
【论文导读】2026年论文导读第三期
【论文导读】2026年论文导读第三期


论文导读
2026年论文导读第三期(总第一百四十三期)
目 录
|
1 |
GROVE: A Generalized Reward for Learning Open-Vocabulary Physical Skill |
|
2 |
Keep the Balance: A Parameter-Efficient Symmetrical Framework for RGB+X Semantic Segmentation |
|
3 |
IceDiff: High Resolution and High-Quality Arctic Sea Ice Forecasting with Generative Diffusion Prior |
|
4 |
Mitigating Hallucinations in Large Vision-Language Models via DPO: On-Policy Data Hold the Key |
|
5 |
LoRASculpt: Sculpting LoRA for Harmonizing General and Specialized Knowledge in Multimodal Large Language Models |
01
GROVE: A Generalized Reward for Learning Open-Vocabulary Physical Skill
作者:
崔洁茗1,2†,刘腾宇2†,孟子喻3,於家乐4,张伟3,宋然3,朱毅鑫1*,黄思远2*
单位:
1北京大学人工智能研究院
2北京通用人工智能研究院
3山东大学控制科学与工程学院
4清华大学自动化系
邮箱:
jeremy.cuij@gmail.com
24.jason.5@gmail.com
mziyu0813@gmail.com
1293007148@qq.com
info@vsislab.com
ransong@sdu.edu.cn
yixin.zhu@pku.edu.cn
thuhsy.cs@gmail.com
论文:
https://arxiv.org/abs/2504.04191
代码链接:
https://github.com/jiemingcui/GROVE-pytorch
项目链接:
https://jiemingcui.github.io/grove/
发表会议:CVPR 2025 Oral
*通讯作者
共同第一作者
1. 研究背景
在人工智能领域,如何让虚拟角色通过自然语言指令学习多样化的物理技能一直是一个重要挑战。传统的强化学习方法依赖于人工设计的奖励函数,例如训练一个人形机器人“向前跑”需要手动设置速度、能量消耗等多重奖励条件。这种方式不仅耗时,而且难以推广到开放词汇的新任务中。
近年来,模仿学习和大语言模型(LLMs)等技术的出现为这一问题提供了部分解决方案,但它们各自存在局限性:模仿学习需要大量特定任务的演示数据,而LLMs虽然能生成精确的物理约束,却无法评估动作的整体自然性和语义合理性。例如,LLMs可能生成技术上正确但看起来不自然的动作,而视觉语言模型(VLMs)虽然能判断动作是否“看起来正确”,却难以保持时间一致性或精确的物理约束。因此,如何结合两者的优势,开发一种既能理解开放词汇指令又能生成自然动作的通用奖励框架,成为了当前研究的核心问题。
