
【论文导读】2025年论文导读第十六期
【论文导读】2025年论文导读第十六期
2025年9月2日 15:17 北京


论文导读
2025年论文导读第十六期(总第一百三十三期)
目 录
|
1 |
Dual-path Collaborative Generation Network for Emotional Video Captioning |
|
2 |
Bridging Visual Affective Gap: Borrowing Textual Knowledge by Learning from Noisy Image-Text Pairs |
|
3 |
Temporal Enhancement for Video Affective Content Analysis |
|
4 |
IBMEA: Exploring Variational Information Bottleneck for Multi-modal Entity Alignment |
|
5 |
Masked Snake Attention for Fundus Image Restoration with Vessel Preservation |
01
Dual-path Collaborative Generation Network for Emotional Video Captioning
作者:
Cheng Ye , Weidong Chen* , Jingyu Li , Lei Zhang , Zhendong Mao
单位:
中国科学技术大学
邮箱:
kyrieye@mail.ustc.edu.cn
chenweidong@ustc.edu.cn
jingyuli@mail.ustc.edu.cn
leizh23@ustc.edu.cn
zdmao@ustc.edu.cn
论文:
https://doi.org/10.1145/3664647.3681603
发表会议:
ACM MM2024
*通讯作者
1.研究背景
情感视频字幕生成(Emotional Video Captioning,EVC)任务旨在生成既能描述视频事实内容,又能传达视频情感的字幕。传统的视频字幕生成方法主要关注事实信息,忽略了视频中的情感变化。然而,EVC不仅需要理解视频内容,还需要捕捉情感的动态变化。现有的EVC方法多依赖全局情感感知,但未能有效捕捉情感的细微变化,导致字幕生成缺乏情感的准确表达。为此,本文提出了一种“双路径协同生成网络”(Dual-path Collaborative Generation Network,DCGN),通过动态感知情感演化,并平衡情感与事实内容的生成,提升了字幕的情感表达能力。
