
【论文导读】2025年论文导读第十九期
【论文导读】2025年论文导读第十九期
2025年10月28日 13:19 北京


论文导读
2025年论文导读第十九期(总第一百三十六期)
目 录
|
1 |
SIA-OVD: Shape-Invariant Adapter for Bridging the Image-Region Gap in Open-Vocabulary Detection |
|
2 |
ADDG: An Adaptive Domain Generalization Framework for Cross-Plane MRI Segmentation |
|
3 |
Anatomical Prior Guided Spatial Contrastive Learning for Few-Shot Medical Image Segmentation |
|
4 |
MTSNet: Joint Feature Adaptation and Enhancement for Text-Guided Multi-view Martian Terrain Segmentation |
|
5 |
Distilled Cross-Combination Transformer for Image Captioning with Dual Refined Visual Features |
01
SIA-OVD: Shape-Invariant Adapter for Bridging the Image-Region Gap in Open-Vocabulary Detection
作者:
王梓烁1,周汶昊2,徐婧林2,彭宇新1
单位:
1北京大学王选计算机研究所
2北京科技大学智能科学与技术学院
邮箱:
wangzishuo@pku.edu.cn
M202320876@xs.ustb.edu.cn
xujinglinlove@gmail.com
pengyuxin@pku.edu.cn
论文:
https://dl.acm.org/doi/abs/10.1145/3664647.3680642
代码:
https://github.com/PKU-ICST-MIPL/SIA-OVD_ACMMM2024
发表会议:ACM MM 2024
*通讯作者
1. 研究背景
开放词汇目标检测(Open-Vocabulary Object Detection)旨在检测训练数据以外的类别,实现任意类别的目标检测,突破传统目标检测只能检测数据集中已有类别对象的局限性。现有的开放词汇目标检测方法以两阶段(定位阶段+分类阶段)框架为主,定位阶段生成大量类别无关的候选区域,分类阶段通过图文预训练模型CLIP对候选区域进行开放词汇分类,实现任意类别的目标检测。然而,由于图像-区域差异问题,CLIP模型在大规模图像-文本数据上预训练,能够进行零样本图像分类,但用于区域分类时的准确率较低,导致开放词汇目标检测存在错误识别目标对象的问题。
