
【论文导读】2025年论文导读第十二期
【论文导读】2025年论文导读第十二期
2025年7月8日 12:04 北京


论文导读
2025年论文导读第十二期(总第一百二十九期)
目 录
|
1 |
Learning to Transfer Heterogeneous Translucent Materials from a 2D Image to 3D Models |
|
2 |
FLIP-80M: 80 Million Visual-Linguistic Pairs for Facial Language-Image Pre-Training |
|
3 |
Designing Spatial Visualization and Interactions of Immersive Sankey Diagram in Virtual Reality |
|
4 |
InstantAS: Minimum Coverage Sampling for Arbitrary-Size Image Generation |
|
5 |
Masked Random Noise for Communication-Efficient Federated Learning |
01
Learning to Transfer Heterogeneous Translucent Materials from a 2D Image to 3D Models
学习从二维图像向三维模型迁移异质半透明材质
作者:
王小刚1, 程宇航1, 樊子扬1, 徐凯2
单位:
西南大学1, 国防科技大学2
邮箱:
wangxiaogang@swu.edu.cn,
chengyuhang1999@email.swu.edu.cn,
y18983458350@email.swu.edu.cn,
kevin.kai.xu@gmail.com
论文:
https://doi.org/10.1145/3664647.3680813
发表会议:
ACM MM2024
1.论文简介
在计算机图形学领域,根据二维图像向三维模型迁移异质半透明材质(如玉石、人体皮肤)的外观仍然是一项具有挑战性的任务。传统方法往往依赖昂贵专用设备或局限于均质材质,限制了其广泛应用。本文针对这些局限性,提出了一种新颖且实用的方法,能够从单张二维图像中学习并迁移复杂的、空间变化的半透明材质属性到三维模型。该方法通过高效的视点选择、半透明材质的初始化、基于输入图像的迭代编辑以及材质参数的逆向渲染优化,实现了高质量且逼真的三维资产创建,能够展现细腻的半透明效果。
2.方法概述
为了实现从单张2D图像到3D模型的异质半透明材质迁移,并解决材质细节丢失、光照不一致等问题,本文提出了一种迭代优化框架。该框架的核心思想是通过对半透明渲染的图像进行风格迁移,并将编辑结果通过可微渲染逆向优化3D模型的材质参数。整体流程如图1所示,关键环节如下:
