
【论文导读】2025年论文导读第十一期
【论文导读】2025年论文导读第十一期
2025年6月24日 10:38 北京


论文导读
2025年论文导读第十一期(总第一百二十八期)
目 录
|
1 |
MoTrans: Customized Motion Transfer with Text-driven Video Diffusion Models |
|
2 |
SM4Depth:Seamless Monocular Metric Depth Estimation across Multiple Cameras and Scenes by One Model |
|
3 |
Tangram-Splatting: Optimizing 3D Gaussian Splatting Through Tangram-inspired Shape Priors |
|
4 |
GS3LAM: Gaussian Semantic Splatting SLAM |
|
5 |
Multi-view X-ray Image Synthesis with Multiple Domain Disentanglement from CT Scans |
01
MoTrans: Customized Motion Transfer with Text-driven Video Diffusion Models
作者:
李小民1,贾旭1,王清和1,刁海文1,葛萌萌2,李鹏翔1,何友2,卢湖川1
单位:
1大连理工大学
2清华大学
邮箱:
xmli22@mail.dlut.edu.cn,
jiayushenyang@gmail.com,
qinghewang@mail.dlut.edu.cn,
diaohw@mail.dlut.edu.cn,
gmm21@mails.tsinghua.edu.cn,
lipengxiang@mail.dlut.edu.cn,
heyou_f@126.com,
lhchuan@dlut.edu.cn
论文:
https://dl.acm.org/doi/10.1145/3664647.3680718
发表会议:
ACM MM2024
1.动机
现有的预训练T2V模型经常难以产生复杂的,以人为中心的运动,如高尔夫挥杆和滑板,这些运动涉及多个连续的子运动。一个潜在的原因是这些基础模型主要是在来自互联网的高度多样化的数据集上训练的,这些数据集可能存在数据分布不均的问题。因此,某些运动在数据集中的数据量较少,导致模型对这些运动的训练不足。为了更好地生成特定的运动,这些预训练的T2V模型需要对包含所需运动模式的一小组视频进行微调。然而,在没有任何附加约束的情况下直接微调模型容易导致在有限的参考视频中的运动和外观之间的耦合,并且削弱运动模式的建模能力。
2.方法
