
【论文导读】2024年论文导读第十七期
【论文导读】2024年论文导读第十七期
CCF多媒体专委会 2024年08月27日 14:28 北京


论文导读
2024年论文导读第十七期(总第一百零八期)
目 录
|
1 |
SgVA-CLIP: Semantic-guided Visual Adapting of Vision-Language Models for Few-shot Image Classification |
|
2 |
Semi-Supervised Domain Adaptation for Major Depressive Disorder Detection |
|
3 |
Hierarchical Local-Global Transformer for Temporal Sentence Grounding |
|
4 |
Reversible data hiding-based contrast enhancement with multi-group stretching for ROI of medical image |
|
5 |
Find Gold in Sand: Fine-Grained Similarity Mining for Domain-Adaptive Crowd Counting |
01
SgVA-CLIP: Semantic-guided Visual Adapting of Vision-Language Models for Few-shot Image Classification
作者:
彭芳1,2,3,杨小汕1,2,3,肖麟慧1,2,3,王耀威2,徐常胜1,2,3
单位:
1中国科学院自动化研究所多模态人工智能系统全国重点实验室(MAIS);
2鹏城实验室;
3中国科学院大学人工智能学院
邮箱:
pengfang21@mails.ucas.ac.cn;
xiaoshan.yang@nlpr.ia.ac.cn;
xiaolinhui16@mails.ucas.ac.cn;
wangyw@pcl.ac.cn;
csxu@nlpr.ia.ac.cn
论文:
https://ieeexplore.ieee.org/abstract/document/10243119
代码:
https://github.com/FannierPeng/SgVA-CLIP
发表期刊:TMM2023
论文简介
