
【论文导读】2025年论文导读第十四期
【论文导读】2025年论文导读第十四期
2025年8月5日 08:45 吉林


论文导读
2025年论文导读第十四期(总第一百三十一期)
目 录
|
1 |
Poly Kernel Inception Network for Remote Sensing Detection |
|
2 |
DAC: 2D-3D Retrieval with Noisy Labels via Divide-and-Conquer Alignment and Correction |
|
3 |
Navigating Weight Prediction with Diet Diary |
|
4 |
Incremental Learning via Robust Parameter Posterior Fusion |
|
5 |
Triple Alignment Strategies for Zero-shot Phrase Grounding under Weak Supervision |
01
Poly Kernel Inception Network for Remote Sensing Detection
作者:
蔡鑫浩1#,赖秋霞2#,王钰炜1#、王文冠3*、孙泽人1、姚亚洲1*
单位:
南京理工大学1,中国传媒大学2,浙江大学3
邮箱:
xinhao@njust.edu.cn
wenguanwang.ai@gmail.com
yazhou.yao@njust.edu.cn
论文:
https://openaccess.thecvf.com/content/CVPR2024/papers/Cai_Poly_Kernel_Inception_Network_for_Remote_Sensing_Detection_CVPR_2024_paper.pdf
发表会议:
CVPR 2024
*通讯作者
#共同第一作者
1.研究背景
遥感图像(RSIs)中的目标检测面临多项挑战,特别是目标尺度的巨大变化和多样的上下文信息。传统方法通过扩大骨干网络的空间感受野来解决这些问题,例如使用大核卷积或空洞卷积。然而,大核卷积会引入大量背景噪声,而空洞卷积可能导致特征表示过于稀疏。
2.方法概述
本文提出了一种名为多核Inception遥感检测网络(PKINet)的新型网络,旨在解决遥感图像中目标尺度变化大和上下文多样性等挑战。PKINet采用无空洞的多尺度卷积核并行排列,以提取不同尺度的目标特征并捕获局部上下文信息。此外,还引入了一个并行上下文锚点注意力(CAA)模块,用于捕获长程上下文信息。这两个组件协同工作,以提升PKINet在DOTA-v1.0、DOTA-v1.5、HRSC2016和DIOR-R等四个遥感检测基准上的性能。PKINet是首次探索Inception风格多尺度卷积和全局上下文注意力在遥感目标检测中应用的工作。该模型通过策略性地使用深度可分离卷积和1D卷积,与现有方法相比更为轻量级。
图1顶部图展示了PKINet在DOTA-v1.0数据集上相对于其他遥感检测器的性能提升,且参数更少。底部图显示了不同核大小对目标检测的影响,并突出了PKINet处理尺度变化的能力。如图2所示,PKINet是一个特征提取骨干网络,主要包含:
