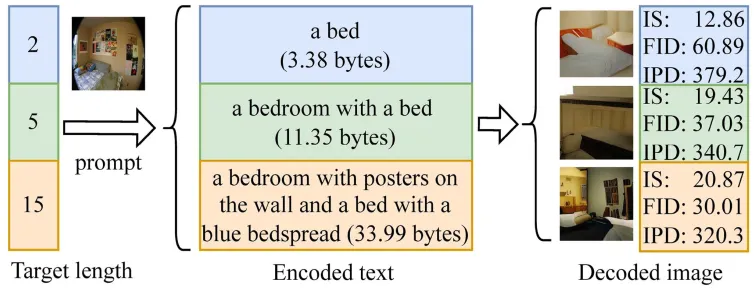
图1 可变码率提示的示意图
2.研究方法
本文提出基于提示学习的可变码率跨模态图像压缩框架,如图2所示。在该框架中,本文基于多模态模型构建编码器和解码器,并基于提示学习控制文本表示的长度。采用提示学习可以使得长度可控的文本生成任务与原始的文本生成任务较为接近,无需更换任务形式或者在大模型中引入新的参数。然而仅仅使用提示学习难以准确控制文本生成长度,因此本文进一步提出更加完善的策略来辅助生成。具体而言,本章提出的方法由三种策略组成,即目标长度提示策略、序列结束标记概率增长和文本增强策略。三种策略分别应用于不同的阶段,即训练、推理和数据准备。目标长度提示策略将所需长度引入语言提示中,以使模型知道所需长度。序列结束标记概率增长策略基于解码步骤和目标文本长度以指数方式增大序列结束标记的概率,其中序列结束标记单词是指示文本生成结束的特殊单词。文本增强策略随机截断训练数据集中的文本,使训练时的文本表示长度更加平衡。
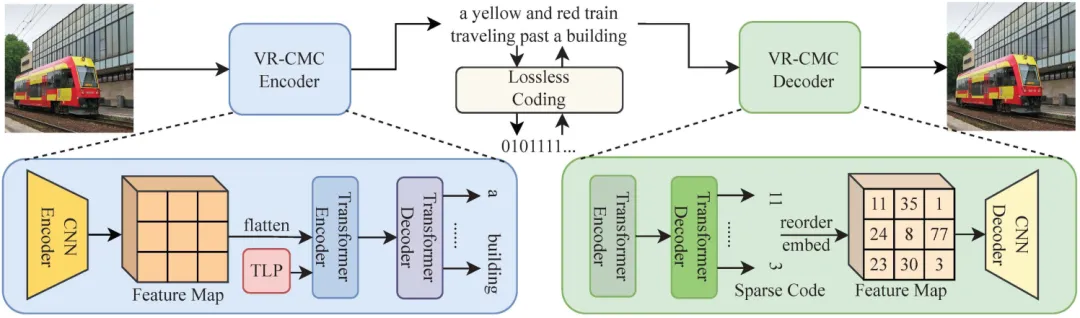
图2 可变码率跨模态图像压缩图
3.实验分析
本文使用 MSCOCO和 IM2P两个数据集来评估模型性能。在表1、2中,展示期望长度 (DL) 和平均长度 (AL)、DL 和 AL 之间的差的绝对值 (AD) 以及绝对差的平均值 (ADm),所提方法使用三种所提策略之后实现较高的文本长度可控性,因此可以更好的控制码率。在表3、4中,在不同期望文本长度下,生成的文本质量相比于当前可控文本长度方法好,表明编码得到的文本较为正确。在图3中,展示了不同码率下的重构图像质量结果,并绘制成曲线,实验结果表明VR-CMC 在 MSCOCO 和 IM2P 的所有指标上都优于 CMC、JPEG、JPEG2000,且具有较好的率失真特性。
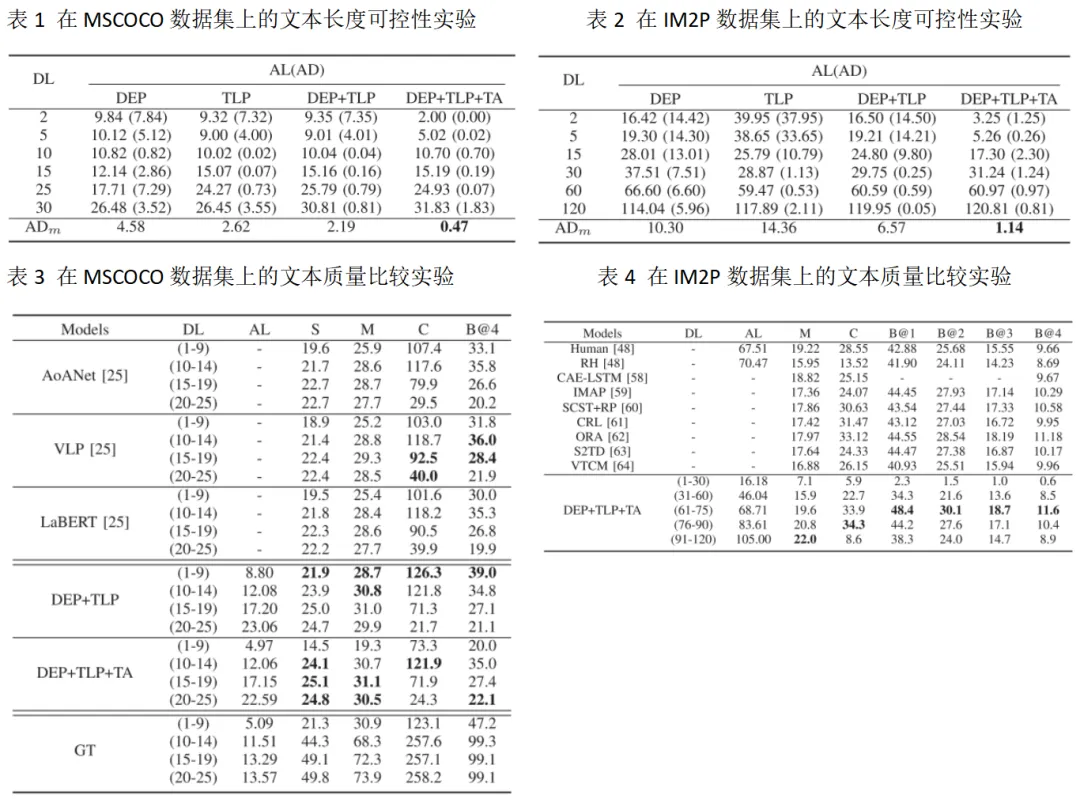
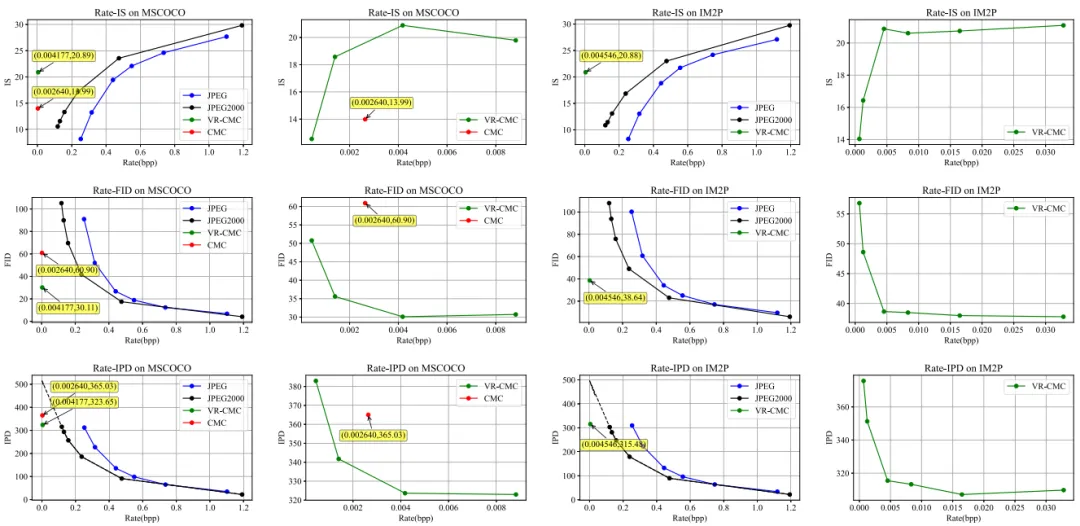
图3 在MSCOCO和IM2P数据集上的率失真曲线
02
RFFNet: Towards Robust and Flexible Fusion for Low-Light Image Denoising
作者:
王强,崔玉宁,李雅文,阮亚平,祝犇,任文琦*
单位:
中山大学深圳校区网络空间安全学院,北京邮电大学,腾讯
邮箱:
wangq637@mail2.sysu.edu.cn; yuning.cui@in.tum.de;
warmly0716@bupt.edu.cn; paulruan@tencent.com; benjaminzhu@tencent.com; renwq3@mail.sysu.edu.cn
