
【论文导读】2025年论文导读第十八期
【论文导读】2025年论文导读第十八期
2025年10月14日 18:32 江苏


论文导读
2025年论文导读第十八期(总第一百三十五期)
目 录
|
1 |
Decoding Urban Industrial Complexity: Enhancing Knowledge-Driven Insights via IndustryScopeGPT |
|
2 |
Visual-linguistic Cross-domain Feature Learning with Group Attention and Gamma-correct Gated Fusion for Extracting Commonsense Knowledge |
|
3 |
Efficient Face Super-Resolution via Wavelet-based Feature Enhancement Network |
|
4 |
Multi-Label Learning with Block Diagonal Labels |
|
5 |
GeNSeg-Net: A General Segmentation Framework for Any Nucleus in Immunohistochemistry Images |
01
Decoding Urban Industrial Complexity: Enhancing Knowledge-Driven Insights via IndustryScopeGPT
作者:
王思琪1,2, 梁超3, 高云帆4, 刘洋5, 李菁*2,6, 王昊奋*5
单位:
1同济大学
2香港理工大学计算学系
3广东省国地资源环境研究院
4同济大学上海自主智能无人系统科学中心
5同济大学设计创意学院
6香港理工大学数据科学与人工智能研究中心
邮箱:
siqi_wang@tongji.edu.cn,
liangc0427@gmail.com,
2311821@tongji.edu.cn,
liuy@tongji.edu.cn,
jing-amelia.li@polyu.edu.hk
carter.whfcarter@gmail.com
论文:
https://arxiv.org/pdf/2411.15758
发表会议:
ACM MM 2024
*共同通讯作者
论文简介