1) PKI模块: 如图2(d)所示,PKI模块是一个Inception风格的模块,包含一个用于捕获局部信息的小核卷积,以及一组并行的深度可分离卷积,用于捕获多尺度上下文信息。PKI模块不使用空洞卷积,从而避免提取过于稀疏的特征表示。局部特征和上下文特征通过1×1 卷积进行融合,以表征不同通道间的相互关系,该卷积作为通道融合机制整合了具有不同感受野大小的特征。
2) CAA Module (上下文锚点注意力模块):如图2(e)所示,CAA模块旨在捕获远距离像素之间的上下文相互依赖关系,同时增强中心区域的特征 。它通过平均池化和 1×1 卷积获取局部区域特征,然后应用两个深度可分离条状卷积来近似标准的、大核的深度可分离卷积。条状卷积轻量且有助于识别和提取细长形状目标的特征 。CAA模块的感受野会随着PKI块的深度增加而增大,增强了PKINet建立长程像素间关系的能力,同时不会显著增加计算成本。最终,CAA模块生成注意力权重,用于增强PKI模块的输出。
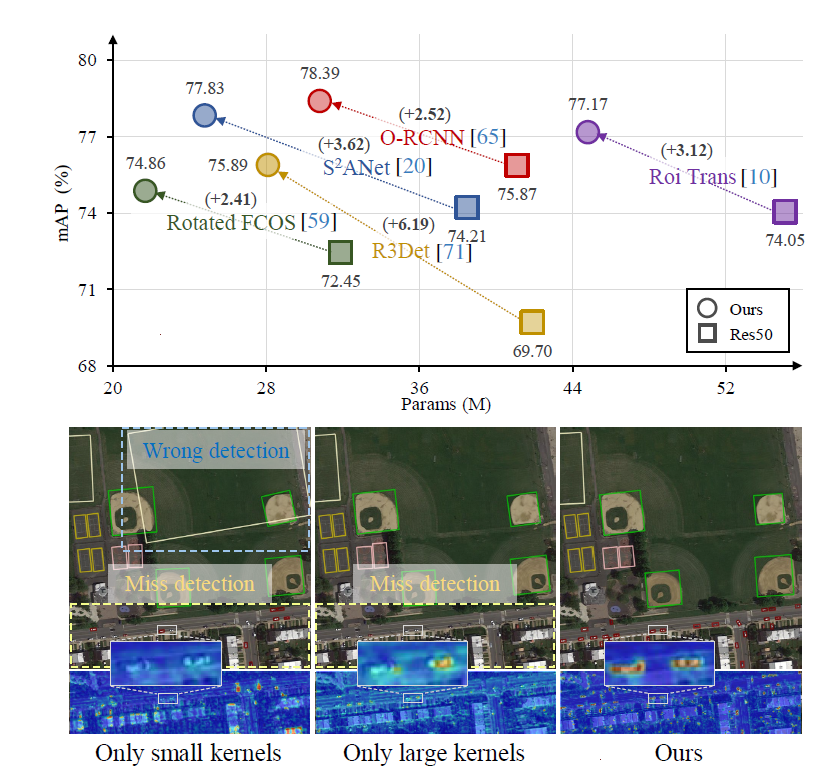
图1 方法概览图模型性能与核大小影响对比图
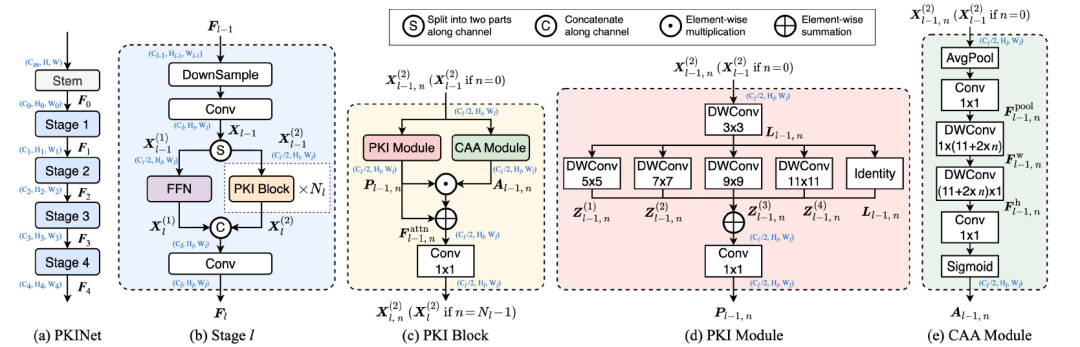
图2 PKINet模型概览图
3.实验结果
PKINet可以与各种遥感目标检测头结合,以生成遥感图像的最终目标检测结果。
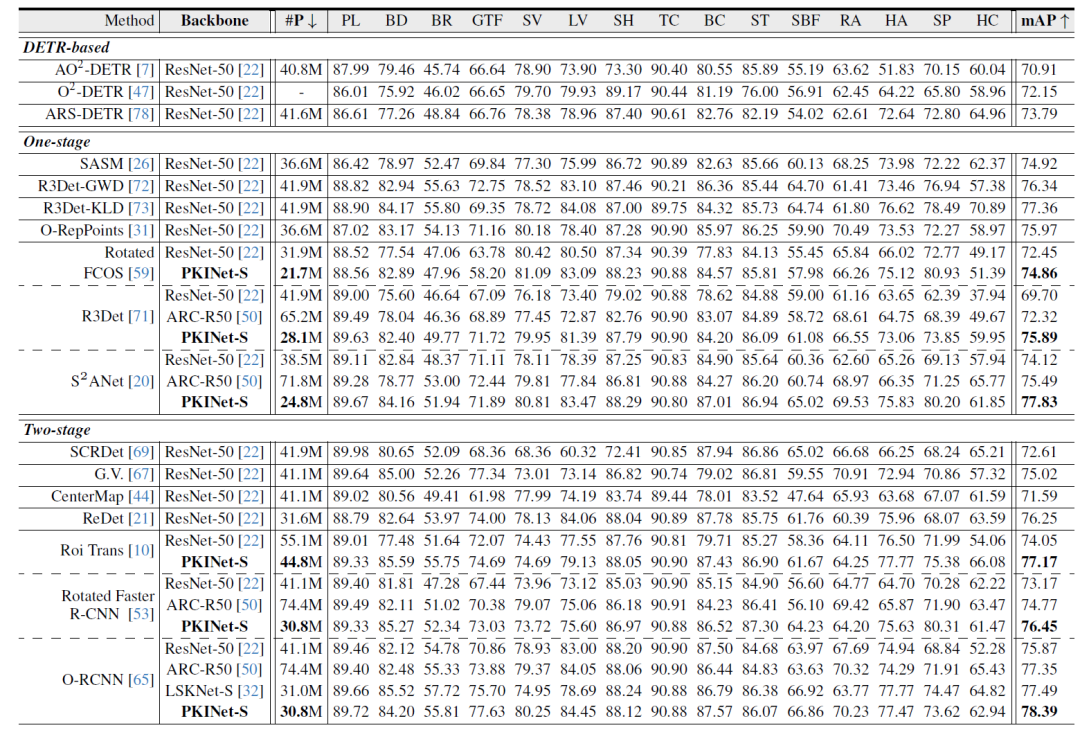
图3 PKINet在DOTA-v1.0上与现有遥感目标检测方法定量结果对比

图4 PKINet与其他方法定性比较
4.总结
本文提出了多核Inception遥感检测网络(PKINet),旨在解决遥感图像中目标尺度变化大和上下文多样性的挑战。PKINet采用并行深度可分离卷积核有效捕获不同尺度的密集纹理特征。同时,引入了上下文锚点注意力机制以进一步捕获长程上下文信息。实验结果表明,PKINet在四个常用的遥感基准数据集上取得了最先进的性能。
02
DAC: 2D-3D Retrieval with Noisy Labels via Divide-and-Conquer Alignment and Correction
作者:
甘超凡1,涂远鹏2,李昱兮1,林巍峣1,*
单位:
上海交通大学1,香港大学2
邮箱:
ganchaofan@sjtu.edu.cn
2030809@tongji.edu.cn
yukiyxli@tencent.com
wylin@sjtu.edu.cn
论文:
https://dl.acm.org/doi/abs/10.1145/3664647.3680859
代码:
https://github.com/ganchaofan0000/DAC
发表会议:ACM MM 2024
*通讯作者
1.背景与动机
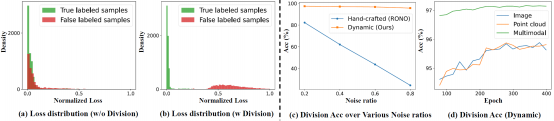
图1 跨模态检索中噪声标签带来的挑战与现有方法的局限性
随着 3D 采集技术的快速发展,2D-3D 跨模态检索在虚拟现实、自动驾驶等领域 具有重要应用价值。然而,3D数据的高维性和不规则分布使其标注成本高昂,导致实际数据集中普遍存在噪声标签问题,数据中的噪声标签导致了模型在训练程中的过拟合。如图1所示,现有方法主要依赖手工设定阈值划分样本,存在以下局限性:
