
【论文导读】2025年论文导读第二十期
【论文导读】2025年论文导读第二十期


论文导读
2025年论文导读第二十期(总第一百三十七期)
目 录
|
1 |
Multi-Granularity Hand Action Detection |
|
2 |
ConsistentAvatar: Learning to Diffuse Fully Consistent Talking Head Avatar with Temporal Guidance |
|
3 |
Self-Supervised Emotion Representation Disentanglement for Speech-Preserving Facial Expression Manipulation |
|
4 |
Scalable Multi-view Unsupervised Feature Selection with Structure Learning and Fusion |
|
5 |
NovaChart: A Large-scale Dataset towards Chart Understanding and Generation of Multimodal Large Language Models |
01
Multi-Granularity Hand Action Detection
作者:
哲婷1,张敬1,李永乾1,罗勇1*,胡晗2,陶大程3
单位:
1武汉大学计算机学院
2北京理工大学
3南洋理工大学
邮箱:
zheting@whu.edu.cn
jingzhang.cv@gmail.com
yongqianli@whu.edu.cn
luoyong@whu.edu.cn
hhu@bit.edu.cn
dacheng.tao@ntu.edu.sg
论文:
https://doi.org/10.1145/3664647.3680723
代码:
https://github.com/superZ678/MG-HAD
发表会议:ACM MM 2024
*通讯作者
1. 研究背景
随着视频理解领域的快速发展,人类动作检测(Action Detection)在人机交互、智能家居、智慧医疗以及机器手设计与控制等场景中具有广泛的应用价值。然而,现有研究多聚焦于人类全身性或粗粒度动作,对细粒度手部动作的关注度严重欠缺。特别是在厨房等真实场景中,在手与物体的交互过程中蕴含大量的细粒度语义信息,例如“左手把住刀柄”,“右手按压西红柿”,“刀身切西红柿”等。然而,传统检测方法难以捕捉手部交互动作中的多维细粒度语义信息,导致手部动作检测工作停滞不前。为弥补这一研究领域空白,我们针对手部动作提出了一个新的挑战——多粒度手部动作检测,构建了全新的手部动作数据集FHA-Kitchens(Fine-Grained Hand Actions in Kitchen Scenes),并设计了专属的手部动作检测模型MG-HAD(Multi-Granularity Hand Action Detection),以实现对多粒度手部动作的准确识别和精准定位。