近年来,多模态预训练大模型快速发展,在图文对话问答,音视频理解等多模态任务上取得了显著的成果。通过在海量多模态数据(如RGB、自然语言、视频、深度图、点云、音频等)上的预训练,模型能够学到不同模态之间的语义对齐和关联关系,对跨模态任务构建底层的多模态知识表征。但是由于预训练阶段和下游任务之间存在数据分布差异问题和数据异构问题,直接将多模态预训练模型的底层通用知识应用到下游任务上是不可靠的。当下游任务的数据稀缺时,直接应用预训练模型容易出现过拟合问题,导致性能下降明显,因此如何以少量的样本将多模态预训练模型的知识快速迁移到新任务上存在挑战。针对上述问题,我们提出了一种基于语义引导的视觉语言预训练模型的小样本自适应迁移学习方法(SgVA-CLIP),联合使用视觉特异性对比损失,跨模态对比损失和隐式知识蒸馏来产生具有判别性的任务相关的视觉特征。具体地,视觉特异性对比损失将模态对齐阶段被忽略的视觉信息建模出来;隐式知识蒸馏将跨模态空间中相对语义距离的细粒度约束作为视觉自适应层额外的监督,利用语义引导视觉特征的自适应学习,有助于提高视觉特征的判别能力。最后,综合考虑基于任务相关视觉特征空间和预训练跨模态特征空间的样本关系,两者融合增强模型的小样本迁移能力。在无需大规模微调的情况下,我们的方法在13个小样本图像分类数据集上达到领先性能。
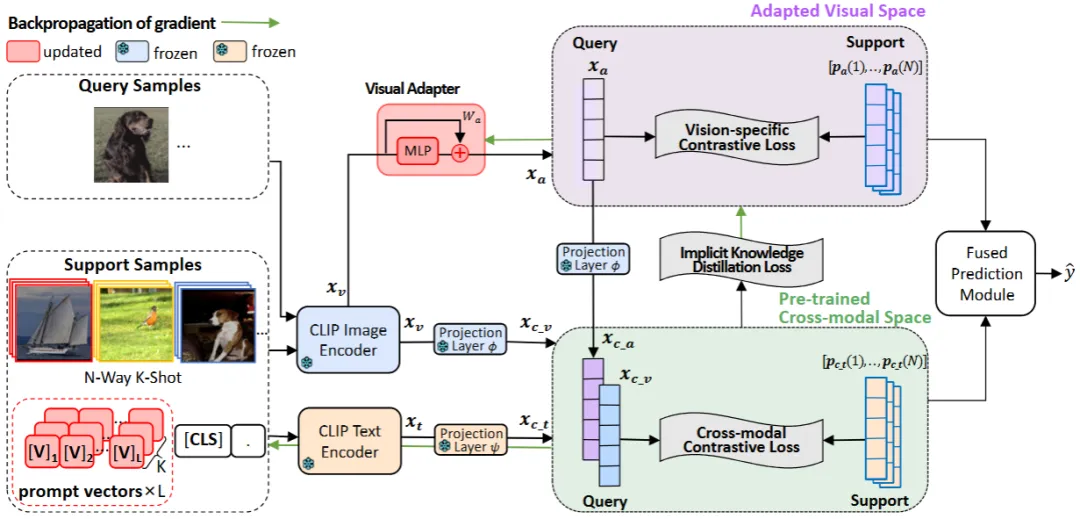
图1 模型的整体框架
模型的整体框架如图1所示,概述如下:我们提出的基于语义引导的自适应迁移学习方法(SgVA-CLIP),旨在通过预训练的CLIP模型学到的跨模态知识来引导学习判别性的视觉特征。这些自适应学习的视觉特征能够很好地补充跨模态特征的不足,从而提升小样本图像分类的能力。具体来说, 在预训练的跨模态空间中,我们通过对支持样本的文本嵌入特征进行了平均池化,构建了跨模态原型。同时,在自适应学习的视觉空间中,我们通过Visual Adapting Layer学习后的视觉特征来构建视觉原型,提出vision-specific对比损失将模态对齐阶段被忽略的视觉信息建模出来。另外,为了充分利用预训练的跨模态知识来指导Visual Adapting Layer,我们还提出了隐式知识蒸馏隐式知识蒸馏利用跨模态特征空间中的细粒度关系来指导Visual Adapting Layer的学习,以产生更具判别性的视觉特征。 我们所提出的隐式知识蒸馏方法,通过投影层(即φ)将视觉特征xa映射到跨模态空间,然后利用预训练的跨模态信息提供的样本间相对语义距离的约束作为额外的监督,隐式地指导Visual Adapting Layer的学习,我们定义了一个新的知识蒸馏损失。知识蒸馏在跨模态空间中进行,梯度被反向传播到Visual Adapting Layer。
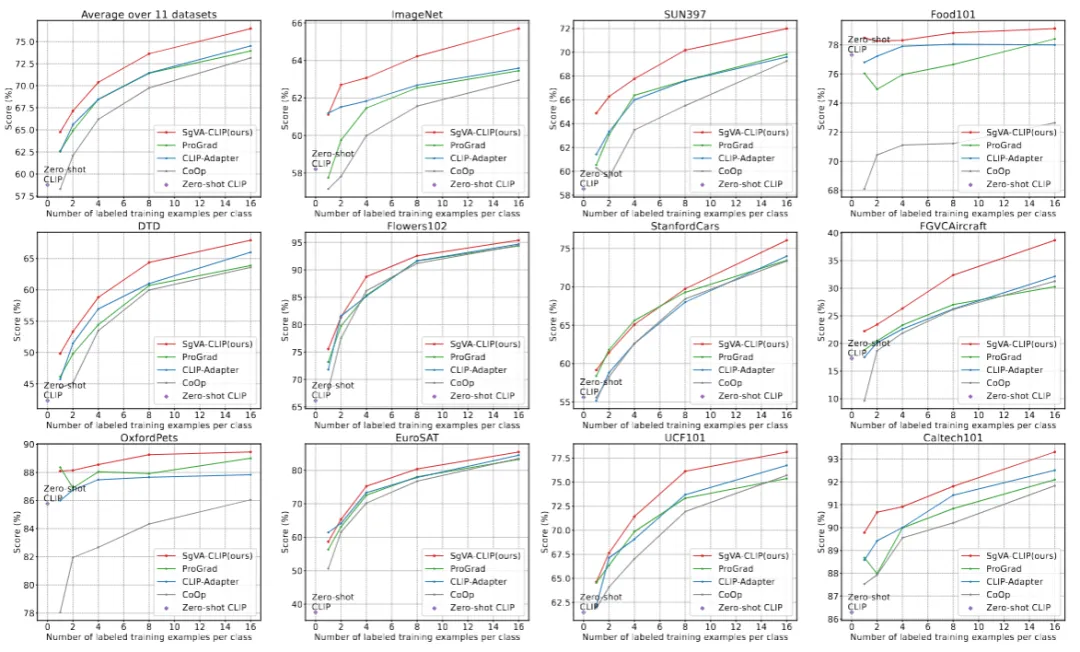
