
【论文导读】2026年论文导读第一期
【论文导读】2026年论文导读第一期


论文导读
2026年论文导读第一期(总第一百四十一期)
目 录
|
1 |
Efficient Test-time Adaptive Object Detection via Sensitivity-Guided Pruning |
|
2 |
DS-Det: Single-Query Paradigm and Attention Disentangled Learning for Flexible Object Detection |
|
3 |
Neural Boneprint: Person Identification from Bones Using Generative Contrastive Deep Learning |
|
4 |
Towards Robust Multimodal Domain Generalization via Modality-Domain Joint Adversarial Training |
|
5 |
MokA: Multimodal Low-Rank Adaptation for MLLMs |
01
Efficient Test-time Adaptive Object Detection via Sensitivity-Guided Pruning
作者:
王堃宇1,傅雪阳1,卢鑫1,葛成杰1,曹成志1,翟伟1,查正军1*
单位:
1中国科学技术大学
邮箱:
kunyuwang@mail.ustc.edu.cn
xyfu@ustc.edu.cn
luxion@mail.ustc.edu.cn
cjge@mail.ustc.edu.cn
chengzhicao@mail.ustc.edu.cn
wzhai056@ustc.edu.cn
zhazj@ustc.edu.cn
论文:
https://arxiv.org/pdf/2506.02462
发表会议:CVPR 2025 Oral
*通讯作者
1. 研究背景
测试时自适应目标检测关注检测模型在真实场景中部署时所面临的持续域偏移问题。由于成像条件、天气和光照等因素不断变化,测试数据分布会逐渐偏离训练阶段的源域分布,导致检测性能显著下降。为此,测试时自适应方法允许模型在推理阶段利用无标注测试数据进行在线更新,以缓解由域偏移引起的性能退化。然而,现有方法大多侧重于适应精度的提升,而对计算效率关注不足。在自动驾驶、无人机和边缘设备等实际应用中,测试时自适应往往需要长期运行,频繁的反向传播与参数更新会带来较高的计算与能耗开销,严重制约方法的可用性。因此,在保证适应效果的同时降低测试时计算成本,仍是测试时自适应目标检测中尚未充分解决的关键问题。