2. 方法介绍
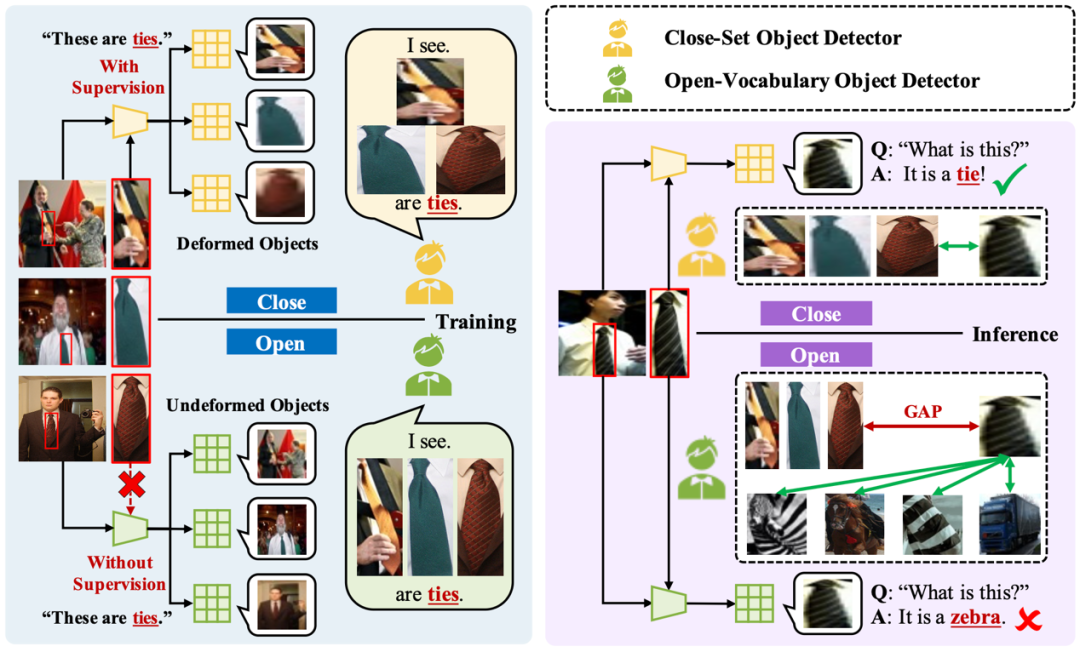
图1 开放词汇目标检测中图像-区域差异的成因
针对上述问题,本文首先分析了这种图像-区域差异的来源。实验发现检测框的形状对分类效果有明显的影响,例如对于“刀”、“领带”、“滑雪板”等细长形状的类别,CLIP的分类效果较差。本文认为RoIAlign在CLIP图像编码器提取的特征图上裁剪出候选区域(RoI)特征后,不同形状的RoI特征均被压缩到正方形,对于细长形状的RoI,其压缩程度更加严重,视觉特征被严重破坏。但CLIP预训练时提取整张图像特征,其中目标的形状压缩幅度有限,导致CLIP无法正确分类压缩后的区域。如图1所示,以“领带”为例,在开放词汇目标检测任务中,领带对应的RoI被大幅压缩,CLIP则类似于人眼,能够识别未压缩的区域,而压缩后的区域即使是人眼也难以分辨,因此被CLIP错误分类。
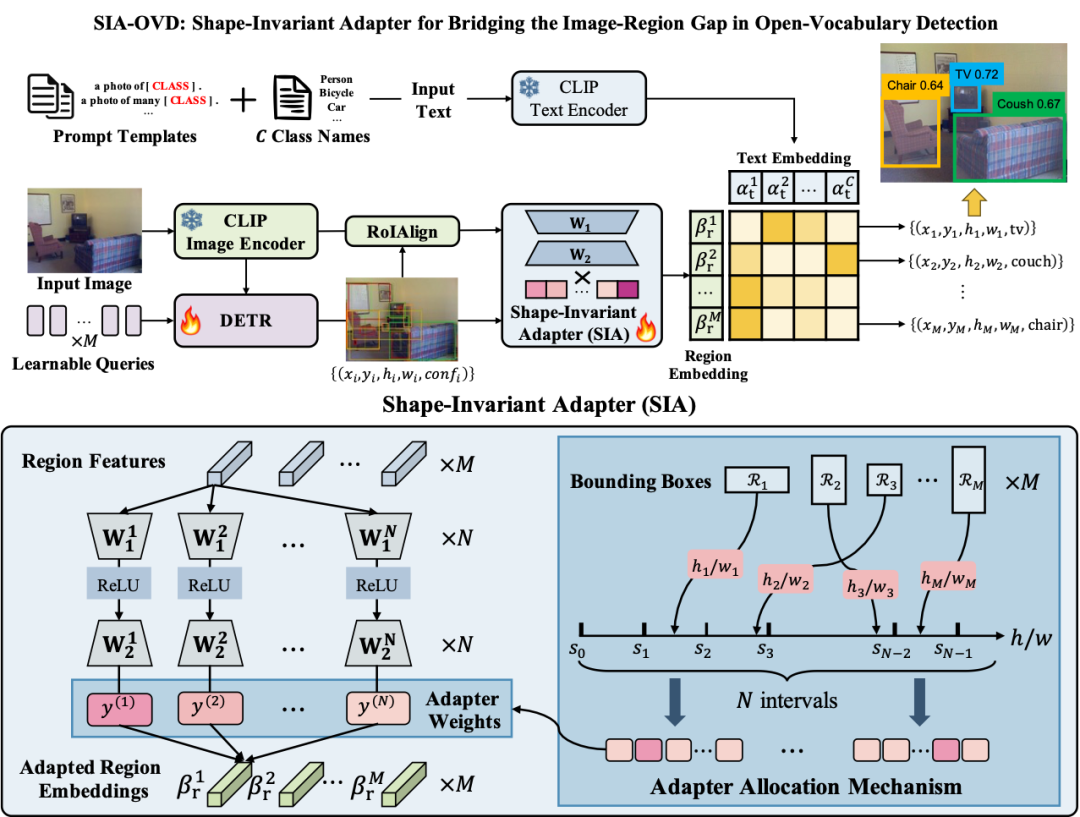
图2 开放词汇目标检测框架与形状不变性适配器结构图
因此,如图2所示,本文提出了一种形状不变性适配器,保持CLIP模型参数冻结以保持开放域性能,同时缓解上述图像-区域差异以提高对检测框的分类准确率。具体而言,维护由多个轻量级特征适配器网络组成的集合,其中每一个适配器处理检测框长宽比在一个固定范围内的区域特征,将其映射为预训练CLIP能够识别的未形变特征。每一个适配器只需要处理形状相似的RoI特征,在训练时面临的特征差异较小,因此能够避免受特征形变的干扰,使冻结的CLIP模型能够识别该区域内的目标物体类别。
3. 实验结果
本文主要在COCO-OVD评测基准上进行实验,从COCO数据集中选取了48个带检测框标注的类别(base)用于训练,选取另外17个类别(novel)用于测试,并在训练数据中移除这17个类别的检测框标注。如表1所示,本文方法在RN50、RN50x4两个骨干网络上,均达到了同期最优性能。此外,图3所示,与直接使用CLIP进行区域分类和CORA(CVPR 2023)相比,本文方法SIA对“冲浪板”、“领带”、“滑雪板”、“刀”等无检测框标注的细长形状物体实现了更准确的识别。
表1 在COCO-OVD评测基准上的实验结果
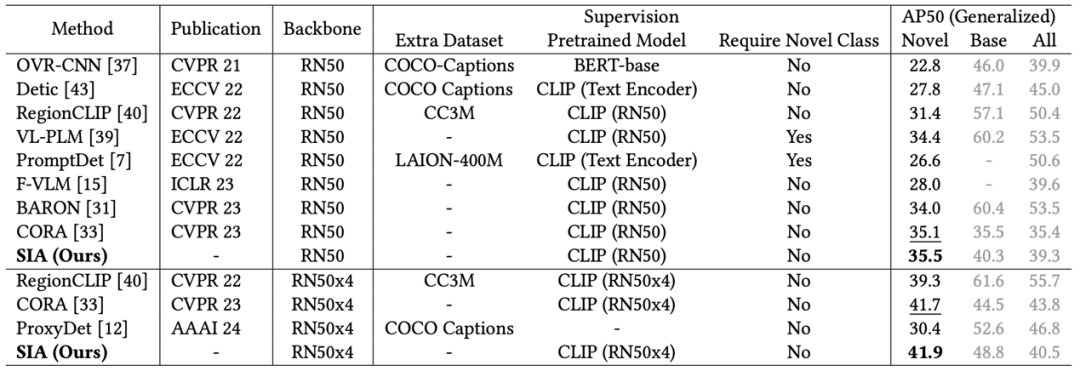
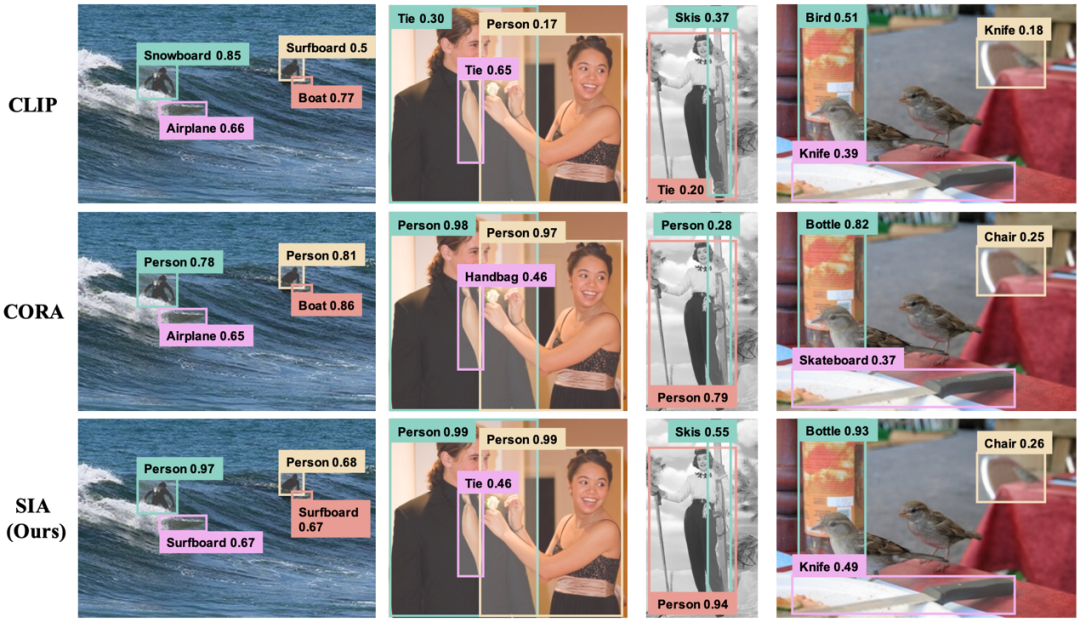
图3 对目标区域的分类结果对比图
02