图2 在11个数据集上与SOTA小样本学习方法(无基类)的比较
02
Semi-Supervised Domain Adaptation for Major Depressive Disorder Detection
作者:
陈涛1,郭艳蓉1*,郝世杰1,洪日昌1*
单位:
1合肥工业大学
邮箱:
chentao.hfut@mail.hfut.eud.cn;
yrguo@hfut.edu.cn;
hfut.hsj@gmail.com;
hongrc.hfut@gmail.com
论文:
https://ieeexplore.ieee.org/abstract/document/10243061
发表期刊:TMM2023
*通讯作者
1. 研究背景和动机
鉴于真实场景下抑郁障碍数据的稀缺性,深度学习模型不得不依赖于来自多家医疗机构的抑郁障碍数据,并采用域适应模型来应对不同数据分布之间的差异。一般来说,现有的域适应框架通常专注于单一的域适应范式。然而,在临床实践中,源域和目标域的数量往往不是固定的,这种不确定性极大地制约了域适应模型在实际场景中的应用和推广。另外,这些方法一般采用固定阈值为无标签样本分配伪标签,但其中包含的噪声伪标签可能导致模型在后续训练中朝错误方向优化,从而削弱伪标签学习的有效性并加剧误差累积。此外,类不平衡问题导致模型在处理无标签样本时可能会存在预测偏差,这意味着模型更倾向于将无标签样本预测为多数类别,忽略了少数类别。上述问题相互叠加,进一步加剧了类别不平衡问题,增加了任务的挑战性。
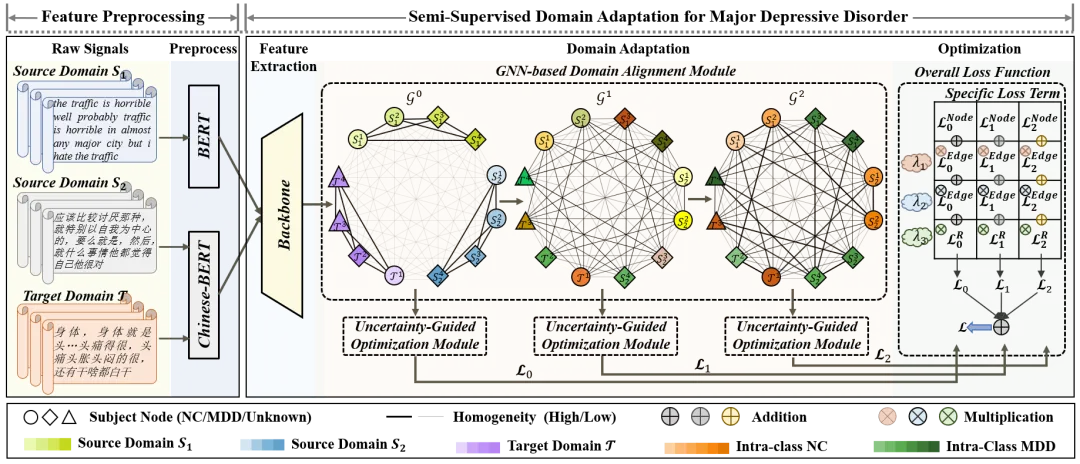
图1 本文所提方法的总体框架图
2.方法概述
针对上述问题,本文提出了一种基于图神经网络的域适应抑郁障碍识别方法(GNN-SDA)。总体网络结构如图1所示,其主要包含两个模块。
(1)基于GNN的域对齐模块将每个样本作为节点,并学习节点之间的连接关系。通过GNN的信息传播机制,同类节点在特征空间中趋于相似,不同类节点彼此远离,从而实现个体级域对齐。此外,该模块可以扩展到不同的域适应范式,从而增强了其在不同数据分布和任务设置下的适应性和通用性。
(2)不确定性引导优化模块通过学习伪标签的不确定性并将其视为衰减项,从而缓解噪声伪标签可能带来的负面影响。且该模块结合标签样本、无标签样本及其不确定性,优化类权重的学习过程,从而有效缓解类不平衡问题。

图2 基于GNN的域对齐模块(左)和不确定性引导优化模块(右)的详细结构
3.实验结果与分析
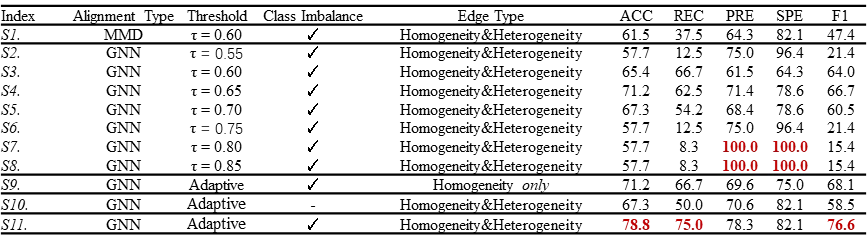
