
【论文导读】2025年论文导读第二十二期
【论文导读】2025年论文导读第二十二期


论文导读
2025年论文导读第二十二期(总第一百三十九期)
目 录
|
1 |
Video Compression Commander: Plug-and-Play Inference Acceleration for Video Large Language Models |
|
2 |
Building Trust in Decision with Conformalized Multi-view Deep Classification |
|
3 |
GalleryGPT: Analyzing Paintings with Large Multimodal Models |
|
4 |
Subjective-Aligned Dataset and Metric for Text-to-Video Quality Assessment |
|
5 |
Diversified Semantic Distribution Matching for Dataset Distillation |
01
Video Compression Commander: Plug-and-Play Inference Acceleration for Video Large Language Models
作者:
刘旭洋1,2†,王一宇1†,麻俊鹏3,张林峰1*
单位:
1上海交通大学
2四川大学
3复旦大学
邮箱:
liuxuyang@stu.scu.edu.cn
ustywan8@ljmu.ac.uk
jpma24@m.fudan.edu.cn
zhanglinfeng@sjtu.edu.cn
论文:
https://aclanthology.org/2025.emnlp-main.98/
代码链接:
https://github.com/xuyang-liu16/VidCom2
发表会议:EMNLP 2025 Main
*通讯作者
共同第一作者
1. 研究背景
在大语言模型的浪潮中,视频大语言模型(VideoLLMs)正以惊人的速度进化,生成的响应越来越精细。然而,“慢”与计算量大依然是制约其大规模应用的最大痛点。视频序列中海量视觉token导致的二次方复杂度,让处理一个长视频往往需要漫长的等待,尤其在高分辨率或长序列场景下。
为了加速,人们通常会想到token压缩技术—剔除冗余,保留精华。但在视频领域,直接照搬这套逻辑却在视频理解领域翻车了:现有token压缩方法往往采用统一压缩策略,忽略帧间独特视觉信号,导致关键信息丢失、性能崩塌:如图1所示,移除24个冗余帧几乎不影响视频理解准确性,但丢弃仅8个独特帧即导致性能急剧下降,这凸显出视频中帧间信息分布的不均衡性,以及忽略这种差异可能带来的严重后果。
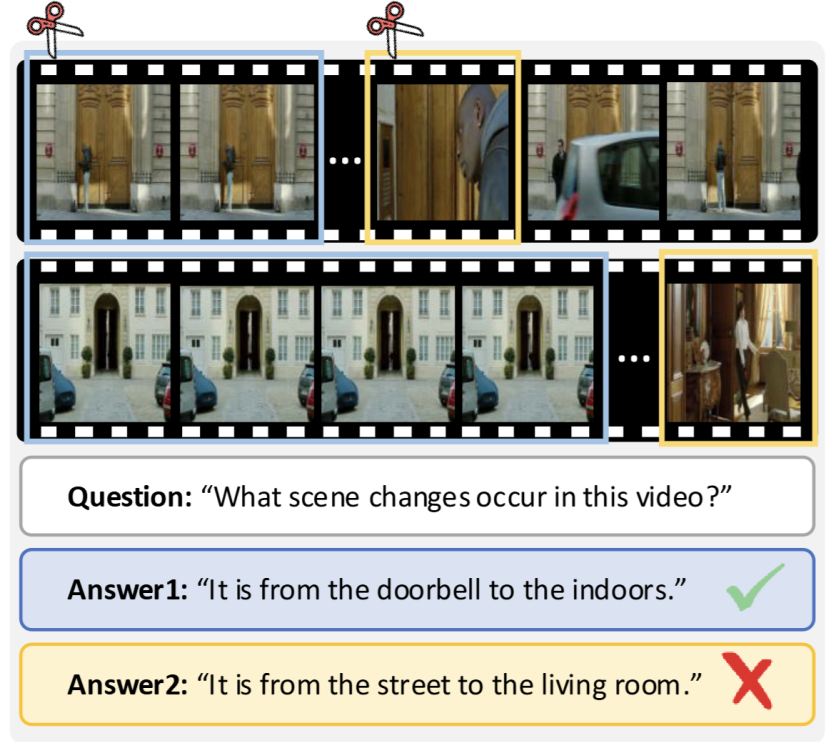
图1 帧独特性的重要性
此外,现有的一些token压缩方法受限于其实现方式,往往依赖过时的 [CLS] token 或显式的注意力权重,难以与现代SigLIP编码器和Flash Attention兼容,反而导致内存占用激增,甚至适得其反。如表1所示,当前框架在处理视频token时,既未充分考虑各帧的独特性,也忽视了压缩方法在实际部署中的可行性,难以有效支持VideoLLM的即插即用式推理加速。
表1 现有token压缩方法的问题

于是,上海交通大学EPIC实验室联合四川大学、复旦大学给出了解决方案-“视频压缩指挥官”Video Compression Commander(VidCom²),其可以在 LLaVA-OV模型上,仅保留25% token,即可实现99.6%原始性能,并减少70.8% LLM生成延迟。相关代码均已开源!
