
【论文导读】2025年论文导读第十七期
【论文导读】2025年论文导读第十七期
2025年9月23日 14:55 北京


论文导读
2025年论文导读第十七期(总第一百三十四期)
目 录
|
1 |
OneRef: Unified One-tower Expression Grounding and Segmentation with Mask Referring Modeling |
|
2 |
Cluster-Phys: Facial Clues Clustering Towards Efficient Remote Physiological Measurement |
|
3 |
VoxInstruct: Expressive human instruction-to-speech generation with unified multilingual codec language modelling |
|
4 |
CMT: Co-training Mean-Teacher for Unsupervised Domain Adaptation on 3D Object Detection |
|
5 |
Exploring in Extremely Dark: Low-Light Video Enhancement with Real Events |
01
OneRef: Unified One-tower Expression Grounding and Segmentation with Mask Referring Modeling
作者:
肖麟慧1,2,3,杨小汕1,2,3,彭芳1,2,3,王耀威2,4,徐常胜1,2,3,*
单位:
1 中国科学院自动化研究所多模态人工智能系统全国重点实验室
2 鹏城实验室
3 中国科学院大学人工智能学院
4 哈工大深圳
邮箱:
xiaolinhui16@mails.ucas.ac.cn
xiaoshan.yang@nlpr.ia.ac.cn
wangyw@pcl.ac.cn
csxu@nlpr.ia.ac.cn
论文:
https://proceedings.neurips.cc/paper_files/paper/2024/hash/fcd812a51b8f8d05cfea22e3c9c4b369-Abstract-Conference.html
发表会议:
NeurIPS 2024
*通讯作者
1.研究背景
现有的视觉定位和指代分割工作受到视觉和语言独立编码的限制,严重依赖于笨重的基于 Transformer 的融合编码器/解码器和各种早期阶段的交互技术。同时,当前的掩码视觉语言建模(mask visual language modeling,MVLM)在指代任务中无法捕捉图像-文本之间微妙的指代关系。在本文中,我们提出OneRef,一个极简的、建立在模态共享Transformer上的指代框架,其统一了视觉和语言特征空间。为了对指代关系进行建模,我们提出了一种新的MVLM范式,称为掩码指代建模(MRefM),它包括指代感知的掩码图像建模和指代感知的掩码语言建模。这两个模块不仅可以重构与模态相关的内容,还可以重建跨模态的指代内容。在MRefM中,我们提出一种指代感知的动态图像掩码策略,该策略可以感知指代区域,而不是依赖于固定掩码比率或通用的随机掩码方案。通过利用统一的视觉语言特征空间,并结合MRefM的建模指代关系的能力,我们的方法可以直接回归指代结果,而无需依赖于各种复杂的技术。我们的方法连续地超越现有的方法,在定位和分割任务上都达到了SoTA的性能,为未来的研究提供了新的有价值的思路。本文的数据集、代码和模型均已开源。
