
【论文导读】2026年论文导读第二期
【论文导读】2026年论文导读第二期


论文导读
2026年论文导读第二期(总第一百四十二期)
目 录
|
1 |
DORNet: A Degradation Oriented and Regularized Network for Blind Depth Super-Resolution |
|
2 |
SegEarth-OV: Towards Training-Free Open-Vocabulary Segmentation for Remote Sensing Images |
|
3 |
SViMo: Synchronized Diffusion for Video and Motion Generation in Hand-object Interaction Scenarios |
|
4 |
DynamicEarth: How Far Are We from Open-Vocabulary Change Detection? |
|
5 |
REMOTE: A Unified Multimodal Relation Extraction Framework with Multilevel Optimal Transport and Mixture-of-Experts |
01
DORNet: A Degradation Oriented and Regularized Network for Blind Depth Super-Resolution
作者:
王正学1,†,严志强1,†*,潘金山1,高广谓2,张凯3,杨健1*
单位:
1南京理工大学
2南京邮电大学
3南京大学
邮箱:
zxwang@njust.edu.cn
yanzq@njust.edu.cn
jspan@njust.edu.cn
csggao@gmail.com
kaizhang@nju.edu.cn
csjyang@njust.edu.cn
论文:
https://openaccess.thecvf.com/content/CVPR2025/html/Wang_DORNet_A_Degradation_Oriented_and_Regularized_Network_for_Blind_Depth_CVPR_2025_paper.html
代码链接:
https://github.com/yanzq95/DORNet
发表会议:CVPR 2025 Oral
*通讯作者
共同第一作者
1. 研究背景
盲深度图超分辨率的目的是从具有未知退化的低分辨率深度图重建准确的高分辨率深度图,其中高分辨率RGB图像经常被用作引导信号来增强深度图。该任务被广泛的应用于许多领域,例如虚拟现实,增强现实和3D重建等。最近,大量基于RGB图像引导的深度图超分辨率方法被提出。这些方法通常基于深度图的退化是已知(例如Bicubic下采样和最近邻下采样)的假设进行设计的,他们通过引入不同的RGB图像和深度图特征融合策略,在合成数据上实现了卓越的性能。然而,在真实应用场景中,由于消费级传感器技术的局限性以及成像环境的复杂性,获取的深度图通常会遭受未知且复杂的退化,例如结构畸变与模糊。这使得现有依赖固定退化假设的方法在面对复杂真实环境时性能显著下降。