针对定制化动作生成,本文提出了基于双阶段外观和运动解耦的运动定制化视频生成。具体来说,本工作拟设计一种双阶段外观运动解耦生成框架,先学习视频中外观信息,再学习时序运动信息,并采用交替学习的策略对空间注意力和时间注意力模块的新增参数进行低秩自适应微调。总体而言,为了防止运动和外观的过度耦合导致参考视频外观的过度迁移,本项目拟在第一阶段分别从文本描述和视觉编码角度增强对参考视频外观信息的学习,并在第二阶段通过多模态表示增强对参考视频中运动模式的学习。具体来说,拟在外观学习阶段,利用提示词重新描述技术,结合视频帧对参考视频原始提示描述进行扩展,使得扩展后的描述既涵盖前景主体外观又包含背景内容,并通过低秩自适应微调更新空间注意力模块参数;在运动学习阶段,拟固定住空间注意力模块参数,促使在时间注意力模块中结合低秩自适应微调技术学习与外观无关的运动信息,实现运动与外观的解耦,避免模型参数对于参考视频外观信息的过拟合,同时,在视频生成过程中,通过进一步计算参考视频的视觉特征,并以残差嵌入表示的方式增强文本描述中相应动词的嵌入向量表示,强化参考视频的动作信息。
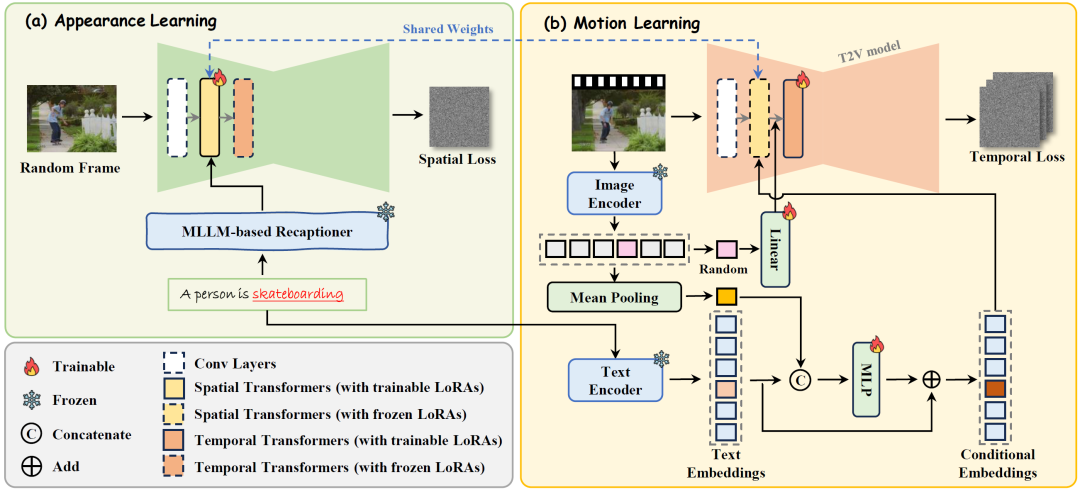
图1 框架图
3.实验结果
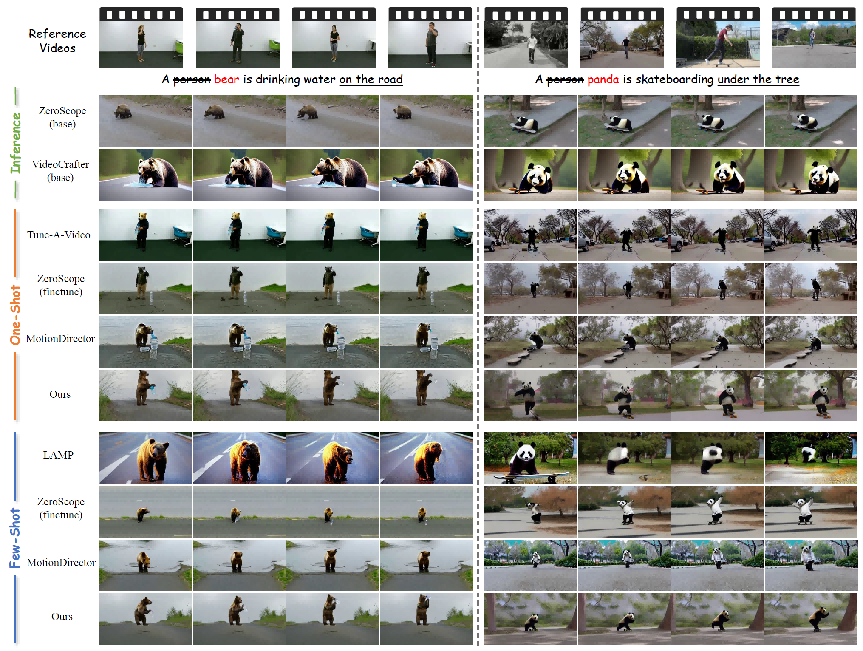
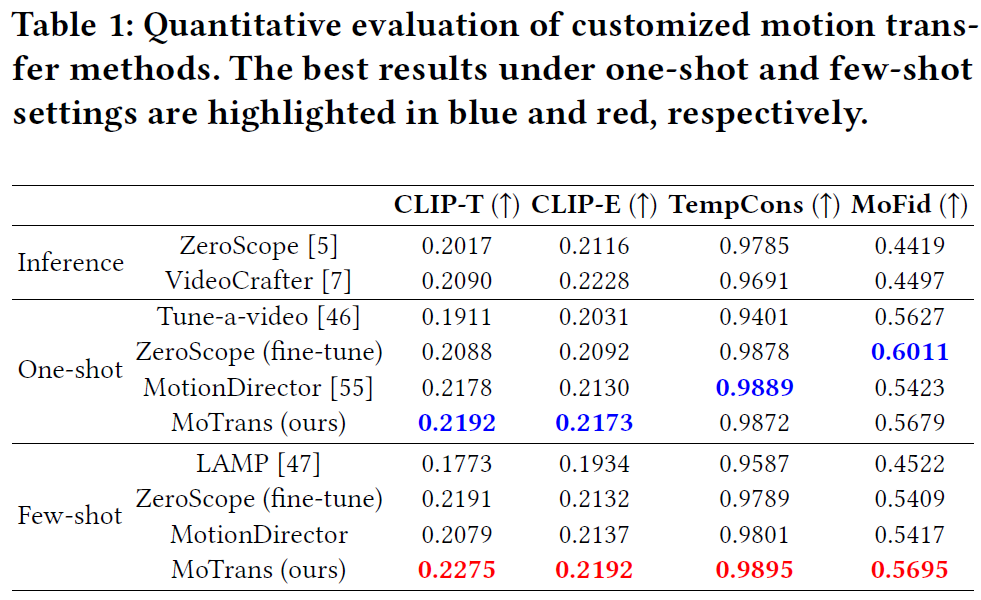
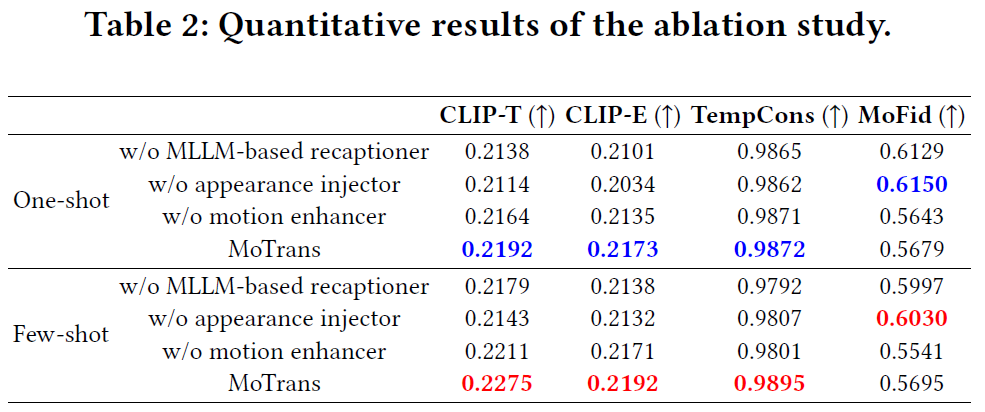
广泛的实验结果表明,我们的方法有效地缓解了过度拟合外观的问题,并产生了高质量的运动,与其他SOTA相比表现良好。为了验证我们的方法的运动定制能力,我们对几种有代表性的开源方法为one-shot和few-shot运动定制进行了比较分析。如下图所示,使用预训练的T2V模型ZeroScope和VideoCrafter无法合成特定的运动模式,因为缺乏在指定的视频上精细的训练过程。此外,合成的视频表现出显着的小运动幅度,这表明预训练的T2V模型难以产生复杂的,以人为中心的运动。特别是,这些模型在没有对特定视频进行有针对性的训练的情况下,在生成特定运动方面面临重大挑战。此外,Zeroscope的无约束微调会导致外观和运动之间产生不希望的耦合,并且生成的视频中的运动与参考视频中的运动不太相似,运动幅度特别小。
Tune-A-Video以单视频定制为目标,基于T2I模型,其帧间平滑度差,外观过拟合严重。类似地,也利用T2I模型的少量运动定制方法灯表现出非常差的时间一致性,并且严重依赖于初始帧的质量。与其他方法相比,LAMP需要更多的参考视频和训练迭代才能获得相对更好的结果。MotionDirector还遇到了外观过度拟合的挑战,通常会产生不切实际的场景,例如穿着人类服装的滑板上的熊猫。此外,它表现出运动模式的建模不足,导致运动幅度减小的视频和与参考视频中观察到的运动的偏差。
然而,我们的方法证明了在few-shot和one-shot运动定制场景中精确捕获运动模式的卓越能力。此外,one-shot方法有时无法辨别是学习相机运动还是前景运动。相比之下,few-shot拍摄方法可以利用来自多个视频的感应偏差,更好地捕捉常见的运动模式。这允许时间变换器专注于前景动作而不是相机动作。
02
SM4Depth: Seamless Monocular Metric Depth Estimation across Multiple Cameras and Scenes by One Model
跨相机跨场景的无缝单目度量深度估计
作者:
刘一好¹,薛峰²,明安龙¹,赵明帅¹,马华东¹,Nicu Sebe²
单位:
¹ 北京邮电大学 ² 意大利特伦托大学
邮箱:
l1h_l1h_l1h@163.com,
feng.xue@unitn.it,
mal@bupt.edu.cn,
mingshuai_z@bupt.edu.cn,
mhd@bupt.edu.cn,
niculae.sebe@unitn.it
论文:
https://doi.org/10.1145/3664647.3681405
代码:
https://github.com/1hao-Liu/SM4Depth
主页:
https://xuefeng-cvr.github.io/SM4Depth
发表会议:ACM MM 2024
1.论文简介
在通用单目深度估计领域近两年取得了长足的进展。然而,面对跨场景数据,模型的精度通常不一致。并且,现有的算法对大规模训练数据高度依赖。为了应对以上挑战,我们提出了一种无需场景特定参数、能同时适用于室内外多种场景的统一模型——SM4Depth。该方法设计了高效的场景尺度学习方法,降低了单目深度估计模型对训练数据规模的高度依赖,实现了室内外一致的单目深度精度。相比于前人的800万和6100万训练数据,SM4Depth仅以15万RGB-D样本对、单张RTX3090训练,即在多个数据集上超越了ZoeDepth-NK、Metric3D。此外,我们发布首个无裁剪RGB-D基准BUPT-Depth用于验证跨场景一致性。
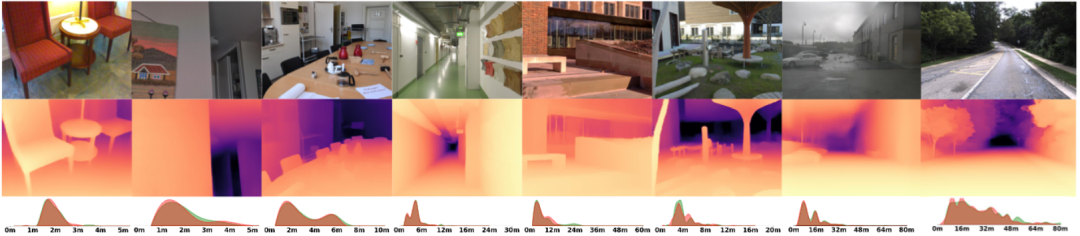
图1 深度预测效果展示
2.方法概述
“跨场景精度不一致”问题与基于变化的深度分箱:现实世界深度跨度巨大,数据集跨度为0.5米至80米,真实世界可能更大。现有的方法通常将图像的度量深度区间划为自适应的分箱,然而,这导致了同一通道的分箱在不同图片上可能存在数十米差异,导致模型训练过程中的监督歧义进而降低了训练效率。为了解决这一问题,我们提出了基于变化的深度分箱(Variation-based depth bin,V-Bin)。该深度分箱依旧由256个数组成。但由于其允许分箱宽度为负,因此针对不同的图片,它仅有少数分箱被激活,使不同场景拥有较为一致的分箱语义,缓解模型训练过程中的监督歧义。
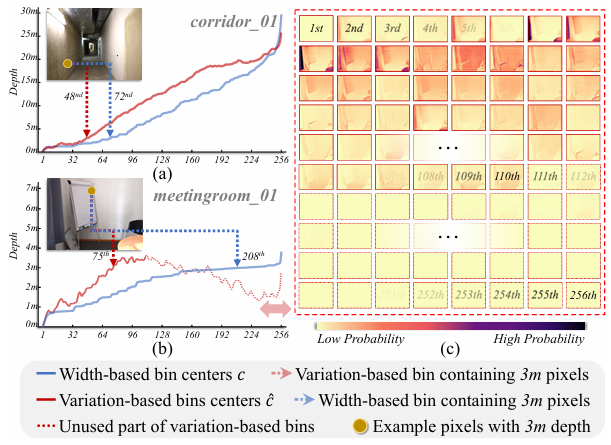
图2 深度分箱对比
“大规模训练数据依赖”问题与域感知的分箱估计:现有的方法为了缓解不同场景不同视野相机的监督低效的问题,通常堆砌800万至6100万级训练数据并依赖多 GPU 集群。为了解决这一问题,我们提出了域感知的分箱估计方法(Domain-aware bin estimation,DBE)。首先将训练数据根据度量深度划分为多个子集,即,将度量尺度的解空间拆成多个尺度域。接着,我们计算图像在每个尺度域的深度分箱,最后通过概率加权拼接回全局深度分箱。