为了验证GNN-SDA的性能,本文在DAIC-WOZ、EATD、CMDC和MODM数据集上与目前的域适应方法进行了对比,包括:单源-单目标域适应(SSDA)方法和单源-多目标域适应(SMDA)方法。实验结果表明,GNN-SDA在所有数据集上的表现均优于现有方法,以表1中的结果为例,提出的模型在多个评价指标上都显示出了明显的优势。GNN-SDA不仅在准确性和鲁棒性方面表现突出,还展现出高度的灵活性,可以有效扩展到不同的域适应范式。
表1 不同域适应方法性能比较
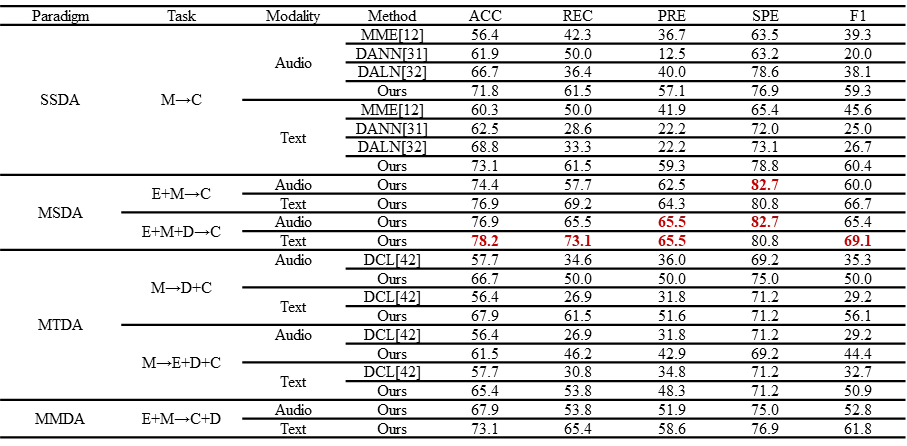
表2展示了使用动态阈值在抑郁障碍识别任务上的有效性,与固定阈值相比,使用动态阈值的方法在处理噪声伪标签的问题上表现出了显著的优势。此外,通过动态学习类权重,即使在面对负样本较少的情况下,模型依然能够保持高准确性和稳定性,有效避免了类不平衡可能带来的负面影响。
表2 基于不同模块的抑郁障碍预测任务的性能比较 (C+D→M)
实验结果表明,本文方法适用于不同的域适应范式,且能够有效地缓解噪声伪标签和类不平衡问题带来的局限性,为实际应用场景中的抑郁障碍识别提供了可靠的解决方案。
03
Hierarchical Local-Global Transformer for Temporal Sentence Grounding
作者:
方翔,刘岱宗,周潘,徐子川,李瑞轩
单位:
华中科技大学,北京大学,大连理工大学
邮箱:
xfang9508@gmail.com;
dzliu@stu.pku.edu.cn;
panzhou@hust.edu.cn;
z.xu@dlut.edu.cn;
rxli@hust.edu.cn
论文:
https://ieeexplore.ieee.org/abstract/document/10233190
发表期刊:TMM2023
1.简介
时间句子定位(TSG)是一个重要的多媒体问题,旨在根据给定的句子查询准确确定未修剪视频中的特定视频片段。传统的TSG方法主要遵循自上而下或自下而上的框架,而不是端到端的,这些严重依赖耗时的后处理来完善定位结果。最近,一些研究者提出了一些基于Transformer的方法来高效且有效地对视频和句子查询之间的细粒度语义对齐进行建模。尽管这些方法在一定程度上取得了显着的性能,但它们同样将视频帧和查询单词作为关联的Transformer输入,未能捕获具有不同语义的不同粒度级别。为了解决这个问题,在本文中,我们提出了一种全新的分层局部-全局Transformer网络HLGT利用这种层次结构信息并对不同粒度级别和不同模态之间的交互进行建模,以学习更细粒度的多模态表示。