2. 方法介绍
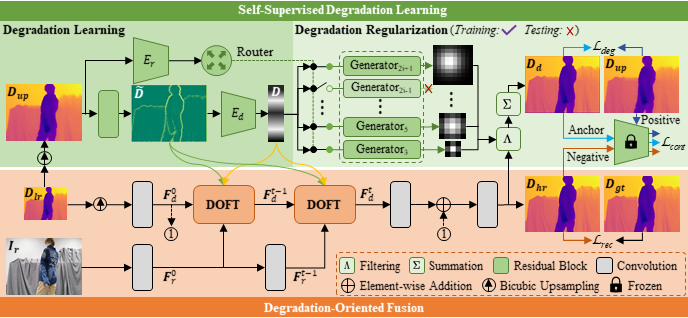
图1 DORNet的整体结构
针对上述问题,本文提出了一种退化导向和退化正则的盲深度图超分辨率网络(DORNet),其通过预测退化表示来自适应地解决真实场景中存在的未知退化问题。由于真实退化标签通常难以获取,显式地估计低分辨率与高分辨率深度图之间的退化表示极具挑战。为此,本文首先提出了一种自监督的退化学习策略,用于隐式的退化表示建模。如图1绿色区域所示,该策略以上采样后的低分辨率深度图为输入,通过退化学习网络估计退化表示 D。为了提升退化学习的准确性,本文进一步提出了一种基于路由选择的退化正则。具体而言,路由编码器首先生成路由器R,用于选择和控制不同尺度退化核的生成。基于图像退化模型,这些多尺度退化核被应用于预测的高分辨率深度图,以模拟低分辨率深度图的退化过程,从而合成新的退化深度图。随后,本文引入退化损失与对比损失来限制原始低分辨率深度图与新合成退化深度图之间的差异,以有效地约束退化表示的学习过程。
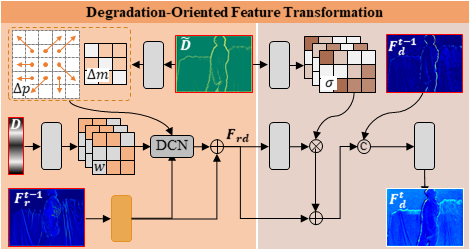
图2 退化导向的特征变换(DOFT)
与遭受严重退化的低分辨率深度图不同,RGB图像能够提供完整的场景信息和丰富的边缘结构。因此,本文提出了一种退化导向的RGB-D融合方案来自适应地利用RGB特征增强深度图。如图1橙色区域所示,该方案主要由多个迭代的退化导向的特征变换模块(DOFT)组成。如图2所示,DOFT包含退化导向的RGB特征学习(左侧)与退化导向的RGB-D特征聚合(右侧)两个阶段,其目的是利用退化表示作为提示滤除RGB特征中与深度无关的纹理噪声,从而选择性地迁移RGB特征中与退化区域匹配的结构信息到深度图特征。
3. 实验结果
表1给出了在真实的RGB-D-D和TOFDSR数据集上的定量比较结果。表2进一步展示了联合深度图超分辨率与去噪的性能比较。这些结果表明,本文提出的方取得了显著的性能优势和鲁棒性,超过了以往的方法。同时,图3进一步揭示了模型复杂度比较。可以明显地看出,DORNet不仅在性能上显著优于现有方法,同时也表现出极具竞争力的模型参数与推理速度。图4和图5提供了在真实数据集上的可视化结果,证实DORNet能够有效地重建严重退化的深度结构,相较于已有方法能够显著减少重建误差。
表1 在真实RGB-D-D和TOFDSR数据集上的定量比较

表2 联合深度图超分辨率与去噪的定量比较

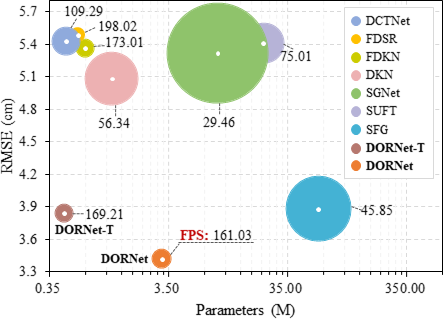
图3 在真实RGB-D-D数据集上的复杂度比较

图4 在真实RGB-D-D数据集上的可视化比较
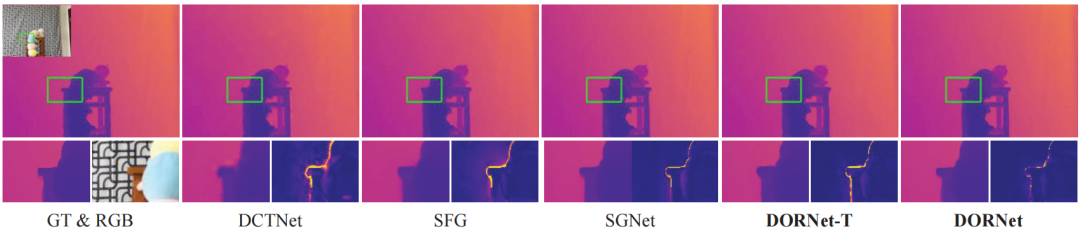
图5 在真实TOFDSR数据集上的可视化比较
4. 总结