1)高效视点选择 (EVS) 与材质初始化:为确保对3D模型的全面且高效的材质优化,我们首先采用EVS策略选择一组信息丰富的视点。随后,为模型赋予初始的同质半透明材质,并在这些选定视点下渲染图像,构建初始的半透明图像数据集。这一步骤为后续的材质编辑和优化提供了基础。
2)结构保持的半透明风格迁移编辑器:如图2所示,该编辑器创新性地采用双分支架构:结构保持分支:该分支通过枢轴转向翻转,学习初始渲染图像的无条件嵌入和初始噪声进行重建,在重建过程中提取关键的注意力图,这些注意力图主要控制图像的结构和光照信息。风格迁移分支:学习2D风格图像的概念作为条件嵌入,并同步学习当前视点渲染图像的无条件嵌入和初始噪声,通过去噪步骤来实现风格迁移。通过注意力控制机制,我们将结构保持分支的注意力图注入到风格迁移分支的去噪过程中。这确保了在引入新材质风格的同时,能够保留3D模型原有的几何细节和光照条件,有效避免了常见风格迁移方法中出现的结构和光照变化问题。
3)迭代优化与多视角一致性保证:为了将单次编辑的结果泛化到整个3D模型,并保证材质在多视角下的一致性,我们设计了迭代的编辑-优化-更新流程。在每次迭代中:
使用上述编辑器对当前视点渲染的图像进行材质风格迁移。
将编辑后的高质量图像作为监督信号,通过可微半透明渲染器进行逆向渲染,优化3D模型的空间变化材质参数(如散射反照率、消光系数等)。
更新半透明图像数据集。
通过这种交替迭代,模型的材质能够逐步向目标2D图像的风格接近,呈现真实的异质半透明材质。
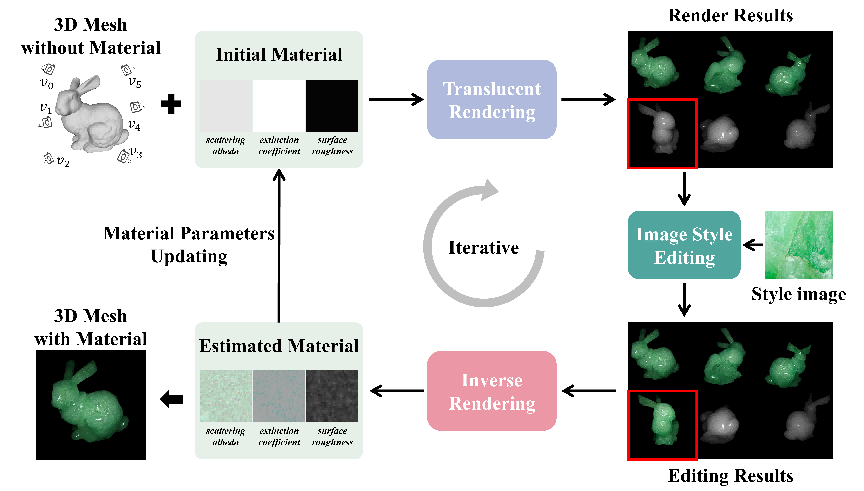
图1 方法概览图
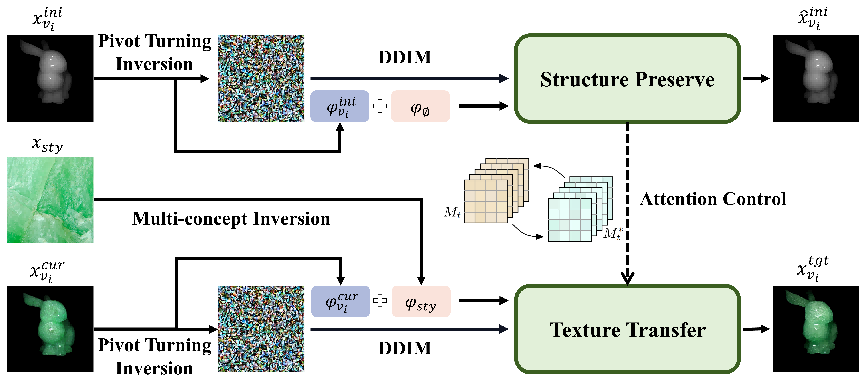
图2 结构保持的半透明风格迁移编辑器
3.实验结果
我们通过一系列实验验证了所提出方法的有效性。
核心结果展示:图3展示了本方法在多种标准模型和不同材质图像上的编辑结果,可以看到方法能够成功迁移各类半透明材质的复杂纹理和光学特性,并保持了模型原有的几何结构和光照信息。
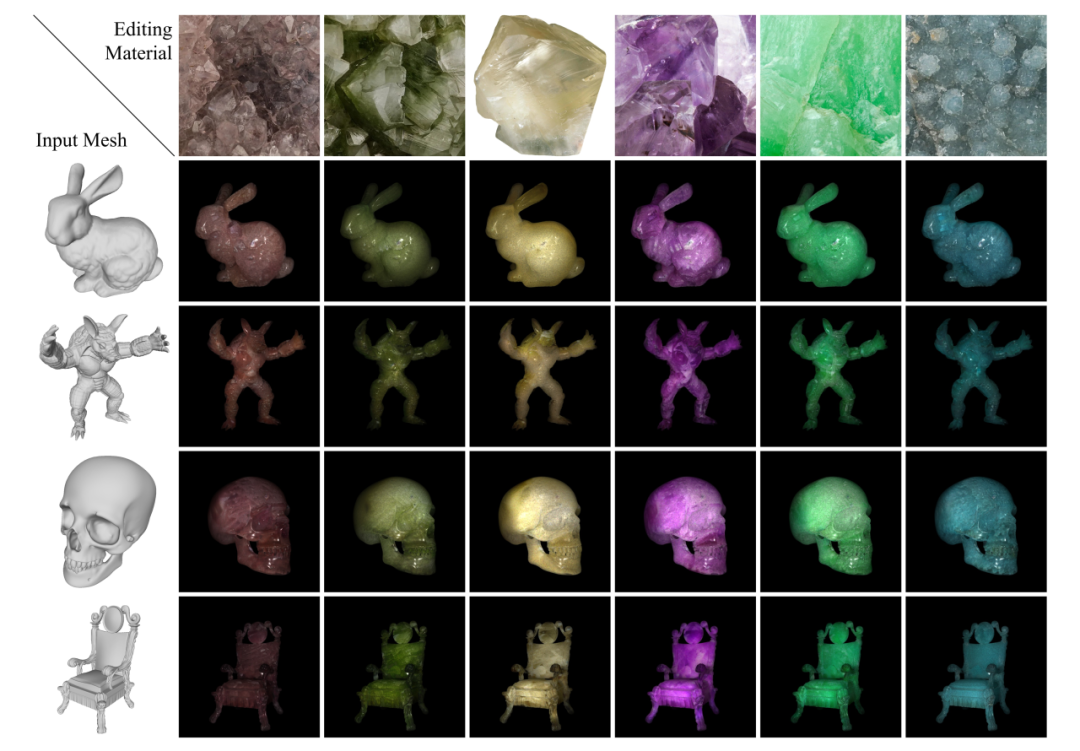
图3 半透明材质迁移结果展示
多视角一致性展示:为了验证方法在不同视角下结果的一致性,图4展示了同一模型在材质迁移后从多个不同视点渲染的效果。可以看出,迁移后的材质在不同视角下均能保持稳定和逼真的外观。

图4 多视角迁移结果一致性展示
定量比较:我们通过纹理相似性测量和用户偏好研究进行了定量评估。结果如表1所示,表明本方法在材质迁移的质量和视觉效果上均优于对比方法。
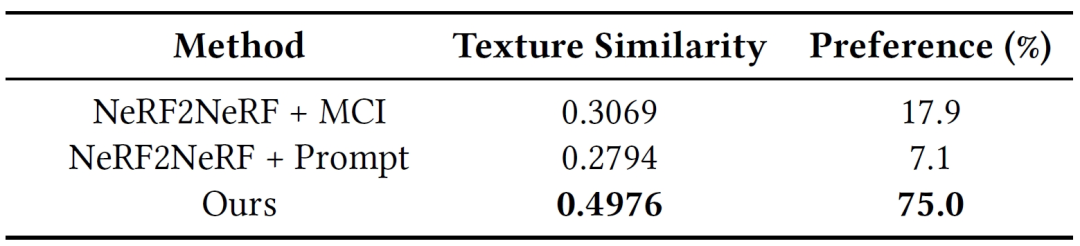
表1 与现有方法比较的性能和用户偏好比较
02