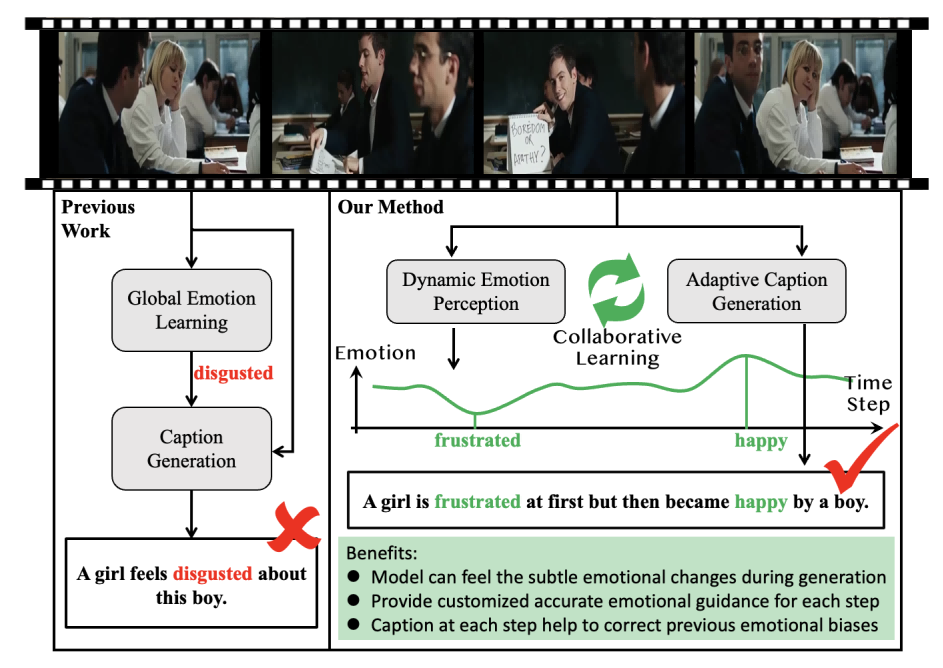
图1 双路径协同生成网络的应用
2.方法概述
本文提出的“双路径协同生成网络”主要由两个路径组成:动态情感感知路径和自适应字幕生成路径。具体架构如图2所示。
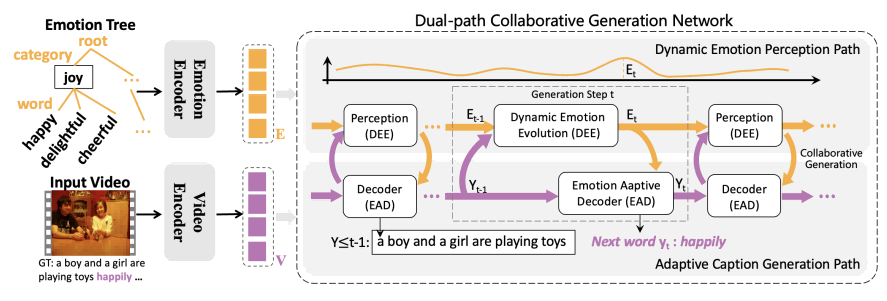
图2 双路径协同生成网络概述
在动态情感感知路径中,本文提出一个动态情感演化模块,该模块汇总视觉特征和历史字幕特征,总结全局视觉情感线索,然后动态选择必要的情感线索,并在每个阶段重新组合这些线索,从而动态增强或抑制不同粒度子空间的语义。因此,动态情感感知不仅能够修正前一阶段的情感偏差,确保在适当时刻生成正确的情感相关词汇,还能够适应真实世界中情感的动态变化,为每个生成步骤提供最准确的情感指导。
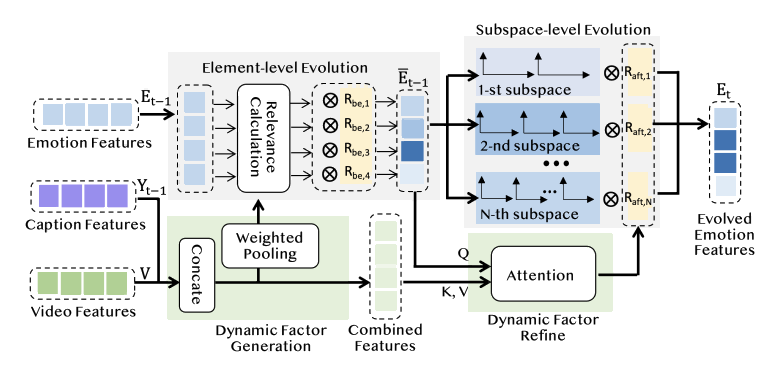
图3 动态情感感知模块框架
在自适应字幕生成的路径中,本文设计了一个情感自适应解码器。该解码器首先通过对感知到的情感演变与历史字幕特征的对齐,估计当前生成步骤的情感强度。如果感知到的演变情感与历史字幕特征相符时,才会在这一步生成情感相关词汇。此外,基于估算的情感强度,解码器自适应地将感知到的情感融入字幕生成过程中。因此,该模块能够在必要的生成步骤中准确感知并表达情感,避免偏重情感或事实内容,从而自适应地生成与情感相关的多样化词汇,使生成的字幕更加生动和丰富。
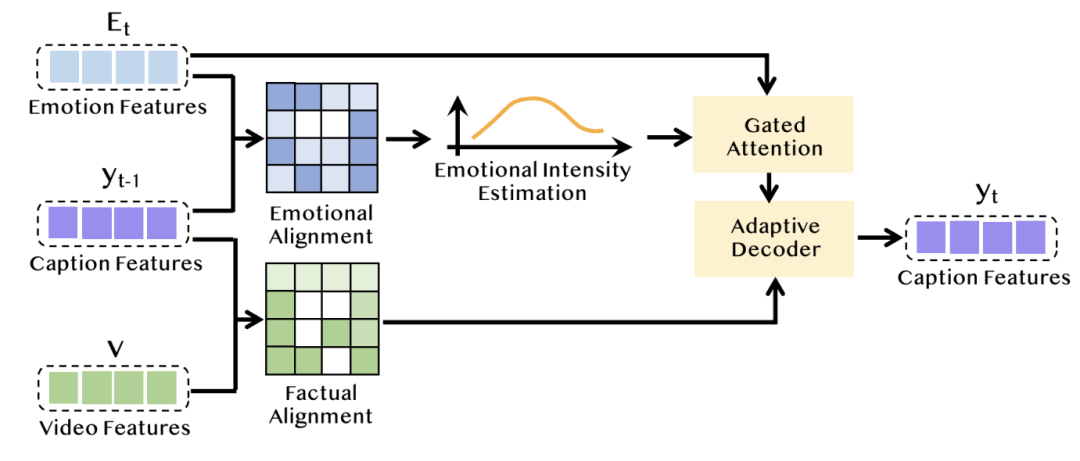
图4 情感自适应解码器框架
3.实验结果
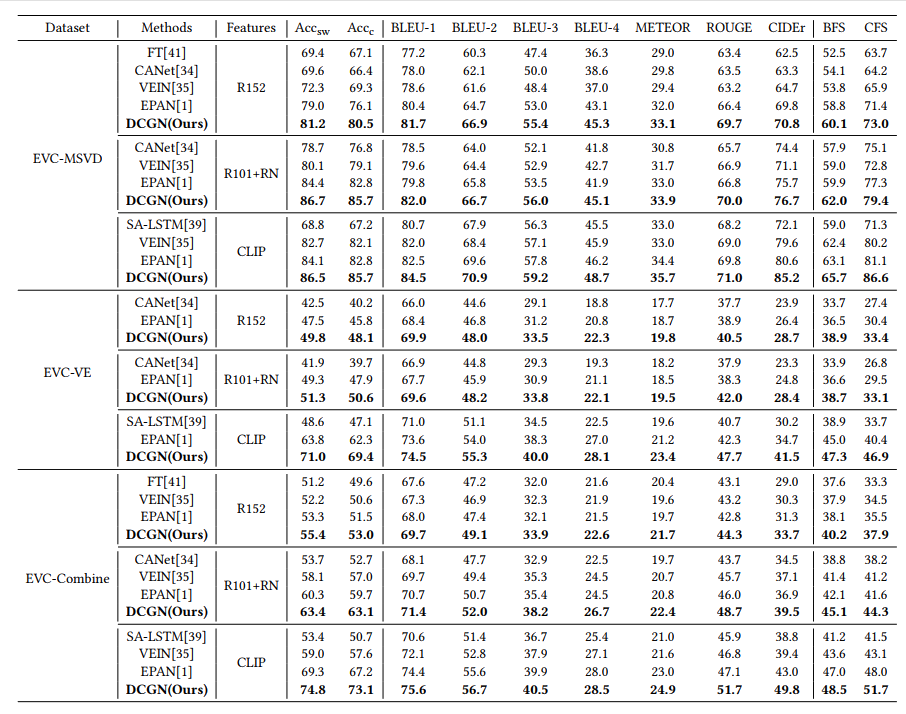
在三个公共数据集(如EVC-MSVD、EVC-VE和EVC-Combined)上的实验展示了本框架的优越性,例如,在EVC-VE数据集上,分别在情感准确度、CIDEr和CFS指标上提高了最新记录的+7.2%、+6.8%和+6.5%。具体结果见表1。
表1 在三个数据集中的结果对比
本文还对DCGN设计了两个角度的消融实验:(1)双路径消融实验;(2)元素级别和子空间级别的情感进化消融实验。证明了各个模块的有效性和必要性。
表2 双路径消融实验(A:动态情感感知路径 B:自适应字幕生成路径)