2. 方法介绍
本文提出了一种面向测试时高效自适应的目标检测方法,核心思想是利用剪枝机制提升适应过程中的计算效率。我们观察到,并非所有从源域学习到的特征都能在目标域中发挥正面作用;相反,部分对域迁移敏感的特征通道会对目标域性能产生负向影响,如图1所示。
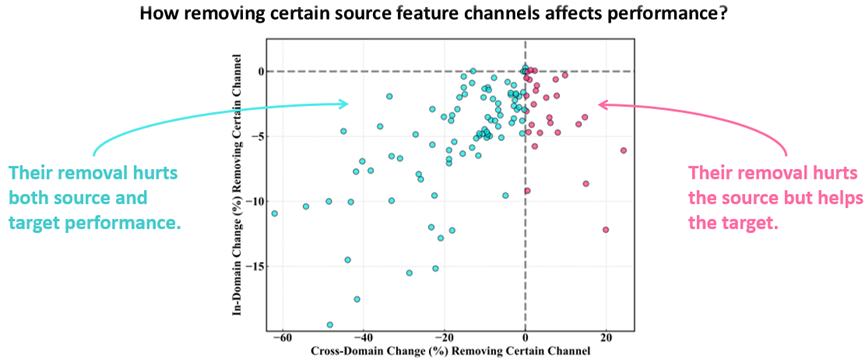
图1 核心洞察:并非所有源域特征都有助于目标域适应
基于此,本文设计了一种通道敏感性引导的剪枝策略,如图2所示。通过图像级与实例级两个层面度量特征通道对域偏移的敏感程度,并据此引导加权稀疏正则化,实现对高敏感通道的选择性抑制与剪除,从而将计算资源集中于更稳定的特征通道上。这样一来,剪除对域迁移敏感的通道不仅降低了计算开销,也有助于提升最终的适应性能。此外,为应对目标域的持续迁移变化并避免剪枝带来的不可逆损失,我们引入了通道的随机重激活机制,使被剪除的通道在后续适应至不同目标域的过程中仍有机会被重新启用,从而动态评估其在新环境下的有效性。
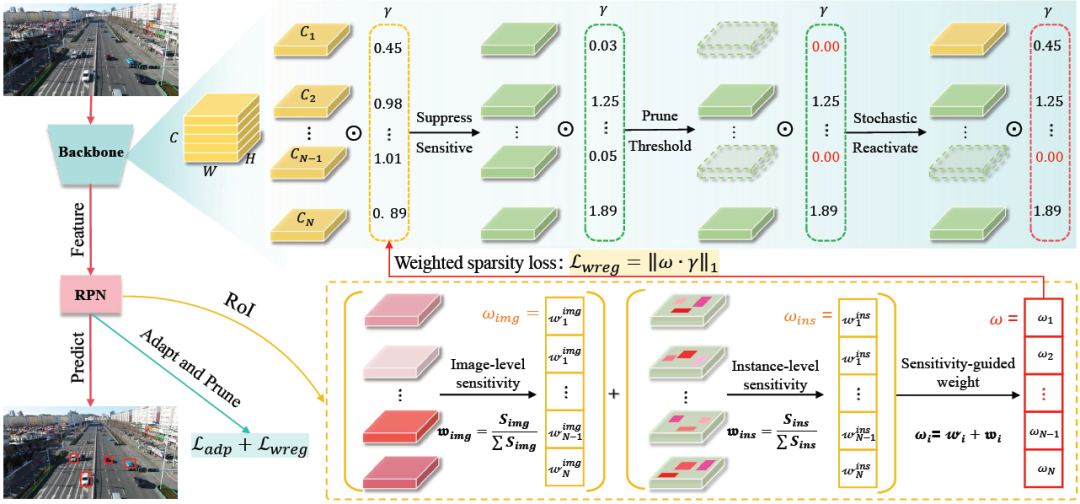
图2 方法:通道敏感性引导的测试时剪枝框架
3. 实验结果
本文在三个测试时自适应目标检测基准上进行了系统评估,采用mAP@50(%) 作为性能指标,并以 FLOPs(G) 衡量计算效率。实验结果如图3所示,在 Cityscapes → Cityscapes-C 和 UAVDT → UAVDT-C 两个合成扰动基准上,所提方法的平均检测精度相比近期最先进方法均提升约 2.3;在真实复杂退化场景 Cityscapes → ACDC 上,平均检测精度提升约 0.6。同时,由于在测试时自适应过程中动态剪除对域迁移敏感的特征通道,所提方法在三个基准上的总浮点运算量均显著降低,整体相比近期最先进方法减少约 12%,在连续十轮测试时自适应过程中实现了更优的性能与效率权衡。
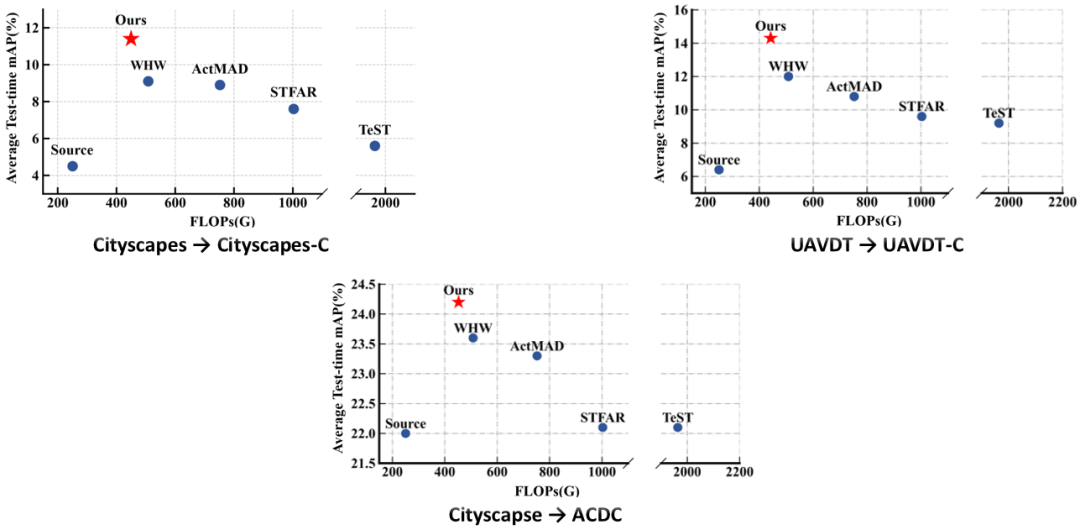
图3 实验结果:在性能–效率平面上的同时更优
4. 总结
本文的核心观点是:并非所有从源域学习到的特征都能在目标域中发挥正面作用,部分对域迁移敏感的特征反而会干扰测试时自适应过程。基于这一洞察,本文通过通道敏感性引导的剪枝,选择性抑制域敏感特征,从而同时降低计算开销并提升适应性能。
02
DS-Det: Single-Query Paradigm and Attention Disentangled Learning for Flexible Object Detection