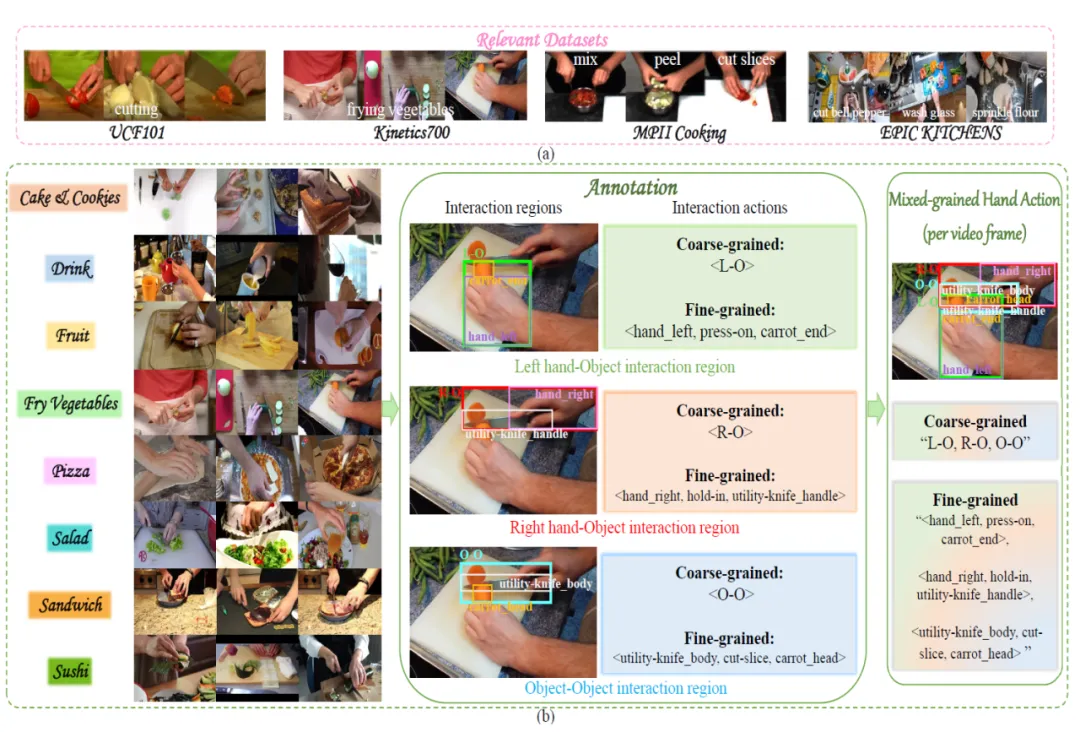
图1 FHA-Kitchens 数据集概述
2. 方法概述
为了填补现有工作空白,我们从两方面开展工作:构建丰富细粒的手部动作数据集和设计专属的多粒度手部动作检测模型。
(一)首先,构建FHA-Kitchens数据集,聚焦厨房真实场景中丰富的手部交互动作,包含了2,377 video clips,30,047 video frames,涵盖8种经典菜系制作场景(见图1(b)左)。我们提出“交互区域 + 交互类别”双层细粒度标注方案(见图1(b)中),(i)手部交互区域:将交互区域细化为左手-物体(L-O)、右手-物体(R-O)、物体-物体(O-O)三类区域;(ii)手部交互类别:将动作类别表示为三元组<Subject, Action verb, Object> (<s,a,o>),每一维精细化到具体接触部位(如 “carrot_end”)。最终构建880个粗-细粒度动作类别、涵盖9个语义维度的877个细粒度三元组类别,实现手部动作在位置与语义上的精确对齐。
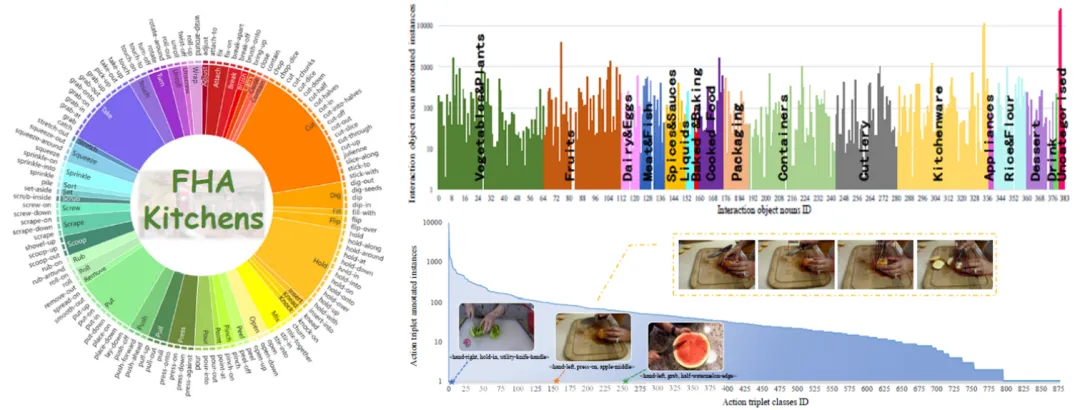
图2 FHA-Kitchens数据集的标注数据分布情况
(二)其次,我们创新性提出MG-HAD模型(见图3)。作为首个面向多粒度手部动作的检测基线。MG-HAD 由视觉骨干网络、Transformer 编码-解码结构与多分支预测头构成,并包含两个创新性设计:(i)多维度动作查询,我们将解码器查询从单一维度语义扩展至多维度,并设计内容查询重组模块(CQR)生成三个关注不同动作维度的查询集合,作为解码器输入;(ii)粗-细粒度对比降噪训练方式,通过构建粗-细粒度样本查询并引入标签的对比去噪策略,引导模型区分不同粒度的动作类别。
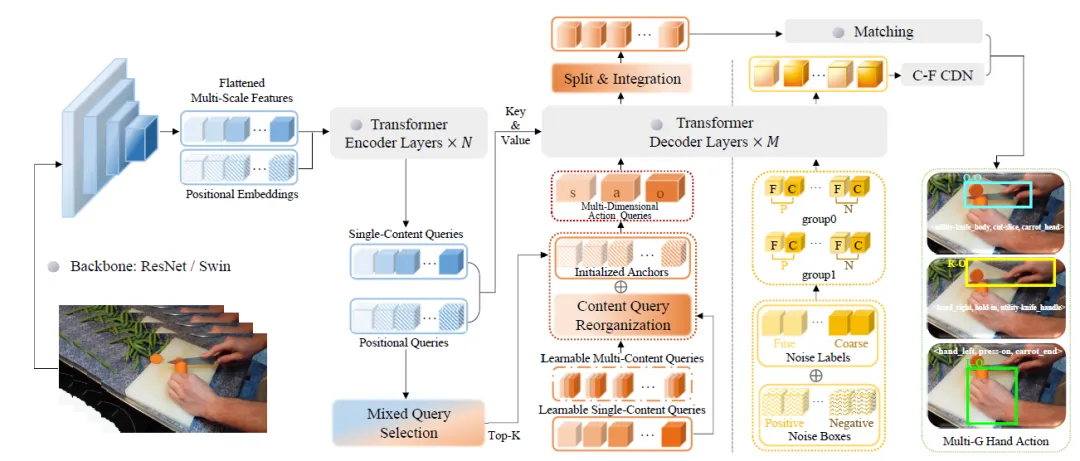
图3 MG-HAD总体框架图
3. 实验结果
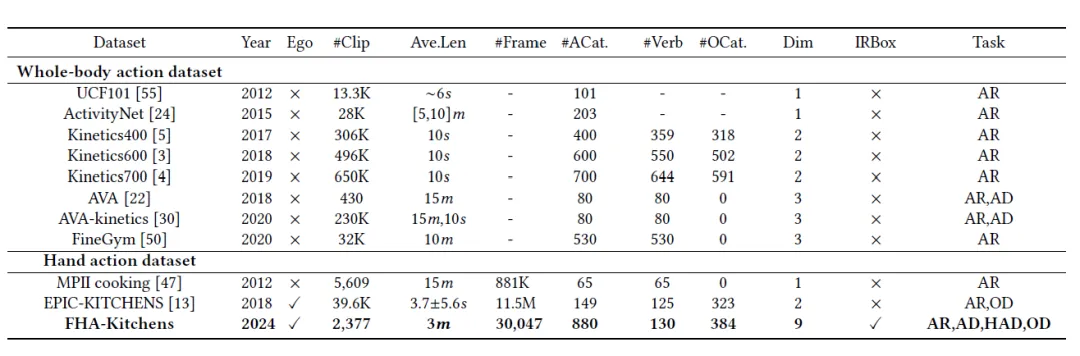
如表1所示,我们从 2,377 段视频中提取出 30,047 视频帧进行手部动作的细粒度标注,最终得到880个动作类别(包含877个动作三元组)、130个动作动词以及 384个交互对象名词。
表1 数据集统计数据对比
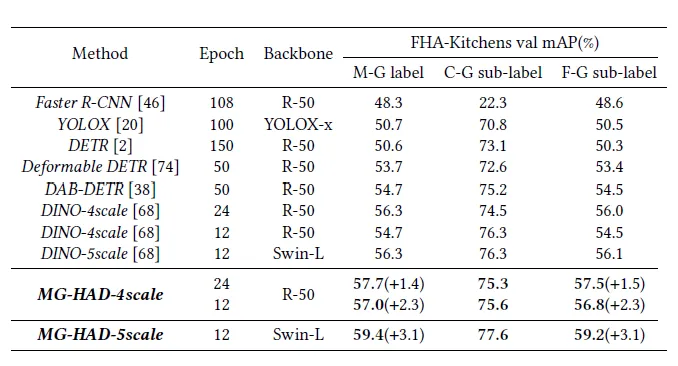
我们在FHA-Kitchens数据集上,与多种当前最先进(SOTA)的检测方法进行了对比评估。表2的结果表明,相比现有检测方法,我们的方法在混合粒度和细粒度类别上均取得了显著地性能提升,特别是在 5-scale Swin-L 骨干下,相比DINO-5scale,我们的方法仅训练12 epoch,就在混合粒度动作上取得了59.4 AP,其中,细粒度动作精度提高+3.1 AP,粗粒度动作提高 +1.3 AP。