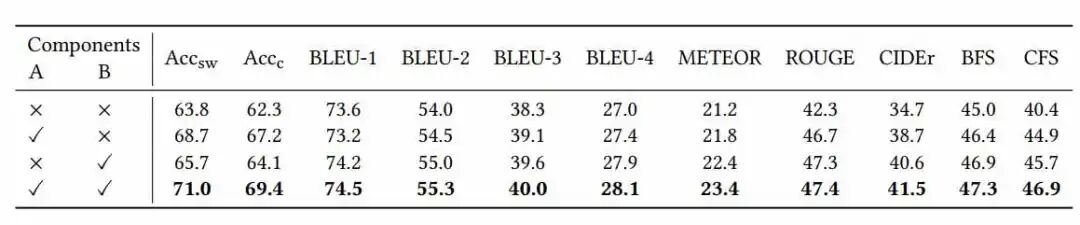
表3 元素级别和子空间级别的情感进化消融实验

此外,还将DCGN与目前先进的EPAN方法进行比较,如图5所示,证明本文的方法能更敏锐察觉视频情感的变化。为验证本方法的泛化能力,将本方法应用于情感图像字幕生成任务,证明了DCGN不仅适用于视频任务,在图像任务中也能表现出较好的情感感知和生成能力。
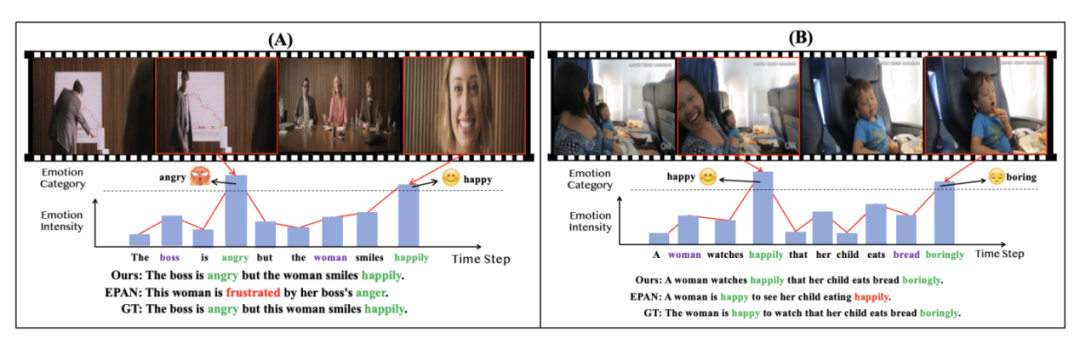
图5 DCGN vs. EPAN 效果可视化
4.总结
本文提出了一种双路径协同生成网络,用于情感视频描述。该方法通过动态感知视觉情感线索的演变,在不同生成步骤中调整情感特征和强度,确保生成的情感描述更加准确和定制化。实验结果表明,所提方法在多个数据集上优于现有技术,具有较强的优势。
02
Bridging Visual Affective Gap: Borrowing Textual Knowledge by Learning from Noisy Image-Text Pairs
作者:
吴岱卿1,2,杨东宝1,*,周宇3,马灿1,*
单位:
1中国科学院信息工程研究所
2中国科学院大学网络空间安全学院
3南开大学
邮箱:
wudaiqing@iie.ac.cn
yangdongbao@iie.ac.cn
论文:
https://dl.acm.org/doi/abs/10.1145/3664647.3680875
发表会议:ACM MM 2024
*共同通讯作者
1.研究背景
视觉情感识别(Visual Emotion Recognition, VER)是近年来迅速发展的研究领域,它旨在让计算机理解图像所传达的情绪。然而,现有的大规模视觉预训练模型主要专注于事实层面的语义特征提取,缺乏对情感维度的建模能力。这种认知层面的断层被称为“情感鸿沟(Affective Gap)”。相比之下,语言作为一种表达情感的天然媒介,拥有更高的信息密度和显式的情绪表达能力。基于这一观察,本文提出了一种全新的思路——通过学习图文对之间的事实与情绪联系,让视觉模型具备感知情绪的能力,从而跨越“情感鸿沟”。
2.方法概述
为实现上述目标,本文提出了PACL(Partitioned Adaptive Contrastive Learning)方法,借助社交媒体中天然存在的大量图文配对数据,自动构建学习目标。
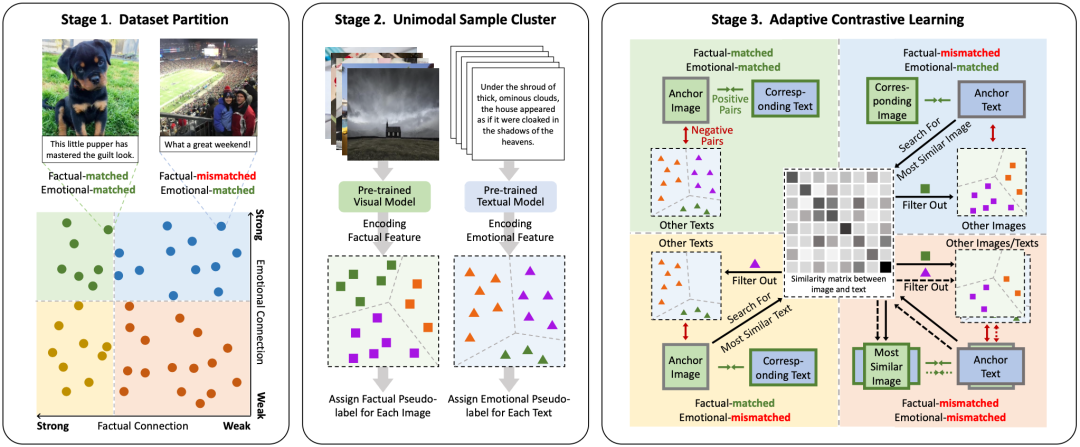