产业园区是城市经济增长的关键引擎和创新中心,然而,许多园区在发展中面临着产业需求与城市服务供给之间的显著失衡,这凸显了对其进行科学化、智能化规划与运营(Industrial Park Planning and Operation, IPPO)的迫切需求。传统的规划方法往往依赖于经验和过时的数据,难以动态整合丰富的城市多源异构数据进行深度分析。近年来,大语言模型凭借其强大的语言推理和上下文学习能力,为解决城市复杂性问题、开发统一自适应的IPPO解决方案提供了新的可能。然而,将LLM应用于专业的IPPO领域仍面临三大核心挑战: 1) 数据构建挑战:如何有效构建一个能够捕捉产业园区复杂关系和语义的专用数据集? 2) LLM适配挑战:如何让LLM适应并有效利用包含图像、文本、数值和地理空间信息的异构知识图谱? 3) 任务泛化与可解释性挑战:如何使LLM能够灵活、可解释地胜任多样化的IPPO任务,并提供清晰的决策过程?

图1 将LLM集成到IPPO(产业园区规划与运营)解决方案中所面临的挑战
针对上述挑战,我们首先构建并开源了首个大规模、多模态、多层次(空间与语义)的产业园区知识图谱IndustryScopeKG。该知识图谱深度整合了上海市的街景、企业、社会经济和地理空间等多源数据,涵盖了264个产业园区、12.8万个空间网格、105万家企业实体,最终构成了包含超过223万实体和5100万三元组的庞大知识库。IndustryScopeKG不仅通过多维度的属性指标体系(如产业发展、城市生活、创新创业三大维度下的111个具体指标)对园区进行精细刻画,还通过地理空间关系(包含、邻接)和语义关系(相似性、产业关联性)建立了实体间的复杂连接,为后续的知识驱动决策提供了坚实的数据基础。
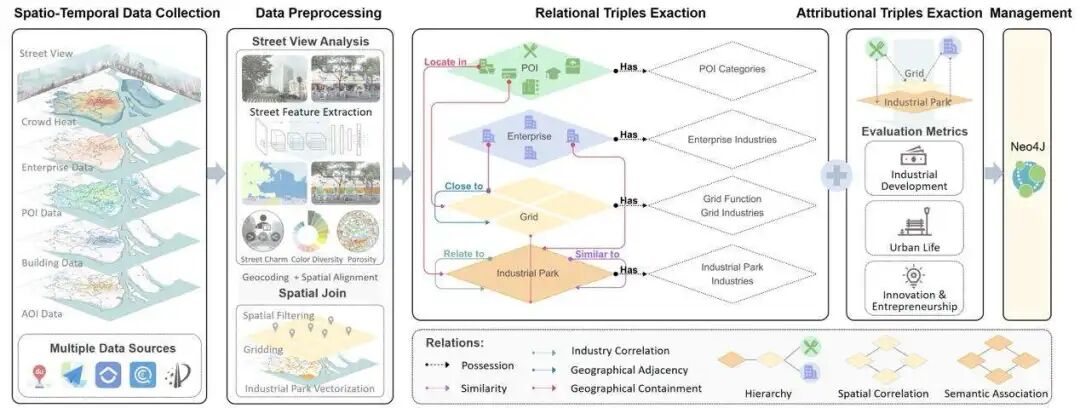
图2 IndustryScopeKG知识图谱构建流程
在此基础上,我们进一步提出了IndustryScopeGPT框架,一个创新的LLM驱动智能体框架,旨在增强LLM在产业园区规划与运营任务中的工具增强推理和决策能力。该框架将LLM作为核心控制器,通过设计一系列专用工具(如Cypher查询器、地理编码/解码器、排序器、功能规划器等)与外部的Neo4j图数据库进行动态交互,实现了LLM与空间计算和动态图谱推理的首次融合。为了解决LLM在复杂决策中可能出现的推理路径不佳或工具使用错误等问题,IndustryScopeGPT创新性地引入了蒙特卡洛树搜索(MCTS)机制。MCTS将复杂的规划决策过程视为一个树搜索问题,通过选择、扩展、模拟和回溯四个步骤,动态平衡探索与利用,从而在巨大的规划空间中寻找最优的决策路径,显著提升了任务执行的灵活性、鲁棒性和可解释性。