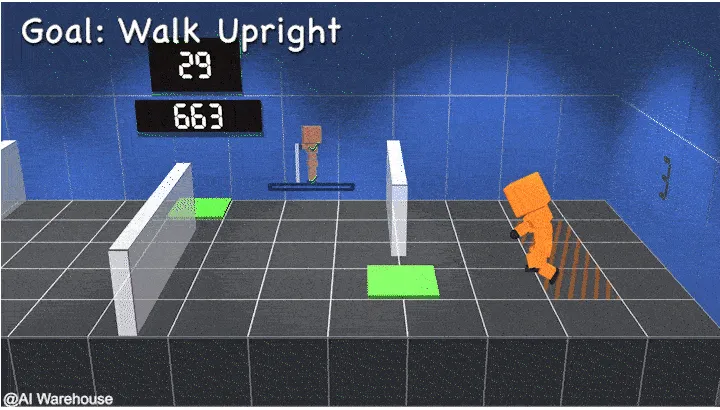
图1 传统RL算法的待解决问题
2. 方法介绍
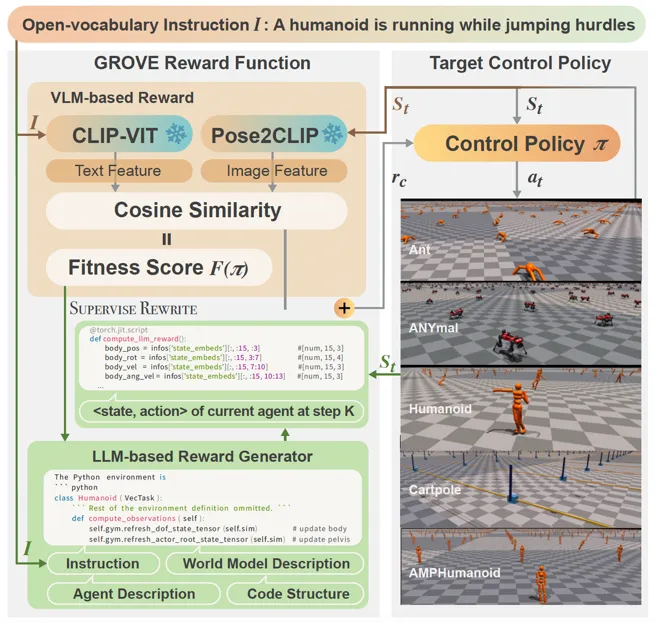
图2 GROVE模型框架
针对上述挑战,本文提出了GROVE,一种无需人工设计奖励或任务特定演示的通用奖励框架,旨在通过结合大型语言模型(LLM)对于细化到关节的准确控制以及视觉语言模型(VLM)提供的丰富语义信息,实现开放词汇物理技能的学习。核心思想在于:a) 更有效的VLM信息提供方式;b) VLM与LLM之间的迭代式奖励优化;c) 能够在多种智能体上体现有效性。
Pose2CLIP
首先,GROVE为了避免仿真环境图像与VLM训练数据之间的领域差异,团队开发了Pose2CLIP这一轻量级映射模型,能够直接将智能体的姿态信息转化为CLIP特征空间中的语义表示,省去了耗时的渲染过程。Pose2CLIP模型的训练采用了170万帧高质量渲染的人体姿态数据,这些数据来自开源数据集(AMASS、Motion-X)以及训练过程中产生的失败和成功的样本。为了确保模型的鲁棒性,每个姿态都从五个不同视角(前、侧、斜、后侧和后)进行渲染,并通过Blender增加更丰富的texture。模型针对人体动作的长尾性采取了基于k-means++聚类的分层均匀采样策略,有效解决了训练数据分布不平衡的问题。

图3 渲染前后的图片对比
奖励函数设计
在分别获得LLM与VLM有效信息之后,GROVE将物理技能学习建模为奖励设计问题(RDP),其核心是通过迭代式奖励优化实现指令与动作的精准对齐。具体而言,RDP被形式化为<所有可能奖励函数构成的函数空间, 适应度函数, 世界模型>的三元组,我们可以通过调节RDP来直接影响模拟环境中的状态变化。文章将VLM的输出值作为适应度评分的标准,当连续8个训练步骤中VLM奖励的平均值出现下降且最终值低于阈值k时,系统会自动触发LLM奖励函数的重新生成,从而进行及时的学习目标纠正。

图4 GROVE奖励函数生成流程
3. 实验结果
文章为了证明GROVE的综合能力,首先在多种智能体上进行从零开始(from scratch)的试验测试,这些智能体包含从简单智能体蚂蚁(Ant)到复杂智能体类人(Humanoid)的多种类别,以及近段策略优化(PPO)和柔性动作-评价(SAC)两种不同的基线方法。
表1 GROVE 在不同智能体上的实验结果
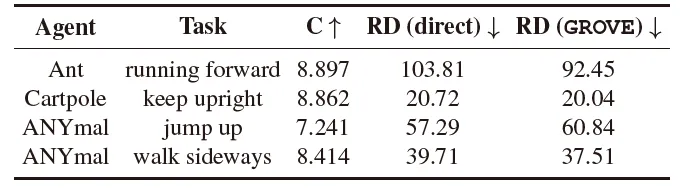
表2 GROVE与仅使用VLM作为基线方法的对比
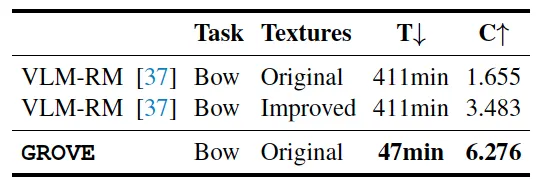

图5 从零开始的部分实验结果展示
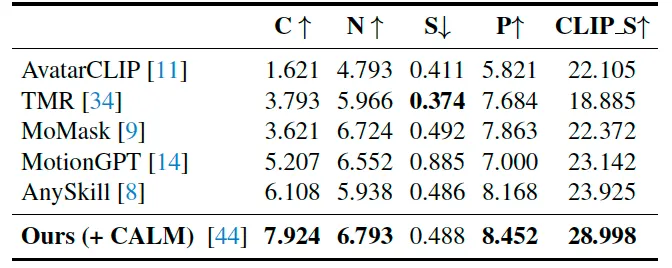