作者:
曹桂平1,2,蓝湘源1,4*,黄文健1,张建国1,2*,蒋冬梅2,王耀威2,3
单位:
1南方科技大学
2鹏城实验室
3哈尔滨工业大大学(深圳)
4琶洲实验室(黄埔)
邮箱:
12131099@mail.sustech.edu.cn
lanxy@pcl.ac.cn
huangwj@sustech.edu.cn
zhangjg@sustech.edu.cn
jiangdm@pcl.ac.cn
wangyw@pcl.ac.cn
论文:
https://dl.acm.org/doi/10.1145/3746027.3755045
代码链接:
https://github.com/Med-Process/DS-Det/
发表会议:ACM MM 2025
*通讯作者
1.研究背景
Transformer检测器(如DETR)因使用固定数量的可学习查询,仅能预测固定数量的目标,导致其在密集场景中灵活性严重受限。此种局限性进而引发了两个核心问题:(1)可扩展性不足:预设的查询数量限制了模型的扩展能力,使其难以应对图像中目标数量剧烈变化的复杂情况;(2)检测歧义性:为提升训练效率而引入的“一对多”标签匹配策略,与模型固有的“一对一”匹配核心机制产生冲突,导致模型不确定应为同一目标生成单个还是多个预测,如图1所示。针对上述问题,本文提出DS-Det检测器,提出了一种新的单一查询检测范式。该范式通过消除固定查询约束并重新设计解码器架构,实现了自适应数量的目标预测,并有效降低了检测歧义性,从而增强了检测器的灵活性与整体性能。

图1 解码器中采用共享权重的“一对一”与“一对多”匹配混合方式会引入查询歧义,导致多个查询预测同一单个对象,并增加误检率
2.方法介绍
为消除DETR-like模型对于固定检测目标数量的限制,拓展模型的检测范围和应用场景,本文提出了DS-Det模型,其整体架构如图2所示。首先,本文重新思考了DETR模型中查询(内容查询和位置查询)、以及注意力机制的作用,并分析了DETR-like模型中对于固定查询限制的因素。在此基础上,提出了灵活的单查询生成(Flexible singLe- quEry generaTion,FLET)方法,从而动态选择来自编码器标记的查询,以解决固定查询的限制。同时,为应对“检测歧义性”问题,本文对解码器进行了重构,提出了一个新的LDD解码框架(Location Deduplication Decoder,LDD),该框架将模型中解码器的检测过程解耦为两个简单步骤:即先进行目标定位,再进行目标识别。