整体结构:SM4Depth 的整体架构由三个主要部分构成:前处理、编码器-变换器模块、解码器。在前处理阶段,为消除“度量歧义”,模型首先对输入图像进行视场(FOV)对齐,统一其拍摄视角。这一步确保了不同相机和场景下图像的尺度信息具有可比性。此外,采用Swin-Transformer提取图像特征,并金字塔场景变换器(Pyramid Scene Transformer,PST)处理不同尺度的视觉信息。在PST阶段,我们采用DBE和V-Bin预测场景尺度。最后我们提出了分层尺度约束的解码器来回复场景尺度并预测深度图。
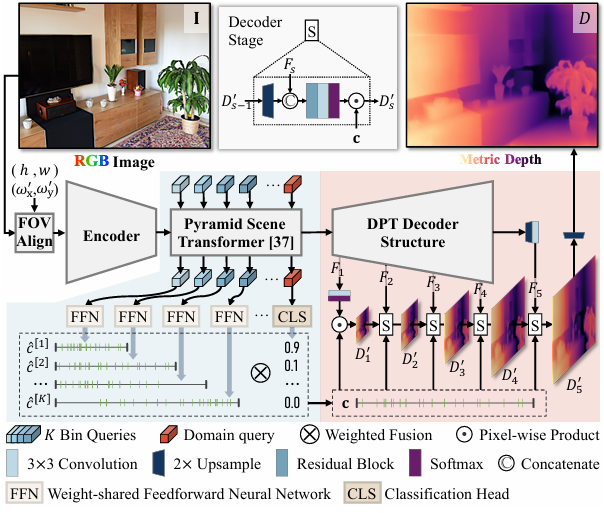
图3 网络整体结构
3.实验结果
1)跨场景一致性:BUPT-Depth(ZED2 GT)上 δ₁=0.536,RMSE=3.44;CREStereo GT上δ₁=0.629,RMSE=2.89,双重领先Metric3D、ZoeDepth-NK与 DepthAnything-NK,且室内-室外误差曲线最平滑。2)多基准零样本:在 SUN-RGBD、ETH3D、DIODE、DDAD 等8基准平均提升δ₁ 4%-58%,ETH3D-Outdoor 相对提升 58%;消融表明去除V-Bin、DBE时,跨域 RMSE 分别升18%、23%,三模块互补性明显。3)数据高效性:训练样本仅15万(Metric3D的0.2%),FLOPs/参数约其一半,却在绝大多数指标匹敌或超越对手;即使在自驾场景nuScenes上,SM4Depth 仍取得-1.285 RMSE的优势,证明模型具备跨相机FOV的泛化潜力。
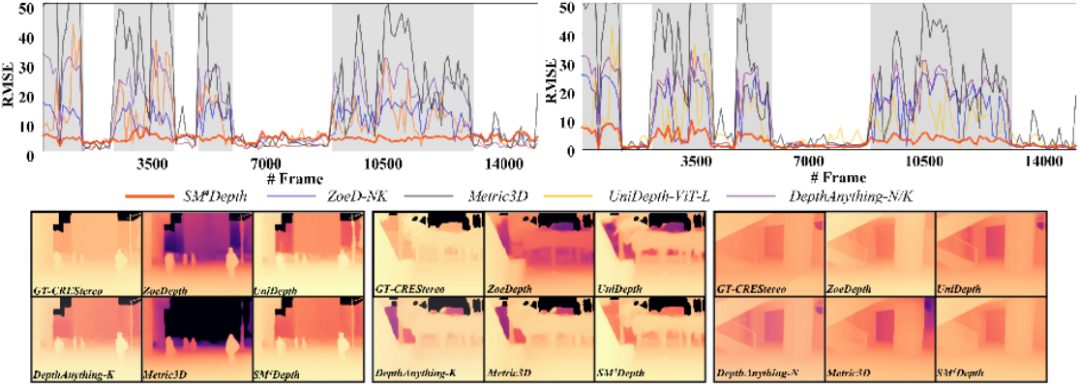
图 2 BUPT-Depth RMSE-帧序曲线
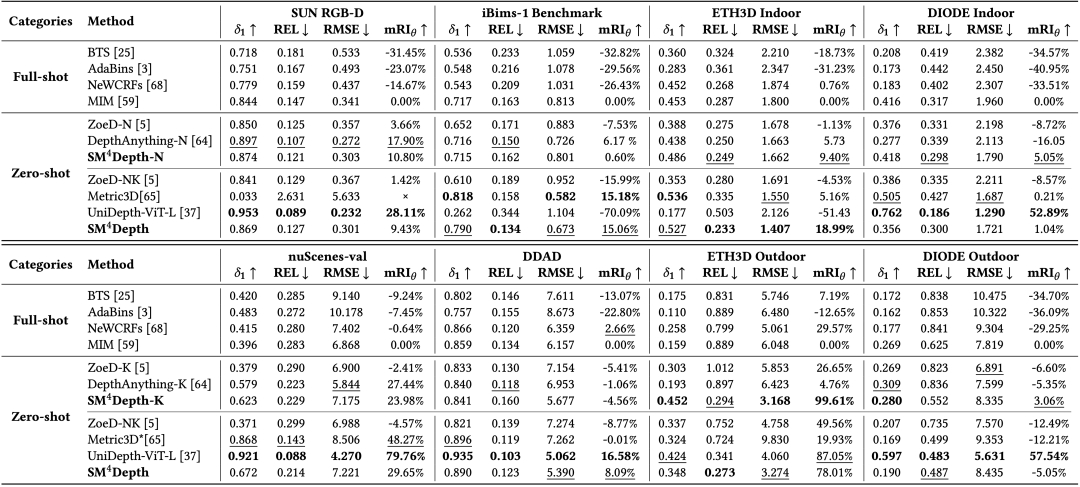
图3 不同方法跨场景深度性能比较

图3 不同方法跨场景深度可视化比较
03
Tangram-Splatting: Optimizing 3D Gaussian Splatting Through Tangram-inspired Shape Priors
作者:
汪怡1,钟柠泽1,陈铭林1,王龙光1,郭裕兰1*
单位:
中山大学1
邮箱:
wangy2356@mail2.sysu.edu.cn,
zhongnz@mail2.sysu.edu.cn,
chenmlin8@mail2.sysu.edu.cn,
wanglg9@mail.sysu.edu.cn,
guoyulan@sysu.edu.cn
论文:
https://dl.acm.org/doi/10.1145/3664647.3680688
发表会议:ACM MM 2024
*通讯作者
1.研究背景
近年来,随着虚拟现实(VR)和增强现实(AR)应用需求的增长,三维重建和新视角合成任务在多媒体领域越来越受欢迎,成为多媒体领域的一个重要课题。然而,新视角合成算法想要在现实场景(如部署在边缘端设备、考虑硬件资源成本)中真正部署,需要考虑计算效率和内存开销两大关键因素。现有的新视角合成算法,如神经辐射场方法,由于密集的体积采样和大型多层感知机计算,导致训练时间较高,渲染过程由于依赖神经网络推理,导致无法实现实时渲染。新兴的三维高斯泼溅方法,提高了新视角合成算法的计算效率,实现了实时渲染,然而由于直接存储整个场景高斯点的参数,导致显著的内存占用。如何设计更紧凑的三维表征,在满足计算效率、渲染实时性要求的同时,降低存储内存的消耗,成为新视角合成算法真正落地的关键。