具体来说,我们首先将视频和句子查询分割成单独的视频小片段和短语,以通过时域Transformer学习它们的局部上下文和全局相关性。然后,我们引入全局-局部Transformer来学习局部级和全局级语义之间的交互,以实现更好的多模态推理。此外,我们开发了一种新的跨模态循环一致性损失来加强两种模态之间的交互并鼓励它们之间的语义对齐。最后,我们设计了一个全新的跨模态并行Transformer解码器,以集成编码的视觉和文本特征,以实现最终的定位。大量实验表明我们提出的 HLGT 实现了新的最先进的性能,展示了其有效性和计算效率。
2.方法
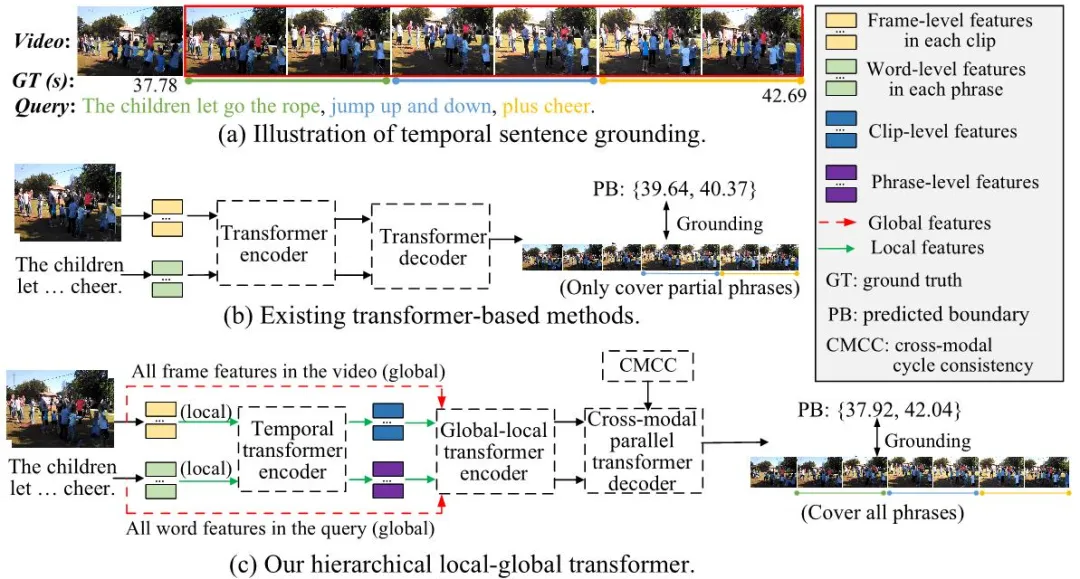
图1 (a) 时间句子定位(TSG)的示例,其中视频包含与句子查询中不同短语语义相关的多个部分。(b) 以往基于Transformer的方法在进行语义配准时,帧级和单词级特征交互作用,无法同时捕捉片段级和短语级语义,容易陷入部分语义匹配问题。(c) 我们的方法开发了一种分层的局部-全局Transformer,以捕捉不同的局部片段-短语语义,并将它们关联起来,对完整句子进行全局推理。
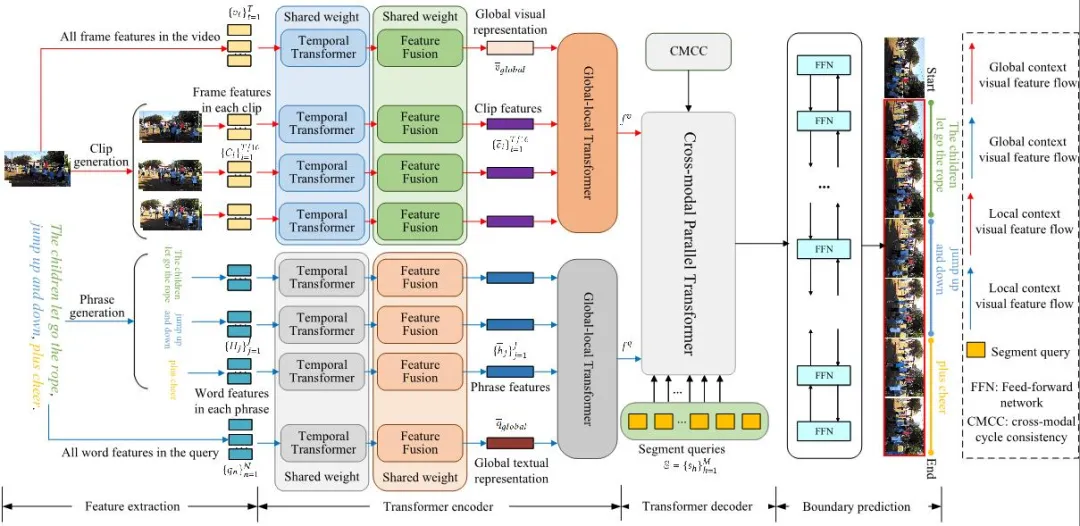
图2 我们提出的 HLGT 模型的整体流程。给定视频和句子查询,我们首先通过特征提取器提取帧级和单词级特征。然后,针对每种模态,我们通过时域Transformer(图3左)和特征融合器生成局部级特征(片段/短语特征)和全局级特征,并基于全局-局部Transformer(图3中)整合这些特征。然后,我们通过跨模态并行Transformer(图3右)将视觉和文本特征进行交互,并设计了一种新的跨模态周期一致性(CMCC)损失来辅助跨模态交互。最后,我们利用带有反馈网络的边界预测头来预测最终的时间片段,以实现准确的定位。
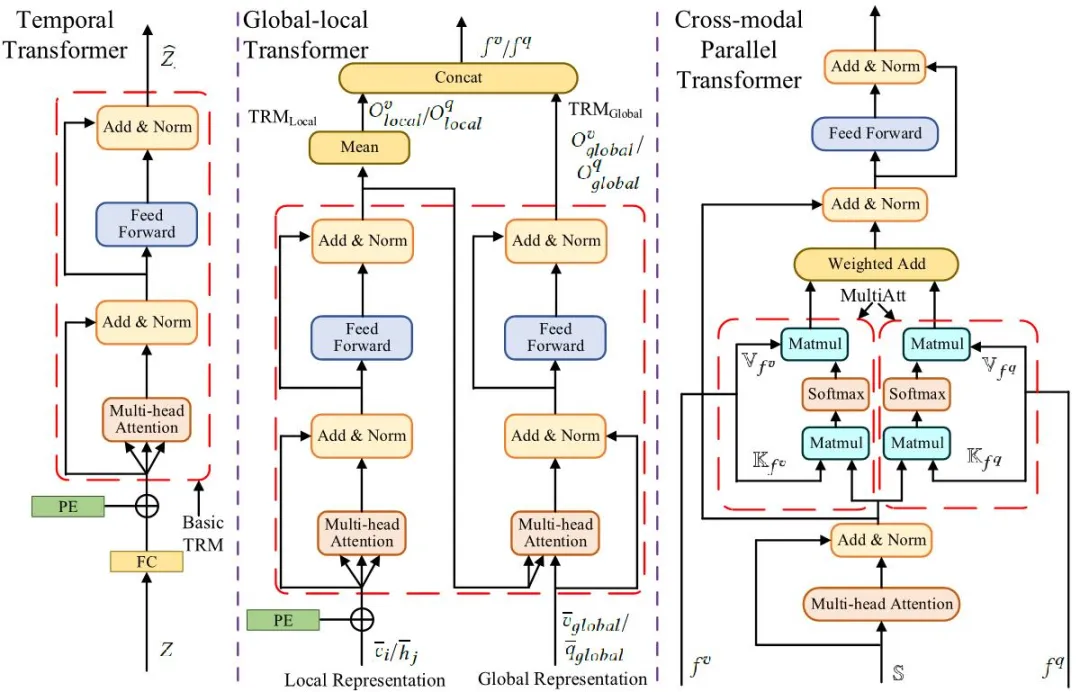
图3 在图2中的不同Transformer。
3.实验
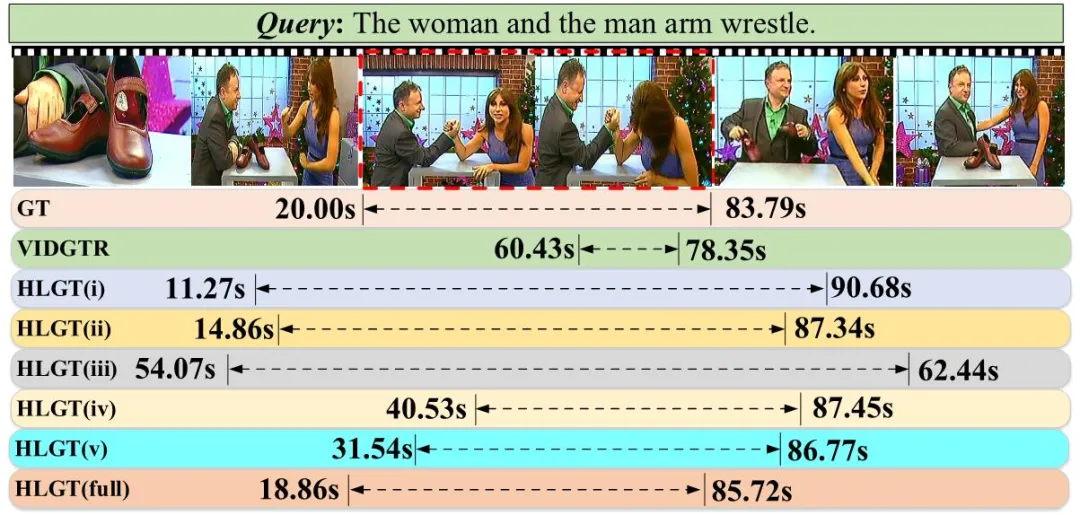
图4 在ActivityNet Captions数据集上TSG任务的定性分析。
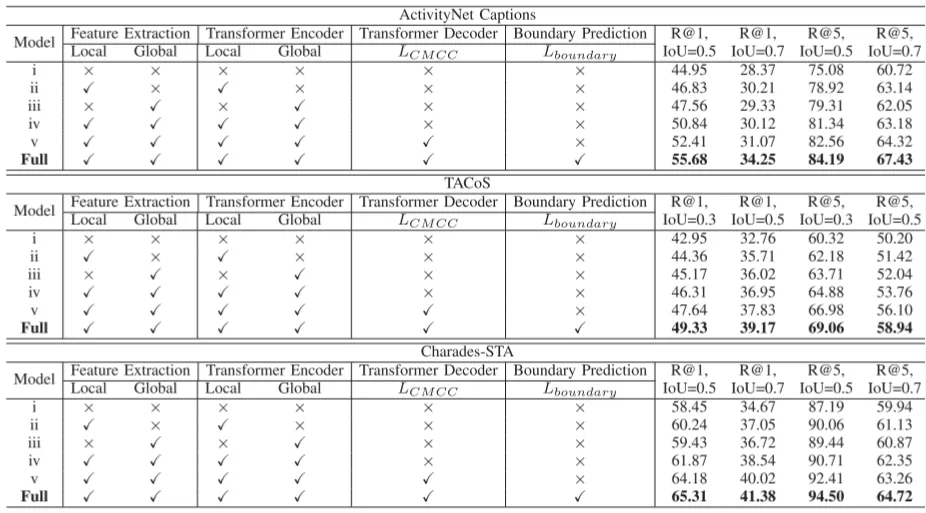
表1 在三个数据集上的定量结果,其中↓表示自顶向下的模型,↑表示自底向上的模型,↕表示端到端的模型。
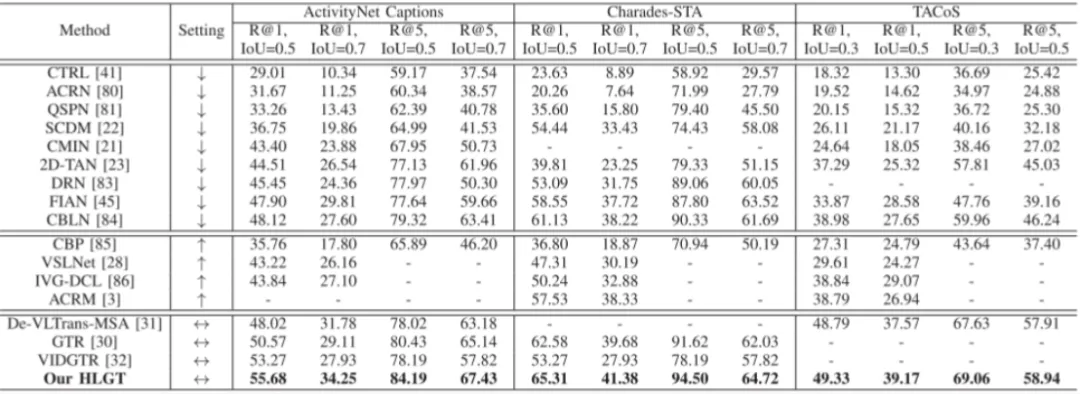
表2 消融实验
04