2. 方法介绍
本文提出“视频压缩指挥官” Video Compression Commander (VidCom²),一种即插即用推理加速框架,通过量化帧独特性,自适应调整帧级压缩强度,显著降低冗余同时保留关键信息。VidCom² 提炼三大设计原则:模型适应性、帧独特性和高效算子兼容性。
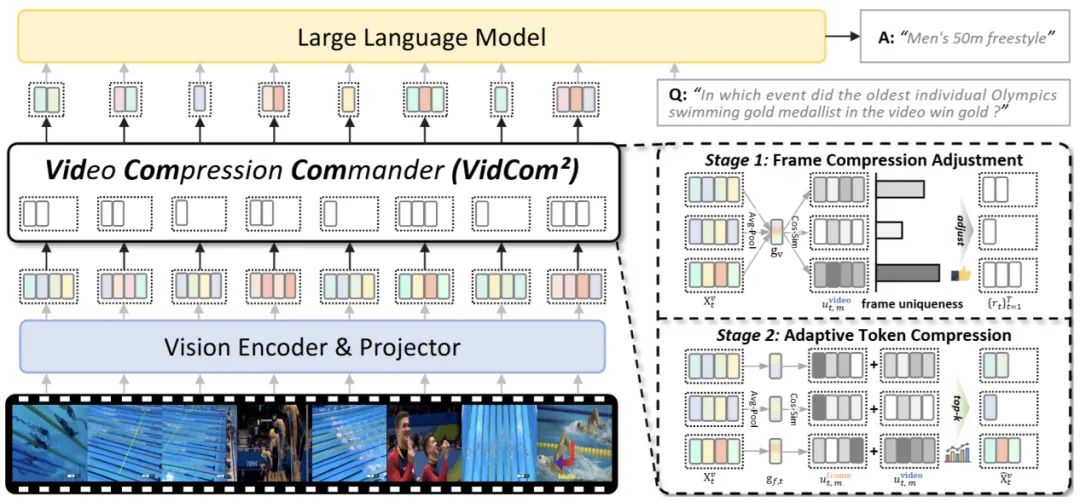
图2 VidCom² 整体框架
VidCom² 通过两阶段实现视频 token 压缩:(1)帧级压缩调整,根据帧独特性,动态分配 token 预算,确保独特帧获得更多计算资源;(2)自适应 token 压缩,结合帧内独特性和帧间独特性,以保留最具信息价值的视觉 token。如图2所示,该框架首先计算全局视频表示,然后通过余弦相似度量化每个帧的独特性分数(图3),并据此调整每帧的保留比率。随后,在第二阶段,结合帧内全局表示和综合独特性分数,自适应选择 token。该设计兼容 Flash Attention,无需额外训练,确保高效集成到 VideoLLM 推理过程中,实现即插即用推理加速。同时,如图3所示,通过柱状图可视化帧独特性分数(高度和深度表示分数大小),VidCom² 优先为独特帧分配更多 token,与人类感知一致,从而在压缩过程中有效保留关键视觉信号。

图3 帧独特性可视化
3. 实验结果
在多个基准(如 MVBench、MLVU、VideoMME)和多个 VideoLLM(LLaVA-OV、LLaVA-Video、Qwen2-VL)上,VidCom² 优于DyCoke、SparseVLM、PDrop等基线。LLaVA-OV-7B上,在25%Token保留率下,LLaVA-OV性能达99.6%(DyCoke仅87.0%);15% 下,领先 SparseVLM 3.9%!
表2 LLaVA-OV/-Video上的对比实验
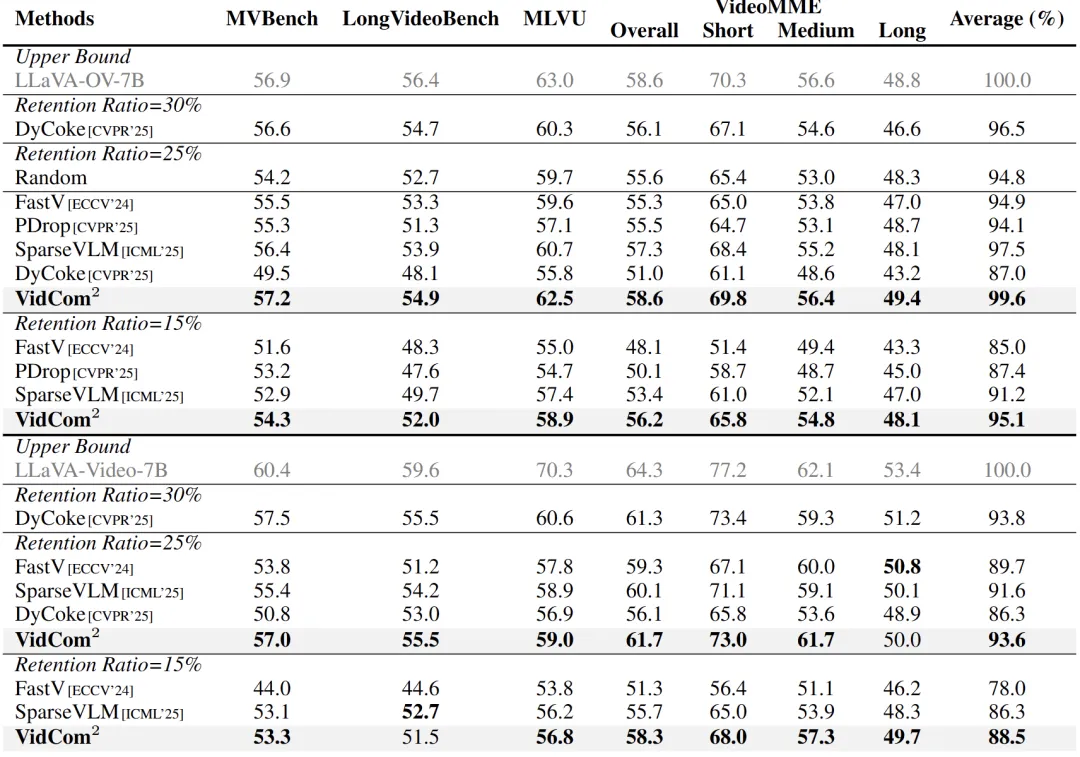
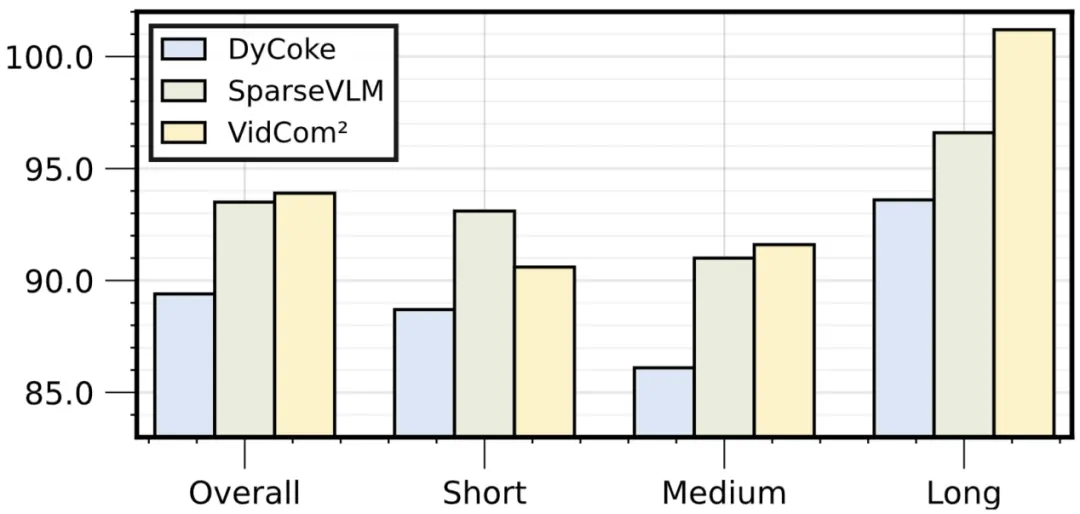
图4 在 Qwen2-VL 模型上的性能对比
此外,效率测试显示,VidCom² 将 LLM 生成延迟减少70.8%,吞吐量提升1.38×,兼容Flash Attention 的同时还可降低峰值显存。
表3 token 压缩效率分析实验
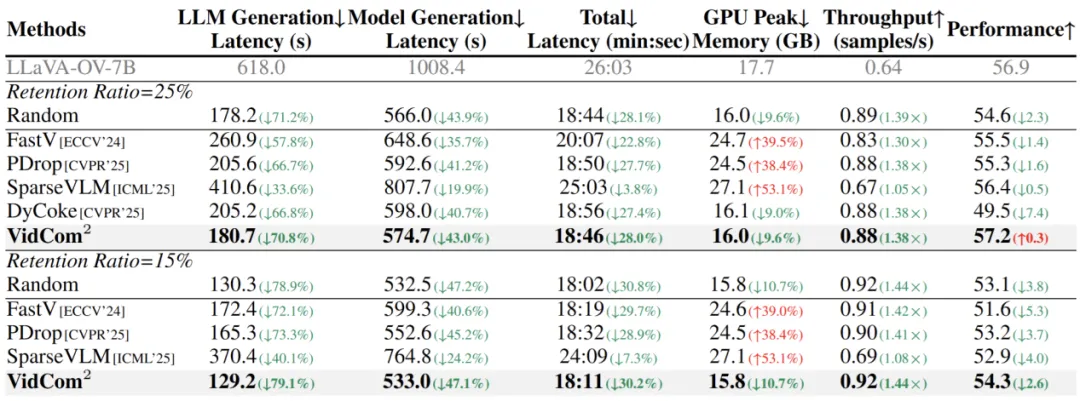
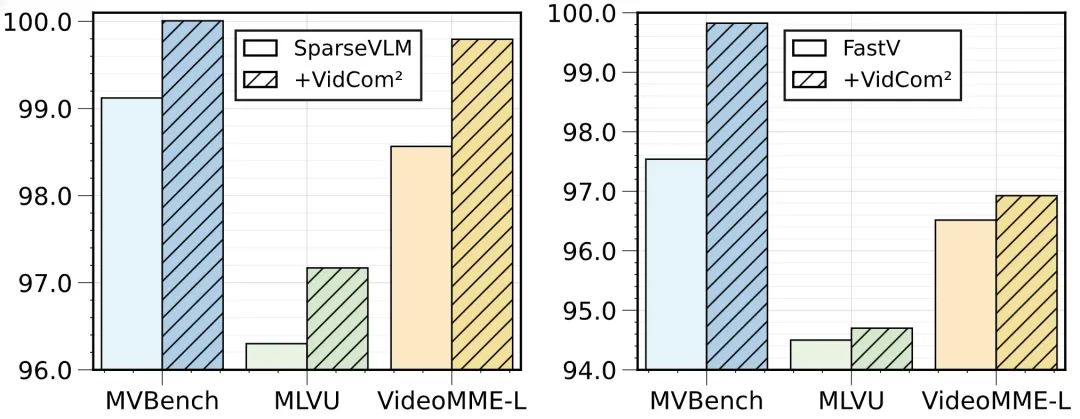
图5 与其它 token 压缩方法结合使用的效果
在 MVBench、MLVU和VideoMME-L基准上,添加 VidCom² 的帧压缩强度调整后,其它压缩方法的性能表现出显著提升,证明其通用性与鲁棒性。
4. 总结
本工作提出VidCom²框架,一种即插即用视频Token压缩方法,用于加速视频大语言模型推理。通过量化帧独特性,自适应调整压缩强度,在LLaVA-OV模型上,仅保留25% Token即可实现99.6%原始性能,并减少70.8% LLM生成延迟。框架提炼模型适应性、帧独特性和操作符兼容性三大原则,在MVBench等基准上优于DyCoke和SparseVLM,提供高效、鲁棒的视频理解新范式。
02
Building Trust in Decision with Conformalized Multi-view Deep Classification
