
【论文导读】2025年论文导读第二十三期
【论文导读】2025年论文导读第二十三期


论文导读
2025年论文导读第二十三期(总第一百四十期)
目 录
|
1 |
Rethinking Joint Maximum Mean Discrepancy for Domain Adaptation |
|
2 |
HPC: Hierarchical Progressive Coding Framework for Volumetric Video |
|
3 |
Video Bokeh Rendering: Make Casual Videography Cinematic |
|
4 |
LiteQUIC: Improving QoE of Video Streams by Reducing CPU Overhead of QUIC |
|
5 |
Advancing Multi-grained Alignment for Contrastive Language-Audio Pre-training |
01
Rethinking Joint Maximum Mean Discrepancy for Domain Adaptation
作者:
王维1,夏海峰1,黄超1*,丁正明2,王聪3,李豪杰4,操晓春1
单位:
1中山大学深圳校区
2美国杜兰大学
3美国加州大学圣地亚哥分校
4山东科技大学
邮箱:
wangwei29@mail.sysu.edu.cn
xiahf5@mail.sysu.edu.cn
huangch253@mail.sysu.edu.cn
zding1@tulane.edu
supercong94@gmail.com
caoxiaochun@mail.sysu.edu.cn
hjli@sdust.edu.cn
论文:
https://openreview.net/pdf?id=XoN10bZtR9
发表会议:NeurIPS 2025 Spotlight
*通讯作者
1. 研究背景
领域自适应已成为解决现实场景中普遍存在的领域差异问题的有效技术,其核心挑战在于如何度量不同概率分布之间的距离。为此,研究者们提出了多种分布距离度量方法。其中,最大均值差异(MMD)通过可再生核希尔伯特空间(RKHS)中的均值嵌入,估计两个概率分布之间的距离。由于其简单性和坚实的理论基础,它已被广泛应用于深度生成模型和变分自编码器等问题中。尽管MMD能够建立边际、类条件和加权类条件概率分布距离,但对于联合概率分布距离(即联合最大均值差异,JMMD)的探索仍不充分,并且难以应用于子空间学习框架,因为其经验估计涉及一个张量积算子,其偏导数难以获得。
2. 方法介绍