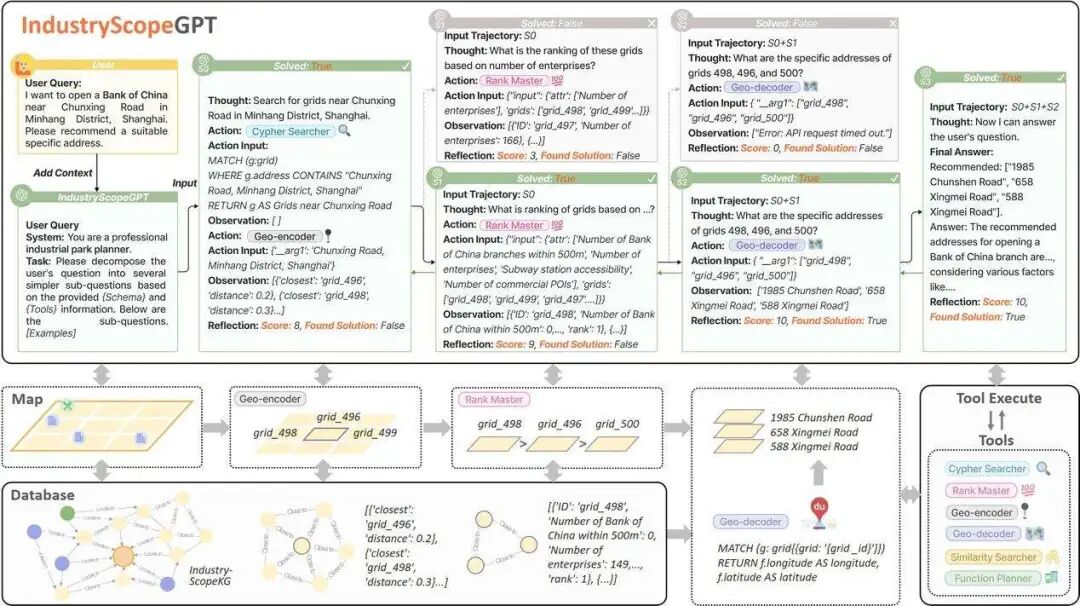
图3 IndustryScopeGPT框架概览,展示了LLM结合MCTS和工具进行决策的过程
为了验证工作的有效性,我们构建了专门的评测基准IndustryScopeQA,并在多尺度设施选址推荐和园区功能规划两大典型IPPO任务上进行了详尽实验。结果表明,IndustryScopeKG的数据深度和结构化优势能够显著提升LLM的性能,而IndustryScopeGPT相较于传统的CoT、ReAct等提示方法,在各项指标上均取得了大幅领先。例如,在有条件的园区级选址任务中,IndustryScopeGPT的F1分数达到了0.590,远超基线模型。在功能规划任务中,它能够生成比传统模型和现实情况更多样化、更均衡的功能布局方案。这项工作为智能化的产业园区规划与运营研究设立了新的基准,并为LLM在未来城市发展策略中的深度融合奠定了坚实的基础。
02
Visual-linguistic Cross-domain Feature Learning with Group Attention and Gamma-correct Gated Fusion for Extracting Commonsense Knowledge
作者:
张佳璐1†, 王馨翊1†, 姚成林1, 任剑锋1*, 蒋旭东2
单位:
宁波诺丁汉大学1,新加坡南洋理工大学2
邮箱:
jialu.zhang@nottingham.edu.cn
scyxw10@nottingham.edu.cn
chenglin.yao@nottingham.edu.cn
jianfeng.ren@nottingham.edu.cn
EXDJiang@ntu.edu.sg
论文:
https://dl.acm.org/doi/10.1145/3664647.3680820
发表会议:ACM MM 2024
†共同第一作者
*通讯作者
1.论文简介
从图像中获取实体以完成常识知识提取(Commonsense Knowledge Extraction)在众多应用中具有重要意义。远程监督学习通过自动检索包含实体对的图像并从这些图像集合中总结常识知识,取得了显著进展。然而,现有方法仍面临着以下挑战:1)它通常需要抽取未见过的实体关系,而模型很难处理训练中未覆盖的实体和关系。2)常识性关系更适合通过一组实例来归纳,而不是依赖单个实例。3)同一实体关系的不一致标签可能会干扰模型对常识性关系的准确推断。为了解决这些问题,本文提出了一种多模态跨域特征学习框架(Multi-modal Cross-domain Feature Learning, MCFL),实现了对实体关系常识的全面总结。