• 阈值敏感性:性能高度依赖阈值选择,泛化能力差;
• 信息利用不足:未充分挖掘不同子集(如干净/噪声样本)的监督信号;
• 模态互补性缺失:单模态划分策略忽略多模态数据的互补信息
因此,本文提出 DAC 框架,通过动态建模样本可信度和自适应对齐策略,显著提升噪声标签下的跨模态检索鲁棒性。
2.技术贡献
我们框架 DAC 如图 2 所示,其中包含两个精心设计的核心模块。
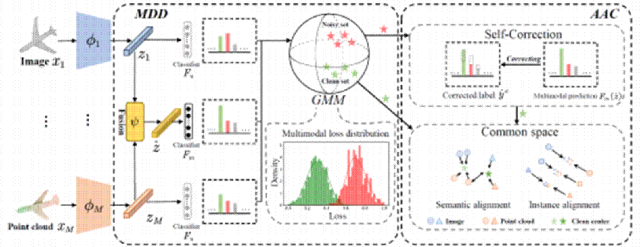
图2 DAC 整体框架
(1)多模态动态划分(MDD)模块
传统方法通常基于单模态信息进行样本划分,这往往会导致信息利用不充分。MDD模块的创新之处在于:提出多模态损失分布的概念,通过特征融合层ψ将图像、点云等多模态特征进行深度融合。具体来说,对于每个样本,我们计算其多模态分类损失,采用高斯混合模型(GMM)对损失分布进行建模。通过 EM 算法迭代优化,我们能够准确估计每个样本属于干净集的概率,然后我们利用阈值α动态划分数据样本,使得模型能够自适应处理不同噪声比例的数据集,避免了手工调参的繁琐。
(2) 自适应对齐与校正(AAC)模块
AAC 模块针对不同子集设计了差异化的处理策略:对于干净集:采用创新的对比中心损失进行语义对齐,该损失函数通过温度系数控制特征分布的紧密度,相比传统中心损失具有更好的优化特性。对于噪声集:首先进行实例级对齐,缩小模态间差异: 然后采用自校正策略,通过 EMA 平滑生成可靠的伪标签。
同通道间的相互关系,该卷积作为通道融合机制整合了具有不同感受野大小的特征。
3.实验结果
我们在传统数据集 ModelNet10/40 和真实噪声数据集 Objaverse-N200 上进行了全面的实验评估。在 ModelNet40 数据集上,DAC 在80%对称噪声下的图像到点云检索任务中取得了 87.9%的 mAP,相比当前最优方法 RONO 提升了5.9个百分点;在点云到图像检索任务中达到 87.1%的mAP,提升幅度为5.0个百分点。 值得注意的是,即使在无额外噪声的原始数据上,DAC仍保持 89.5%的优异性能,验证了方法的通用性。
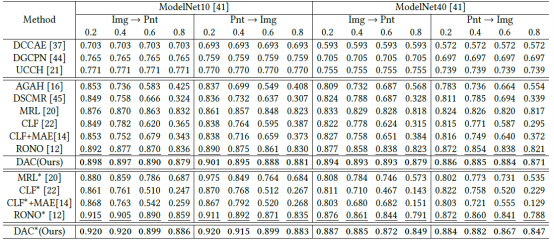
表1 在 ModelNet10/40 数据集上的结果
在更具挑战性的 Objaverse-N200 真实噪声数据集上,DAC 展现出更强的鲁棒性,在图像到点云检索任务中取得 33.4%的mAP,显著优于无监督方法OpenShape(27.4%),而在点云到图像检索任务中更是实现了31.5%的相对性能提升。结合两个数据集的实验结果,跨模态可视化实验结果如图3所示,我们的方法在不同类型噪声上展现了卓越且稳健的性能,从而验证了我们方法的有效性。
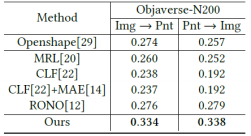
表 2 在 Objaverse-N200 数据集上的结果
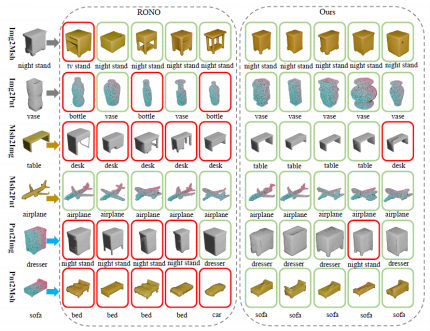
图 3 跨模态检索可视化结果
03
Navigating Weight Prediction with Diet Diary