图1 PACL的整体流程
PACL整体流程如上图所示,包含三个阶段:
1)第一阶段:图文样本划分
我们基于预训练模型评估图文对之间的事实一致性与情绪一致性,将样本划分为四类:强耦合样本:图文高度匹配,既语义一致也情绪一致;部分耦合样本:语义或情绪一致,但另一维度不匹配;弱耦合样本:图文关系混乱,均不一致。这种划分允许我们对不同类型样本设计有针对性的学习策略,充分利用数据中蕴含的噪声结构。
2)第二阶段:单模态伪标签聚类
在图像和文本各自的预训练编码器中,我们进行K-Means聚类,获取伪标签,分别描述图像间的事实相似性、文本间的情绪相似性。这些标签在后续对比学习中作为构建“正负样本对”的判断依据,从而使学习更加可靠。
3)第三阶段:自适应对比学习
在对比学习阶段,我们根据样本类型和伪标签信息,动态构建“图-文正对”与“图-文负对”:对于强耦合样本,直接使用原始配对;对于部分/弱耦合样本,则过滤掉可能导致误导的负样本,或重构正样本。这一过程显著增强了视觉模型从文本中学习情绪特征的能力,并避免“噪声数据”带来的负面影响。
3.实验结果
本文在六个主流视觉情感识别数据集上验证了PACL的有效性,涵盖不同标签形式(单标签、多标签、层级标签)与情绪理论(基本情绪、维度模型),并使用四种预训练视觉模型(ResNet-50、ViT-base、Swin-base、ViT-clip)进行测试,结果表明:PACL在大多数任务和模型设定下都实现了显著性能提升。
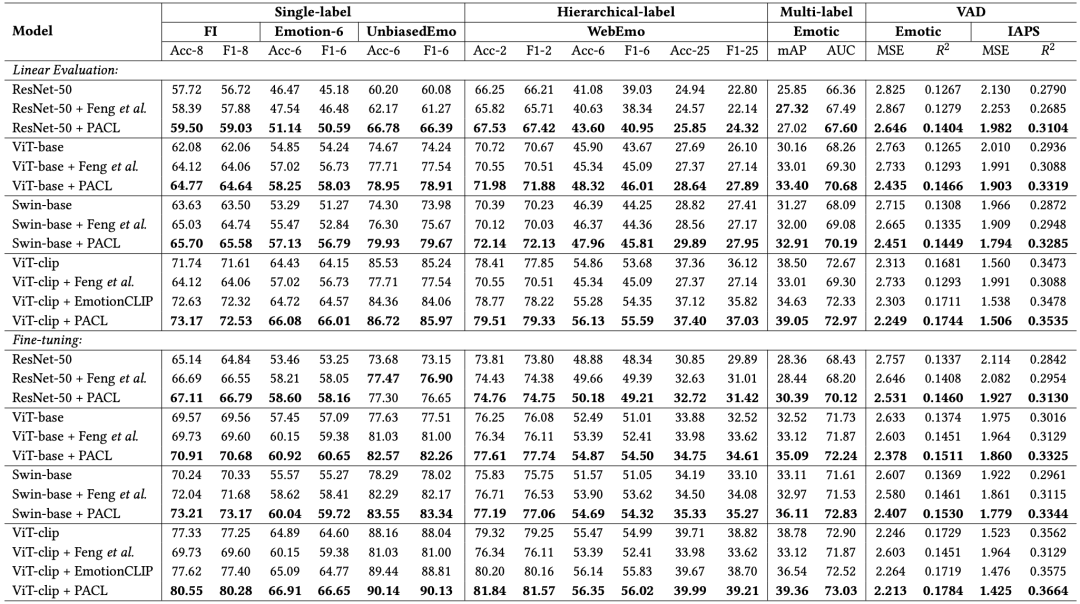
图2 PACL与相关基线在多种下游任务上的性能对比
本文还设计了详细的消融实验,验证了样本划分、伪标签聚类与对比学习策略的有效性。实验发现即使是“情感错配”或“事实错配”的噪声样本,在合理利用伪标签后也能显著增强模型性能。
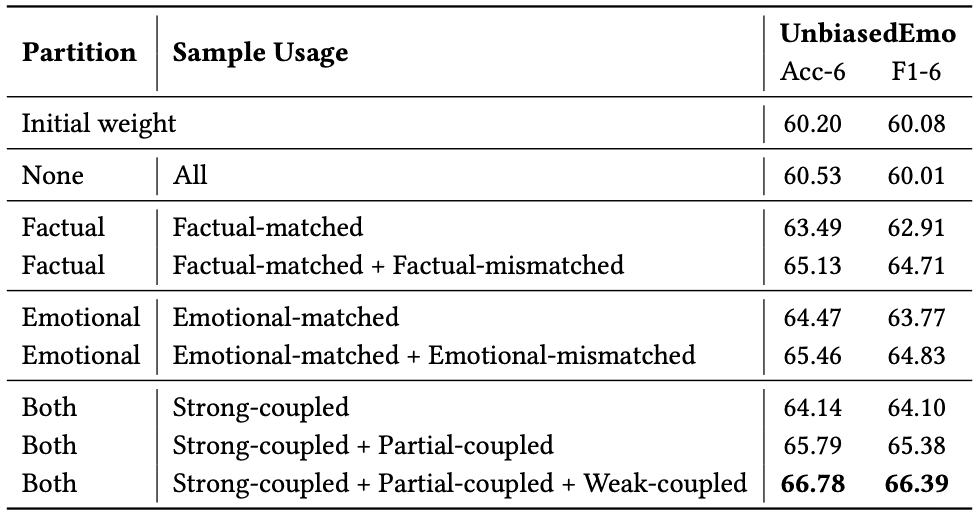
图3 不同样本划分策略下的性能对比
03
Temporal Enhancement for Video Affective Content Analysis
视频情感内容分析中的时序增强
作者:
李昕,王上飞*,黄晅东
单位:
中国科学技术大学 计算机科学技术学院
邮箱:
lixin514@mail.ustc.edu.cn
sfwang@ustc.edu.cn
xuandong@mail.ustc.edu.cn
论文:
https://dl.acm.org/doi/10.1145/3664647.3681631
