
【论文导读】2025年论文导读第十五期
【论文导读】2025年论文导读第十五期
2025年8月19日 09:56 北京


论文导读
2025年论文导读第十五期(总第一百三十二期)
目 录
|
1 |
Enhancing Robustness in Learning with Noisy Labels: An Asymmetric Co-Training Approach |
|
2 |
Making Large Language Models Perform Better in Knowledge Graph Completion |
|
3 |
Towards Effective Data-Free Knowledge Distillation via Diverse Diffusion Augmentation |
|
4 |
Sparse Query Dense: Enhancing 3D Object Detection with Pseudo Points |
|
5 |
Leveraging Knowledge of Modality Experts for Incomplete Multimodal Learning |
01
Enhancing Robustness in Learning with Noisy Labels: An Asymmetric Co-Training Approach
作者:
盛猛猛1,孙泽人1*,裴根生1,陈涛1,罗浩楠2,姚亚洲1*
单位:
南京理工大学1, 西南交通大学2
邮箱:
shengmengmemg@njust.edu.cn;
zerens@njust.edu.cn;
peigsh@njust.edu.cn;
taochen@njust.edu.cn;
lhn@swjtu.edu.cn;
yazhou.yao@njust.edu.cn
论文:
https://doi.org/10.1145/3664647.3680835
代码:
https://nust-machine-intelligence-laboratory.github.io/project-ACT
发表会议:
ACM MM2024
*通讯作者
1.论文简介
本文旨在解决深度神经网络在含噪标签数据集上的鲁棒性问题。标签噪声作为各种现实世界数据集中不可避免的问题,往往会损害深度神经网络的性能。大量文献集中于对称协同训练,旨在通过利用具有不同能力的模型之间的交互来增强模型鲁棒性。然而,现有方法中采用的对称训练过程通常导致模型共识,降低了它们处理噪声标签的有效性,存在模型后期收敛导致处理效果下降的问题。本研究提出一种创新的非对称协同训练(ACT)方法,通过构建鲁棒训练模型(RTM)和非鲁棒训练模型(NTM)的差异化训练策略,实现持续的模型能力差异,从而显著提升对噪声标签的抗干扰能力。这种方法不需要任何数据集依赖的先验知识,具有更强的实用性和适应性。