FLIP-80M: 80 Million Visual-Linguistic Pairs for Facial Language-Image Pre-Training
作者:
Yudong Li1, Xianxu Hou2, Dezhi Zheng1, Linlin Shen1*, Zhe Zhao3
单位:
深圳大学计算机与软件学院计算机视觉研究所,
西交利物浦大学人工智能与先进计算学院,
腾讯 AI Lab
邮箱:
liyudong123@hotmail.com,
hxianxu@gmail.com,
2310273055@email.szu.edu.cn,
llshen@szu.edu.cn,
nlpzhezhao@tencent.com
论文:
https://dl.acm.org/doi/pdf/10.1145/3664647.3681287
代码:
https://github.com/ydli-ai/FLIP
发表会议:ACM MM 2024
*通讯作者
1.引言
图1 示意图
大规模预训练范式已经被广泛用于图像和文本等深度学习研究中,但相较于通用领域,人脸领域数据源可用性仍然存在较大差距。为了推动人脸多模态预训练研究,本文提出了FLIP-80M数据集,该数据集从50亿条原始数据中构建,采用了多条数据筛选管线最终得到超过8000万条高质量人脸图文样本。基于获取到的数据,本文训练了人脸领域对比学习模型FLIP,在多个人脸分析下游任务上取得最优效果,能够作为人脸领域基础模型和通用人脸表征。
2.技术贡献
本工作主要贡献如下:
本文构建了大规模高质量人脸文本数据集,包含超过 8000 万条图文对,比之前已有的相关工作LAION-Face 数据集大 3 倍;
本文提出了一种新颖的AIGC的数据构建流程,它能够作为高质量数据增强基线方法;
基于提出的数据集,本文训练了大规模人脸图文对比学习模型FLIP,实验表明它在多个下游任务上能够达到最先进性能。
3.方法介绍
FLIP-80M数据集构建流程如图1所示。
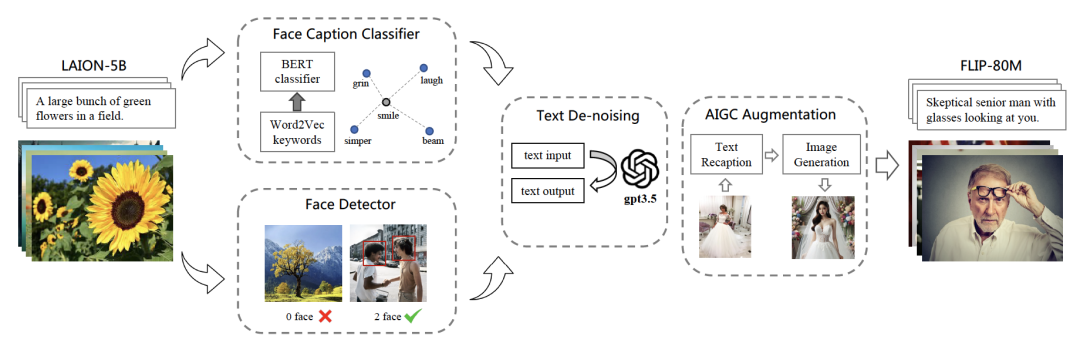
图2 FLIP-80M 数据集构建流程概述
首先,我们以LAION-5B作为数据源,其中包含了50亿条从common crawl获取的通用图文样本。为了从中筛选出和人脸相关的高质量图文数据,我们构建了一条数据流水线:(1)使用RetinaFace对图像进行人脸检测,保留包含人脸图像的样本;(2)训练word2vec和BERT分类器,筛选出包含对人脸描述的文本数据;(3)利用GPT-3.5实现文本去噪,消除互联网数据中的语义无关信息;(4)利用GPT-4和DALL-E3理解并图文数据语义并仿造重新生成样本,构造更高清晰度和图文相关性的高质量数据子集。
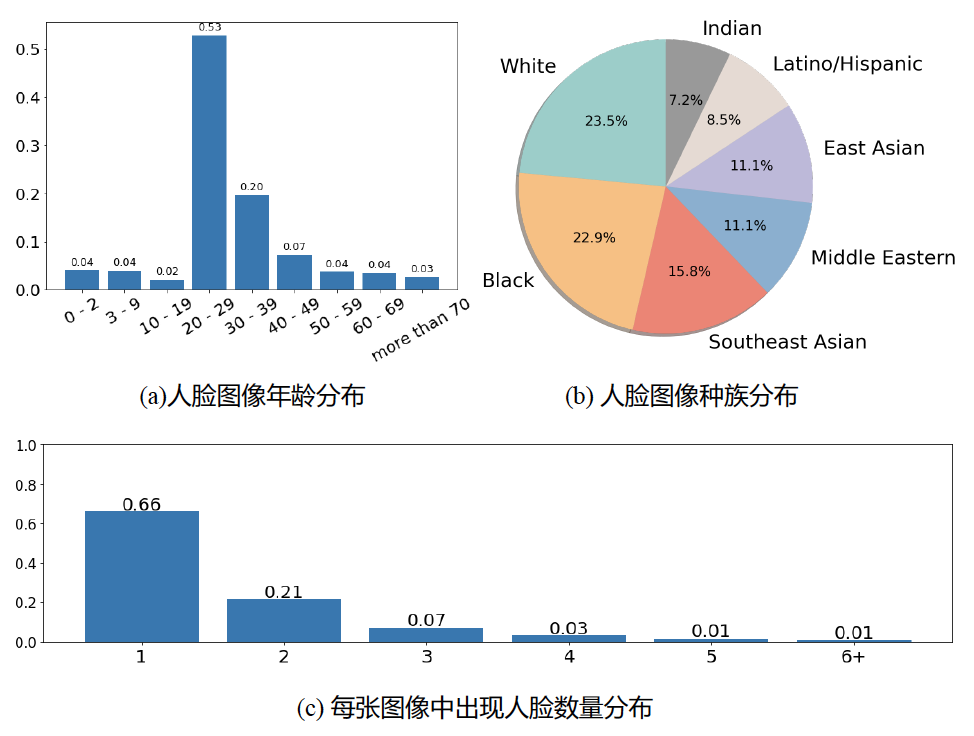