Reversible data hiding-based contrast enhancement with multi-group stretching for ROI of medical image
作者:
高光勇1,2,3,张辉1,2,夏志华4,罗向阳5,6,施云庆7
单位:
1南京信息工程大学教育部数字取证工程研究中心;
2南京信息工程大学计算机学院;
3郑州信达先进技术研究院;
4暨南大学网络安全学院;
5数学工程与先进计算国家重点实验室;
6河南省网络空间态势感知重点实验室;
7New Jersey Institute of Technology
邮箱:
gaoguangyong@163.com;
2291520135@qq.com;
xia_zhihua@163.com;
xiangyangluo@126.com;
shi@njit.edu
论文:
https://ieeexplore.ieee.org/document/10258312
数据集:
https://www.cancerimagingarchive.net/
发表期刊:TMM2023
1.研究背景和动机
在医疗图像处理领域的实际应用中,由于成像条件不同,生成的原始图像往往不够清晰,会在一定程度上影响医生进行准确的诊断。因此,基于可逆信息隐藏的医疗图像对比度增强技术(Reversible Data Hiding-based Contrast Enhancement, RDHCE)应运而生,它可用于医学图像的对比度增强,是近年来的一个热门研究课题。然而,现有的RDHCE方法存在着对医学图像感兴趣区域(ROI)分割不准确的问题,影响了图像的对比度增强效果。此外,对于两侧空bin较少的ROI直方图,一些方法的通用性存在局限性,导致嵌入容量和对比度增强效果不理想。因此,本文提出了一种改进的医学图像RDHCE方法,其流程如图1所示。
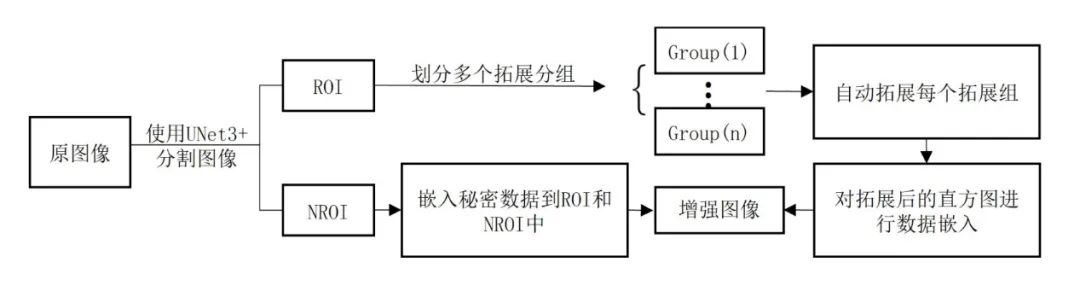
图1 所提出方法的流程图
2.方法概述
本文提出的方法的创新性主要体现在两个模块:ROI分割、ROI的多组拉伸。
ROI分割:利用预先训练好的UNet3+网络模型将医学图像分割为感兴趣区域(ROI)和非感兴趣区域(NROI),为了提高分割精度,该方法在原有UNet3+结构的基础上进行了一定的改进,引入了注意机制CBAM(卷积块注意模块),以提取重要特征并提高网络效率。其分割效果如图2所示。