之后为了证明GROVE的泛用性,GROVE基于在少量人体数据集上预训练好的低阶控制器又进行了试验测试,包括与现阶段各个类别的SOTA方法进行比较、进行模型所有组成部分的消融实验。
表3 GROVE和现阶段各类SOTA方法相比较
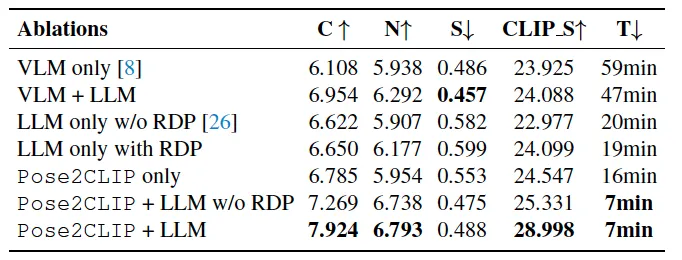
表4 消融实验
在不同智能体形态和学习范式下的广泛实验显示GROVE框架具有卓越性能:动作自然度提升22.2%,任务完成度提高25.7%,同时训练速度达到传统方法的8.4倍。这一突破为模拟环境中可扩展的物理技能学习奠定了新的技术基础。
02
Keep the Balance: A Parameter-Efficient Symmetrical Framework for RGB+X Semantic Segmentation
作者:
蔡家鑫1†,苏镜泽1†,李琦1,杨文杰1,王舒1,赵铁松1,何盛烽2,刘文犀1*
单位:
1福州大学
2新加坡管理大学
邮箱:
jiaxincai528@163.com
2501010011@fzu.edu.cn
fzuliqi2022@163.com
hokkien.ywj@gmail.com
shu@fzu.edu.cn
t.zhao@fzu.edu.cn
shengfenghe7@gmail.com
wenxi.liu@hotmail.com
论文:
https://openaccess.thecvf.com/content/CVPR2025/papers/Cai_Keep_the_Balance_A_Parameter-Efficient_Symmetrical_Framework_for_RGBX_Semantic_CVPR_2025_paper.pdf
代码链接:
https://github.com/imcjx/KTB
发表会议:CVPR 2025 Oral
*通讯作者
†共同第一作者
1.研究背景
语义分割作为计算机视觉核心任务,仅依赖RGB数据在复杂场景中表现受限,为解决这一问题,融合RGB与深度、热成像、偏振等多模态数据的RGB+X语义分割技术应运而生,成为提升性能的关键方向。现有方法存在明显不足,全微调策略计算与存储成本高、泛化性弱,而参数高效微调方法多以RGB为核心,无法充分挖掘其他模态潜力,还易受模态间噪声干扰,并且在极端环境例如模态缺失时性能骤降。因此,亟需一种能平衡性能、效率与多模态协同能力的可控框架,这构成了本研究的出发点。
2.方法介绍
本文以对称架构为核心,将RGB与X模态视为平等贡献者,而非主辅关系,通过三大组件实现高效分割。模态感知的提示适应模块生成模态专属提示与适配器,适应不同模态特征;动态稀疏跨模态融合模块在低维空间聚焦不同模态的主导区域,加权融合降噪;掩码模态自教学策略随机掩码模态,以三重监督强化鲁棒性。整体冻结主干仅微调少量参数,兼顾性能与效率。如图1所示。
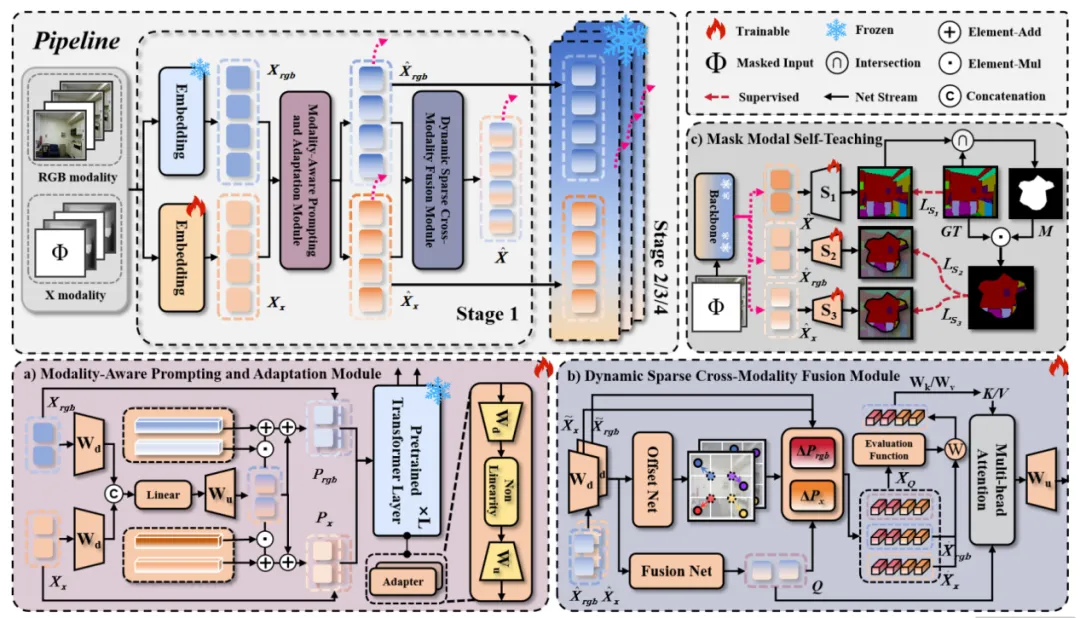
图1 总体架构示意图
模态感知的提示适应模块(MAPA):核心作用是让预训练模型能力同时适配RGB与X模态。首先将双模态特征融合为统一表示,实现跨模态信息共享;再基于该统一表示生成各模态专属提示,引导预训练模型聚焦模态特性;最后通过模态专属适配器,将预训练模型的特征表示能力高效迁移至对应模态,仅微调少量参数即可实现模态适配。