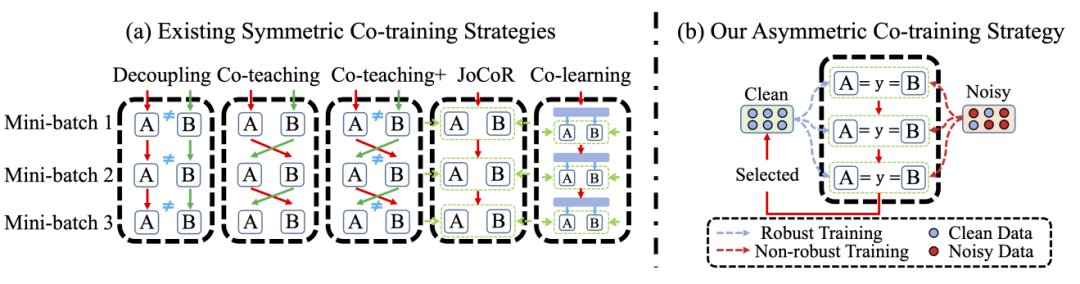
图1 方法概览图
2.方法概述
现有的对称协同训练方法依赖于双网络通过不同权重初始化实现相互指导,尽管能增强鲁棒性,但由于模型结构和训练方式相似,后期易出现收敛,导致处理噪声标签的能力显著下降。这一问题根源在于孪生网络之间学习能力差异有限,同质化训练过程限制了信息增益。为此,本文提出一种非对称协同训练框架:其中,RTM(鲁棒模型)仅在精心挑选的干净样本子集上训练,专注于学习稳定特征;NTM(普通模型)则在完整训练集上常规训练,以逐步适应数据中的多样模式与噪声。该异构结构打破传统对称架构的局限,有效维持两个模型在整个训练过程中的差异性和互补性。
在此基础上,本文设计了两个关键的样本选择与挖掘标准。第一,一致性共识标准:当RTM与NTM的预测均与标签一致时,判定为高可信度的干净样本。第二,预测差异挖掘标准:当NTM预测与标签一致而RTM不一致,且NTM尚未受到标签记忆影响时,将其识别为潜在干净样本。为动态控制样本挖掘的时机,本文进一步提出自适应度量指标,通过计算NTM与RTM准确率差异的相对比值,量化NTM对噪声标签的记忆程度。该机制确保了样本选择策略的动态性和精度,显著提升了在噪声标签环境下的训练鲁棒性和模型协同效率。
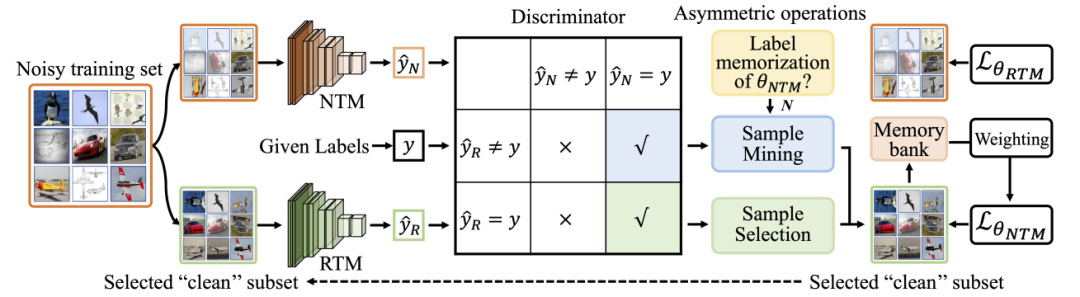
图2 两个关键的样本选择与挖掘标准
3.实验结果
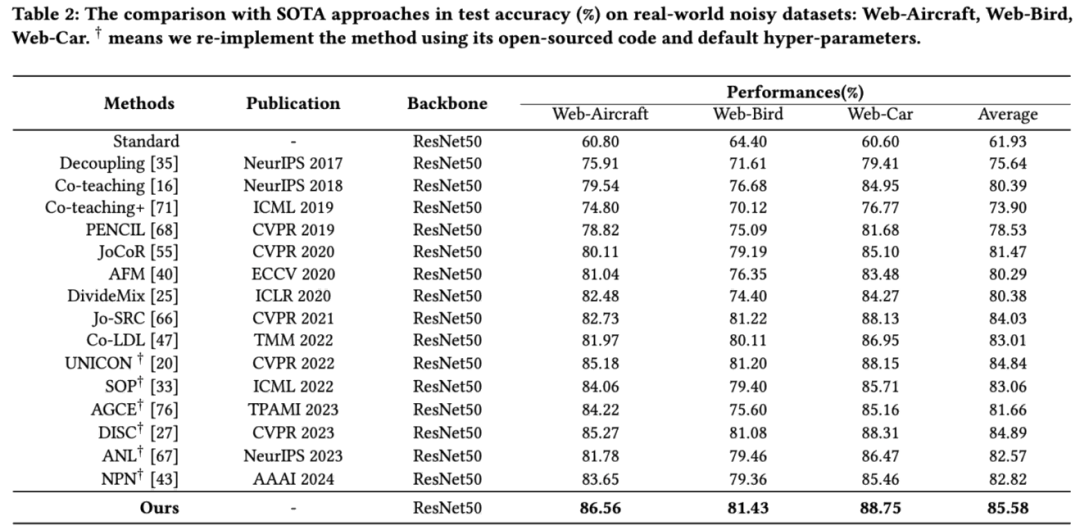
本文在两个人工合成噪声数据集(即 CIFAR100N 和 CIFAR80N)以及四个真实世界噪声数据集(即Web-Aircraft、Web-Bird和Web-Car)上评估本文提出的的 ACT 方法。表 1 展示了在合成数据集(即 CIFAR100N 和 CIFAR80N)上,在各种噪声类型(即对称和非对称)和噪声率(即 20%、40% 和 80%)下的比较结果。表 2 展示了我们的 ACT 与现有 SOTA 方法在三个真实世界数据集(即 Web-Aircraft、Web-Bird 和 Web-Car)上的比较结果。从实验结果可以看到,本文提出的ACT均取得性能的显著提升。
表1实验结果1
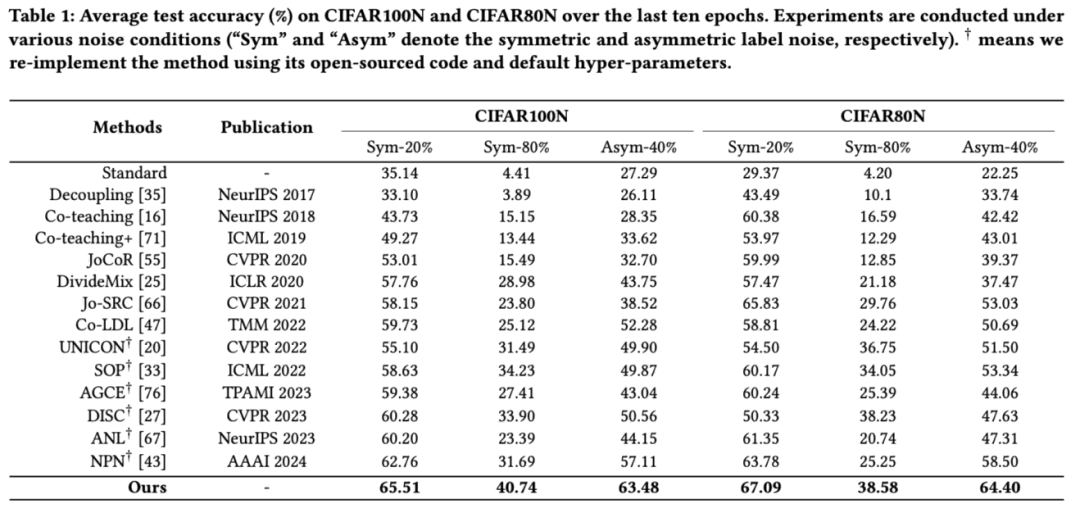
表2实验结果2
02
Making Large Language Models Perform Better in Knowledge Graph Completion
作者:
张溢弛、陈卓、郭凌冰、徐雅静、张文、陈华钧*
单位:
浙江大学
邮箱:
zhangyichi.each@zju.edu.cn
论文:
https://dl.acm.org/doi/10.1145/3664647.3681327
