
【论文导读】2025年论文导读第二十一期
【论文导读】2025年论文导读第二十一期


论文导读
2025年论文导读第二十一期(总第一百三十八期)
目 录
|
1 |
Coarse-to-Fine Proposal Refinement Framework for Audio Temporal Forgery Detection and Localization |
|
2 |
De-fine: Decomposing and Refining Visual Programs with Auto-Feedback |
|
3 |
WorldGPT: Empowering LLM as Multimodal World Model |
|
4 |
Overcoming Spatial-Temporal Catastrophic Forgetting for Federated Class-Incremental Learning |
|
5 |
Open-Vocabulary Audio-Visual Semantic Segmentation |
01
Coarse-to-Fine Proposal Refinement Framework for Audio Temporal Forgery Detection and Localization
作者:
吴俊彦1,卢伟1*,罗向阳2,杨锐3,王骞4,操晓春1
单位:
1中山大学
2数学工程与高级计算国家重点实验室
3阿里巴巴安全部
4武汉大学
邮箱:
wujy298@mail2.sysu.edu.cn
luwei3@mail.sysu.edu.cn
luoxy_ieu@sina.com
duming.yr@alibaba-inc.com
qianwang@whu.edu.cn
caoxiaochun@mail.sysu.edu.cn
论文:
https://dl.acm.org/doi/abs/10.1145/3664647.3680585
代码链接:
https://github.com/ItzJuny/CFPRF
发表会议:ACM MM 2024
*通讯作者
1. 研究背景
局部伪造音频能够通过合成单个词语替换真实音频中片段,以达到语义篡改的目的。然而现有的伪造音频取证方法仅能够提供单个样本或者是帧级的分类结果,未能提供伪造段的起止时间以帮助用户更好理解取证分析的结果。为了填补音频取证的空白,我们引入了时序伪造检测和定位任务 (Temporal Forgery Detection and Localization, TFDL),它不仅需要识别每个音频片段是真实或是伪造的,还需要确定这些伪造片段开始和结束的精确时间。我们总结了音频TFDL面临的两大技术挑战,首先是短区间伪造挑战,在元音或辅音被修改的情况下,如何精确定位单帧或者仅连续几帧的修改。其次是多区间伪造挑战,伪造音频中可能会存在多个被伪造的片段,伪造片段越多对定位性能的影响就越大。
2. 方法介绍
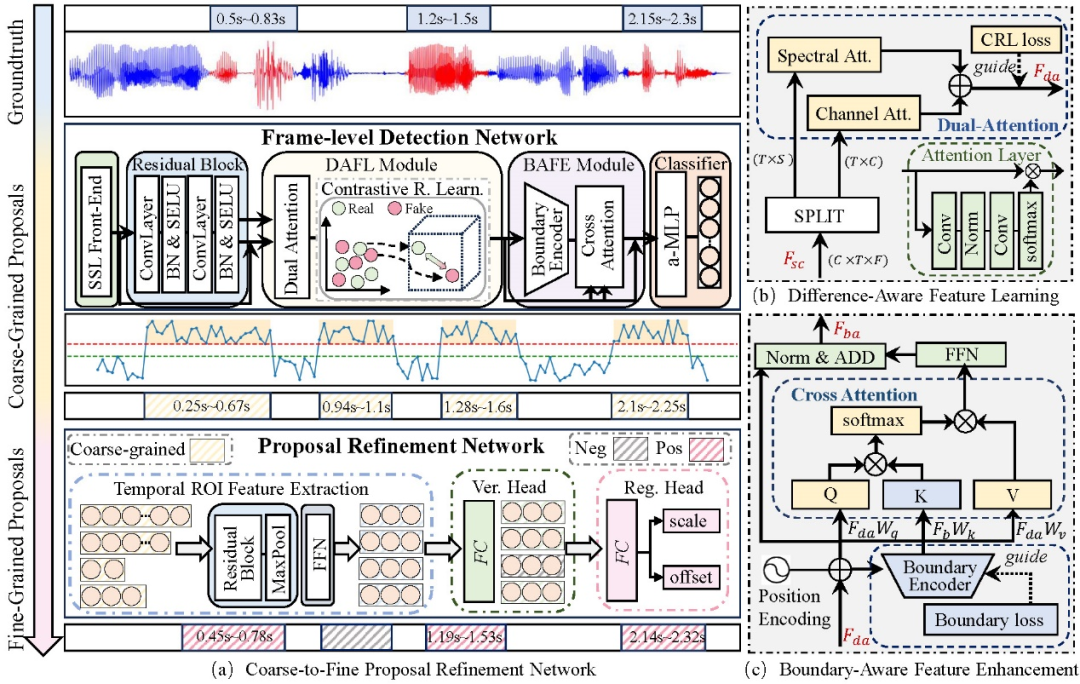
图1 CFPRF模型结构图