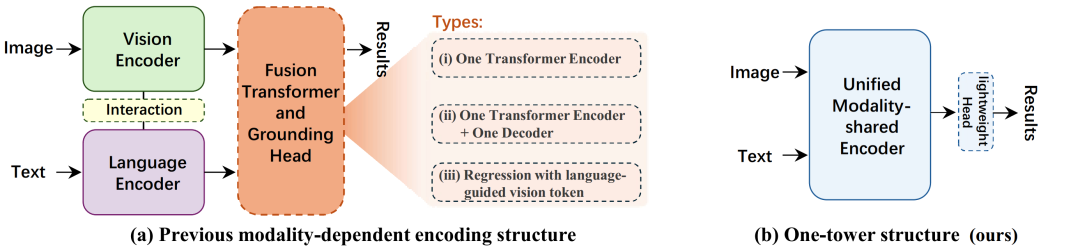
图1 我们提出的方法和主流的REC/RES架构的对比
2.方法概述
在本文中,我们提出了一种新的范式,称为掩码指代建模(MRefM),以及一种统一的、极其简洁的定位和指代分割框架,称为OneRef。这一框架不再需要融合或交互的Transformer结构,也不需要特殊的定位Token。
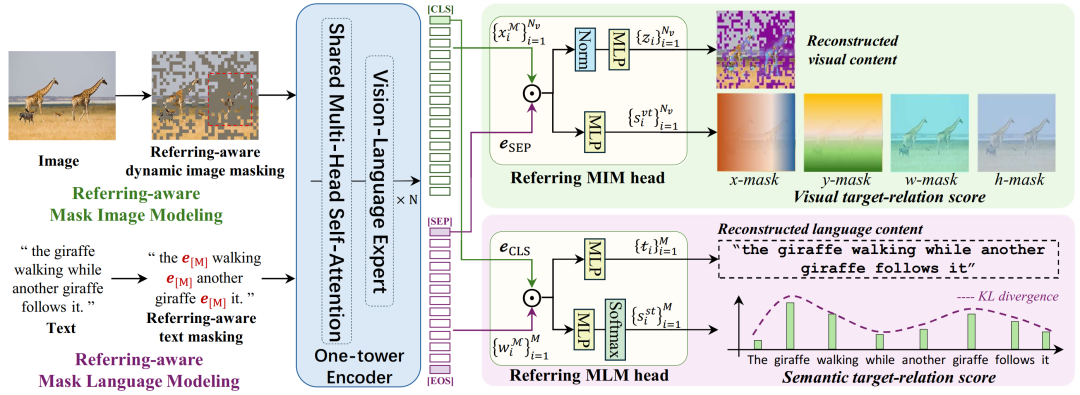
图2 我们提出的多模态的掩码指代建模(MRefM)范式的示意图
首先,我们提出MRefM范式,以灵活的方式增强BEiT-3的指代能力。MRefM由两个部分组成:指代感知的掩码图像建模(Referring-aware Mask Image Modeling,简称Referring MIM,指代MIM)和指代感知的掩码语言建模(Referring-aware Mask Language Modeling,简称Referring MLM,指代MLM)。传统的MVLM通常基于单模态MIM和MLM交替或随机训练来实现。相比之下,指代MIM和指代MLM需要重构两种不同类型的内容:与自身模态相关的内容和跨模态的指代信息。具体而言,(i) 指代MIM使用与聚合文本token进行点积运算之后的视觉token进行重建。其不仅需要重建本身掩码的视觉特征,还需要重建视觉目标关联分数,这一分数用以表示当前token与定位区域之间的距离。同时,得分包括四个维度:到定位中心的水平和垂直距离,以及定位区域的宽度和高度。为了提高模型对指代区域的理解能力,我们提出一种指代感知的动态图像掩码策略,取代传统的固定比例的随机掩码策略,以较高的掩码比例重建指代区域。(ii) 指代MLM使用与聚合的视觉token进行点积运算后的文本token进行重建。其不仅需要重建掩码文本本身,还需要重建表示当前文本token与指代图像区域之间相关性的语义目标关联分数。
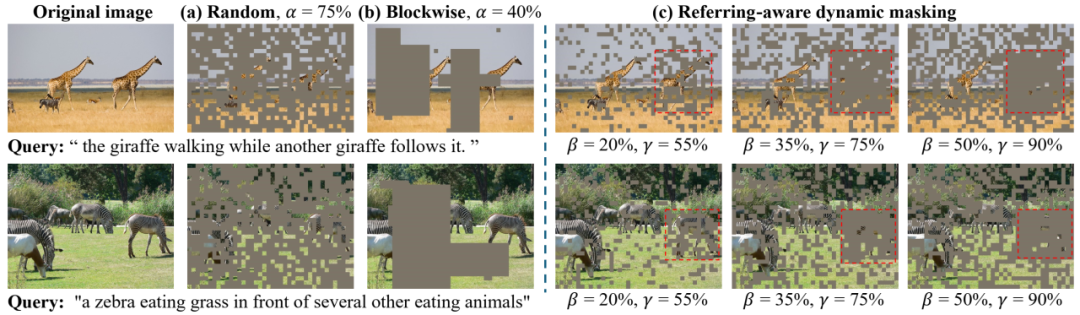
图3 随机掩码(MAE)、分块掩码(BEiT)和我们的基于指代的动态图像掩码的示意图
其次,现有的定位和分割模型通常使用[Region] token和多个查询锚等特殊的定位 token 来回归结果。然而,在主干网络中嵌入[Region] token会破坏预训练的模型,并且查询锚也依赖于额外的解码器。由于模态共享编码器建立了统一的特征空间,我们不再需要额外的跨模态的编码器/解码器来融合单模态特征,可以使我们能够更有效地利用预训练主干网络获得的知识。受益于MRefM范式,视觉token内在地包含了指代信息。因此,我们可以抛弃特殊的定位token或者查询anchor,直接在基于点积运算的指代MIM的基础上构建起轻量级且高度简洁的定位和分割任务头,从而实现了统一的指代框架。
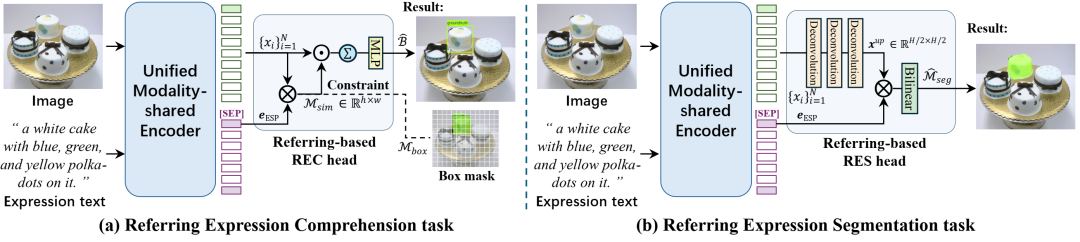
图4 基于指代的定位和分割迁移的实现示意图