动态稀疏跨模态融合模块(DSCF):用于解决融合噪声问题。先将双模态特征映射至低维空间,生成参考点网格并预测偏移量,得到各模态的关键变形点,聚焦核心区域;再通过可学习的模态优势评估函数,量化每个变形点上不同模态的重要性;最后基于权重对双模态关键特征进行融合,结合多头注意力构建跨模态长距离上下文关系,实现高效降噪融合。
掩码模态自教学策略(MMST):用于强化模态增强与融合效果,提升模型鲁棒性。训练时随机掩码其中一种模态输入,模拟模态缺失场景,减少模型对单一模态的依赖;同时引入三重分割头监督机制,利用双模态融合结果的精准预测区域,反向指导单模态分割结果优化,让单模态特征具备更优的跨模态表示能力,强化模型效果。
3.实验结果
在6个涵盖不同模态组合的数据集上验证我们模型的通用性和有效性:RGB-Depth(表1)、RGB-Thermal(表2)、RGB-Polarization(表3)、RGB-Event(表4),对比全微调(FFT)方法,本模型仅需训练极少量的参数就能取得了超出或相近的性能(例如在RGB-Depth上相较于GeminiFusion,训练参数仅为其的4%),对比其他参数高效微调(PEFT)方法,本模型大幅领先此前模型。在任意一种模态缺失的条件下(图2),相较于先前的方法本模型具备极强的鲁棒性。
表1 各模型在RGB-D任务上的性能对比
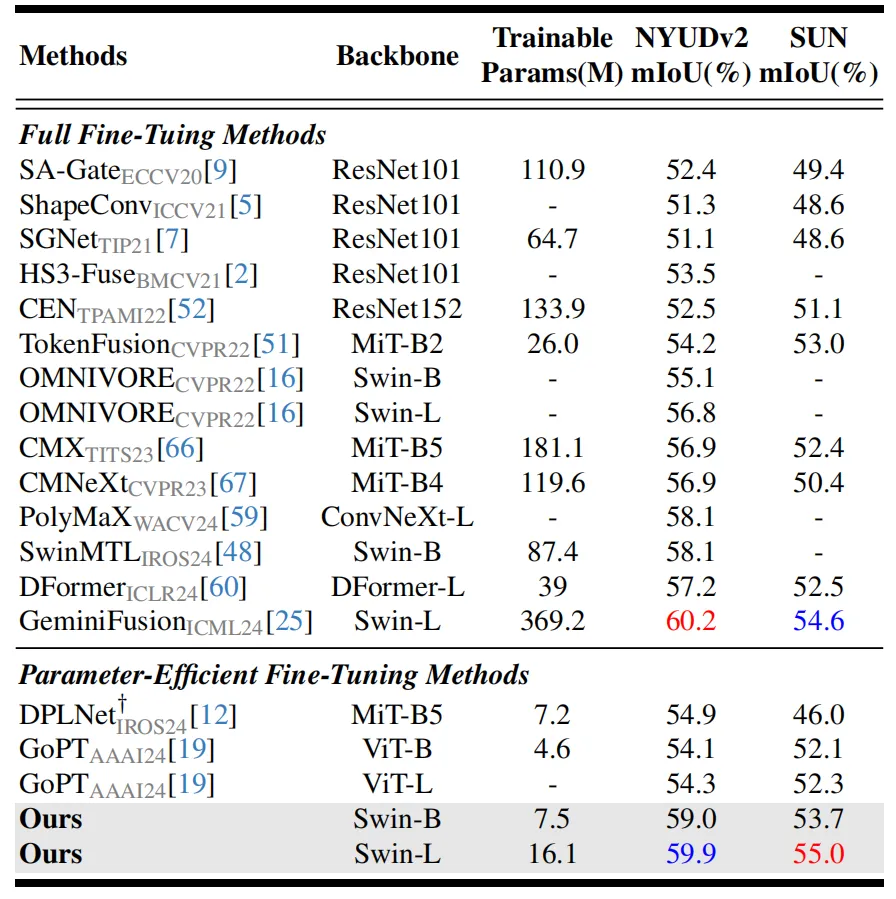
表2 各模型在RGB-T任务上的性能对比
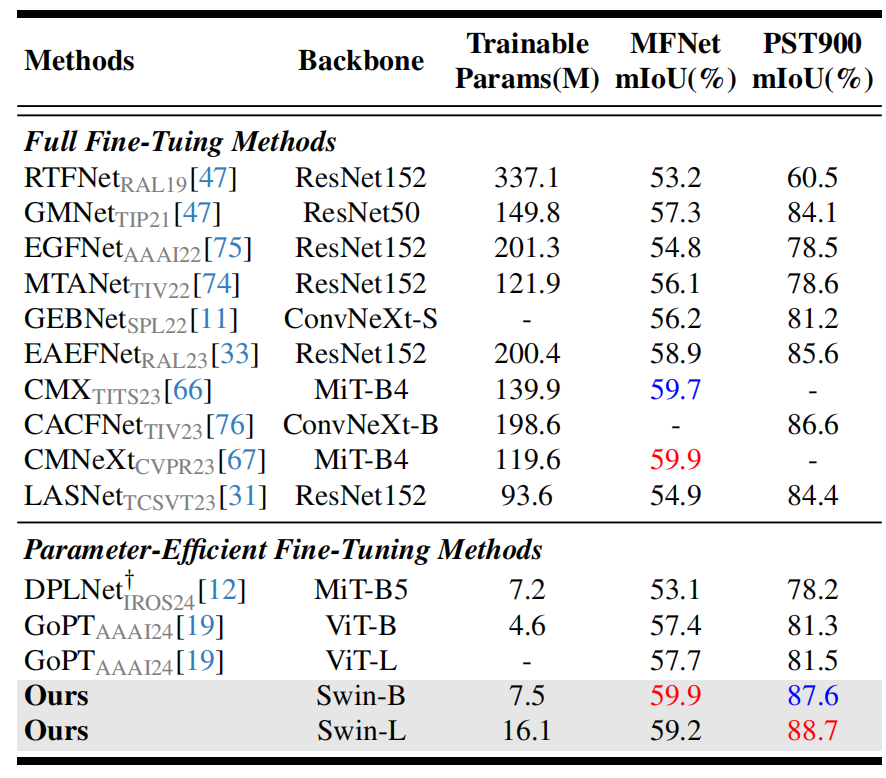
表3 各模型在RGB-P任务上的性能对比
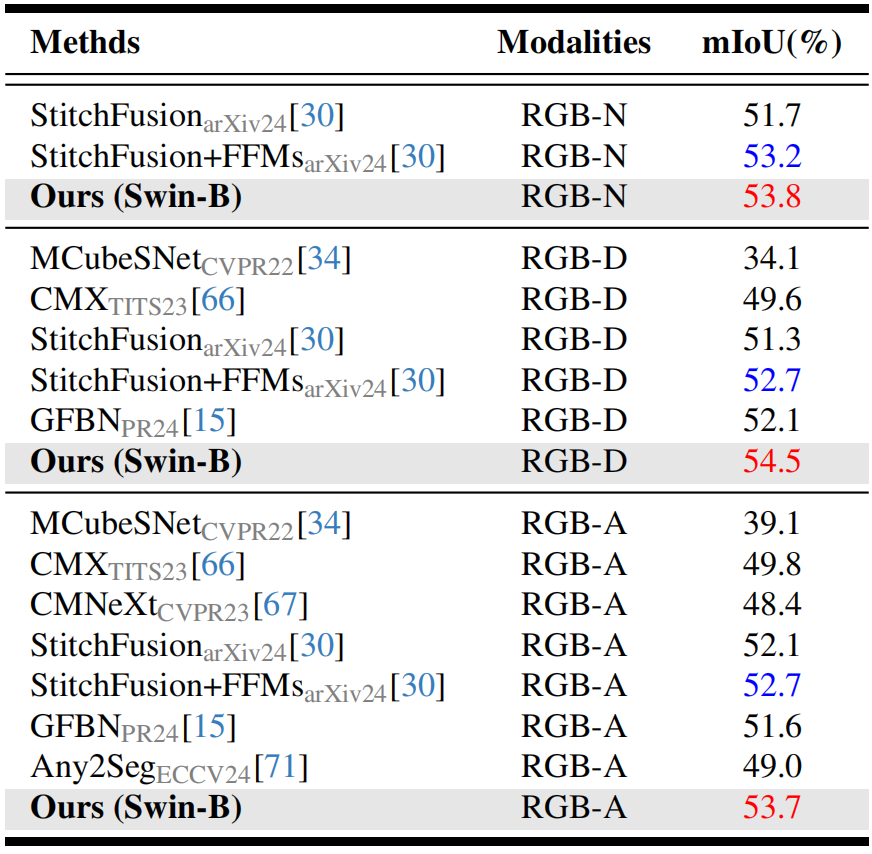
表4 各模型在RGB-E任务上的性能对比

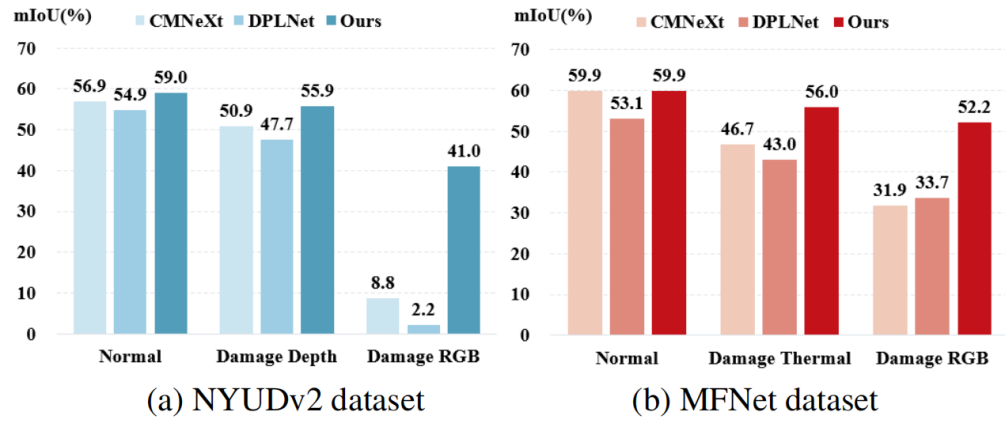
图2 各模型在模态缺失时的性能对比
03
IceDiff: High Resolution and High-Quality Arctic Sea Ice Forecasting with Generative Diffusion Prior
作者:
徐竞屹1,涂思危1,杨卫东1,费奔2,李舒豪1,刘可伊1,罗烨琪1,马立鹏1,白磊3
单位:
1复旦大学计算与智能创新学院
2香港中文大学
3上海人工智能实验室
邮箱:
jyxu22@m.fudan.edu.cn
wdyang@fuda.edu.cn*
benfei@cuhk.edu.hk*
baisanshi@gmail.com
论文:
https://ieeexplore.ieee.org/abstract/document/11094615
发表会议:CVPR 2025
*通讯作者
1.研究背景