图3 FLIP-80M 数据分布
基于以上方法构建出的8000万条数据(部分统计分布如图2所示),我们训练了FLIP模型。FLIP模型分别以CLIP base和large版本权重作为初始化,使用FLIP-80M进行增量训练,经过5轮迭代后,实现了人脸领域的图文对比学习基础模型。经过评估,在人脸属性分类、人脸对齐、人脸解析等多项下游任务中,FLIP模型均展现出卓越的性能,远超现有图像-文本基线模型。
为了深入探究FLIP-80M数据集对模型性能的具体影响,我们还设计了消融实验。通过对比使用不同数据源从头预训练的模型在下游任务上的表现(如表1所示),我们发现FLIP-80M数据集能够显著提升模型的各项性能指标。特别是引入AIGC增强数据子集后,模型性能得到了显著提升,这充分证明了高质量、高相关性数据对预训练模型性能的影响。
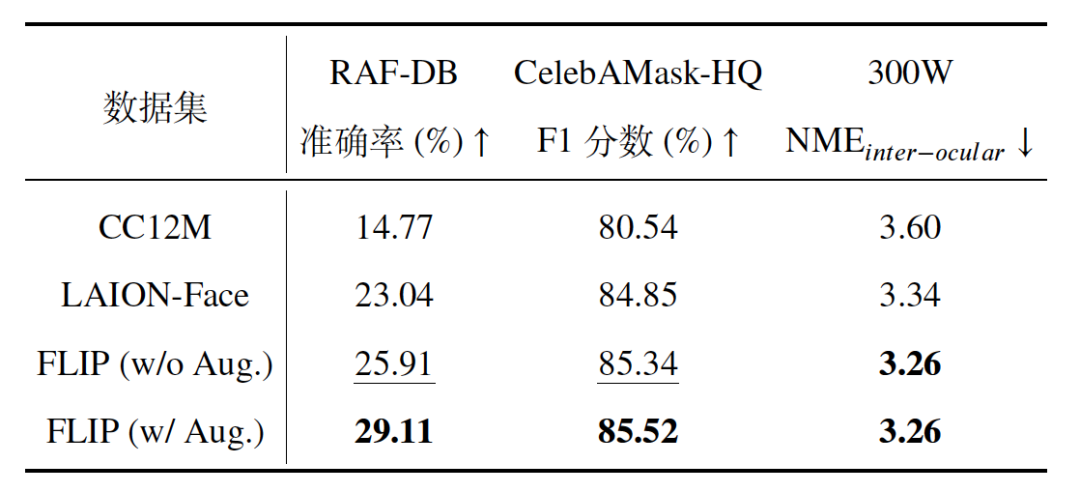
表1 基于不同数据源训练FLIP 模型的消融实验结果
4.结果展示
FLIP模型在多个基准数据集上的表现均超过了现有的图像-文本基线模型(如CLIP、FaRL等),显示出卓越的泛化能力和特征学习能力。特别是在零样本设置下,FLIP模型的性能提升尤为显著,这得益于FLIP-80M数据集中精细的文本描述与高质量的人脸图像匹配。
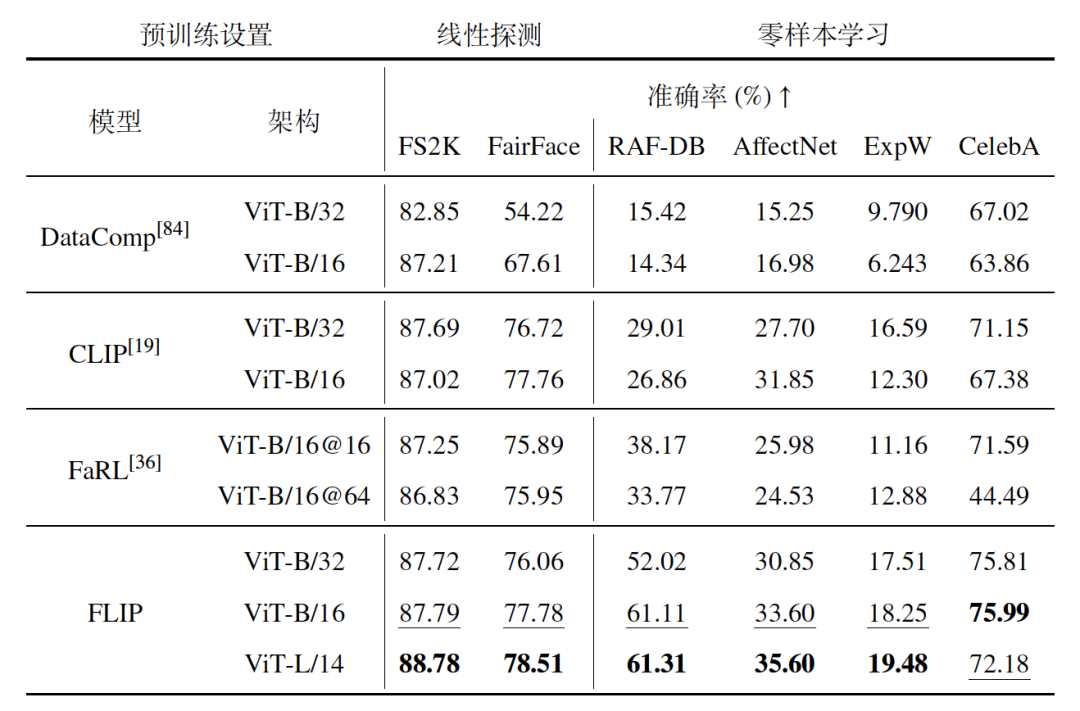
表2 人脸属性分类定量比较结果
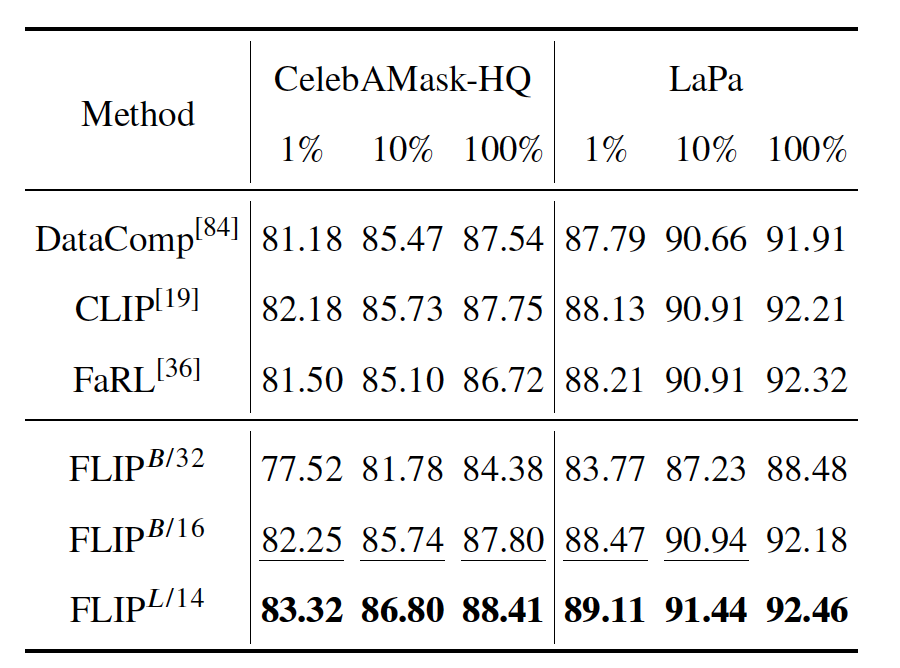
表3 人脸解析任务定量比较结果
为了进一步验证FLIP模型在人脸特征定位方面的优势,我们对不同模型生成的类激活图(CAM)进行了可视化对比。实验结果表明,FLIP模型在根据文本查询定位人脸区域时表现出更高的准确性。例如,在查询“头发”时,FLIP模型的CAM能够完整地覆盖整个头发区域,而其他模型则只能捕捉到部分区域。同样地,在查询“耳环”时,CLIP模型激活了整个耳朵区域,而FLIP模型则能够更精确地定位到耳环的位置。
03
Designing Spatial Visualization and Interactions of Immersive Sankey Diagram in Virtual Reality
沉浸式桑基图在虚拟现实中的空间可视化与交互设计
作者:
卢杨1,李俊贤1,崔志彤1,胡家鹏1,林燕娜2,罗仕鉴1*
单位:
浙江大学1,香港科技大学2
邮箱:
danaluyang@zju.edu.cn,
junxianli@zju.edu.cn,
zhitongcui@zju.edu.cn,
paulhu@zju.edu.cn,
ylindg@connect.ust.hk,
sjluo@zju.edu.cn
论文:
https://dl.acm.org/doi/pdf/10.1145/3664647.3681460