作者:
刘伟1,陈宇飞1*,岳晓冬2
单位:
1同济大学
2上海大学
邮箱:
ldachuan@outlook.com
yufeichen@tongji.edu.cn
yswantfly@shu.edu.cn
论文:
https://dl.acm.org/doi/abs/10.1145/3664647.3681297
发表会议:ACM MM 2024 (Oral)
*通讯作者
1.研究背景
现有的不确定性感知多视图分类方法,在实际应用中面临两大核心局限。以胰腺肿瘤亚型分类({Normal,SCN,PDAC})为例:
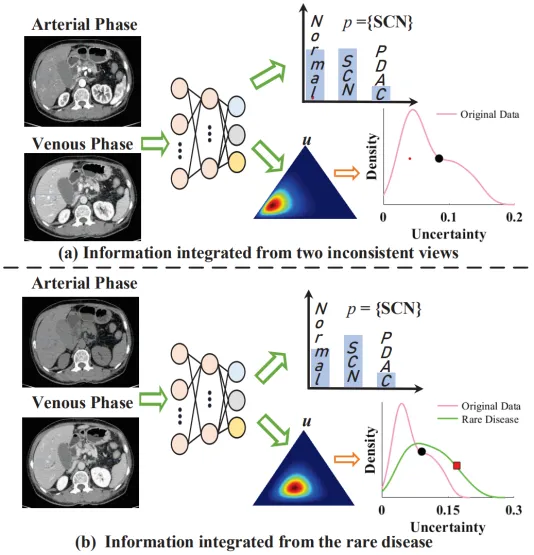
图1 现有方法在两种常见情况下的局限性
1)预测结果单一:当不同视图(如动脉期和静脉期)的信息相互冲突或类别边界模糊(如图1a所示,融合后的SCN与Normal支持度持平),现有方法仍局限于提供一个单一类别预测(如SCN)。这种无法反映决策模糊性的预测,给高风险场景(如临床诊断)带来了隐患。
2)不确定性度量缺乏标准:尽管模型能量化不确定性,但其度量值的大小缺乏统一标准,常随数据集而异。如图1b所示,一个罕见病样本(绿色曲线)的不确定性得分虽相对高于常规数据(粉色曲线),但其绝对值可能仍然很低,导致决策者难以设定一个可靠阈值来识别异常或分布外样本。
2.方法介绍
为解决上述问题,本研究提出共形多视图分类(CMDC)框架。该方法以集值预测取代单值预测,并通过以下三个核心机制构建可信决策:
1)预测集生成:CMDC不再输出单一类别,而是生成包含一个或多个候选标签的子集。对于信息冲突或边界模糊的困难样本,该预测集将包含所有可能的类别。
2)显式异常识别:为清晰量化不可靠性,CMDC在输出空间中显式定义了一个异常类别。这使得模型能够清晰地指代由数据噪声或分布外样本引起的不可靠预测。
3)理论覆盖保证:基于共形预测理论,CMDC能确保其生成的预测集以用户自定义的置信概率(如1-τ=90%)在理论上包含真实标签。
3.实验结果
我们在膝关节数据集MRNet上进行了真实案例分析。如图2所示,案例1212的三个视图(轴位、冠状位、矢状位)均包含大量噪声,而案例1194则包含积液与伪影。
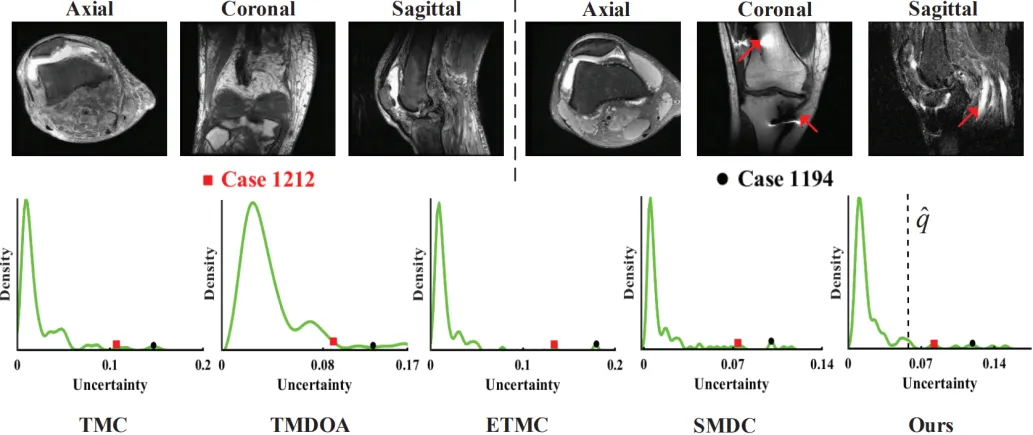
图2 MRNet数据集上的案例分析
尽管这两个案例的不确定性估计值高于其他测试点,但由于其绝对值仍然较小,其他四种方法难以设定清晰阈值来判定其为异常。相比之下,我们的方法提供了一个具有统计保证的判定阈值,极大简化了判断过程。
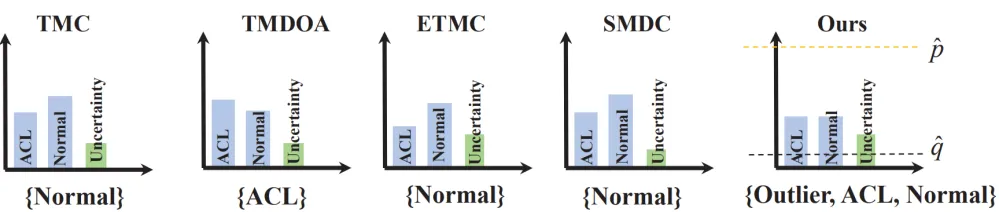
图3 案例1212的预测结果可视化
此外,如图3所示,我们进一步展示了案例1212的类别概率。由于该病例视图中存在严重噪声,其他方法在ACL类与Normal类上给出了几乎相等的概率,导致预测结果高度模糊或接近随机猜测。CMDC则通过阈值提供了一个包含所有可能选项的预测集,从而有效规避了由多视图冲突或异常样本所带来的决策风险。
4.总结
本文提出了一种新的共形多视图分类模型。它通过生成包含异常类的可靠预测集,代替了传统的不确定的单一预测。通过有效的多视图融合策略和共形预测理论,为决策者提供了具有理论覆盖率保证的预测结果,在处理视图冲突和异常样本时表现出显著优势,有效提升了多视图决策的可信性。