2.方法概述
论文提出 Multi-modal Cross-domain Feature Learning (MCFL) 框架,主要有以下三个核心贡献:
(1) 多模态跨域学习模块:通过大规模预训练视觉-文本基座模型引入丰富的通用领域知识,从而缩小稀疏对象与其丰富关系之间的知识鸿沟。具体而言,给定一个实体对,该模块使用 VinVL 提取视觉特征,并利用 GLoVe向量对实体标签进行词嵌入以获取语言特征。由于检索到的图像数量有限且已有图文特征可能无法涵盖实体之间的所有可能关系,因此利用预训练大模型生成包含丰富关系的图像描述,以补充未体现的更多语言信息。最后,该模块利用CaptionBert整合三者信息以高效提取视觉-文本特征。
(2) 分组注意力模块:传统单实例学习无法提取实例间的关系以及由实例集合所提供的整体信息,而多实例学习容易忽视单个实例中的实体关系。为增强单个实例的特征,本文提出了一种群体注意力(Group Attention, GA)模块,通过计算每一对实例之间的交互矩阵以构建实例对之间的协同注意力特征,随后聚合整个实例组中的注意力支持。通过这种方式,单个实例的特征能够通过充分利用群体中的部分注意力信息而得到显著增强。
(3) Gamma 校正门控融合模块:由于采用自动标注,已有实例可能会被分配错误的标签,因此从多个实例中最优地聚合共有关系仍然具有挑战性。为解决这一问题,本文提出了一种 Gamma 校正门控融合模块,用于最优地聚合经过群体注意力增强的单实例特征。该模块对所有实例应用门控网络,以确定每个实例的自适应权重。直观地看,在组内拥有更多相似实例的实例,更有可能包含共有关系,因此应分配更高的权重。由于跨多个实例计算得到的门控比率往往相近,本文进一步设计了 Gamma 校正机制,以放大这些比率之间的差异。这样一来,包含较少出现关系的实例会被赋予较小的权重,而包含共有关系的实例则会被赋予较大的权重。最后,所有实例的关系特征被输入至多层感知机,以完成答案空间的映射。
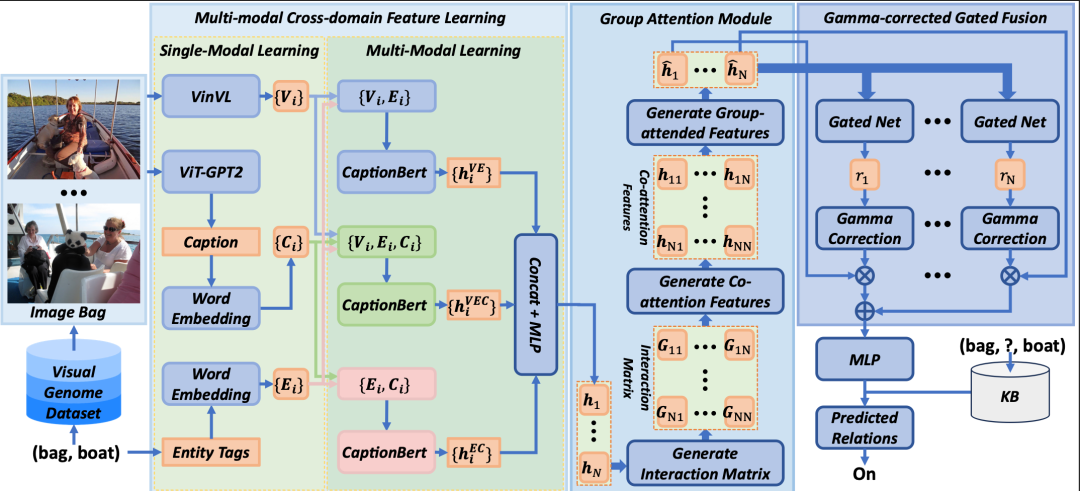
图1 MCFL示意图,及其包含的3个主要模块
3.实验结果
如表1和图2所示,在VG-CKE数据集的广泛实验结果表明,MCFL在常识性知识提取中表现出出色性能。从可视化分析来看,MCFL准确提取了指定实体对的更多关系事实。综合来说,通过三个模块系统设计,MCFL解决了常识知识提取现有挑战,在大规模数据集上使得模型性能得到了可观的增长。