2.方法概述
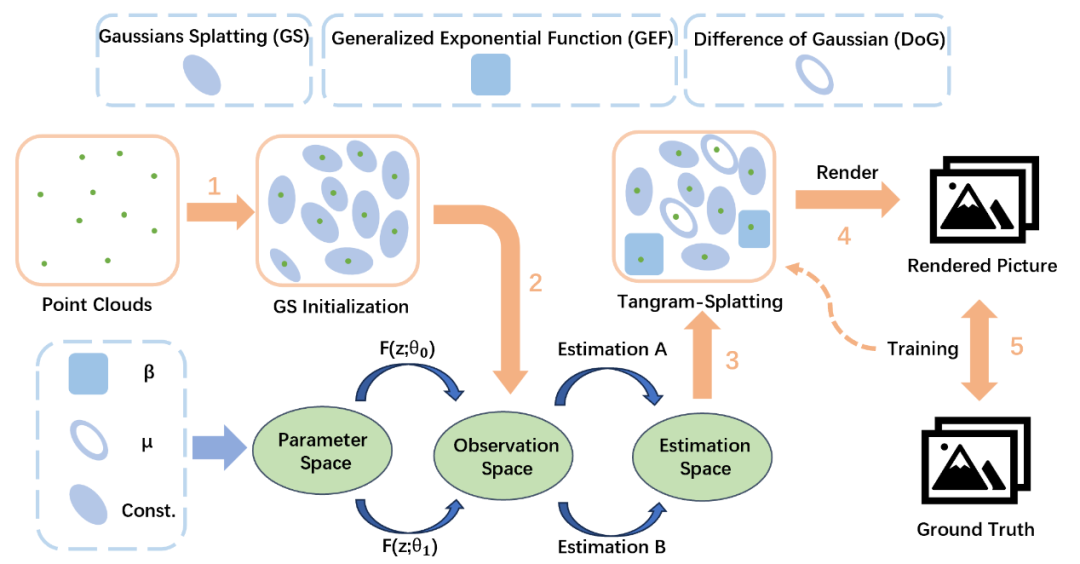
图1 本文所提出方法的示意图
如图1所示,本文尝试利用不同类型的高斯函数来近似三维场景,以获得更为紧凑的表示。在本研究中,本文提出了 Tangram-Splatting,这是一种旨在为三维场景提供更精确高效表征的新方法。本文研究了多种基于高斯的函数,如高斯混合函数、差分高斯函数以及广义指数函数,发现它们在信号表征方面各自具备独特优势。例如,广义指数函数在拟合矩形波时表现更好,差分高斯函数在拟合三角波时更快收敛,而其他函数则适用于不同形状。中国古代的七巧板游戏旨在利用不同形状的几何图形拼凑出特定形状,这启发本文充分利用这些函数的优势并将它们结合起来,以更好地适应三维场景的重建。然而,直接将原始高斯表示转换为新的基于高斯的函数并非易事,尤其是在光栅化过程中。为了保留原有的光栅化过程,本文采用最大似然估计,用一个自适应乘法矩阵来表示不同的函数,而不是直接更改原始的高斯光栅化过程。由于不同的三维场景区域需要不同的形状先验,本文基于高斯函数特征值这一先验信息来对不同的基于高斯的函数进行选择。为了寻找最适合三维场景的表征并降低内存消耗,本文对三维高斯泼溅的克隆操作进行了改进,并设置了全新的标准来分配三维高斯泼溅中高斯的类型。
3.实验结果
如表1所示,在保证图像质量和训练速度相当的情况下,相比于三维高斯泼溅算法,Tangram-Splatting 约提高了62.4% 的内存效率,在训练时间上相比三维高斯泼溅平均减少了44.23%,同时实现了计算效率的提升与内存消耗的降低。
表1 对比实验定量结果

在压缩内存的同时,本文同样关注 Tangram-Splatting 的重建效果。图2展示了在Tanks&Temples数据集、Mip-NeRF360数据集以及 由Deep Blending提供的两个场景上的定性结果。本文将Tangram-Splatting与GES算法、三维高斯泼溅算法以及 Mip-NeRF36算法进行比较。从上至下依次为来自 Mip-NeRF360 数据集的 BICYCLE、GARDEN、STUMP、COUNTER、ROOM 场景,来自 Deep Blending的 PLAYROOM 和 DRJOHNSON 场景,以及来自 Tanks&Temples 数据集的 TRUCK 和 TRAIN 场景。结果表明,Tangram-Splatting的整体效果与先前工作所达到的重建效果相当,从渲染图像中很难分辨出 Tangram-Splatting 与现有工作的差异。只有在某些细节(例如来自 Mip-NeRF360 数据集的 GARDEN 场景中的窗户的反光,以及来自 Tanks&Temples 数据集的 TRAIN 场景中天空的阴影部分)上,其表现略低于真实值。
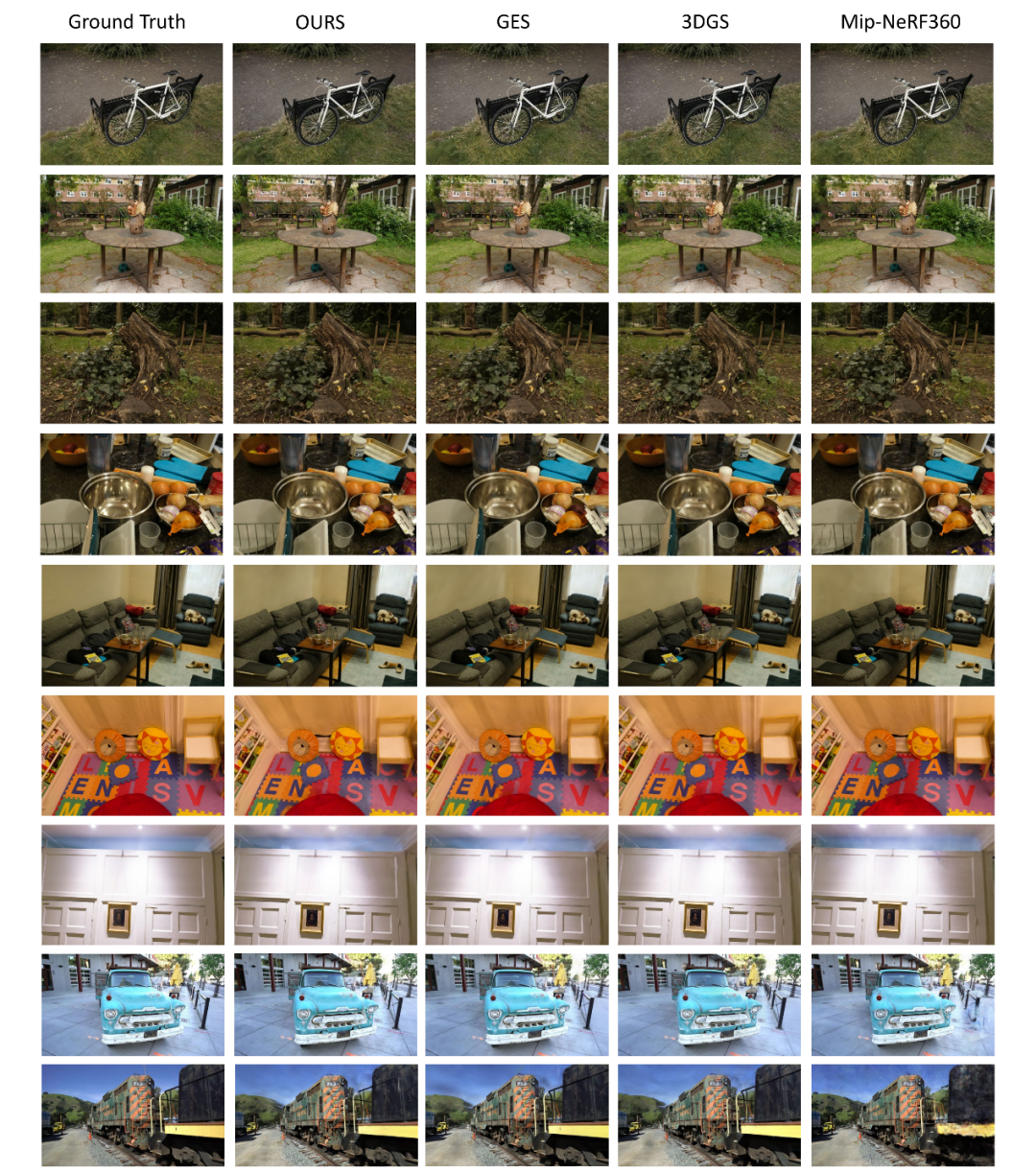
图2 对比实验定性结果
04
GS3LAM: Gaussian Semantic Splatting SLAM
作者:
李林飞,张林*,王忠,沈莹
单位:
同济大学,上海交通大学