ADDG: An Adaptive Domain Generalization Framework for Cross-Plane MRI Segmentation
作者:
马梓博1,张波1,张征1*,刘武2,王吴凡1,高慧1,王文东1*
单位:
1北京邮电大学 2中国科学技术大学
邮箱:
zma@bupt.edu.cn
zbo@bupt.edu.cn
zhangzheng@bupt.edu.cn
liuwu@ustc.edu.cn
wufanwang@bupt.edu.cn
gaohui786@bupt.edu.cn
wdwang@bupt.edu.cn
论文:
https://dl.acm.org/doi/abs/10.1145/3664647.3680632
发表会议:ACM MM 2024
*通讯作者
1.研究背景
多平面磁共振成像(multi-planar MRI)能够为疾病诊断提供准确的三维结构信息。受制于高昂的标注成本,使得开发适用于不同平面MRI的深度学习分割算法十分困难。为实现精准的多平面图像分割算法,一种思路是将其建模为域泛化(domain generalization)问题。如图1所示,不同于多站点(multi-site)MRI数据存在的站点间数据分布差异,多平面MRI间的数据分布差异是不同方向对相同个体的不同观测结果,是一种由特殊分布差异所导致的域泛化问题。为解决相关方法在跨平面MRI分割上表现不佳这一问题,本文提出了一种自适应域泛化分割架构ADDG,通过加入三维形状约束,显著减轻了不同平面MRI由于大切片间距导致的信息损失的影响;还通过自适应数据划分策略从不同站点的数据中捕捉与域无关特征,进一步增强了模型的泛化能力。
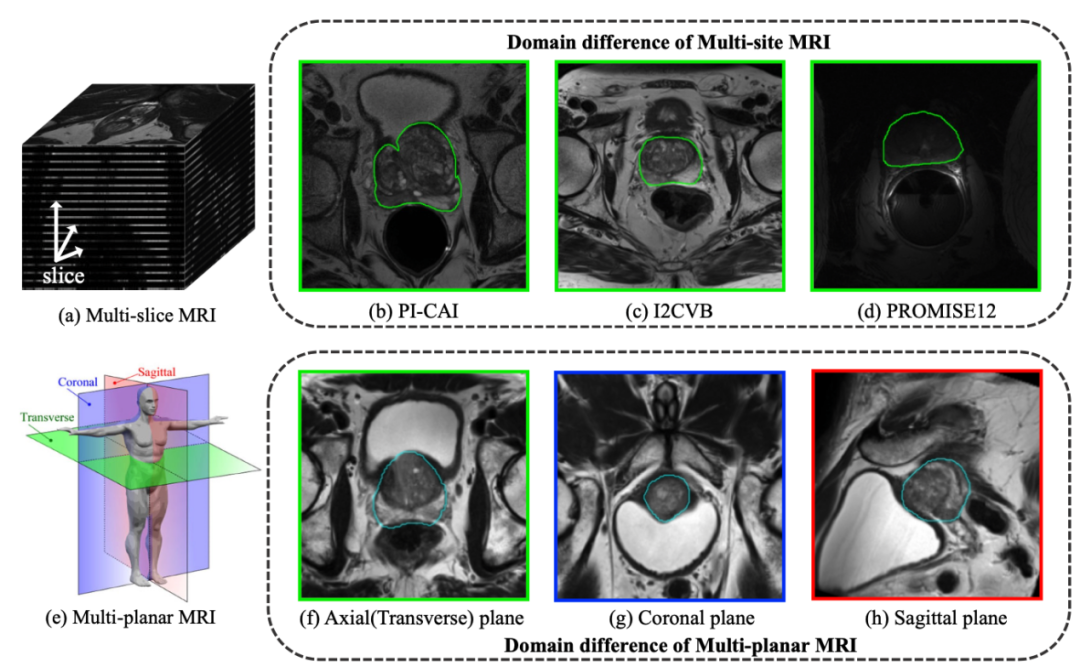
图1 问题说明
2.方法概述
ADDG框架旨在从未见过平面的MRI中分割目标器官(前列腺),如图2所示。ADDG由基于网格变形的器官分割网络(MDOS-Net)和无数据划分元学习(DPF-ML)训练策略组成。具体来说,MDOS-Net旨在从单平面MRI中更好地估计前列腺形状,而DPF-ML旨在通过充分利用多个机构的轴向平面MRI来捕获更多域无关的特征表示。
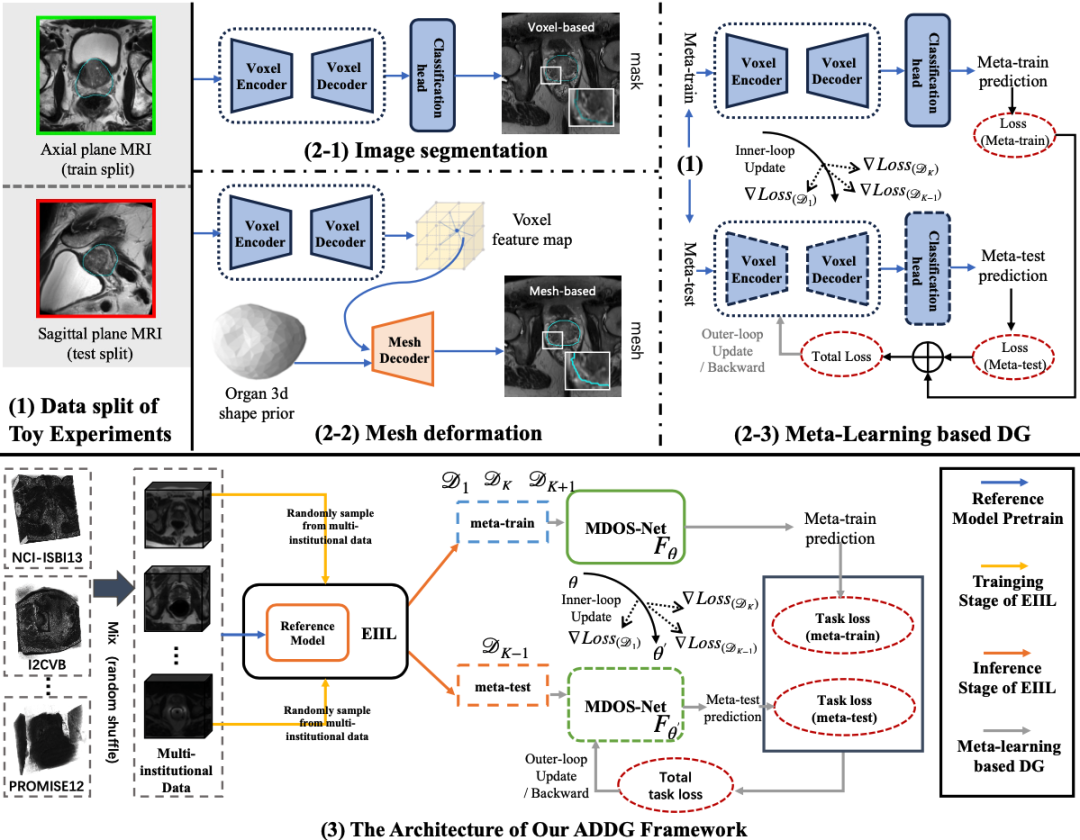
图2 ADDG总体框架图
为了更好地利用三维上下文信息来指导跨平面分割,本文基于轴向位MRI构建器官的三维网格模型,然后通过光栅化算法将三维网格转换为体素分割掩码。该思想受到Voxel2Mesh的启发,Voxel2Mesh即使从单平面MRI也具有很强的生成合理形状的能力。然而,Voxel2Mesh没有考虑到单平面MRI存在的各向异性,即切片间距通常比每个切片内单个像素代表的实际距离大得多。