表1 MCFL与相关基线模型在VG-CKE数据集上测试精度对比

图2 MCFL在VG-CKE数据集上的可视化分析
03
Efficient Face Super-Resolution via Wavelet-based Feature Enhancement Network
作者:
李文杰, 郭亨*, 刘炫男, 梁孔明, 胡佳妮, 马占宇, 郭军
单位:
北京邮电大学
邮箱:
lewj2408@gmail.com
guoheng@bupt.edu.cn
mazhanyu@bupt.edu.cn
论文:
https://arxiv.org/pdf/2407.19768
代码:
https://github.com/PRIS-CV/WFEN
发表会议:ACM MM 2024
*通讯作者
1.研究背景
人脸超分辨率旨在从低分辨率人脸图像重建高分辨率人脸图像。现有方法通常采用编码器-解码器结构提取面部结构特征,但直接降采样不可避免地引入失真,尤其对边缘等高频特征影响显著。为解决此问题,我们提出基于小波变换的特征增强网络:通过小波变换无损分解输入特征为高频与低频分量,并分别处理以减轻特征失真。为提升面部特征提取效率,进一步引入全域Transformer模型增强局部、区域及全局面部特征。此类设计使本方法无需像传统方案那样堆叠大量模块,即可实现更优性能。实验表明,本方法在性能、模型规模与运行速度之间实现了有效平衡。
2.研究动机与内容
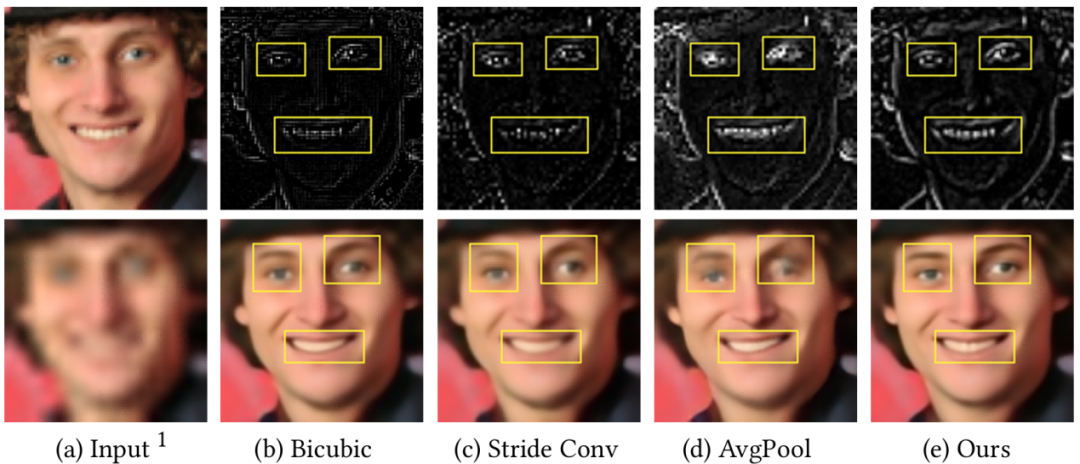
图1 特征图与FSR结果
特征图(第一行)与FSR结果(第二行)展示了多种下采样方法的效果:双三次插值、步长卷积、平均池化以及我们的小波特征下采样。(a)和(b)中高频特征的损失尤为明显,而(c)则出现了频域特征混叠现象。我们的方法能有效防止特征损失或频域混叠现象。
受此启发,我们提出小波特征下采样(WFD)与小波特征上采样(WFU)技术。WFD旨在编码阶段下采样过程中最小化关键面部结构的失真;WFU则通过解码阶段利用DWT获取的高频特征来增强面部轮廓。
如下图2所示,针对给定的退化人脸图像,我们旨在通过采用基于小波的编码器-解码器结构(集成残差块与全域变换器),重建清晰人脸图像。该结构包含基于小波的编码器-解码器架构,其中编码器阶段采用小波特征下采样(WFD),解码器阶段则通过小波特征上采样(WFU)实现图像的下采样与上采样。这些操作负责逐步实现下采样与上采样,构成了我们网络的主要结构。
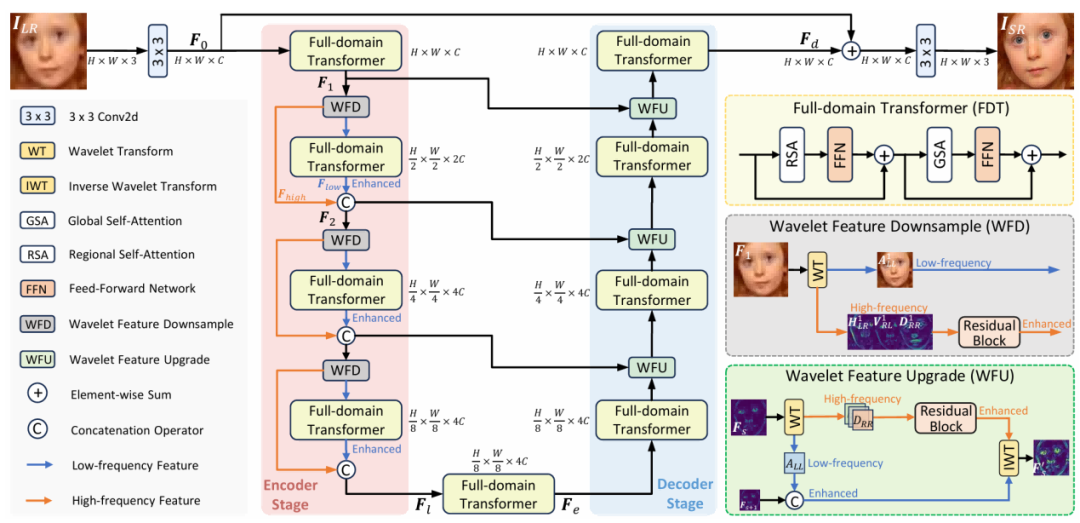