发表会议:ACM MM 2024
*通讯作者
1.研究背景
在数据爆炸式增长的时代,数据可视化成为人们理解复杂信息、辅助决策的重要手段。桑基图(Sankey Diagram)因其在展示数据流向与比例方面的优势,广泛应用于能源流、金融流、产品生命周期等多种应用场景。然而,现有的桑基图主要以二维静态形式呈现,尤其在高密度复杂数据情形下,容易出现信息遮挡、视觉重叠等问题,限制了用户对数据结构与流动趋势的全面理解。虚拟现实(Virtual Reality,VR)技术凭借其特有的沉浸感与空间自由度,为复杂数据可视化提供了突破口,有望缓解二维平面可视化的瓶颈,提升复杂数据流可视化与分析的效率与体验。
2.研究内容与方法
本文提出了一套适用于虚拟现实环境的沉浸式桑基图可视化系统,结合三位空间可视化设计和空间交互方式,帮助用户更好地理解复杂数据流。
三维空间可视化设计:通过引入节点厚度、基于节点权重的空间深度排序与阴影效果,优化了高密度数据中的层次关系与数据流动趋势的视觉辨识度(图1)。
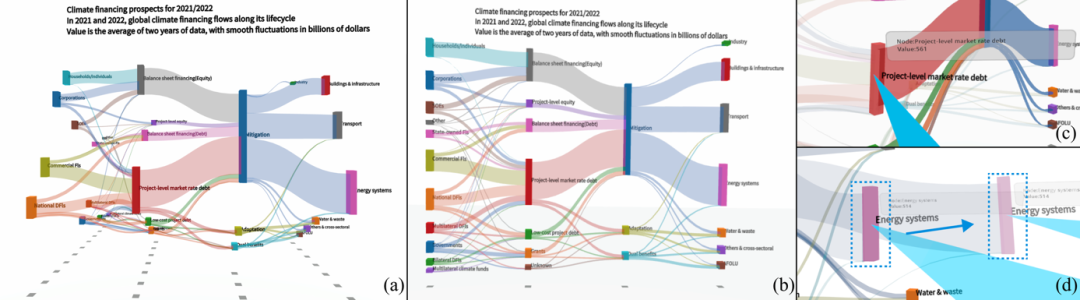
图1 该图展示了在虚拟现实环境中应用于高密度数据集的三维与二维桑基图。(a) 展示了三维桑基图的两个视角,其中通过阴影辅助突出节点的层级信息;(b) 则展示了对应的二维桑基图,其设计未考虑VR所提供的额外空间深度维度。
空间交互机制设计:系统支持空间高亮、节点拖拽、二维与三维视图切换、悬停标签与快速复位等多种空间交互方式,提升了复杂数据分析中的灵活性与操控体验(图2)。
图2 虚拟现实中的沉浸式桑基图系统。(a) 系统的三维形式;(b) 系统的二维形式;(c) 空间高亮功能与悬停标签功能;(d) 拖拽功能。
3.实验设计与结果
本文通过两轮系统性用户实验验证了所提出方法的有效性与应用价值:
a) 第一轮实验:在虚拟现实环境下对比二维与三维桑基图的可视化效果,针对不同数据密度任务表现进行评估。结果表明,在高密度数据场景中,三维桑基图图显著提升了任务完成时间、准确率以及任务难易评分,在低密度场景下则与二维效果相当。
b) 第二轮实验:选取真实数据集(加拿大能源流与全球气候金融流),对比虚拟现实系统与桌面系统在任务效率、理解准确性与用户体验方面的表现。结果显示,虚拟现实系统在复杂数据任务中任务效率与准确性均优于桌面系统,用户参与感显著提升,系统整体可用性良好。
实验结果验证了沉浸式三维桑基图在复杂数据流分析任务中的实际优势,特别在高复杂度、高数据密度任务中表现尤为突出。
4.主要创新点与贡献
提出适用于虚拟现实环境的三维桑基图空间布局设计,充分利用空间深度信息,有效缓解高密度数据可视化中的遮挡与信息混淆问题;
设计并实现了结合空间特性的交互机制(高亮、拖拽、视图切换等),提升了复杂数据流可视化分析的交互效率与参与感;