在子空间学习框架中,JMMD通过无限维投影矩阵T,将数据特征和标签映射到投影RKHS中(图1(a)至图1(b)上部分)。在该空间中,通过最小化源域与目标域特征—标签依赖的差异,实现联合概率分布对齐(图1(d))。该依赖关系由张量积算子描述的协方差表征。但无限维T的偏导数难以直接计算。本文基于表示定理,推导出简化的JMMD形式。该定理利用核函数系数矩阵B(有限维),结合矩阵运算性质消除张量积。因此,JMMD在子空间学习框架中关于B的导数较易获得。通过简化的JMMD形式,得出两项核心发现。首先,证明了JMMD的统一性:以往广泛应用的边缘概率分布距离、类条件概率分布距离及加权类条件概率分布距离,均为JMMD在标签核函数K1,K2,K3下的三种特例,且已验证这些标签核函数均满足可再生性质。该发现为领域自适应中针对不同问题设计标签核函数以优化JMMD提供了理论指导。
此外,近期研究表明,分布对齐过程会意外降低特征判别性,但缺乏理论支撑。为揭示这一现象,借鉴JMMD的推导思路,提出了一种简洁的希尔伯特—施密特独立性准则(HSIC),该准则通过建模特征与标签的依赖关系并最大化此依赖度来提升特征判别性(特征—标签依赖度越高,特征判别性越强,反之则越弱)(图 1(b)下半部分)。我们为HSIC设计了标签再生核函数K4,以增强类内紧致性或特征判别性。随后,受图嵌入思想启发,探究JMMD与HSIC的内在关联,从而深入理解JMMD导致特征判别性下降的本质原因。具体而言,发现在HSIC的图结构中用于增强类内紧致性的相似权重,在JMMD的图结构中取相反符号,这正是JMMD意外降低特征判别性的核心诱因。如图1(c)所示,在特征空间中,JMMD的作用是拉远同一领域内同类数据点的距离,同时拉近不同领域间同类数据点的距离;而HSIC则旨在拉近同一领域内同类数据点的距离(即增强类内紧致性)。为此,提出一种损失函数JMMD-HSIC,通过联合考虑JMMD与HSIC的优化目标,有效提升了JMMD的特征判别性,进而增强其领域自适应性能(图1(d))。
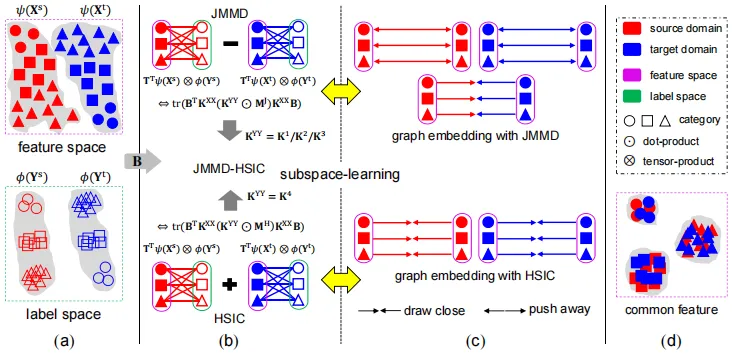
图1 本文所揭示的理论结果及所提JMMD-HSIC方法的整体概述如下:(a)分别将源域与目标域的特征和标签映射至可再生核希尔伯特空间;(b)JMMD与HSIC在子空间学习框架中的应用;(c)子空间学习框架下JMMD与HSIC的图嵌入解释;(d)子空间学习后得到的源域与目标域特征表示。
3. 实验结果
由表1和表2可见,所提方法的平均性能优于基线方法SPL和OGL2P,且OGL2P+JMMD-HSIC在所有对比方法中取得了最优的平均结果。图2展示了特征分布可视化结果,评判标准如下:相同颜色但不同形状的数据点对齐度越高,表明分布差异越小;相同颜色数据点的聚类越紧密,表明特征判别性越好。如图2所示:原始特征在分布对齐与判别性两方面均表现较差;JMMD虽能尝试对齐源域与目标域的特征分布,但严重破坏了特征判别性;HSIC增强了源域与目标域的判别结构,然而其分布对齐效果不佳(虚线框标注区域可清晰看出,相同颜色但不同形状的数据点分布在不同区域);与HSIC相比,JMMD-HSIC的特征分布匹配效果更优(虚线框标注区域中,相同颜色但不同形状的数据点集中分布在同一区域);且与JMMD相比,同类数据点的聚类更紧密(判别性更优)。