图2 方法概述
为更好地增强小波变换分解后获得的低频面部信息,如下图,我们引入全域Transformer(FDT)。具体而言,由于低频信息包含图像的众多细节特征,提取全面的低频信息至关重要。尽管Transformer在处理低频信息方面表现出有效性,但现有FSR方法中使用的Transformer难以有效聚焦于局部特征(例如皮肤细节)、区域特征(例如眼睛、鼻子等组件)和全局特征(例如整体面部轮廓)。为解决此问题,本文提出FDT,旨在探索多样化的感受野并发掘面部特征间的深层关联,从而提取更全面的人脸信息以提升FSR效果。
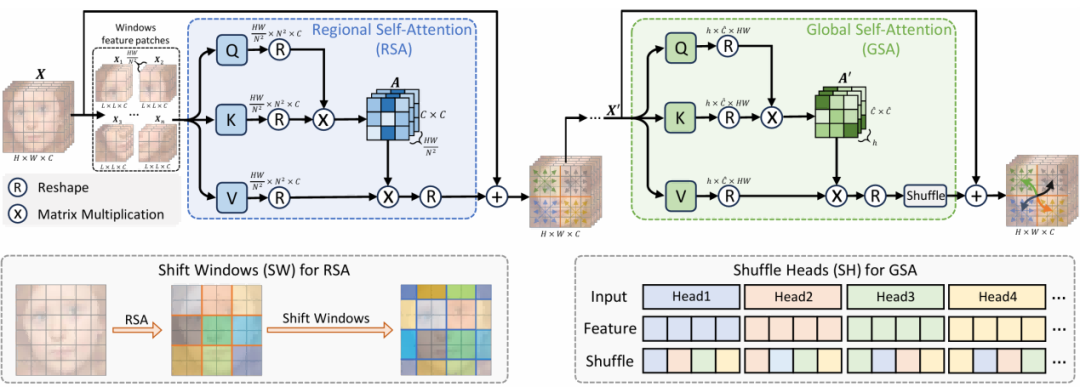
图3 FDT模块
3.实验结果
本文在2个公开基准上测试了我们的方法和相关基线的性能。性能和模型尺寸和推理速度如下表所示,我们的方法的性能要远优于现有方法:
表2 性能和模型尺寸和推理速度
我们在图4和图5进一步给出了可视化结果和效率平衡分析,我们的方法能重建更合理的人脸结构。

图4 可视化结果
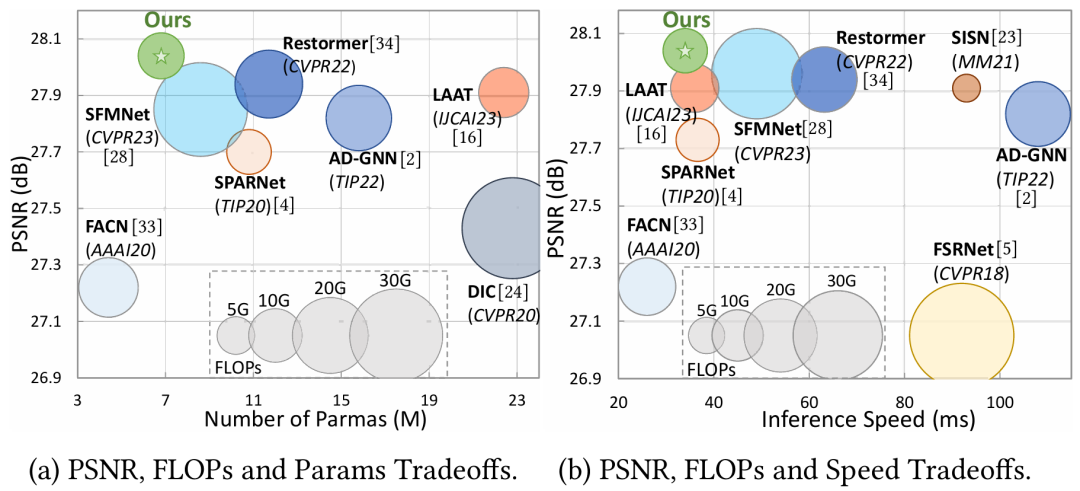
图5 效率平衡
04
Multi-Label Learning with Block Diagonal Labels
作者:
沈乐琦1,赵思成1,张屹峰2,陈辉1,周君栋1,刘朋樟2,包勇军2,丁贵广1
单位:
1 清华大学 2 京东
邮箱:
lunarshen@gmail.com
schzhao@gmail.com
dinggg@tsinghua.edu.cn
发表会议:
ACM MM 2024
*通讯作者
1.研究动机
在现实世界的场景中,收集带有完整标签的大规模多标签数据集是非常困难的。我们发现标注工作量之所以很高,主要有两个原因:标注员成本和数据成本。许多研究已经探讨了缺失标签设置,主要关注数据成本方面,其中图像部分标注。在本文中,我们提出了一种新的设置,即分组标签,以减轻标注员成本和数据成本方面的工作负担。大量的类别可以根据语义和相关性划分为不同的组。每个标注员只需关注自己的标签组,这样就可以对每张图像的小部分高度相关的标签进行详尽的标注,而忽略其他标签。
2.方法介绍
分组标签的标注过程分为三个阶段:(1) 根据语义将N个类别划分为K个组,可以手动完成,也可以利用WordNet。 (2) 对于K个组,我们可以收集一个小型的K分类数据集,与收集全标签数据集相比,这成本更低且高效。然后,训练一个低成本的分类器将原始数据集划分到不同的标签组中。如果一张图像包含多个组,可以随机选择一个组。 (3)属于分组A的标注员只需关注分组A内的类别。由于它们在语义上相关且数量较少,这使得它们更容易进行详尽的标注。