为了解决上述问题,本文提出了从粗粒度到细粒度的定位框修复框架(Coarse-to-Fine Proposal Refinement Framework, CFPRF),以实现对伪造音频时序检测和定位。如图1所示,该框架由一阶段的帧级检测网络(Frame-level Detection Network, FDN)来学习鲁棒特征表示,以便指示粗粒度的伪造区间,并由二阶段的定位修复网络(Proposal Refinement Network, PRN)生成细粒度的提议。其中,为了扩大由细微伪造操作引起的不同帧之间的差异,我们设计了一个由对比表征学习为指导的差异感知特征学习模块。此外,我们还设计了一个边界感知特征增强模,以捕获多伪造区间的过渡边界提供的上下文信息。
3. 实验结果
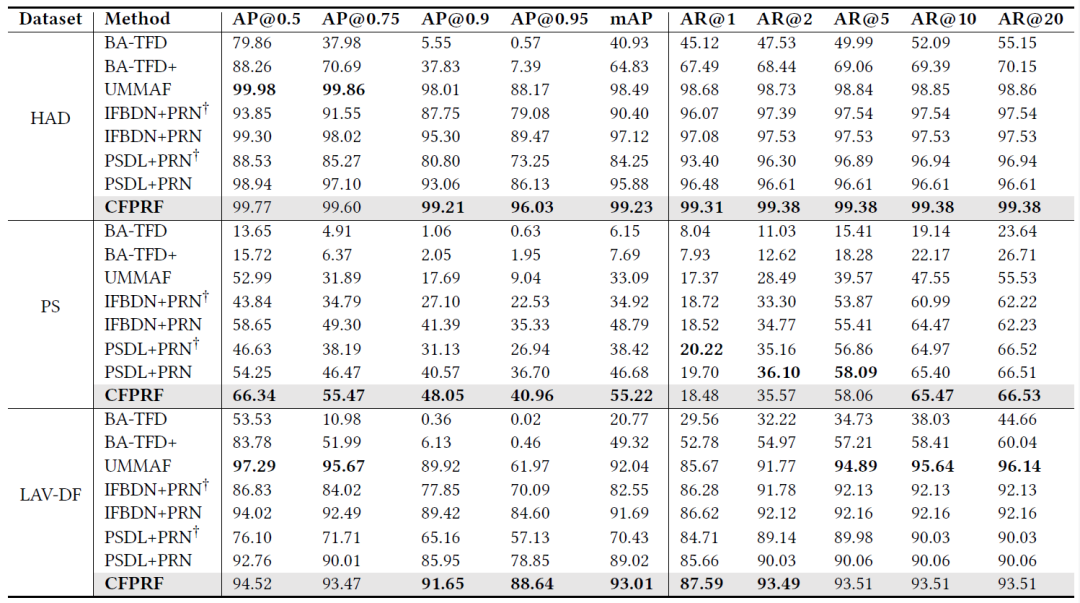
我们在LAV-DF,ASVS2019PS和HAD数据集上进行了实验,结果如表1和表2所示。针对最具有挑战性的ASVS2019PS数据集,我们的CFPRF在帧级检测任务的EER和F1指标上相对于次优方法分别相对提高了23.45%和2.07%性能,在时序定位任务的mAP指标上相对提高了13.18%定位性能。此外,当现有的音频部分伪造检测模型IFBDN和PSDL与PRN进行集成时,mAP性能分别相对提高了39.7%,21.5%,证明了PRN作为即插即用模块的有效性。
表1 帧级检测结果
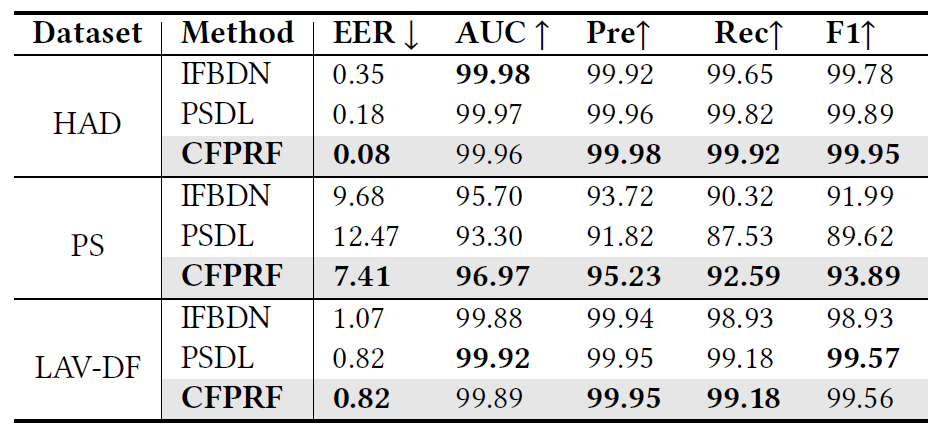
表2 时序伪造定位结果
02
De-fine: Decomposing and Refining Visual Programs with Auto-Feedback
作者:
高明合1,李俊成1,*,费豪2,庞亮3,吉炜2,王国明1,吕喆奇1,张文桥1,*,汤斯亮1,庄越挺1
单位:
1浙江大学
2新加坡国立大学
3中国科学院
邮箱:
minghegao@zju.edu.cn
junchengli@zju.edu.cn
haofei37@nus.edu.sg
pangliang@ict.ac.cn
weiji0523@gmail.com
nb21013@zju.edu.cn
zheqilv@zju.edu.cn
wenqiaozhang@zju.edu.cn
siliang@zju.edu.cn
yzhuang@zju.edu.cn
论文:
https://doi.org/10.1145/3664647.3681430
发表会议:ACM MM 2024
*通讯作者
1.研究背景
近年来,随着大型视觉语言模型(Visual-Language Models, VLMs)的发展,视觉理解、图像问答、视觉推理等任务取得了显著进展。尽管这些端到端模型在性能上表现出色,但仍面临两个突出问题:一是缺乏对推理过程的可解释性;二是每遇到新任务都需要昂贵的再训练或微调,难以适应复杂或长尾任务场景。
为提升可解释性与泛化能力,学界提出了“视觉编程(Visual Programming)”范式,即通过自动生成代码,将视觉和语言模型模块化组合起来执行复杂任务。这一方法能够利用现有视觉模型完成推理,无需额外训练。然而,当前主流的视觉编程方法通常仅生成一次性程序,缺乏利用执行反馈进行自我改进的能力,导致在复杂推理、多步骤任务中表现有限。