发表会议:ACM MM 2024
*通讯作者
1.背景与动机
大语言模型凭借其强大的文本理解与生成能力在AI的各个领域中掀起了研究的热潮。大语言模型(LLM)与知识图谱(KG)的结合是未来大语言模型未来的重要发展方向之一。一方面,大模型凭借其丰富的文本理解和生成能力可以完成知识图谱的构建以及推理和补全,另一方面,知识图谱也可以为大模型提供可信的外部知识,缓解大模型中出现的幻觉现象。这篇论文着眼于基于大模型的知识图谱补全(LLM4KGC),探索了如何才能更好地让大语言模型完成知识图谱补全这项任务。
2.技术贡献
已有的LLM4KGC的方法往往是通过指令微调的方式,构造提示词模版将一条条的三元组输入大模型中对大模型进行微调,来训练出能够完成KGC任务的LLM,但是这样的方法没有充分利用KG中存在的复杂结构信息,导致LLM无法充分地理解知识图谱中的结构信息,从而限制了LLM解决KGC问题的能力。围绕如何在LLM中引入KG结构信息这一个问题,该文章做出了如下几点贡献:
论文探究了在常见的LLM范式(不需要训练的In-Context Learning和需要训练的指令微调)基础上如何引入知识图谱的结构信息,分别提出了一种结构增强的上下文学习方法和结构增强的指令微调方法;
论文提出了一种知识前缀适配器(Knowledge Prefix Adapter, KoPA),将KG中提取的结构知识通过一个适配器映射到大模型的文本token表示空间中,并和三元组的文本一起进行指令微调,使得LLM能够充分理解KG中的结构信息,并在结构信息的辅助下完成知识图谱的推理;
论文进行了大量的实验,来验证了论文中提出的多种方法的性能,探索最合理的结构信息引入方案。
3.方法介绍
论文首先提出了结构增强的上下文学习和指令微调方法,通过将输入的三元组的局部结构信息通过文本描述的方式添加到指令模版中,实现结构信息的注入。
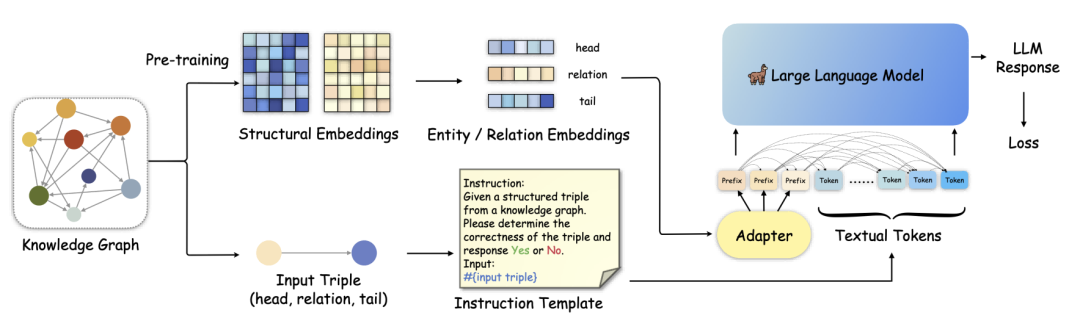
图1 方法概述
另一方面,论文中提出的知识前缀适配器(KoPA)的主要设计方案如上图所示,首先KoPA通过结构特征的预训练提取知识图谱中实体和关系的结构信息,之后,KoPA通过一个设计好的适配器,将输入三元组对应的结构特征投影到大语言模型的文本表示空间中,然后放置于输入prompt的最前端,让输入的提示词模版中的每个token都能“看到”这些结构特征,然后通过微调的Next Word Prediction目标对LLM的训练。论文对不同的结构信息引入方案进行了对比,对比的结果如下:
表1

4.实验结果
实现部分,该论文选取了三个数据集,进行了三元组分类的实验。三元组分类是一项重要的知识图谱补全任务,旨在判断给定三元组的正确性。论文的主要实验结果如下:
表2
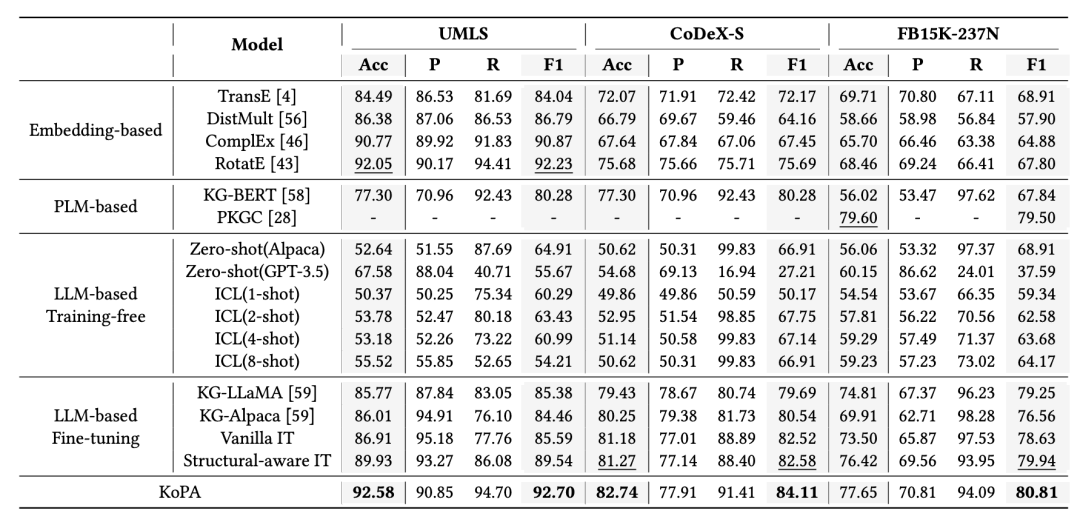