03
GalleryGPT: Analyzing Paintings with Large Multimodal Models
作者:
宾燚1,3,史文浩2,丁玉娟4*,胡志强5,汪政1,杨阳2,See-Kiong Ng3,申恒涛1,3
单位:
1同济大学
2电子科技大学
3新加坡国立大学
4香港理工大学
5新加坡科技设计大学
邮箱:
yi.bin@hotmail.com
shiwenhao16@gmail.com
dingyujuan385@gmail.com
zhiqiang_hu@mymail.sutd.edu.sg
zh_wang@hotmail.com
yang.yang@uestc.edu.cn
seekiong@nus.edu.sg
shenhengtao@hotmail.com
论文:
https://doi.org/10.1145/3664647.3681656
代码链接:
https://github.com/steven640pixel/GalleryGPT
发表会议:ACM MM 2024
*通讯作者
1.研究背景
现有的多模态大模型大多聚焦于视觉信息(图像/视频)理解,特别是日常视觉内容理解。然而,作为人类社会发展和精神生活的重要组成部分,艺术作品(如绘画)分析被视为人类创造力的特有表现,智能分析还鲜有研究。本工作以此为切入点,探究了当前多模态大模型,如GPT4V以及Gemini,在艺术绘画分析中的表现,并发现现有模型在绘画分析中会受所学习到的先验知识影响,进而生成部分错误的分析,我们将这种现象称为“LLM-biased Visual Hallucination”。针对此问题,我们尝试收集高质量的艺术绘画分析数据微调现有多模态大模型来增强其对艺术绘画特有的视觉特性感知能力,如线条、光影以及构图等方面的感知能力。值得注意的是,本工作巧妙利用大语言模型所学习到的海量先验知识,仅使用语言模型就可以收集到高质量的图像-文本数据用于微调增强多模态大模型。
2.方法介绍
我们精心收集了大约19k幅艺术绘画图片,利用大语言模型根据绘画的标题和艺术家姓名,标注仅关注视觉特征的整体艺术分析段落,并对特定的艺术分析层面如构图、色彩、光影、线条等进行标注,从而合成50k艺术绘画分析数据PaintingForm。具体流程如下:
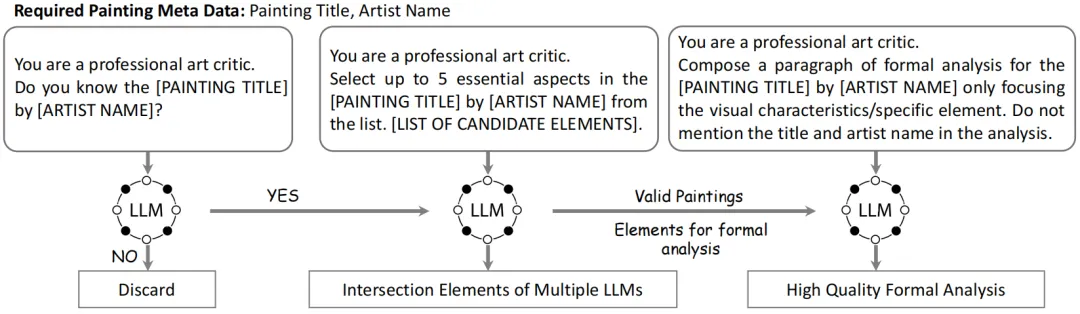
图1 PaintingForm数据集构建流程
1)绘画数据收集
大量艺术绘画以数字化图像形式存储,我们选用1st Art Gallery网站作为艺术绘画图像的数据来源,首先爬取了19295幅著名的艺术家画作图像。为了确保大语言模型提供准确的艺术绘画分析标注,我们根据Gemini判断知道这些画作的标题和艺术家的姓名与否,从而过滤掉判断为未知或没有特定标题的画作,最终获得18526幅画作图像。不同艺术家的画作数量统计如下:
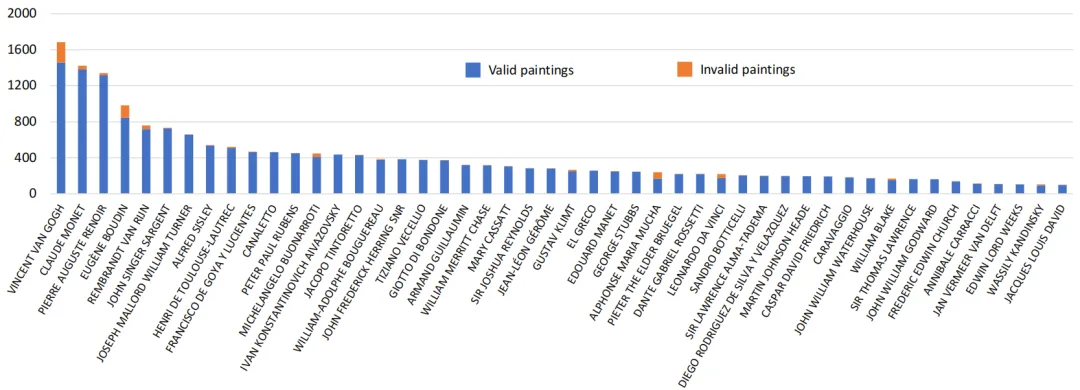
图2 数据集中不同艺术家画作数量的统计分布图
2)艺术分析数据标注
对选取的艺术绘画进行人工标注需要标注者具备艺术品分析鉴赏方面的专业知识,这是困难且昂贵的,而且对艺术绘画进行人工标注需要大量时间开销。对于每一幅绘画,我们利用GPT-4和Gemini的海量先验知识,仅通过输入画作标题和艺术家姓名,不输入任何视觉信息,生成一段只关注艺术视觉特征的分析。其中不能提及画作标题和艺术家姓名,不能仅凭分析段落就轻易识别出对应的画作。