我们的贡献有三个方面:
(i) 我们通过提出一种称为掩码指代建模的新范式,首次将掩码建模应用于指代任务。这种范式有效地建模了视觉和语言之间的指代关系。
(ii) 与以往的工作不同,我们提出了一个非常简洁的单塔框架,用于在统一的模态共享的特征空间中进行定位和指代分割。我们的模型消除了常用的模态交互模块、模态融合编码器/解码器和特殊的定位token。
(iii) 我们在三个指代任务、五个数据集上广泛的验证了MRefM的有效性。我们的方法不断地超越了现有的方法,并在多种设置下实现SoTA性能,为未来的定位和指代分割研究提供了有价值的新的思路。
3.实验结果
如表1、2所示,我们在两种设定下对 REC(指代定位)任务进行实验。(1) 在单数据集微调设定中,Base基础模型在表1五个数据集上分别超越当前的SoTA 方法HiVG为2.07%(testB)、6.15%(testB)、4.73%(test)、1.95%(test) 与1.50%(test),同时显著优于传统单模态检测器方法 TransVG++,性能分别提升达到 4.37%(testB)、7.98%(testB)、7.22%(test)、2.47%(test) 与2.12%(test)。(2) 在数据集混合预训练设定中,Base基础模型在RefCOCO/+/g的 testB/testB/test 划分上分别超越HiVG为1.35%、 2.79%与2.63%,超过Grounding-DINO 达2.59%、 4.76%与2.38%,优于 OFA 达到5.28%、5.18%与 5.01%,甚至超越了参数量是我们20-60 倍的GMLLM 模型 LION,提升达到3.76%、2.13%与1.69%。需指出,UniTAB、OFA、LION等工作中同样采用MVLM 进行预训练。
表1 五个指代定位数据集采用单数据集微调设置的对比实验
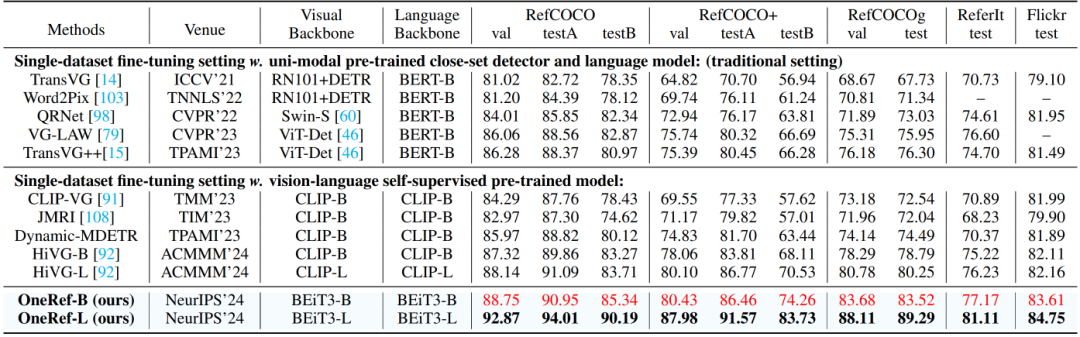
表2 REC 任务采用数据集混合中间预训练设置的对比实验
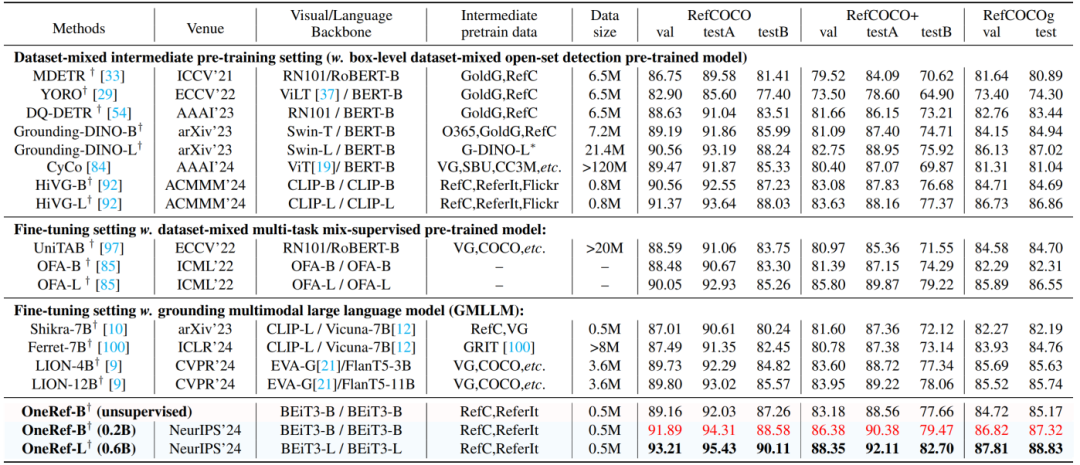
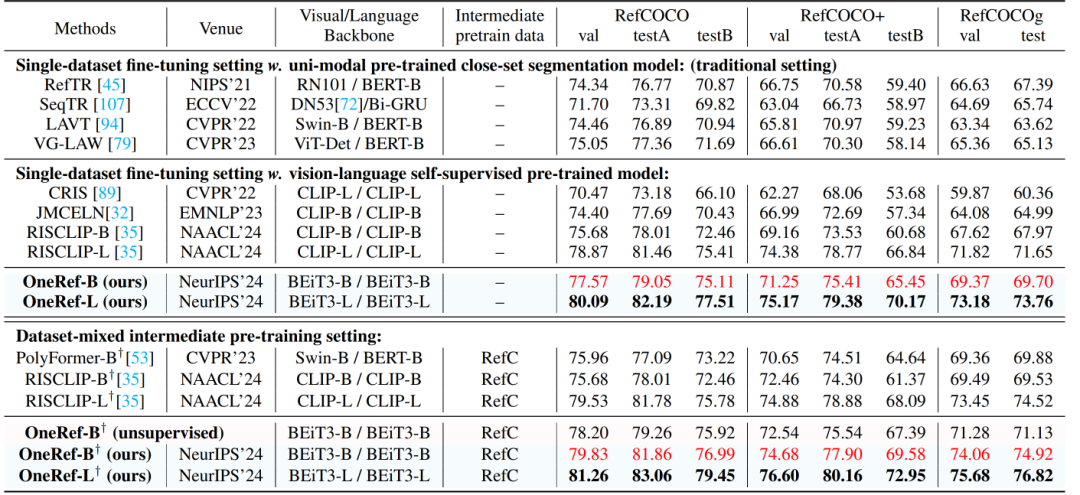
如表3所示,我们在两种设定下进行 RES(指代分割)任务实验。 (1) 在单数据集微调设定中,Base基础版模型在 RefCOCO/+/g 的 testB/testB/test 划分上分别超越 SoTA 自监督方法RISCLIP达到2.65%、4.77%与1.73%,同时显著优于传统单模态检测器方法 VG-LAW 达到 3.42%、7.31%与4.57%。 (2) 在数据集混合预训练设定中,Base基础版模型相较 SoTA 方法 RISCLIP 实现4.53%、8.21% 与5.39%的性能提升。
表3 RES 任务上采用两种不同设置下的比较 (mIoU 结果)
如图5所示,我们展示了 OneRef-B 模型在 RefCOCOg 数据集上一些相对具有挑战性的应用示例,并给出了模型的指代定位(REC)和指代分割(RES)的定性结果。这些结果表明,我们的 OneRef 模型在复杂文本理解和跨模态指代定位任务中展现了强大的语义理解的能力。

图5 OneRef 框架在RefCOCOg (val)数据集上的定性结果
02