本文提出了一种面向真实场景的深度图超分辨率方法——退化导向与退化正则网络(DORNet)。该方法提出了一个自监督的退化学习策略,利用基于路由选择的退化正则实现了无需标签的退化建模,有效地估计低分辨深度图的退化表示。此外,本文进一步提出了一个退化导向的RGB-D融合方案。该方案使用学习到的退化表示作为提示,选择性地迁移RGB特征中与退化区域匹配的结构信息到深度图,显著提升了深度结构的恢复质量。大量实验证明,所提出方法在真实场景中表现出卓越的性能和鲁棒性。
02
SegEarth-OV: Towards Training-Free Open-Vocabulary Segmentation for Remote Sensing Images
作者:
李开宇1,刘睿勋1,曹相湧1*,白雪茹2,周峰2,孟德宇1,王志1
单位:
1西安交通大学
2西安电子科技大学
邮箱:
likyoo.ai@gmail.com
liuruixun6343@gmail.com
caoxiangyong@mail.xjtu.edu.cn
xrbai@xidian.edu.cn
fzhou@mail.xidian.edu.cn
dymeng@mail.xjtu.edu.cn
zhiwang@xjtu.edu.cn
论文:
https://openaccess.thecvf.com/content/CVPR2025/html/Li_SegEarth-OV_Towards_Training-Free_Open-Vocabulary_Segmentation_for_Remote_Sensing_Images_CVPR_2025_paper.html
代码链接:
https://github.com/likyoo/SegEarth-OV
发表会议:CVPR 2025 Oral
*通讯作者
1.研究背景

图1 当前OVSS方法在遥感图像中存在的问题
在地球观测任务中,传统的“闭集”语义分割模型受限于预定义的训练类别,难以应对现实世界中成千上万的地物类型。虽然视觉语言大模型(如 CLIP)提供了强大的零样本识别能力,但将其应用于遥感领域时存在两大瓶颈:首先是空间分辨率的严重损失,CLIP 提取的特征图通常仅为原图分辨率的 1/16,导致预测掩码边缘模糊,细长道路或微小建筑等目标极易扭曲甚至消失;其次是全局信息的干扰,CLIP 在预训练过程中强化的全局 [CLS] 标记会给局部特征带来偏置(Global Bias),导致模型在判断局部像素类别时受到背景或主要类别的“污染”。
2.方法介绍
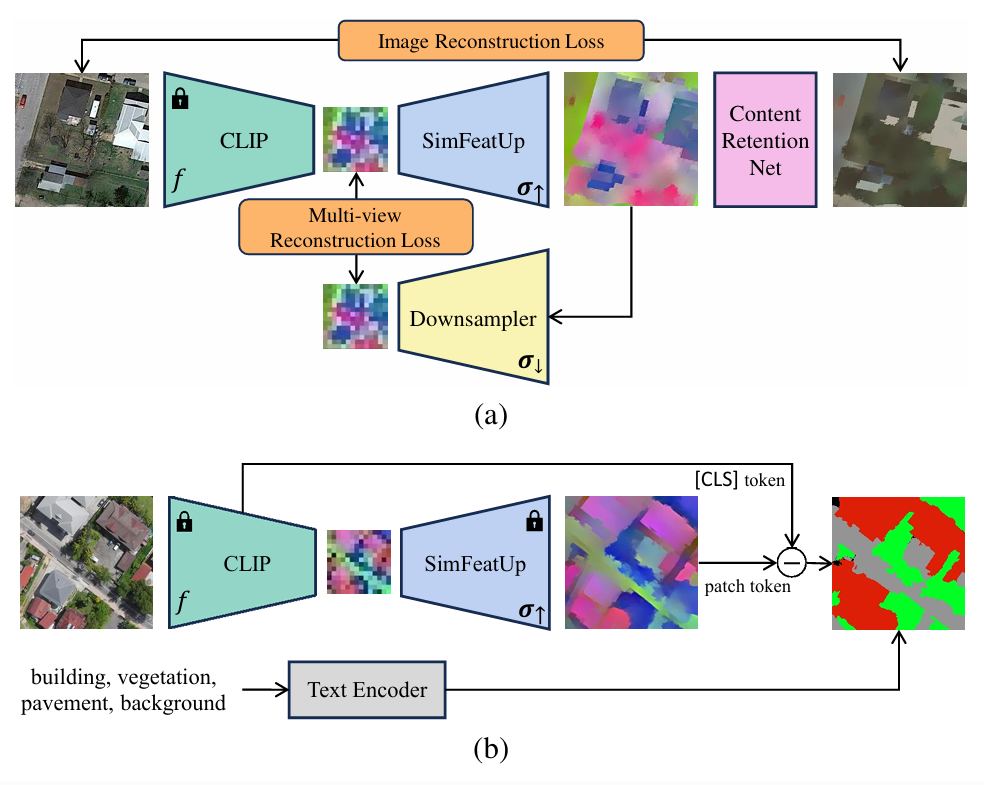
图2 所提方法的训练和推理流程
为了找回丢失的空间细节,本文引入并改进了FeatUp这一特征上采样框架。FeatUp 的核心思路是建立一个“上采样-下采样”的循环:通过学习一个联合双边上采样器(JBU)将低分辨率特征拉伸至高分辨率,再通过一个学习过的下采样器将其还原,利用两者之间的重构损失来约束高分辨率特征的语义一致性。然而,原始 FeatUp 在遥感任务中仍会丢失关键纹理。为此,本研究提出了SimFeatUp,其引入了内容保留网络(CRN)和图像重构损失—不仅要求高分辨率特征能还原低维特征,还要求它能重构出原始RGB图像。这一强约束确保了高分辨率特征在保留语义的同时,精准锁定了原图的几何边界,有效解决了细小地物消失的问题。此外,本文将结构简化为单层“JBU One”,并扩大采样窗口以适应遥感影像巨大的尺度波动。