论文:
https://openreview.net/forum?id=w6rJxukAap
代码:
https://github.com/WQ-Vincent/RFFNet
*通讯作者
1. 论文简介
低光照环境会在拍摄的图像中引入高强度的噪声。低光照图像去噪旨在消除不希望的噪声,这在全天候监控、自动驾驶技术和摄影中扮演着至关重要的角色。仅以单张图像为输入的图像去噪器在处理这些严重退化的噪声图像时,往往导致去噪不足或过度平滑,如图1(c)所示。引导图像恢复提供了一种图像去噪的新解决方案。近红外(NIR)图像(图1(b))和闪光图像由于噪声少、结构清晰、细节丰富,可以引导低光照图像去噪。然而,目标和引导图像对之间存在不一致性,例如在在NIR或闪光照明下物体上的亮点和物体后的硬阴影,如图1(b)底部所示。因此,直接融合跨域信息往往会引入伪影,这使得低光照引导去噪成为一个复杂的问题,因为它不仅需要去除强烈噪声和恢复细节,还需要抑制伪影。然而,现有的基于融合的方法未能有效抑制由引导/噪声图像对之间不一致性引起的伪影,并且没有充分挖掘引导图像中包含的有用频率信息。
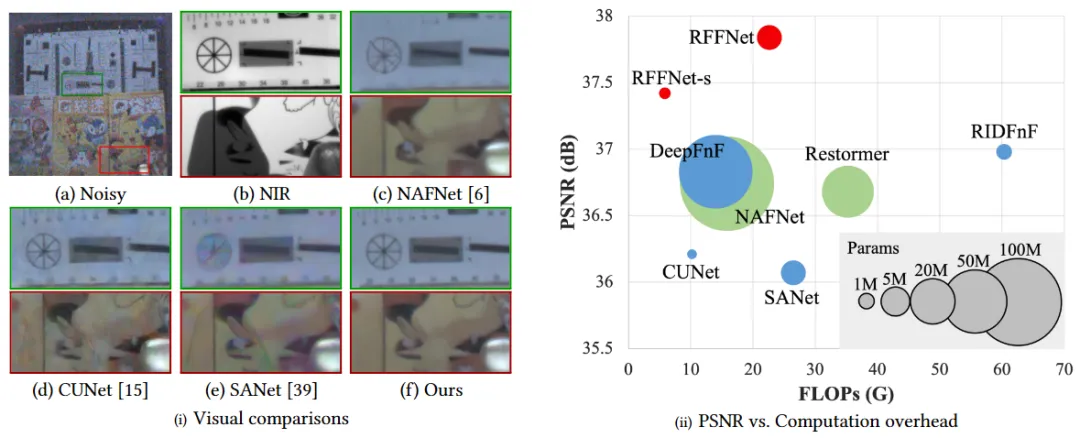
图1 我们方法的优势
为了缓解上述问题,我们提出了一个用于低光照图像去噪的稳健且灵活的融合网络(RFFNet)。具体来说,我们提出了一个多尺度不一致性校准模块,通过首先将引导特征映射到多尺度空间,并借助预去噪特征以从粗到细的方式对其进行校准,以此来解决融合之前的局部不一致性。此外,我们提出了一个双域自适应融合模块,以自适应地从引导特征中提取有用的低/高频信号,然后突出信息丰富的频率,差异性地恢复显著结构和平坦区域。 图1以及更广泛的实验结果表明,我们的方法在NIR引导的RGB图像去噪和闪光引导的无闪光图像去噪上实现了最先进的性能,在噪声去除、细节恢复和伪影抑制方面取得了更好的平衡,同时保证了更高的计算效率。
2.论文方法
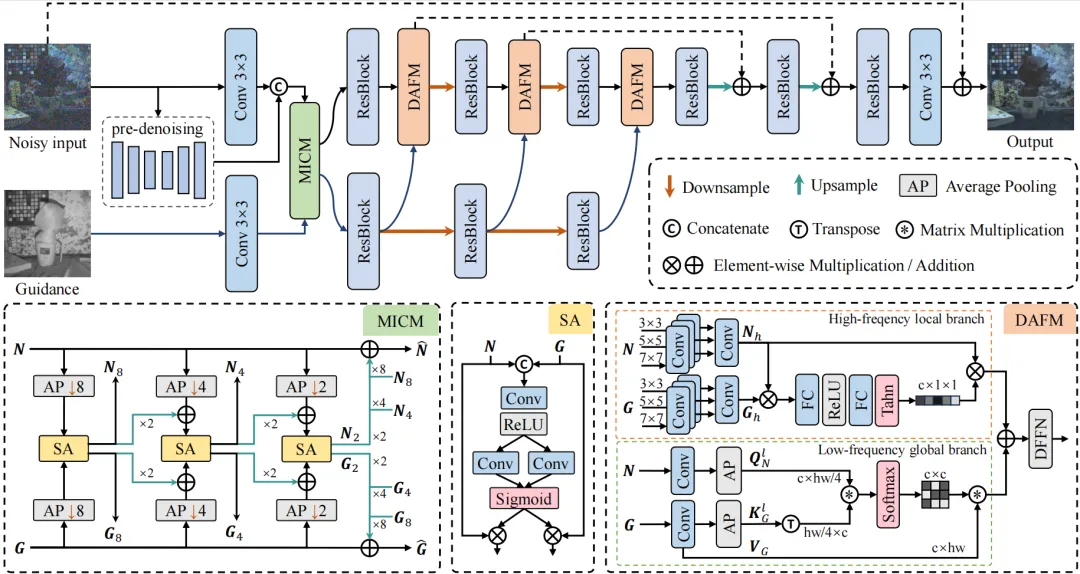
图2 RFFNet方法框图
针对当前基于融合的图像去噪中存在的不一致伪影难抑制与跨域特征融合不充分等问题,本文设计一种端到端的两阶段融合网络RFFNet,用于逐步恢复无噪声且细节丰富的图像,其整体结构如图2所示。两个阶段都包含一个编码器-解码器架构,具有两个下采样层和两个上采样层。第一阶段进行预去噪,不仅便于融合阶段的噪声移除,还提供了噪声图像较为干净的轮廓,以便于后续轻松识别不一致性。第二阶段经过我们的多尺度不一致校正模块校正跨域特征后,由双域自适应融合模块融合校正后的特征并注入主干网络。