Cluster-Phys: Facial Clues Clustering Towards Efficient Remote Physiological Measurement
作者:
钱威1,李坤2,胡斌3,郭丹1,*,汪萌1,*
单位:
合肥工业大学1,浙江大学2,兰州大学3
邮箱:
qianwei.hfut@gmail.com
kunli.hfut@gmail.com
guodan@hfut.edu.cn
bh@lzu.edu.cn
eric.mengwang@gmail.com
论文:
https://dl.acm.org/doi/10.1145/3664647.3680670
发表会议:ACM MM 2024
*共同通讯作者
1.研究背景
随着计算机视觉和人工智能的发展,远程光电容积描记(rPPG)技术成为非接触式生理信号测量的重要手段。它可通过普通摄像头捕捉面部细微色彩变化,估计心率(HR)、心率变异性(HRV)和呼吸频率(RF)等生理参数,广泛应用于智能健康监测、面部反欺诈等场景。然而,rPPG信号往往因面部区域组织差异、光照变化、头部运动等干扰变得微弱而不稳定,导致信号质量下降。为应对上述问题,本文提出了一种创新性方法——Cluster-Phys,旨在以更紧凑、高效、语义一致的方式提取rPPG相关特征,提升远程生理测量的鲁棒性与准确性。
2.方法概述
Cluster-Phys的核心思想是:将面部视频中的多个区域(ROI)进行语义聚类,提炼出能代表局部光吸收特征的“原型”,并通过这些原型追踪周期性的生理信号变化,如图1所示。整个方法由以下模块组成:
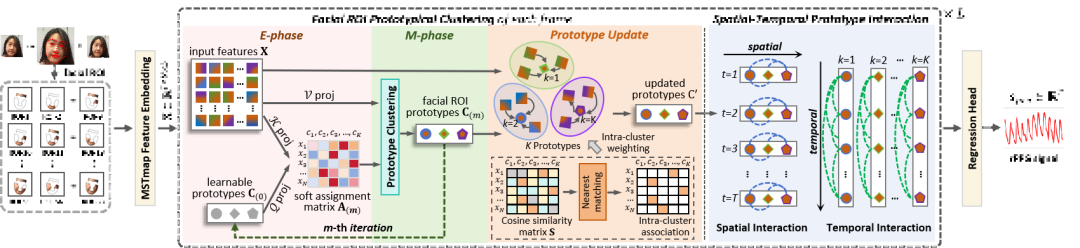
图1 方法概览图
面部ROI原型聚类模块:使用密度峰值聚类结合软分配策略,动态聚合来自不同面部区域的rPPG信号线索,构建紧凑且语义一致的ROI原型表示。
原型更新策略:基于语义相似性权重和最近匹配机制,对原型进行时间更新,使其更好地捕捉动态生理变化。
时空原型交互模块:对每一帧内的原型执行空间交互以学习区域间依赖,对跨帧原型执行时间交互以保持信号的平滑性与周期性。
rPPG回归头:最终将原型表示输入轻量的回归网络,输出一维的rPPG信号序列。
3.实验结果
如表1、表2所示,本文在UBFC-rPPG、PURE、VIPL-HR等多个公开数据集上验证了Cluster-Phys的性能。在数据集内与跨数据集测试中,Cluster-Phys均超越现有最先进方法,如PhysFormer与EfficientPhys,显示出更强的泛化能力。
表1 数据集内测试结果
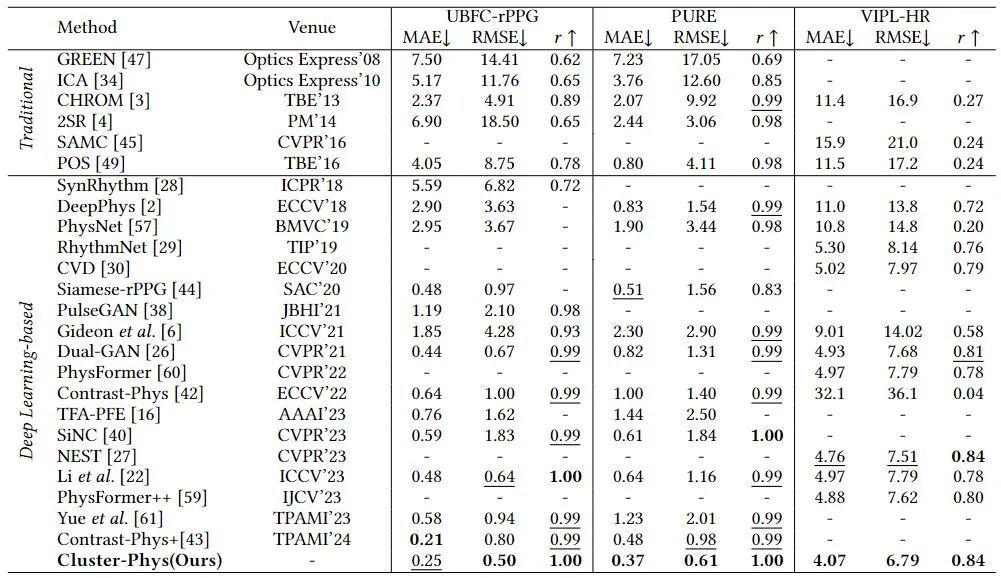
表2 跨数据集测试结果
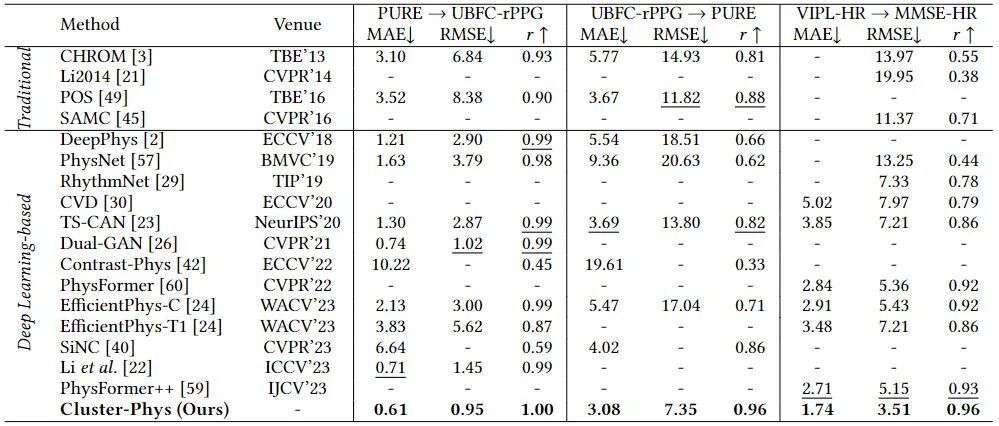
此外,如表3所示,该方法在HRV、RF估计任务上同样取得领先效果,证明其在高质量生理信号提取方面的强大能力。
表3 在UBFC-rPPG数据集上的HRV和RF测试结果

在头部运动、遮挡干扰等复杂场景下依然保持稳定信号预测,体现出极强的鲁棒性。
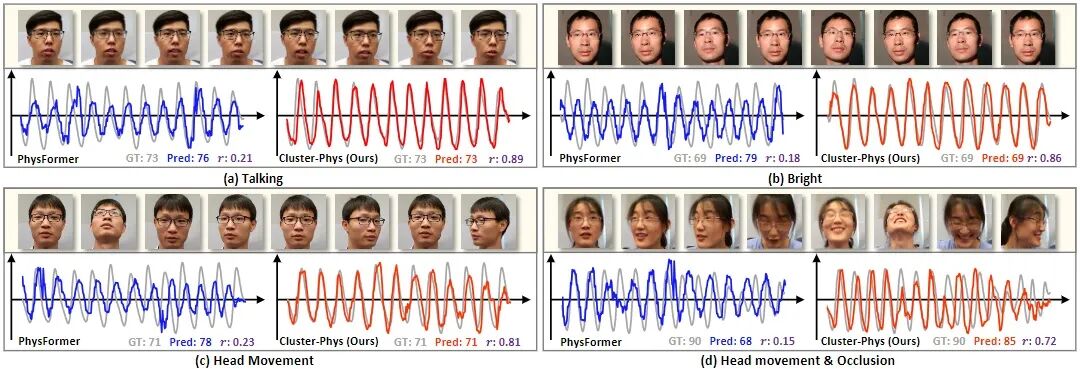
图2 不同复杂场景下的预测结果
03