基于时序饮食日记的体重变化预测研究
作者:
桂引暄1 朱斌2 陈静静1,* Chong Wah Ngo2 姜育刚1
单位:
复旦大学1,新加坡管理大学2
邮箱:
yxgui22@m.fudan.edu.cn
binzhu@smu.edu.sg
chenjingjing@fudan.edu.cn
cwngo@smu.edu.sg
ygj@fudan.edu.cn
项目主页:
https://yxg1005.github.io/weight-prediction
发表会议:ACM MM 2024 (Oral)
*通讯作者
1.论文简介
在数据爆炸式增长的时代,数据可视化成为人们理解复杂信息、辅助决策的重要手段。桑基图(Sankey Diagram)因其在展示数据流向与比例方面的优势,广泛应用于能源流、金融流、产品生命周期等多种应用场景。然而,现有的桑基图主要以二维静态形式呈现,尤其在高密度复杂数据情形下,容易出现信息遮挡、视觉重叠等问题,限制了用户对数据结构与流动趋势的全面理解。虚拟现实(Virtual Reality,VR)技术凭借其特有的沉浸感与空间自由度,为复杂数据可视化提供了突破口,有望缓解二维平面可视化的瓶颈,提升复杂数据流可视化与分析的效率与体验。
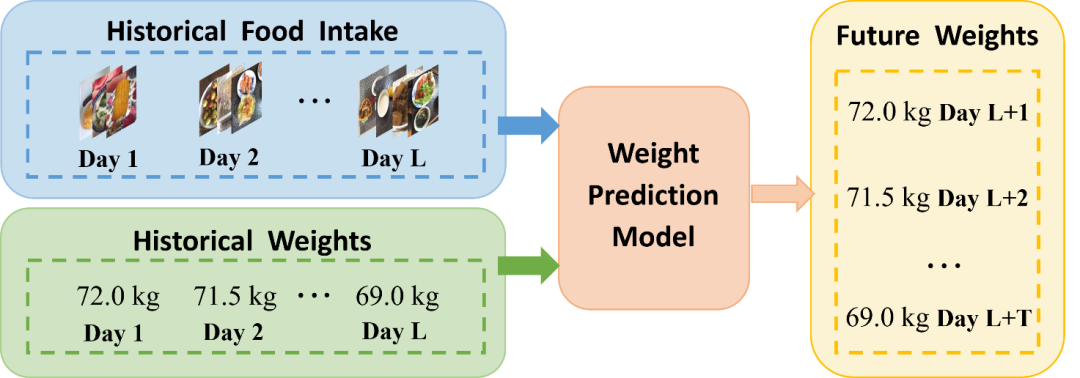
图1 体重预测任务示意图
2.数据集构建
饮食日记数据集收集自一个健康管理系统,参与者需要详细记录每日三餐的饮食情况,并同步记录对应的体重测量数据。每条饮食记录不仅包含食物图像,还配有人工标注的食材信息。该数据集涵盖了611名参与者,累计收集了超过5000 条日常记录,近 3 万张食物图像,以及 1.5 万余条食材标注。数据集中的部分食物图片如图2所示。这些数据为研究饮食习惯、食材种类及其与体重变化的关联性提供了支持。据调研,饮食日记是目前首个提供此类数据的数据集。

图2 数据集展示
3.方法概述
本文提出的体重预测框架如图3 所示。本框架主要由三个关键组件组成:统一膳食表征学习模块(Unified Meal Representation Learning)、通用时间序列预测模型(Time Series Forecasting Model)以及基于饮食和体重的损失计算(Diet-aware Loss)。
给定历史饮食数据,统一膳食表征学习旨在分别为每日的早餐、午餐和晚餐获取特征表示。在从统一膳食表征学习模块获取历史饮食摄入的特征后,该特征与对应的历史体重序列进行融合,以形成完整的输入特征,随后将其输入至时间序列预测模型。值得注意的是,本方法在时间序列预测模型的选择上具有高度的通用性,不依赖于特定模型架构。此外,本文引入了一种基于饮食信息的损失函数:饮食-体重损失,用于建模食物摄入与体重变化之间的关系。
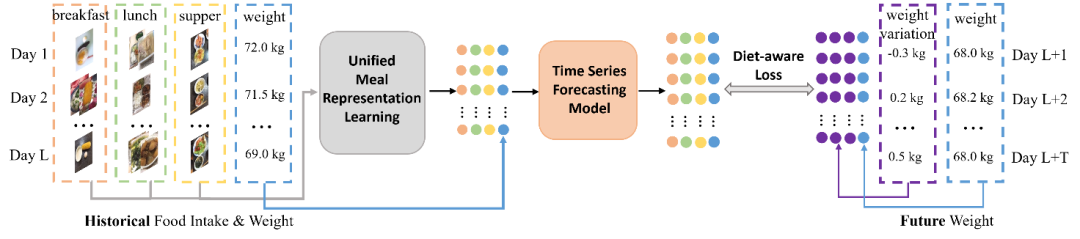
图3 体重预测框架图
4.实验与分析