为了解决两种图像之间的局部不一致问题,我们设计了多尺度不一致校正模块(MICM),如图2左下所示。我们的MICM通过从粗到细的方式逐步校准跨光谱特征来解决不一致性问题。 多尺度处理允许网络关注不同层次的结构和内容。我们使用不同下采样率的平均池化(AP)将引导特征和预去噪特征转换到不同的尺度空间。在这里,AP可以作为低通滤波器,显著降低较低尺度上的噪声影响,并为大尺度不一致性实现有效的感受野。在下采样部分的三个分支中,我们对跨模态特征应用空间注意力模块(SA)以校准不一致性。具体来说,SA使用一个简单的卷积层来融合跨特征,并将它们分配到不同的卷积层以自适应地生成注意力权重。 通过SA,我们可以获得重新加权的特征以减轻不一致性。 然后,校准后的特征被上采样到原始大小,并通过跳跃连接与初始特征聚合。校正后的噪声特征和引导特征被注入到主网络中融合。
此外,我们提出双域自适应融合模块(DAFM)来充分融合引导图像中不同频率的有效信息,如图2右下所示。为了提取特征的不同频率,一种直接的方法是使用小波变换或傅里叶变换。然而,这些工具难以区分需要增强或抑制的频率成分,并且它们需要额外的计算开销才能将特征转换回空间域。相反,我们使用自适应频率滤波器来产生高/低输入频率。对于高频提取,我们将特征分为几组,并对每组应用不同核尺寸的深度卷积,以模拟不同高通滤波器中的截止频率。对于低频提取,我们使用平均池化作为低通滤波器。我们将上述频率提取应用于噪声特征和引导特征。然后,将高/低频率分别输入到局部和全局分支中,以突出信息信号。
对于高频局部分支,我们在噪声特征和引导特征上应用动态高通滤波器。我们将两类特征各分为三组,并使用核尺寸为{3,5,7}的深度卷积对特征提取高频,并拼接得到完整的高频特征。然后我们将噪声高频和引导高频相乘,并将结果输入到一个修改后的挤压激励块中,以获得局部注意力图。在挤压激励块中,我们使用Tanh函数而不是sigmoid函数,因为Tanh将注意力权重投射到(−1,1),负权重有助于抑制有害频率。随后,将得到的注意力图与初始高频相乘。然后我们可以获得高频输出。对于低频全局分支,我们使用通道级别的交叉注意力来捕捉有用的全局低频,其中查询Q)来自噪声分支,键(K)和值(V)来自引导分支。注意力图通过Q和K的乘积生成。我们的低频滤波器具有下采样率,应用于Q和K,以同时学习低频空间中的全局表示并降低计算复杂度。然后,将得到的通道注意力图与V相乘。通道间的交叉注意力也能提供比空间版本更低的复杂度。此外,我们部署多头机制来进一步降低复杂度并增强特征空间的多样性。最后,我们聚合初始特征与高/低频分支的输出。
3.实验分析
为综合评估我们方法的去噪性能,论文在近红外引导低光图像去噪和闪光引导无闪光图像去噪两个任务上进行了定性可视化及定量分析实验。