为了使分析数据更加多样,生成两方面的艺术分析:(1)整体分析;(2)对某一艺术层面包括构图、光影、色彩、形状、纹理、象征与图标、透视、运动与姿态、线条质量、尺度比例进行分析。对具体的艺术层面进行分析标注,我们要求GPT-4和Gemini分别提供5个给定画作可分析的层面,再利用两者输出的交集作为所选定层面进行标注。不同层面对应的绘画数量统计如下:
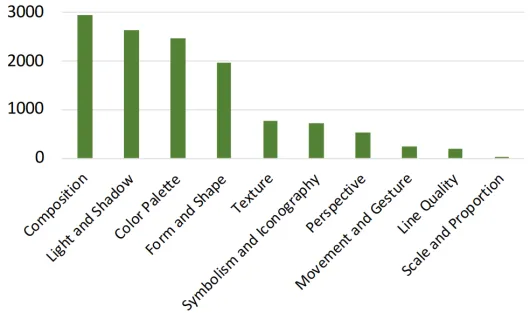
图3 不同要素层面的统计分布情况
3.实验结果
我们使用PaintingForm对ShareGPT4V进行微调得到我们的GalleryGPT模型,来增强对艺术绘画特有的视觉特性感知能力和以视觉元素为重点的艺术分析能力。本工作首先对5000幅相较非著名的艺术绘画的分析数据进行文本生成验证,采用字幕描述指标进行分析评估。同时测试了开源多模态大模型LLaVA-1.5、Qwen-VL-Chat和ShareGPT4V,实验结果验证了高质量的绘画图像-艺术分析文本数据合成和微调增强多模态大模型的有效性。
表1 艺术分析生成任务的性能对比
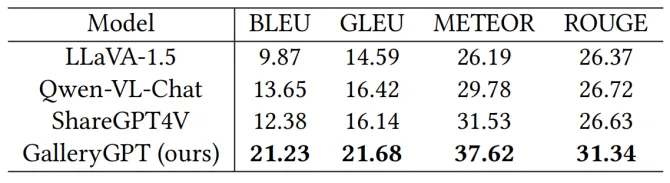
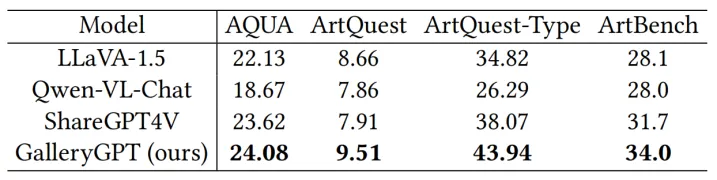
我们还验证GalleryGPT对艺术绘画下游分析任务的表现,在现有的风格分类和问答数据集上的实验结果表明GalleryGPT显著优于其他开源多模态大模型,展示其对下游艺术绘画分析任务的泛化能力。
表2 艺术绘画下游分析任务的性能对比
相较于一些主流的多模态大模型,GalleryGPT展现出了对不著名画作进行全面艺术分析的能力。例子如下,GalleryGPT不仅仅能简单的描述画作的真实视觉内容,也更注重分析微妙的艺术元素,包括色彩、光影、构图和透视等。

图4 不同多模态大模型在艺术分析生成方面的定性对比示例
此外,GalleryGPT能够遵循艺术绘画分析的指令,给出输入绘画的整体艺术分析,不同艺术层面分析以及艺术风格等。指令对话的例子如下:

图5 GalleryGPT模型指令对话示例
4.总结
本工作聚焦于艺术绘画智能分析,当前主流的多模态大模型在进行艺术绘画分析时面临LLM-biased Visual Hallucination现象,会受所学习到的先验知识影响,识别为其他对象进而生成部分错误的分析。因此我们巧妙地利用大语言模型收集高质量的绘画图像-艺术分析文本数据PaintingForm,用于微调增强多模态大模型对艺术绘画特有的视觉特性感知能力,我们的GalleryGPT展现出优越的艺术绘画分析表现。在未来的研究工作中,我们将不局限于绘画,探索更广泛的艺术种类和作品分析。最后欢迎大家交流探讨,特别是有艺术专业背景的朋友。
04
Subjective-Aligned Dataset and Metric for Text-to-Video Quality Assessment
作者:
寇腾川1,刘笑宏1*,张子澄1,李春一1,吴昊宁2,闵雄阔1,翟广涛1,柳宁1*
单位:
1上海交通大学
2南洋理工大学
邮箱:
2213889087@sjtu.edu.cn
xiaohongliu@sjtu.edu.cn