当前全球气候变暖加剧,北极海冰面积、多年冰的厚度正急剧减少,使得开发北极地区蕴含的大量油气资源成为可能,北冰洋航线日益凸显其重要的资源、航运和地缘战略地位。随着人工智能技术的发展,基于数据驱动范式的人工智能模型逐渐展现出超越传统数值模型的预报能力。然而受限于海冰数据产品的空间分辨率,目前AI模型的预报尺度仍限定在25 km x 25 km范围。本文提出了一种基于Patch扩散模型的高精度空间分辨率数据的预测模型IceDiff将北极海冰预报尺度降至6.25 km x 6.25 km。
2.方法介绍
(1)基于Patch扩散模型的预报-降尺度方法(IceDiff)模型
IceDiff(如图1所示)将基于视觉Transformer的低分辨率、大空间尺度预报模型与基于Patch方法的降尺度扩散模块结合,在实现不同时间尺度下低分辨率北极海冰精确预报的同时,将北极海冰预报空间尺度大幅细化、提供4倍的预报分辨率,不仅为研究北极海冰局部变化研究提供了支撑,也使得更精确的北极航线规划成为可能。
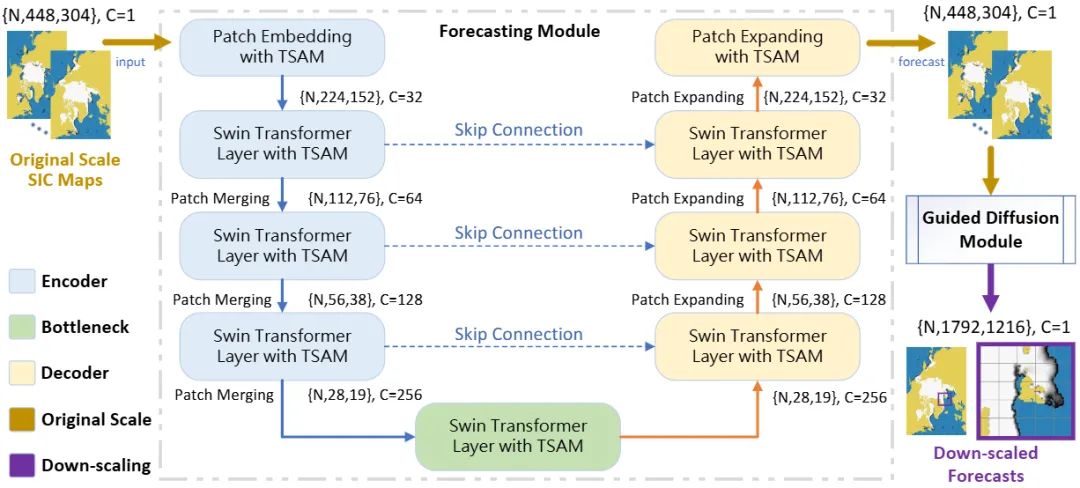
图1 IceDiff模型架构
(2)低分辨率海冰预报引导的高分辨率扩散模块(Guided Diffusion Module)
IceDiff基于Patch的扩散模型(如图2所示)实现高分辨率的北极海冰预报。利用卷积核学习低分辨率和高分辨率预报之间的隐含关系(图2a),将低分辨率预报结果基于Patch进行特征提取与融合后,作为扩散模型的先验引导(图2b)迭代更新卷积核参数(图2c),进而生成符合北极海冰分空间布模式的高分辨率预报结果(如图3所示)。
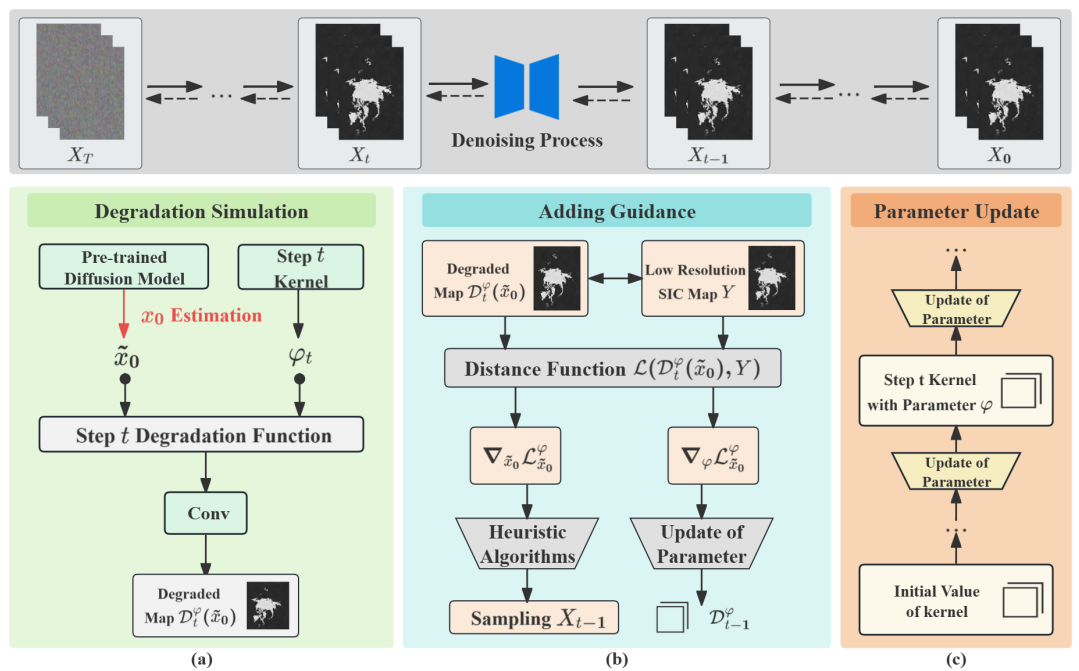
图2 基于Patch方法和低分辨率SIC引导的扩散模型
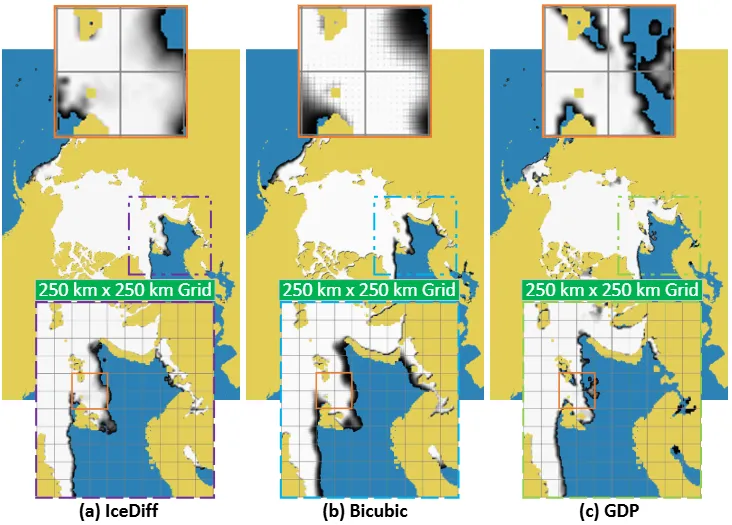
图3 高分辨率预报可视化细节对比
3.实验结果
IceDiff不仅在预报相关性能指标上超过对比方法(如表1a、b所示),在极端事件的预报结果上,IceDiff对2016年北极海冰范围的历史低值时期,以及2022年北极海冰相较过往年份出现的异常增加,都做出了较为精确的预报(如图4所示),体现了其具备良好的分布外预报能力。
表1 北极海冰预报实验结果(测试集为2016至2023年)(a)低分辨率预报结果(b)高分辨率预报质量比较
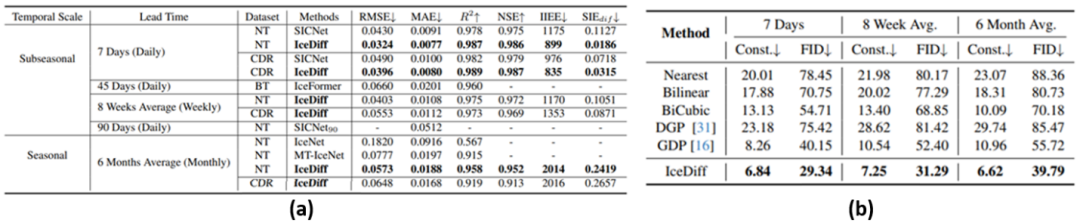
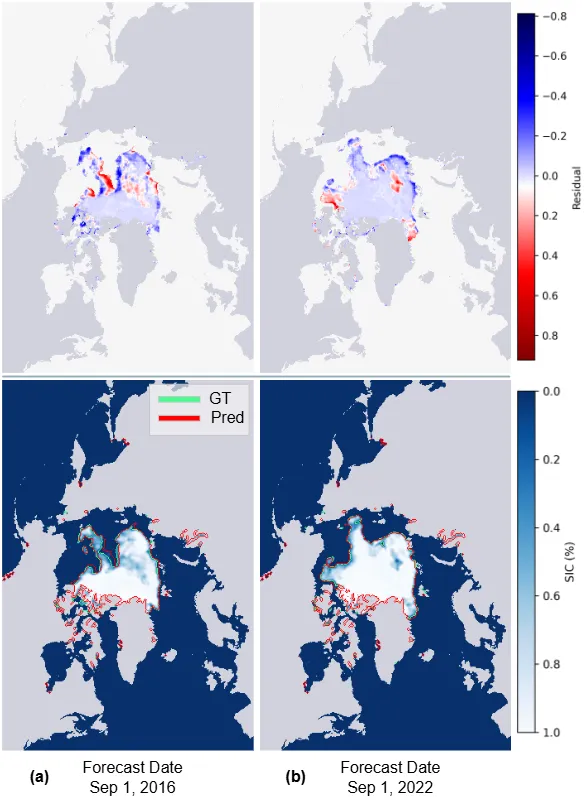
图4 北极海冰极端变化预报
04
Mitigating Hallucinations in Large Vision-Language Models via DPO: On-Policy Data Hold the Key
作者:
杨志赫1,3,骆煦芳2*,韩东起2,徐云建1,3*,李东胜2
单位:
1香港中文大学
2微软亚洲研究院
3香港中文大学,香港中文大学深圳研究院
邮箱:
zhyang@link.cuhk.edu.hk
xufang.luo@microsoft.com
dongqihan@microsoft.com
yunjianxu@cuhk.edu.hk
dongsli@microsoft.com
论文:
https://doi.org/10.1109/CVPR52734.2025.00992
代码链接:
https://github.com/zhyang2226/OPA-DPO
项目主页:
https://opa-dpo.github.io
发表会议:CVPR 2025
*通讯作者
1.研究背景
在视觉多模态大语言模型领域,生成内容与图像不符的“幻觉”现象,是亟待攻克的核心难题。作为一种简单有效的解决方案,直接偏好优化(DPO)正备受关注。研究者们通过比较模型在同一图文输入下的不同响应,根据幻觉程度构造偏好数据对进行训练。然而,不同的数据构造方法会导致显著的性能差异。为此,作者们对“基于DPO消除多模态幻觉”的各类算法进行了全面分析,总结了其表现与局限,并从理论层面揭示了性能差异的根本原因:决定模型效果的关键,在于构建偏好对的数据相对于参考策略(reference policy)是否“同策略分布(on-policy)”。
2.方法介绍
作者们首先对现有的工作总结为以下三类:
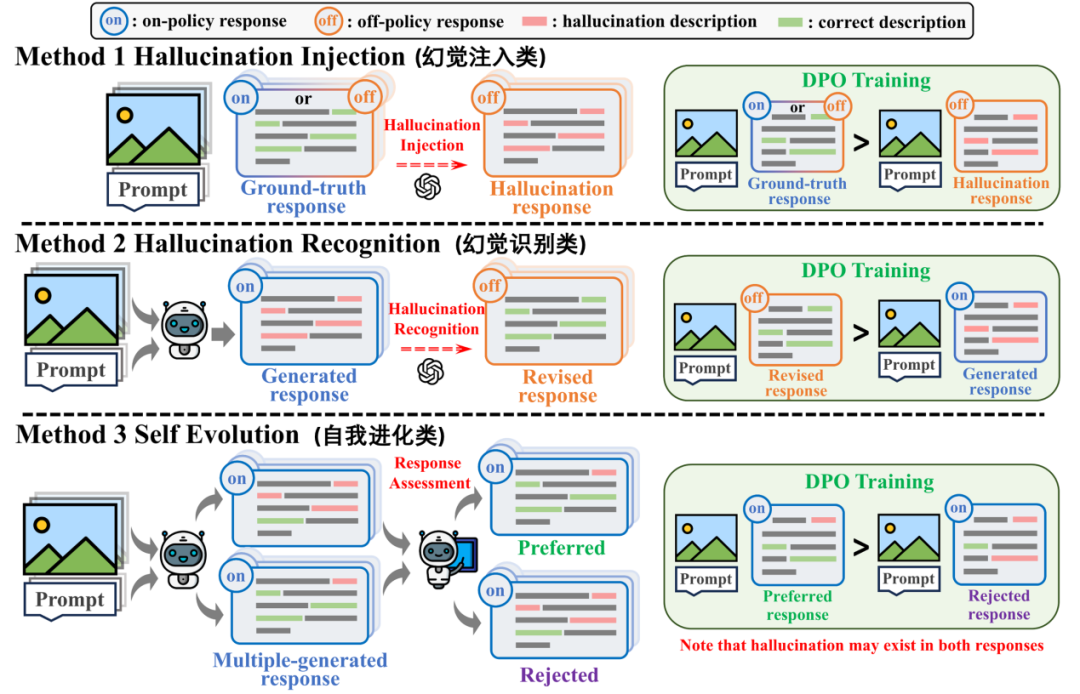
图1 三类此前的研究工作
根据实验结果,这三类算法的性能总结为:自我进化类 > 幻觉识别类 > 幻觉注入类。对于幻觉注入类,幻觉通常并不来自模型本身,因此通过 DPO 训练往往不能给模型带来很大增益。对于自我进化类,理论上由于维度灾难问题,让模型自行探索并找到完全正确的回复是十分困难的,所以那些存在于多个回复中的顽固幻觉通常无法通过这种方法消除。直觉上,幻觉识别类的方法应该是最高效的解决幻觉的方案,但它在实践中却劣于自我进化类。
通过简明的数学推导,作者们发现:受限于 DPO 训练过程中隐式的 KL 散度约束,幻觉识别任务中常用的“异策略(off-policy)”数据会引发梯度消失现象。因此,即便这些样本的质量很高,受算法本身的机制所限,也无法发挥应有的效用。
针对现有方法的局限性,作者们提出了一种简单而高效的算法 On-Policy Alignment(OPA)-DPO,将专家的精确反馈数据在 DPO 训练前通过LoRA-SFT与模型策略对齐。在仅使用4.8k数据的情况下,OPA-DPO 可以实现目前 SOTA 的性能,而之前的 SOTA 算法需要16k数据。其流程及效果示意图如下:
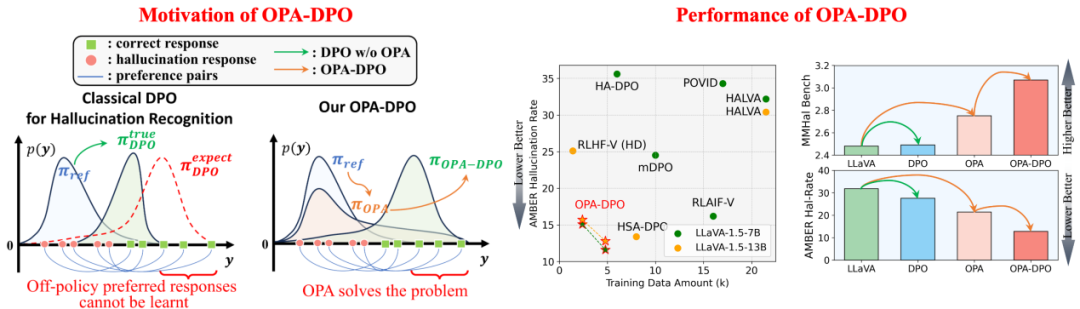
图2 OPA-DPO的流程及效果示意图
OPA-DPO 的具体实现方法如下:首先,给定图像和提示,让模型自行生成对应的响应;接着,利用专家反馈(如 GPT-4v)对生成内容进行细粒度修改,保留正确的响应部分,同时纠正其中存在的幻觉内容;然后,将数据集中的真实响应与专家修改后的响应进行 LoRA-SFT 微调,得到一个新的模型(研究员们将其称为 OPA 模型);最后,在OPA 模型的基础上,进行后续的 DPO 训练。
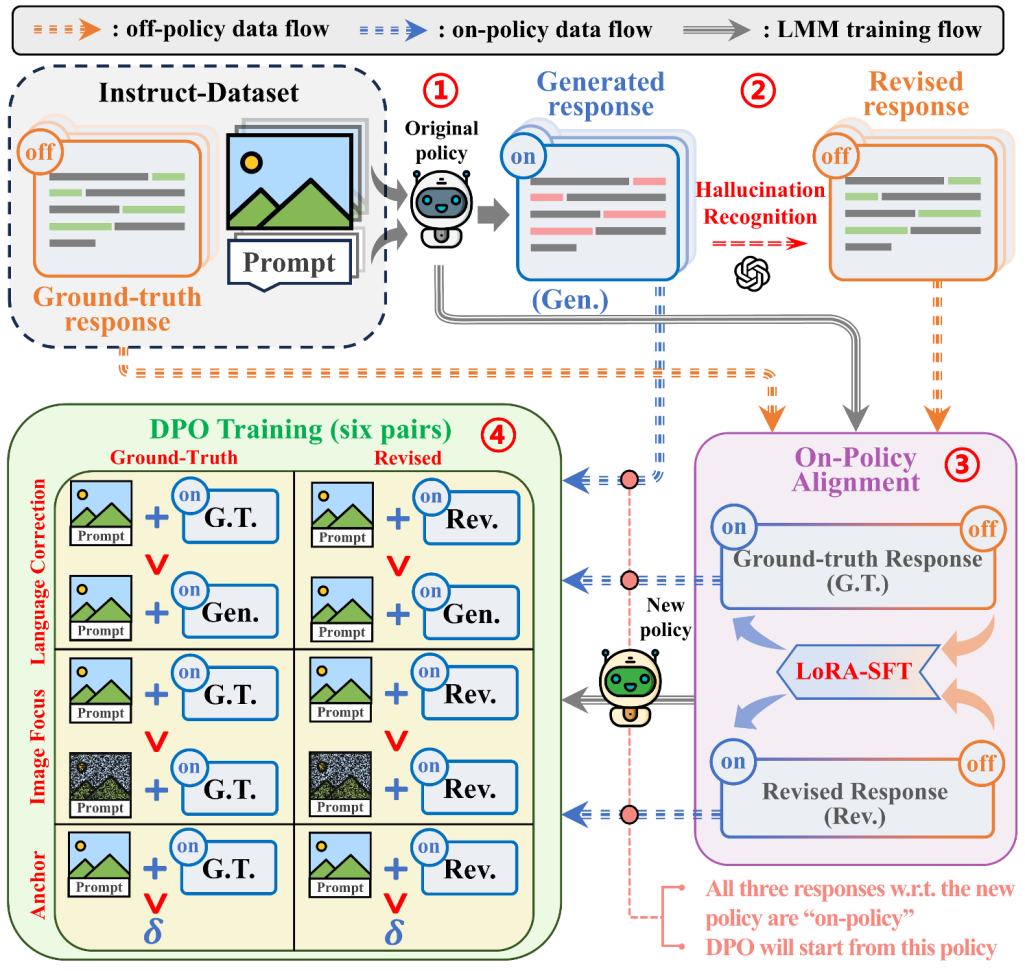
图3 OPA-DPO的具体实现
3.实验结果
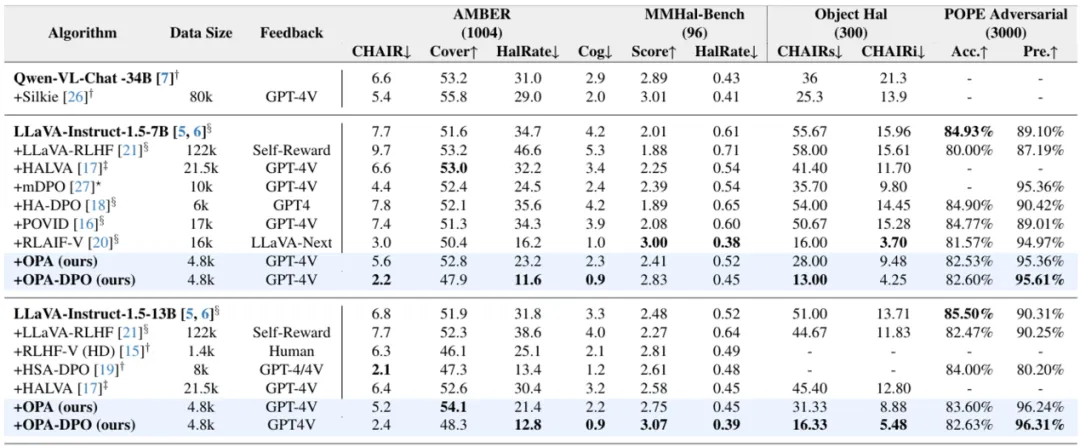
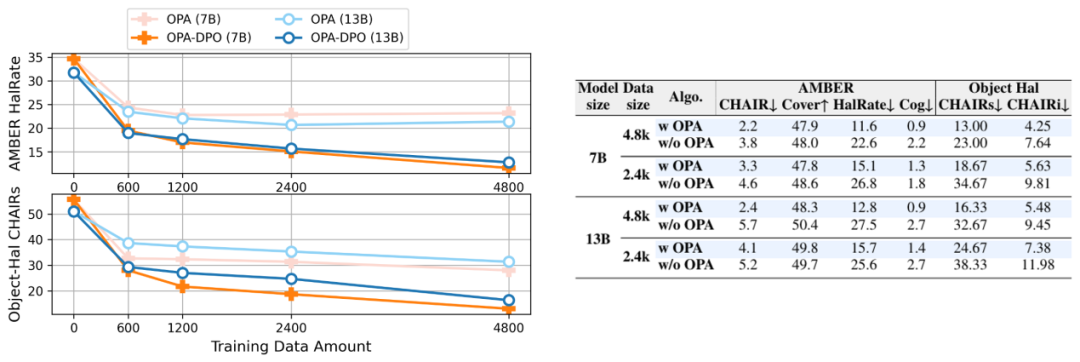