发表会议:ACM MM 2024
*通讯作者
1.研究背景
视频情感内容分析旨在理解并预测视频创作者希望引发观众的情感。具体而言,该任务的输入为一段视频片段,预测分类后的情感类别,或愉悦度–唤醒度。其中可能存在两类噪声,其中包括: 1) 视频中出现与情感无关的冗余片段,2) 同一时间下不同模态之间的表达的情感不一致。其核心挑战在于如何捕捉与情感相关的时序表征。为此,本文提出了时空增强框架(Temporal Enhancement)增强模型对噪声的鲁棒性以及提高其检测和识别关键时间片段的能力。
2.方法概述
如图1所示,本文提出了一个名为时序增强(Temporal Enhancement) 的视频情感分析框架,旨在增强模型对冗余噪声的鲁棒性,并更好地捕捉关键的情感片段。其中,时空采样替代了传统的均匀间隔连续帧采样,能有效降低冗余和同质化信息,提高特征多样性,并帮助防止模型过拟合。跨模态时序增强模块整合同一时刻各模态的关键信息和互补信息,更好地关注跨模态共享的关键时序片段,同时抑制无关或噪声信息。
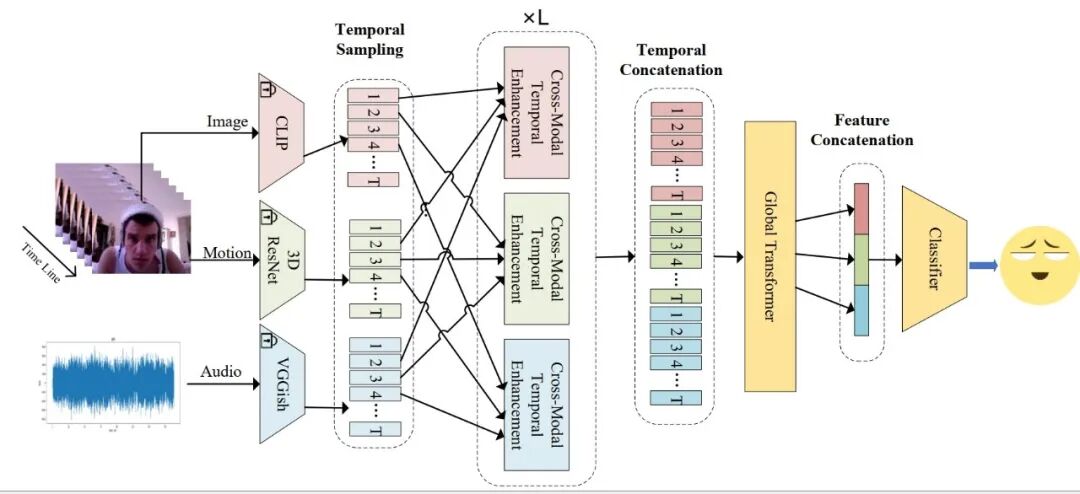
图1 Temporal Enhancement模型架构图
3.实验设计与结果
本文在分类和回归任务中多个数据集上进行了全面的实验,部分实验结果如表1,2,3所示:在YF-E6和VE-8的预测准确率上,本文方法在不使用额外辅助信息的情况相比最好的方法分别提高了3.79%和2.12%。在ME16上的大部分指标超过其他方法。在VAD中,本文的方法不仅增强了模型的性能,同时在分类中达到更好的平衡。
表1 在YF-E6和VE-8上的结果
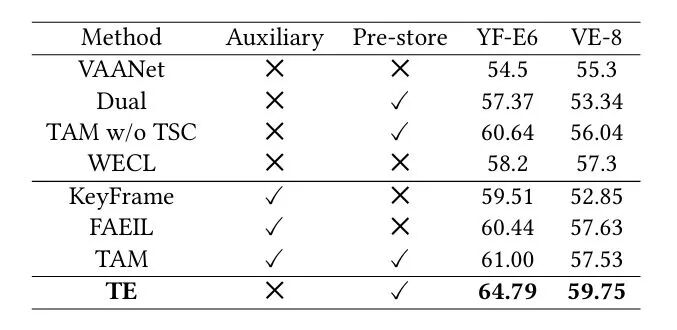
表2 在MediaEval2016上的结果
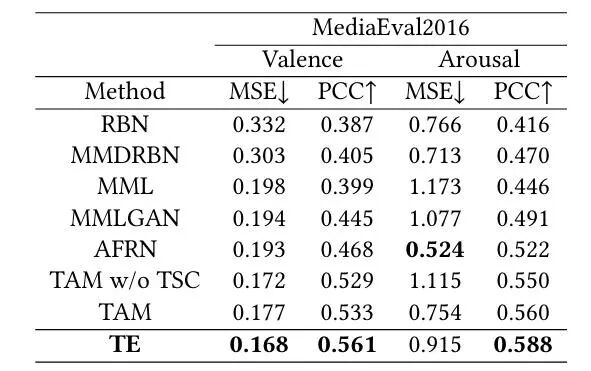
表3 在VAD上的结果
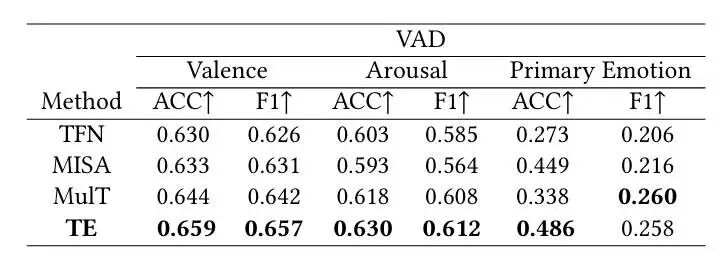
表4中消融实验结果表明,不同模块对模型性能的影响具有显著差异。其中,简单拼接(Simple Concatenate)由于缺乏深层次的模态交互,表现较差;而全局Transformer(Global Transformer)通过模态内和模态间的交互机制显著提升了模型性能。此外,我们提出的跨模态时序增强(Cross-modal Temporal Enhancement)进一步增强了单模态的表征能力,充分利用了多模态的互补优势。相比之下,独立模态交互(Independent Modal Interaction)由于限制了跨模态信息的整合,效果相对较差。这些结果验证了模态间深度交互对提升模型性能的重要性。