通过设计解耦匹配方法,分别对one-to-one和one-to-many的标签匹配过程、以及一对一和一对多的解码器处理过程进行了分离。故此,该解码器架构消除了现有模型需额外解码器分支进行高效模型训练的需求,保持了模型的训练效率,并显著减轻了检测的歧义性。最后,本文设计了一种新的损失函数,结合了分类分数、IoU分数和检测框的大小(incorPOrates Classification with IOU and bOx Size,PoCoo),用于重新加权分类损失,保持模型预测一致性,提高模型对困难样本的检测能力。
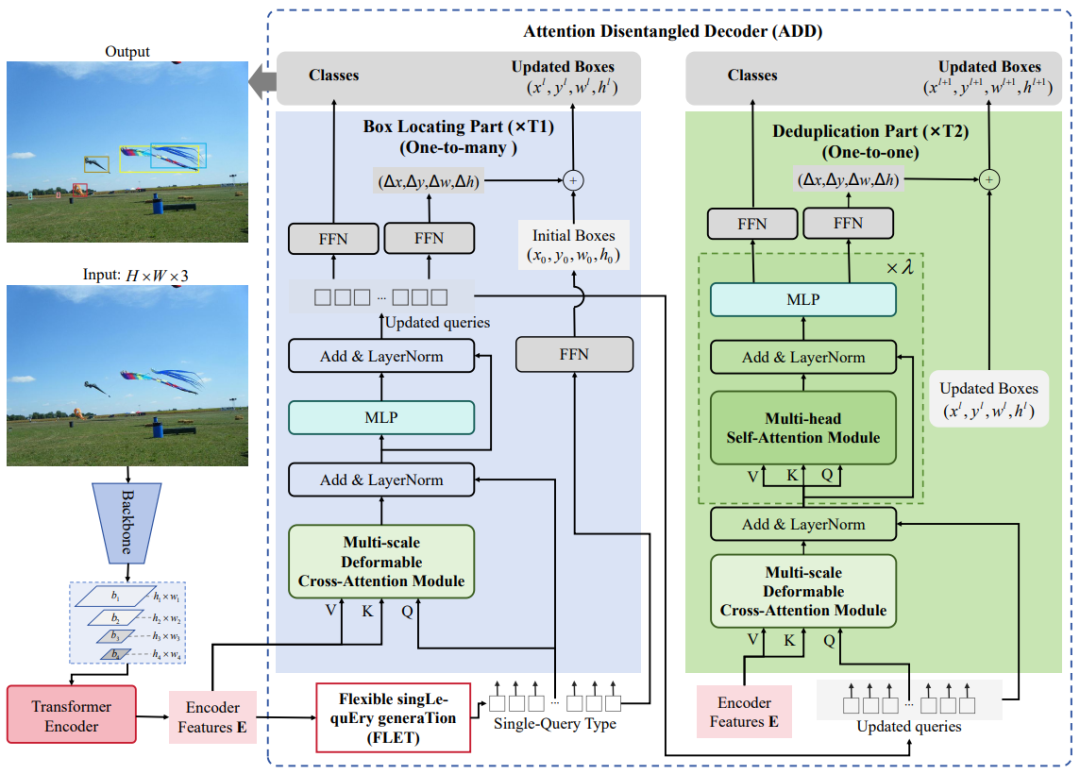
图2 DS-Det模型整体架构
3.实验结果
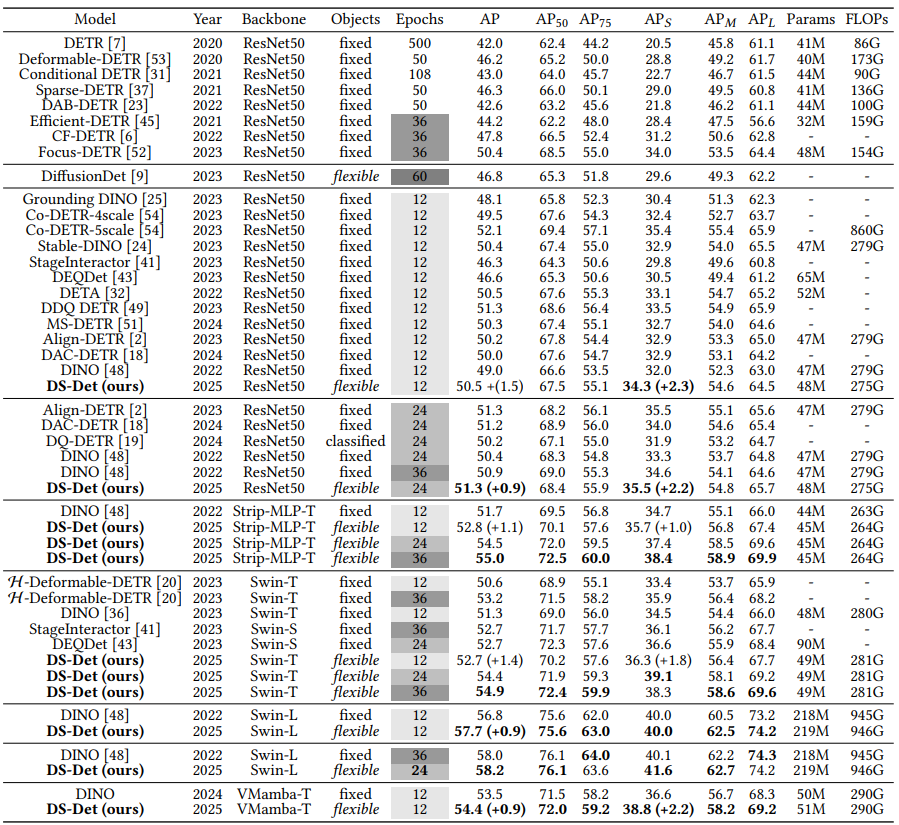
模型的精度评估实验在目标检测基准数据集COCO2017进行,通过使用不同的骨干网络和不同的训练周期,与当前主流的检测模型进行了全面比较,如表1所示。DS-Det在五种不同的骨干网络中,在检测指标AP和APs上均取得了最佳的性能。特别地,在1×训练周期(12个epoch),模型的AP指标达到了54.4%,APs为38.8%,高于标杆模型DINO+0.9% AP和 +2.2%APs。此外,与能够预测自适应数量目标的 DiffusionDet模型相比,DS-Det(训练24epochs)显著优于DiffusionDet(训练60epochs),AP提高了+4.5%,APs提高了+5.9%,充分展现了本文方法的优越性。
表1 DS-Det与其他主流检测器在COCO val2017数据集的评测结果
03
Neural Boneprint: Person Identification from Bones Using Generative Contrastive Deep Learning
作者:
牛超群1,2,†,陈东东3,†,周吉喆1,2,王坚1,2,罗祥4,刘权辉1,2,李媛4*,吕建成1,2*
单位:
1四川大学计算机学院
2机器学习与工业智能应用教育部工程研究中心
3赫瑞瓦特大学数学与计算机科学学院
4四川大学华西基础医学与法医学院
邮箱:
niuchaoqun@stu.scu.edu.cn
d.chen@hw.ac.uk
jzzhou@scu.edu.cn
jianwang.scu@gmail.com
481695790@qq.com
quanhuiliu@scu.edu.cn
liyuan5300602@163.com
lvjiancheng@scu.edu.cn