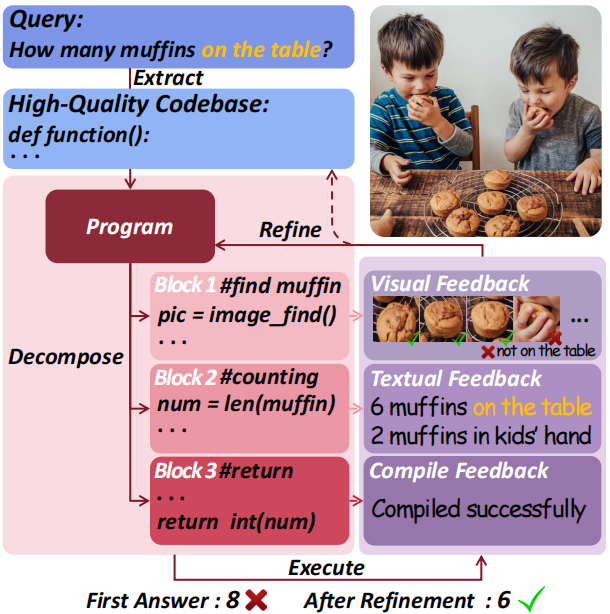
图1 De-fine将任务分解为可执行的程序块,并根据执行过程中获得的多方面反馈自动优化程序
针对这一瓶颈,我们提出了一个训练无关(training-free)的视觉编程框架——De-fine(Decomposing and Refining Visual Programs with Auto-Feedback)。该方法受“Benders 分解”思想启发,能够自动拆解任务、执行并根据反馈循环优化,实现视觉程序的自进化。
2.方法介绍
De-fine 旨在让计算机像人类程序员一样“思考与改进”程序。其核心流程包括四个环节:
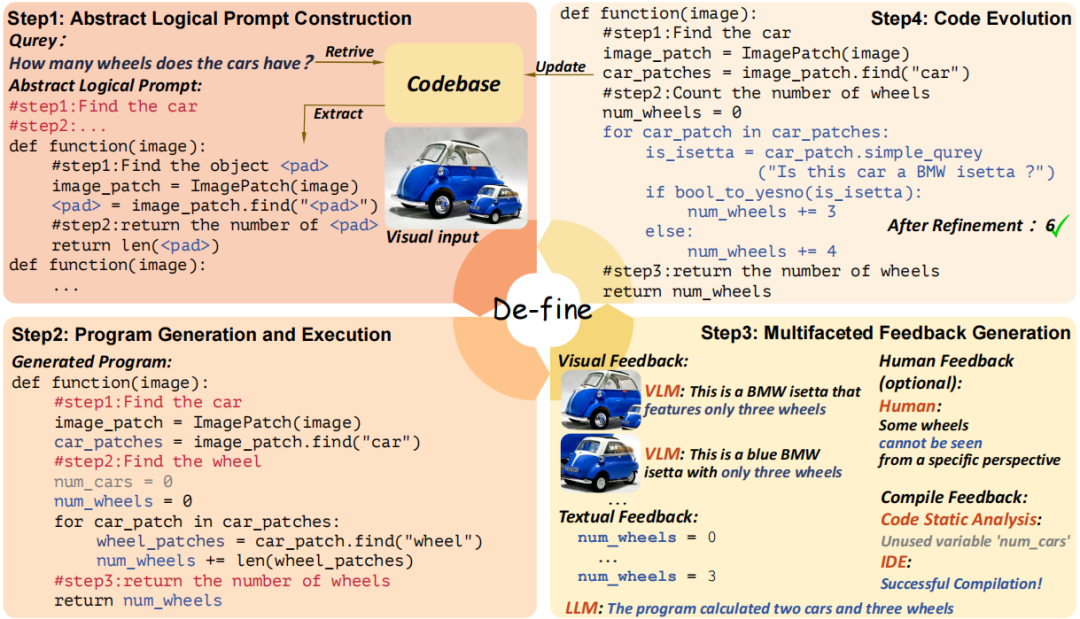
图2 De-fine是一款基于编程的框架,能够分解任务并优化程序。我们将其流程归纳为四个步骤:(1)首先构建抽象逻辑提示;(2)生成并执行程序;(3)在执行过程中,De-fine会自动生成多维度优化反馈;(4)根据反馈持续优化代码,并扩展代码库以供后续使用
(1)任务分解与抽象逻辑提示构建:模型首先将输入问题自动拆解为多个逻辑子任务,并检索历史代码库中语义相似的程序片段,生成“抽象逻辑提示(Abstract Logical Prompt)”,为后续程序生成提供结构性指导。
(2)程序生成与执行:通过大语言模型生成层次化、可执行的 Python 程序。每个子任务对应独立模块,确保逻辑清晰、易于调试。
(3)多模态自反馈机制:在程序执行后,De-fine 自动采集三类反馈信息:
视觉反馈:利用视觉语言模型判断图像区域是否符合预期结果;
文本反馈:语言模型分析中间变量与逻辑推理是否一致;
编译反馈:检测语法与逻辑错误,自动修复异常代码。
(4)代码自进化与知识积累:优化后的高质量程序会被加入“逻辑代码库”,供后续任务复用与持续改进,形成闭环的自学习机制。
3.实验结果
我们在多个主流视觉理解任务上系统评估了 De-fine 的性能,包括视觉定位(RefCOCO/RefCOCO+)、组合式视觉问答(GQA、OK-VQA、TallyQA)以及图像对推理(NLVRv2)等五个数据集。
表1 视觉任务的实验结果。我们展示了REC(参考表达理解)任务在test-A 分布集合上RefCOCO和RefCOCO+数据集上的准确率表现
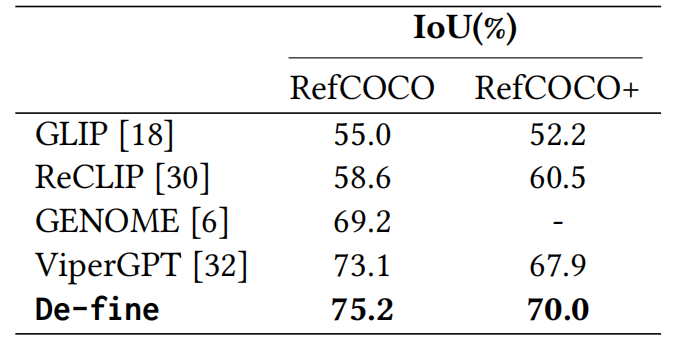
表2 我们在GQA测试集上展示了准确率。其中,GT-data表示真实数据,AL表示抽象逻辑提示
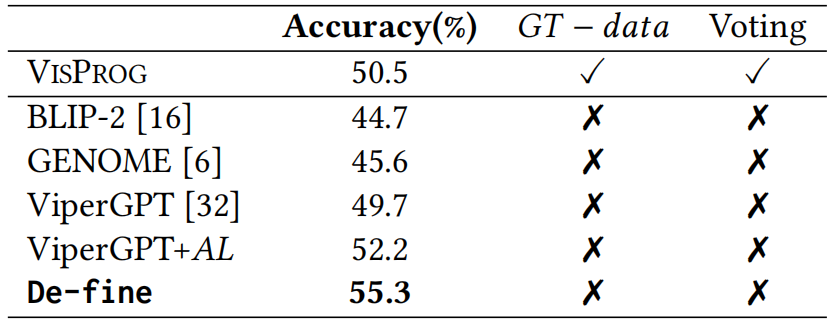
表3 我们通过OK-VQA验证集、TallyQA测试集和NLVRv2测试集的准确率(%)进行衡量
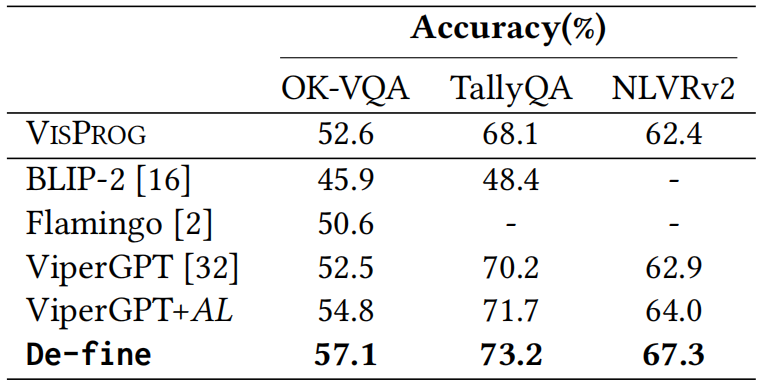
结果显示,De-fine 在所有任务中均取得零样本(zero-shot)性能最佳(SOTA),相比代表性方法 ViperGPT 提升显著。例如,在GQA数据集上准确率提升至 55.3%,在OK-VQA上达到 57.1%,在 NLVRv2 推理任务中也实现 67.3% 的优异成绩。