表4部分消融实验

04
IBMEA: Exploring Variational Information Bottleneck for Multi-modal Entity Alignment
视频情感内容分析中的时序增强
作者:
苏涛宇1,2,盛傢伟1,*,王士承1,2,张兴华1,2,许洪波1,柳厅文1,2
单位:
1中国科学院信息工程研究所
2中国科学院大学
邮箱:
sutaoyu@iie.ac.cn
shengjiawei@iie.ac.cn
wangshicheng@iie.ac.cn
zhangxinghua@iie.ac.cn
hbxu@iie.ac.cn
liutingwen@iie.ac.cn
论文:
https://dl.acm.org/doi/10.1145/3664647.3680954
代码:
https://github.com/sutaoyu/IBMEA
发表会议:
ACM MM 2024
*通讯作者
论文简介
多模态实体对齐(Multi-modal Entity Alignment, MMEA)旨在识别多模态知识图谱(Multi-modal Knowledge Graph, MMKG)之间的等效实体。通常多模态知识图谱中实体可以与相关图像相关联,从而提供多模态信息。现有的大多数研究严重依赖于自动学习的融合模块来整合多模态信息,很少明确地抑制多模态实体对齐过程中的冗余信息,而这种冗余信息涉及来自不同模态中与对齐无关的误导性线索,并且在低资源或高噪声数据场景中尤其普遍,从而阻碍模型预测能力。
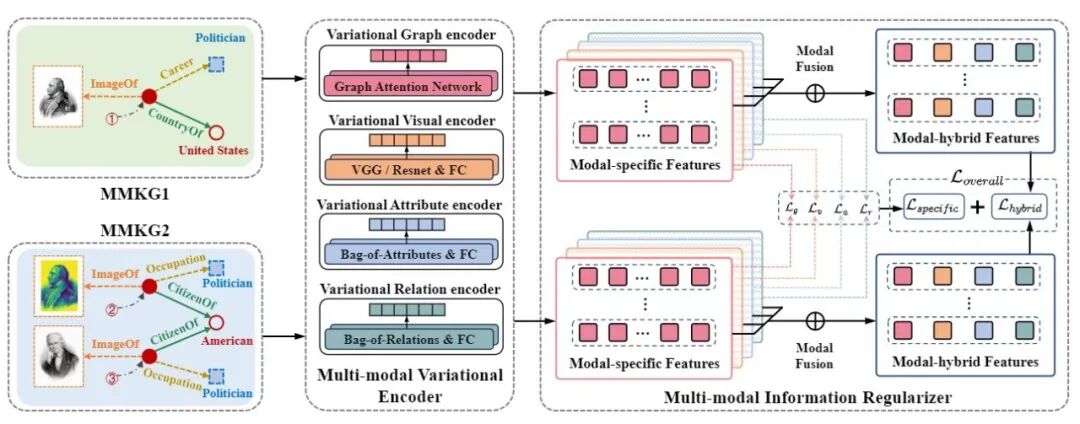
图1 基于变分信息瓶颈的多模态实体对齐方法框架图
为了解决这一问题,本文提出了一种全新的基于变分信息瓶颈的多模态实体对齐方法(IBMEA),框架图如图1所示,该方法在生成对应实体嵌入表示时重点关注对齐相关信息并抑制对齐无关信息。首先,本文设计了多模态变分编码器,以概率分布的形式生成特定模态的实体表征。然后,本文提出了四种特定模态信息瓶颈正则项,在完善特定模态实体表征时对误导线索进行限制。最后,本文通过提出的一种模态混合信息对比正则项,用于整合所有精细化的特定模态表征,增强不同多模态知识图谱上同一实体间的相似性,从而实现更高效的多模态实体对齐。