zzc1998@sjtu.edu.cn
lcysyzxdxc@sjtu.edu.cn
haoning001@e.ntu.edu.sg
minxiongkuo@sjtu.edu.cn
zhaiguangtao@sjtu.edu.cn
ningliu@sjtu.edu.cn
论文:
https://doi.org/10.1145/3664647.3680868
代码链接:
https://github.com/QMME/T2VQA
发表会议:
ACM MM 2024
*通讯作者
1.研究背景
随着生成式模型的快速发展,人工智能生成内容(AIGC)在日常生活中的应用呈指数级增长。其中,文生视频(Text-to-Video,T2V)技术备受关注。然而众多文生视频模型的生成质量参差不齐,严重影响消费者体验,因此亟需建立与主观感受相一致的质量评估方法。遗憾的是,现有视频质量评价(VQA)模型难以胜任此任务。一方面,文生视频模型产生的失真现象(如抖动效应、不合逻辑的物体)与自然视频中的失真截然不同;另一方面,传统VQA模型未考虑文本-视频对齐关系,而这恰是评估文生视频质量的关键维度。
2.方法介绍
为构建更全面精准的文生视频评价指标,我们建立了至论文发表为止规模最大的主观文生视频质量评价数据集(T2VQA-DB)。我们首先从WebVid-10M中采样得到1,000条文本提示用于视频生成,并根据文本内容将其分为自然、人体、人造景观、动物、物体、抽象和其他七类。图1展示了所用文本的词云图。接着我们使用Text2Video-Zero,AnimateDiff,Tune-a-video,VidRD,VideoFusion,ModelScope,LVDM,Show-1,和LaVie等9种具有代表性的文生视频模型,使用上述文本生成了10,000段视频。图2展示了9种模型由文本“海上的落日”所生成的视频帧示例。最后我们进行了完备的主观实验,由27名受试者对生成视频的整体质量进行评分,收集每段视频的平均意见得分(MOS)。我们相信T2VQA-DB将推动后续文生视频质量评价模型的发展。
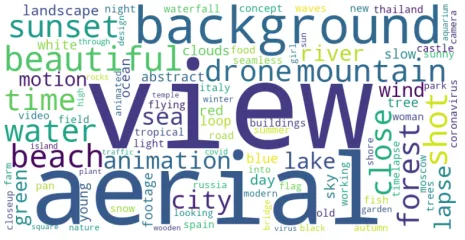
图1 T2VQA-DB词云图

图2 根据文本“海上的落日”生成的视频帧示例
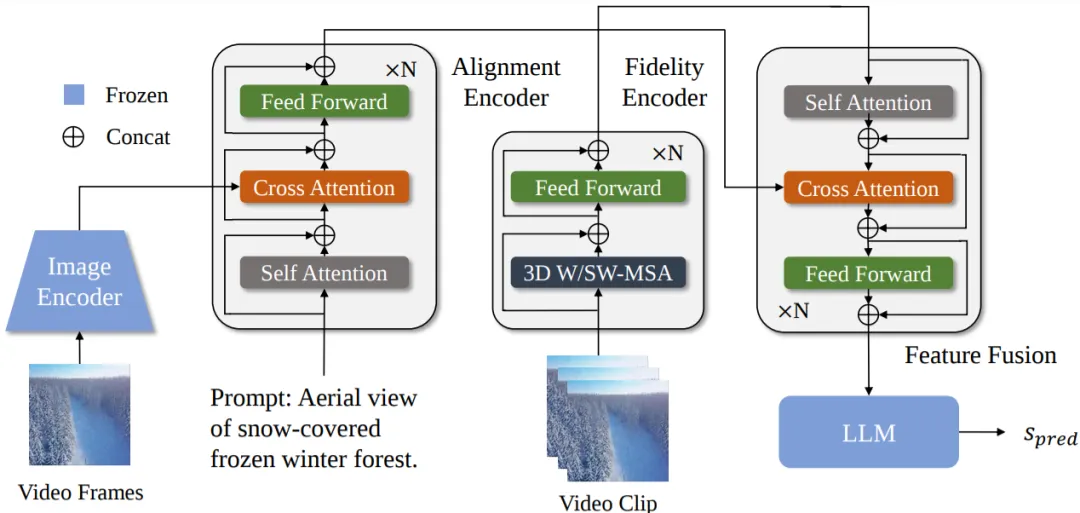
图3 T2VQA模型框架概览
基于T2VQA-DB,我们提出T2VQA,该模型利用基于Transformer架构来进行文生视频质量评价,图3展示了T2VQA的大致框架。该模型从文本-视频对齐度和视频保真度两个维度进行特征提取。在文本-视频对齐度维度,我们使用预训练的BLIP图像和文本编码器,分别提取视频帧和文本特征后,通过交叉注意力模块进行交互,最终输出表示文本-视频帧相似度的特征。视频保真度指的是从空间和时间域感知到的失真程度。在空间域中,常见的失真类型包括模糊、噪声、低/高对比度等;时间域失真包括抖动、卡顿、运动模糊等。该维度可以被视为经典的视频质量评价任务。我们使用Swin-Transformer进行该维度的特征提取,其使用基于3D移位窗口的多头自注意力机制,已被证明在各种 VQA 任务中表现出色。在使用交叉注意力机制融合两维度特征后,我们利用大语言模型(LLM)进行质量回归。具体来说,我们将融合特征与指令“请给这段视频评分”连结,作为大模型Vicuna v1.5的输入。在Vicuna的输出中,我们提取体现质量的五类词语:“bad”,“poor”,“fair”,“good”,“excellent”的logit并做softmax,使其代表每类词语的输出概率。我们再依次对五类词语赋予1~5的权重,进行加权平均,通过以上操作,我们得到最终的预测质量分数。