可以看到,相比于传统方法、基于大模型的方法和引入结构信息的方法来说,KoPA在三个数据集上的准确率、F1值等指标取得了一定的提升。此外论文还对KoPA中适配器的可迁移性、模块设计的合理性等进行了分析,感兴趣的读者可以通过阅读原论文了解进一步的内容。
5.总结
该论文探索了如何将知识图谱中的结构知识引入大语言模型中,以更好地完成知识图谱推理,同时提出了一个新的知识前缀适配器,将从知识图谱中提取到的向量化的结构知识注入到大模型中。在未来,作者将进一步探索基于大语言模型的复杂知识图谱推理,同时也将关注如何利用知识图谱使得大语言模型能够在知识感知的情况下完成更多下游任务比如问答、对话等。
03
Towards Effective Data-Free Knowledge Distillation via Diverse Diffusion Augmentation
基于多样扩散增广的高效无数据知识蒸馏
作者:
李睦铨1, 张东阳1,*, 何涛1, 解羞蕊1, 李元放2, 秦科1
单位:
电子科技大学1,莫纳什大学2
邮箱:
muquanli2023@std.uestc.edu.cn
dyzhang@uestc.edu.cn
tao.he01@hotmail.com
xiexiurui@uestc.edu.cn
yuanfang.li@monash.edu
qinke@uestc.edu.cn
论文:
https://dl.acm.org/doi/10.1145/3664647.3680711
代码:
https://github.com/SLGSP/DDA
发表会议:ACM MM 2024
*通讯作者
1.研究背景
随着深度学习模型规模的不断增大,模型压缩成为在资源受限环境中部署高性能模型的关键技术之一。其中,知识蒸馏通过将大规模、性能优异的“教师模型”知识迁移到轻量级“学生模型”上,实现了显著的模型压缩效果。然而,传统知识蒸馏方法依赖于原始训练数据,因数据获取成本高昂及隐私安全等问题在实际场景中往往难以满足需求。为此,无数据知识蒸馏(DFKD)方法应运而生,其核心思路是先合成伪数据,再利用此伪数据完成模型蒸馏。但现有无数据知识蒸馏方法往往面临以下两大挑战:一是合成数据多样性不足,难以覆盖原始数据的复杂分布;二是合成数据与真实数据存在分布偏移,影响学生模型的泛化能力。针对这两点,本文提出在无数据知识蒸馏流程中引入扩散模型进行自监督增强,同时结合余弦相似度过滤,以在保证数据多样性的同时维护伪数据的分布一致性和质量。
2.方法概述
本文提出了一种名为多样扩散增广(DDA)的新型无数据知识蒸馏框架,整体框图如图1所示,主要包括以下三个步骤:
1)伪数据合成
采用现有的模型反演技术利用教师模型的类别先验和BN层统计信息,通过优化随机噪声或生成器网络生成初步伪数据,同时引入对比学习增强伪数据在特征空间的区分度,以提高多样性。