MRI的各向异性会造成模型过度拟合切片间的噪声,从而导致性能下降。因此,本文提出了MDOS-Net,它可以更好地利用三维MRI中的丰富信息,以实现更好的跨平面分割。如图3所示,该骨干网络由三部分组成:1)多路径2.5D分割网络,用于处理不同程度各向异性的数据;2)平面内目标边界分割网络,利用各向异性MRI的高分辨率二维图像切片来学习目标器官的二维边缘信息;3)三维三角形网格变形分支,用于精确生成目标器官的形状。
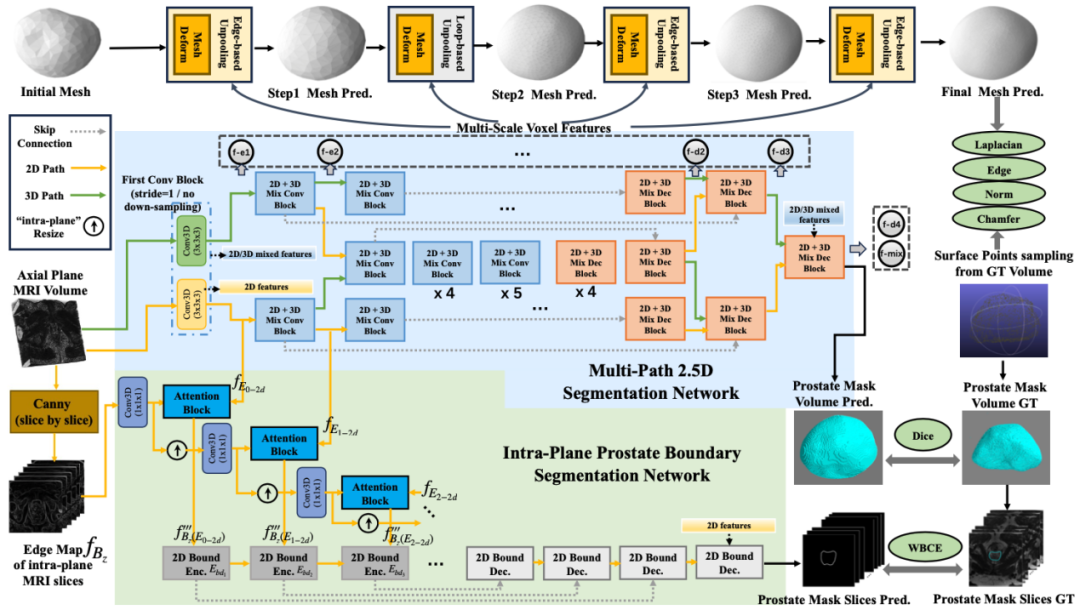
图3 MDOS-Net图
进一步地,受不变性学习方法EIIL的启发,本文提出了无数据划分元学习(DPF-ML),以打破MLDG中由于固定的数据划分标准(既不手动预定义不同的域,也不从多站点训练集中随机采样数据以获得元训练和元测试分割的数据划分)而对多站点医学图像中包含的各种潜在数据分布的忽视。然后,基于不变学习理论对更多潜在的数据分布漂移进行建模,将MLDG的数据划分过程转变为一个可学习的过程,这使得MLDG能够学习更广泛的域无关特征。
3.实验结果
在前列腺多平面MRI数据集PROSTATEx上开展了跨平面MRI分割实验(轴向位作为训练和验证集,矢状位和横断位作为测试集)。结果表明,ADDG相较于其他医学图像分割方法以及域泛化分割方法有着更优的跨平面分割效果。
表1 ADDG与其他相关方法的定量结果评估
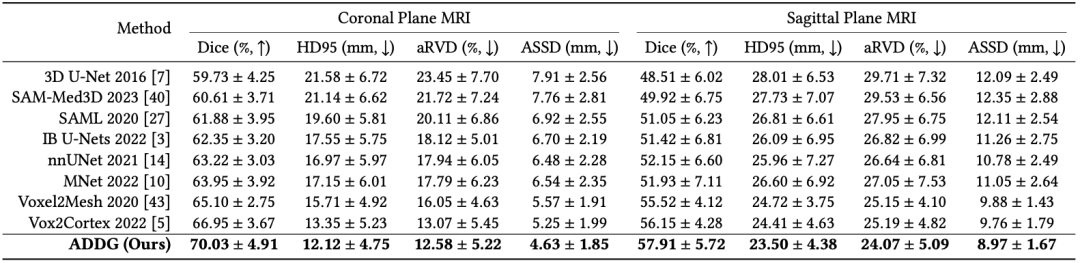
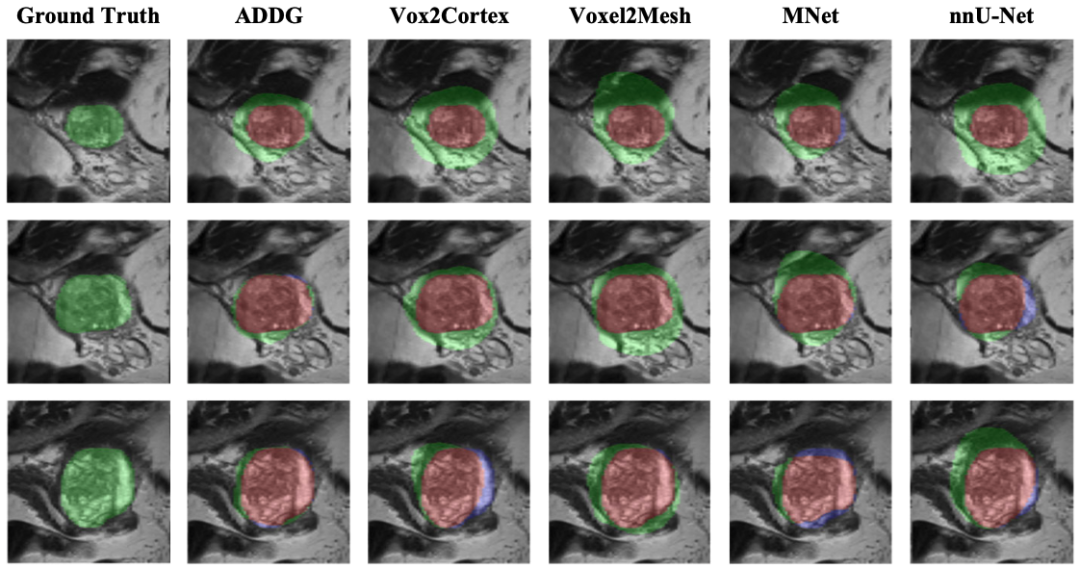
图4 ADDG与其他相关方法的部分定性结果比较(以横断位MRI为测试集)
4.总结
本文提供了一种有关跨平面医学图像分割的泛化问题新颖设定,并针对性地提出了一种基于单视角三维物体重建的跨平面图像分割方法,能够实现精准的跨平面3D MRI器官分割。
03
Anatomical Prior Guided Spatial Contrastive Learning for Few-Shot Medical Image Segmentation
作者:
黄文东1, 胡晋武2, 毕秀丽1,肖斌1,*
单位:
1重庆邮电大学 2华南理工大学
邮箱:
D220201013@stu.cqupt.edu.cn
202310189376@mail.scut.edu.cn
bixl@cqupt.edu.cn
xiaobin@cqupt.edu.cn
论文:
https://dl.acm.org/doi/abs/10.1145/3664647.3680558
发表会议:ACM MM 2024
*通讯作者
1.研究背景