3.实验结果
我们首先在T2VQADB上进行训练和测试。遵循数据集分割的惯例,80%的数据被用于训练,20%用于测试。为了消除单个拆分中的偏差,我们将数据集随机拆分10次,并使用平均结果进行性能比较。表1中的前四列是T2VQA与其他模型在T2VQA-DB上的性能比较。结果表明,T2VQA在两项指标中都表现最好,在SRCC中比次佳的Q-Align高出4.79%,在PLCC中高出3.84%。零样本模型的指标得分都相对较低。因它们要么只考虑文本-视频对齐,要么不分析视频帧内的时域信息。VQA模型得分较高,表明视频保真度严重影响对文生视频质量的评估。然而,从视频保真度的单一角度不能正确地解决问题,因为在某些情况下,生成的高保真视频与文本提示并不匹配。图4展示了不同模型的预测分数和真实分数的散点图。T2VQA具有更贴近对角线的拟合曲线,表示其性能更佳。
为验证模型泛化性,我们在ECTV,TVGE和Sora数据集上进行了测试。对ECTV和TVGE,我们分别随机挑选800个视频进行测试。对Sora,我们从其官网收集得到48段生成视频。T2VQA和其他模型性能列于表1右侧六列中。实验结果表明,T2VQA在所有模型中具有最好的泛化能力。
表1 T2VQA和其他视频质量评价模型的性能对比

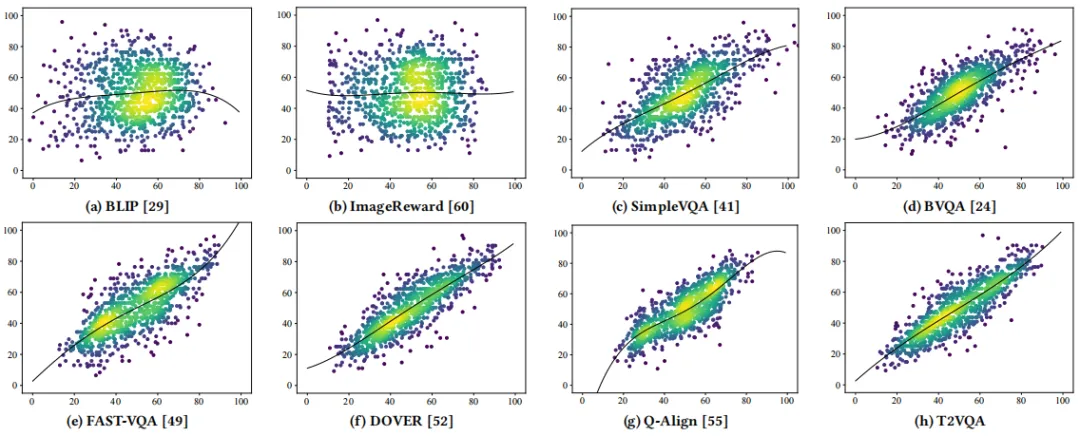
图4 预测分数和真实分数的散点图
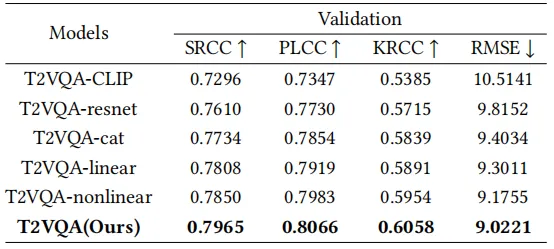
为了验证T2VQA中每个模块的有效性,我们进行了全面的消融实验。对视频-文本对齐编码器,我们对比了使用CLIP作为视频帧和文本编码器的性能。对视频保真度编码器,我们对比了使用ResNet的性能。对融合模块和回归模块,我们对比了使用简单连结融合,线性回归和非线性回归的性能。表2结果显示,T2VQA在所有指标上均为最优,验证了其各部分的有效性。
表2 消融实验结果
4.总结
综上,本文致力于为文生视频的质量提供预测。为此,我们建立了规模最大的文本到视频数据集T2VQA-DB,该数据集包含由9种先进文生视频模型生成的10,000个视频。我们还开展了主观研究以获取视频整体质量的平均评分(MOS)。基于T2VQA-DB,我们提出一种基于Transformer的文生视频质量评价新模型——T2VQA。该模型分别从文本-视频对齐和视频保真度两个维度提取视频特征,融合特征后通过大语言模型进行最终预测回归。实验结果表明,T2VQA能有效评估文生视频的质量。
05
Diversified Semantic Distribution Matching for Dataset Distillation
作者:
李洪成1,2,3†,周玉灿1,2*,古晓艳1,2,3*,李波1,3,王伟平1
单位:
1中国科学院大学网络空间安全学院
2中国科学院信息工程研究所
3网络空间安全防御全国重点实验室
邮箱:
lihongcheng@iie.ac.cn
zhouyucan@iie.ac.cn