表1 Office-31数据集上的对比结果
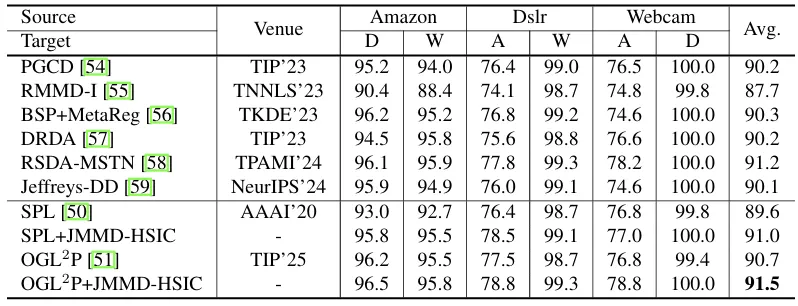
表2 Office-Home数据集上的对比结果
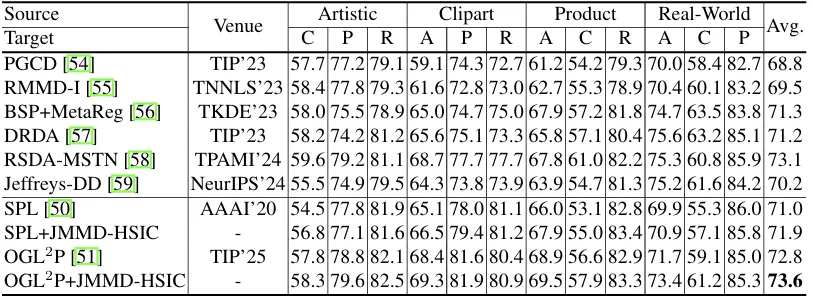

图2 特征可视化结果。不同颜色表示不同类别,而不同形状则表示不同域
02
HPC: Hierarchical Progressive Coding Framework for Volumetric Video
作者:
郑子涵†、钟后强†、胡强*、张小云、宋利、张娅、王延峰
单位:
上海交通大学
邮箱:
1364406834@sjtu.edu.cn
zhonghouqiang@sjtu.edu.cn
qiang.hu@sjtu.edu.cn
xiaoyun.zhang@sjtu.edu.cn
song_li@sjtu.edu.cn
ya_zhang@sjtu.edu.cn
wangyanfeng@sjtu.edu.cn
论文:
https://dl.acm.org/doi/10.1145/3664647.3681107
发表会议:ACM MM 2024
*通讯作者
共同第一作者
1.研究背景
基于神经辐射场(Neural Radiance Field, NeRF)的体视频在各类3D应用中具有巨大潜力,但其庞大的数据量给压缩和传输带来了严峻挑战。当前的NeRF 压缩技术缺乏灵活性,无法在单一模型内根据不同的网络和设备性能调整视频质量与码率。为解决这些问题,我们提出了HPC(Hierarchical Progressive Coding Framework for Volumetric Video)框架,这是一种新型的分层渐进式体视频编码框架,可通过单一模型实现可变码率。
2.方法介绍
HPC核心灵感源自传统视频编码中成熟的“可伸缩视频编码 (Scalable Video Coding, SVC)”思想,通过设计一种分层 (Hierarchical) 的神经特征表示来实现。HPC基础层分辨率最低,包含了场景最核心的结构和外观信息,仅用它便可渲染出基础画质的视频。在此之上,HPC构建了多个分辨率递增的残差特征层,每一层都是对上一层的细节补充,具有渐进式的特性。当用户开始观看时,播放器可以先快速下载并解码基础层,迅速呈现画面。若网络条件允许,则继续下载增强层,画质便会“逐级”提升。这赋予了系统在几个预设“档位”间灵活切换的能力。为了让每个档位都达到最优性能,HPC还引入了一套渐进式训练策略,在训练时逐层优化,确保了每一层特征的表达和压缩都足够高效。图1为HPC的框架图。