在特征精练阶段,针对 CLIP 固有的全局偏置问题,本文提出了一种简单且极具启发性的全局偏置缓解策略(Global Bias Alleviation)。本文观察到,CLIP 的局部patch标记往往携带了过多与整幅图像相关的宏观信息。通过在推理阶段从每一个patch标记中减去一定比例的全局 [CLS] 标记特征,模型能够像“减法滤镜”一样滤除背景噪声和全局偏置。这种策略显著增强了局部特征的判别力,使得模型能够更纯粹地聚焦于局部地物的属性,从而生成边缘锐利、识别准确的分割掩码,且整个过程无需任何标注数据训练。
3.实验结果
SegEarth-OV 在涵盖卫星与无人机影像的 17 个典型遥感数据集上进行了全面评估。任务横跨多类语义分割、建筑物提取、道路提取以及洪水检测。实验结果表明,在完全不使用人工标注的情况下,该方法在四大任务上的平均性能相比现有最先进方法分别提升了5.8%、8.2%、4.0% 和 15.3%。
此外,该方法表现出极强的泛化能力。实验证明,SimFeatUp 和全局偏置缓解策略具有“即插即用”的特性,能够直接提升 MaskCLIP 等现有框架在自然图像数据集(如 COCO-Stuff)上的表现。这项研究不仅为遥感影像提供了高效的开集感知方案,也为如何利用基础大模型进行高精度密集预测任务提供了新的思路。
表1 SegEarth-OV与其他相关方法在遥感语义分割上的定量比较
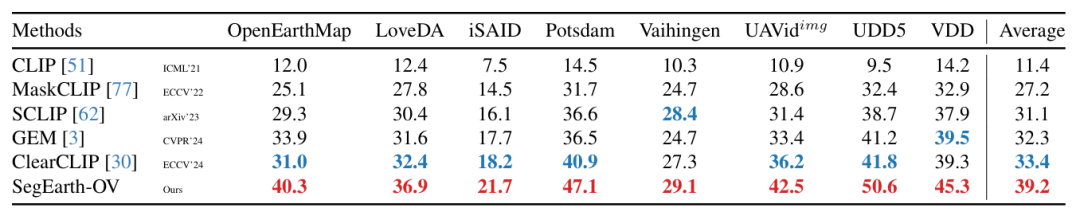
表2 SegEarth-OV与其他相关方法在遥感特定地物提取上的定量比较
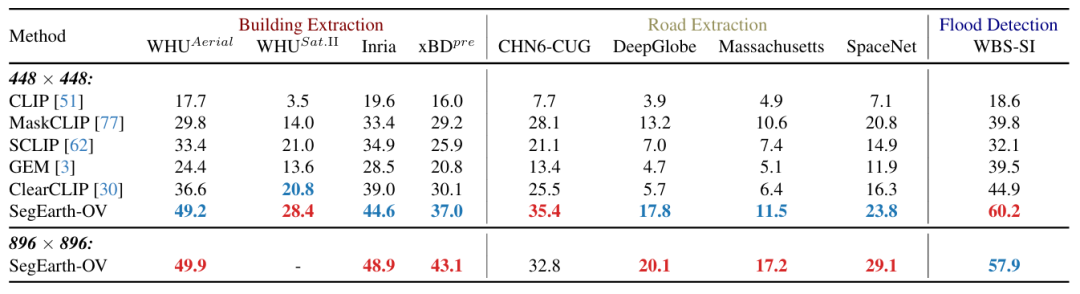

图3 SegEarth-OV与其他相关方法的定性比较
4.总结
本文提出了SegEarth-OV框架,通过引入带图像重建损失的SimFeatUp模块与全局偏置缓解策略,解决了CLIP模型在遥感影像中细节丢失与空间偏置的瓶颈。
本文的后续版本SegEarth-OV-2(arXiv: 2508.18067)通过提出AlignEarth蒸馏方法,成功将开集感知能力扩展至SAR影像,实现了免标注的跨模态感知。最新版本SegEarth-OV-3(arXiv: 2512.08730)则探索了SAM 3的潜力,利用双头掩码融合与存在分数过滤技术,大幅提升了遥感场景下的语义分割精度。
03
SViMo: Synchronized Diffusion for Video and Motion Generation in Hand-object Interaction Scenarios
作者:
党灵伟1,†,邵睿智2,†,张鸿文3,闵伟4,刘烨斌2,吴庆耀1*
单位:
1华南理工大学
2清华大学
3北京师范大学