邮箱:
cslinfeili@tongji.edu.cn,
cslinzhang@tongji.edu.cn,
cszhongwang@sjtu.edu.cn,
yingshen@tongji.edu.cn
论文:
https://dl.acm.org/doi/10.1145/3664647.3680739
代码:
https://github.com/lif314/GS3LAM
课题组主页:
https://cslinzhang.github.io/home/
发表会议:
ACM MM 2024
*通讯作者
1.论文简介
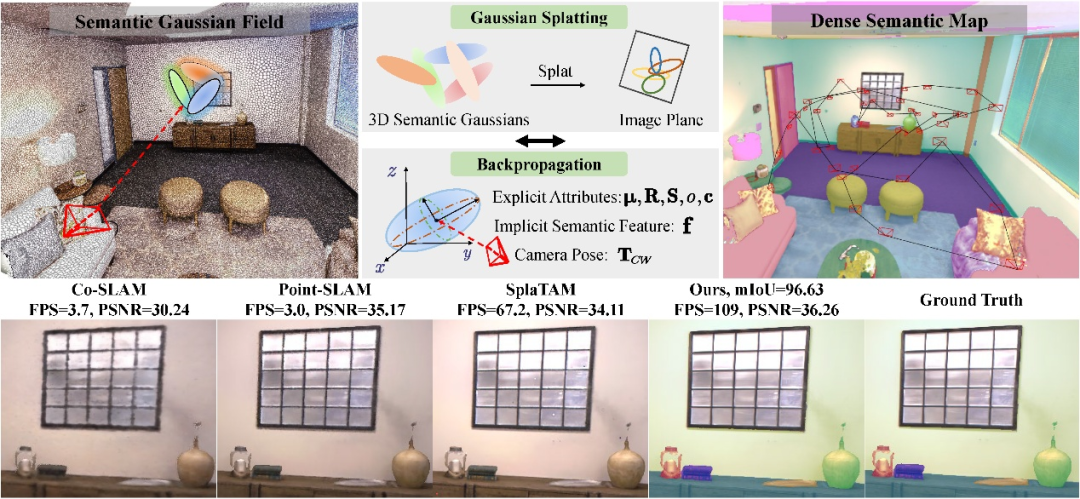
图1 GS3LAM概览图
通过将语义理解融入地图构建,语义同步定位与建图(semantic SLAM)实现了在估计相机位姿的同时,构建在几何、外观和语义上保持一致性的地图。相比传统的 SLAM 技术,它在场景中实体的识别、分类与关联方面表现出更强的能力。目前,语义 SLAM 系统已广泛应用于机器人和自动驾驶等多个领域。
目前,已有的基于显式场景表示的语义 SLAM 系统通常采用点/面元、网格或体素等方式构建地图。这些表示在几何表达、存储效率、计算效率以及可扩展性方面具有一定优势,但在未知区域的预测能力有限,且受到分辨率限制,难以生成高质量的稠密语义地图。与之相对,近年来兴起的基于隐式场景表示的神经渲染方法,如神经辐射场(NeRF),在解决这些问题方面展现出潜力。NeRF 通过将场景建模为连续的隐式体积函数,能够以极低的存储成本实现逼真的新视角合成。基于该思路,已有部分工作通过引入额外的 MLP 通道来编码和解码语义标签,并联合优化相机位姿和语义场景。然而,由于 NeRF 依赖计算开销巨大的基于光线追踪的体积渲染方法,这类方法无法满足 SLAM 对实时性的要求。
幸运的是,我们观察到三维高斯投影(3D Gaussian Splatting,简称 3DGS)技术的出现,在稠密三维重建方面展现出极佳的能力。该方法通过将场景表示为密集的高斯点云,并采用基于图块的光栅化方法实现高效渲染。我们发现,3DGS 在解决上述问题方面具有巨大潜力。作为语义 SLAM 的场景表示形式,它继承了点/面元表示的效率、本地性和可修改性,同时以连续、可微的方式表示几何结构,使得构建细致且复杂的稠密地图成为可能。为了进一步提升语义 SLAM 在跟踪、渲染和语义重建方面的能力,我们提出将 3DGS 扩展为语义场景表示的自然思路,然而令人惊讶的是,这一简单而直观的想法在现有文献中鲜有探索。基于上述发现,我们提出了一种稠密语义 SLAM 框架,命名为 GS3LAM(如图1所示),以充分利用 3DGS 的优势。
2.理论和方法介绍
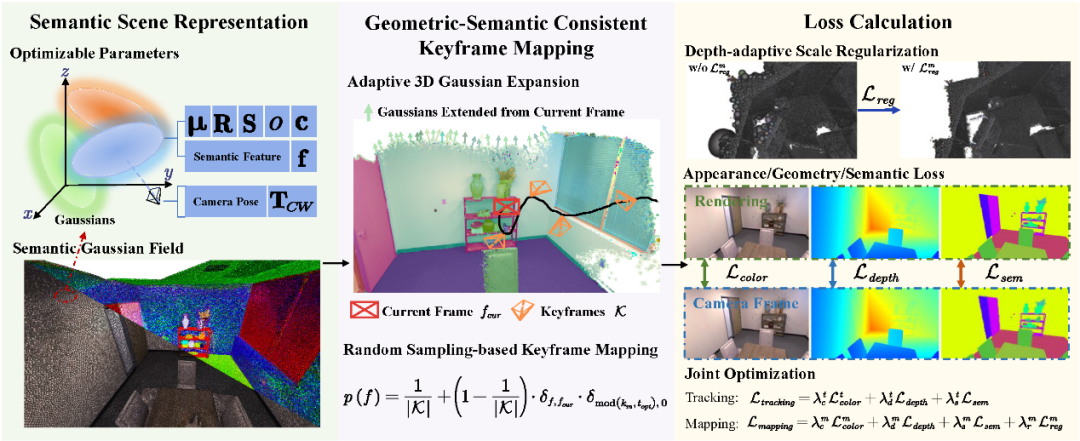
图2 GS3LAM架构图
如图2所示,在 GS3LAM 中有效嵌入并实时优化高维语义类别面临重大挑战。为了解决这个问题,GS3LAM 将场景建模为一个语义高斯场(Semantic Gaussian Field,简称 SG-Field),其中语义类别被表示为低维隐式特征。通过一个简单的解码器,GS3LAM 可以高效地将这些特征转化为语义类别,实现三维隐式特征与二维语义标签之间的转换。