小样本语义分割在低数据场景中具有巨大潜力,尤其对于需要专家级密集标注的医学图像而言。现有的小样本医学图像分割方法主要通过原型学习来处理该任务。然而,这种方案依赖支持原型来指导查询图像的分割,忽略了医学图像中丰富的解剖先验知识,这阻碍了对医学图像进行有效的特征增强。本文提出了一种解剖先验引导的空间对比学习方法(APSCL),该方法利用从医学图像中提取的解剖先验知识,从空间角度构建对比学习,用于小样本医学图像分割。
2.方法概述
APSCL的整体框架如图1所示,其中包含两个关键步骤:
1)基于分布一致性的解剖先验生成
受LDM中分布正则化的启发,我们从正则化的角度寻求减少输入样本的潜在嵌入空间与相应标签之间的分布差异。具体来说,我们首先使用特征编码器和标签编码器分别将输入样本和标签映射到潜在嵌入变量。之后,可以通过参数变分的方式推断近似后验分布。通过正则化输入样本与其标签之间的分布差异,可以捕捉到要分割的解剖结构知识,即解剖先验。
2)基于解剖先验的特征增强
为了更好地引导解剖目标的激活,受FiLM的启发,我们设计了带有解剖先验的特征增强模块(FEM)。该模块旨在根据从解剖近似后验概率分布中采样的数据,对嵌入特征进行仿射变换,以实现特征增强。用于仿射变换的缩放和平移因子由潜在因子预测。
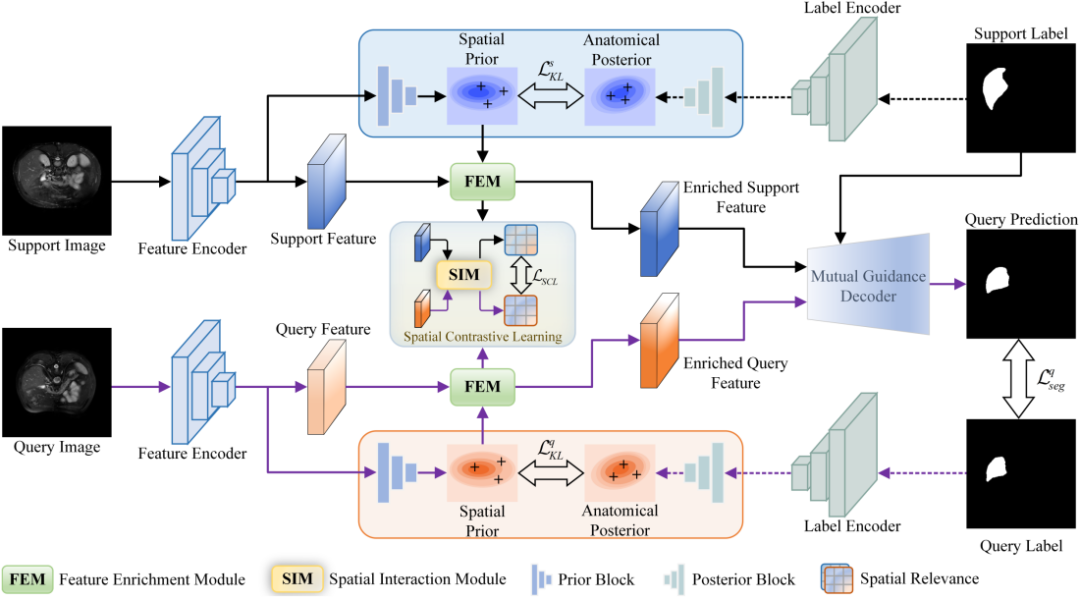
图1 解剖先验引导的空间对比学习框架图
3.实验结果
在三个公共数据集(如CHAOS-T2、MS-CMRSeg和Synapse)上的实验展示了本框架的优越性,例如,在CHAOS-T2数据集上,在Liver、LK、RK和Spleen四种器官类别上分别提高了最新记录的+3.65%、+4.65%、+2.12%和+4.03%。具体结果见表1。
表1 在三个数据集上的分割结果对比
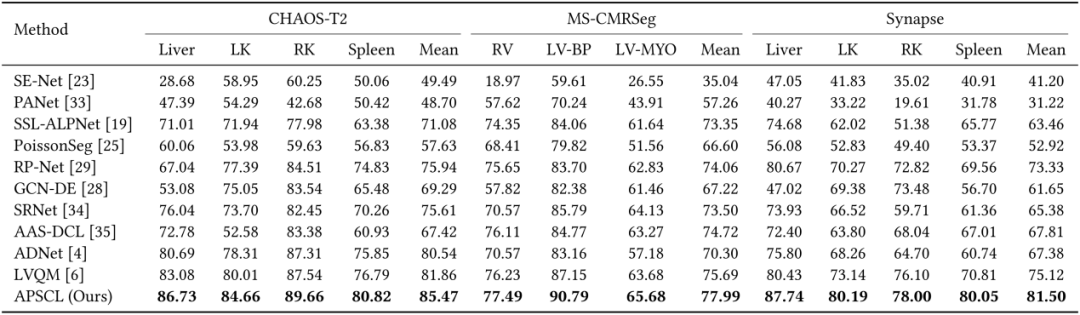
图2展示了各种方法在腹部器官分割任务评估中的视觉结果,反映出本文的方法可以为复杂背景下具有各种强度、尺度和形态的器官提供了理想的分割掩码。
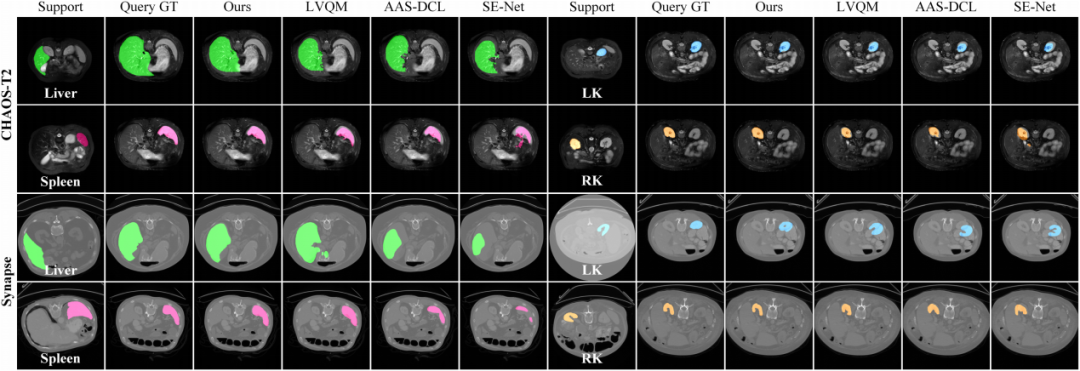
图2 CHAOS-T2和Synapse两个数据集上的腹部器官分割结果可视化
4.总结
本文提出了解剖先验引导空间对比学习框架(APSCL),旨在解决极端低数据条件下具有挑战性的医学图像分割任务。我们的框架充分利用医学图像中的解剖先验信息,从空间视角构建对比学习机制以增强学习特征的可区分性。此外,通过设计互导解码器,我们充分利用支持样本的引导信息,从而获得更精确的分割结果。实验结果表明,APSCL在三个常用的医学基准数据集上取得了最先进的性能。
04
MTSNet: Joint Feature Adaptation and Enhancement for Text-Guided Multi-view Martian Terrain Segmentation