定性分析表明,De-fine 能够自动纠正程序逻辑错误与编译异常,生成的代码更简洁、可读性更强。在代码质量评测中,其平均得分(Pylint 7.5)与可编译率(92.8%)均高于对比模型,验证了多维反馈机制的有效性。

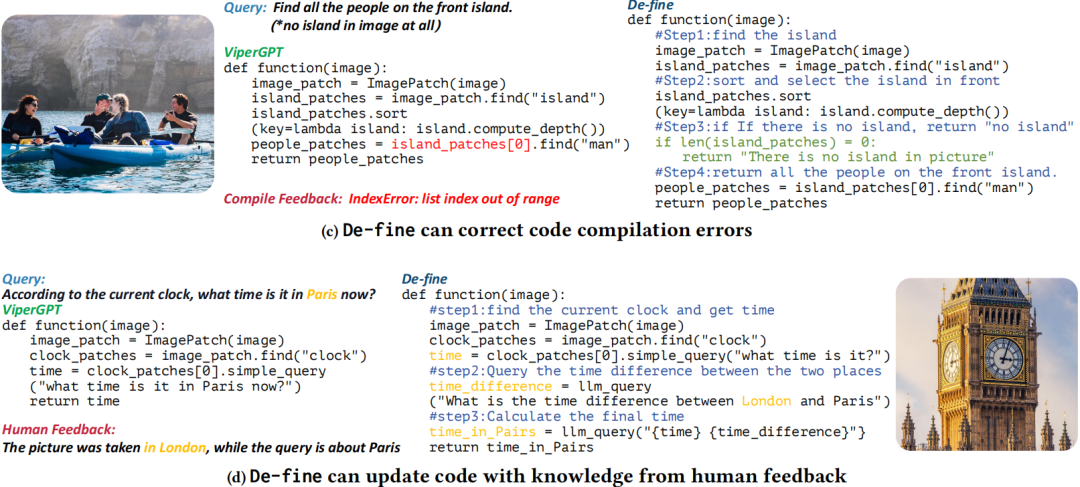
图3 De-fine反馈的优化示例
4.总结
De-fine 提出了一种融合任务分解、自反馈与代码进化的视觉编程新范式,在无需额外训练数据的前提下实现了复杂视觉推理任务的自我优化执行。其思想不仅提升了模型的可解释性与泛化能力,也为多智能体协作与视觉推理自治系统提供了新的研究方向。未来,我们计划进一步探索 De-fine 在开放环境、多模态智能体和可持续学习场景中的潜力。
03
WorldGPT: Empowering LLM as Multimodal World Model
作者:
葛郅琦1,†,黄泓喆1,†,周明泽1,†,李俊成1*,王国明1,汤斯亮1,庄越挺1
单位:
1浙江大学
邮箱:
gzq@zju.edu.cn
22321202@zju.edu.cn
mingze@zju.edu.cn
Jethro9783@gmail.com
nb21013@zju.edu.cn
siliang@zju.edu.cn
yzhuang@zju.edu.cn
论文:
https://doi.org/10.1145/3664647.3681488
代码链接:
https://github.com/DCDmllm/WorldGPT
发表会议:ACM MM 2024
*通讯作者
†共同第一作者
1.研究背景
世界模型(World models)是人工智能领域的一个重要研究方向,它通过构建一个内部表征来镜像外部现实,从而封装关于环境动态的知识。一个可靠的世界模型能让智能体(agent)通过最少的直接互动来洞察环境规律,甚至通过“想象”来预测动作的潜在后果。目前,世界模型已从基础的环境模拟扩展到复杂的场景构建,尤其在虚拟仿真、机器人操控和具身探索等控制任务中展现了价值。
然而,现有的世界模型大多面临几个关键挑战:
1)局限性与模态单一:它们通常在特定领域(如自动驾驶)的数据上训练,且主要依赖单一的视觉模态来表征状态,忽视了现实世界中(如声音、文本)的多模态复杂性。
2)泛化能力差:模型在训练中未见过的场景中推理能力有限,并且难以处理长序列的连续预测任务。
如何构建一个能够理解多模态输入、预测复杂动态,并能泛化到未知场景的通用世界模型,是当前领域亟待解决的问题。
2.方法介绍
为了应对上述挑战,本文提出了 WorldGPT,一个基于多模态大语言模型(MLLM)构建的通用世界模型。WorldGPT的核心思想是利用MLLM强大的文本知识为基础,并通过分析数百万跨领域的互联网视频来学习复杂的世界动态。该模型主要由三个核心部分组成:
1)多模态编码器:将来自不同模态(视频、音频、图像等)的状态信息转换为统一的表征。
2)大型语言模型(LLM):作为模型的核心,在抽象的特征空间中预测状态的转移。