此外,在SG-Field 中,高斯尺度的非规律性阻碍了几何表面的准确表达,从而影响像素级语义重建的精度。为了解决这一问题,我们提出了一种深度自适应尺度正则化(Depth-adaptive Scale Regularization,简称 DSR)策略,该策略通过在深度相关范围内约束高斯尺度,间接使高斯对齐几何表面,有效减少物体表面的模糊现象,从而提升跟踪的鲁棒性和语义重建的精度。
最后,为了解决 GS3LAM 中出现的遗忘现象,我们提出了一种基于随机采样的关键帧映射(Random Sampling-based Keyframe Mapping,简称 RSKM)策略,该策略相比目前在 3DGS-based SLAM 中常用的局部共视关键帧映射(LCKM)策略表现更优。我们的观察表明,后者在高斯场优化过程中会引入较大的偏差,导致全局地图一致性较差。具体来说,在密集共视帧和大量优化迭代的场景下,高斯点半径扩大,PSNR 值下降,说明该策略下的高斯场难以收敛。而我们提出的 RSKM 策略不仅提升了全局地图的渲染质量(更高的平均 PSNR),还保持了不同视角之间的一致性(更小的 PSNR 方差),有效减少了优化偏差。
3.实验结果
与同期方法相比,GS3LAM 在渲染性能(表1和表2)以及语义分割能力(表4)方面均取得了显著优势,同时其跟踪精度也与现有先进方法相当(表3)。从图3的定性实验可以看出,GS3LAM 构建的地图具有更好的全局一致性,不会因遗忘现象导致某些视角下优化不足,从而确保了语义重建在不同视角间的均衡性和一致性。
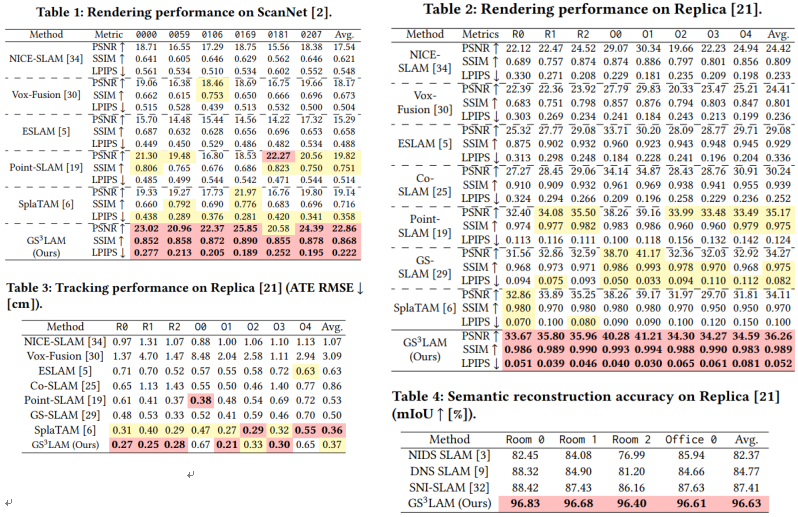

图3 在Replica和ScanNet数据集上的定性实验
05
Multi-view X-ray Image Synthesis with Multiple Domain Disentanglement from CT Scans
作者:
谭立行1,宋爽1,周康能2,段程博1,王澜颖1,任化杨1,刘琳琳1,张巍3,肖若秀1
单位:
北京科技大学1
南开大学2
中国人民解放军总医院3
邮箱:
lexontran@163.com,
ssong@ustb.edu.cn,
elliszkn@163.com,
lucas007d@163.com,
m202210613@xs.ustb.edu.cn,
m202310669@xs.ustb.edu.cn,
m202210605@xs.ustb.edu.cn,
bszw@hotmail.com,
xiaoruoxiu@ustb.edu.cn
论文:
https://dl.acm.org/doi/abs/10.1145/3664647.3681154
发表会议:ACM MM 2024
1.研究背景