作者:
方阳1,饶雪锋1,高新波1*,李伟生1,闵子剑2
单位:
1重庆邮电大学 2韩国仁荷大学
邮箱:
fangyang@cqupt.edu.cn
s220231077@stu.cqupt.edu.cn
gaoxb@cqupt.edu.cn
liws@cqupt.edu.cn
minzijian@inha.edu
论文:
https://doi.org/10.1145/3664647.3681430
发表会议:
ACM MM 2024
*通讯作者
1.研究背景
火星地形分割(Martian Terrain Segmentation)在火星车的自主导航、安全行驶以及火星全球地质地貌分析中扮演着关键角色。传统的基于深度学习的语义分割方法在应对火星表面高度非结构化的地形环境时,往往表现出适应性不足和泛化能力有限的问题。为此,本文提出了一种新颖的多视角火星地形分割框架(MTSNet),通过引入火星地形文本引导的SAM(Segment Anything Model)适配器(MTG-SAM) 和局部地形特征增强网络(LTEN),实现全局与局部特征的协同建模,显著提升了多视角火星地形的分割精度。
2.方法概述
本文提出的“多视角火星地形分割框架”主要由带地形上下文注意力适配模块的SAM编码器、局部地形特征增强网络、门控融合模块(GFM)和文本提示编码器组成。具体架构如图1所示。
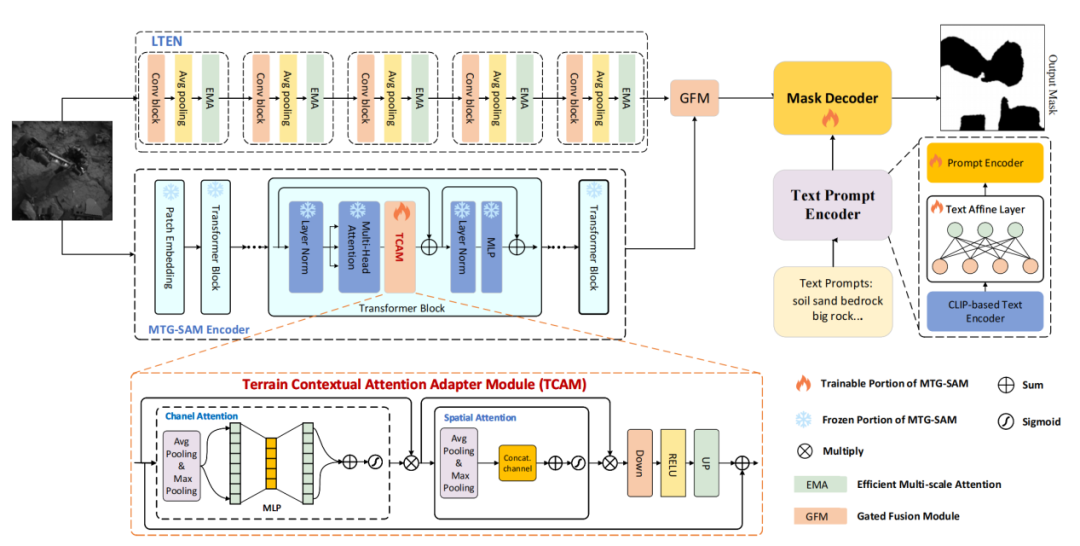
图 1 多视角火星地形分割框架
地形上下文注意力适配器模块是一个轻量级的适配器模块,插入到SAM的ViT(Vision Transformer)编码器中,通过通道-空间注意力机制,增强了模型的跨域适应能力。
局部地形特征增强网络由一组局部地形特征增强模块堆叠组成,如图2所示。该网络主要提取细粒度地形特征,利用多尺度注意力机制处理从小沙砾到大岩石等不同尺度的地形特征。
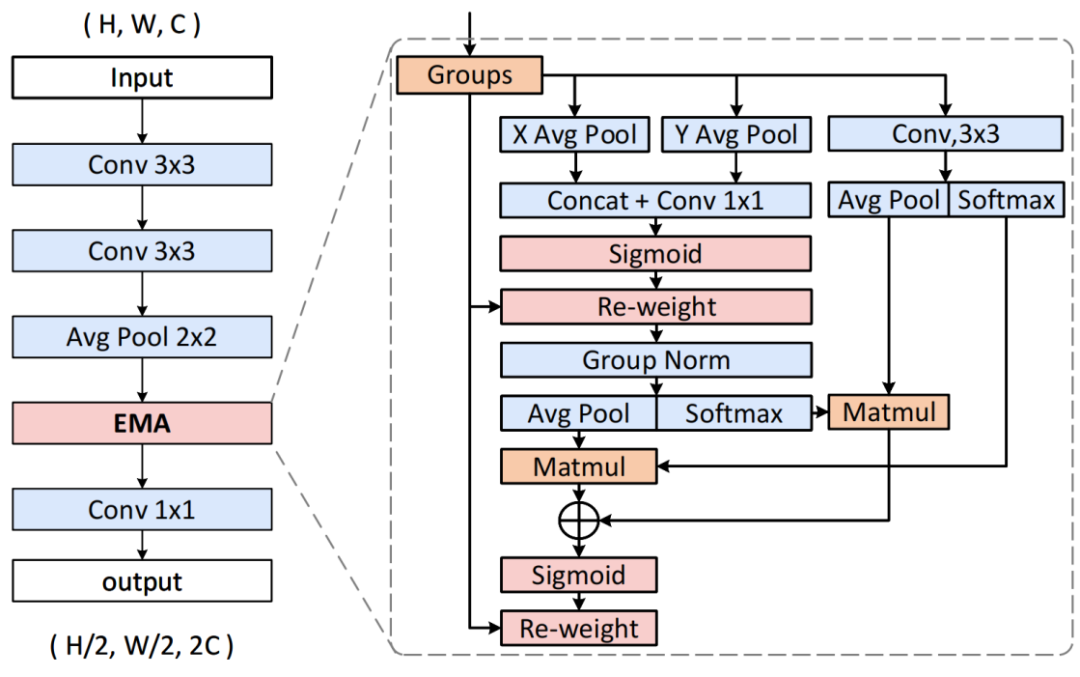
图 2 局部地形特征增强模块
在融合SAM编码器与LTEN提取的特征时,本文设计了一个门控融合模块。该模块通过自适应门控机制融合全局与局部特征,避免冗余,增强分割的鲁棒性。
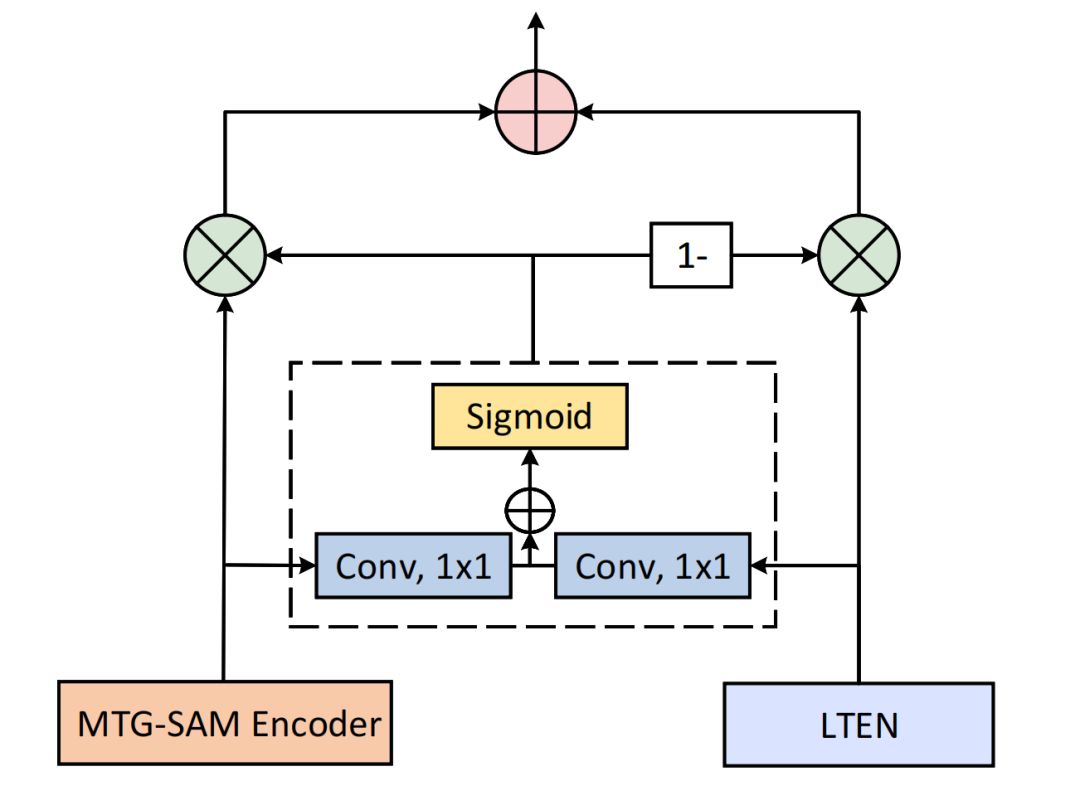
图 3 门控融合模块
当下SAM的应用依赖点框作为提示词,本文创新性地引入了一种文本提示编码器,其通过可学习的适配层,将CLIP(Contrastive Language-Image Pre-training)的通用文本特征转化为火星地形专用表征,使模型能够仅凭文字指令(如“土壤”、“基岩”)即可完成精准分割,减少了对昂贵人工标注(如框、点提示)的依赖。