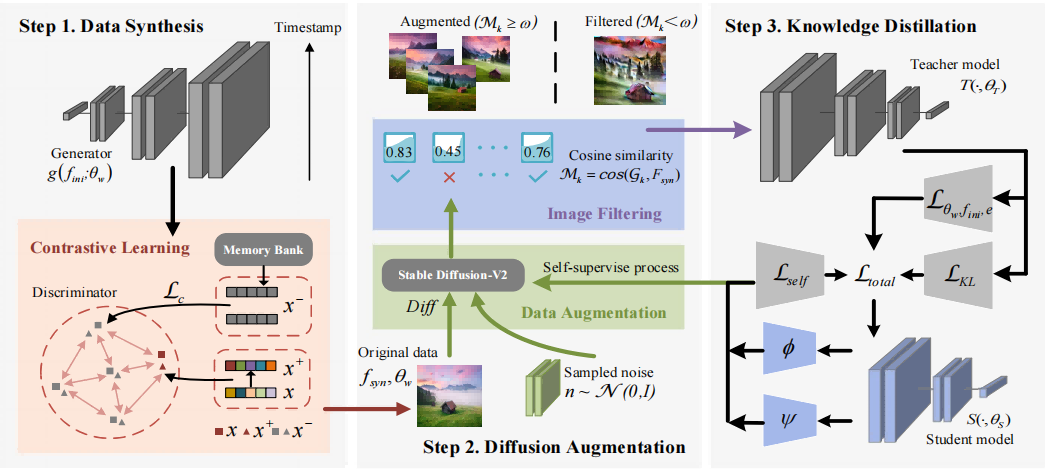
图1 多样扩散增广的整体框图
2)扩散自监督增强
将生成的伪数据输入到预训练的Stable Diffusion-V2扩散模型中,基于潜在特征进行多次扩散采样,得到一组语义一致但信息丰富多样的增强图像。为了避免扩散过程中的低质量样本干扰,使用余弦相似度对每张增强图像与原伪数据在像素级或特征级空间进行相似度计算,只有相似度高于阈值(实验证明取0.75效果最佳)者才被保留。扩散效果如图2所示。

图2 多样扩散增广的效果展示
3)知识蒸馏
最终,将过滤后的增强图像喂入学生模型,通过KL散度损失和特征映射损失等约束,使学生模型模仿教师模型的输出分布;同时,将学生模型在自监督分类任务上的交叉熵损失并入整体损失中,形成一种类似对抗的自适应增强策略,加速学生模型对伪数据语义的学习。
3.实验设计与结果
我们在CIFAR-10、CIFAR-100和Tiny-ImageNet三个常用数据集上,选取多种教师-学生网络对进行评估,比较了多种基线方法与DDA的性能差异。如图3所示,在CIFAR-10上,DDA平均提升了0.5%–2.0%的测试精度;在CIFAR-100和Tiny-ImageNet上,同样取得了显著的优越性。
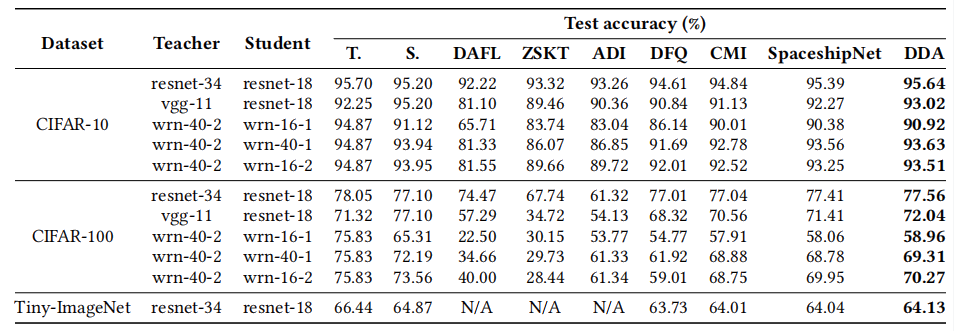
图3 DDA与相关基线测试准确率对比
图4展示了CIFAR-10上不同方法生成的知识蒸馏伪数据。与ADI、CMI和SpaceshipNet相比,DDA合成的图像在保持类别可辨性的同时,更加清晰且多样,有助于学生模型学习更全面的特征表示。

图4DDA与相关基线合成图像对比
我们还对扩散步数、指导系数、余弦相似度阈值等超参数进行了系统性探究,图5和图6的结果表明:当扩散步数为50、指导系数为0.5时,生成图像质量与多样性最优;余弦相似度阈值在0.75左右时可在多样性和保真度间取得最佳平衡。
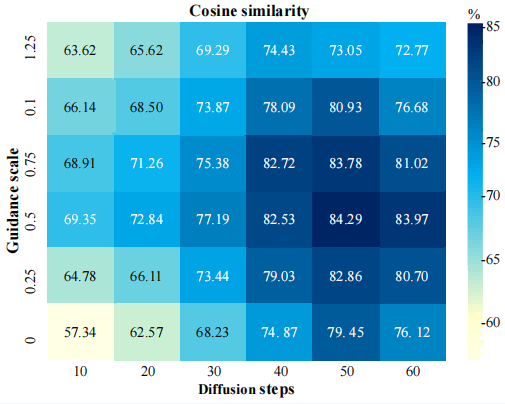
图5 扩散步数和指导系数的消融实验结果
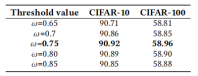
图6 余弦相似度阈值的消融实验结果
04
Sparse Query Dense: Enhancing 3D Object Detection with Pseudo Points
作者:
莫宇剑1,武妍1,*,赵君峤1,侯振杰2,黄伟泉1,户英豪1,王济君1,严俊3
单位:
1同济大学 计算机科学与技术学院
2常州大学 计算机与人工智能学院
3同济大学 电子与信息工程学院
邮箱:
yujmo@qq.com
yanwu@tongji.edu.cn
zhaojunqiao@tongji.edu.cn
houzj@cczu.edu.cn
weiquanh@tongij.edu.cn
2233024@tongji.edu.cn