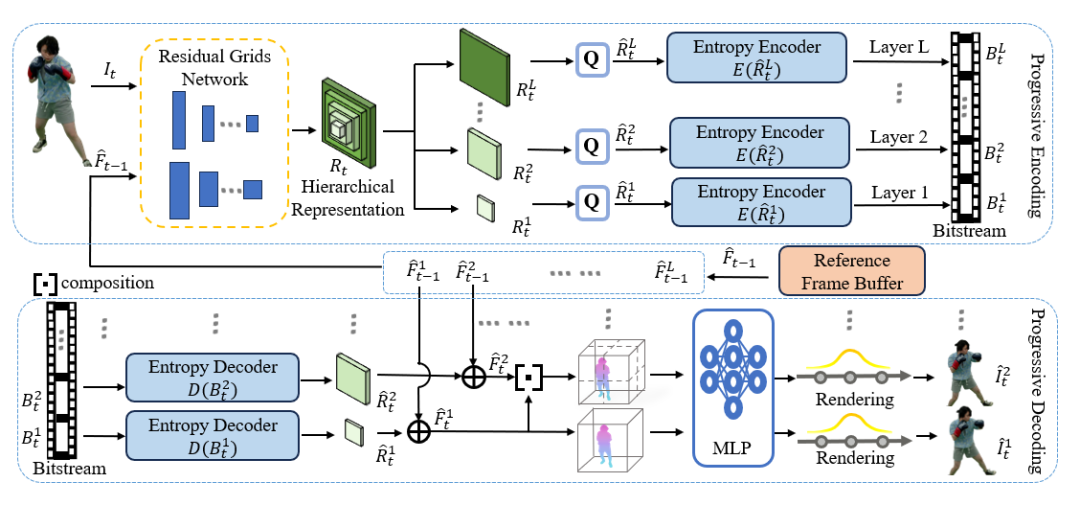
图1 HPC总体框架图
3.实验结果
为验证 HPC 的有效性,我们利用ReRF和DNA-Rendering两个数据集在不同分辨率下从定性和定量两方面将其与TiNeuVox、K-Planes、ReRF和TeTriRF进行对比。图2展示了两个序列的视觉结果,可看出HPC在模型紧凑性和细节精度上具有优势。
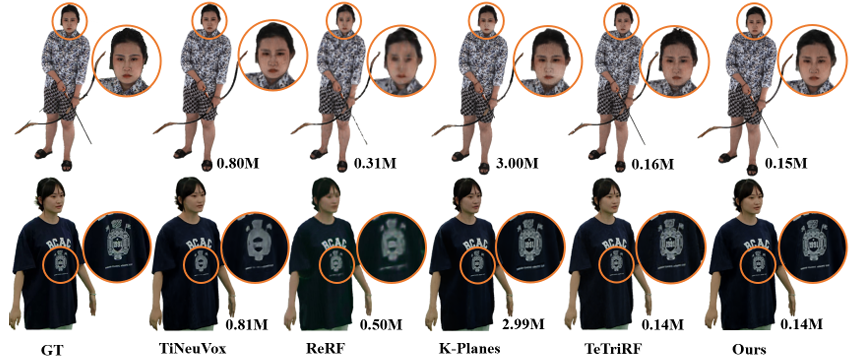
图2 不同方法的视觉效果
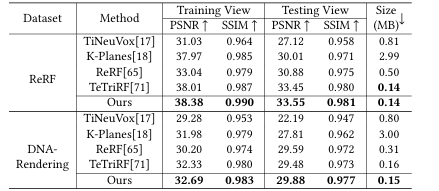
除定性实验外,我们还从峰值信噪比(PSNR)、结构相似性指数(SSIM)和模型存储量三个维度进行了定量对比,结果如表 1 所示。我们的方法在重建质量和模型存储量上展现出显著优势,实现了最优的码率-失真性能。
表1 不同方法的定量指标对比
4.总结
本文提出的HPC为首个渐进式体视频编码方法,该方法能够在质量与码率之间实现灵活且高效的调整,仅通过单一模型即可实现可变码率,且性能优于当前最先进的固定码率方法。HPC支持在不同质量级别下进行渐进式流式传输与渲染,使其尤其适用于带宽和计算资源波动的场景,这为体视频的广泛应用奠定了重要基础。
03
Video Bokeh Rendering: Make Casual Videography Cinematic
作者:
罗亚文1,施珉1,申力奥1,黄亚川1,叶紫璇1,彭珏文2,曹治国1*
单位:
1华中科技大学
2南洋理工大学
邮箱:
luoyw0207@gmail.com
mshi88@gatech.edu
u201914745@hust.edu.cn
yachuan@hust.edu.cn
yezixuan@hust.edu.cn
juewen.peng@ntu.edu.sg
zgcao@hust.edu.cn
论文:
https://dl.acm.org/doi/10.1145/3664647.3680629
发表会议:ACM MM 2024
*通讯作者
1.研究背景
背景虚化(Bokeh,或称散景)是一种通过模糊背景来突出主体的摄影技术,能够营造出电影般的浅景深美感,在专业影视制作中被广泛应用。虽然数码单反相机(DSLR)可以自然地产生这种效果,但其设备昂贵、便携性差且需要专业技巧,限制了其在日常生活中的普及。与此同时,智能手机已成为大众记录生活的主要工具,但受限于其小光圈的物理结构,拍摄的视频往往景深较大,缺乏虚化的艺术效果。
为了弥合这一差距,计算摄影领域的研究者们致力于通过算法为普通视频渲染出背景虚化效果。然而,现有方法大多基于单张图像,当被逐帧应用于视频时,由于缺乏对时序信息的有效建模,常常会导致帧间闪烁、边缘伪影等问题。此外,视频中因物体或镜头移动产生的“反遮挡”(Disocclusion)现象——即原先被前景遮挡的背景区域重新出现——对渲染的真实性提出了巨大挑战。当前研究不仅面临着技术上的难题,也受困于缺乏用于模型训练的高质量成对视频数据集。