论文:
https://doi.org/10.1145/3664647.3681174
发表会议:ACM MM 2024
*通讯作者
†共同第一作者
1.研究背景
在事故和刑事调查中,法医人员身份识别至关重要。如果尸体严重腐烂、白化或烧焦,现有的基于软组织(人脸、虹膜、指纹或掌纹)的方法可能无效。DNA检测方法也极具挑战性,除技术困难、时间和财务成本限制外,DNA关键点位可能会随时间降解,且若是该个体或近亲的DNA没有预先测序和存储,DNA检测方法难以发挥作用。一个重要但易被忽视的基本事实是:骨头通常可以保存很长时间。这引出了一个自然的问题:我们是否可以通过骨骼数据实现个体身份识别?对于尸体,拍摄CT、获取其VRT图像进行分析是法医学的常用分析方法。对于个人,胸片(CXR)是常规的体检项目,特别是在新冠疫情后,几乎每个人都曾拍摄过胸片。
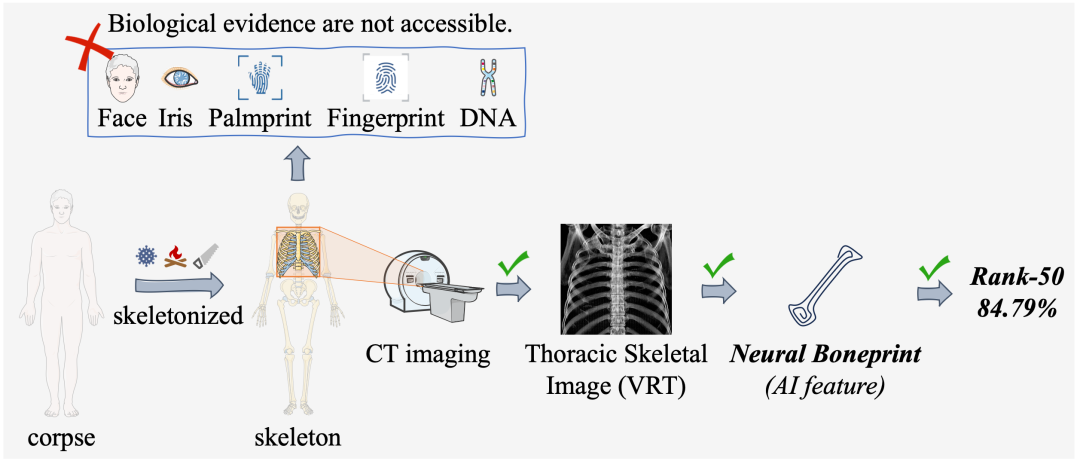
图1 当尸体严重腐烂(高度分解、烧焦或被蓄意破坏)时,涉及软组织或 DNA 的生物证据将无法获取。本文以胸骨为例介绍了通过神经骨纹进行人员身份识别的方法。
2.方法介绍
本文以胸骨为例使用其图像数据探索神经骨纹(Neural Boneprint,NBP)的存在及可用性,具体使用VRT图像与CXR图像实现个体身份特征的提取与识别。本任务中存在几大挑战:(1)小样本:每一类(每个个体)仅有1张VRT图像和1张CXR图像;(2)类内差异大:模态差异、拍摄体位差异带来的非线性形变、语义差异导致同一人的不同图像差异很大;(3)类间差异小:不同人的相同模态照片差异很小。
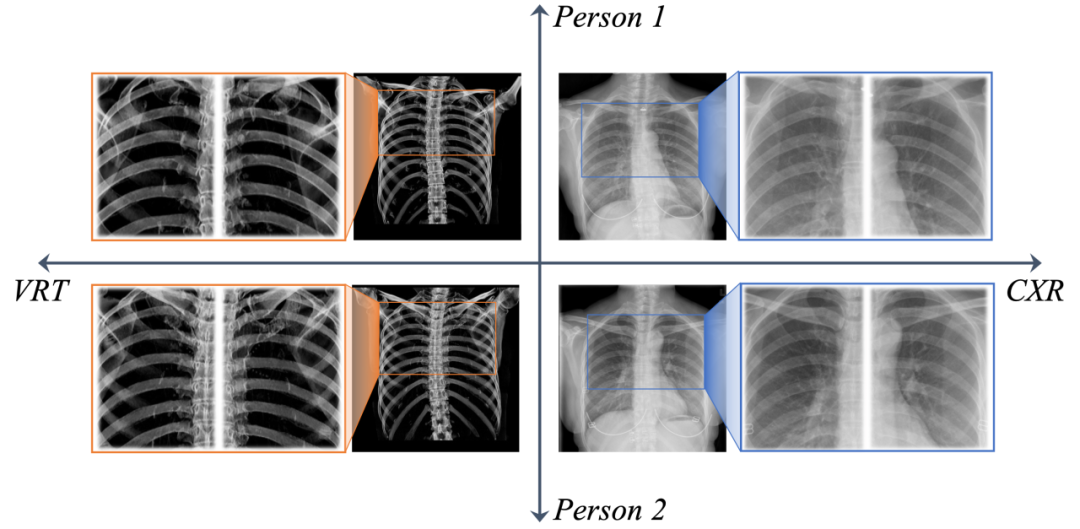
图2 两个个体的CXR和VRT图像对比
本文提出一套生成式对比学习框架解决所涉任务,具体提出三个模块来学习神经骨纹:(1)交叉模态翻译:在保留个体身份信息的约束下,CXR与VRT图像分别被转换成彼此的模态来弥补模态差距,提高数据的完整性。(2)跨模态融合:使用基于对比学习的双重重构网络融合骨骼身份的细粒度表示,并用其优化类间和类内距离以提取NBP。(3)NBP库建立与检索:利用CXR数据构建NBP库。获取待检索VRT的NBP并与库中NBP进行匹配以进行身份识别。
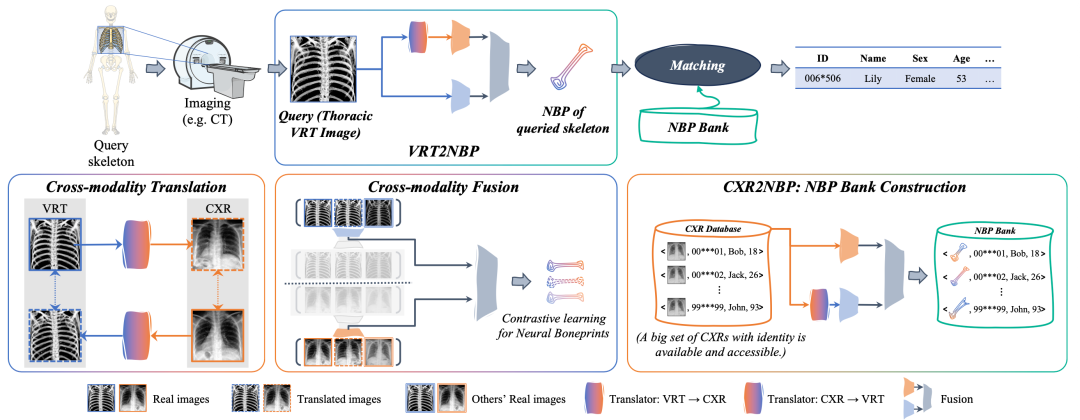
图3 基于生成式对比学习的人员骨骼身份识别
3.实验结果