2332118@tongji.edu.cn
yanjun@tongji.edu.cn
论文:
https://dl.acm.org/doi/10.1145/3664647.3681420
代码:
https://github.com/yujmo/SQDNet
发表会议:
ACM MM 2024
*通讯作者
1.问题引出
由于激光雷达(LiDAR)具备高精度的距离测量能力,且对光照变化不敏感,能够适应多种光照条件,因此在3D目标检测等领域被广泛应用。LiDAR传感器接收到的远程物体表面的测量值较少,而RGB传感器却能捕获到数百个像素信息。于是,一个常见的做法就是:把图像上的像素点转换成“伪点(Pseudo Point)”,以丰富LiDAR点云。
然而,由于伪点数量庞大,预处理过程往往计算开销大且效率低。同时,由深度补全网络估计得到的伪点并不总是准确,它们常常无法真实还原物体表面的局部细节,特别是在边缘区域容易引入显著的噪声,反而影响了检测性能。
2.方法概述
图1展示了模型的整体结构,其中包含两个核心模块:(1)SQD模块(Sparse Query Dense),该模块通过稀疏的LiDAR点来高效地采样稠密的伪点,增强远距离物体表面的结构表达;(2)3D Backbone,用来提取体素的特征,并引入大核卷积来扩大特征的Receptive Field,有效缓解伪点的局部结构模糊问题。
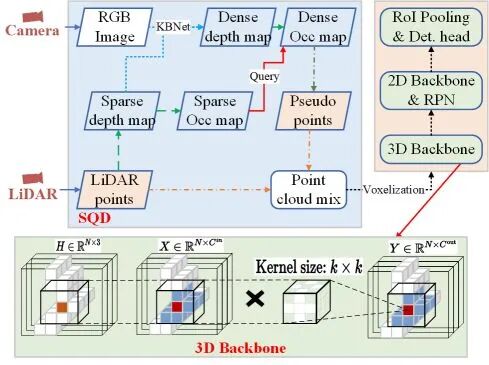
图1 基于稀疏查询稠密的3D目标检测模型结构图
图 2 进一步说明了SQD模块的流程。首先,将稀疏的LiDAR点与稠密的伪点分别投影到二维占用栅格图上,生成稀疏占用图与稠密占用图。基于栅格位置的索引关系,SQD实现了高效的稀疏到稠密的匹配。
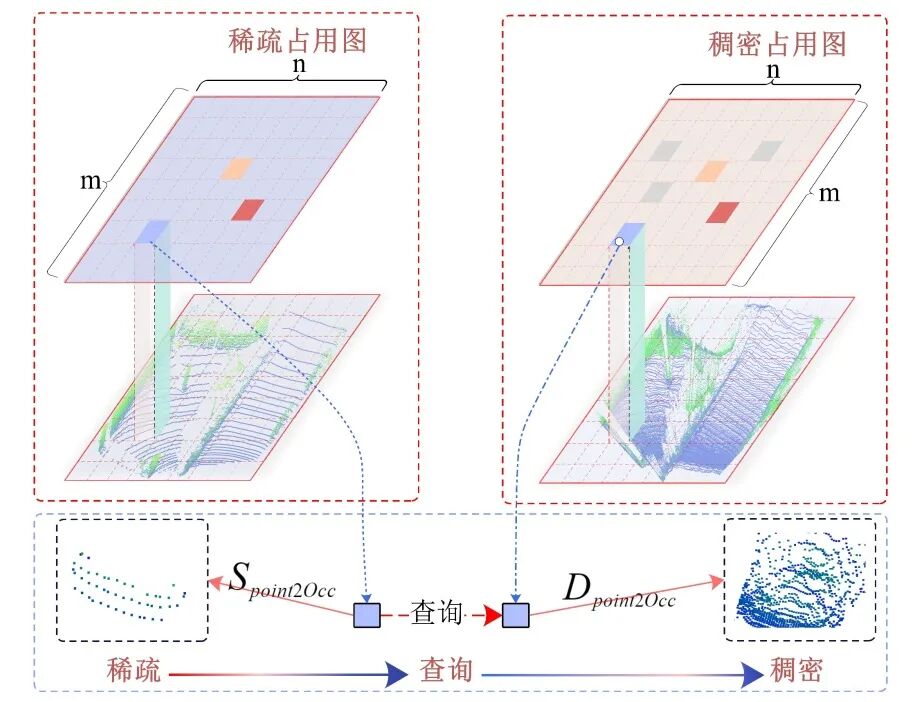
图2 SQD的流程图
具体而言,SQD根据稀疏占用图中每个栅格内的LiDAR点数量,决定是否采样对应位置的伪点。当某个栅格内没有LiDAR点但存在伪点时,这些伪点被视为可能的边缘噪声,全部舍弃。因为LiDAR和伪点应在结构上保持一致,缺乏LiDAR支持的伪点通常是不可靠的。
相反地,当某个栅格内LiDAR点密度较高时,SQD对相应位置的伪点将进行随机采样以减少冗余。而在LiDAR点密度较低但非零的栅格中,为保留潜在的补充信息,SQD将保留该位置的全部伪点。
3.实验结果
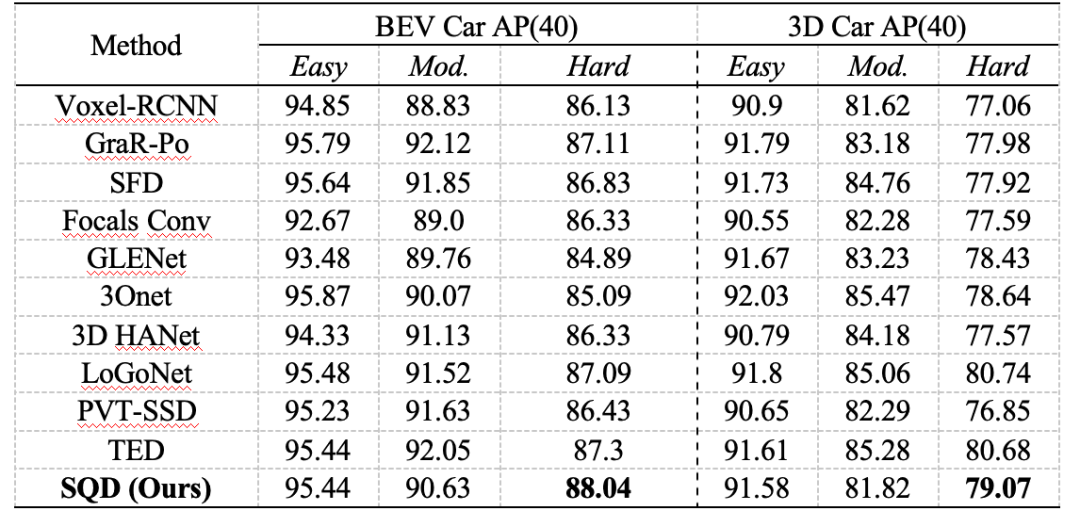
表 1展示了SQDNet在KITTI测试集上针对Car类别的3D检测性能。
表1 Car类别的检测性能
我们将个点采样至个点,并比较各方法的采样时间,结果如表 2。
表2 不同方法的采样时间对比
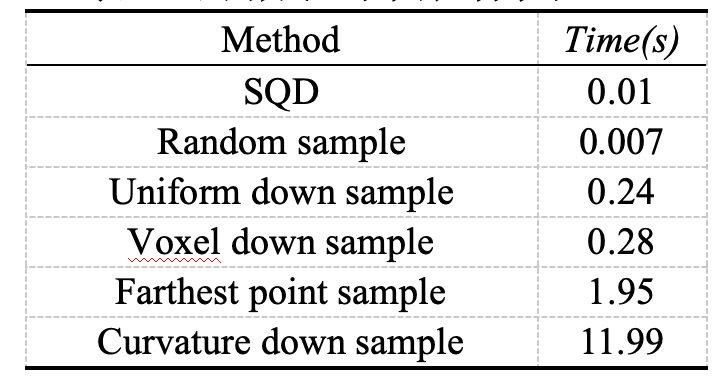