系统性开展双轮用户实验,综合评估了系统在任务表现、主观体验与工作负荷等多维度下的优势,验证了方法的实际应用价值;
总结并提炼了沉浸式数据可视化系统的设计经验与应用启示,为未来沉浸式可视化系统设计与开发提供参考和借鉴。
04
InstantAS: Minimum Coverage Sampling for Arbitrary-Size Image Generation
作者:
Changshuo Wang, Mingzhe Yu, Lei Wu*, Lei Meng, Xiang Li, Xiangxu Meng
单位:
山东大学
邮箱:
202115242@mail.sdu.edu.cn,
202215265@mail.sdu.edu.cn,
i_lily@sdu.edu.cn,
lmeng@sdu.edu.cn,
202035260@mail.sdu.edu.cn,
mxx@sdu.edu.cn
论文:
https://dl.acm.org/doi/pdf/10.1145/3664647.3681185
发表会议:
ACM MM 2024
*通讯作者
1.论文简介
在图像生成模型快速迭代的背景下,如何在保持高质量生成效果的同时实现任意尺寸图像的快速生成,已经成为当前生成模型研究中的一个重要方向。传统的预训练文本到图像的扩散模型大多基于固定尺寸图像训练,难以适应实际应用中对图像尺寸与比例的灵活需求,如海报、插画与长图等场景。针对这一挑战,本文提出了一种无需额外训练即可生成任意尺寸图像的方法InstantAS,旨在提升图像一致性和语义控制能力的同时,显著加快采样速度。
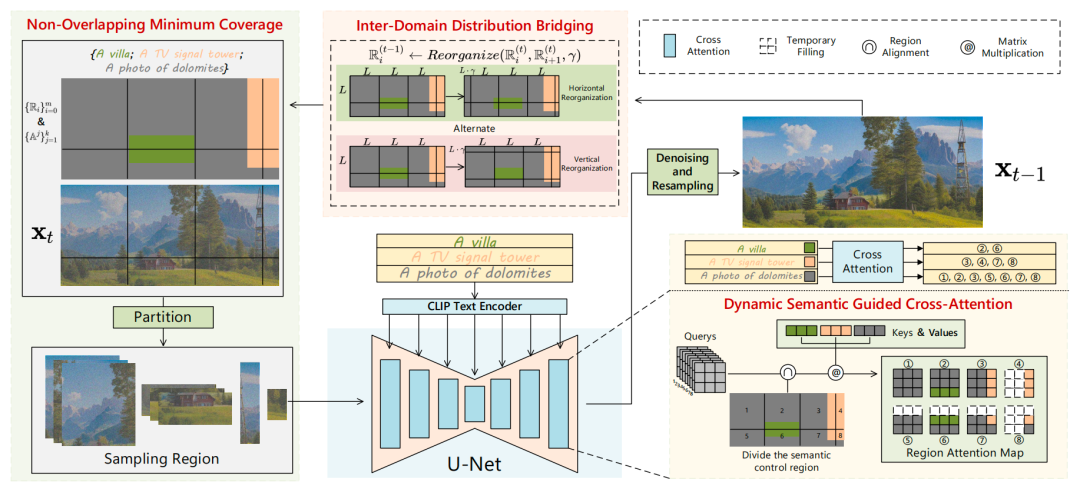
InstantAS的核心技术体现在三个方面:
(1)非重叠最小覆盖采样。该采样策略将大尺寸噪声图像精确划分为若干不重叠的小区域,其中各区域可独立扩散采样。相比之下,先前的工作MultiDiffusion需要将图像划分为相互重叠的多个区域,通过大幅重叠相邻区域以平滑区域间的衔接。InstantAS通过无重叠的区域采样策略减少冗余,显著提升了采样效率。
(2)域间分布桥接。上述采样策略完全消除区域重叠后,不同区域各自独立进行噪声预测,可能会导致生成轨迹彼此偏离,最终出现明显的拼接痕迹和内容不一致的情况。为此,InstantAS引入了域间分布桥接机制,在扩散过程中周期性地重新划分采样区域、交替相邻区域的位置,从而使不同区域的扩散路径产生信息交互。即该机制在扩散过程中融合各局部的潜在分布信息,促使相邻区域朝着同一概率流方向演化,避免彼此孤立。
(3)动态语义引导。InstantAS提出了动态语义指导的跨注意力机制,用于细粒度控制不同区域的生成内容。该方法支持为图像的不同非重叠区域指定不同的文本提示,在扩散过程中通过改进的Cross-Attention层动态调节每个区域的语义引导强度。由于域间分布桥接会在采样步骤中不断改变区域划分,InstantAS会相应更新各区域所用的提示条件,使语义指导动态匹配当前的区域位置,确保不同内容在边界处自然融合。