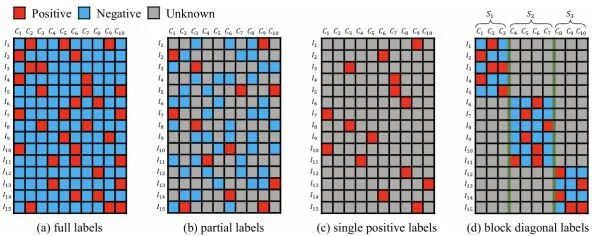
图1 分组标签
在分组标签的设置中,未知标签仍然是核心问题。我们提出了一种简单但有效的方法来处理未知标签的问题。一种简单的方法是使用硬阈值来区分哪个标签是真正的负标签,但这将不可避免地引入一些噪声。因此,我们提出了一种自适应伪标签方法,该方法动态调整阈值以减少为未知标签打标签时的噪声。我们的方法不涉及类别之间的任何关系或数据的先验统计信息,可以被视为一个强大的基准方法。
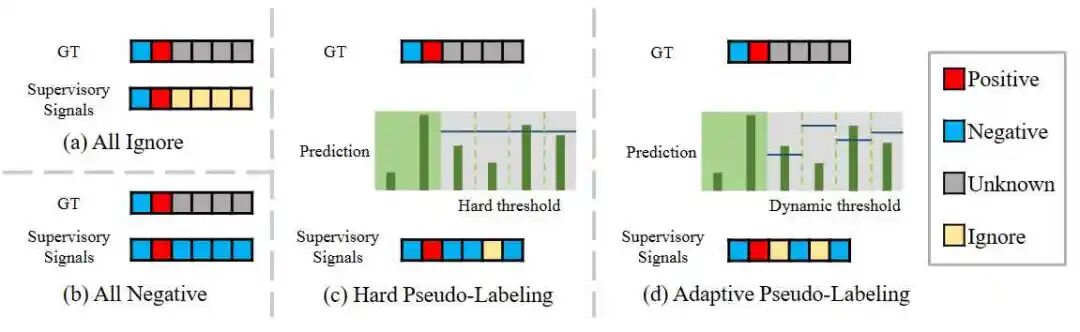
图2 自适应伪标签方法
3.实验结果
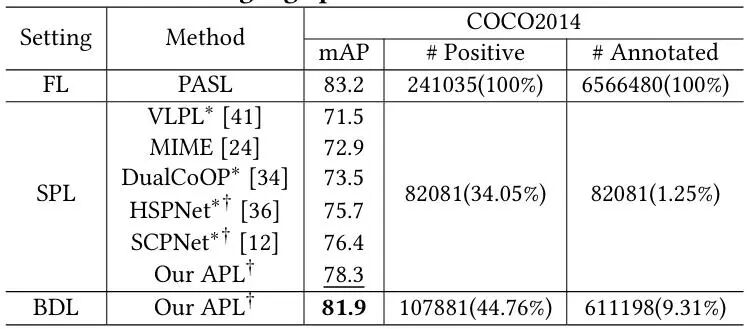
在分组标签的场景中,我们的方法在广泛使用的多标签数据集(VOC2012,COCO2014,NUSWIDE)上实现了最先进的性能,如表1所示。具体来说,在COCO2014上只有9.31%的标注标签,我们的方法达到了81.92%的mAP。另外在单一正标签的场景中,如表2所示,我们的方法超越了之前的相关方法。
表1 对比实验
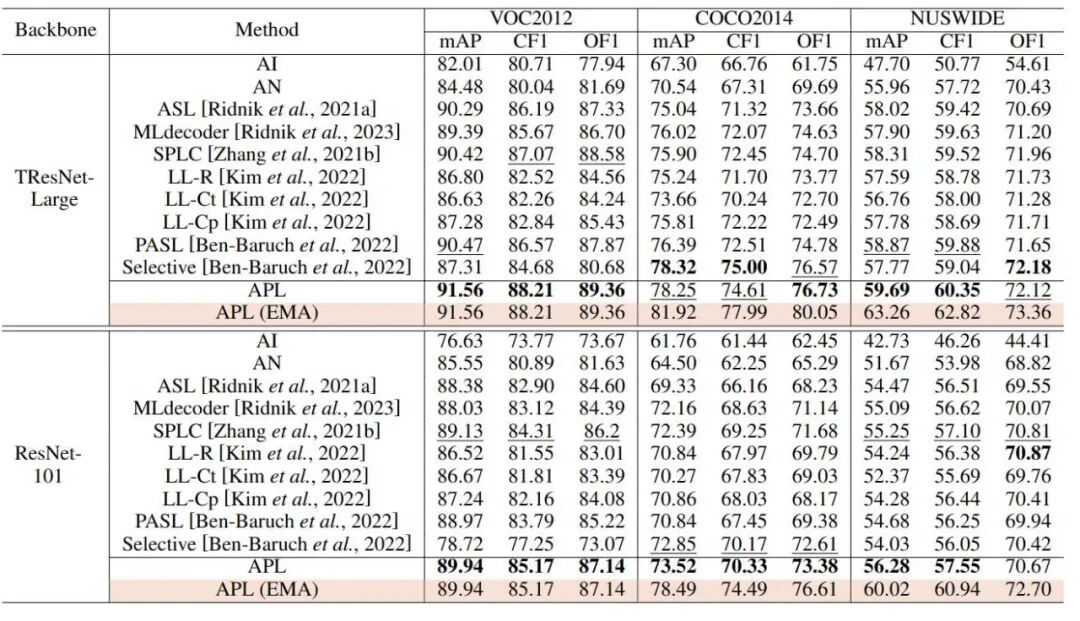
表2 CMT与相关基线对比结果
05
GeNSeg-Net: A General Segmentation Framework for Any Nucleus in Immunohistochemistry Images
作者:
徐思源1,2,李冠男1,2,宋昊飞1,2,王健生1,2,王妍1,2,李庆利1,2,*
单位:
1 华东师范大学
2 上海市多维度信息处理重点实验室
邮箱:
syxu@stu.ecnu.edu.cn
gnli@cs.ecnu.edu.cn
hfsong@stu.ecnu.edu.cn
52191214001@stu.ecnu.edu.cn
ywang@cee.ecnu.edu.cn
qlli@cs.ecnu.edu.cn
发表会议:ACM MM 2024
*通讯作者
论文简介