所有实验均在 DietDiary 数据集上进行。本文在两个先进的时序预测模型Nlinear和iTransformer上均证明了在体重预测任务中加入食物信息的有效性。以Nlinear为例,在用历史七天的食物信息和体重数据预测未来七天的体重变化的实验中,与Baseline相比,本文方法的MAE(平均绝对误差)从1.958下降到1.376,MSE(平均均方误差)从6.791下降到2.497,显著优于Baseline。接着,本文在多种不同历史-未来天数组合下进行实验(如图4所示)以进一步验证方法的有效性。方便起见,用L-T表示利用历史L天的数据预测未来T天的体重。 图4的结果表明,无论何种天数组合,食物信息的加入均能大幅降低体重预测的误差。
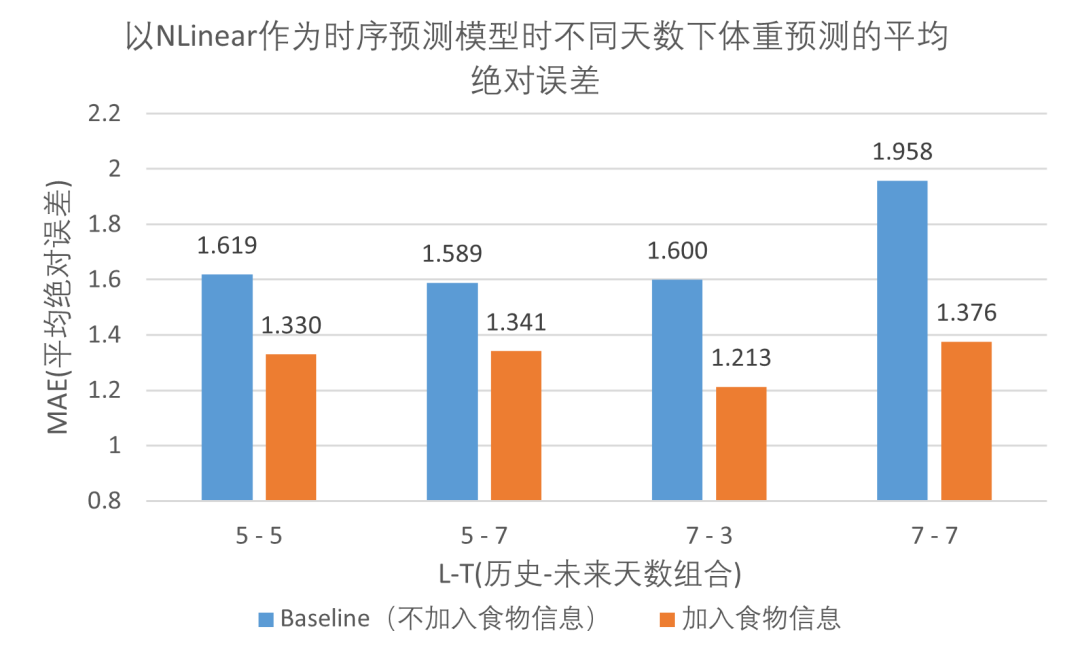
图4 实验结果
04
Incremental Learning via Robust Parameter Posterior Fusion
作者:
孙文举,李清勇,张思雨,王雯,耿阳李敖*
单位:
北京交通大学
邮箱:
sunwenju@bjtu.edu.cn
论文:
https://dl.acm.org/doi/abs/10.1145/3664647.3681164
代码:
https://github.com/SunWenJu123/RP2F
发表会议:
ACM MM 2024
*通讯作者
1.研究背景与问题定义
在增量学习中,模型面临一个核心挑战:在连续接受新任务训练时容易遗忘旧任务,造成灾难性遗忘。为缓解此问题,现有方法多借助正则化(如EWC、SI)、参数重放(如DER++)、子空间约束(如GPM)或样本回放等手段。然而,正则化类方法在权重调节、损失冲突以及任务间知识整合方面存在局限,特别是在任务间分布差异较大时,往往难以维持稳定性能。
本文提出鲁棒参数后验融合(Robust Parameter Posterior Fusion, RP2F)框架,如图1所示,基于贝叶斯理论与最大后验估计(MAP),以任务后验分布为基本单位,通过结构化融合历史与当前任务的后验,实现跨任务参数整合,无需额外回放样本或显式正则项,展现出优越的可扩展性和鲁棒性。
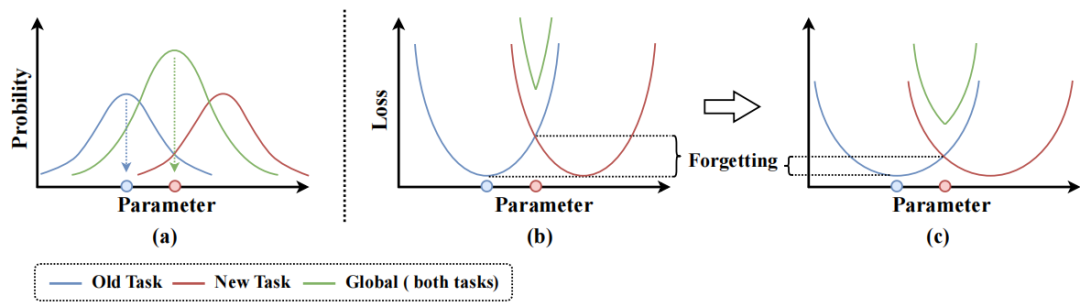
图 1 鲁棒参数后验融合方法概念图。(a) 通过融合新旧任务参数分布,可以找到最优的参数似然估计。为了缓解参数分布融合导致的遗忘(b),本工作通过参数鲁棒性先验使融合过程更稳定(c)。
2.方法概述与关键技术
RP2F 所提出的方法核心在于:将每个任务的训练过程视为一次独立的参数后验估计,并以最大后验(MAP)原则构建任务之间的累积知识。在传统贝叶斯方法中,历史知识往往通过加入额外正则项来实现“软约束”,而 RP2F则直接在参数空间中对多个任务的后验进行融合,避免了权重调节与优化冲突的问题。具体做法是,在每轮任务完成后,将当前任务的后验估计作为新的参数分布,与先前任务的后验在分布层面融合,从而形成全局更新后的参数估计,即:
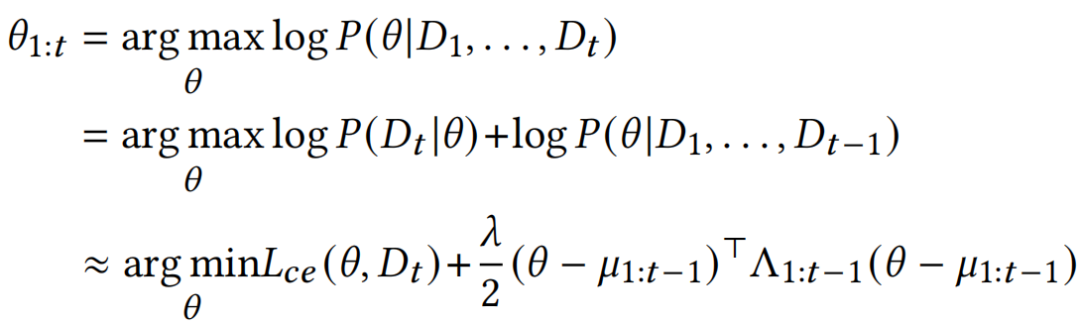
然而,在实践中,此框架面临两方面挑战。一方面是如何高效、准确地估计二阶梯度信息;另一方面是如何减少分布融合的带来的误差。本工作分别提出了针对性的解决方案。
RP2F并不直接计算复杂的二阶梯度信息,而是采用了一种基于参数扰动的高效近似方法。具体来说,作者在每轮训练后,对模型参数进行小幅度扰动,并通过观察扰动前后的梯度变化,估算每个参数方向上的曲率信息,即后验分布的精度(Hessian 对角元)。这一策略相比传统的数值差分或高阶自动微分,既保持了较高的估计准确度,又将计算代价控制在可接受范围内,尤其适用于大规模神经网络的增量训练场景。