图 3展示了不同距离GT框中LiDAR点与伪点的平均数量,反映出两者在密度上的显著差异。通过SQD补充伪点,可有效提升GT内的点云密度。
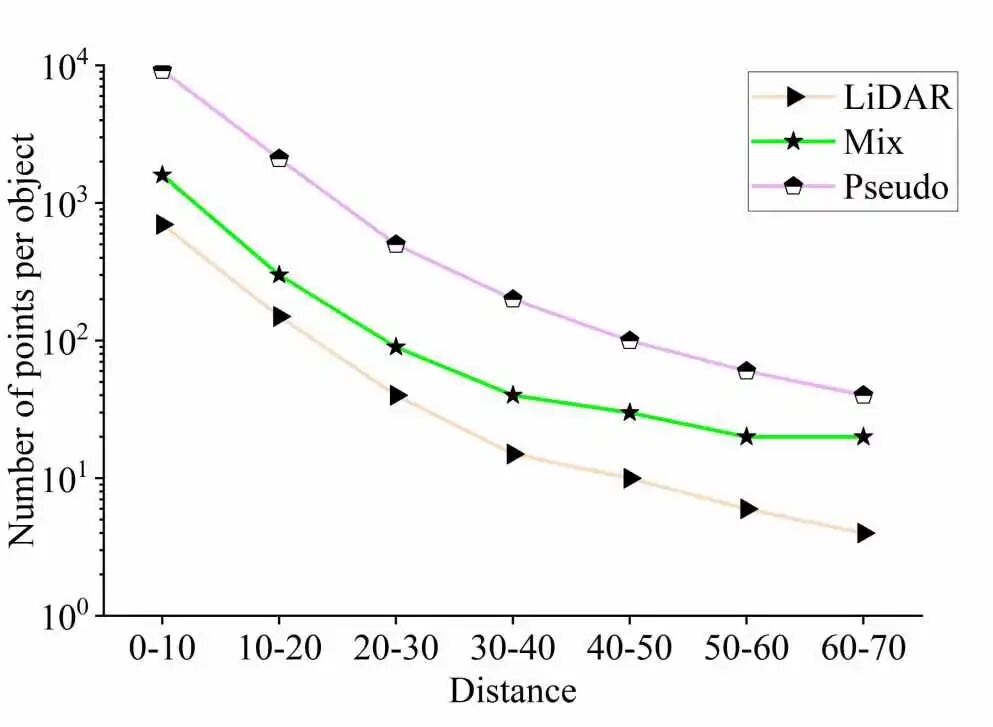
图3 不同距离GT框中LiDAR点、伪点及混合点的平均数
图 4显示,SQD能有效填补目标表面LiDAR点稀疏的区域。对于如 Car2这类存在遮挡的目标,SQD无法补全被遮挡区域的点云。Car2的俯视图中可见两个明显的空白区域,这是由于图像中的遮挡也反映在深度图中,导致无法生成伪点。
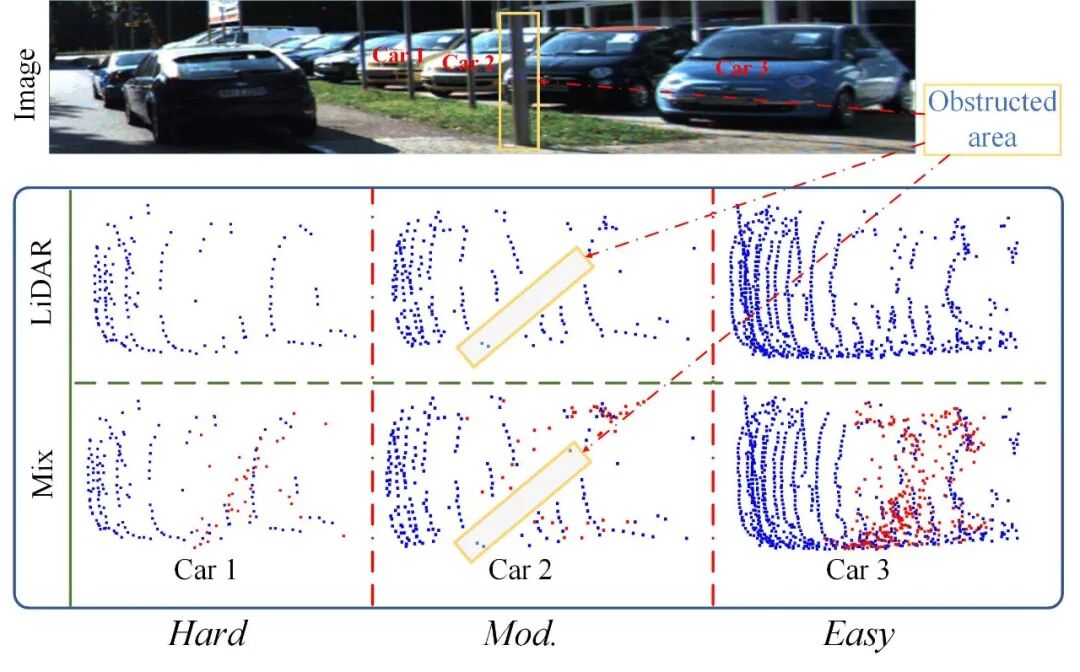
图4 定性分析
4.待解决问题
未来可在以下方向进一步探索:一是减少对超参数的人工依赖,使伪点查询与筛选更为灵活高效;二是将SQD策略从车辆扩展至类别,以提升模型在多样化场景下的适应能力。此外,提升遮挡区域的伪点补全效果也是关键挑战之一。在更具挑战性的数据集上进一步验证方法的鲁棒性。
05
Leveraging Knowledge of Modality Experts for Incomplete Multimodal Learning
利用模态专家的知识进行不完整多模态学习
作者:
许文鑫¹,江河欣²,梁雪峰²*
单位:
1西安电子科技大学广州研究院
2西安电子科技大学人工智能学院
邮箱:
xliang@xidian.edu.cn
hxjiang@stu.xidian.edu.cn
xliang@xidian.edu.cn
代码:
https://yxg1005.github.io/weight-prediction
发表会议:ACM MM 2024
*通讯作者
1.研究背景
在真实场景中,情感识别往往面临音频、文本、视觉模态缺失的情况,例如传感器损坏或隐私屏蔽。这给依赖完整多模态信息的传统模型带来了巨大挑战。现有方法多通过编码器–解码器框架学习跨模态联合表征,并利用重构损失来约束表示一致性,但往往忽视了单模态自身的判别能力,导致在模态缺失的场景下性能不佳,特别是在“只剩一个模态”的极端条件下性能急剧下降。
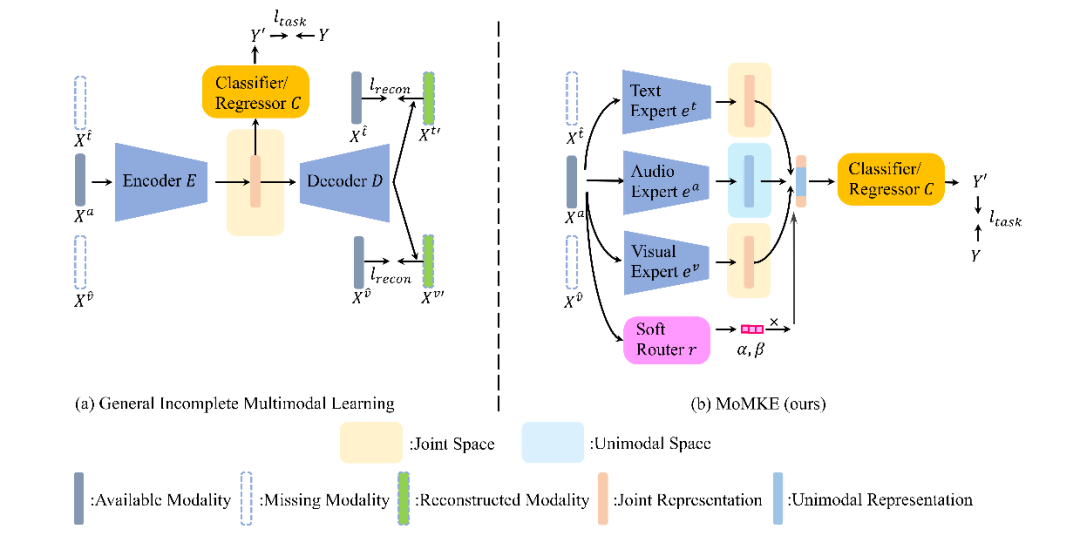
图1 传统不完整多模态学习的范式与提出的MOMKE范式比较
2.方法概述
针对这一痛点,我们提出 MoMKE(Mixture of Modality Knowledge Experts) 框架,以“两阶段训练 + 软路由”策略融合单模态表征与联合模态表征。
1) 第一阶段Unimodal Expert Training:为每个模态预训练一个Transformer专家,三个模态专家各自独立训练到收敛,最终得到三份“单模态知识库”。这一阶段的训练可以确保每个模态专家对其特定的模态具备较强判别能力。