本文在真实临床数据上的实验结果验证了所提方法在身份识别中的有效性,其Rank-50识别准确率达到84.79%,远超其他基线模型。此外,与相近工作相比,本文所提方法检索库规模更大、性能更强,在前10%候选结果中即可达到75.29%的准确率,这一性能指标显著优于日本宫崎大学研究团队所提出的方法(检索范围前55.56%时准确率为74.07%),即本方法不仅将有效检索范围缩小了5.56倍,同时实现了1.22个百分点的准确率提升。
表1 方法性能对比及消融实验
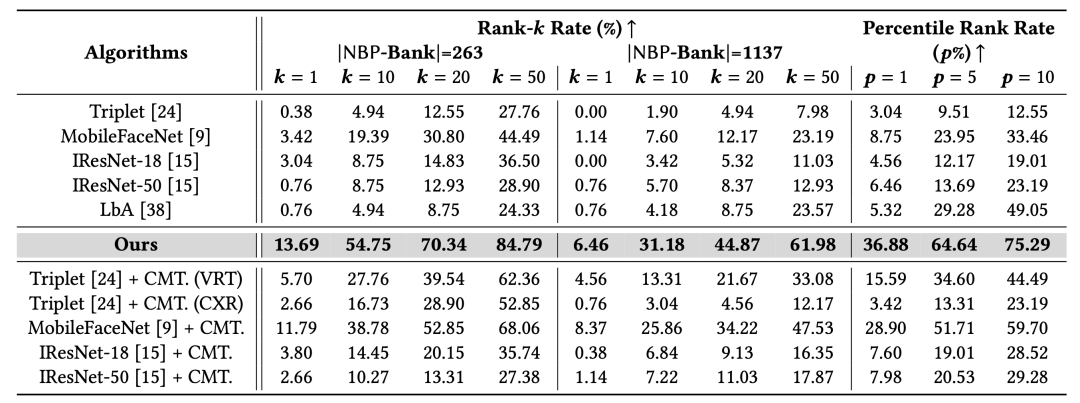
表2 相近方法对比

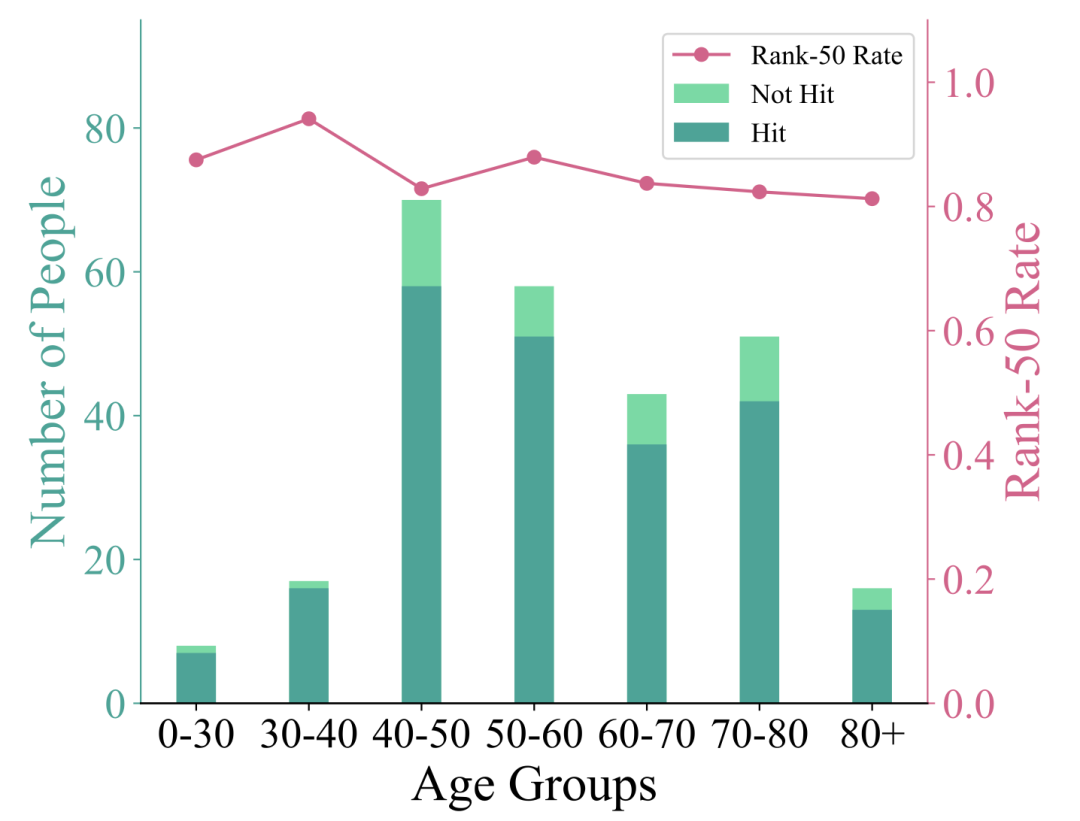
图4 年龄群体公平性研究
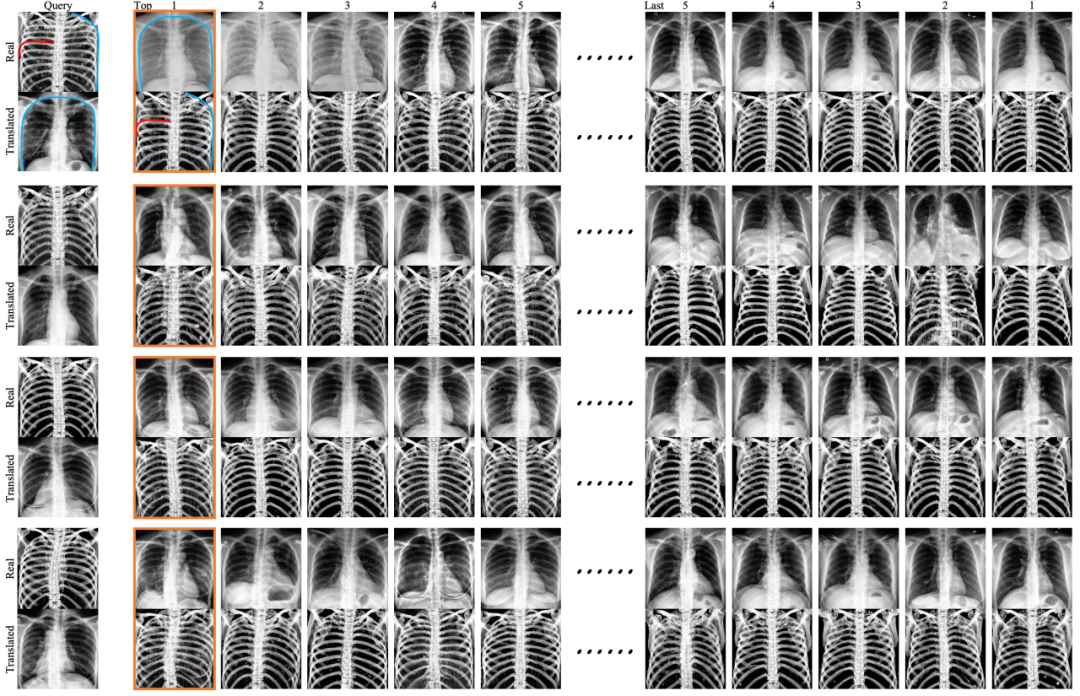
图5 检索结果定性分析
4.总结
本工作首次提出“神经骨纹”概念,证明骨骼本身蕴含可用于身份识别的独特信息。所提出的生成式对比学习框架,为法医学中极端条件下的身份鉴定提供了一种自动化、可扩展的新范式。
04
Towards Robust Multimodal Domain Generalization via Modality-Domain Joint Adversarial Training
作者:
李泓钊1,万华磊1,张良旨1,酒明远1,李书攀1*,徐明亮1*,Muhammad Haris Khan2
单位:
1郑州大学 计算机与人工智能学院
2穆罕默德·本·扎耶德人工智能大学 (MBZUAI)
邮箱:
lihongzhao@gs.zzu.edu.cn
hlwan197031@gs.zzu.edu.cn
zhang_liang_zhi@gs.zzu.edu.cn
iemyjiu@zzu.edu.cn
iespli@zzu.edu.cn
iexumingliang@zzu.edu.cn
muhammad.haris@mbzuai.ac.ae
论文:
https://dl.acm.org/doi/10.1145/3746027.3754954
代码链接:
https://github.com/lihongzhao99/MMDG-Joint-Adversarial-Training
发表会议:ACM MM 2025
*通讯作者
1.研究背景
多模态学习通过整合视觉和听觉等多种信息,在复杂任务中表现优异。然而,现实应用中数据常面临分布偏移(如环境光照变化、背景噪音等),导致模型在未见过的目标域上性能下降 。这使得多模态域泛化成为一个关键挑战。现有的单模态域泛化方法难以直接应用于多模态场景,主要面临两大难题:一是模态异构性,即不同模态的特征空间差异巨大,难以统一对齐;二是模态稳定性差异,即不同模态对域偏移的敏感度不同。如图1所示,在跨风格动作识别中,视觉特征可能因画风突变而失效,但音频的节奏特征可能依然稳定。忽略这种差异会导致模型过度依赖不稳定模态,从而降低泛化能力。