此外,RP2F在后验融合过程中引入了鲁棒性先验,用以缓解不同任务间特征空间分布不一致所带来的融合偏移问题。该先验通过约束隐藏层特征的奇异值分布,鼓励网络在学习过程中保持表征维度的均衡性,从而提升各任务之间共享子空间的一致性。实验表明,这一结构性正则不仅提升了融合质量,也显著增强了模型对任务数量增加和任务间差异扩大的适应能力。
3.实验设计与分析
(1)基础对比实验。作者在CIFAR-10、CIFAR-100、Tiny -ImageNet数据集上将RP2F与多个主流方法(EWC, DER++, GPM, EFT等)进行比较。如图表 2所示,RP2F在最终平均精度上显著优于对比方法。
(2)稳定性分析。作者在CIFAR-100和Tiny -ImageNe数据集上对比RP2F与多个主流方法的稳定性。如图表 3所示,RP2F在后向迁移指标(BWT)上首次取得正值(>0),表明其不仅减缓遗忘,还促进了旧任务性能提升。
(3)消融实验。论文对核心组件进行了系统性消融,包括Hessian估计方案和参数鲁棒先验。如图表 4所示,基于扰动的Hessian估计相比已有Fisher信息矩阵估计方法更高效稳定,同时鲁棒先验在各种Hessian估计方案下都能显著提升增量融合的质量。
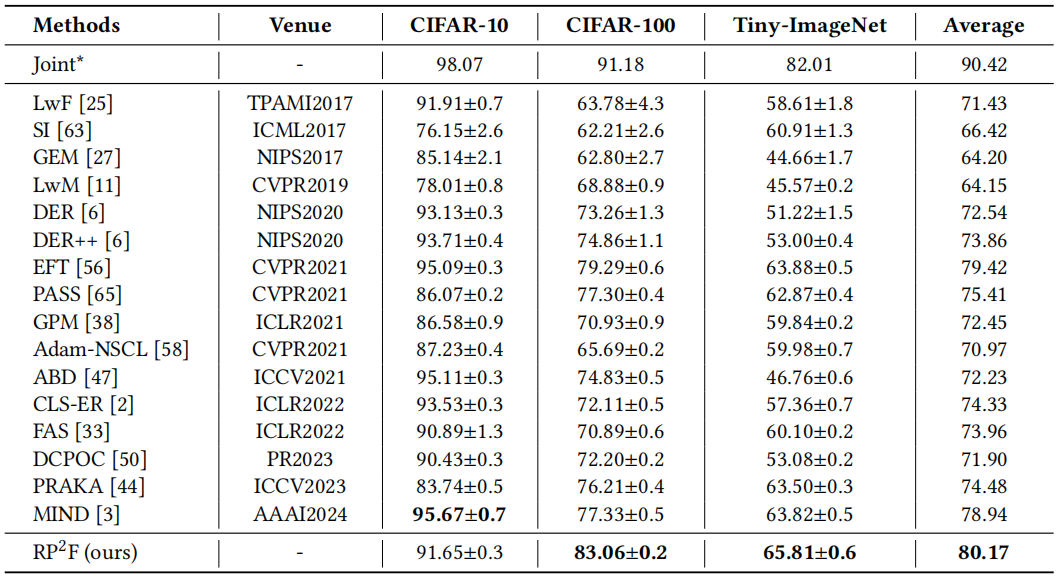
图2 对比实验

图3 稳定性对比实验
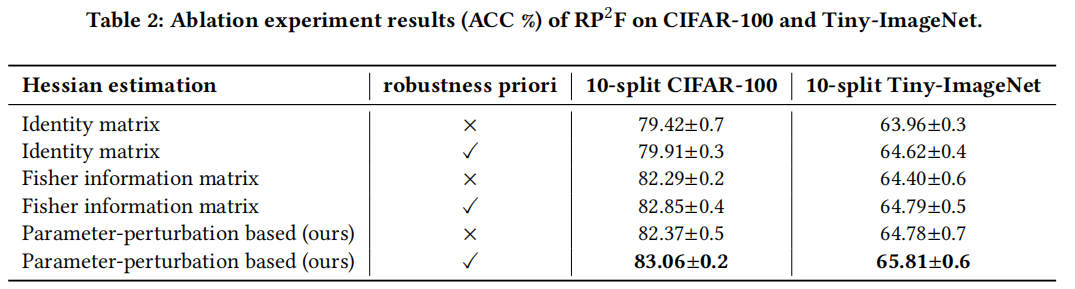
图4 消融实验
05
Triple Alignment Strategies for Zero-shot Phrase Grounding under Weak Supervision
作者:
林芃樾,李睿凡*,季宇哲,余之寒,冯方向,马占宇,王小捷
单位:
北京邮电大学
邮箱:
linpengyue@bupt.edu.cn
rfli@bupt.edu.cn
jiyz@bupt.edu.cn
yzh0@bupt.edu.cn
fxfeng@bupt.edu.cn
mazhanyu@bupt.edu.cn
xjwang@bupt.edu.cn
论文:
https://dl.acm.org/doi/abs/10.1145/3664647.3680897
代码:
https://github.com/LinPengyue/ZS-WSG
发表会议:ACM MM 2024
*通讯作者
1.研究背景
短语接地(Phrase Grounding)旨在定位名词短语指代的目标物。目前研究者分别提出两种方法:一种是在缺乏区域级标注的前提下进行短语接地(即弱监督短语接地),另一种是从已知类别推断未知类别的短语接地(即零样本短语接地)。然而,这两种方法在实际应用中存在局限性,它们未能充分考虑场景的复杂性及数据分布的不确定性。因此,本文首次考虑弱监督条件下的零样本短语接地,此任务存在以下三个关键挑战:(1)如何将已知类别的属性与未知类别的属性关联起来?(2)如何将从已知类别中学到的知识转移到未知类别中?(3)如何衡量已知类别和未知类别的相似性和差异性?