2) 第二阶段Experts Mixing Training:对于每一个模态,利用所有模态专家对输入进行编码。利用本模态专家编码的表征为单模态表征,利用其他模态专家编码的表征为联合表征,并通过Soft Router根据样本动态分配权重,实现单模态表征与联合表征的自适应融合。该机制既保持了模态缺失场景下的鲁棒性,又能在信息完整时充分发挥多模态互补优势。
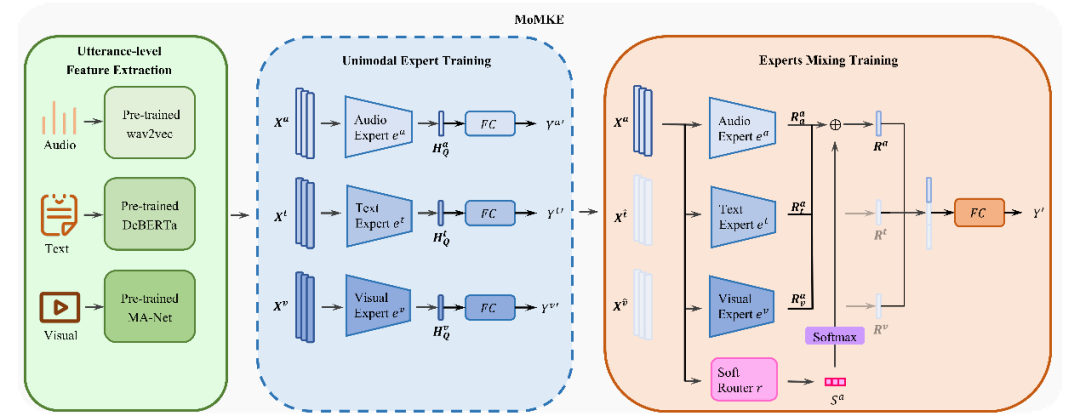
图2 MoMKE的整体框架
针对这一痛点,我们提出 MoMKE(Mixture of Modality Knowledge Experts) 框架,以“两阶段训练 + 软路由”策略融合单模态表征与联合模态表征。
1) 第一阶段Unimodal Expert Training:为每个模态预训练一个Transformer专家,三个模态专家各自独立训练到收敛,最终得到三份“单模态知识库”。这一阶段的训练可以确保每个模态专家对其特定的模态具备较强判别能力。
2) 第二阶段Experts Mixing Training:对于每一个模态,利用所有模态专家对输入进行编码。利用本模态专家编码的表征为单模态表征,利用其他模态专家编码的表征为联合表征,并通过Soft Router根据样本动态分配权重,实现单模态表征与联合表征的自适应融合。该机制既保持了模态缺失场景下的鲁棒性,又能在信息完整时充分发挥多模态互补优势。
3.实验结果
我们在IEMOCAP、CMU MOSI、CMU MOSEI三个基准数据集的6种缺模态组合上进行了实验。以IEMOCAP为例,当仅有音频 / 文本 / 视觉 时,MoMKE 的准确率分别提升 13.74% / 10.80% / 5.37%,大幅刷新当前最佳结果;在任何双模态或完全多模态设置下亦保持领先。
表3 在所有可能的不完整多模态测试条件下,在三个基准数据集上与SOTA方法的对比
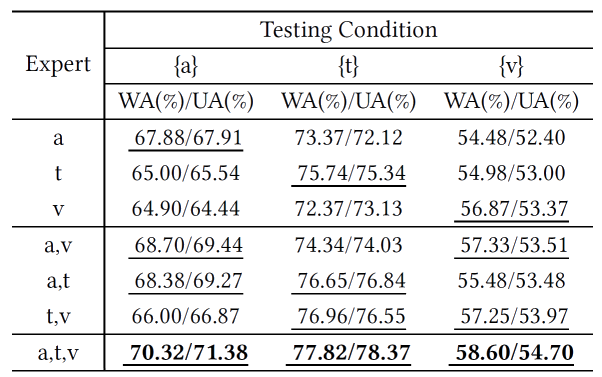
专家消融实验分两组:使用对应可用模态专家(带下划线)和未使用(无下划线)。结果表明使用对应专家的模型性能更优,验证了严重模态缺失场景下单模态表征的关键作用。同时,在单模态表征的基础上融合更多专家知识,性能更优。
表4专家消融实验
我们对Experts Mixing Training阶段训练过程中测试集的专家负载(即由 Soft Router 为每个模态专家分配的权重)进行了可视化。随着训练的进行,模型逐渐收敛,专家负载趋于稳定。结果表明,模型往往更依赖相应的单模态表示,这些表示包含更多模态特有的判别信息。
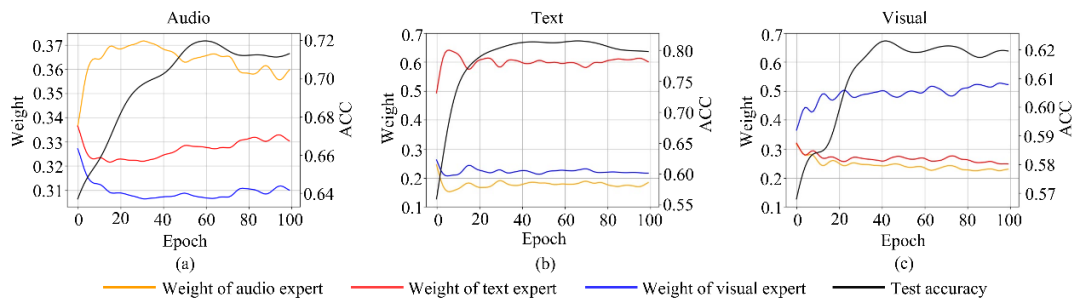
图5 Experts Mixing Training阶段的专家负载可视化

编辑人:吴建龙、任文琦
专委会责任副主任:张勇东
 京公网安备11010802017125号
京公网安备11010802017125号