2.方法介绍
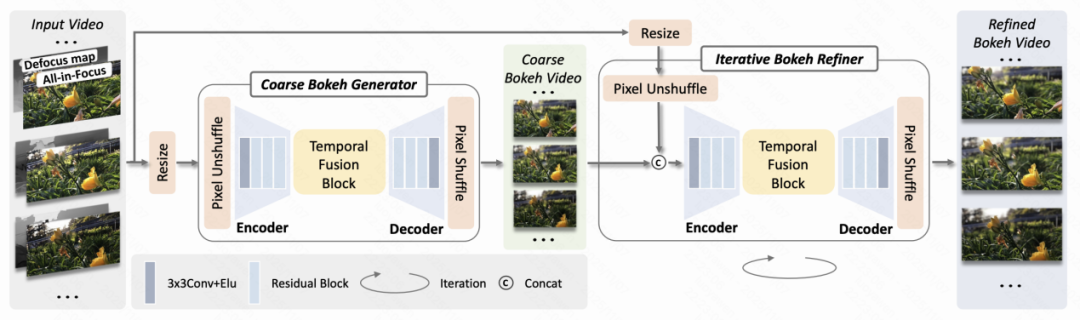
图1 视频背景虚化渲染器方法图
针对上述挑战,本文提出了一个专为视频背景虚化设计的端到端深度学习框架——视频背景虚化渲染器 (Video Bokeh Renderer, VBR)。据我们所知,这是首个在视频背景虚化任务中显式地利用时序信息的框架。VBR的核心创新在于其高效利用相邻帧信息的能力,以生成兼具美感与时序一致性的虚化视频。
具体而言,我们设计了一个核心的时序融合模块 (Temporal Fusion Block, TFB)。该模块嵌入在网络中,通过可变形卷积动态地对齐来自相邻帧的特征图,再将对齐后的特征进行深度融合。这一机制不仅能够有效抑制视频的闪烁,确保渲染效果的平滑稳定,更重要的是,它能够从相邻帧中“借用”信息来恢复被前景物体暂时遮挡的背景细节,从而完美地处理“反遮挡”难题,生成清晰、自然的物体边缘。VBR整体采用了一种由粗到精 (Coarse-to-fine) 的级联式架构。首先,一个粗糙虚化生成器在低分辨率下快速生成基础的虚化效果;随后,一个迭代式虚化精炼器逐步将结果上采样,并结合原始视频帧和深度图信息进行细节优化,最终输出高清、高质量的虚化视频。
3.实验结果
由于业界缺乏用于视频背景虚化研究的公开数据集,我们构建并发布了首个大规模的合成视频背景虚化数据集 (Synthetic Video Bokeh, SVB)。该数据集利用光线追踪技术合成了3000段训练视频和300段测试视频,包含了焦点变换、光圈调整和复杂物体运动等多种真实场景,为该领域的研究提供了宝贵的数据基础。
我们在自建的SVB数据集和多个真实世界的视频上进行了充分的实验验证。如表1所示,与当前主流的图像/视频虚化方法相比,VBR在各项客观评价指标(如PSNR、SSIM)上均取得了最优性能,尤其在物体边缘区域的渲染质量上优势明显。此外,我们进行了一项覆盖55名参与者的主观用户研究。结果表明,相较于其他方法,参与者普遍认为VBR生成的视频在美学效果和时序稳定性上更胜一筹。图2显示了定性的视觉对比效果,在复杂的真实场景中,VBR能够更好地保留前景细节,同时生成平滑、无伪影的背景虚化效果。
表1 合成数据集上定量测试结果
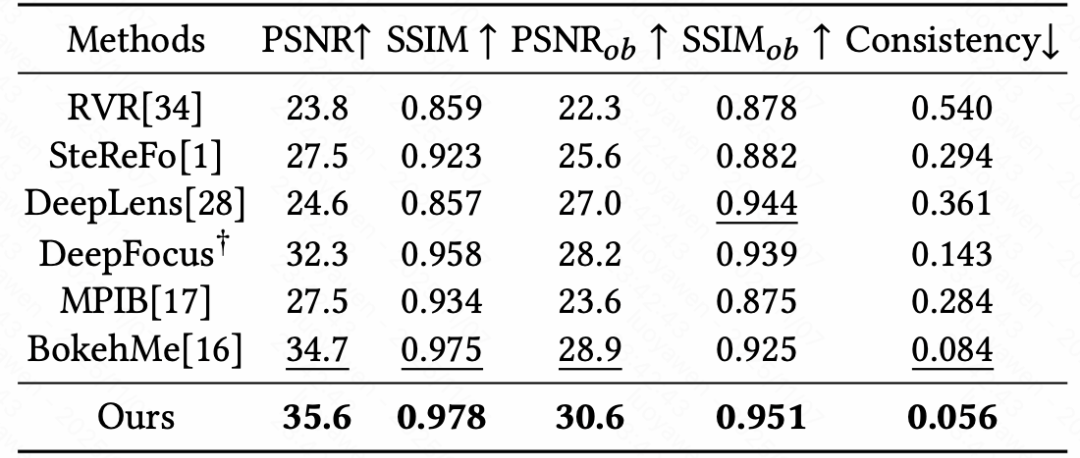

图2 实际视频上不同方法背景虚化效果对比
4.总结
本文提出了引入时序信息建模的视频背景虚化渲染器VBR。通过其核心的时序融合模块,VBR有效解决了视频虚化中的闪烁和边缘伪影问题。同时,本文贡献了一个大规模视频背景虚化数据集SVB,填补了该领域的数据空白。我们的工作为如何将普通视频转化为具有电影感的作品提供了一个基线模型,有助于激发该方向后续更多的研究。