作者们综合比较了基于 LLaVA-1.5-7B 和 13B 模型微调的各种 DPO-based 的算法,OPA-DPO 在使用 4.8k 数据的情况下可在多个指标上实现 SOTA 效果。
表1 在四种主流的幻觉bench上各算法之间的效果比较。为公平比较各类RLAIF/RLHF增强LVLM的算法,作者们在多个基准上统一使用了贪婪采样评估,标注了来源以区分官方复现与论文结果,并对每组指标中的最佳成绩加粗标示
为了验证 OPA 操作的重要性以及数据量对最终效果的影响,作者们进行了细致的消融实验。
表2 训练数据量和OPA操作对OPA-DPO的影响(消融实验)
4.总结
OPA-DPO 中“利用专家反馈生成同策略(on-policy)数据”的理念,已被证实为多模态对齐训练的重要突破口。腾讯混元多模态团队的最新视频生成模型 Hunyuan-Video1.5,正是采用了该算法对全系列 Caption 模型的幻觉问题进行压制,并取得了显著成效。
05
LoRASculpt: Sculpting LoRA for Harmonizing General and Specialized Knowledge in Multimodal Large Language Models
作者:
梁健1,†,黄文柯1,†,万冠呈1,†,杨衢1,叶茫1*
单位:
1武汉大学
邮箱:
jianliang@whu.edu.cn
wenkehuang@whu.edu.cn
guanchengwan@whu.edu.cn
yangqu@whu.edu.cn
yemang@whu.edu.cn
论文:
https://arxiv.org/abs/2503.16843
代码链接:
https://github.com/LiangJian24/LoRASculpt
发表会议:CVPR 2025 Oral
*通讯作者
共同第一作者
1.研究背景
多模态大模型凭借大规模预训练,在跨模态理解任务中展现出强大的通用能力。然而,在实际应用中,模型往往需要通过视觉指令微调来适配各种下游任务。这一过程不可避免地引入通用知识与任务特定知识之间的冲突:模型在获得专用能力的同时,容易遗忘预训练阶段所学到的通用知识。低秩适配(LoRA)作为一种参数高效微调方法,被广泛用于大模型和多模态大模型中。尽管 LoRA在一定程度上缓解了全参数微调带来的遗忘问题,但其在指令微调过程中仍会对预训练权重产生密集的参数更新,从而带来灾难性遗忘的风险。进一步地,本文发现,该遗忘问题并不局限于语言模型主体:多模态大模型中承担跨模态对齐功能的连接器模块同样会发生显著遗忘,表明在多模态大模型中,保持通用知识的下游微调仍然面临额外挑战。
2.方法介绍
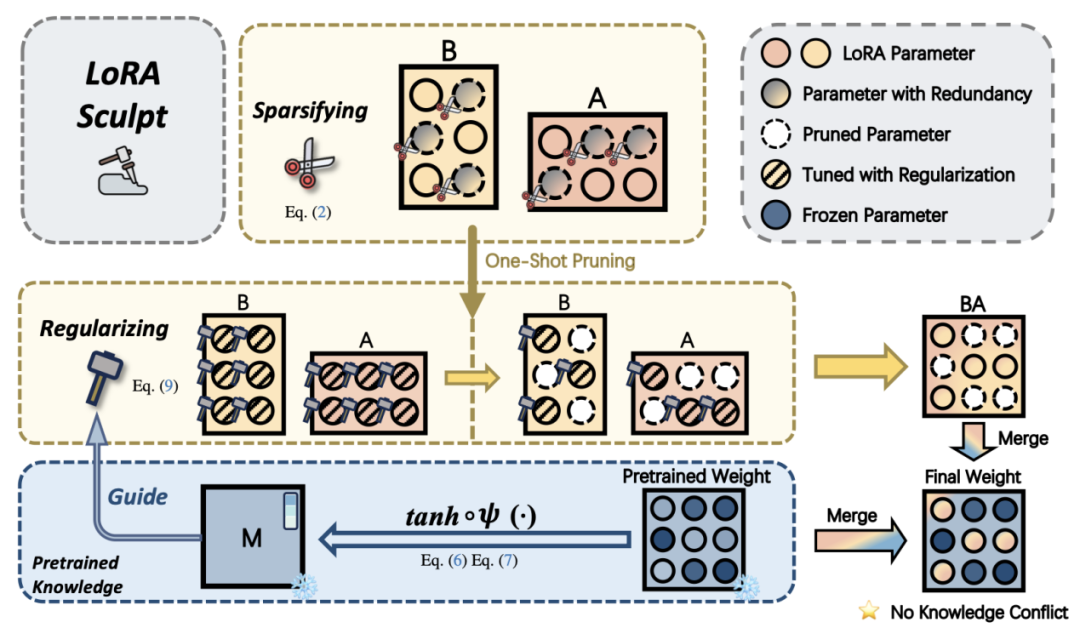
图1 LoRASculpt框架图
本文首先通过实证分析发现,LoRA 在指令微调后会引入相当一部分显式的冗余更新,这些更新不仅未能有效服务于下游任务学习,反而加剧了通用知识的退化。尽管训练后剪枝类方法在一定程度上能够缓解这一问题,但随着稀疏度的提高,往往会对下游性能造成损伤,难以在通用能力保持与任务性能提升之间取得稳定平衡。