表2 MG-HAD与其他SOTA模型的对比结果
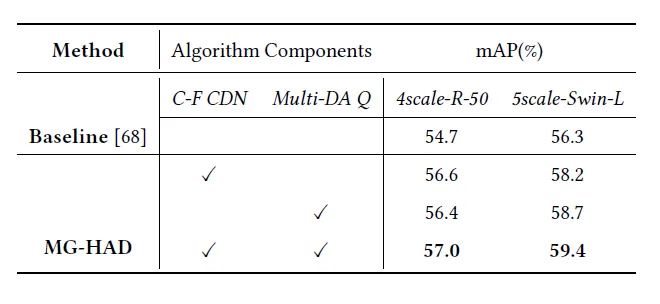
消融实验结果表明,MG-HAD中的多维动作查询与粗-细粒度对比去噪的设计在 ResNet-50与Swin-L骨干上均显著超越了DINO 基线性能,且两者结合又进一步增强了检测效果,验证了其在细粒度手部动作理解上的互补性与有效性。
表3 消融实验结果
可视化结果如图4所示,我们随机抽取4种厨房场景,并可视化展示了MG-HAD对复杂多粒度手部动作的精准检测能力。

图4 可视化结果
4.总结
本文首次提出对多粒度手部动作检测展开深入研究,并构建丰富细粒的手部动作数据集FHA-Kitchens和专属的MG-HAD模型,通过双重创新设计不仅有效提升了细粒度手部动作的检测性能,还能稳健面对多粒度动作场景,为手部动作理解领域提供了超高价值的数据基准与基线参考。
02
ConsistentAvatar: Learning to Diffuse Fully Consistent Talking Head Avatar with Temporal Guidance
作者:
杨海杰1,张振宇2,*,唐浩3,钱建军1,杨健1,*
单位:
1南京理工大学
2南京大学
3北京大学
邮箱:
yanghaijie@njust.edu.cn
zhangjesse@foxmail.com
bjdxtanghao@gmail.com
csjqian@njust.edu.cn
csjyang@mail.njust.edu.cn
论文:
https://arxiv.org/abs/2411.15436
project page:
https://njust-yang.github.io/ConsistentAvatar.github.io/
发表会议:ACM MM 2024
*通讯作者
1.研究背景
现有的说话头部生成方法(如基于3DMM、GAN、NeRF或扩散模型的方法)在生成质量上已有很大提升,但仍存在时间抖动、3D不一致、表情不准确等问题。扩散模型虽然在图像生成上表现出色,但直接应用于视频序列时难以保证帧间一致性。多模态条件(如法线图、情感标签)的引入虽然有助于控制生成过程,但其本身的不准确性会干扰生成结果。
2.方法概述
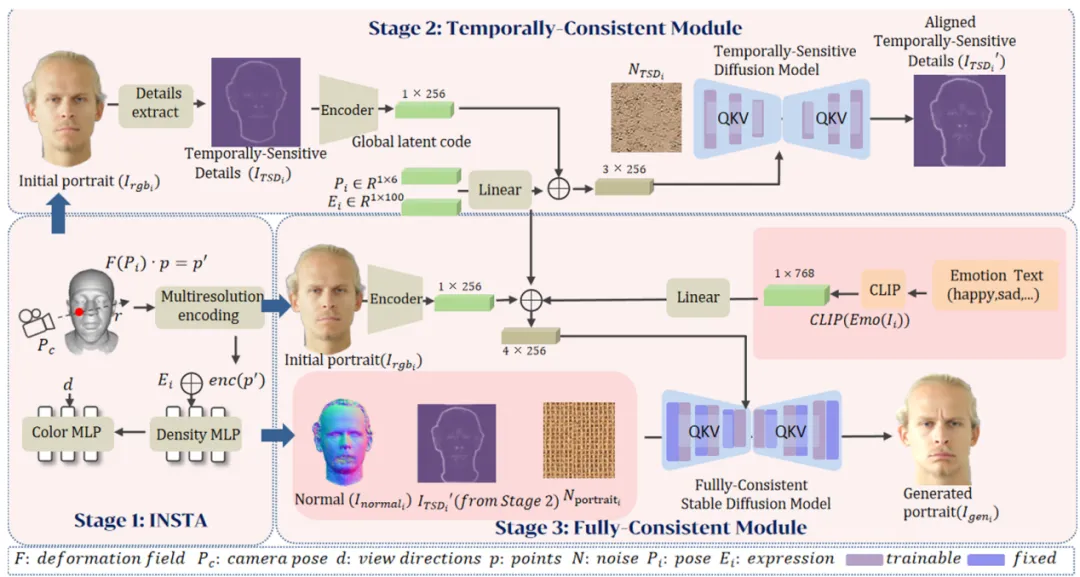
ConsistentAvatar 是一个基于扩散模型的说话头部生成框架,旨在实现时序、3D和表情的完全一致性。方法分为三个阶段:
初始生成(Stage 1)
使用 INSTA 方法从输入视频中生成粗糙的 RGB 图像和法线图。
时间敏感细节对齐(Stage 2)
提出 Temporally-Sensitive Detail (TSD)图,通过傅里叶变换从粗糙RGB图像和真实帧中提取高频细节和轮廓。使用一个时序一致性扩散模型将粗糙TSD对齐到真实的TSD,以捕获帧间稳定特征。