3.实验结果
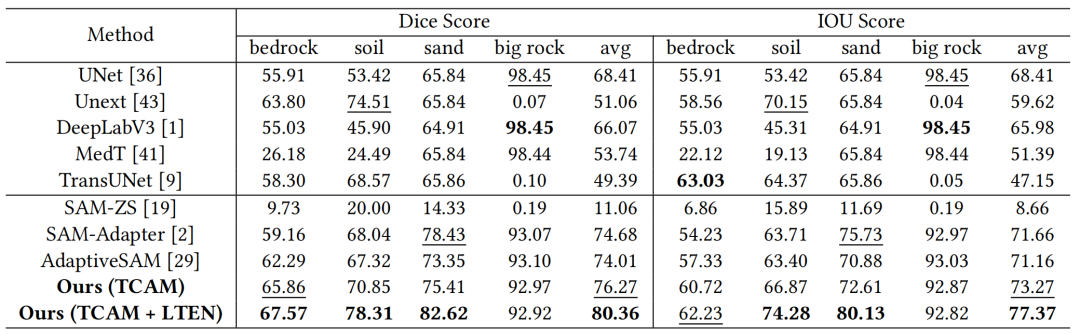
本文在AI4Mars与ConeQuest两大火星数据集上验证了MTSNet的有效性。如表1所示,MTSNet在AI4Mars上平均IoU达到77.37%,显著超越所有对比模型;
表 1 在AI4Mars数据集上的结果
在ConeQuest的HP(Hypanis)区域Pixel Recall指标提升6.78%,展现出较强的跨区域泛化能力。
表 2 在ConeQuest数据集的HP区域的结果
消融实验进一步证明,文本适配层(TAL)和门控融合模块(GFM)等核心模块均为性能提升做出关键贡献。
表 3 部分消融实验

可视化结果如图4显示,本方法能够更精准地捕捉火星地形细节,显著减少误分割与漏分割。

图 4 不同方法在ConeQuest数据集上的结果
4.总结
本文提出的MTSNet通过轻量化适配、局部特征增强与门控融合,有效实现了火星地形与非结构化地貌的精准分割,在火星车及卫星遥感数据上达到了领先性能,未来将进一步轻量化模型并拓展应用。
05
Distilled Cross-Combination Transformer for Image Captioning with Dual Refined Visual Features
作者:
胡钧博1,2,李志欣1,2*
单位:
1教育区块链与智能技术教育部重点实验室
2广西多源信息挖掘与安全重点实验室
邮箱:
hujb@stu.gxnu.edu.cn
lizx@gxnu.edu.cn
论文:
https://dl.acm.org/doi/10.1145/3664647.3681161
发表会议:ACM MM 2024
*通讯作者
1、研究背景
图像描述生成是计算机视觉与自然语言处理的交叉研究领域,其旨在通过让机器自动地理解图像内容,生成与之紧密相关的自然语言描述,它是一项具有挑战性的跨模态数据分析任务。对于目前图像描述任务用于编码区域特征和网格特征的基于Transformer的编码器已经屡见不鲜,因为它的多头自注意力机制,编码器可以更好地捕捉到图像中不同区域之间的关系和上下文信息。然而,由于Transformer块的堆叠,视觉特征会经过自注意力进行反复计算,这不仅使Transformer的自注意力机制计算了许多冗余的特征,而且增大了计算开销。同时,对于基于Transformer的解码器的交叉注意力模块的一些融合方式,如顺序融合、级联融合等方法,这些方法不能充分利用区域特征和网格特征之间的相关性和互补性。
2、方法概述