基于上述观察,本文的核心动机在于:是否可以在训练过程中对 LoRA 进行“雕刻”,使其仅在必要参数位点精确注入稀疏的任务知识,从而缓解多模态大模型中的通用知识遗忘问题,并促进通用与专业知识的协调。
围绕这一目标,本文关注并解决 LoRA 在多模态大模型指令微调过程中面临的两个关键挑战。第一,如何在 LoRA 训练阶段有效引入稀疏性,以消除有害冗余更新,实现稀疏精确的参数更新,而非依赖训练后剪枝。由于 LoRA 的权重增量由低秩矩阵乘积构成,其权重增量的稀疏性难以直接在训练过程中施加。针对这一挑战,本文在理论分析的支撑下,在 LoRA 训练过程中引入稀疏精确的参数更新机制,将任务特定知识压缩并注入至有限且关键的参数子空间中。第二,在实现稀疏更新之后,如何进一步矫正 LoRA 的更新轨迹,缓解其与预训练模型中承载通用知识的关键参数区域之间的冲突。为此,本文提出一种基于预训练权重信息的冲突缓解正则化方法,在优化过程中引导 LoRA 的更新避开对通用知识敏感的参数位置,从而在保持下游任务性能的同时,降低对预训练知识的破坏。此外,考虑到多模态大模型中连接器模块在结构与功能上的差异,本文对其采用了相应的适配策略,以进一步缓解多模态大模型特有结构连接器中的遗忘问题。
基于上述设计,本文提出通专知识协同的参数高效微调框架 LoRASculpt,通过在下游任务训练阶段对 LoRA 进行“雕刻”,实现多模态大模型中通用知识与专业知识的有效协调。方法整体框架如图 1 所示。
3.实验结果
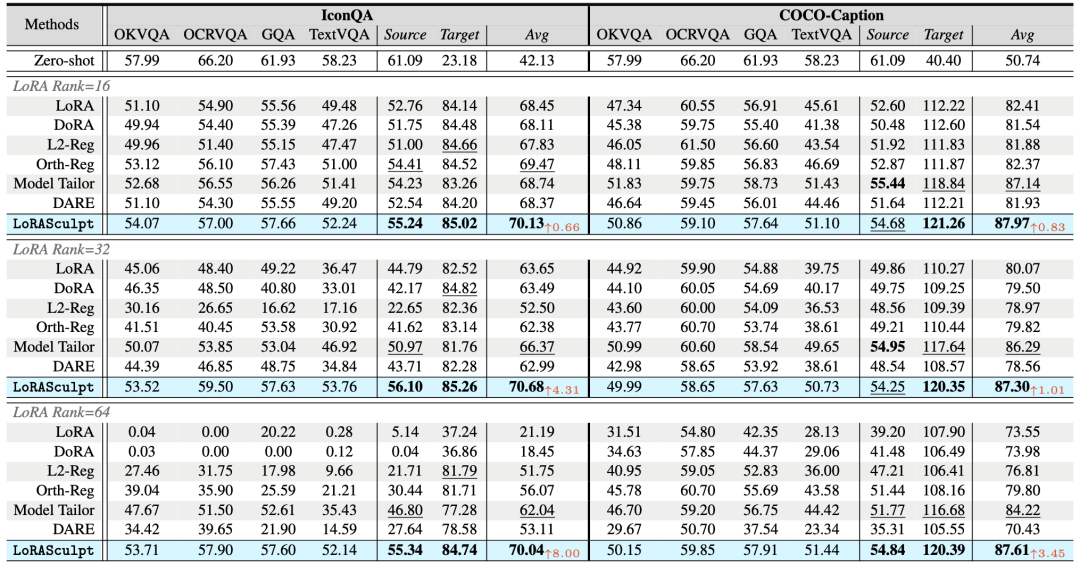
在不同LoRA rank的设置下,LoRASculpt 在不同的下游任务上均取得了强大的性能,且在通用知识与下游知识之间保持了更好的平衡,体现出更强的整体鲁棒性。相比之下,依赖训练后剪枝的方法虽然在一定程度上能够缓解冗余更新,但通常伴随着下游性能受损的风险;另外,未引入抗过拟合或冲突缓解机制的参数高效微调方法 LoRA 与 DoRA 在高秩设定下出现明显的灾难性遗忘,Source 性能大幅下降。相比之下,LoRASculpt 则能稳定保持通用与下游性能,实现更好的通专知识协同。
表1 不同数据集下的方法对比结果
更长的训练过程通常伴随着更强的遗忘现象。随着训练的进行,标准 LoRA 以及对比方法的 Source 性能持续下降,而 LoRASculpt 的下降幅度显著更小。与此同时,LoRASculpt 的 Target 性能稳步提升,表明其在不同训练设置下均表现出更好的稳定性与整体鲁棒性。
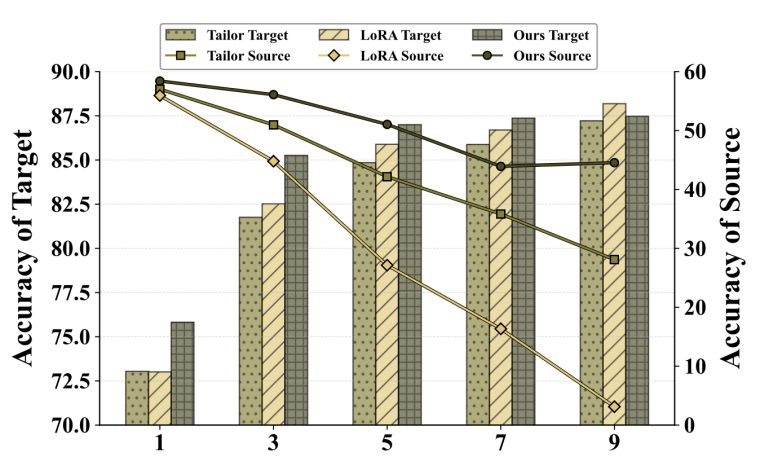
图2 不同训练epoch下的source与target性能对比
4.总结
本文提出通专知识协同的参数高效微调框架LoRASculpt,通过在下游任务训练阶段实现稀疏而精确的参数更新,并结合预训练知识引导优化过程,有效缓解多模态大模型微调中的灾难性遗忘,促进通用知识与下游知识的稳定融合。

编辑人:吴建龙、任文琦
专委会责任副主任:张勇东
 京公网安备11010802017125号
京公网安备11010802017125号