相关实验结果证明,InstantAS在各场景下均生成出清晰、一致的图像内容。从定量评估看,InstantAS在图像质量和一致性上均有所提升。其中FID和CLIP评分等指标显示,在多种输出分辨率下,InstantAS生成结果的FID更低、CLIP-Similarity和美学评分更高,相比MultiDiffusion等方法生成的图像更加逼真且与文本描述吻合。综合来说,InstantAS相较MultiDiffusion等方法实现了向量量化与采样流程的全面优化——既加速了生成,又提升了图像重建和生成效果,在任意尺寸图像生成任务中取得了更好的性能表现。
05
Masked Random Noise for Communication-Efficient Federated Learning
作者:
李世伟1,程英逸2,王号召1*,唐兴3,许世杰3,罗潍红3,李玉华1,刘杜钢4,何秀强3,李瑞轩1
单位:
1华中科技大学,2北京邮电大学,3腾讯金融科技,4光明实验室
邮箱:
lishiwei@hust.edu.cn,
hz_wang@hust.edu.cn,
idcliyuhua@hust.edu.cn,
rxli@hust.edu.cn
论文:
https://arxiv.org/abs/2408.03220
代码:
https://github.com/Leopold1423/fedmrn-mm24
发表会议:ACM MM 2024
*通讯作者
1.研究背景
联邦学习(Federated Learning, FL)是一种保护数据隐私的分布式训练方法,其典型架构由一个中央服务器与若干客户端组成。联邦学习的训练过程通常分为四个主要步骤:首先,中央服务器将初始全局模型分发至各客户端;接着,客户端利用本地私有数据对模型参数进行训练和更新;然后,客户端将更新后的参数或相应的参数增量返回至服务器;最后,服务器聚合各客户端的参数增量,生成新的全局模型以进一步优化。然而,全局模型通常需要很多轮训练才能实现收敛,而每轮训练都伴随着服务器与客户端之间的一次双向通信。这种通信开销会显著降低联邦学习的整体训练效率。另一方面,彩票假设理论(Lottery Ticket Hypothesis, LTH)指出,神经网络中存在稀疏子网络(又称中奖彩票),当从头开始训练这些子网络时能够达到与训练的原始密集网络相当的精度。后续研究发现,即使没有经过从头训练,稀疏子网络(中奖彩票)也有着不错的性能。为此,研究人员提出寻找超级掩模(Supermasks),来识别未经训练的网络中性能优异的子网络。
2.方法概述