对于近红外引导的低光图像去噪,我们在DVD测试集上评估了RFFNet在高斯-泊松混合噪声条件下的表现。我们将RFFNet与当前最先进的引导图像去噪方法进行了比较,包括DKN、SVLRM、CUNet、SANet和DVN。此外,我们还考虑了单图像去噪方法,如RIDNet、SADNet、NBNet、MPRNet、Restormer和NAFNet。所有比较的方法都是在与我们相同的训练集上训练的。表1显示,我们的方法在三个噪声水平上都取得了最佳结果。
表1 各类方法在DVD数据集上的去噪指标情况
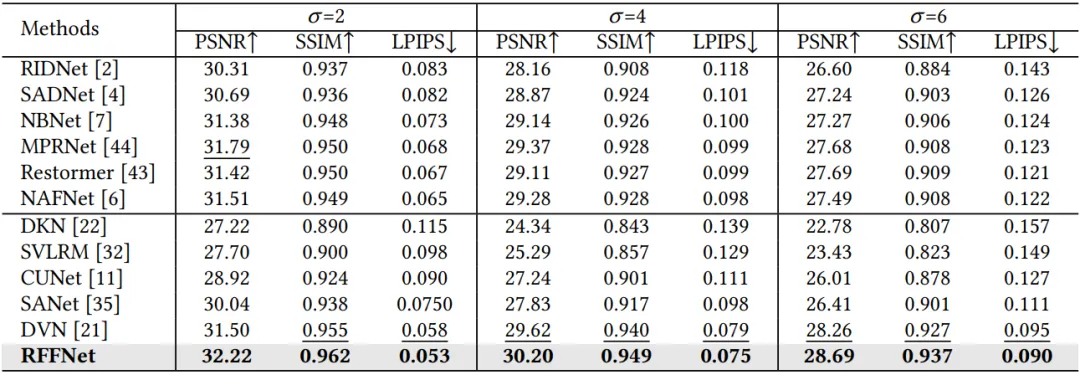

图3 各类方法在DVD数据集上的去噪结果可视化情况
图3中的定性比较清楚地展示了我们的方法在去除噪声、抑制伪影和细节恢复方面相对于其他先进方法的显著优势。对于像NAFNet这样的单张图像去噪器,在弱噪声数据集上取得了满意的结果。然而,随着合成噪声强度的增加,NAFNet不得不牺牲大量的边缘和细节。对于引导去噪方法,SVLRM和CUNet在面临强噪声时不可避免地会产生部分去噪的结果。此外,它们未能处理RGB与NIR图像对之间的不一致性,导致严重的伪影。DVN虽然有效地去除了噪声,但未能估计目标图像的完整结构,因此,NIR图像的细节无法完全融入RGB图像。相比之下,我们的RFFNet展现了强大的去噪能力,并有效地抑制了伪影。此外,我们从NIR图像中提取有用的频率,并选择性地聚合边缘和纹理,得到了细节丰富的结果。
对于闪光引导的无闪光图像去噪,我们在FAID测试集上进行了验证。除了在上述比较的方法外,我们还比较了专门为闪光引导去噪设计的DeepFnF和RIDFnF。为了进一步展示我们方法的优势,我们还提供了小模型(-s)的闪光引导去噪结果,其参数量仅为0.99 M。表2显示,我们的RFFNet,甚至是RFFNet-s,在不同噪声水平下的PSNR、SSIM和LPIPS指标上都优于所有比较方法。
表2 各类方法在FAID数据集上的去噪指标情况
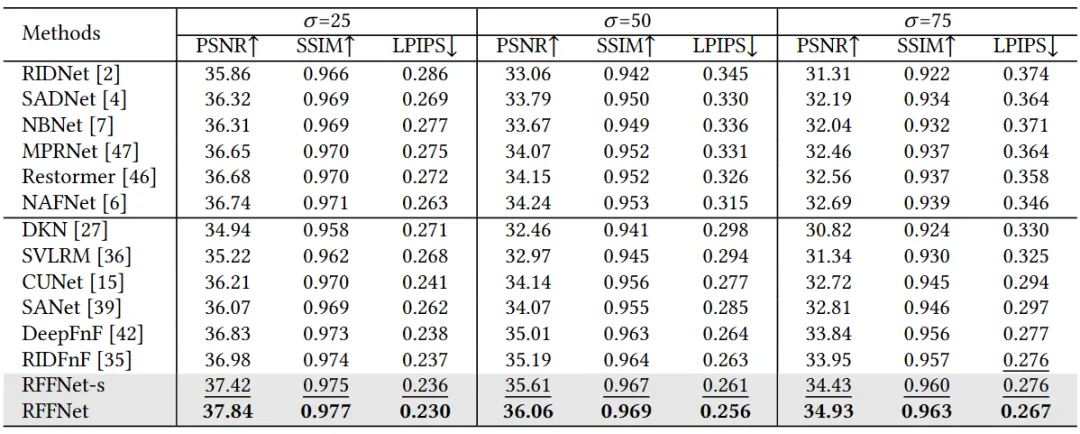

图4 各类方法在DVD数据集上的去噪结果可视化情况
图4显示,Restormer过度平滑了细节。包括CUNet、DeepFnF和RIDFnF在内的引导去噪方法,在底部两张图像中由于闪光图像中的阴影产生了伪影。相比之下,RFFNet完全去除了噪声,并保留了与目标图像一致的精细结构。
此外,如图5所示,与其他基于融合的方法相比,我们的方法在真实数据上产生了更少的伪影和更好的细节。表3表明,我们的在追求去噪效果的同时也保持了优秀的计算性能。

图5 各类方法在真实数据上的去噪结果可视化情况
表3 各类方法的计算效率

03
Fast Fourier Inception Networks for Occluded Video Prediction
作者:
李平1,2、张陈翰1、徐向华1
单位:
1杭州电子科技大学