3)多模态解码器:将LLM预测的特征解码回目标模态空间(如生成未来的视频帧或音频)。
为了让模型有效学习,我们提出了一种新颖的 “渐进式状态转移训练”(Progressively State Transition Training) 方法。该方法遵循从易到难的范式,将训练任务按难度分为单模态、跨模态、多模态组合等四个阶段,引导模型平稳收敛,使其最终能处理任意模态组合的输入和输出。
此外,为增强WorldGPT在特定场景和长时序任务中的能力,我们设计了一个创新的 “认知架构”(Cognitive Architecture)。该架构受认知科学启发,集成了三个关键模块:
1)记忆卸载(Working Memory):管理历史预测信息,以应对长序列任务。
2)知识检索(Knowledge Retrieval):为特定或未见过的场景提供外部知识支持。
3)上下文反射器(ContextReflector):一个高效的信息提取器,从检索到的记忆和知识中提取与当前任务最相关的 grounded 信息,辅助LLM进行更准确的预测。
通过后续的“认知增强调优”(Cognitive-Augmented Tuning),WorldGPT学会了如何利用历史经验和外部知识来优化其预测。
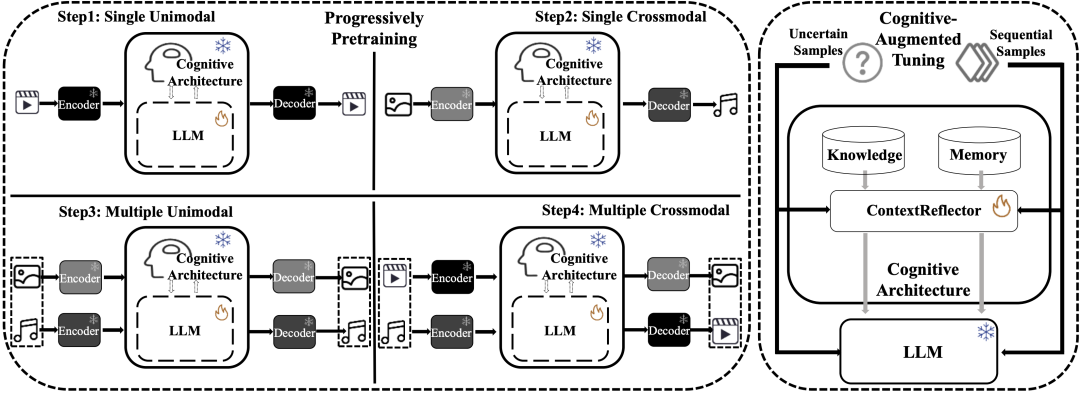
图1 WorldGPT的训练流程(左)与认知架构(右)
3.实验结果
数据集构建:为了全面评估WorldGPT,我们首先构建了一个全新的多模态状态转移基准数据集——WorldNet。WorldNet包含两个子集:1)WorldNet-Wild:源自数百万互联网原始视频,多样性强,用于模型的预训练;2)WorldNet-Crafted:整合自多个高质量、人工标注的数据集(如Ego-4D, YouCook2等),用于模型的精调和评估。
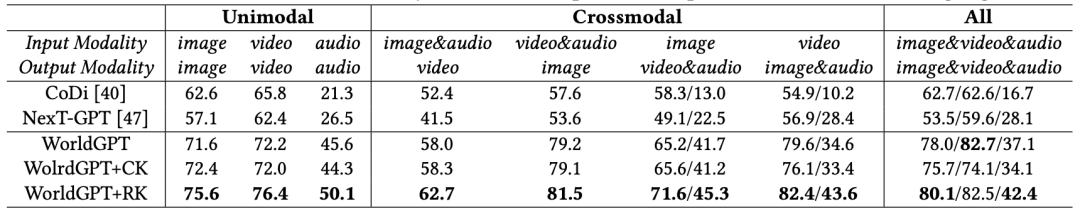
状态转移能力评估:我们在WorldNet-Crafted上进行了全面的评估。实验结果表明,WorldGPT在处理各种模态组合(包括单模态预测、跨模态生成、多模态联合预测)的状态预测任务上,其性能显著优于CoDi和NeXT-GPT等基线模型。消融实验进一步证明,集成了认知架构(特别是ContextReflector)的WorldGPT(即WorldGPT+RK / +RM),在知识增强和长序列预测任务上表现更佳,证实了该架构在提取和利用上下文信息方面的有效性。
表1 WorldGPT与基线模型在不同模态组合下的性能对比
作为世界模拟器的潜力: 本研究探索了WorldGPT作为“世界模拟器”的新兴潜力。我们提出了一种 “梦境调优”(Dream Tuning)的学习范式,即利用WorldGPT高效合成高质量的多模态指令数据(例如,根据一个目标自动生成包含图文步骤的复杂食谱),并使用这些合成数据来微调下游的多模态智能体。

图2 “梦境调优”范式(即多模态指令合成)流程
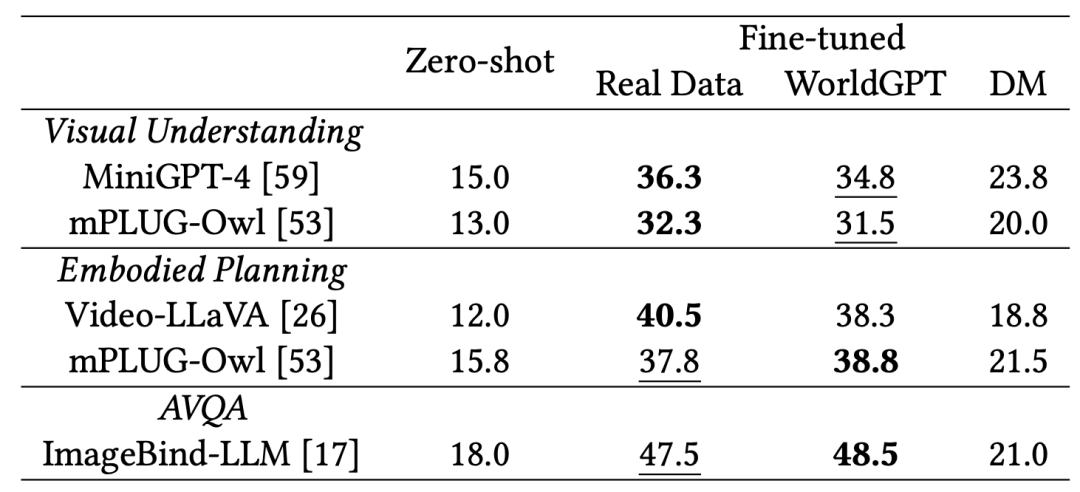