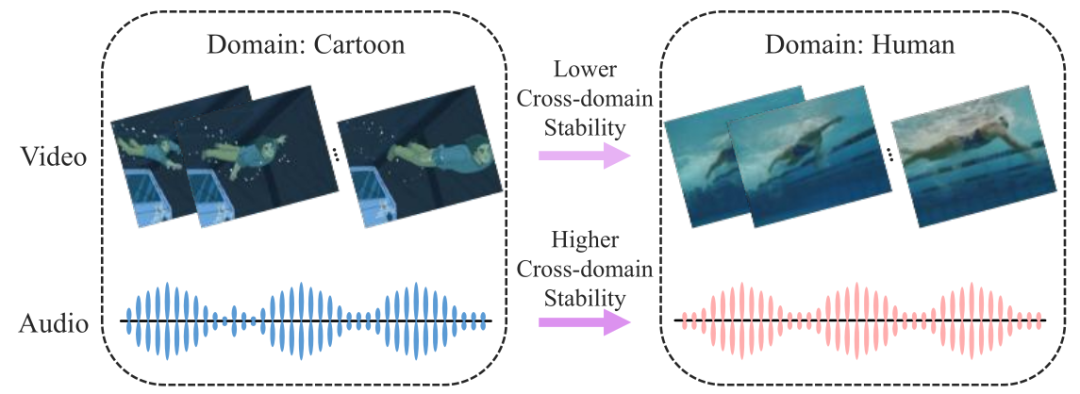
图1 问题说明
2.方法介绍
本文提出模态-域联合对抗训练框架,通过两大核心组件解决上述问题。首先,三判别器对抗组件通过共享域判别器、共享模态判别器及融合域判别器的联合博弈,全方位消除单模态域偏差、模态特有模式及融合特征的跨域差异,迫使模型学习去偏的统一特征 。其次,稳定性感知动态加权机制利用域判别器的预测熵量化模态稳定性(熵高即稳定),据此动态赋予高稳定性模态更大的学习权重,降低对不稳定模态的依赖,从而提升整体泛化能力。
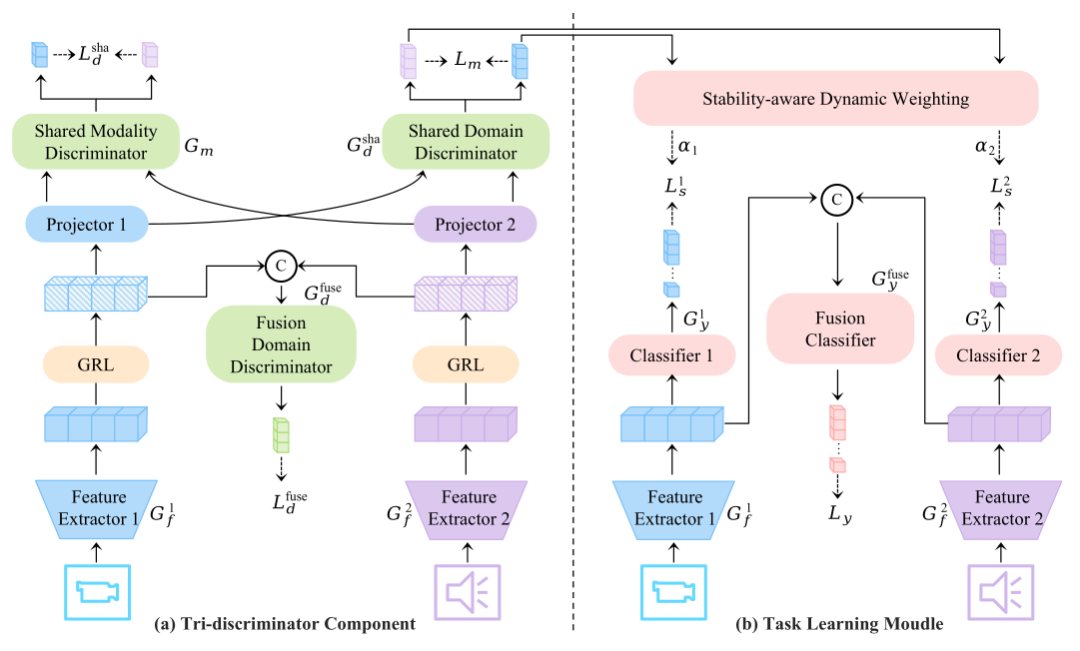
图2 方法框架概览
3.实验结果
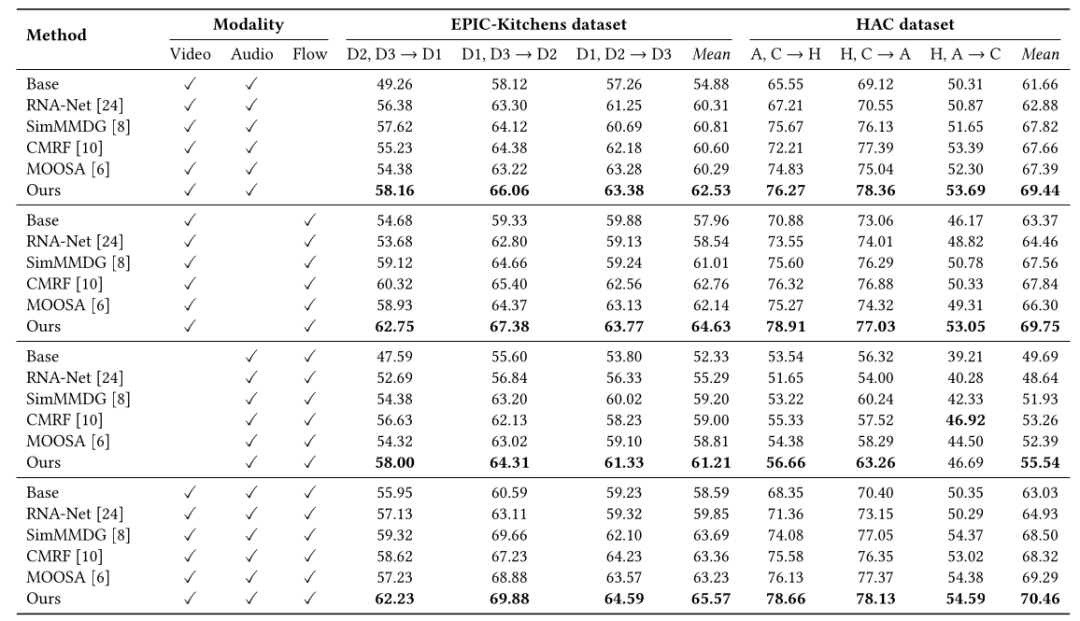
我们在 EPIC-Kitchens和 HAC两个基准数据集上进行了验证 。如表1所示,该方法在大多数跨域设置下均优于现有的SOTA方法。我们的模型参数量仅为34.01M,相比目前最轻量的MMDG基准模型减少了75.2%,在大幅降低计算成本的同时实现了最佳性能。
表1 实验结果
4.总结
本文提出了一种参数高效的鲁棒多模态域泛化框架。通过三判别器对抗训练实现多层次特征对齐,并利用稳定性感知加权机制动态平衡模态贡献,有效解决了模态异构性和稳定性差异问题。同时,本文还提供了首个针对MMDG的理论误差界证明。
05
MokA: Multimodal Low-Rank Adaptation for MLLMs
作者:
卫雅珂1,2,3,苗雨1,2,3,周东展4,胡迪1,2,3,*
单位:
1中国人民大学高瓴人工智能学院
2大模型与智慧治理北京市重点实验室
3新一代智能搜索与推荐教育部工程中心
4上海人工智能实验室
邮箱:
yakewei@ruc.edu.cn
ymiao@ruc.edu.cn
zhoudongzhan@pjlab.org.cn
dihu@ruc.edu.cn
论文:
https://arxiv.org/abs/2506.05191
代码链接:
https://gewu-lab.github.io/MokA/
发表会议:NeurIPS 2025
*通讯作者
1.研究背景