免疫组化(Immunohistochemistry, IHC)技术在疾病机理研究、病理诊断和临床治疗决策中具有核心作用,其中细胞核分割的准确性直接影响定量分析的可靠性。自动化细胞核分割十分具有挑战,主要由于细胞核的固有特点,如密度较高且存在大量粘连的边缘,容易导致欠分割或过分割问题。此外,诸多复杂因素,例如差异较大的形状和尺寸、模糊的边缘、重叠的细胞群、不充分的染色和不同的成像条件,都增加了分割错误的风险。在IHC图像中,由于有不同的成像技术(明场成像和荧光成像),以及来源于不同组织的细胞核具有较大形态差异,反映出现有算法的泛化能力较差。这些算法在处理未包含在训练数据中的组织类型的细胞核时,分割准确度通常都较低。
为解决这一难题,本文提出GeNSeg-Net,一种具有高泛化能力的通用框架。该方法采用两阶段设计:首先通过增强模型对细胞核进行生成式“标准化”,将多样的形态特征转化为理想的、边界清晰且质地均匀的核结构;随后使用经典的分割模型(如U-Net结合分水岭算法)完成精确分割。这种“先增强、再分割”的策略,有效降低了因组织和成像差异带来的挑战,使分割模型在面对未见过的组织类型时仍能保持较高准确度。
在模型设计上,GeNSeg-Net的增强模型采用轻量化生成器与基于Transformer的判别器,既保证了生成效果,又提升了计算效率。论文在自建的多组织多模态免疫组化核数据集(涵盖明场与荧光成像)以及公开数据集DSB2018和BBBC006v1上进行了系统验证。结果显示,GeNSeg-Net在Dice、AJI、PQ等多项指标上均达到或超越当前最优方法,同时在跨数据集测试中展现了显著的泛化能力。例如,在未见过的组织类型测试中,GeNSeg-Net相较其他方法在AJI和PQ等指标上提升超过5%。
此外,GeNSeg-Net在推理速度上表现出较强竞争力,尽管采用两阶段框架,但得益于轻量化设计,其处理速度仍优于大部分现有方法。论文还通过消融实验详细分析了生成器、判别器以及模块设计对整体性能的贡献,进一步验证了框架的合理性与有效性。
整体而言,GeNSeg-Net首次提出了一个免疫组化图像核分割通用框架,能够跨越不同组织类型和成像方式,兼顾准确性、效率与泛化能力,为自动化病理图像分析提供了新的解决方案,并有望推动智能病理辅助诊断在临床实践中的落地。
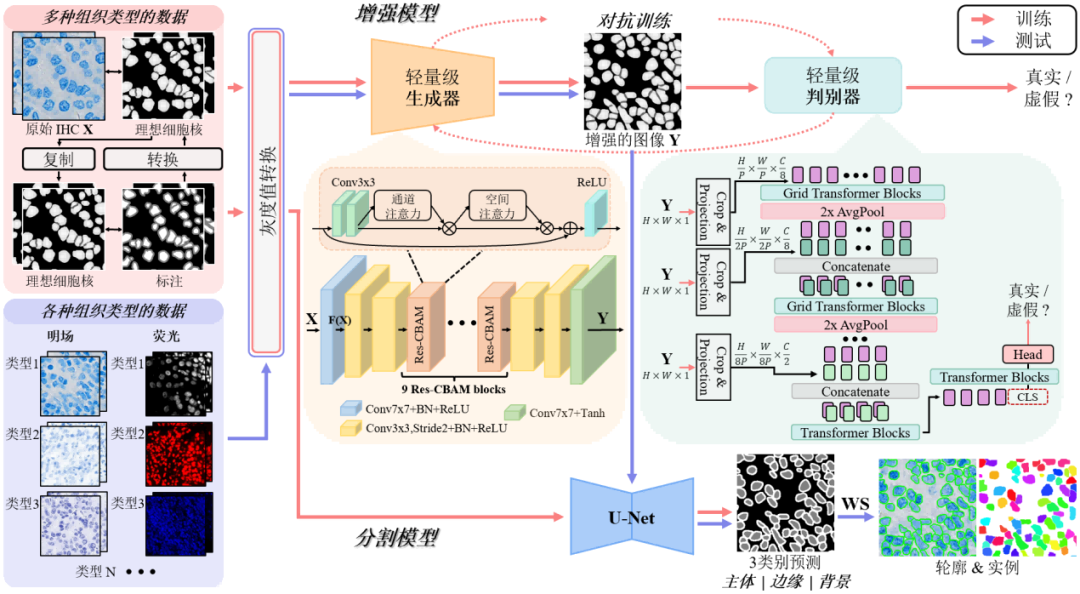
图1 细胞核分割算法的框架图
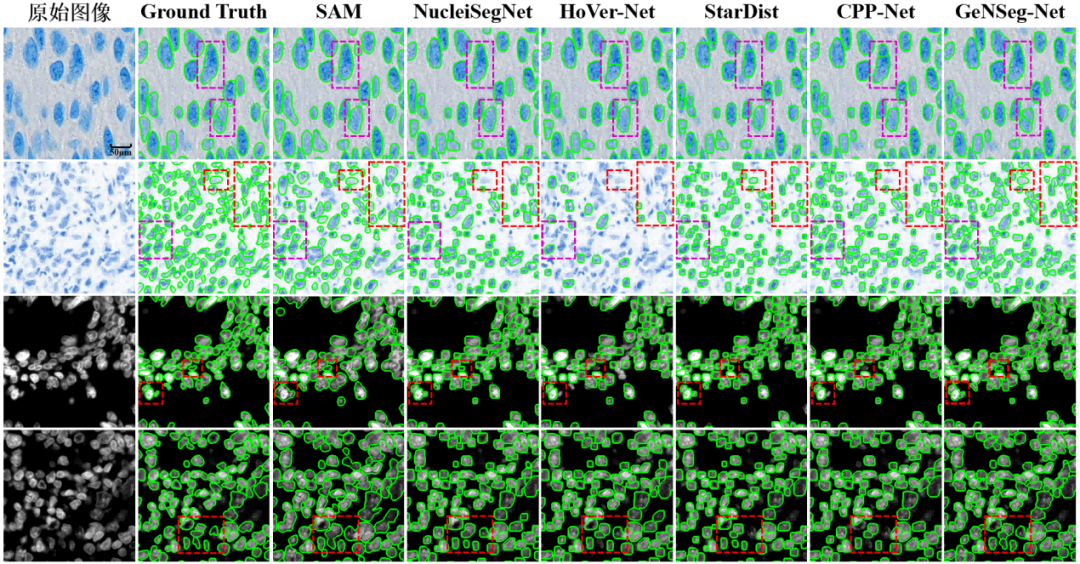
图2与SOTA算法在私有数据集上的定性比较图
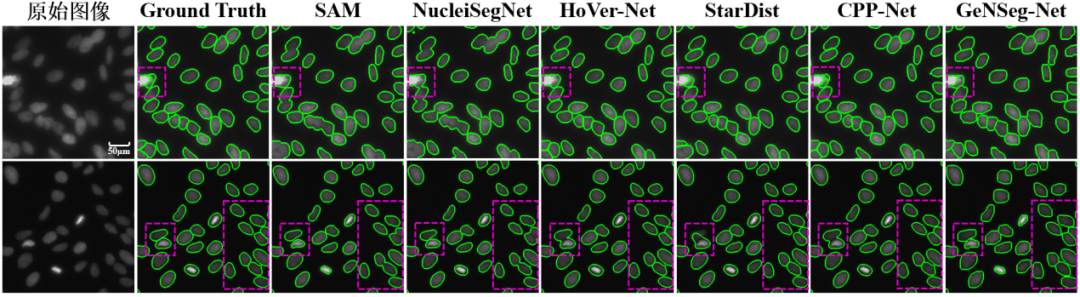
图3 与SOTA算法在DSB2018和BBBC006v1上的定性比较图

编辑人:吴建龙、任文琦
专委会责任副主任:张勇东
 京公网安备11010802017125号
京公网安备11010802017125号