04
LiteQUIC: Improving QoE of Video Streams by Reducing CPU Overhead of QUIC
作者:
毕鹏强1,邹逸飞1*,肖梦白1*,于东晓1,李毅骏2,刘志雄2,谢群2
单位:
1山东大学
2白山云科技
邮箱:
pq.bi@mail.sdu.edu.cn
yfzou@sdu.edu.cn
xiaomb@sdu.edu.cn
dxyu@sdu.edu.cn
yijun.li@baishan.com
zhixiong.liu@baishan.com
qun.xie@baishan.com
论文:
https://dl.acm.org/doi/10.1145/3664647.3681670
发表会议:
ACM MM 2024
*共同通讯作者
1.研究背景
当今,视频流量占据了互联网流量的大部分,其中基于 HTTP 的自适应码率(ABR)流媒体已成为事实标准。作为 HTTP/3 的底层传输协议,QUIC 已被内容提供商广泛部署,在 Facebook 等平台承载了大部分流量,并带来了更高的用户体验质量(QoE)。随着 QUIC 和 HTTP/3 在视频点播、直播以及实时内容分发等场景中的广泛应用,网络传输对性能的要求持续提升。然而,在高带宽和大规模并发环境下,现有 QUIC 实现仍存在吞吐量不足、CPU 占用过高以及视频播放质量下降等问题,限制了整体服务能力,难以满足视频业务快速增长的需求。因此,需要设计更加轻量、高效的 QUIC 实现以降低 CPU 开销。
2.方法介绍
针对上述问题,我们首先对HTTP/3和HTTP/1.1进行系统剖析,分析它们的开销瓶颈。我们发现,HTTP/3在数据传输中的主要 CPU 消耗来自三个方面:(1)ACK 处理开销高;(2)数据包发送需要大量系统调用;(3)TLS 加密在小包场景成本过高。
基于这些瓶颈,我们提出了LiteQUIC,首先,在发送路径上,LiteQUIC 引入 UDP Generic Segmentation Offload (GSO),将多个 QUIC 数据包合并后一次性发送,从而显著减少系统调用次数,把原本“每发送一个包调用一次 sendmsg”的模式优化为“多个包一次发送”。这削减了 CPU 在发送路径上的大量开销,使发送过程更加高效。
其次,在加密模块上,LiteQUIC 使用了更轻量的 PicoTLS 加密库,替代传统 TLS 实现中复杂度和资源消耗较高的路径。PicoTLS 对小包加密的性能优化,使其特别适合 QUIC 这种大量小数据包的场景,进一步降低了加密开销,使整体协议栈更加轻量化。