X射线图像合成任务旨在突破传统单平面成像系统每次只能获取一个角度X射线图的限制,从而提供丰富、全面的人体解剖结构信息。然而,现有方法往往基于数字投影重建(DRR)技术,需要依赖于繁琐的分割、光线投射和后处理等步骤,这样的做法存在以下几个问题:(1)合成影像的准确度依赖于分割模型的精度;(2)合成图像与真实X射线图像之间存在较大风格差异,这些限制了其实用性和泛化能力。为此,本文提出了一个端到端的X射线图像生成网络——CT2X-GAN。该方法无需建模成像物理,通过风格解耦编码器从不成对的CT扫描与X射线图解耦解剖结构信息和风格信息,可直接从三维CT扫描学习合成多视角X射线图,省略了显式分割与射线投射步骤,突破了传统方法的局限。通过设计一致性正则项,CT2X-GAN实现了兼顾合成图像的结构一致性与风格一致性,从而提高了合成X射线图的真实感。
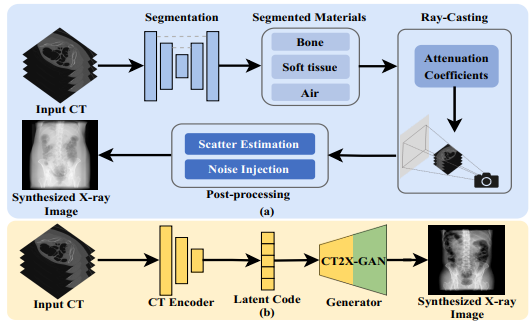
图1 传统X射线图合成与端到端合成的流程差异
2.方法概述
方法如图2,3所示,本文提出了一种新颖的端到端多视角X射线图合成网络。输入的CT扫描首先通过CT编码器提取解剖信息编码。为了最大程度保留目标视角的信息,针对目标视角进行最大密度投影(MIP)并经过姿态注意力机制(PAM)从内容编码中增强对应视角的信息。X射线图经过一个风格解耦编码器提取风格编码,通过AdaIN注入生成器引导合成图的风格贴近真实X射线图。为了更好地约束编码器对于风格信息的解耦提取,本文额外构建了一个风格重建的辅助任务以在特征层面形成一致性正则项约束训练。利用真实X射线图与DRR作为两种风格参考引导合成X射线图以及DRR图,提取的X射线图风格编码以及DRR风格编码应分别具有一致性,同时重建的DRR以及合成X射线图之间的解剖结构也应具有一致性,通过分别约束风格与内容一致,从而完成风格编码器对于风格信息的解耦提取。
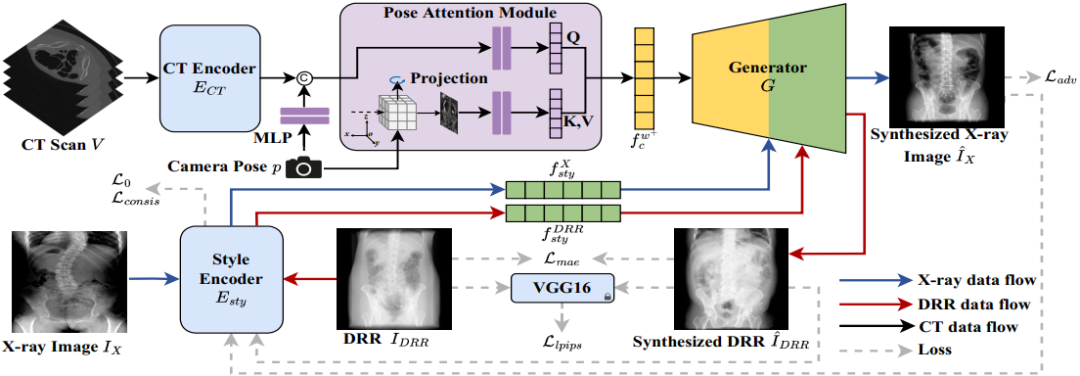
图2 模型框架图
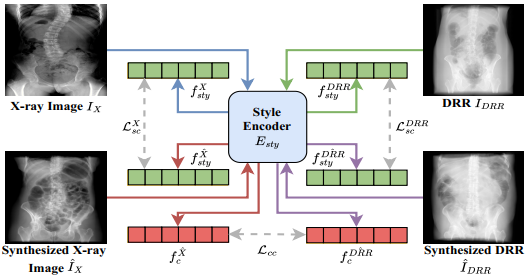
图3 一致性正则项示意图
3.实验结果
由于本文提出任务较新颖,当前无直接可用的公开数据集,本文基于CTSpine1K数据集构建测试集进行实验,并将CT2X-GAN与此前的先进3D感知生成方法进行比较,以评估多视角生成质量。表1展示了X射线图合成方法的结果。结果表明,在CTSpine1K数据集上,我们的方法在多视角X射线图合成任务上实现了显著的性能提升。图4和图5分别展示了不同方法合成X射线图的结果,包括传统DRR方法以及当时先进的3D感知的生成方法,我们的方法生成的结果更符合真实X射线图风格特征,并且表现出更平滑的视角过渡。为了进一步量化X射线图合成结果与真实X射线图的感官相似度,表2展示了用户评分结果,我们的方法能够实现最具真实感的X射线图合成。
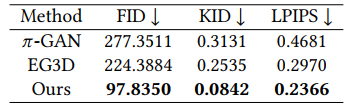
表1 在CTSpine1K数据集的X射线图合成性能比较
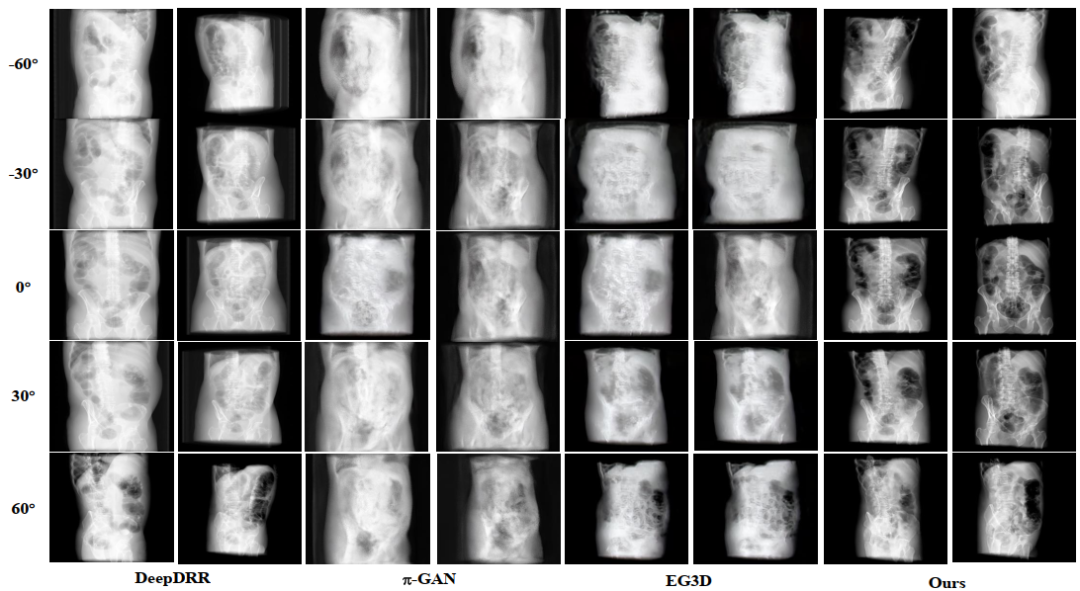
图4 不同模型X射线图合成的视觉比较
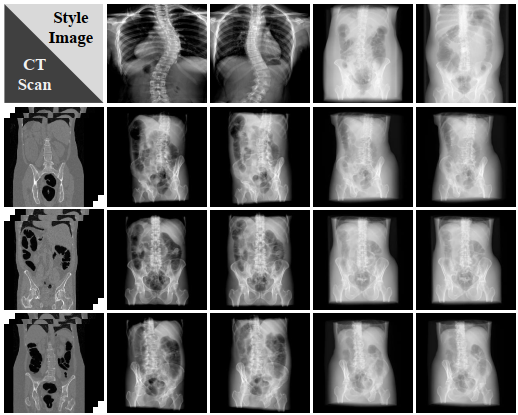
图5 风格解耦合成的可视化展示

表2 X射线图合成真实度的用户评分

编辑人:吴建龙、任文琦
专委会责任副主任:张勇东
 京公网安备11010802017125号
京公网安备11010802017125号