本文通过在2个跨域多模态知识图谱数据集和3个双语多模态知识图谱数据集上进行的大量实验结果表明,本文方法达到多模态实体对齐领域的先进水平,而且在低资源和高噪声数据场景下也表现出了良好的实体对齐稳健性。
05
Masked Snake Attention for Fundus Image Restoration with Vessel Preservation
作者:
丁小洹,龚杨锐,史天意,黄梓航,许刚伟,杨欣*
单位:
华中科技大学
邮箱:
dingxiaohuan@hust.edu.cn,
gongyangrui@hust.edu.cn,
d201980598@alumni.hust.edu.cn,
huangzihang@hust.edu.cn,
gwxu@hust.edu.cn,
xinyang2014@hust.edu.cn
论文:
https://dl.acm.org/doi/abs/10.1145/3664647.3680722
发表会议:ACM MM 2024
*通讯作者
1.研究背景
恢复低质量的眼底图像,尤其是血管结构的恢复,对临床观察和诊断至关重要。现有的最先进方法使用标准卷积和基于窗口的自注意力块来恢复低质量眼底图像,但这些特征计算方法与视网膜血管的细长和曲折结构不匹配,难以准确地恢复血管结构。为此,本文提出了一种新的低质量眼底图像恢复方法,称为掩码蛇形注意力网络(Masked Snake Attention Netowork, MSANet)。它是专门为准确恢复血管结构而设计的。具体来说,引入了蛇形注意力模块(Snake Attention, SA),以根据血管的形态结构自适应地聚合血管特征。由于图像中血管像素所占比例较小,本文进一步提出了掩码蛇形注意力模块(Masked Snake Attention, MSA),以更有效地捕捉血管特征。MSA 通过将蛇形注意力约束在分割方法预测的区域内来增强血管特征。
2.方法概述
为使网络关注目标的复杂几何特征,我们引入了可变形偏移。首先将输入特征图x通过线性投影获得查询向量 q=xWq,然后输入轻量化子网络生成偏移量,H、W和C分别表示解码器中特征图的高度、宽度和通道数。然而,考虑到血管的独特几何特征,为避免变形特征偏离血管。我们采用迭代策略,按顺序选择每个目标的后续观察位置,以确保变形特征的连续性。然后,在变形点的位置采样特征作为key和value,并应用投影矩阵:
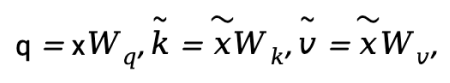