完全一致性生成(Stage 3)
将对齐后的TSD、粗糙法线图和情感嵌入作为条件,输入到一个完全一致性扩散模型中。使用 ControlNet 结构融合多模态条件,生成高质量、一致的说话头部图像。引入LCM(Latent Consistency Model) 和SDXL Refiner加速推理并提升图像质量。
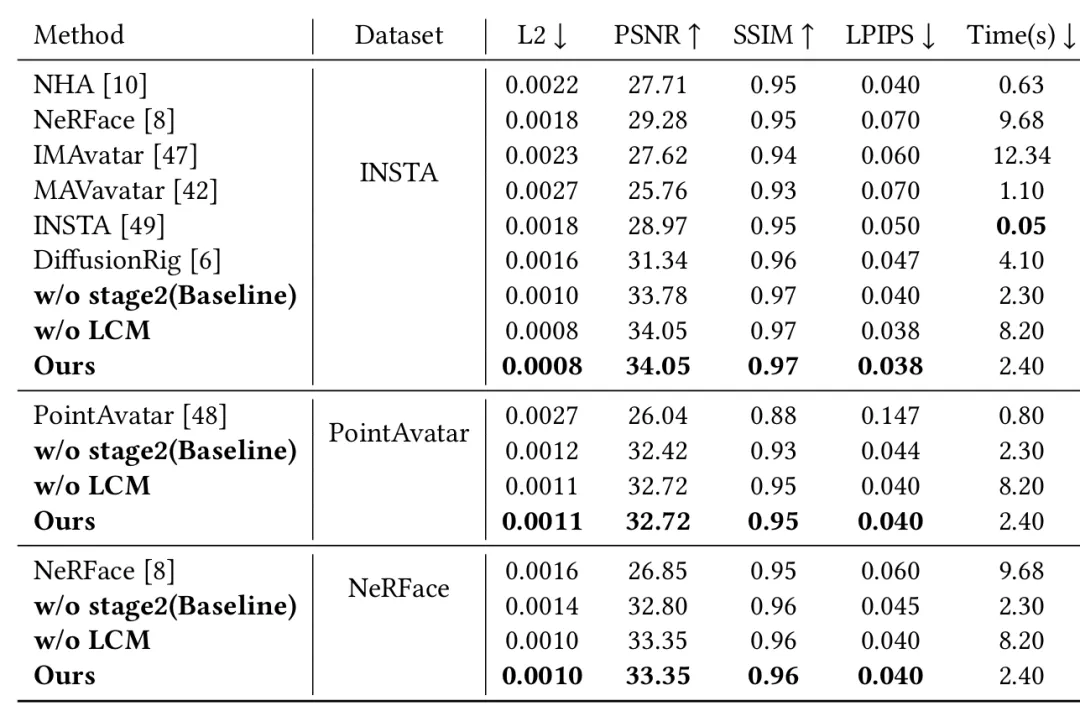
3.实验结果
在多个数据集上(INSTA、PointAvatar、NerFace)均取得最优的 PSNR、SSIM、LPIPS、L2 Loss。生成的图像细节更丰富(如皱纹、眼镜框),更接近真实图像,一致性更好。

图1 图像生成细节质量对比
表1 图像生成质量、效率指标对比
03
Self-Supervised Emotion Representation Disentanglement for Speech-Preserving Facial Expression Manipulation
作者:
徐志华1,陈添水1,杨志景1*,青春美2,施煜凯1 ,林倞3
单位:
1广东工业大学
2华南理工大学
3中山大学
邮箱:
zihua@mail2.gdut.edu.cn
tianshuichen@gmail.com
yzhj@gdut.edu.cn
qchm@scut.edu.cn
ykshi@gdut.edu.cn
linliang@ieee.org
论文:
https://dl.acm.org/doi/10.1145/3664647.3681017
发表会议:ACM MM 2024
*通讯作者
1.研究背景与问题
在视频内容生成与编辑中,语音保持的面部表情操纵(SPFEM) 是一个重要且具有挑战性的任务。其目标是在不改变说话者口型与语音同步的前提下,仅调整其面部表情以传达目标情感。传统方法面临两大瓶颈:
1.情感表示不足:难以从参考图像中准确提取并迁移复杂的情感信息;
2.缺乏对齐的成对数据:同一说话者在不同情感下说同一句话的视频帧难以严格对齐,导致缺乏直接的监督。
2.核心思想与创新
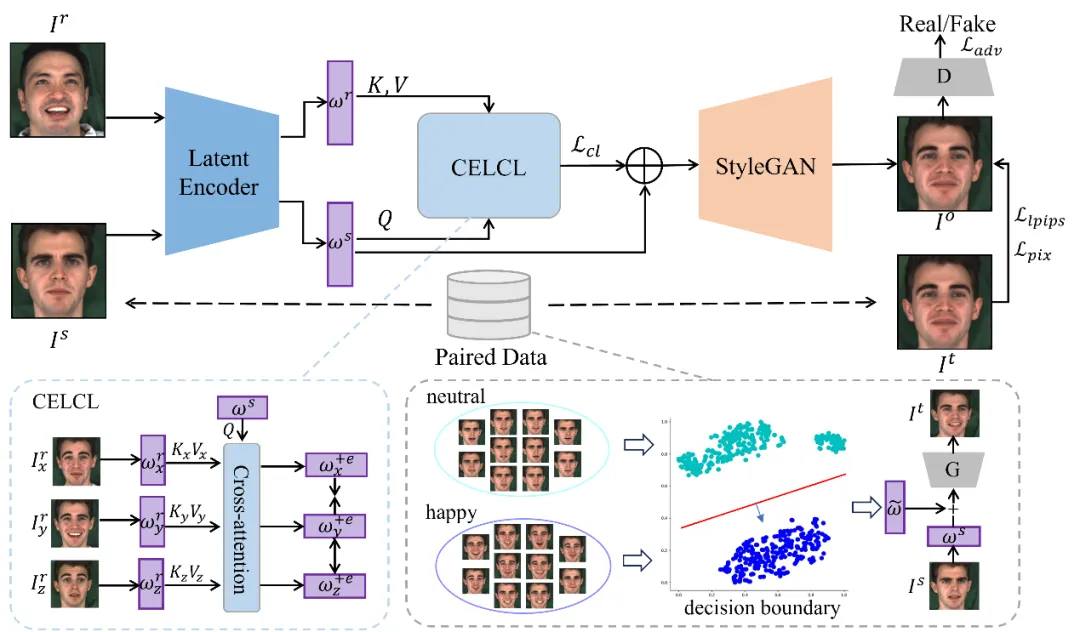
图1 所提出的自监督情感表征解耦框架的整体流程
本文提出了一种自监督情感表示解耦框架(SSERD),主要包括三个模块:
1.对比式情感潜码学习模块(CELCL)
o 使用StyleGAN的潜在空间表示情感;
o 引入跨注意力机制提取参考图像的情感信息;
o 使用对比学习增强情感表示的区分度。
2.成对数据构建模块
o 利用预训练StyleGAN生成口型一致、情感不同的成对图像;
o 通过SVM在潜在空间中寻找情感编辑方向,实现精准控制。
3.混合训练策略
o 结合合成成对数据与真实非成对数据进行训练;
o 提升生成图像的真实感与泛化能力。
3.实验结果与性能