ROI的多组拉伸:所提出的方法为ROI直方图中的每个bin定义一个标签,该标签的值为0或1。为了划分拓展组,将连续且标签值相同的bin划分到同一个区间,每个区间的标签值由区间所包含的bin的标签值决定。将具有不同标签值的相邻区间组合成拓展组,每组的拓展方向都是从标签值为1的区间到标签值为0的区间。由此将整个直方图划分为需要拉伸的区域和提供拉伸空间的区域。接下来,提供拉伸空间的非空bin被暂时排除在ROI直方图移位和拉伸过程之外,拉伸操作完成后自适应地改变其灰度值。多组拉伸示例图如图3所示。
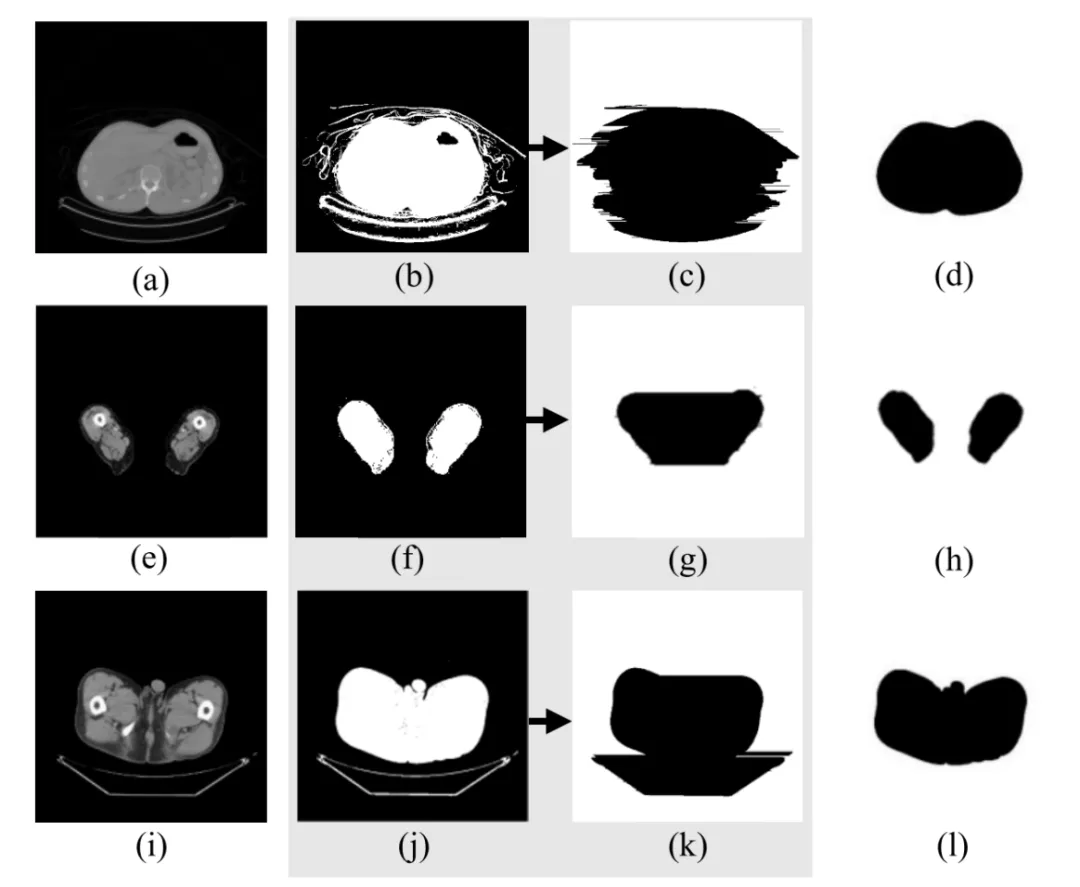
图2 分割效果对比图。(a)、(e)、(i)原始图像;(b)、(f)、(j)ATD分割方法;(c)、(g)、(k)Gao的分割方法;(d)、(h)、(l)本文的分割方法
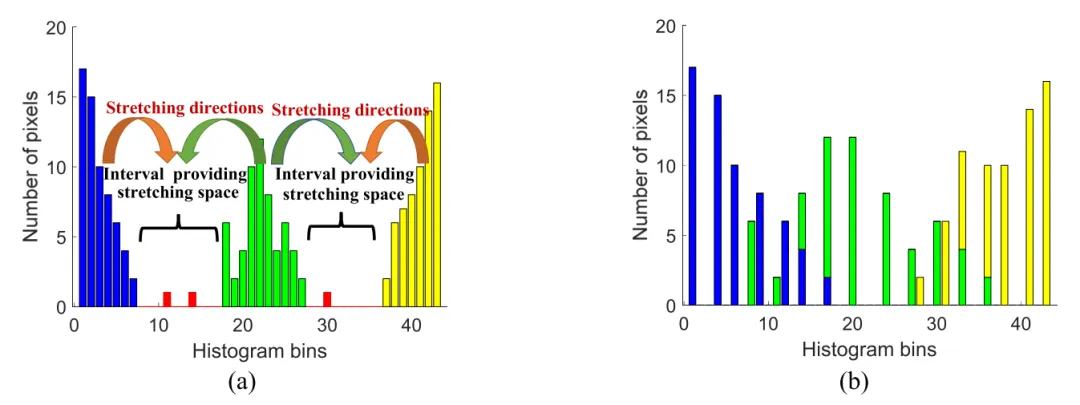
图3 多组拉伸的示例图。(a)拉伸间隔和方向;(b)拉伸后的直方图
3.实验结果
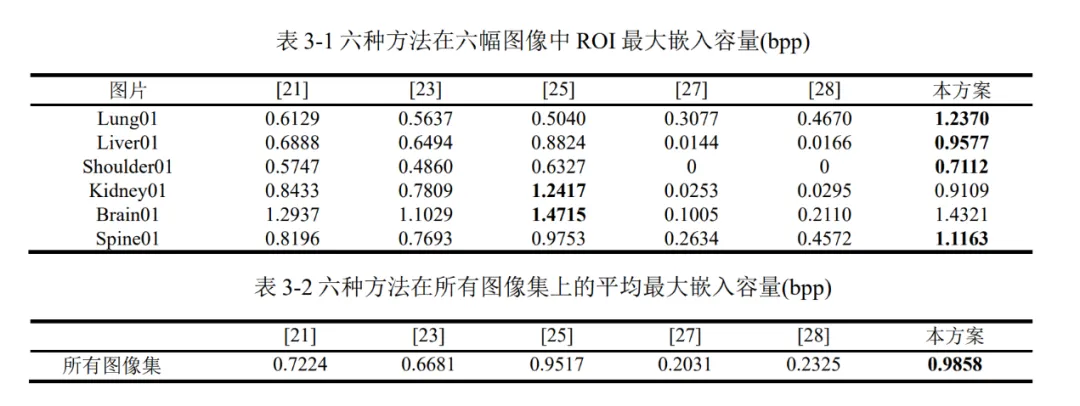
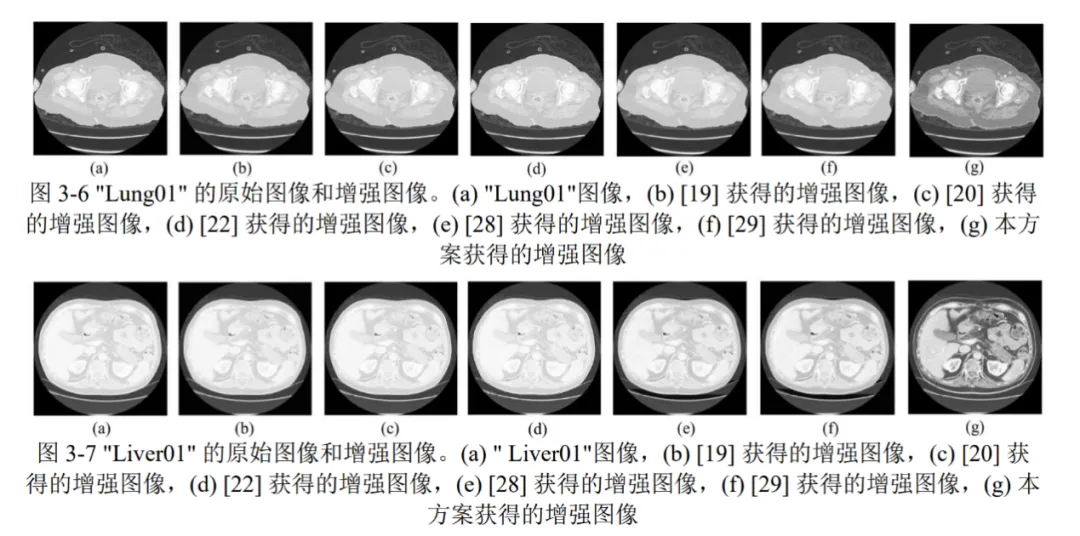
我们从嵌入能力、对比度增强效果和视觉质量三个方面证明了与其他现存方法相比,本文提出的方法具有更好的通用性,生成的增强医疗图像具有更好的视觉质量和更大的ROI嵌入容量。此外,本文章还对所提出的RDHCE算法的安全性和计算复杂度进行了分析。为了确保数据嵌入的可逆性和安全性,该方法使用密钥生成一个序列,该序列可以控制秘密数据嵌入像素的顺序。对于一个拥有p个像素组成的图像,假设对原始图像进行分割后的ROI包含共包含q个像素,并且在进行数据嵌入时,一共进行了t轮嵌入,则所提出的方法的总体计算复杂度为O(qt)。
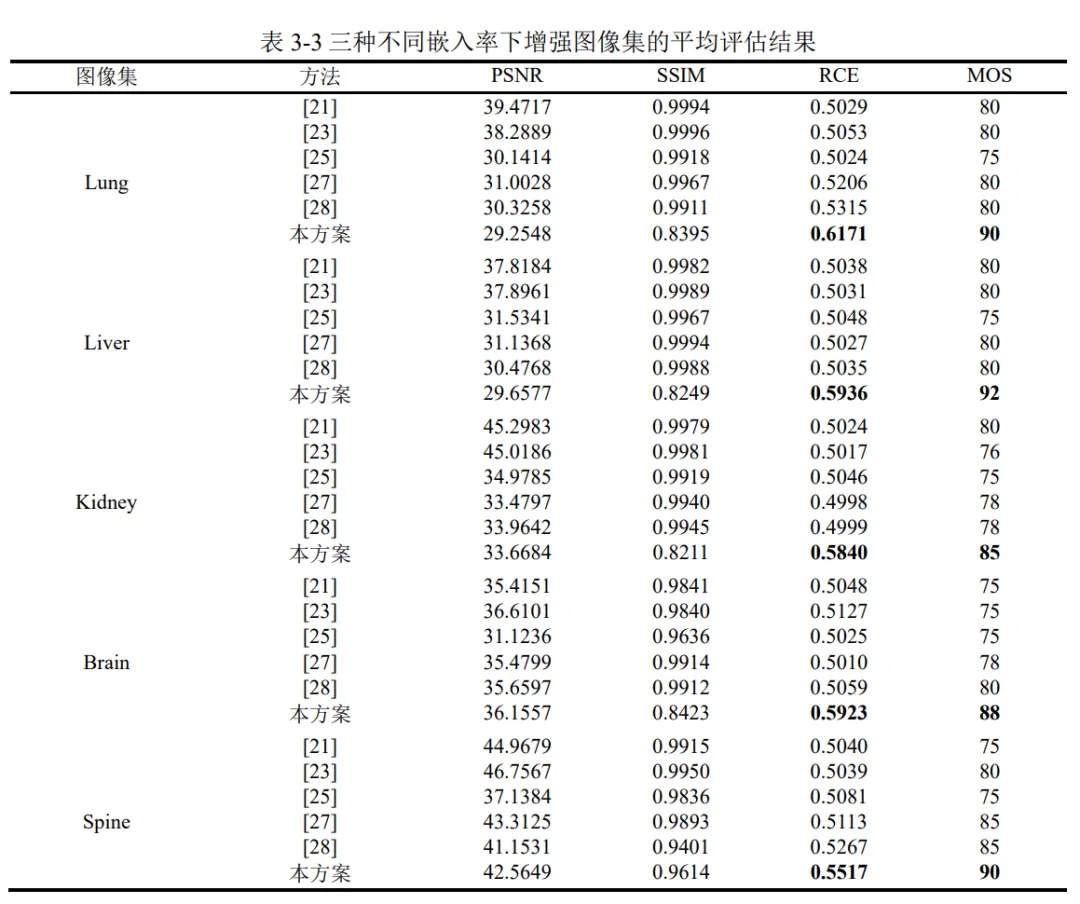
05
Find Gold in Sand: Fine-Grained Similarity Mining for Domain-Adaptive Crowd Counting
作者:
朱慧琳,袁景凌*,钟忺*,廖良,王正
单位:
武汉理工大学,武汉大学
邮箱:
jsj_zhl@whut.edu.cn;
yjl@whut.edu.cn;
zhongx@whut.edu.cn;
liang.liao@ntu.edu.sg;
wangzwhu@whu.edu.cn
论文:
https://ieeexplore.ieee.org/document/10272678
代码:
https://github.com/HopooLinZ/FSIM
发表期刊:TMM2023
*通讯作者
1.动机
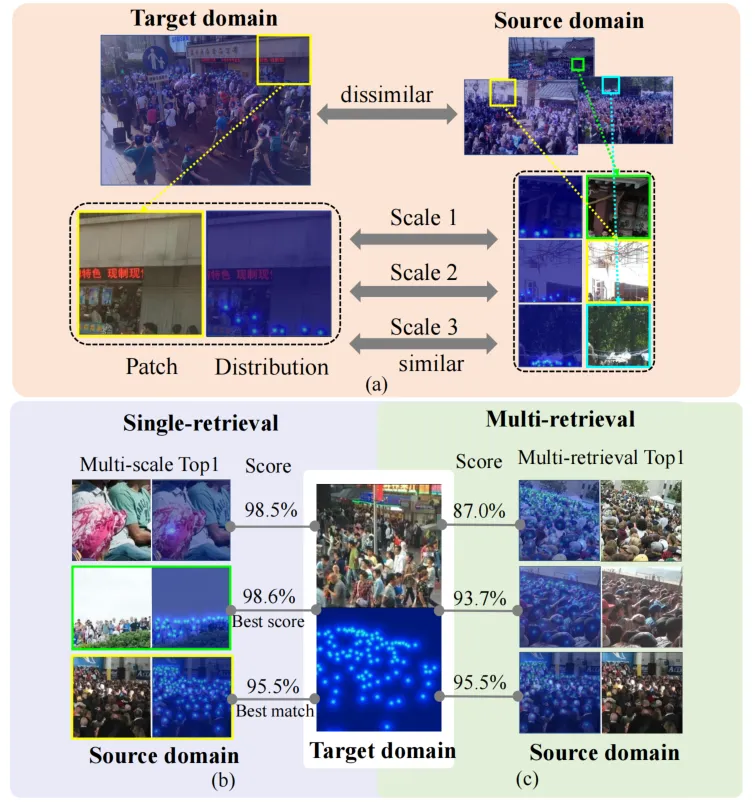