我们在视觉理解、具身规划和音视频问答三个下游任务上进行了实验。结果显示,通过“梦境调优”训练的智能体,其性能可与使用真实数据训练的智能体相媲美,甚至在某些任务上有所超越。这证明了WorldGPT作为模拟器所合成数据的可靠性与高效性,为多模态智能体的训练提供了一种新的可能。
表2 “梦境调优”合成数据与真实数据的下游任务性能对比
04
Overcoming Spatial-Temporal Catastrophic Forgetting for Federated Class-Incremental Learning
作者:
喻皓1,杨新1,*,高欣1,冯艺辉1,王浩2,康焱3,李天瑞4
单位:
1西南财经大学计算机与人工智能学院
2四川大学
3微众银行
4西南交通大学
邮箱:
yuhao2033@163.com
yangxin@swufe.edu.cn
xingaocs@hotmail.com
fengyh0727@163.com
cshaowang@gmail.com
kangyan2003@gmail.com
trli@swjtu.edu.cn
论文:
https://dl.acm.org/doi/abs/10.1145/3664647.3681384
发表会议:
ACM MM 2024
*通讯作者
1.研究背景
联邦类增量学习(Federated Class-Incremental Learning,FCiL)旨在在分布式环境下持续学习不断涌现的新类别。与传统联邦学习不同,FCiL不仅需要应对跨客户端的数据异质性,还要处理随时间演化的任务序列。然而,现有方法普遍面临时空灾难性遗忘(Spatial-Temporal Catastrophic Forgetting,STCF)的问题:一方面,模型在学习新任务时容易遗忘旧任务的知识(时间遗忘);另一方面,在服务器聚合异构客户端模型时,不同客户端的特定关键信息容易被覆盖(空间遗忘),从而导致聚合后的全局模型在客户端本地测试集上的表现变差。这种双重遗忘显著削弱了全局模型的泛化能力,尤其是当客户端拥有“私有类别(Private Class)”(仅由单一客户端持有)的场景下更为严重。为解决这一问题,本文提出了一种联邦类特定二分类器框架(Federated Class-specific Binary Classifier,FedCBC)。该方法通过类特定二分类器捕捉细粒度知识,结合服务器端的选择性知识融合与客户端的持续个性化学习,有效缓解了时空遗忘,提升了模型在多客户端、多任务环境下的鲁棒性和准确性。
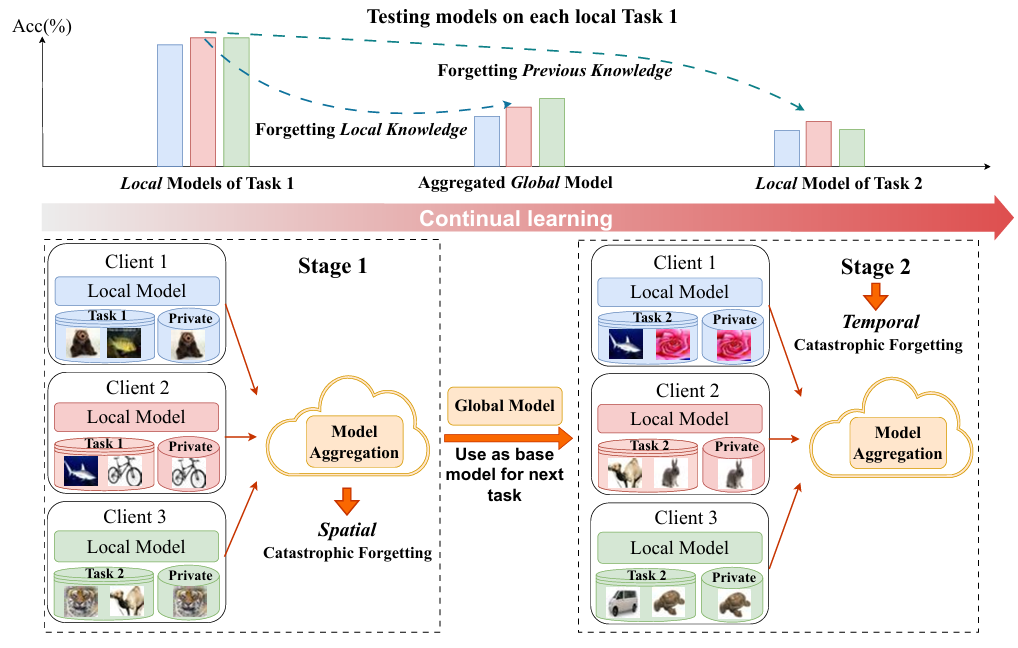
图 1 联邦持续学习过程及时空灾难性遗忘
2.方法概述
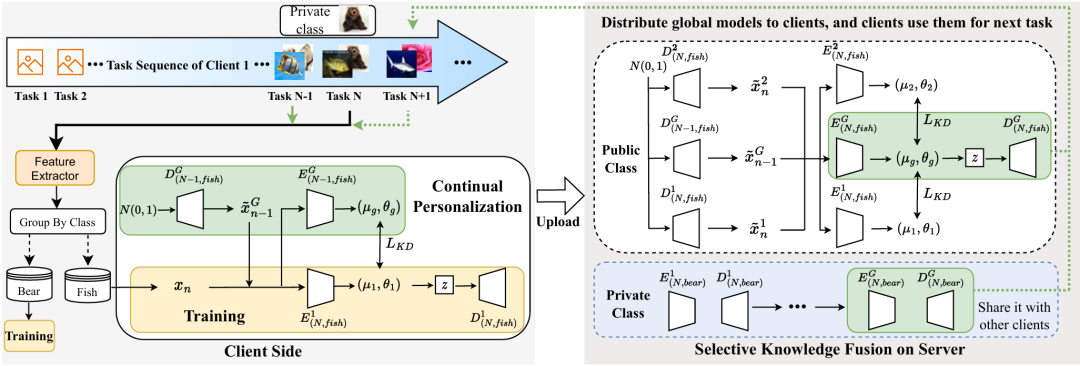
图 2 FedCBC的整体流程
FedCBC整体流程如上图所示,包含三个阶段:
1)第一阶段:类特定二分类器构建
在每个客户端,我们利用变分自编码器(VAE)为每个类别单独构建类特定二分类器。它通过重构误差来判断样本是否属于该类别,从而避免不同类别之间的知识干扰。这种独立建模方式能有效缓解局部模型在增量学习过程中出现的时间遗忘问题。
2)第二阶段:选择性知识融合