在MEAD和RAVDESS数据集上的实验表明,SSERD在以下指标上显著优于现有方法(如ICface、DSM、NED、EAT):
· FAD↓(图像真实感)
· LSE-D↓(口型-语音同步性)
· CSIM↑(情感相似性)
用户研究也显示,SSERD在真实感、情感相似性、口型保持三个方面均获得最高评分。
4.局限性与未来方向
目前方法仅支持7种基本情感,未来可探索:
· 使用多模态大模型(如CLIP)支持更广泛的情感描述;
· 扩展至连续或复合情感的控制。
5.总结
SSERD为SPFEM任务提供了一种高效、自监督、高质量的解决方案,不仅在技术上实现了情感表示的精准解耦与迁移,也为多媒体内容生成、虚拟人驱动等应用提供了有力工具。
04
Scalable Multi-view Unsupervised Feature Selection with Structure Learning and Fusion
作者:
张成龙1,梁新彦2,周芃3,凌兆龙3 ,张迎伟4,吴兴宇5,盛伟国1,江兵兵1,*
单位:
1杭州师范大学
2山西大学
3安徽大学
4中国科学院计算技术研究所
5香港理工大学
邮箱:
clzhang123@163.com
liangxinyan48@163.com
zhoupeng@ahu.edu.cn
zlling@ahu.edu.cn
zhangyingwei@ict.ac.cn
xingy.wu@polyu.edu.hk
w.sheng@ieee.org
jiangbb@hznu.edu.cn
论文:
https://dl.acm.org/doi/abs/10.1145/3664647.3681223
代码链接:
https://openreview.net/forum?id=N7AdbHQFwA
发表会议:
ACM MM 2024
*通讯作者
1.研究背景
为了处理具有多重表示的高维数据,近年来多视图无监督特征选择已成为一个重要的学习范式。然而,现有算法存在以下问题:(i) 这些算法侧重于选择能够保持数据相似性结构的特征,而往往忽略了聚类结构中的判别信息;(ii) 它们通常在伪标签上施加正交约束,破坏了聚类标签的局部结构;(iii) 从所有样本中学习近邻信息或聚类信息需要大量的计算资源。针对上述问题,本文提出了一种可扩展的多视图无监督特征选择算法SMUFS(Scalable Multi-view Unsupervised Feature Selection with Structure Learning and Fusion),以期通过协同利用聚类结构与近邻结构,选择出更具判别力的特征。
2.算法概述
本文提出的可扩展多视图无监督特征选择算法架构如图1所示。具体来说,SMUFS通过隶属度矩阵来挖掘各视图中特有的聚类结构,并对隶属度矩阵进行对齐与融合,以捕获跨视图一致的聚类信息。同时,隶属矩阵可以在优化过程中根据近邻结构动态更新,从而有效提升聚类信息的判别性。最终,SMUFS对特征投影矩阵施加范数约束,可以在优化过程中自动识别出最优的k个特征。