本文提出了一种新颖的蒸馏交叉融合Transformer模型(Distilled Cross-Combination Transformer , DCCT),使得图像描述生成更加的高效和准确。在编码阶段,本文提出了蒸馏级联融合编码器(Distillation Cascade Fusion Encoder, DCFE),通过过滤冗余的视觉特征使得注意力更多的聚焦在重要的特征上面,从而得到更加精炼的特征表示。在解码阶段,本文提出了一种新颖的并行交叉融合注意力模块(Parallel Cross-Fusion Attention, PCFA),该模块将处理后的网格特征与区域特征进行交叉关注,充分将利用了区域特征和网格特征之间的相关性和互补性,之后再通过门控机制调整两种多模态特征对描述生成的重要性和贡献程度,使模型能够更好地利用不同特征的信息,实现全面的多模态信息融合。其中图1展示了本文提出的蒸馏级联融合Transformer模型的整体框架图。
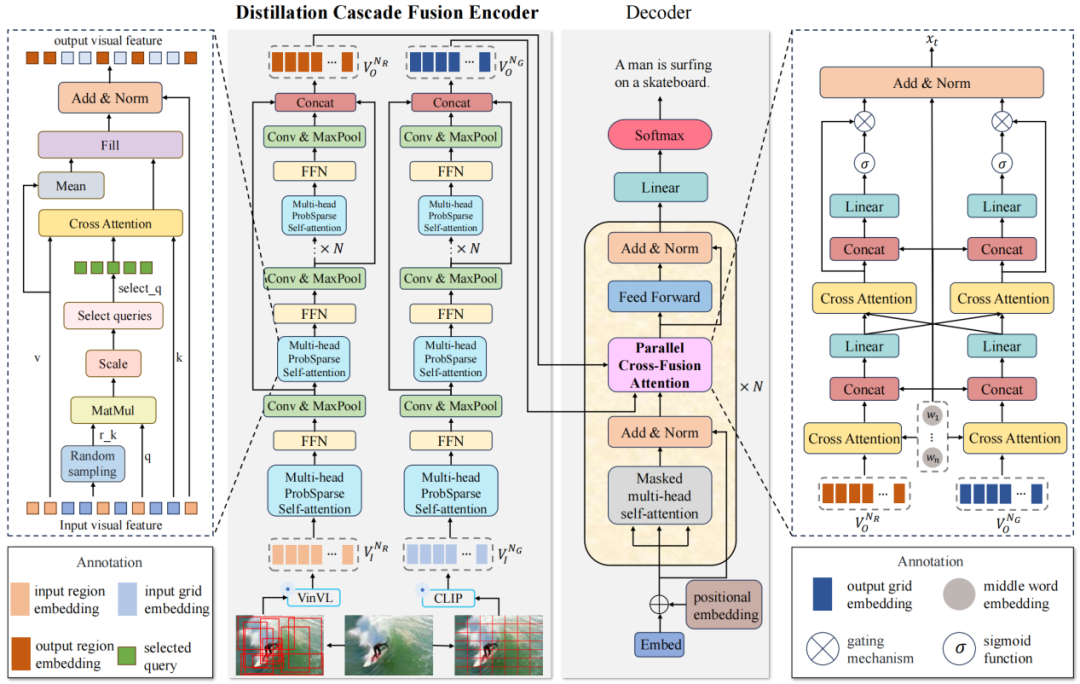
图1 蒸馏级联融合Transformer模型的整体框架图
3、实验结果
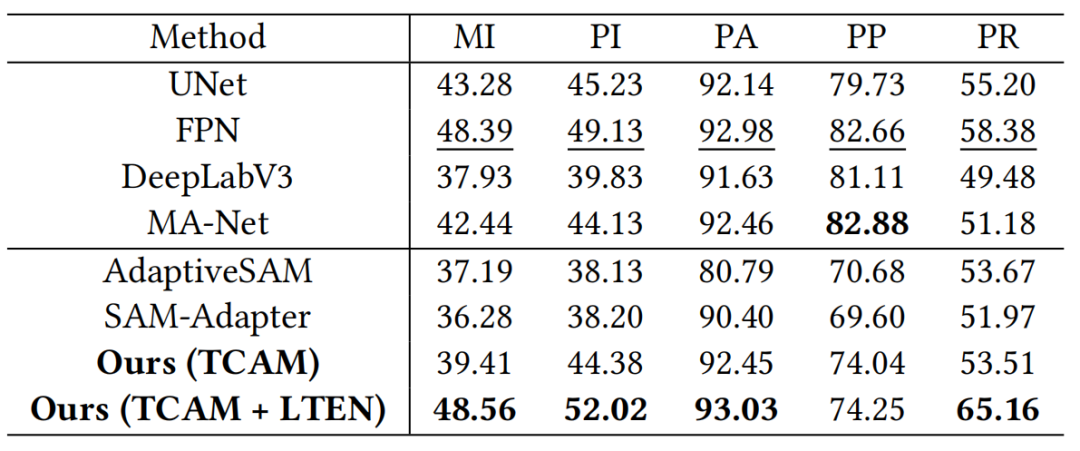
表1展示了DCFE和PCFA是如何影响DCCT在MS COCO数据集的整体性能。可以看到,当在基准模型上配备了DCFE和PCFA之后,CIDEr取得了最佳性能127.5%。
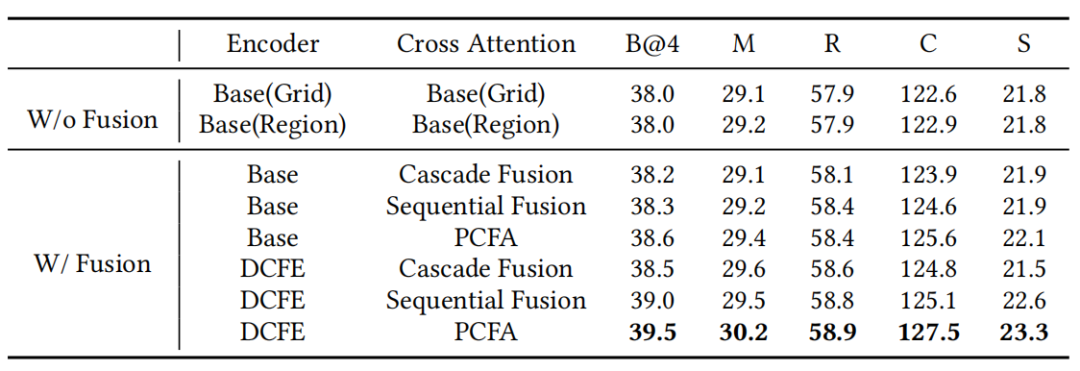
表1 本文提出的方法在在MSCOCO Karpathy 测试集划分上的消融实验结果
表2展示了本文的方法与最先进的方法在MSCOCO Karpathy 测试集划分上的性能比较。可以看到,本文的方法在大多数指标上均表现出优异的性能,尤其在CIDEr指标上达到了141.7%。
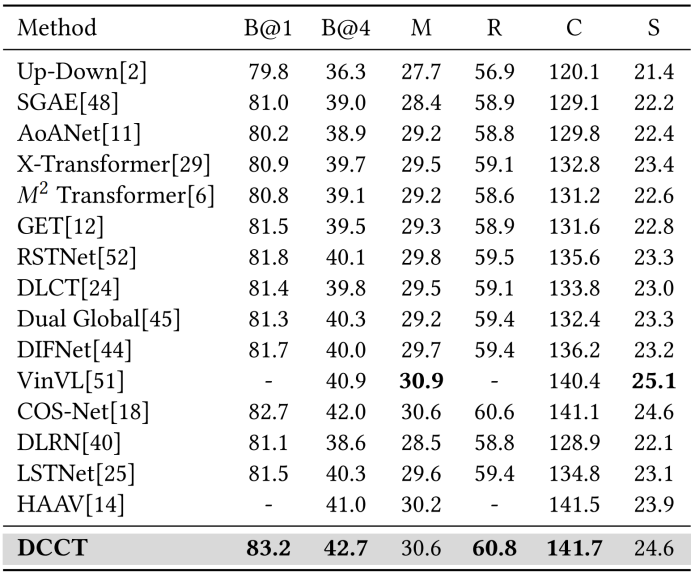
表2 不同方法在 MSCOCO Karpathy测试集划分上的有效性
图2展示了本文提出的模型DCCT和Transformer基线生成的描述语句示例,以及人类注释的基本事实句子(Ground-Truth, GT)。可以看到,在第二个例子中,由于基线模型无法对一些冗余特征进行过滤,无法对细粒度信息进行捕捉,导致生成错误的关键描述词“balloons”,而DCCT生成的与GT相同为“kites”。同时,通过补充网格特征来弥补区域特征的缺点,DCCT获取了更精确的位置信息和细粒度信息,比如第一个示例中的“next to”和第四个示例中的“broccoli”。

图2 本文提出的模型DCCT和Transformer基线生成的描述语句示例

编辑人:吴建龙、任文琦
专委会责任副主任:张勇东
 京公网安备11010802017125号
京公网安备11010802017125号