4影身智能
邮箱:
levondang@163.com
jia1saurus@gmail.com
zhanghongwen@bnu.edu.cn
minwei@yingshen-ai.com
liuyebin@tsinghua.edu.cn
qyw@scut.edu.cn
论文:
https://openreview.net/pdf?id=huZzy5w2Js
代码链接:
https://droliven.github.io/SViMo_project/
发表会议:NeurIPS 2025 (Spotlight)
*通讯作者
†共同第一作者
1.研究背景
手物交互视频与动作生成研究通过精准建模人手与物体的动态关联,在提升虚拟交互真实感与内容生产效率的同时,更为具身机器人的模仿学习提供了符合物理规律的大规模训练资源,成为突破灵巧操作瓶颈的关键。这种视频与动作的“共生生成”范式,通过实现外观演化与动力学约束的深度对齐,有效克服了传统分步生成中常见的视觉伪影与物理失真。在这种双向驱动的关联机制下,模型能够在合成高保真视觉细节的同时,精确捕捉复杂的接触时序与运动轨迹,从而为重构复杂操作逻辑提供更完备的表征支撑。

图1 手物交互视频动作共生背景与动机
2.方法介绍
基于手物交互2D视频与3D动作本质上共享着真实世界的物理动力学基础这一动机,本工作提出一种视频-动作共生框架,能够从参考图像与文本指令中同时生成手物交互视频与对应的动作序列。方法上,首先通过一个同步扩散模型将视频生成与运动合成统一于联合去噪过程中,有效融合视觉先验与运动学约束。其次,引入视觉感知的3D动作扩散模型,生成显式动作序列,并与同步扩散模型形成闭环反馈机制,从而增强视频与动作之间的一致性。此外,为更好地整合文本语义、视觉外观与运动动态的异构特征,本文提出三模态自适应调制机制进行特征对齐,并采用三维全注意力机制以挖掘深层特征关联。该方法无需依赖预定义的姿态或物体模型,在生成结果的真实感、合理性和一致性方面均优于现有方法。并在域外数据及真实世界数据上具备一定泛化性。
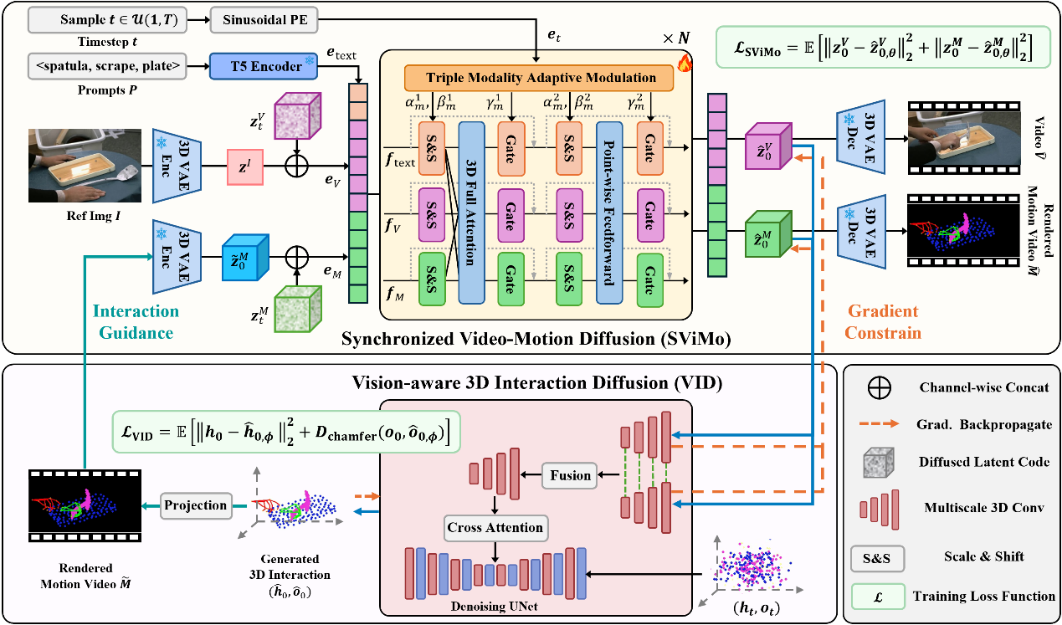
图2 方法框架图
3.实验结果
本文与两大类典型视频生成模型进行了充分对比。包括原生3D视频生成模型、由图像生成增强扩展所得的2.5D视频生成模型。表中显示了本文方法能够得到最优的综合分数。而基线方法表现欠稳,暴露出动作静止、凭空幻想、以及时序闪烁畸变和不一致的问题。 相比之下,本文方法得益于视觉和动态信息的同步建模,从而实现了更优越的包括视觉真实感与动作合理性在内的综合表现。图3定性展示了本文方法视频与动作的共生结果,并且在真实世界采集的数据上进行了零样本泛化实验。
表1 三大类方法视频生成结果定量对比
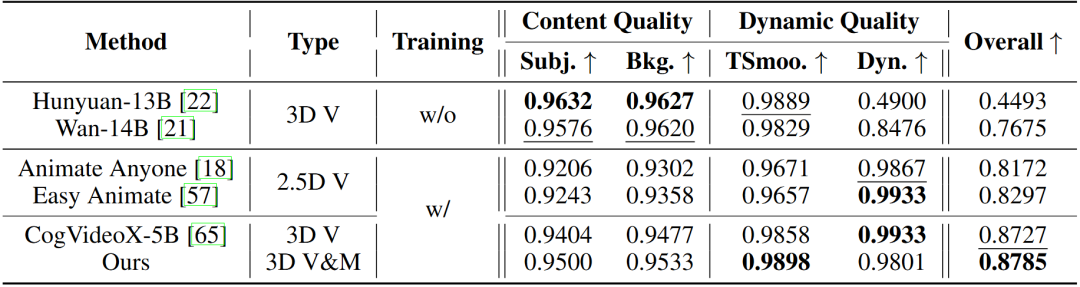

图3 视频动作共生结果展示(前两行)及真实数据零样本泛化结果(第三行)
4.总结