近年来,伴随多模态大模型(MLLMs)的兴起,已经在视觉-语言、音频-语言等任务上取得了巨大进展。然而,当在多模态下游任务进行微调时,当前主流的多模态微调方法大多直接沿用了在纯文本大语言模型(LLMs)上发展出的微调策略,比如 LoRA。但这种“照搬”策略,未结合多模态学习特性进行深入思考。事实上,在多模态场景中,单模态信息的独立建模(Unimodal Adaptation)和模态之间的交互建模(Cross-modal Adaptation)是同等重要的,但当前的微调范式往往没有并重地显式考量前者,导致对单模态,尤其是非文本模态的利用存在潜在局限性。
2.方法介绍
基于此本文提出,要高效地微调多模态大模型,单模态信息的独立建模和模态之间的交互建模缺一不可。基于以上思想,本文提出了MokA方法,兼顾单模态信息的独立建模和模态之间的交互建模。
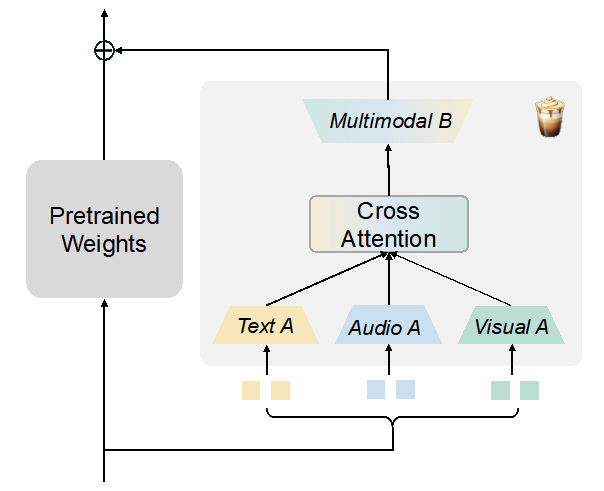
图1 MokA方法架构图
MokA在结构上继承了LoRA的核心思想,以保持高效的优点。但基于多模态场景对于A、B投影矩阵的角色进行了重新定义。如上图所示,MokA包括三个关键模块:模态特异的A矩阵,跨模态注意力机制和模态共享的B矩阵。
-模态特异的A矩阵: MokA考虑多模态场景,使用模态特异的 A 矩阵,从而可以在参数空间中保留模态独立性,确保每种模态的信息压缩过程不会互相干扰,实现单模态信息独立建模。
-跨模态注意力机制:这一模块的主要目的是显式增强跨模态之间的交互。在进行instruction tuning时,通常文本信息包含了具体的问题或任务描述,而其他模态信息提供了回答问题的场景。因此,为了显式加强跨模态交互,MokA在独立压缩后的低秩空间内对文本和非文本模态之间进行了跨模态建模,加强任务和场景间的关联关系。
-模态共享的B矩阵:最后,在独立子空间中的各个模态被统一投影到一个共享空间中,利用一个共享的低秩矩阵 B 进行融合,以共享参数的方式进一步隐式实现跨模态对齐。
在多模态场景下,MokA有效保证了对单模态信息的独立建模和模态之间的交互建模。
3.实验结果
实验在三个具有代表性的多模态任务场景上进行了评估,分别包括音频-视觉-文本、视觉-文本以及语音-文本。同时,在多个主流语言模型基座(如 LLaMA 系列与 Qwen 系列)上系统地验证了方法的适用性。结果表明,MokA 在多个标准评测数据集上均取得了显著的性能提升,展现出良好的通用性与有效性。
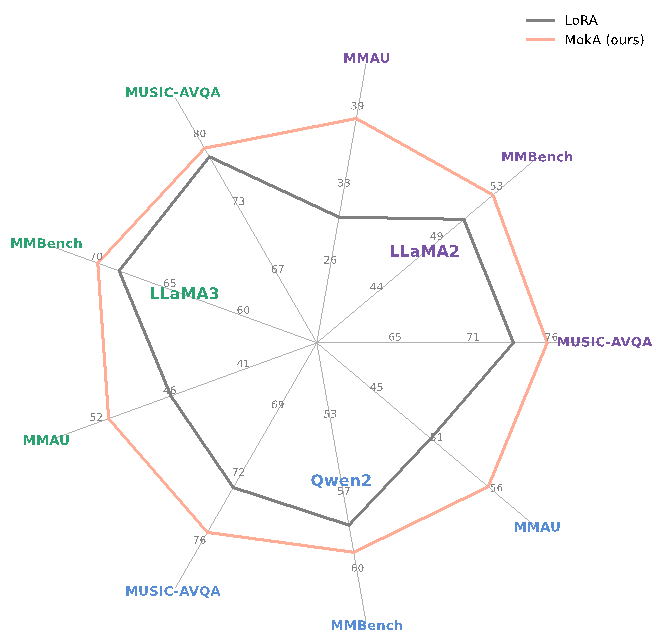
图2 MokA在多种多模态场景、多个基座上均取得增益

编辑人:吴建龙、任文琦
专委会责任副主任:张勇东
 京公网安备11010802017125号
京公网安备11010802017125号