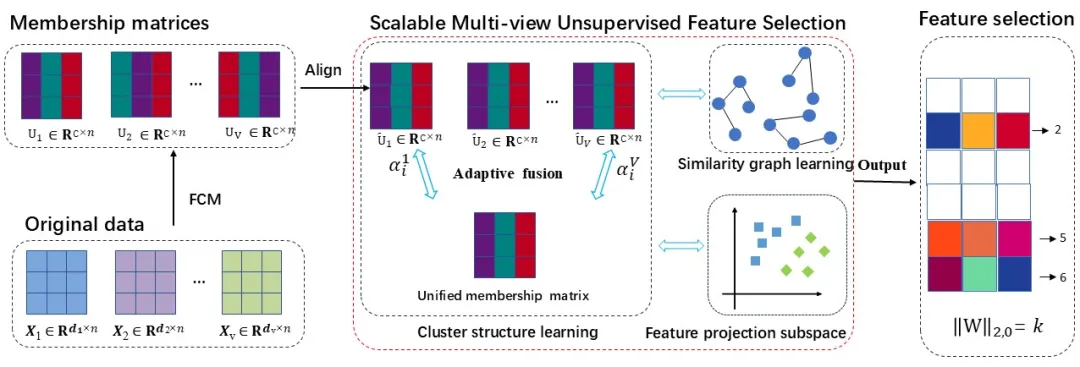
图1 SMUFS算法架构图
3.实验结果
本文在多个公共数据集上验证了SMUFS的优越性,部分实验结果如表1所示。同时,图2展示了各算法运行时间与数据规模的关系,可以观察到随着训练样本规模的增加其他算法的训练时间迅速增加,而SUMFS呈现线性增长,表明 SMUFS在处理大规模任务时具有可扩展性。此外论文还对SMUFS所选特征子集的有效性、模块设计的合理性等进行了分析,感兴趣的读者可以通过阅读原论文了解进一步的内容。
表1 各算法在选择不同特征数量时的性能。最优和次优的结果用粗体和下划线表示
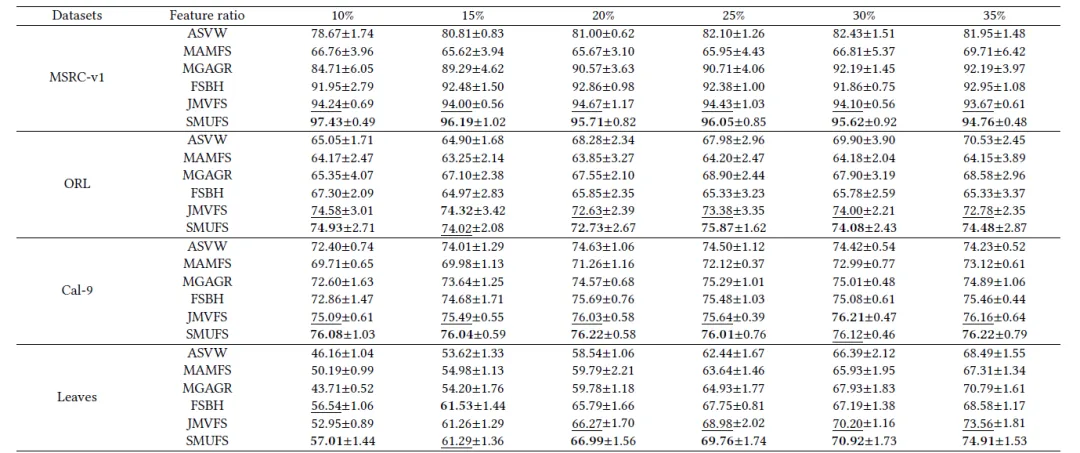
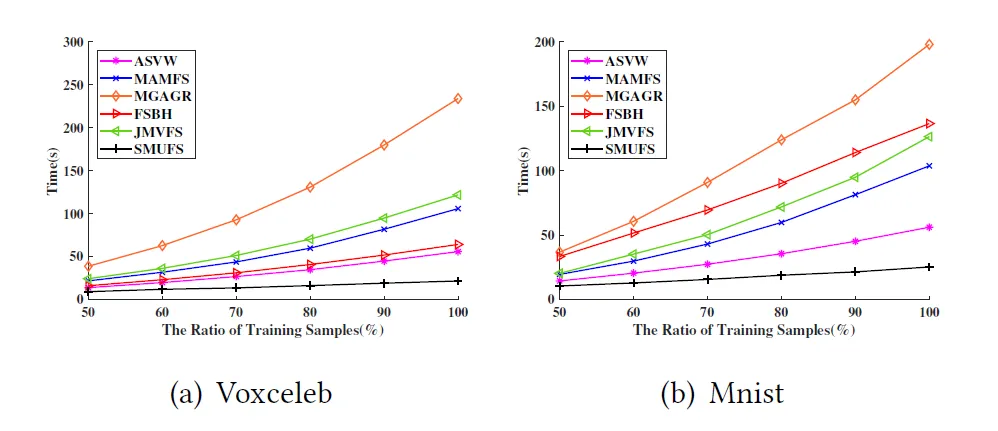
图2 各算法运行时间与样本数量的关系
4.总结
本文提出了一种新颖的多视图无监督特征选择算法(SMUFS),旨在充分挖掘数据的潜在结构。具体而言,SMUFS将对齐的隶属度矩阵进行融合,以获得一个统一的隶属度矩阵。同时,通过在隶属度空间构建近邻图,SMUFS能够保留聚类标签的局部结构,从而有效增强隶属度矩阵的判别能力,有助于最终的特征选择。此外,SMUFS引入锚点策略来降低计算复杂度,使其能够适应大规模特征选择任务。实验结果表明,SMUFS在多个数据集展现出明显的优势。
05
NovaChart: A Large-scale Dataset towards Chart Understanding and Generation of Multimodal Large Language Models
作者:
Linmei Hu1* ,Duokang Wang2*,Yiming Pan1, Jifan Yu3, Yingxia Shao2, Chong Feng1, Liqiang Nie4
单位:
1Beijing Institute of Technology
2Beijing University of Posts and Telecommunications
3Tsinghua Univerisity
4Harbin Institute of Technology
邮箱:
hulinmei@bit.edu.cn
wandokan@bupt.edu.cn
ympan@bit.edu.cn
yujf21@mails.tsinghua.edu.cn
shaoyx@bupt.edu.cn
fengchong@bit.edu.cn
nieliqiang@gmail.com
论文:
https://dl.acm.org/doi/10.1145/3664647.3680790
https://github.com/Elucidator-V/NovaChart
ympan/novachart · Datasets at Hugging Face