guxiaoyan@iie.ac.cn
libo@iie.ac.cn
wangweiping@iie.ac.cn
论文:
https://dl.acm.org/doi/10.1145/3664647.3680900
代码链接:
https://github.com/Li-Hongcheng/DSDM
发表会议:ACM MM 2024
*通讯作者
†共同第一作者
1.研究背景
在大数据时代,多媒体数据规模激增,使模型训练与存储面临巨大压力,因此从海量数据中提炼紧凑且具有代表性的子集成为关键问题。数据集蒸馏旨在将原始数据“浓缩”为小规模数据集,同时保持模型性能。现有基于分布匹配的方法通常通过对齐类原型进行优化,但如图1所示,仅对齐原型会使蒸馏样本集中在类别中心,无法覆盖颜色、姿态、视角等语义差异,导致多样性不足。为改进这一问题,可利用刻画类内变异的协方差矩阵,其不同方向对应颜色、姿态、视角等变化,可生成丰富语义变体。因而,对齐蒸馏数据与原始数据的协方差矩阵能够在保持类中心一致的同时提升语义多样性,进一步增强模型的泛化能力。
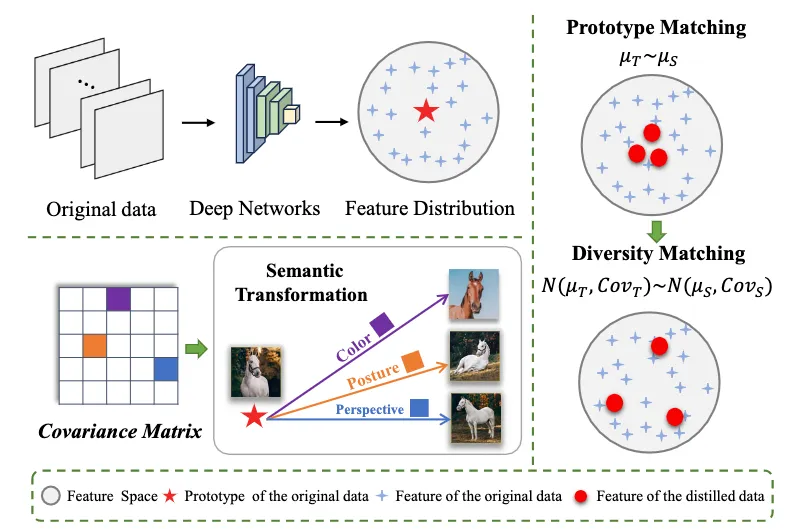
图1 不同于以往仅对齐原始数据与蒸馏数据原型的方法,我们的方法对齐两者的高斯分布
2.方法介绍
为了获得更准确的特征,我们首先使用原始数据集训练多个模型。在每次迭代中随机选择一个预训练模型,并分别从原始数据集和蒸馏数据集中提取特征。基于这些特征,我们计算每个类别的原型及其协方差矩阵,其中原型表征类别的固有特征,而协方差矩阵则刻画类内所有特征的语义多样性。随后,我们对齐原始数据与蒸馏数据在每个类别上的原型和协方差矩阵,以提升蒸馏分布的表征能力。然而,由于迭代过程中使用的预训练模型不同,蒸馏数据在各轮迭代中可能呈现显著的特征分布差异,从而导致优化不稳定。为缓解这一问题,我们进一步将蒸馏数据的历史原型与当前原型对齐,以减少模型切换带来的分布波动,提升整个蒸馏过程的稳定性。
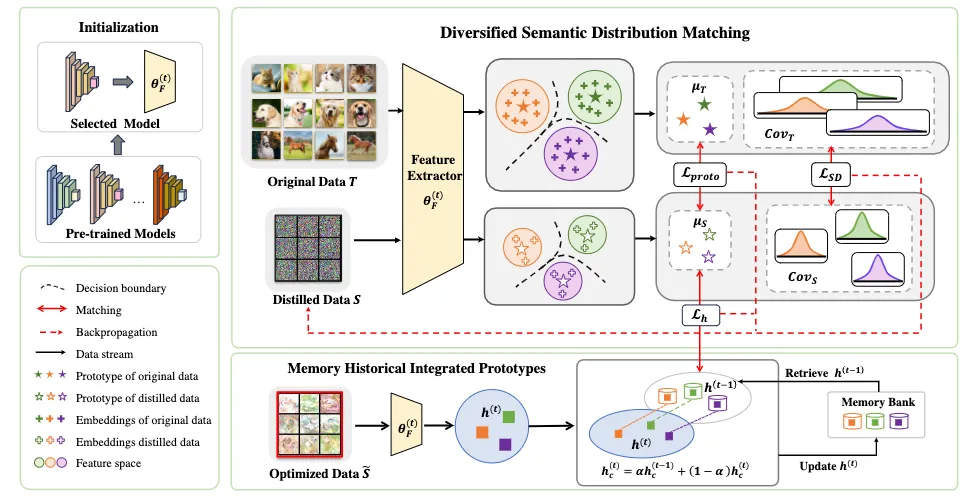
图2 方法框架图
3.实验结果
为了全面评估所提出数据集蒸馏方法的有效性,我们在五个图像数据集和一个语音数据集上进行了实验。五个图像数据集包括 MNIST、FashionMNIST(FMNIST)、SVHN、CIFAR-10 和 CIFAR-100;语音数据集选用 Mini-Speech-Commands,其包含 8000 条 1 秒钟的音频片段,涵盖八类语音指令。在所有数据集上,我们的方法均取得了优于现有方法的实验结果,验证了其在不同模态和任务场景下的稳健性与优越性。
表1 在多个图像数据集上蒸馏图像训练的模型的Top-1准确率
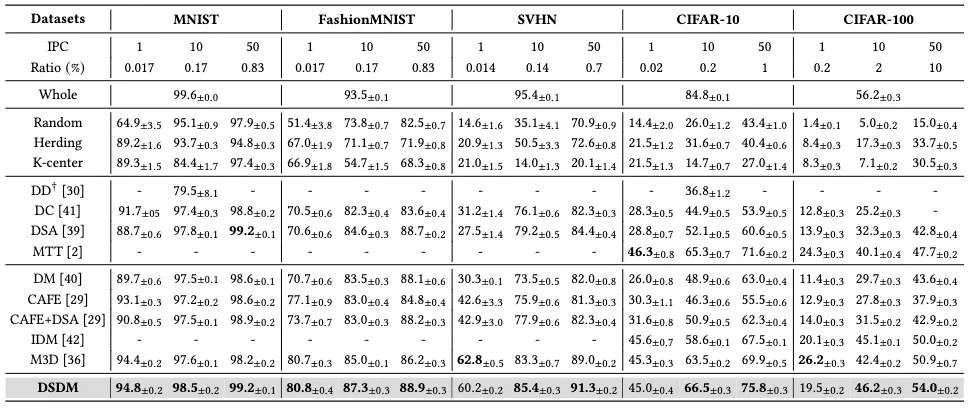
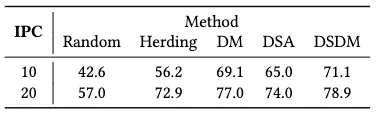
表2 在经过蒸馏声谱图训练的ConvNet-4的Top-1准确率
4.总结
本研究提出多样性语义分布匹配(DSDM)方法,通过原型对齐、语义多样性对齐和历史原型对齐三项损失,显式捕捉原始数据的语义多样性。其中前两项用于对齐真实数据分布,历史原型对齐用于提升蒸馏过程的稳定性。

编辑人:吴建龙、任文琦
专委会责任副主任:张勇东
 京公网安备11010802017125号
京公网安备11010802017125号