本文针对视觉外观与运动动力学的协同演化关系,提出了一种同步扩散模型。该模型将手物交互视频生成与运动合成整合于统一的扩散过程,确保了结果的视觉真实性与动力学合理性。此外,通过引入视觉感知3D交互扩散模型提供引导与约束,构建了增强视频-运动一致性的闭环优化管线。本方法为多模态表征融合及复杂世界模型的构建提供了新范式。
04
DynamicEarth: How Far Are We from Open-Vocabulary Change Detection?
作者:
李开宇1,曹相湧1*,邓毓弸2,庞超3,辛泽鹏1,乔慧4,龚铁梁1,孟德宇1,王志1
单位:
1西安交通大学
2中国科学院空天信息创新研究院
3武汉大学
4陕西电信
邮箱:
likyoo.ai@gmail.com
caoxiangyong@mail.xjtu.edu.cn
dengyp@aircas.ac.cn
pangchao@whu.edu.cn
37xinzepeng@stu.xjtu.edu.cn
qiaoh@chinatelecom.cn
gongtl@xjtu.edu.cn
dymeng@mail.xjtu.edu.cn
zhiwang@xjtu.edu.cn
论文:
https://arxiv.org/abs/2501.12931
代码链接:
https://likyoo.github.io/DynamicEarth
发表会议:AAAI 2026
*通讯作者
1.研究背景
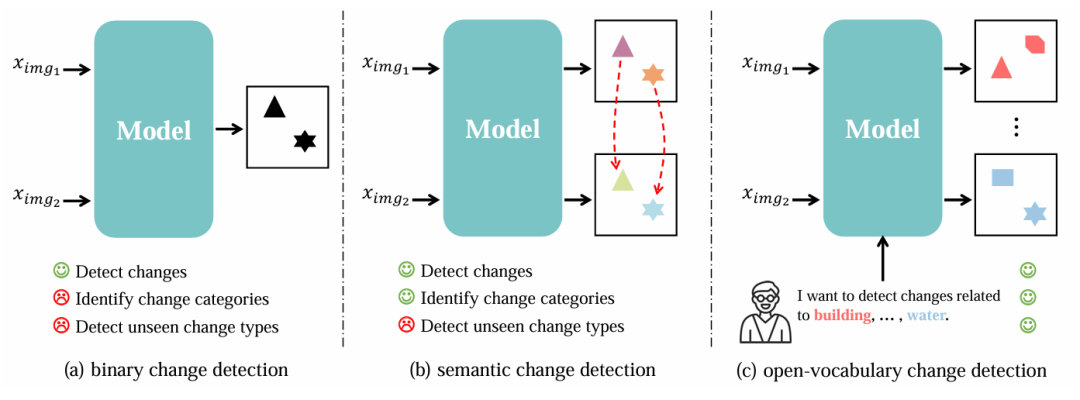
图1 不同的变化检测任务
在遥感领域,传统的变化检测(Change Detection)长期受限于“闭集”设定:模型只能识别训练集里定义好的类别(如建筑、道路),面对新出现的类别(如光伏板、临时帐篷)则无能为力。此外,遥感标注数据成本极高,导致模型往往在特定区域表现优异,换一个城市或传感器就会因为“域偏移”而性能骤降。
为了解决这一痛点,本文正式提出了开放词汇变化检测(Open-Vocabulary Change Detection, OVCD)任务。其核心目标是:不再依赖固定类别的标签进行训练,而是通过自然语言描述,让模型在“开放世界”中识别和定位任何用户感兴趣的变化。这要求模型不仅要具备强大的空间感知能力(哪里变了),还要具备深度的语义理解能力(变成了什么)。
2.方法介绍
考虑到遥感领域高质量标注数据的匮乏,本文并未选择从头训练大型模型,而是巧妙地提出了两种免训练(Training-free)的通用框架,通过串联不同的视觉基础模型(Foundation Models)来实现 OVCD 任务。两个框架都由三个核心组件构成:掩码提议(Mask Proposal)、比较器(Comparator)和识别器(Identifier)。
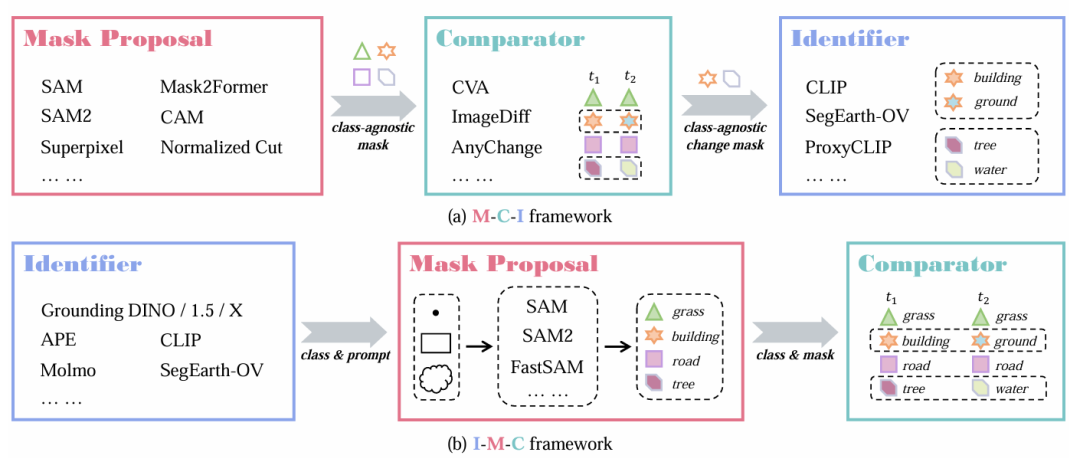
图2 本文所提出的两种框架
M-C-I 框架(先发现后分类):旨在“不放过任何变化”。它首先利用 SAM/SAM2 在双时相图像中生成海量的类无关掩码;接着,比较器通过 DINOv2 提取特征,计算两个时相对应区域的负余弦相似度,筛选出发生显著变化的区域;最后,识别器采用一种高效的“掩码平均池化”策略,将变化区域的特征与 CLIP 或 SegEarth-OV 的文本嵌入进行匹配,从而确定具体类别。