发表会议:ACM MM Oral, 2024
*通讯作者
1.背景与动机
随着数据的爆炸式增长,图表作为一种高效的可视化工具,可以帮助人们直观地理解和分析复杂的数据。多模态大模型通过结合视觉和语言模态,具备理解复杂图表视觉元素和响应多样化任务指令的潜力,能够为智能化的数据分析和决策提供有力支持。然而,现有的多模态大语言模型(Multimodal Large Language Models, MLLMs)在图表理解和生成上的能力较为有限。尽管最近研究取得了一定进展,MLLM在相关领域仍面临诸多挑战,主要原因是高质量训练数据的缺失。现有的数据集存在覆盖的图表类型较少、任务多样性不足等问题,无法有效支持模型在实际应用中的表现。
为了解决这些问题,我们提出了NovaChart,一个大规模的图表数据集,专注于提升多模态大模型在图表理解与生成任务上的表现。NovaChart包含47K张高分辨率图表,涵盖18种不同类型的图表,并提供856K个与图表相关的指令,支持4大类、15种形式各异的图表理解与生成任务,以覆盖模型在实际应用中所需求的能力,赋能MLLM成为更优质的图表助手。
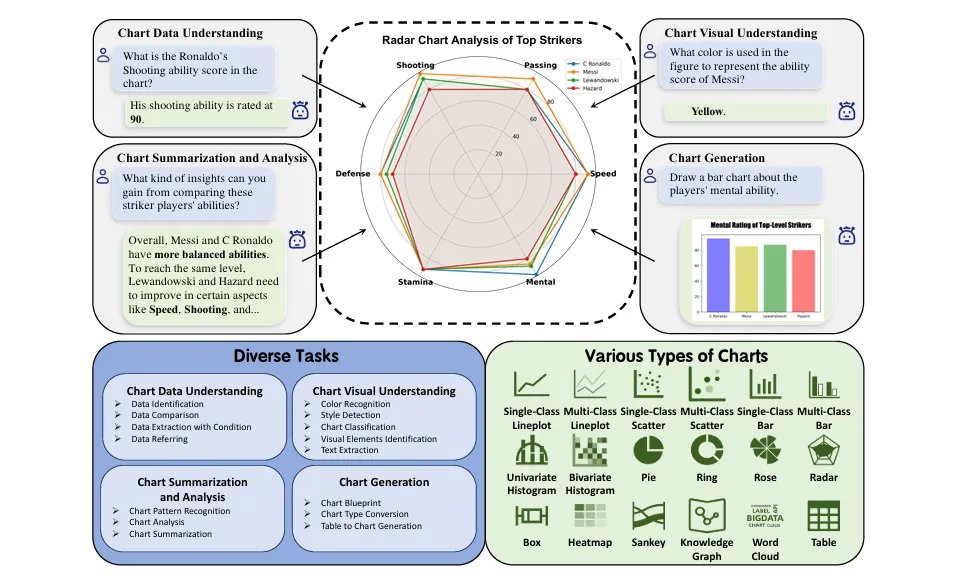
图1 NovaChart概述
2.方法与数据集
为了克服现有数据集的种种不足,我们构建了一个完整的数据引擎以支持NovaChart的自动生成。其包含四个主要步骤:
1)原始数据获取:本研究从Kaggle中收集了用户好评(vote)居多的原始数据表格,这些数据往往结构清晰、源于数据科学的真实场景、涵盖了多样的主题且反映了现实世界中数据的复杂性和多样性。这些数据经过清洗后作为图表生成的原始数据。
2)数据整理:通过对原始表格的行列维度分别进行采样和组合,我们从原始数据中抽取适合进行可视化的子表,通过预处理计算子表中的统计数据,进一步生成图表所需的元数据,包括数据点、视觉元素以及用于图表可视化的代码等。
3)图表可视化:基于处理后的子表数据,我们利用主流的Python库如Matplotlib、Seaborn等生成图表。特别地,我们高度利用了不同工具中的多样化参数,以最大限度使生成的图表形式多样,强调数据集泛化能力的同时也进一步扩展数据规模。
4)指令形式化:我们结合了基于模板和基于大语言模型(如GPT-4)生成的方法,生成了涵盖15类不同任务的大规模图表指令数据,覆盖了从图表数据理解、图表视觉理解、图表综合理解到图表生成的广泛任务类型。
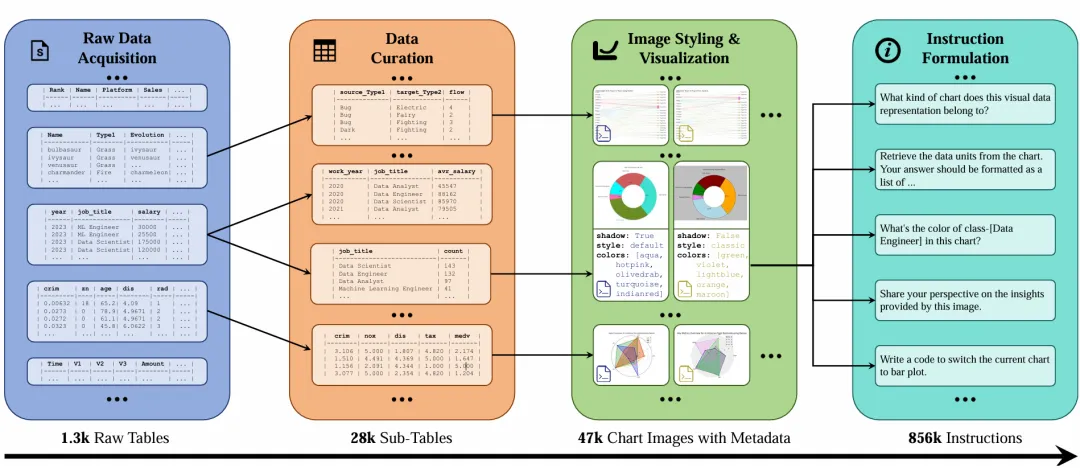
图2 Novachart 数据引擎概述
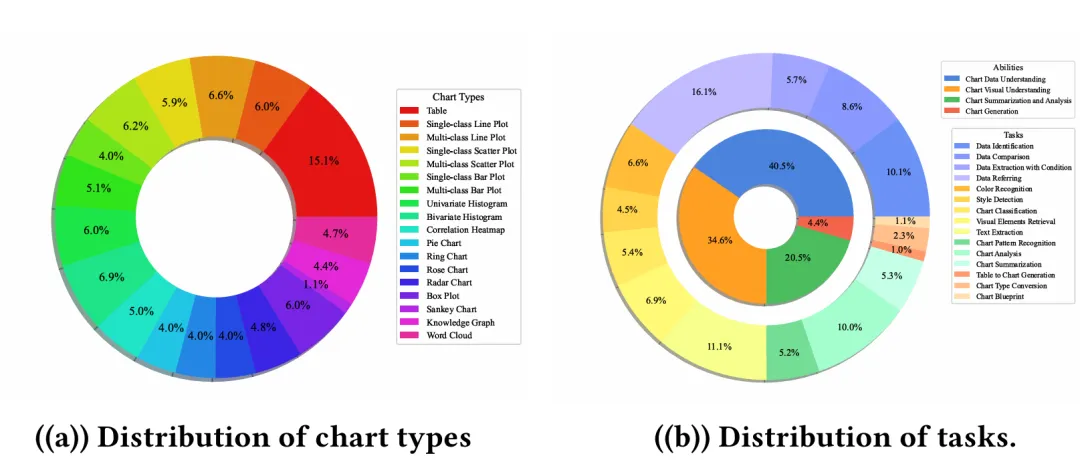
下图展示了NovaChart的图表类型和任务类型的分布情况,NovaChart对不同的图表类型和任务类型均实现了覆盖,且比例较为均衡。
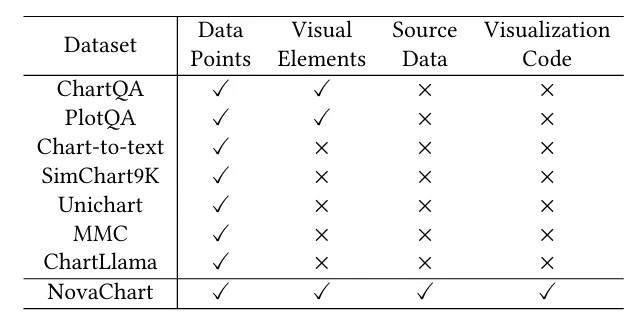