最后,LiteQUIC 对 ACK 处理路径进行了关键优化,包括 ACK 帧合并(ACK Merge)机制和自适应 ACK 频率调节(Adaptive ACK Frequency)。通过将单包读取替换为批量读取,并将多个 ACK 帧合并进行统一解析,LiteQUIC 显著减少 ACK 处理的系统调用与遍历开销。此外,自适应 ACK 频率能够在 CPU 紧张时降低 ACK 的生成频率,而在弱网环境中恢复高频 ACK,以确保吞吐量不受损失。这两项机制结合,使 ACK 处理从高频、高成本的流程转变为高效、可调的轻量路径。

图1 HTTP/1.1与HTTP/3不同优化的CPU开销分析图
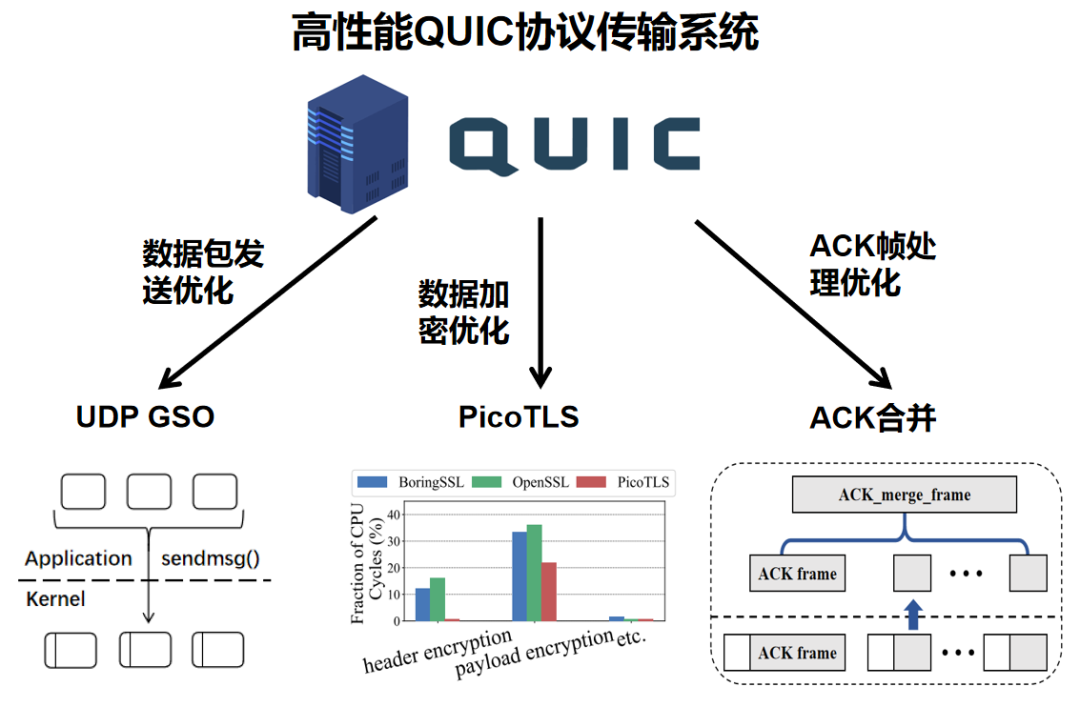
图2 LiteQUIC设计概述图
3.实验结果
实验结果显示,LiteQUIC 在不同网络条件下均表现出显著的性能优势。在10Gbps的带宽实验环境中,LiteQUIC 显著优于 picoquic、lsquic、mvfst 等主流 QUIC 实现。在 DASH 视频流播放实验中,当客户端数量逐渐增加至 100 个时,HTTP/3 的吞吐量与 QoE 均出现严重下降,而 LiteQUIC 依旧保持接近 HTTP/1.1 的表现,说明其 CPU 开销显著降低,能够支撑更大规模的服务端并发。在弱网环境(例如 RTT 20 ms 与 0.5% 丢包)中,LiteQUIC 的吞吐量为 HTTP/1.1 的 1.28 倍,同时重缓冲时长显著降低。
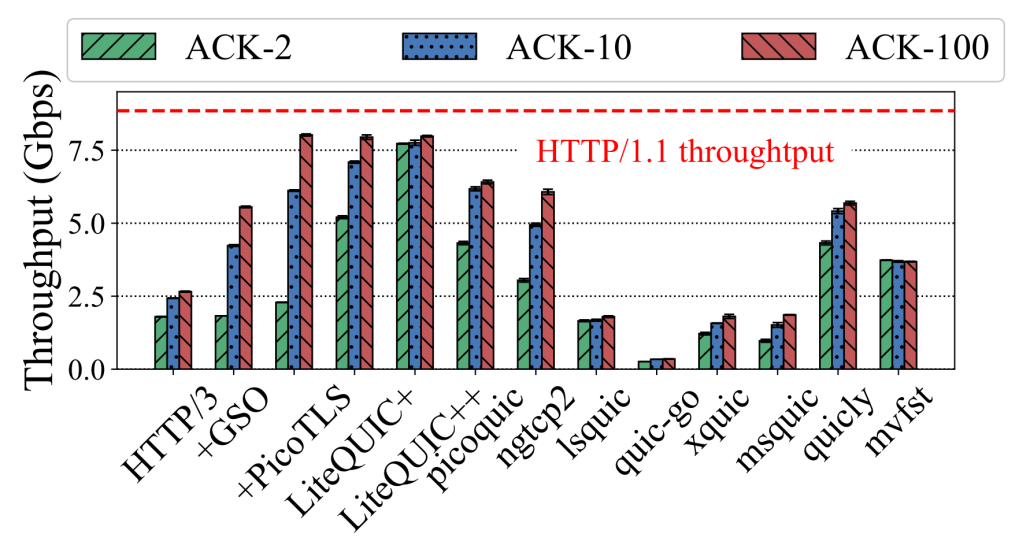
图3 CPU受限下不同QUIC协议实现吞吐量对比图
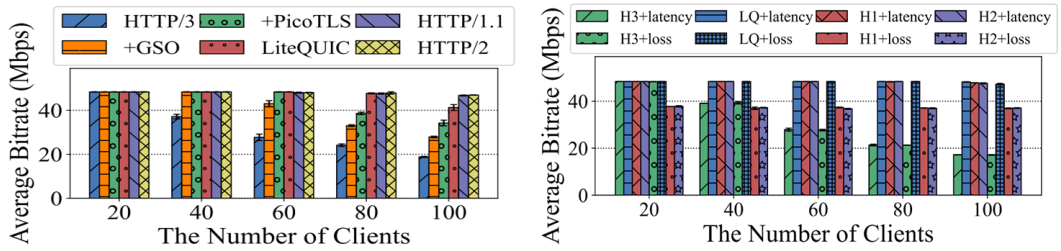
图4 DASH视频流中不同客户端数量下的视频播放比特率对比图
05
Advancing Multi-grained Alignment for Contrastive Language-Audio Pre-training
作者:
李一鸣1,2,郭智方1,2,王向东1,2*,刘宏1,2
单位:
1中国科学院计算技术研究所
2中国科学院大学
邮箱:
liyiming22s1@ict.ac.cn
guozhifang21s@ict.ac.cn
xdwang@ict.ac.cn
hliu@ict.ac.cn
论文:
https://doi.org/10.1145/3664647.368114
代码链接:
https://github.com/Ming-er/MGA-CLAP
发表会议:ACM MM 2024
*通讯作者
1.研究背景
对比语言-音频预训练(CLAP)模型通过在高维潜在空间关联音频和文本描述,在多模态理解任务中取得了成功。现有CLAP模型通常将单模态局部特征直接聚合为全局特征,并应用对比损失实现粗粒度跨模态对齐。然而,其缺乏细粒度对齐能力,例如帧级特征与文本短语的对应关系,这导致模型在可解释性和细粒度任务上表现不佳。图1展示了一个现有CLAP模型对齐效果不佳的例子,在该示例音频中,说话声Speech发生在首尾,而警报声Alarm发生在中部,可以看到,现有CLAP模型只能粗略地感知音频当中存在的声音事件,而无法精确地捕捉其细粒度时序位置。针对上述问题,本文提出了MGA-CLAP,通过模态共享码本隐式地建立连接音频、文本模态的语义桥梁,并通过局部感知编码器与困难样本引导损失进一步提升音频、文本模态多粒度对齐效果,如图1(b)所示,所提MGA-CLAP极大地提升了细粒度对齐效果。