2人工智能与数字经济广东省实验室(深圳)
邮箱:
lpcs@hdu.edu.cn;
zch2020@hdu.edu.cn;
xhxu@hdu.edu.cn
论文:
https://ieeexplore.ieee.org/document/10236005
代码:
https://github.com/mlvccn/research/tree/main/FFINet_VidPre
1.研究动机
视频预测任务旨在根据连续的历史视频帧,对视频的未来状态给出近似估计,并输出预测视频片段,可以应用于雷达气象图预测、交通热力图预测、自动驾驶以及机器人控制等实际应用场景。然而现有的视频预测方法均假设输入视频帧为无损表示,不包含任何的噪声,但在实际应用场景中视频预测会受到各类噪声例如遮挡噪声、对抗噪声的干扰,影响模型的预测结果。
本文拟解决的主要挑战有两个:1)实际应用场景存在镜头被污染、遮挡,目标被其他物体遮挡等情况,造成目标的外观信息部分丢失,影响对目标动作的准确预测;2)遮挡情况下的视频预测模型不仅要对遮挡部分填充,还要对视频的时空特征做预测;可归纳为时空感受野狭窄和遮挡类噪声破坏时空连续性问题。其中,时空感受野狭小是指现有多数工作难以利用相隔较远的视频帧所包含的时空特征,导致难以捕获复杂长期依赖关系。当视频中发生突变时,未来时刻的视频帧应更多地依赖其邻近时刻的视频帧;但当视频场景中的多个运动物体出现频繁的重叠情况,使得运动物体邻近区域图像的像素值分布产生多次突变,要求模型能利用较远时刻重叠发生前的视频帧。此外,现有的基于深度学习的视频预测模型均假设视频是无损表示,未考虑真实场景中遮挡类噪声的影响,其会破坏时间和空间特征的连续性,例如气象雷达发射的电磁波会由于山体的阻挡导致雷达回波图上出现遮挡区域,遮挡区域会对后续预测结果产生很大的干扰。
2.方法概述
针对视频预测模型时空感受野狭窄与遮挡类噪声影响时空连续性问题,本文提出一种利用快速傅里叶变换的遮挡视频预测模型(Fast Fourier Inception Network for Occluded video prediction,FFINet)。该方法首次探讨了遮挡视频预测任务,具体根据傅里叶理论中的频谱卷积定理(频域中单个像素的变化会影响频域中所有的特征)设计的傅里叶单元(Fourier Unit),具备全局时空感受野,能够利用更远时刻的时空特征,生成更真实的预测视频帧。同时,为了更好地处理带有遮挡的输入视频帧,FFINet在视频预测模型的基础上增加了遮挡还原部分Inpainter(修补器)和还原损失,将遮挡视频预测任务拆分成两个阶段,即先对遮挡视频帧进行还原,再根据还原的视频帧对未来进行预测。还原损失不同于以往视频预测任务计算模型输出和未来视频帧之间的损失,而计算经过修补器还原后的视频帧和不包含遮挡的输入视频帧之间的损失,使修补器专注对遮挡部分缺失的空间特征进行还原。