下表展示了NovaChart与现有的其他图表数据集在统计指标和元数据类型上的比较,NovaChart在对图表类型、指令类型的覆盖上均超过现有数据集,且更全面的元数据开源保证了NovaChart数据集的进一步扩展的潜力。
表1 Novachart 与现有图表数据集的对比
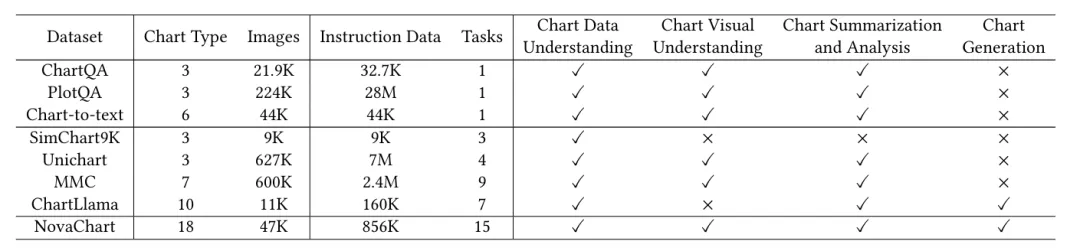
表2 不同数据集的图表元数据
3、实验结果
为了验证NovaChart在增强MLLM的图表理解和生成能力方面的有效性,我们选择了一系列支持较高分辨率视觉输入的开源MLLM进行微调,并评估模型微调前后在NovaChart所覆盖的一系列任务中的性能。同时,我们构造了一个独立于训练数据的NovaChart测试集,并采用了一系列适合于评测图表相关任务的评测方法。下图分别展示了三个模型微调前后在不同任务类型、不同图表类型上的性能差异(蓝色为微调前,绿色为微调后)。可以看到,微调后的模型在不同任务上均取得了较为显著的性能提升(35.47%-619.47%),在部分任务(例如图表分类和文本抽取)中更是表现卓越,展示了NovaChart对MLLM的性能增益;在不同图表类型上性能的提升同样显著,尤其表现在长尾图表类型上,彰显了NovaChart对不同类型的图表进行的数据平衡的显著意义。
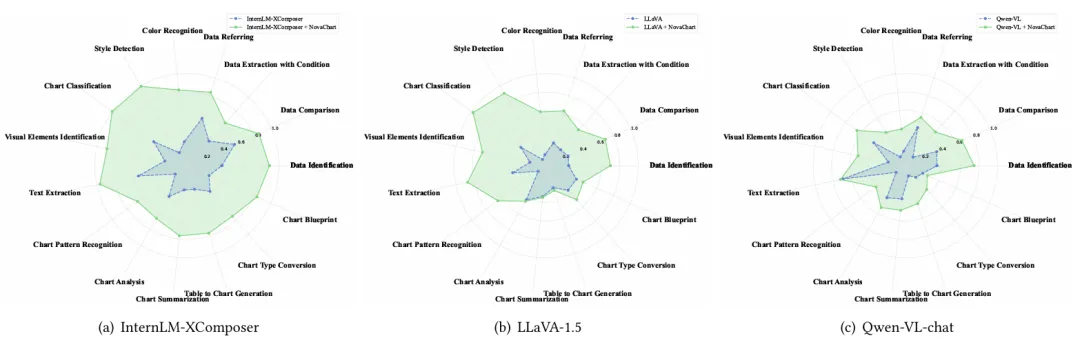
图3 模型在15项图表相关任务上训练前后的性能对比
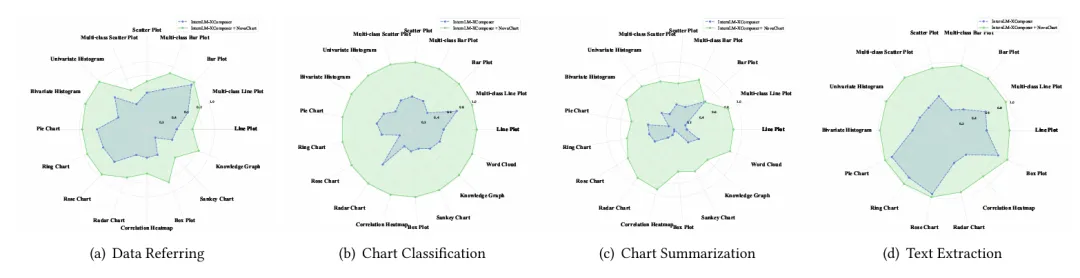
图4 InternLM-XComposer 模型在不同类型图表上的四项典型任务性能
下图展示了在InternLM-XComposer上的一个案例分析。示例A显示,微调前的原始模型无法正确理解图表坐标轴和数据的含义,将其误认为年份并生成了幻觉回复,而微调后的模型则正确的给出了图表的数据解析并提供了有意义的分析;示例B显示,微调前的原始模型完全错误地理解了用户的意图,并生成了保守回复,而微调后的模型能够基于用户需求生成完整的可执行可视化代码。
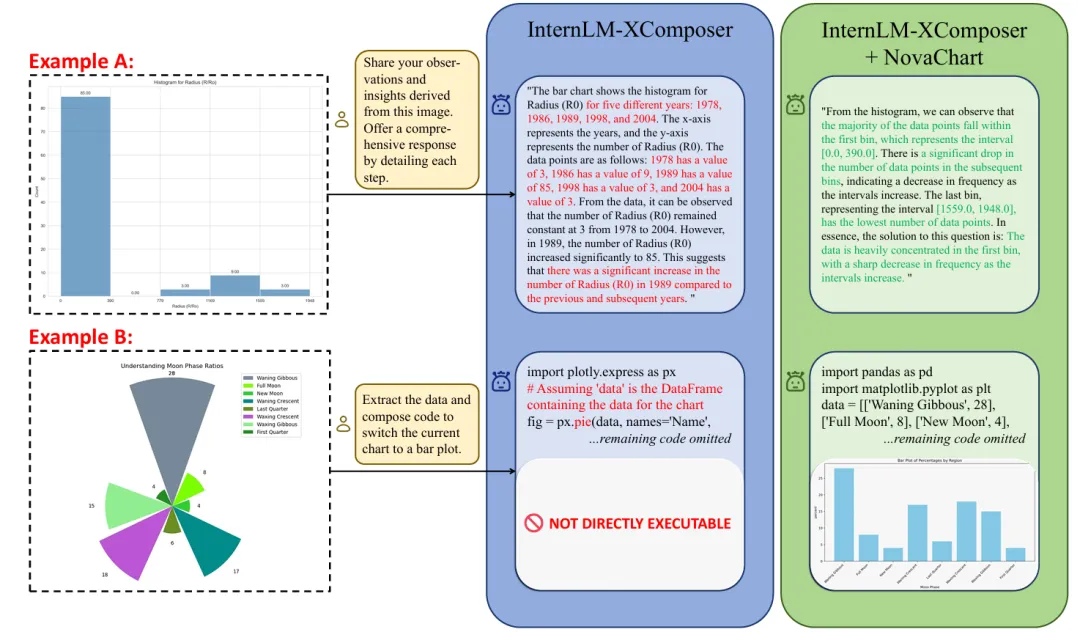
图5 图表分析任务与图表类型转换任务的定性分析
4.本文贡献
大规模图表数据集:我们构建了一个包含47K张高分辨率图表的NovaChart数据集,涵盖多种图表类型,支持多样不同任务。
完整的数据引擎:我们设计了一个全面、自动化的数据生成引擎,使得其能够包含每个图表详细的元数据,包括数据点、可视化元素、原始数据和可视化代码等,极大提升了数据集的扩展性。
一系列具备增强图表能力的MLLM:通过在NovaChart上进行微调,我们显著提升了多模态大语言模型在图表理解与生成任务上的表现,使其更接近实际应用中的智能图表助手。

编辑人:吴建龙、任文琦
专委会责任副主任:张勇东
 京公网安备11010802017125号
京公网安备11010802017125号