图1 多尺度细粒度相似性和检索错误的示意图
人群计数中的领域适应问题源于不同数据集中人群密度、视角和尺度的多样性,导致源域和目标域数据分布的差异。我们发现了两个关键问题。首先,领域相似性信息的挖掘和利用不足,阻碍了模型的迁移性能,忽略了多尺度的细粒度分布,如图1(a)所示。其次,选择合适的相似性检索方法对最大化领域间关系探索至关重要。单一的相似性检索方法容易出错,而多种方法评估相似性分布时显得不便。图1(b)显示,多尺度检索效果更好,但阈值过滤最佳匹配的方式过于僵化。图1(c)表明,多种检索方法产生了相似的分布,难以确定最佳方法。因此,还有很大潜力进一步挖掘领域间相似性,以更好地捕捉目标域的数据分布并解决领域漂移问题,从而实现更有效的领域适应。相似性挖掘的可靠性也很重要,因为错误挖掘可能影响数据分布建模的准确性和模型的领域迁移能力。
2.方法
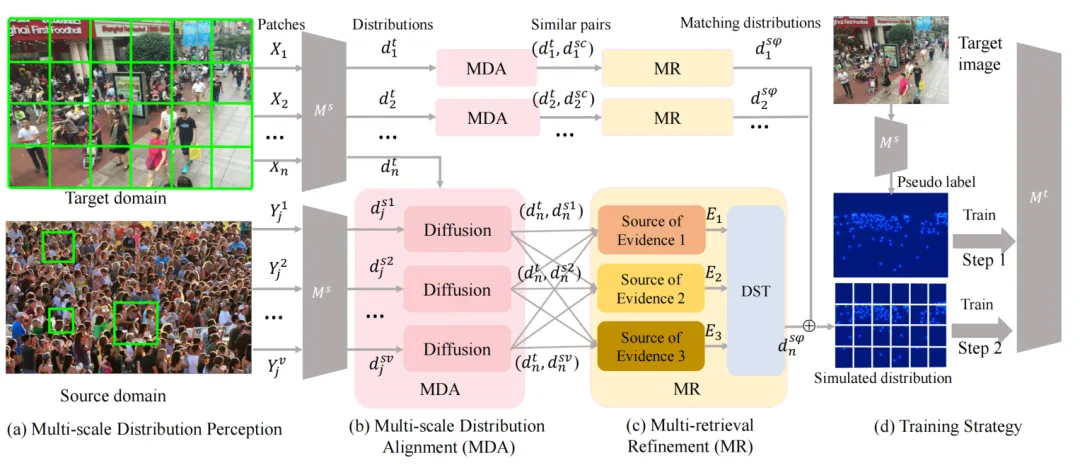
图2 FSIM框架图
为了解决跨领域任务中的细粒度信息不足和相似性干扰问题,我们提出了细粒度相似性挖掘框架(FSIM),如图2所示。首先,我们引入了多尺度分布对齐(MDA)模块,通过滑动窗口策略,从源域和目标域收集多尺度补丁,并使用扩散检索模型对齐这些补丁,得到初步相似的多尺度细粒度分布对。其次,我们开发了多检索精炼(MR)模块,基于Dempster-Shafer证据理论(DST),将不同分布的相似性度量作为证据来源,通过基于证据的决策过程过滤掉不合理的分布,提高结果的可信度,确保分布相似性的精确性,并减轻相似性引起的检索错误影响。
3.评价和结果
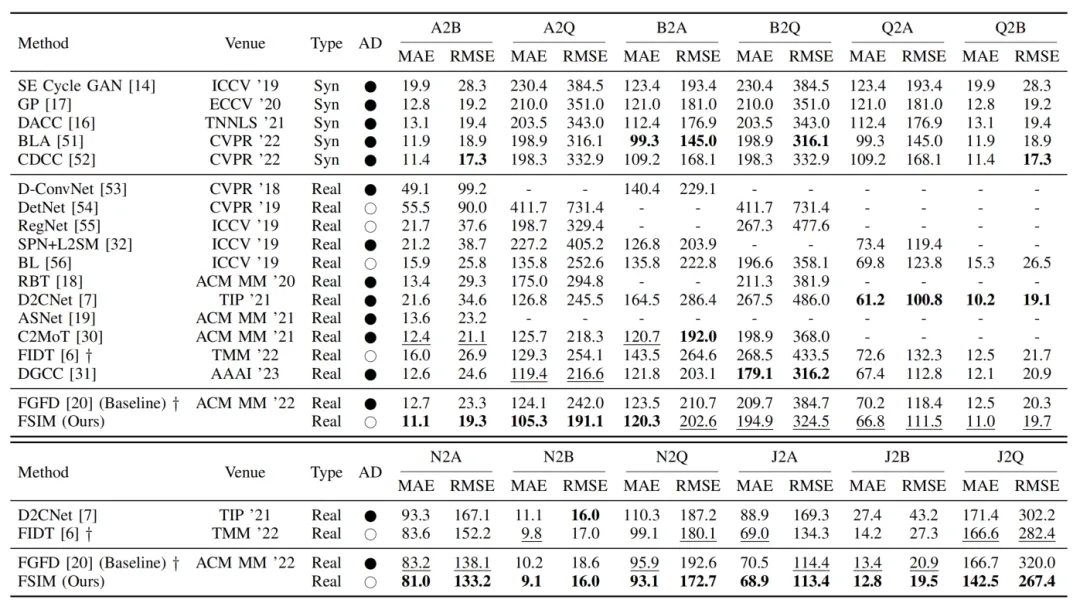
如表1所示,FSIM在所有迁移任务中表现优异,特别是在A2B、A2Q和B2A任务中。这证明了跨域多尺度相似性的存在,并表明FSIM能够有效识别这些相似性,尤其在密度差异显著的数据集中(如A和B)。在Q作为源域的实验中,FSIM在Q2B任务中取得了第二好的结果,显示Q中存在多尺度细粒度的稠密和稀疏信息。FSIM在各种场景中均表现出色,包括从密集到稀疏(A2B)、小规模密集到大规模(A2Q)、小规模稀疏到大规模(B2Q)。
表1 与SOTA方法的实验比较结果
如图3所示,FSIM在这些场景中的表现尤为出色,特别是在A2B任务中,FSIM预测人数与实际人数的差异仅为4,展示了在无监督设置下接近监督学习的效果。

图3 密度图展示

编辑人:吴建龙、任文琦
专委会责任副主任:张勇东

微信扫一扫
关注该公众号
 京公网安备11010802017125号
京公网安备11010802017125号