VoxInstruct: Expressive human instruction-to-speech generation with unified multilingual codec language modelling
作者:
周逸轩+,秦霄羽+,金泽宇,周朔亦,雷舜,周松涛,吴志勇*,贾珈*
单位:
清华大学
邮箱:
yx-zhou23@mails.tsinghua.edu.cn
xyqin@tsinghua.edu.cn
jinzeyu23@mails.tsinghua.edu.cn
zhousy23@mails.tsinghua.edu.cn
leis21@mails.tsinghua.edu.cn
zhoust19@mails.tsinghua.edu.cn
zywu@sz.tsinghua.edu.cn
jjia@tsinghua.edu.cn
论文:
https://dl.acm.org/doi/abs/10.1145/3664647.3681680
代码:
https://github.com/thuhcsi/VoxInstruct
发表会议:ACM MM 2024
+共同第一作者,*共同通讯作者
1.研究背景
随着AIGC技术的快速发展,根据人类语言指令生成多媒体内容方面已取得显著进步。但在语音生成领域,现有方法仍存在明显局限性。其一,输入方式僵化,通常要求用户将指令拆分为内容提示(说话内容)和描述提示(说话风格、情感、音色等)两部分,形式上不够自然且无法与其他模态生成式方案对齐。其二,缺乏细粒度控制能力,无法通过指令精确控制词级别重读等局部表达,限制了实际应用中的灵活性和表现力。为了解决这些难题,我们提出了一个统一的指令到语音(instruction-to-speech)生成框架—VoxInstruct,旨在让语音生成像文生图一样,仅凭一句文本指令便可直接合成兼具内容与表现力的高质量语音。
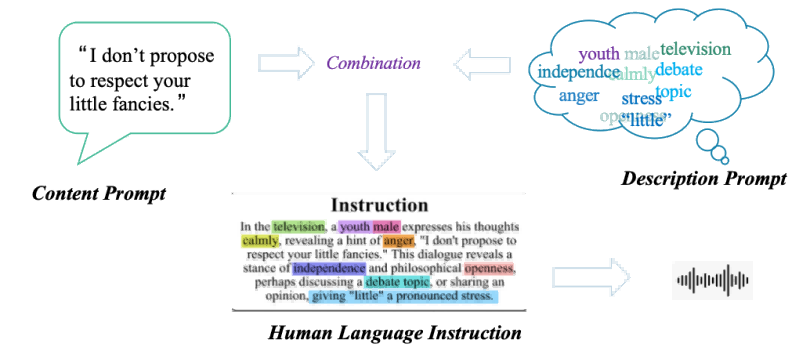
图1 指令到语音生成任务示意图
2.技术贡献
本工作主要贡献如下:
Ø 提出统一的指令到语音生成框架:支持直接根据一句话指令生成高表现力语音,无需显式分离内容提示和描述提示。适配多种任务场景(图2所示),可实现对生成语音的性别、年龄、情感、风格、环境以及局部重音等多维度的精细控制。
Ø 引入语音语义单元作为中间表示:为增强模型对指令中发音内容的理解抽取,VoxInstruct引入语义单元建模,有效提升了合成语音可懂度,同时替代传统语音合成方法对音素输入的依赖。
Ø 设计多种无分类器引导(CFG)策略:通过结合条件生成和无条件生成的训练推理方式,增强了生成语音对人类指令的遵循能力。
Ø 支持语音提示与文本指令的结合:该框架首次实现了参考语音提示与描述性文本指令的结合,支持同时使用两者进行语音生成。
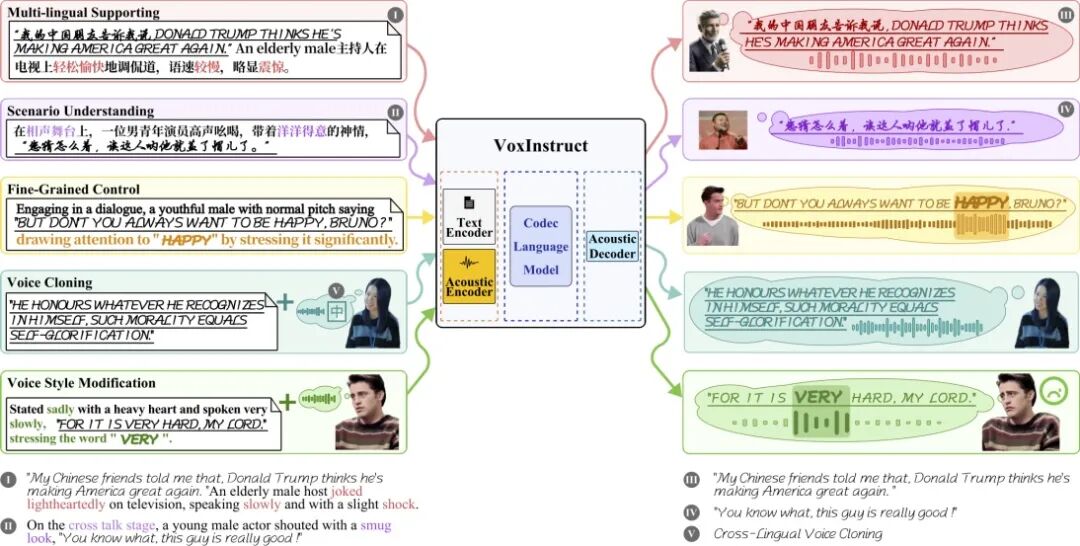
图2 VoxInstruct能力展示
3.方法概述
本文提出的VoxInstruct框架如图3所示,整体架构由文本编码器(MT5)、声学编码器(Encodec)、声学解码器(Vocos)和编解码语言模型四部分组成。其中主体部分的编解码语言模型采用LLaMA架构,分三个阶段建模从文本指令到目标语音声学单元生成过程。
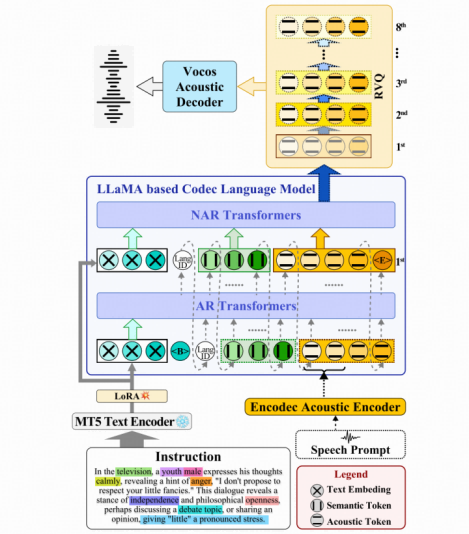