在服务器端,我们根据类别标签对来自不同客户端的类特定模型进行分组,并采用选择性知识融合机制。对于公共类别,将多个客户端的类特定模型与历史全局模型结合,生成更具泛化性的全局模型;对于私有类别,则通过伪样本重放与蒸馏实现间接共享,保证隐私安全。该机制避免了无关知识的混淆,有效缓解了空间遗忘。
3)第三阶段:持续个性化学习
在聚合后的全局模型下发到客户端后,每个客户端通过两种方式进行持续个性化:一是利用全局模型生成的伪数据来回顾旧知识,二是通过知识蒸馏提升新任务学习效果。这样既保证了新旧任务知识的平衡,又增强了模型对非独立同分布数据的适应性。
3.实验结果
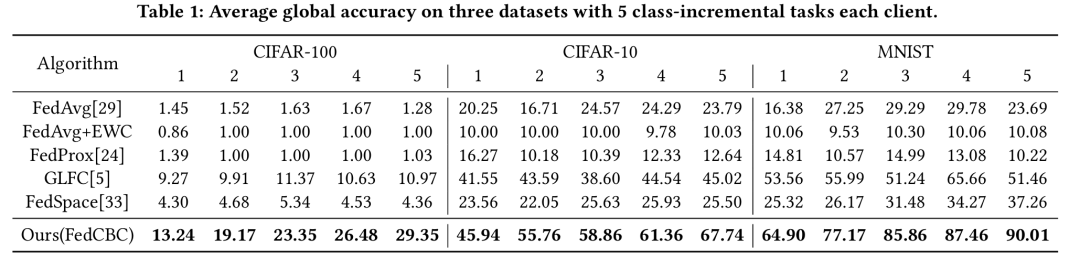
FedCBC在MNIST、CIFAR-10和CIFAR-100三个基准数据集上,对比了 FedCBC 与多种联邦类增量学习方法,包括FedAvg、FedAvg+EWC、FedProx、GLFC、FedSpace等。实验结果表明,FedCBC显著优于所有基线方法。
表1 主实验结果
在时间知识保持(Temporal Knowledge Retention, KRT)上,FedCBC 能在增量任务中有效保留旧知识,明显缓解了“时间遗忘”。在空间知识保持(Spatial Knowledge Retention, KRS)上,FedCBC 通过选择性知识融合避免了无关信息覆盖,使全局模型在本地任务上表现更佳。消融实验表明:去掉“选择性知识融合”或“持续个性化”都会导致性能大幅下降,验证了两者的必要性。
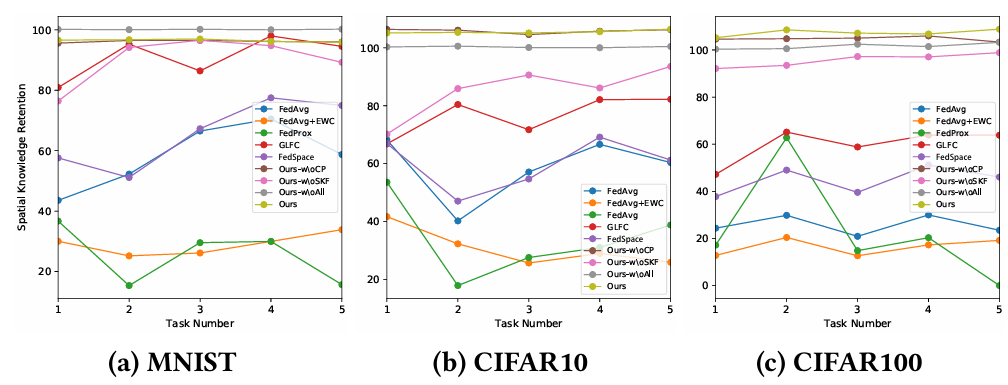
图 3 空间知识保持度
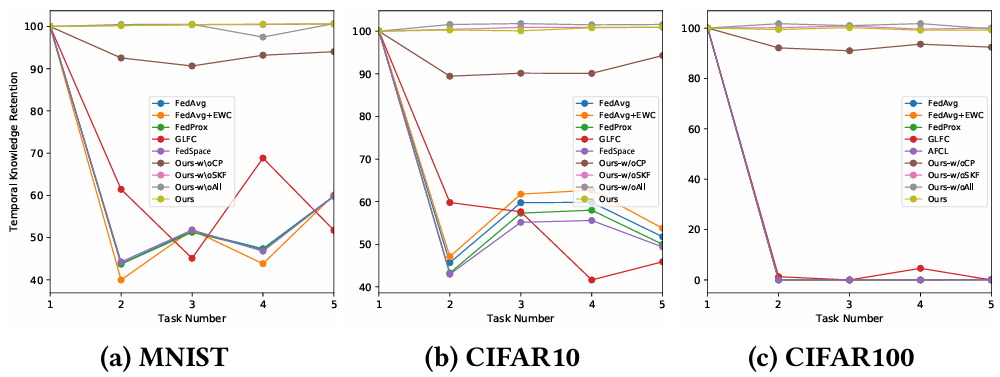
图 4 时间知识保持度
在隐私与鲁棒性方面,通过伪样本生成与蒸馏,FedCBC 能在不泄露原始数据的前提下共享私有类别知识;在不同 α 参数下,方法可以在准确率与隐私保护之间灵活权衡。
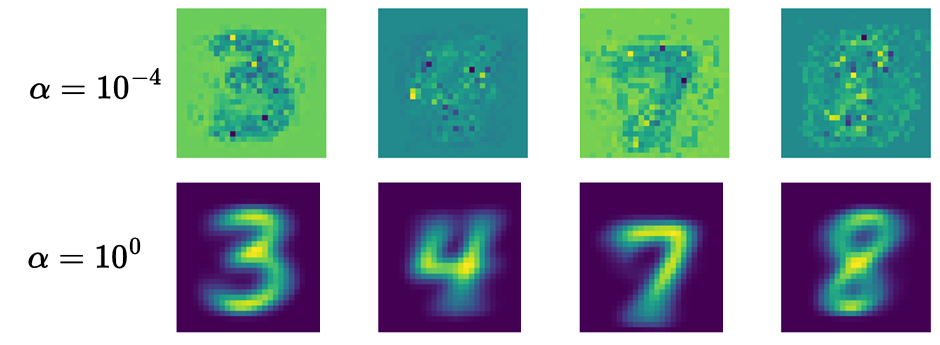
图 5 不同α参数下为样本可视化
05
Open-Vocabulary Audio-Visual Semantic Segmentation
作者:
郭若皓1,瞿李傲2,牛丹彤3,齐彦宇4,岳文振1,史记1,邢博威1,英向华1*
单位:
1北京大学
2美国卡耐基梅隆大学
3美国加州大学伯克利分校
4中国农业大学
邮箱:
ruohguo@stu.pku.edu.cn
liaoq@andrew.cmu.edu
Bias_88@berkeley.edu
yanyu.qi@cau.edu.cn
yuewenzhen@stu.pku.edu.cn
sjj118@pku.edu.cn
xingbowei@pku.edu.cn
xhying@pku.edu.cn
论文:
https://doi.org/10.1145/3664647.3681586
代码链接:
https://github.com/ruohaoguo/ovavss
发表会议:ACM MM 2024
*通讯作者
1.研究背景