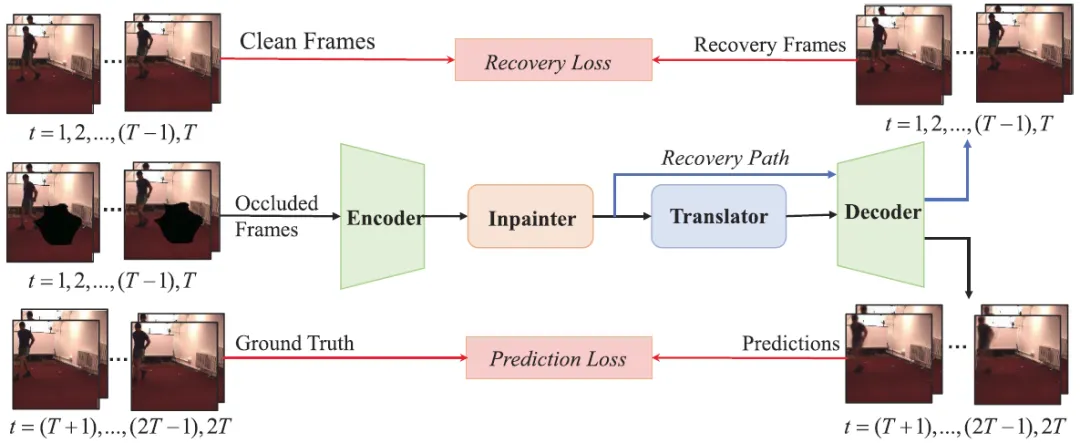
图1遮挡视频预测任务示意图
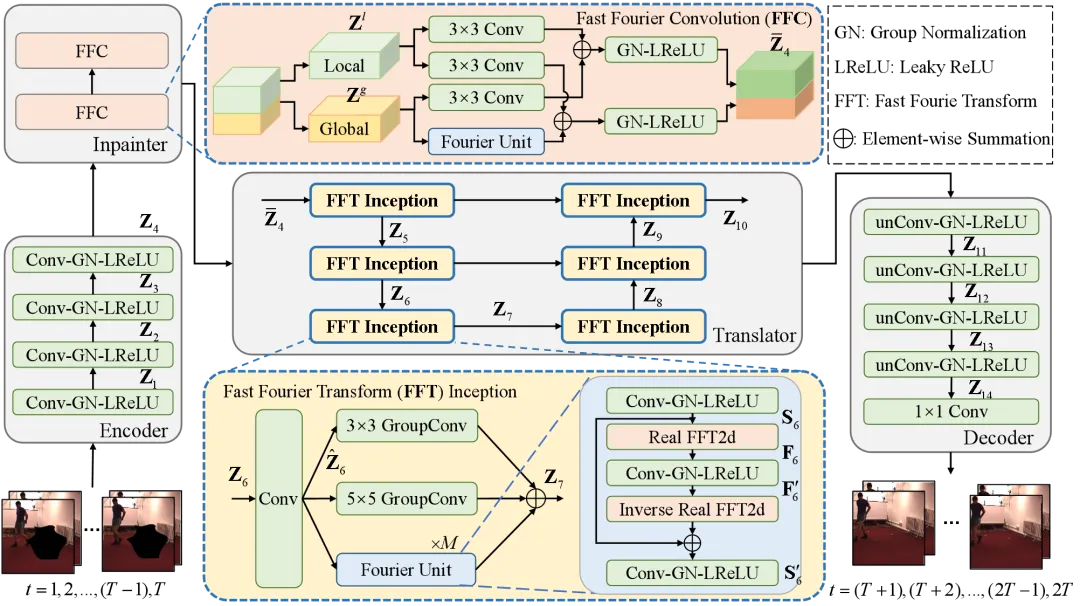
图2 遮挡视频预测方法FFINet的框架图
3.实验
本文在基准数据集MovingMNIST、TaxiBJ、Human3.6M、KITTI&Caltech Pedestrian和KTH上开展实验,验证了所提FFINet模型的有效性。表1给出了无遮挡视频预测方法的性能比较, FFINet利用傅里叶变换获取全局时空感受野,让模型能够利用较长时刻前的时空特征表示,大大加强了字符频繁重叠情况下的预测能力,在所有指标上均超过现有方法。表2和表3分别给出遮挡情形下在Moving MNIST和TaxiBJ上的性能比较,可以发现过去方法没有考虑视频中的遮挡情况,在失去遮挡区域的空间特征后,难以提取到足以刻画视频目标的动作模式的时空特征,进而导致预测结果模糊,而FFINet能够利用全局时空特征先对遮挡部分进行还原,再依据还原后的时空特征对后续视频帧进行预测,不仅在无遮挡情况下性能超过所有方法,在数据集存在遮挡情况下三个指标的降幅最小。图3展示了FFINet和主流方法在Moving MNIST数据集上有无遮挡两种情形下的定性结果,上部分无遮挡时的大部分输入视频帧中字符“4”和“8”之间存在大面积重叠情况,FFINet能预测得到清晰且稳定的字符“4”,展现了其在困难情况下强大的预测能力;下部分有遮挡时示例中字符“3”和“5”被长期遮挡,FFINet利用全局时空上下文对字符“3”进行还原,然后预测得到清晰的结果。
表1 无遮挡视频预测方法的性能比较
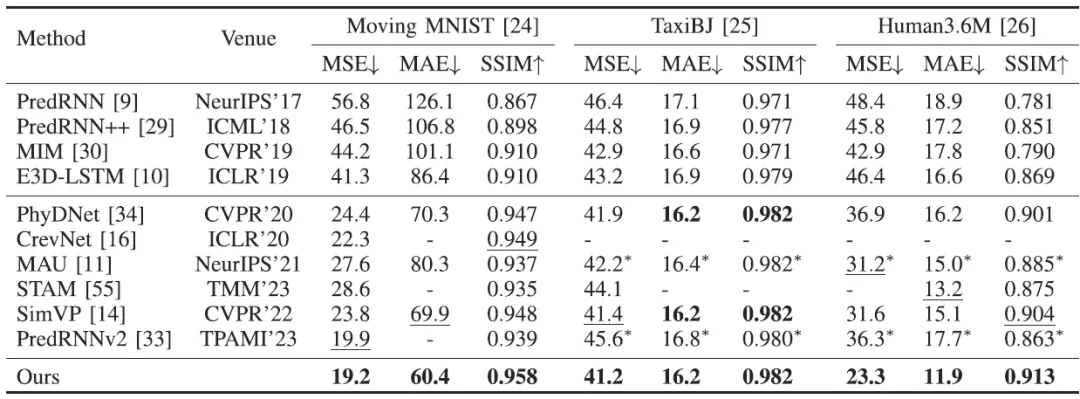
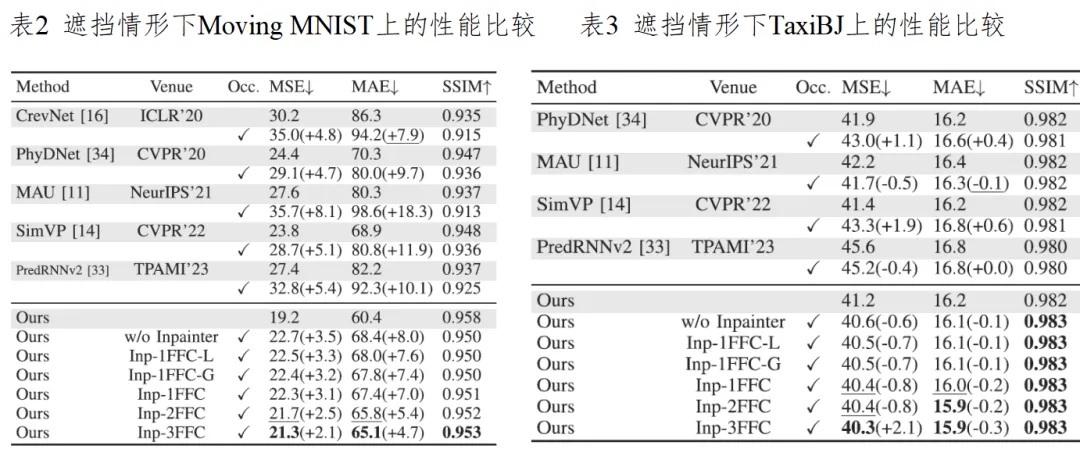
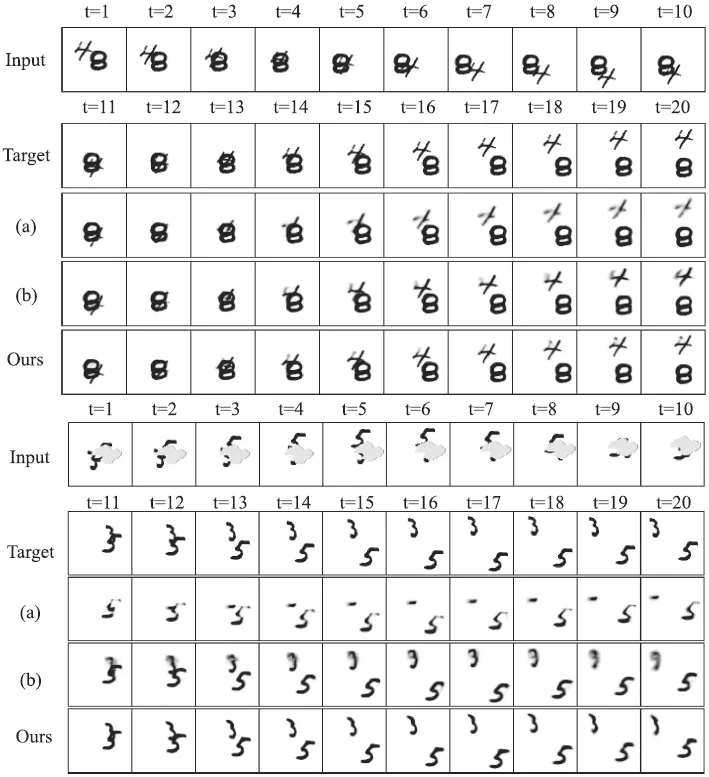
图3 遮挡视频预测方法FFINet的框架图
04
Unsupervised Monocular Estimation of Depth and Visual Odometry Using Attention and Depth-Pose Consistency Loss
作者:
宋霄罡*1,胡浩越1,梁莉1,石伟伟1,谢国1,鲁晓锋1,黑新宏1
单位:
西安理工大学
邮箱:
songxg@xaut.edu.cn;
786059151@qq.com;
liangli@xaut.edu.cn;
296988125@qq.com;
luxiaofeng@xuat.edu.cn;
heixinhong@xaut.edu.cn
论文:
https://ieeexplore.ieee.org/document/10243088
*通讯作者
1.研究背景和动机
深度估计是三维重建、自动驾驶等领域中关键环节,对于场景理解至关重要。无监督学习的单目深度估计方法具有便于部署、成本低的优点。尺度模糊和病态区域是无监督单目模型中存在的两个问题。尺度模糊问题是由于框架的训练样本是三个相邻的单目帧,缺乏全局约束导致。为了限制不同训练样本间尺度不一致性,本文利用深度信息和位姿信息间的几何一致性原理构建了深度-位姿一致性损失,得到全局一致的尺度。针对由动态物体和遮挡违反光度一致性假设而引起的病态区域,提出了由深度-位姿一致性损失衍生的覆盖掩膜,采用过滤及对异常值分配较低权重策略,减轻病态区域对网络训练的不利影响,提升模型性能。
2.方法概述
本文提出一种基于注意力机制和深度-位姿一致性损失的无监督单目深度估计方法ADPDepth,包括深度估计和位姿估计两部分,其模型框架如图1所示。选取三个相邻图像帧(It-1,It,It+1),分为参考帧Is和目标帧It(It-1,It+1),分别输入ADPDepth,估计出相应的稠密深度图Ds和Dt,并将Is和It聚合后作为位姿估计网络的输入,生成两相邻帧之间的相对相机位姿。
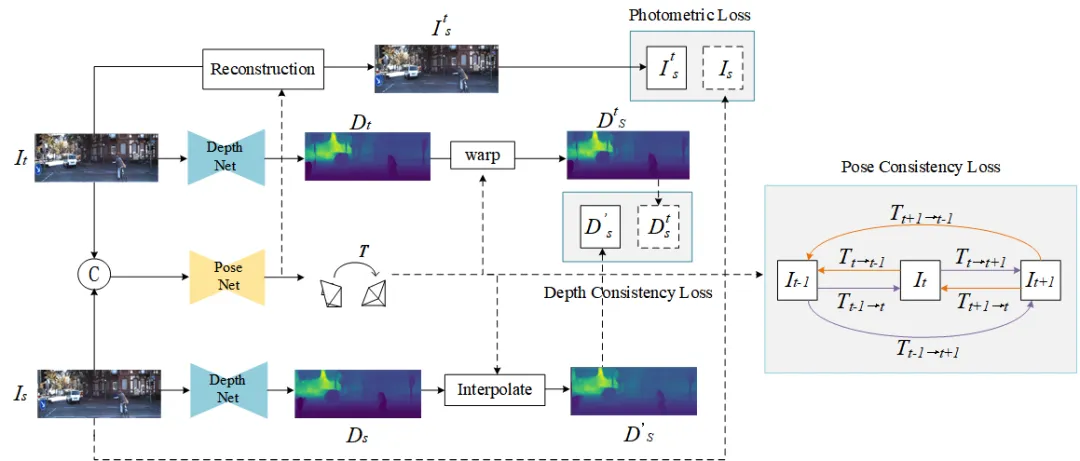
图1 ADPDepth模型框架
深度估计网络的结构如图2所示,采用编码器-解码器结构,并建立长跳跃连接,使解码器可以融合更多的细节信息。深度网络每次以一帧作为输入,估计四个不同尺度的视差图。将金字塔通道注意力模块PCAModule插入编码器的四个残差块后,网络能够捕获多尺度的空间信息,并赋予更有用的特征更多的关注,提升深度估计性能,恢复出更多的细节信息。
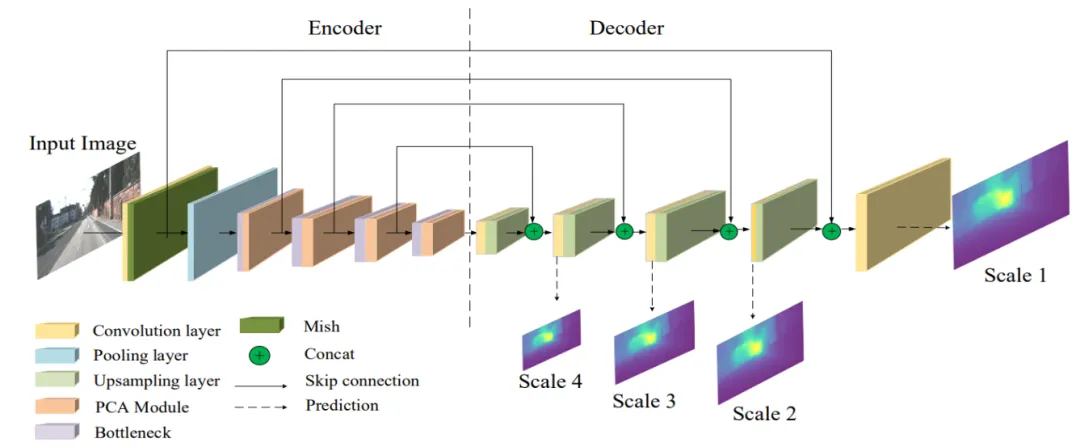
图2 深度估计网络结构
设计PACModule的目的是构建一种有效的注意力机制,克服卷积神经网络在特征提取过程中感受野有限的局限性。如图3所示,采用多分支的策略处理输入特征;利用SEWeight模块获取通道注意力权值,提取不同尺度特征图的通道相关性,将元素级乘积应用于权重和相应的特征映射;对不同尺度上重新加权的特征图进行串联融合;最后,通过利用通道洗牌操作对组进行重新排列,使不同分支之间实现信息交互。
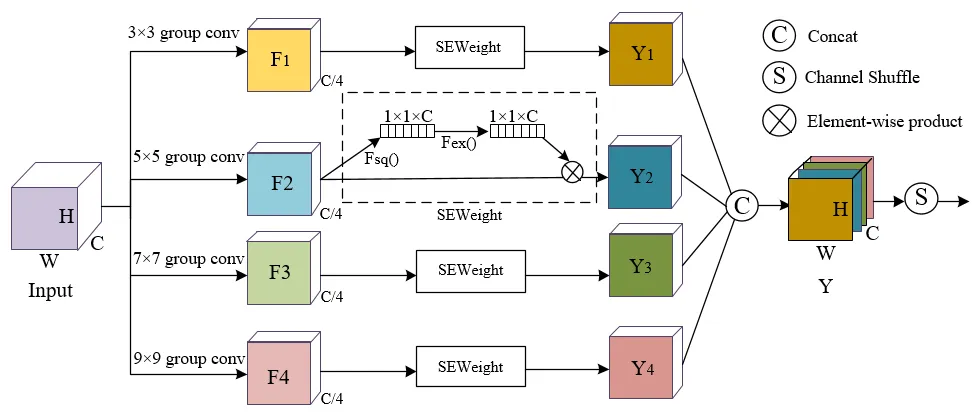
图3 金字塔通道注意模块结构
3.实验分析
本文同时使用KITTI和NYUv2两种数据集对模型进行深度估计性能评估,表1和表2分别为KITTI和NYUv2数据集上的深度估计对比结果;图4和图5分别为KITTI和NYUv2数据集上的深度估计可视化结果。实验对比结果表明,本方法在物体重建方面表现更好,尤其是在汽车、树木、行人、路灯柱、路障等一些小型物体上生成了更清晰的边界和细节。