图3 VoxI
与文生图不同,语音生成需要更加严格的内容对齐,发音单元的精确出现和正确顺序都显著影响生成语音的可懂度。我们在前置实验中发现,让模型直接根据复杂的文本指令预测声学单元是非常困难的。受思维链(Chain-of-Thought)启发,VoxInstruct引入了基于HuBERT的语音语义单元作为中间建模表示,从而生成过程被拆分为“指令到语义单元生成”和“声学单元生成”两部分。而在Encodec模型提取的多层声学单元中,对第一层特征的建模至关重要(包含了目标语音的绝大部分信息,以及决定整体时长),因此需要将“声学单元生成”进一步分解为“粗粒度(第一层)声学单元生成”和“声学细节(其余层)生成”两个阶段。在三阶段生成中,前两个阶段采取自回归(AR)方式预测,而第三阶段的声学细节建模则采用并行方式以提高效率。
在训练AR模型时,VoxInstruct通过一定概率掩蔽条件(包括文本指令、语义单元序列)来学习无条件生成能力,从而在自回归推理的每个时间步中都可以应用CFG来增强生成结果对条件的遵循度。另外在训练步骤上,VoxInstruct结合预训练和渐进微调范式,首先在大规模转录文本-语音数据上训练模型基本的语音合成、零样本克隆能力,然后在精标的语音指令数据集上进一步学习对人类指令的理解和遵循生成能力,从而兼具泛化性和功能性。
4.实验设计与结果
如表1和表2所示,VoxInstruct在生成语音质量和指令遵循度方面的表现均显著优于现有方案(如PromptTTS等)。在细粒度重音控制上,VoxInstruct也能够准确实现指令要求的局部重读效果。此外,该框架在零样本声音克隆任务上也表现出色,达到了与VALL-E等方案相当的水平,并支持跨语种克隆。表3所示的消融实验也进一步验证了我们所提方法的关键作用,当移除语义单元序列建模或去除CFG策略,均会导致性能明显下降。
表1 指令到语音生成任务比较结果(英文测试集)

表2 指令到语音生成任务比较结果(中文测试集)

表3 消融实验结果
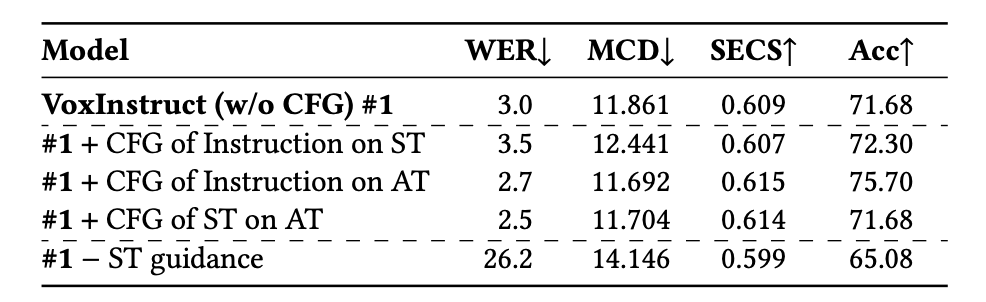
表4部分消融实验

04
CMT: Co-training Mean-Teacher for Unsupervised Domain Adaptation on 3D Object Detection
基于平均教师协同训练的无监督领域自适应三维目标检测
作者:
陈世杰¹,卓君宝¹,*,李欣¹,刘海壮¹,王荣全¹,陈健生¹,马惠敏¹,*
单位:
1 北京科技大学
邮箱:
chensj37@foxmail.com
junbaozhuo@ustb.edu.cn
linuxin@foxmail.com
d202110401@xs.ustb.edu.cn
rongquanwang@ustb.edu.cn
jschen@ustb.edu.cn
mhmpub@ustb.edu.cn
代码:
https://github.com/csj777/CMT
发表会议:
ACM MM 2024
*共同通讯作者
1.研究动机
基于点云的3D目标检测是机器人、自动驾驶等多媒体应用的核心技术,但其性能严重依赖于训练数据。当一个在特定数据集(源域,如Waymo)上训练好的模型,直接应用到另一个不同环境(目标域,如KITTI)时,性能往往会急剧下降。这种域差异可能源于激光雷达线数、天气条件、物体尺寸分布等多种因素。由于在新领域重新标注海量3D数据成本极高,无监督域适应(UDA) 成为了关键解决方案。然而,现有方法(如自训练、协同训练等方法)在跨域3D检测上面临三大挑战:
(1)伪标签噪声:模型在目标域预测的伪标签本身是不可靠的,用其训练会导致误差累积。
(2)伪标签不完整:基于高置信度的伪标签筛选机制往往只覆盖了简单样本,导致模型无法学习到目标域全部的特征多样性。
(3)域不变特征学习不足:现有方法简单地将源域和目标域数据混合训练,难以真正捕捉到对领域变化鲁棒的特征。
为了解决这些挑战,我们提出了Co-training Mean-Teacher (CMT) 框架,旨在更可靠、更全面地将知识从有标签的源域迁移到无标签的目标域。
2.方法介绍
我们首先使用源域数据预训练一个基础检测器,然后将其初始化为学生模型和教师模型。教师模型为无标签的目标域数据生成伪标签,同时我们从源域中通过困难实例挖掘(HIM) 筛选出点云数量少的困难样本,将其注入目标域场景中。这极大地丰富了目标域前景的多样性,缓解了伪标签不完整的问题。随后,学生模型同时利用源域的真值标签和目标域的增强后伪标签进行协同训练。在协同训练时,我们构建了一个混合域(HDG),其背景来自源域,前景则来自上述增强后的目标域。随后,将目标域和混合域的数据分别输入学生和教师模型。通过在两个模型对同一物体的预测特征之间进行类别感知对比学习(CCL),我们拉近同类特征、推远异类特征,从而提炼出更具判别力的域不变特征,并有效抑制伪标签噪声的负面影响。教师模型的参数通过学生模型的指数移动平均(EMA)进行更新,以提供稳定的监督信号。
此外,我们引入了批量自适应归一化(BAN)。该模块在每批训练中动态地使用目标域数据更新教师模型BN层的统计量,使教师模型的内部特征分布与目标域对齐,从而生成更高质量、更可靠的伪标签。
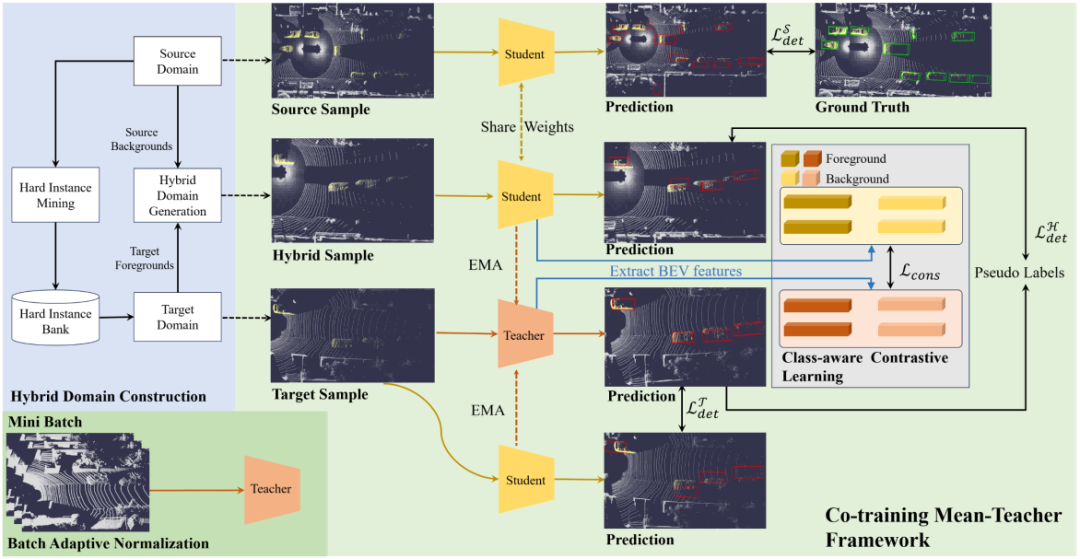
图1CMT框架图
在Waymo、nuScenes、KITTI三个主流数据集上的大量实验表明,CMT在多种跨域场景以及多种检测器中均取得最优性能,部分任务甚至接近在目标域进行全监督训练的性能。
表1 CMT与相关基线对比结果
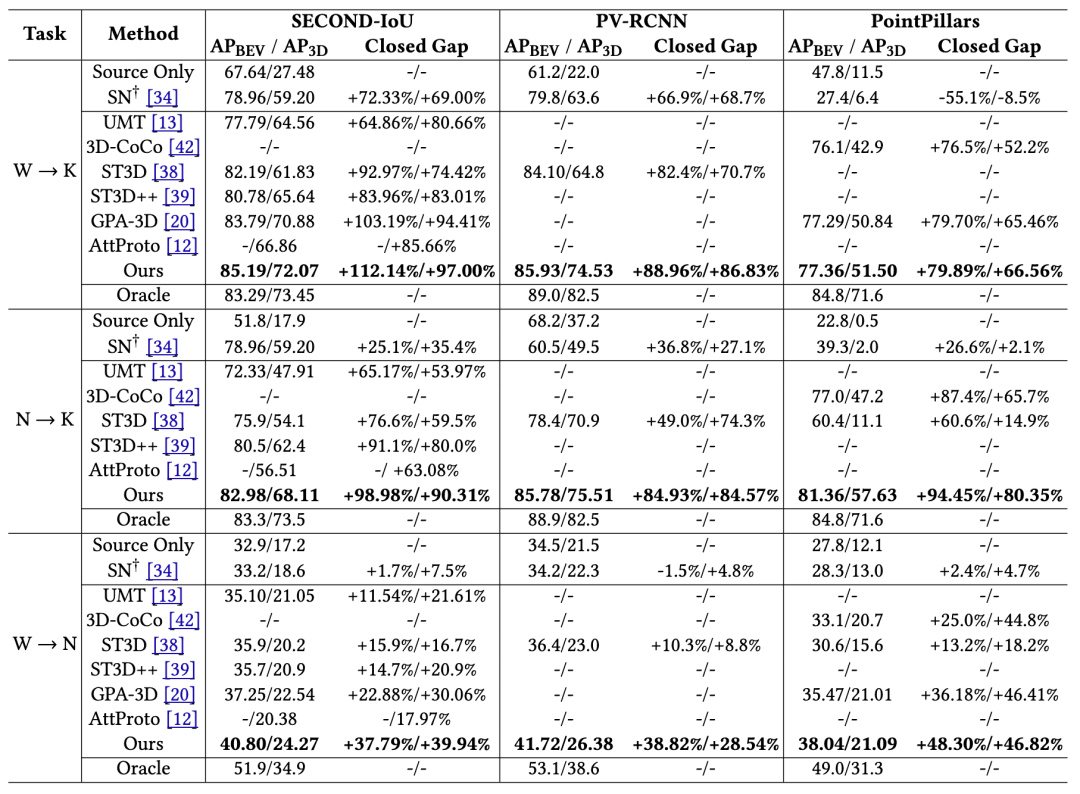
表2 主消融实验结果
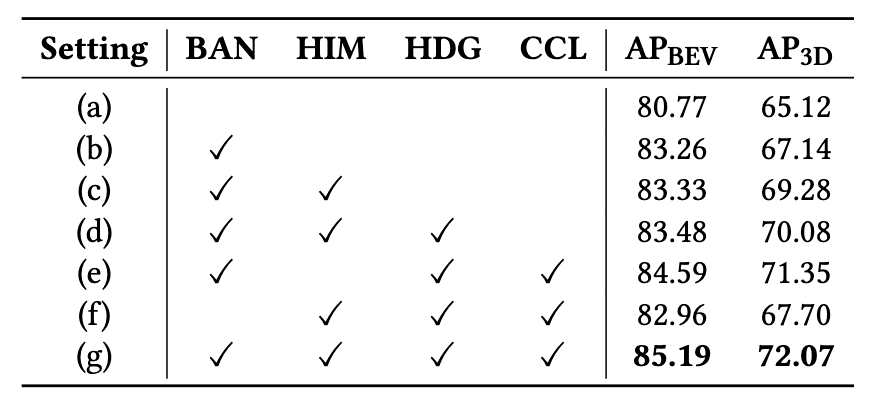
表3 混合域构建策略对比实验
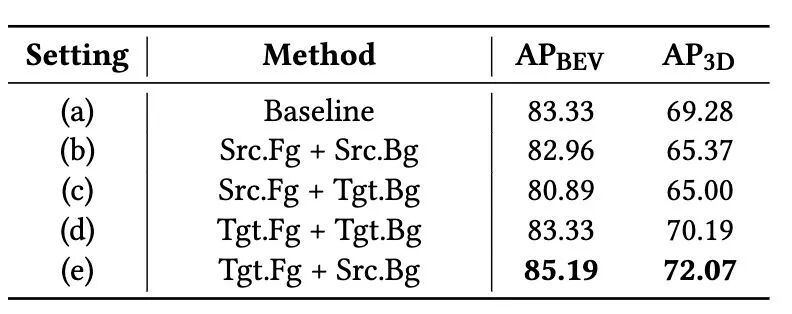
表4 CMT与相关基线对比结果
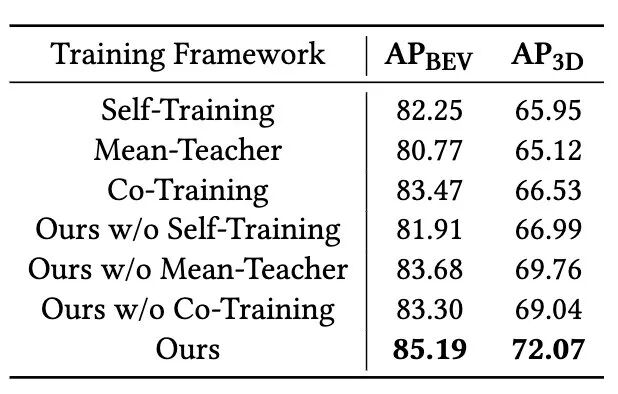
表5 BN参数更新策略对比实验
05
Exploring in Extremely Dark: Low-Light Video Enhancement with Real Events
作者:
王喜聪1,傅慧源1*,王家璇1,王新2,张恒,马华东1
单位:
1 北京邮电大学
2 纽约州立石溪大学
邮箱:
wangxc@bupt.edu.cn
fhy@bupt.edu.cn
2018213169@bupt.edu.cn
x.wang@stonybrook.edu
kazenokizi@live.com