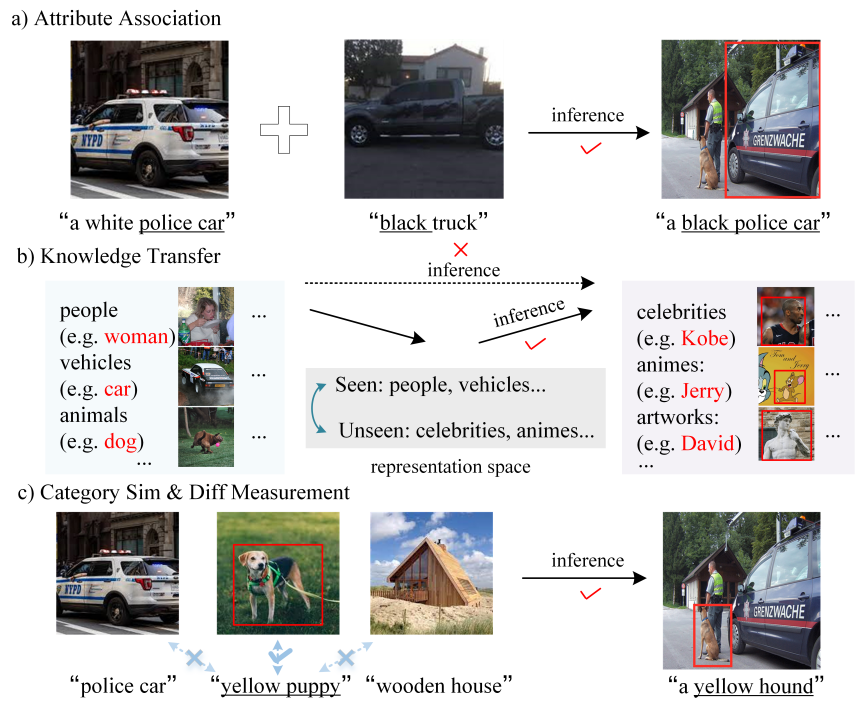
图1 弱监督条件下零样本短语接地的关键挑战示意图
2.方法概述
本文提出基于三元对齐策略的短语接地框架,旨在解决弱监督条件下零样本短语接地的关键挑战。该框架主要包含以下三个对齐策略:
1)区域-文本对齐(RTA)策略:该策略旨在基于对比语言-图像预训练模型(CLIP)建立区域级别的属性关联。首先,本文提取给定短语对应的区域级视觉语义,并将其与文本嵌入进行匹配。其次,引入patch级梯度图对CLIP生成的热力图进行优化,并将该热力图作为伪标签用于弱监督学习过程。
2)域对齐(DomA)策略:该策略旨在迁移在已见类别中学习到的知识。首先,本文通过学习域不变空间,将接地相关特征与预训练模型中的特征对齐。其次,设计对齐损失函数以自适应地调整接地相关特征。
3)类别对齐(CatA)策略:该策略旨在同时考虑类别语义和区域-类别关系,以区分被定位目标的类别。首先,本文基于短语嵌入对类别进行判断。其次,为了建立准确的区域-类别关系,使用CLIP衡量图像区域与短语之间的相似性。