I-M-C 框架(先定位后比较): 遵循“按需检测”的逻辑。首先利用 Grounding DINO 或 APE 等模型,根据文字提示(如“检测建筑变化”)在图像中直接定位目标框或点;随后利用 SAM 将这些粗略的定位细化为精确掩码;最后,比较器结合了 IoU 几何重叠度分析和潜在特征匹配,排除掉由于光照或季节变化引起的“伪变化”,只保留语义上的真实变化。
3.实验结果
表1 在建筑物变化检测数据集上的定量比较
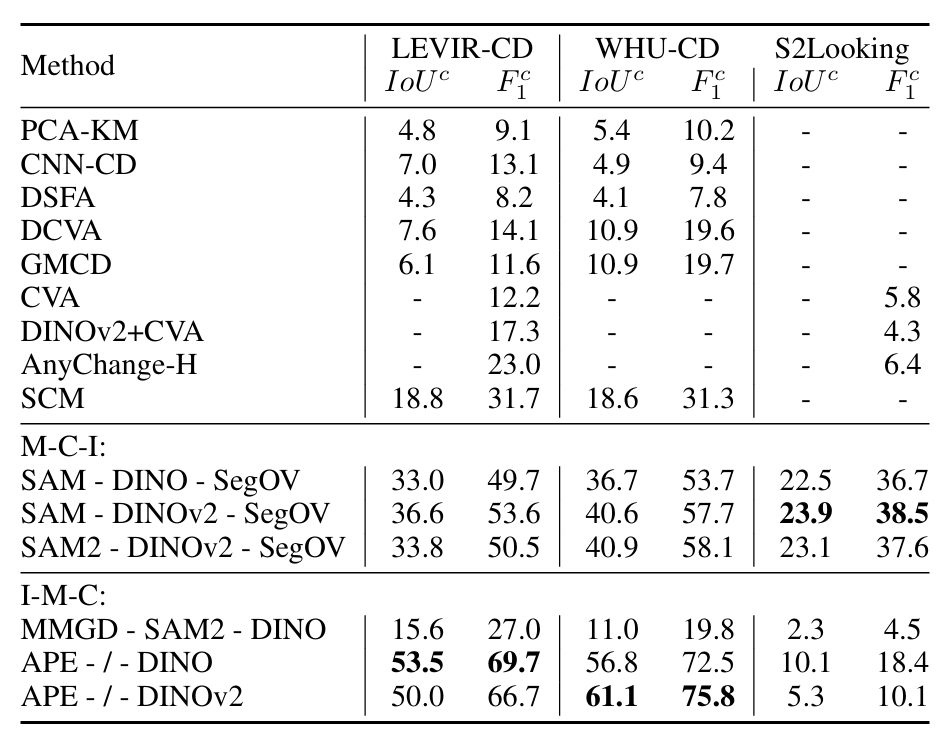
本文在 LEVIR-CD、WHU-CD、S2Looking 等四个数据集上进行了实验。结果显示,DynamicEarth 中提出的框架在性能上全面超越了传统的无监督方法(如 PCA-KM, CVA 等),并在多个指标上达到了与全监督模型竞争的水平。
表2 OVCD方法与监督学习方法在跨数据集场景下的对比
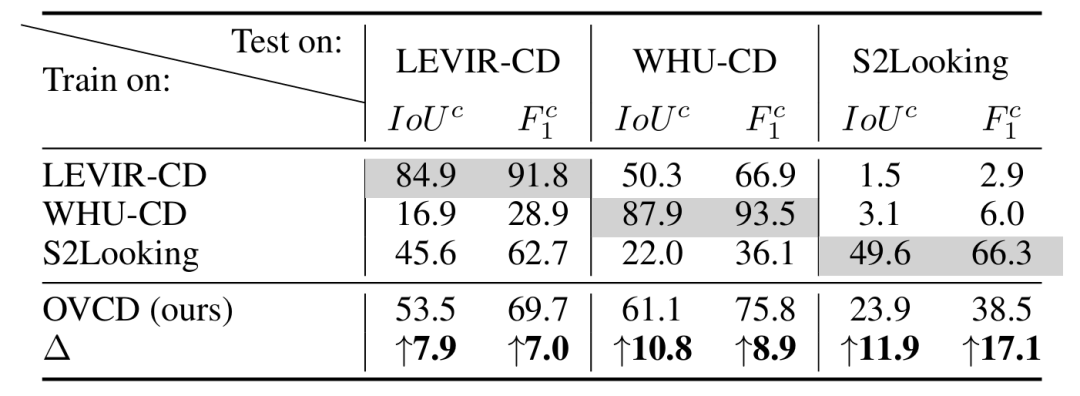
卓越的跨数据集泛化: 实验中一个极具说服力的发现是(见表2):在 LEVIR-CD 数据集上训练的监督模型,在处理 S2Looking 数据集(侧视卫星影像)时性能会断崖式下跌(IoU 仅 1.5);而本文的免训练 OVCD 方法在未见数据上表现出了极强的鲁棒性,IoU 提升了近 12 个百分点,充分证明了视觉基础模型在处理复杂地理环境时的天然优势。
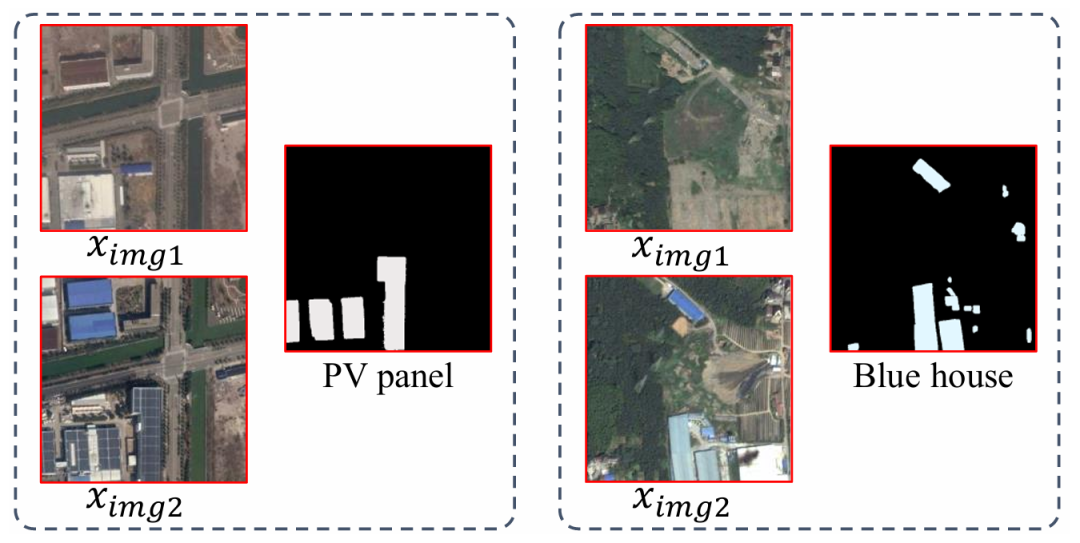
图3 OVCD方法在不常见的变化类别上的检测效果
罕见类别的“零样本”发现: 图3展示了模型在检测“光伏板”和“蓝色房屋”等非常规目标时的惊人潜力。即使在没有任何相关遥感标注训练的情况下,通过简单的文字指令,模型也能精准勾勒出这些细分目标的变更边界。尽管在处理“低矮植被”等模糊背景类时仍有挑战,但该研究为构建“全能型”地球观测系统迈出了关键一步。
05
REMOTE: A Unified Multimodal Relation Extraction Framework with Multilevel Optimal Transport and Mixture-of-Experts
作者:
林昕奎1,2,徐永秀1,2*,唐铭浩1,2,张世龙1,2,许洪波1,2*,徐浩1,2,王玉斌1,2
单位:
1中国科学院 信息工程研究所
2中国科学院大学 网络空间安全学院
邮箱:
linxinkui@iie.ac.cn
xuyongxiu@iie.ac.cn
tangminghao@iie.ac.cn
zhangshilong@iie.ac.cn
hbxu@iie.ac.cn
xuhao@iie.ac.cn
wangyubin@iie.ac.cn
论文:
https://dl.acm.org/doi/abs/10.1145/3746027.3754868
代码链接:
https://github.com/Nikol-coder/REMOTE