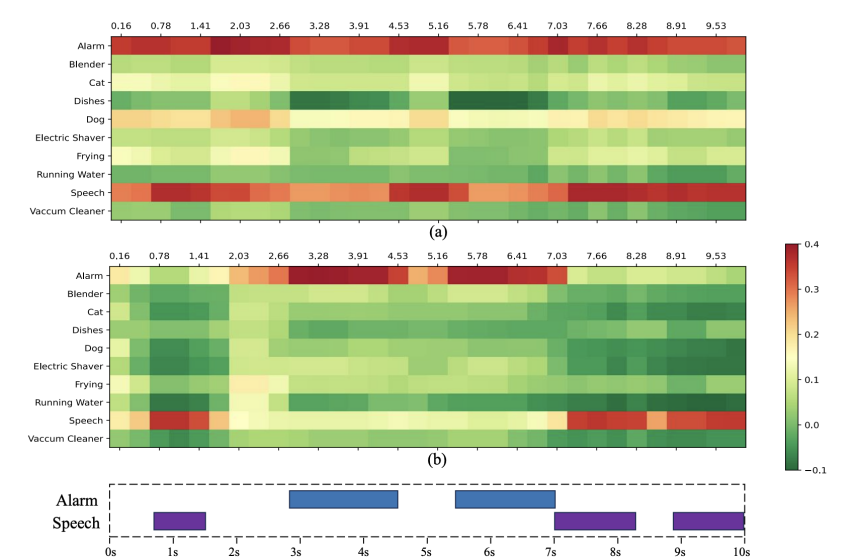
图1 (a) 现有CLAP与 (b) 所提MGA-CLAP的帧级对齐效果
2.方法介绍
本文核心创新包括模态共享码本、局部感知编码器设计和困难样本引导的对比损失,如图2所示。
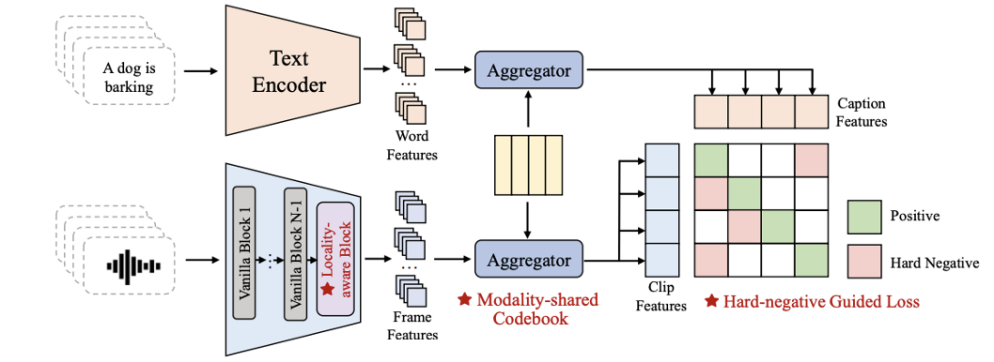
图2 MGA-CLAP总体架构示意图
模态共享码本:本文设计的共享码本由一组可学习的码元组成,通过码元的线性组合表征音频、文本的全局特征。具体地,利用帧(或词)与码元的最大余弦相似度及稀疏约束计算组合权重,鼓励局部特征激活相同的码元,以捕捉共享语义(如声音事件)从而隐式地连接帧、词级特征,促进细粒度对齐,并使音频和文本特征共享同一特征空间。
局部感知编码器设计:原Transformer编码器的Query-Key注意力聚合机制可能导致当前帧中混入其他帧的信息,从而造成局部音频模式破坏。针对此,本文设计了局部感知编码器模块,直接使用投影后的Value矩阵作为输出,避免全局注意力聚合带来的噪声,提升了帧级特征的质量,便于码本聚合。
困难样本引导的对比损失:通过重新加权对比损失,本文旨在强调难以区分的负样本对,增强特征空间的判别性。损失函数中引入难度分数,使模型更关注相似度高的负样本对。
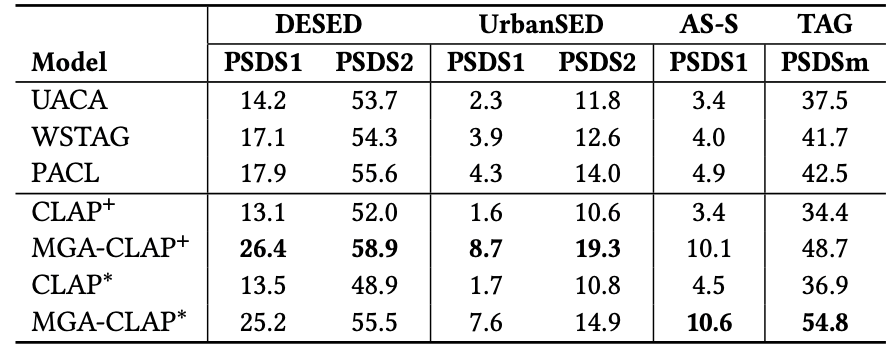
3.实验结果
本文在WavCaps这一大规模音频-描述数据集训练了所提MGA-CLAP模型(其中*、+代表不同骨干网络),在多个音频检索(表1)、零样本音频分类(表2)等粗粒度理解任务上相较于现有CLAP模型均有一定提升,而在音频描述定位、零样本声音事件监测(表3)等细粒度理解任务上大幅领先此前模型。
表1 各模型在音频检索任务的性能对比
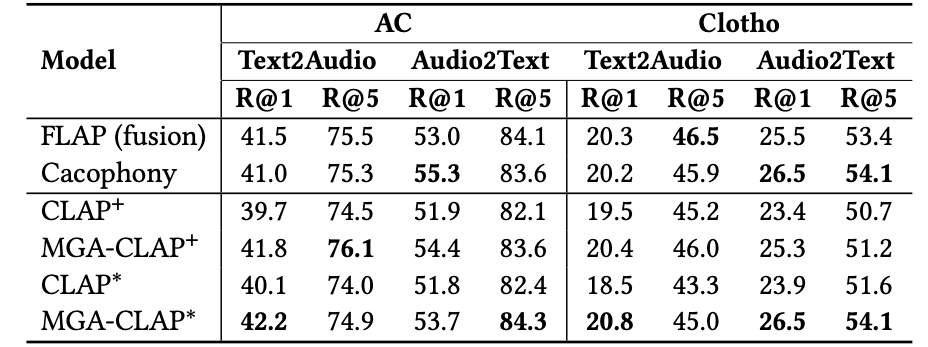
表2 各模型在零样本音频分类任务的性能对比
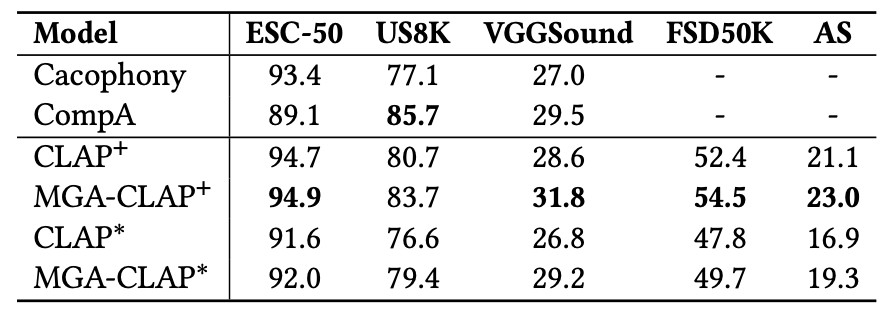
表3 各模型在零样本声音事件检测、音频描述定位任务的性能对比
4.总结
通过多粒度对齐设计,本文提出的MGA-CLAP,在保持粗粒度对齐效果的同时,显著提升了细粒度对齐能力,为音频-语言理解任务提供了更优范式。

编辑人:吴建龙、任文琦
专委会责任副主任:张勇东
 京公网安备11010802017125号
京公网安备11010802017125号