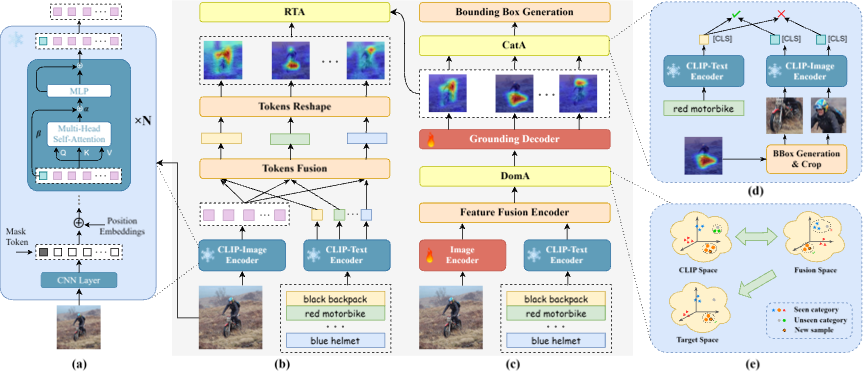
图2 模型框架图
3.实验结果
本文在Flickr-Split和VG-Split数据集上进行实验,并将我们的方法与此前的先进方法进行比较,以评估其有效性。表1结果显示,相比于弱监督方法,本文方法在零样本短语接地评测基准上实现了显著的性能提升。
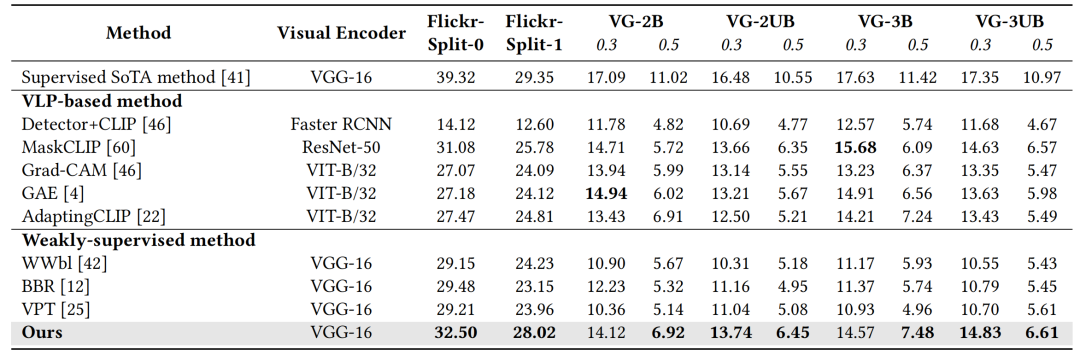
表1 在零样本短语接地评测基准上性能对比
表2展示在Flickr30K、VG和ReferIt数据集上的结果,本文方法超越之前的先进方法。结合多个数据集的实验结果,我们的方法在弱监督条件下的零样本短语接地上展现了卓越且稳健的性能,从而验证了三元对齐策略的有效性。可视化实验结果如图3所示。
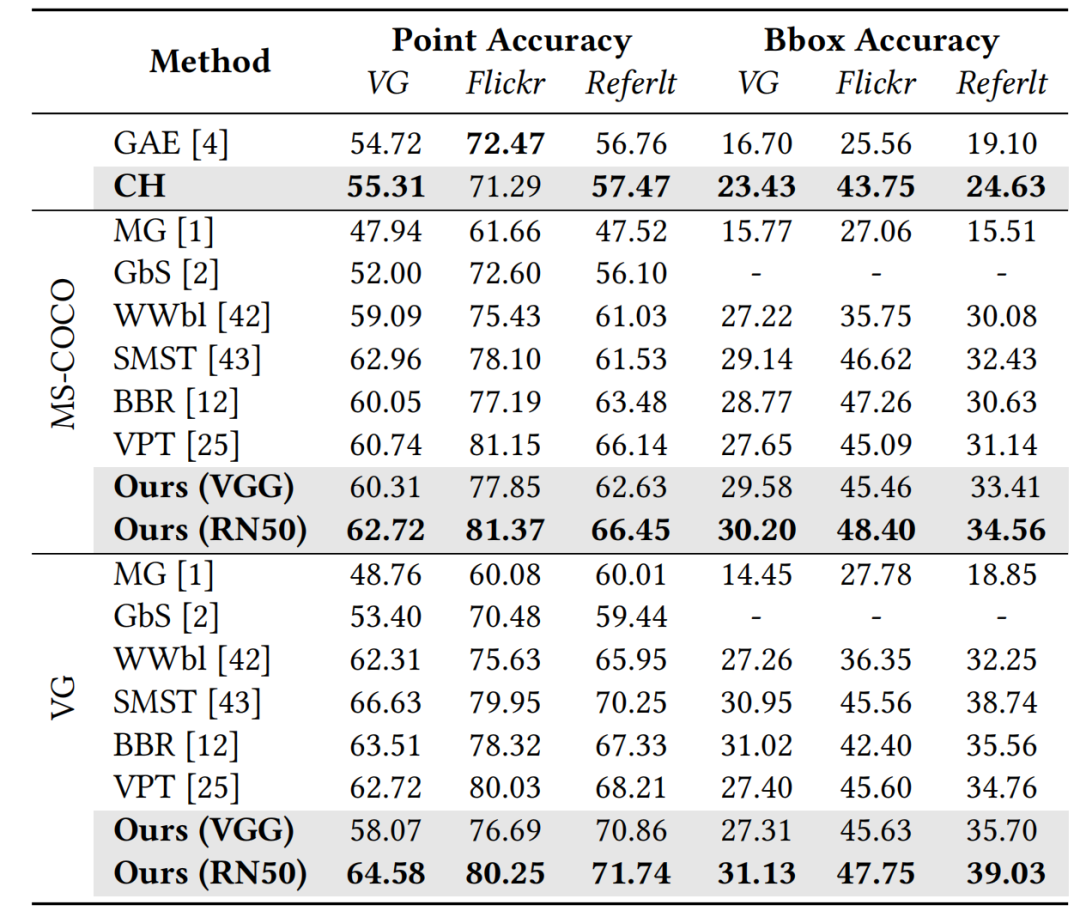
表2 在弱监督短语接地评测基准上性能对比

图3 可视化结果对比

编辑人:吴建龙、任文琦
专委会责任副主任:张勇东
 京公网安备11010802017125号
京公网安备11010802017125号