表1 数据集KITTI上的深度估计对比结果
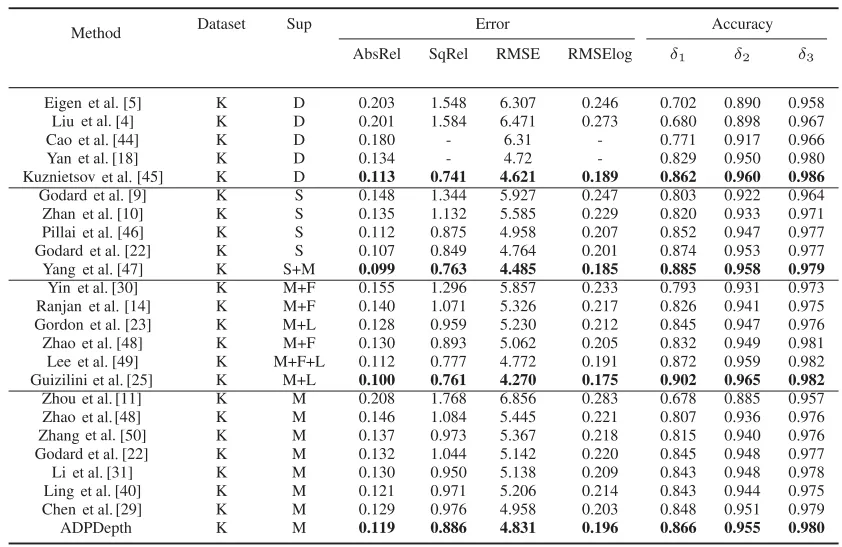
表2 数据集NYUv2上的深度估计对比结果
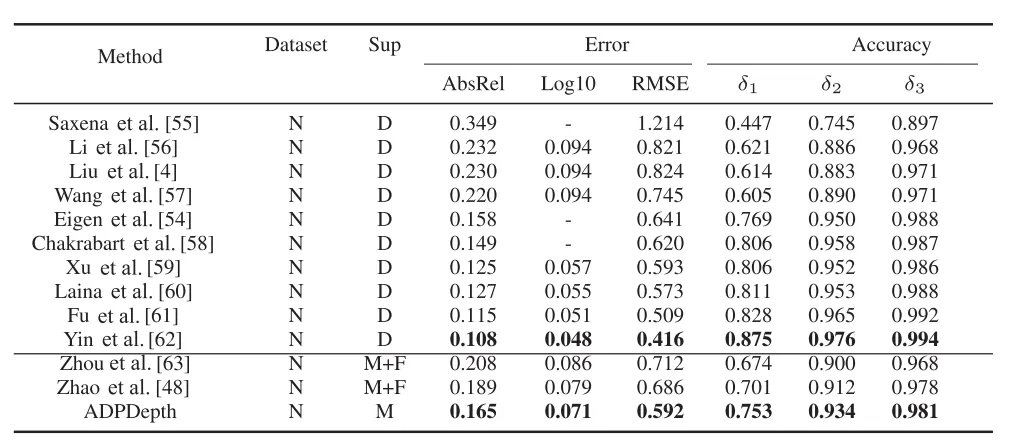
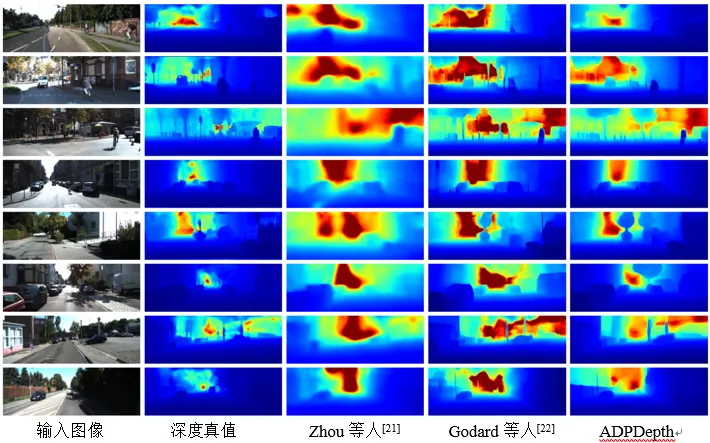
图4 KITTI数据集上的深度估计可视化结果

图5 NYUv2数据集上的深度估计可视化结果
05
MFNet:Real-time motion focus network for video frame interpolation
作者:
朱国淞 ,秦臻,丁熠,刘瑶,秦志光
单位:
电子科技大学网络与数据安全四川省重点实验室
邮箱:
202111090804@std.uestc.edu.cn;
qinzhen@uestc.edu.cn;
yi.ding@uestc.edu.cn;
ly@uestc.edu.cn;
qinzg@uestc.edu.cn
论文:
https://ieeexplore.ieee.org/document/10231373
1.论文简介
视频帧插值作为计算机视觉领域的一个热门研究课题,在视频处理任务中得到了广泛的应用。然而,在实际应用中,该任务往往受到处理速度慢或内存消耗高的限制。实际上,在很多视频场景中,运动目标往往处于运动叠加状态,与背景不一致。因此,预测运动目标的中间状态与预测背景的难度差异明显。
为了准确预测运动叠加下的目标中间状态并节约预测背景的简单线性运动所需的计算资源,本文提出了一种名为MFNet的帧插值网络,该网络专注于运动区域,包括一个用于从背景中高效分离运动区域的采样器、一个用于直接近似中间流的细粒度模块,以及一个用于双向光学流融合的轻量级模块。这个采样器结合了我们所提出的新颖的运动分解算法,能够对复杂的叠加运动进行分解,并抑制光照变化的干扰。随后框架为运动目标与背景采取不同的中间帧预测手段,分别预测出两者中间状态后进行融合,并经过新颖的边缘校正网络优化融合边缘。这样做的好处在于,对复杂运动进行分解后预测能够有效降低伪影出现的概率,并有效节约了背景预测所消耗的计算资源。
广泛的实验表明,我们的MFNet在某些帧插值任务上实现了最优精度,并且在效率方面也优于其他先进的方法。此外,将MFNet的核心组件移植到其他帧插值网络中可以显著提高性能。本文整体框架流程图如图1所示:
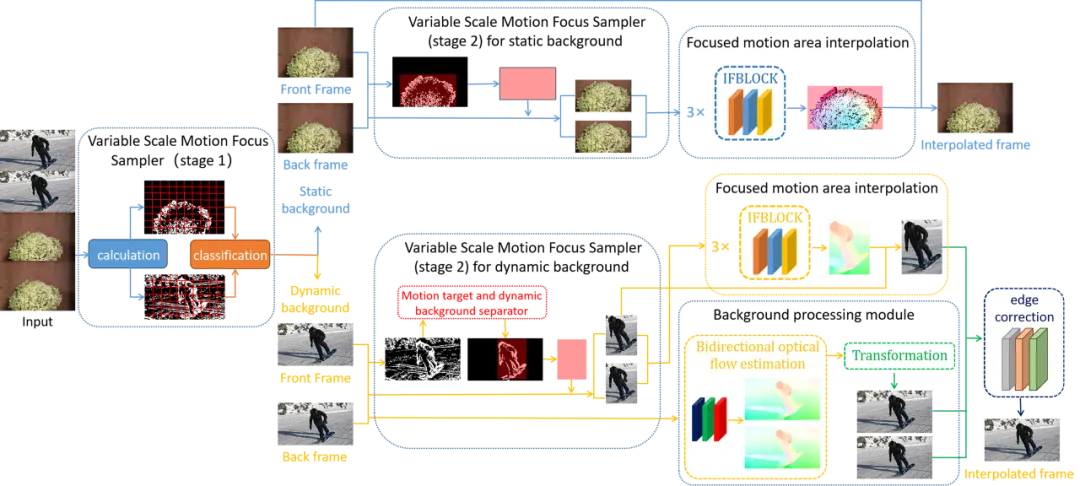
图1 整体框架流程图

编辑人:吴建龙、任文琦
专委会责任副主任:张勇东

微信扫一扫
关注该公众号
 京公网安备11010802017125号
京公网安备11010802017125号