本文的主要动机是利用Supermasks学习掩蔽随机噪声作为模型增量。为此,本文提出Federated Masked Random Noise (FedMRN)。FedMRN的示意图如下图所示。FedMRN冻结每个客户端的全局模型参数,并使用预先给定的随机种子生成一份随机噪声。本地训练中,客户端将额外维护一份参数代表模型增量,并将其映射为随机噪声与二值掩码的乘积。训练结束后,客户端仅需将二值掩码发送给服务器进行聚合。
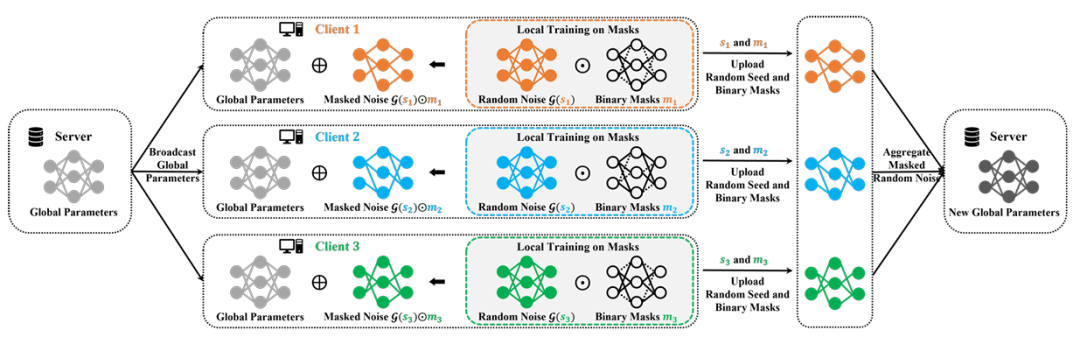
图1 FedMRN示意图
为了在本地训练中学习到更为准确的掩码,本文提出渐进随机掩蔽(Progressive Stochastic Masking, PSM)策略,其中包括两项设计,分别是随机掩蔽(Stochastic Masking, SM)和渐进掩蔽(Progressive Masking, PM)。SM的目的是实现掩蔽过程的无偏估计,也即掩蔽随机噪声的期望近似等于原始的模型增量。如下图所示,SM首先通过模型增量除以随机噪声得到掩码为1的概率,并以此概率进行采样得到二值掩码。PM的目的是降低掩蔽过程对早期模型增量更新的影响。在训练早期,PM仅将少数模型增量映射为随机噪声以确保早期模型增量的准确更新,并随着本地训练进行逐渐增大该比例。具体来说,PM将根据当前迭代次数和总迭代次数计算比例,并随机选择比例为的模型参数增量将其映射为随机噪声。注意下图中的采样操作均为不可导算子,本文利用直通估计器(Straight-through Estimator, STE)将采样算子的导数近似为1,从而实现端到端的参数更新。
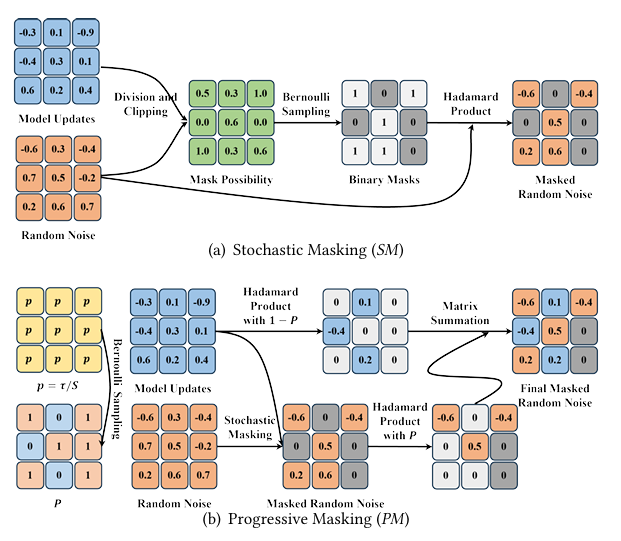
图2 PSM示意图
3.实验结果
本文在四个数据集上分别测试了FedMRN和相关基线的性能。测试精度和收敛速度分别如下图所示,FedMRN的性能要远优于基线方法。
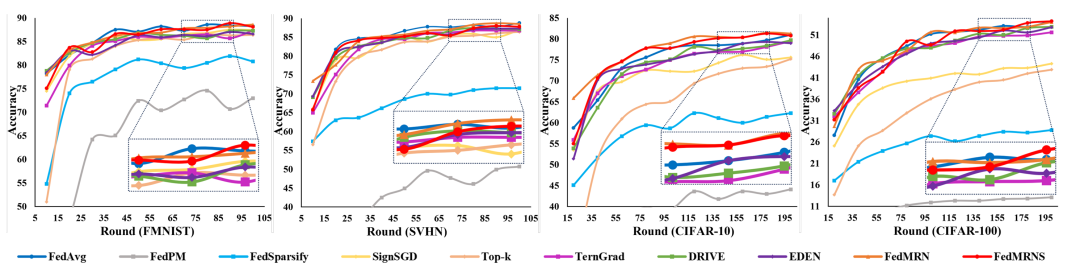
图3 FedMRN与相关基线收敛速度对比
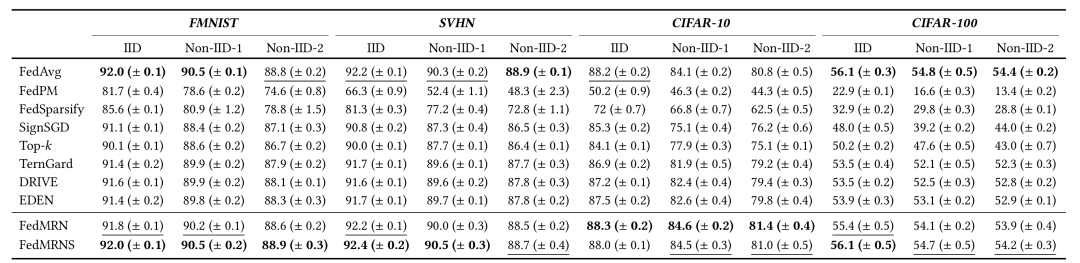
图4 FedMRN与相关基线测试精度对比
此外,本文还对PSM设计了消融实验,实验结果如下图。可以看到SM和PM对精度均有正向作用,其中属SM的作用更为显著。另外,FedAvg w. SM代表在本地训练后使用SM对FedAvg中的模型增量映射到随机掩蔽噪声上。对比FedAvg w. SM与FedMRN w.o. PM可以发现本地训练学习到的掩码的性能要明显优于训练后生成的掩码。
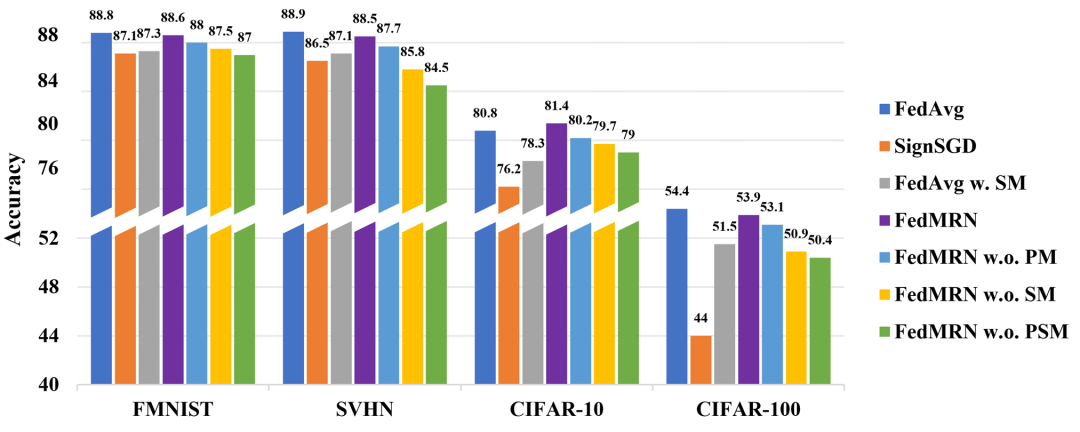
图5 PM与SM的消融实验结果

专委会责任副主任:张勇东
 京公网安备11010802017125号
京公网安备11010802017125号