发表会议:ACM MM 2025
*通讯作者
1.研究背景
随着多媒体在线内容的迅速发展,多模态关系抽取(Multimodal Relation Extraction,MRE)已经成为驱动跨模态检索和多模态知识图谱构建的重要任务。然而,现有的多模态关系抽取方法高度割裂,存在明显局限性。

图1 不同多模态关系抽取任务的展示
其一,多数方法仅能抽取单个类型的关系三元组,限制了其抽取特定类型外三元组的能力,缺乏为不同类型关系三元组动态选择最适配跨模态交互特征的能力。

图2 特征融合不同层次的注意力可视化
其二,现有的特征融合方法主要使用编码器的倒数一或二层表征,只关注了主体对象特征,而忽视了低层次的细节信息。
为了解决这些问题,我们提出了一个统一的多模态关系抽取框架—REMOTE,首次实现了文本实体与视觉对象之间的模态内(文本实体之间,视觉对象之间)和模态间(文本实体和视觉对象之间)关系的统一抽取,能够为不同类型的关系三元组选择最优的交互特征。
2.方法介绍
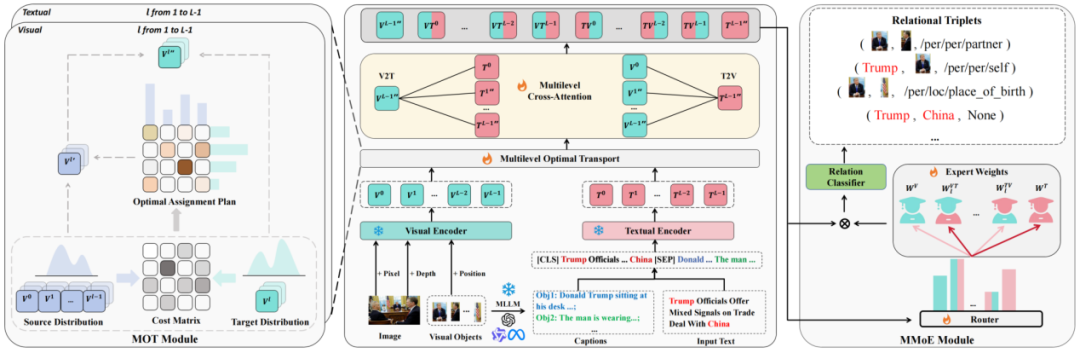
图3 REMOTE框架图
本工作主要贡献如下:
(1)多级特征融合模块(Multilevel Optimal Transport,MOT):利用最优传输将编码器不同层次的表征结合起来,进行多层次特征融合,同时关注全局特征和低级细节信息。
(2)多模态混合专家模块(Multimodal Mixture of Experts,MMOE):引入多模态混合专家机制,为不同类型的关系三元组动态选择最优交互特征。
首次实现对文本实体与视觉对象之间模态内及模态间关系的统一抽取。
REMOTE融合多层次最优传输机制,同时保留全局特征和低层细节信息,并引入多模态混合专家结构,根据关系类型动态路由最优特征组合,从而在保持语义完整性的同时显著提升跨模态推理的灵活性与准确性。
3.实验结果
如表1所示,REMOTE无论是在统一式关系抽取,还是在单独的关系抽取任务上均显著优于现有方案。此外,表2的模块消融实验也证明了在保留多层次特征方面,最优传输要优于注意力机制。表3和表4的特征和专家消融也进一步验证了我们所提方法的关键作用,无论移除哪个策略,均会导致性能下降。
表1 多模态关系抽取任务比较结果
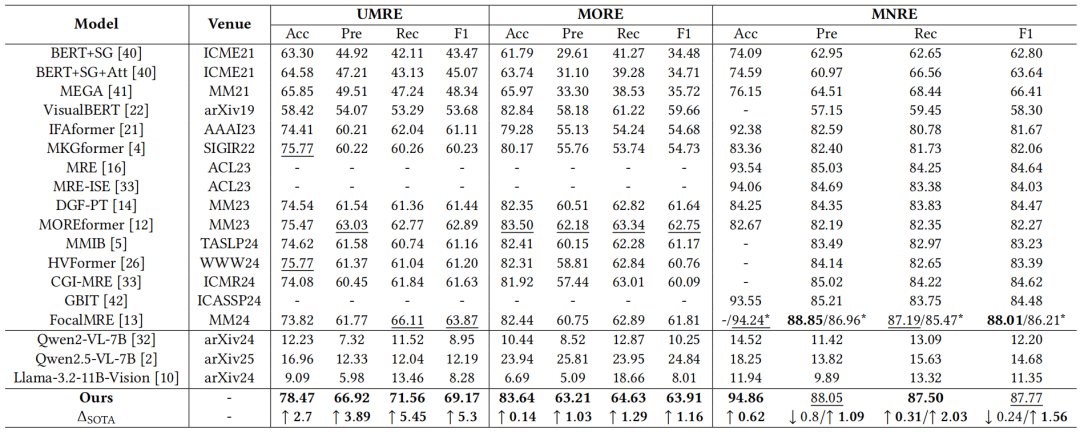
表2 模块消融实验结果
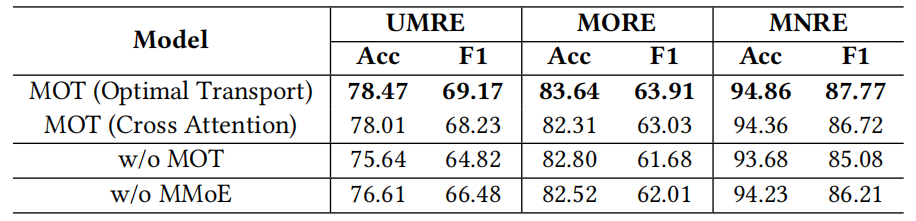
表3 特征消融实验结果 (P:position, C:caption, D:depth)
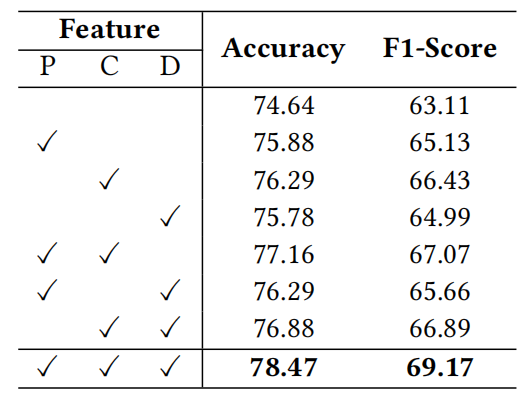
表4 专家消融实验结果 (T2V: Text-to-Vision, V2T: Vision-to-Text, T: Text-only, V: Vision-only)

编辑人:吴建龙、任文琦
专委会责任副主任:张勇东
 京公网安备11010802017125号
京公网安备11010802017125号