我们沿着x轴和y轴获取沿x轴的变形点,将垂直偏移相加以确保变形点的连续性,公式表示如下:
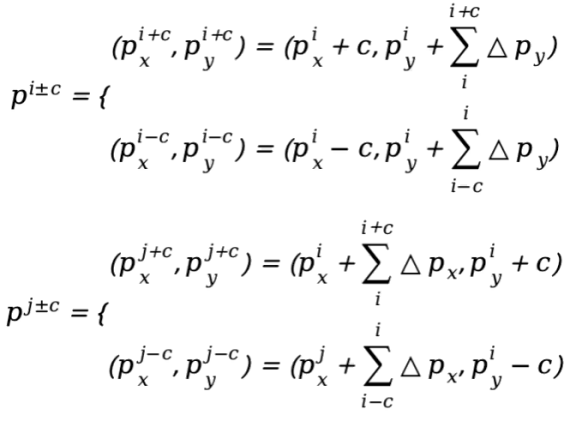
我们沿着x轴和y轴进行注意力操作。蛇形注意力的输出公式为:
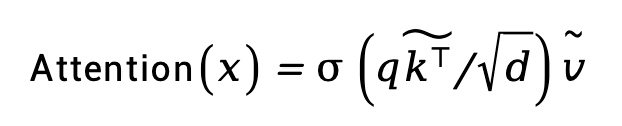
语义先验可以为提高增强性能提供丰富的信息,我们设计了掩码蛇形注意力模块(MSA),在掩码区域上应用蛇形注意力。我们选择传统的语义分割方法最优定向通量(OOF)来提供语义先验信息,而无需注释数据和训练时间成本。具体来说,如图1所示,我们使用在低质量眼底图像上预测的 OOF 掩码,根据预定义的阈值确定蛇形注意力的区域。基于预定义阈值,我们能够在查询特征位置获得注意力掩码M,其计算方式如下。我们定义M为通过OOF预测的血管分割掩码:
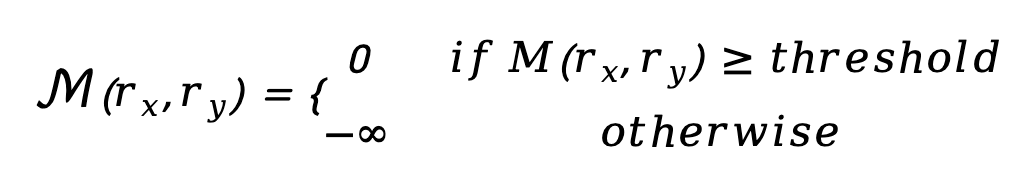
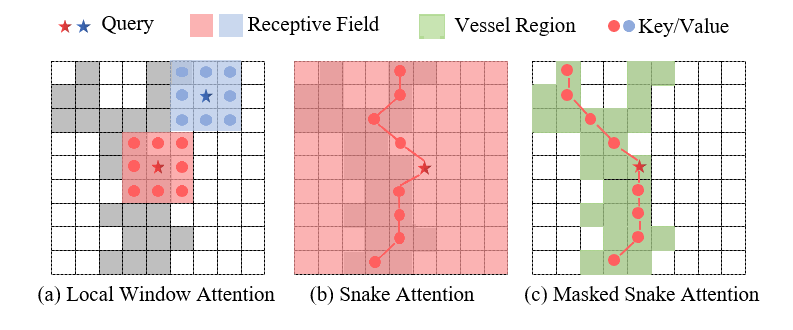
图1 掩膜蛇形注意力、蛇形注意力和局部窗口注意力的比较。红色和蓝色星号表示查询,红色和蓝色方块表示相应的感受野区域,绿色方块表示掩膜蛇形注意力中的查询所关注的血管区域。(a)局部窗口注意力旨在提取局部特征 (b)蛇形注意力能够基于血管结构自适应地捕获特征 (c)掩码蛇形注意力在掩码的指导下能够比蛇形注意力更精确地捕获血管特征
我们的基于掩码的蛇形注意力通过以下方式来计算注意力矩阵:
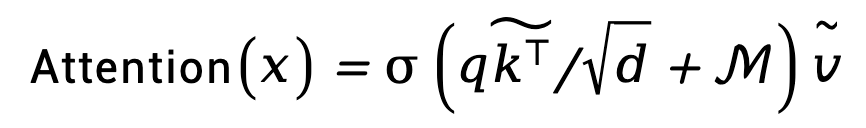
3.实验结果
我们通过低质量眼底图像增强任务和下游分割任务上的实验验证了所提出方法的有效性。
表1 MSANet与其他方法对比的定量评估
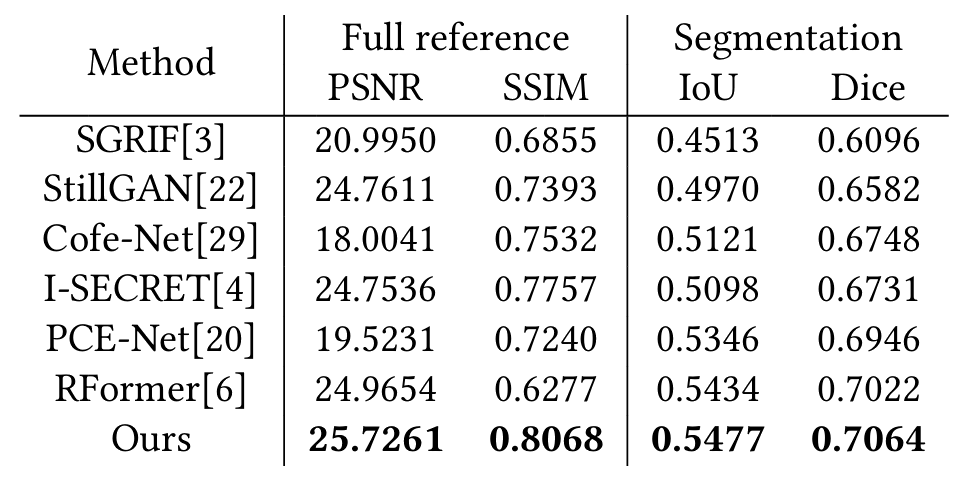
如表1所示,在低质量眼底图像恢复和下游分割任务上,我们提出的 MSANet 方法始终优于各种图像恢复方法。图 2 和图 3 分别提供了各种方法在低质量眼底图像恢复和下游分割任务评估中的视觉结果。

图2 RF数据集上的图像恢复结果可视化
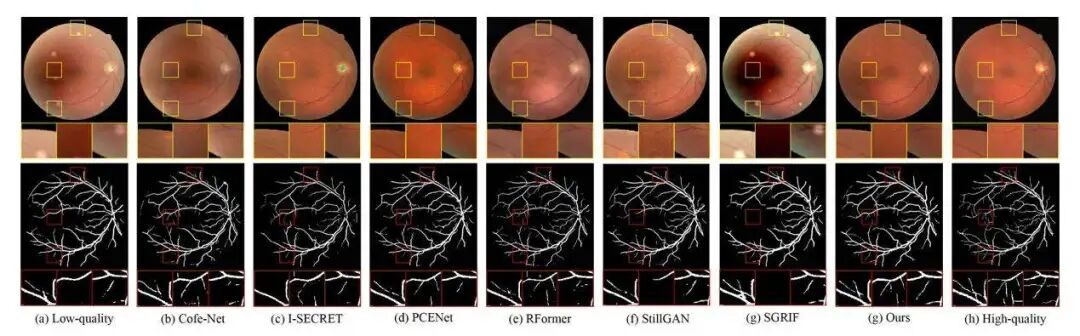
图3 DRIVE数据集上的图像恢复结果可视化。所有分割结果均由预训练的 U-Net 提供。

编辑人:吴建龙、任文琦
专委会责任副主任:张勇东
 京公网安备11010802017125号
京公网安备11010802017125号