视听语义分割(Audio-Visual Semantic Segmentation)旨在融合视觉与听觉信息,以实现对视频中发声物体的精准分割与分类。然而,当前主流方法普遍局限于“封闭集”设定,即只能识别训练数据中预先定义的物体类别。这一固有的局限性导致模型在面对现实世界出现的新类别时,泛化能力严重不足,极大地限制了其实际应用潜力。为此,本文提出开放词汇视听语义分割新任务,如图1所示,其目标是使模型能够超越训练集的范畴,识别并分割任意未曾“见过”或“听过”的新物体,从而将该技术推向更具挑战性、也更贴近真实应用的开放世界场景。
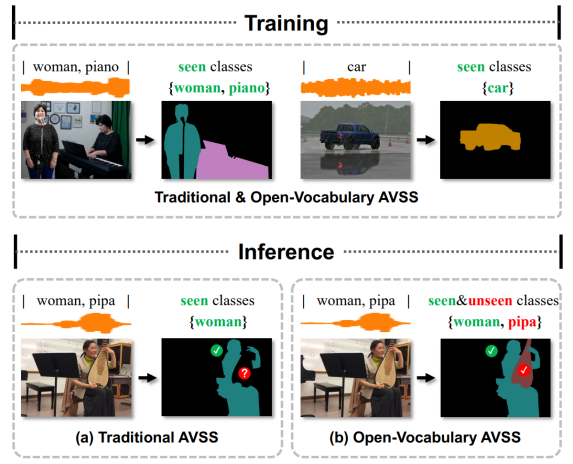
图1 基于开放词汇的视听语义分割任务说明
2.方法介绍
为解决开放词汇视听语义分割任务,本研究提出一种先定位后分类的两阶段级联框架,即OV-AVSS,如图2所示。在定位阶段,模型致力于生成“类别无关”的分割掩码,其目标是在不依赖预设类别标签的情况下,识别并分割出视频中所有正在发声的物体。为此,该框架首先独立提取视觉与听觉模态的特征。随后,通过一个采用双向注意力机制的“视听早期融合模块”,对两种模态的特征进行融合。接着,一个“音频条件Transformer解码器”利用一组物体查询,在时空维度上搜索与音频线索具有高度相关性的视觉区域。在音频信息的持续引导下,该解码器能够有效锁定发声目标,同时过滤无关的视觉干扰,最终输出精准的像素级分割掩码。成功定位发声物体之后,框架进入第二阶段的开放词汇分类任务。此阶段利用了大规模预训练的视觉-语言模型CLIP所蕴含的丰富先验知识。模型依据前一阶段生成的掩码,从视频帧中精确提取出对应的物体图像,并将其输入CLIP的图像编码器以生成视觉编码。同时,一个包含大量已知与未知类别的扩展词汇库被送入CLIP的文本编码器,从而产生相应的文本嵌入。最后,通过计算每个物体视觉嵌入与所有文本嵌入之间的相似度,模型能够为该物体赋予最匹配的类别标签,即使该类别从未在训练数据中出现过。通过这种“先定位后识别”的解耦策略,OV-AVSS框架不仅有效利用了跨模态的动态关联性来实现精准分割,也借助大规模预训练模型的知识赋能开放词汇分类,实现了对任意发声物体的精准分割与识别。
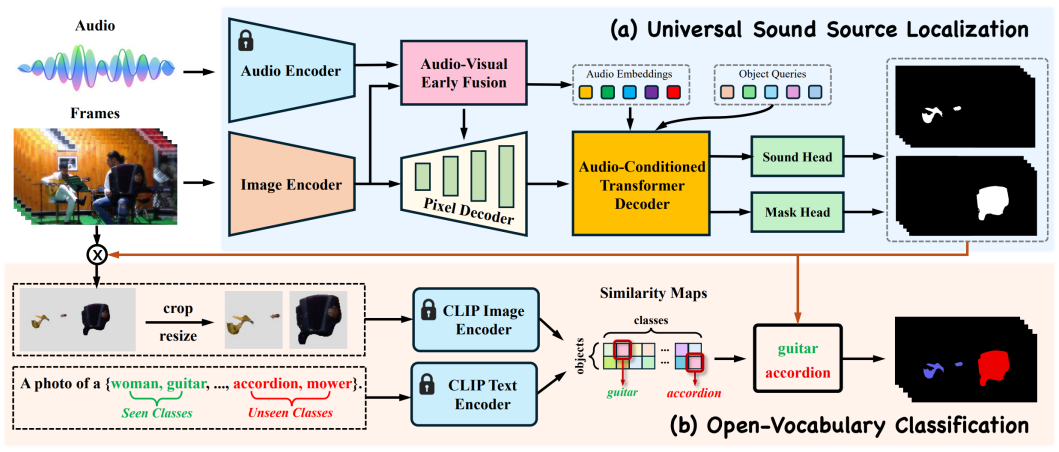
图2 OV-AVSS模型框架图
3、实验结果
为验证OV-AVSS模型的有效性,本文在AVSBench-OV数据集上进行了综合评估,如表1所示。实验结果表明,该模型在开放词汇设定下取得了当前最优的性能。与现有方法相比,OV-AVSS在分割精度等关键指标上实现了显著提升,尤其在识别和分割训练集中未见的新类别物体时,展现出良好的泛化能力。定性分析结果(图3)也直观地展示了本框架能够生成高质量的分割掩码,并准确识别任意发声物体,充分证明了其在开放世界场景下的鲁棒性与先进性。
表1 在AVSBench-OV评测基准上的实验结果
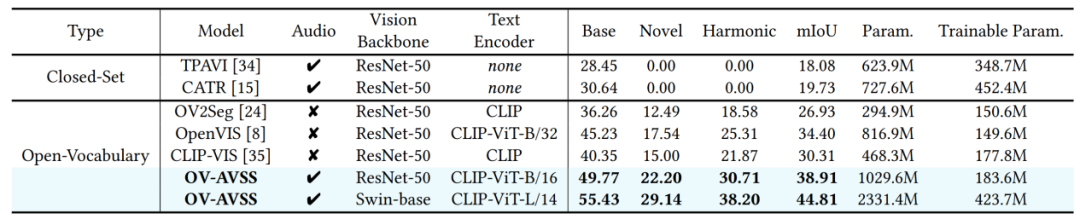
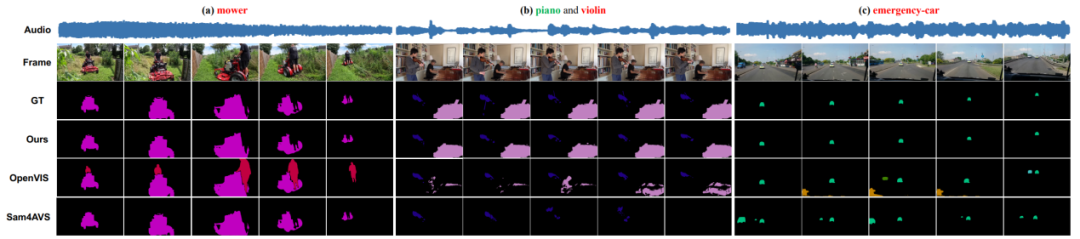
图3 不同视听场景下的分割结果比较图

编辑人:吴建龙、任文琦
专委会责任副主任:张勇东
 京公网安备11010802017125号
京公网安备11010802017125号