mhd@bupt.edu.cn
论文:
https://dl.acm.org/doi/10.1145/3664647.3681370
发表会议:ACM MM 2024
*通讯作者
1.研究背景
由于传感器性能受限,传统相机在视频拍摄中难以捕捉极暗区域的细节,而这些缺失信息会显著影响低光视频增强的有效性。相比之下,事件相机具备更高的动态范围,即使在极端黑暗条件下仍能捕获运动信息。基于这一优势,本文提出了一种融合真实事件的低光视频增强网络。为充分利用事件数据以针对性增强极暗区域,设计了事件图像融合模块,有助于定位并显著提升极暗区域的可见性,同时结合无监督损失设计,确保增强结果的时序一致性和细节保真度。
2.方法概述
我们提出的融合真实事件的低光视频增强网络(Real-event Embedded Network, REN)基于Retinex理论构建,旨在利用真实事件改善低光视频增强性能。与现有方法相比,REN的三个核心特点是:1)首次引入真实事件用于低光视频增强;2)针对性增强极暗区域,而非统一处理所有区域;3)通过空间注意力机制实现图像与事件的特征对齐,提升真实场景下的鲁棒性。
为此,我们设计了事件图像融合模块(Event-Image Fusion, EIF),能够自适应识别极暗区域并借助事件特征进行增强,同时在图像与事件特征之间实现空间对齐。为了在缺乏配对数据的情况下有效训练网络,我们进一步提出了两种无监督损失:时序一致性损失确保视频序列输出的连续性,细节对比度损失则引导极暗区域的细节恢复。结合常规有监督损失,REN实现了在配对与非配对数据上的半监督训练。
REN采用端到端双分支架构,以视频帧和事件流作为输入。图像和事件特征通过EIF模块融合实现反射分量估计。光照分量基于UNet架构建模以捕捉全局上下文,随后与反射分量在解码器中融合生成增强帧。网络同时引入残差连接以提升重建质量。训练数据涵盖两类:一类为有标签数据,包括低光与正常光视频对及合成事件;另一类为无标签数据,仅包含低光视频与真实事件。该设计既保证了合成数据的监督信号,又充分发挥了真实事件的优势。
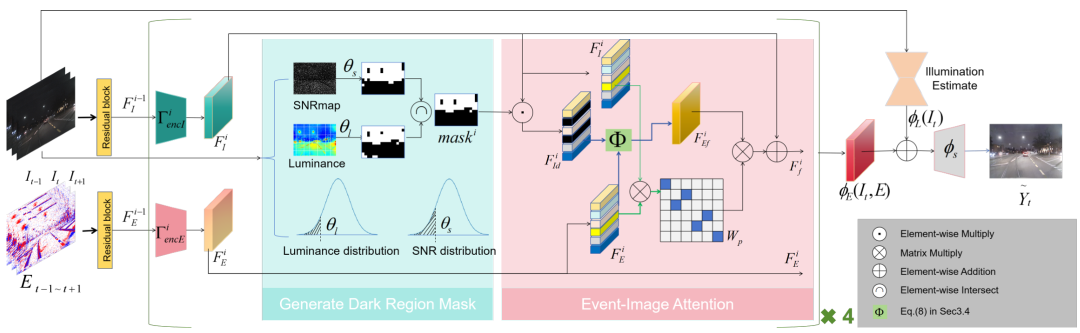
图1 融合真实事件的低光视频增强网络REN框架图
3.实验结果
由于缺乏真实的低光事件视频数据集,我们基于SDSD生成合成事件流,并从DSEC中选取低光视频进行训练与测试,同时在ViViD++数据集上进行交叉验证。实验表明,无论在合成数据还是实际数据上,REN均优于现有方法。特别是,仅在SDSD上训练的RENsd已能取得较好表现,而在SDSD与DSEC联合训练的REN则进一步提升了性能。定性对比结果表明,REN在合成和真实场景中均能生成更自然的增强结果,在全局亮度提升与极暗区域的细节恢复方面展现出显著优势。
表1 在合成事件数据集SDSD上的实验结果
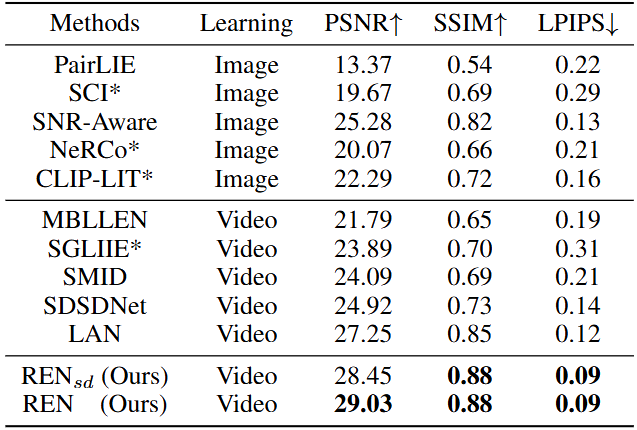
表2 在真实事件数据集DSEC上的实验结果,*为无监督方法

图2 合成事件数据集SDSD的视觉质量对比结果

图3 真实事件数据集DSEC的视觉质量对比结果

图4 真实数据集ViViD++的视觉质量对比结果

编辑人:吴建龙、任文琦
专委会责任副主任:张勇东
 京公网安备11010802017125号
京公网安备11010802017125号